谢赛宁团队重磅新作带来新方向:宣判VAE“退役“,“RAE”将接棒!!!
尽管"压缩催生智能"是AI领域的经典认知,但VAE的压缩方式并未产生预期效果:其潜空间的信息承载能力与原始3通道像素几乎无异,反而因过度压缩丢失大量细节信息,直接限制了生成图像的精细度。更关键的是,SD-VAE的设计初衷并未将"高质量表征学习"纳入目标,这种先天定位偏差使得基于VAE的扩散模型不仅收敛速度缓慢,最终生成质量也难以突破瓶颈。采用RAE的模型收敛速度比基于SD-VAE的REPA快达16
一、行业地震:谢赛宁宣判VAE"退役",三大硬伤成致命短板

AI生成模型领域再迎颠覆性突破。知名学者谢赛宁团队通过最新研究正式宣告:支撑扩散模型发展数年的VAE(变分自动编码器)已走到尽头,其地位将由全新的RAE(表征自编码器)彻底取代。这一结论并非空穴来风,而是源于VAE在当前技术生态中暴露的无法调和的三大核心缺陷。
- 论文链接:https://t.co/FGOAP3Eg5m
- 项目链接:https://rae-dit.github.io/
1. 算力黑洞:过时架构拖垮效率
作为2021年推出的技术,SD-VAE采用的骨干网络早已跟不上Transformer时代的节奏。实测数据显示,SD-VAE完成一次图像编码需消耗约450 GFLOPs的运算量,而基于标准化ViT架构的简易编码器(如ViT-B)仅需22 GFLOPs即可达成同等目标,算力成本相差20倍以上。在大模型参数持续扩张的当下,这种低效架构已成为性能提升的严重桎梏。
2. 信息瓶颈:过度压缩得不偿失
VAE的核心设计思路是通过压缩构建低维潜空间,但这种策略在实践中走向了极端——将图像强行压缩至仅4个通道的潜空间。尽管"压缩催生智能"是AI领域的经典认知,但VAE的压缩方式并未产生预期效果:其潜空间的信息承载能力与原始3通道像素几乎无异,反而因过度压缩丢失大量细节信息,直接限制了生成图像的精细度。
3. 表征孱弱:生成质量的先天缺陷
生成模型的性能高度依赖表征质量,而VAE仅依赖重建训练的模式,导致其学得的特征质量极低,线性探测精度仅约8%。更关键的是,SD-VAE的设计初衷并未将"高质量表征学习"纳入目标,这种先天定位偏差使得基于VAE的扩散模型不仅收敛速度缓慢,最终生成质量也难以突破瓶颈。
二、RAE横空出世:极简设计颠覆行业认知
面对VAE的诸多弊端,谢赛宁团队提出的RAE给出了堪称"降维打击"的解决方案。这种新型表征自编码器以"预训练编码器+轻量解码器"的极简架构,实现了性能的全面超越,更打破了学界此前的诸多认知误区。
1. 核心架构:站在巨人肩膀上的创新
RAE的设计思路堪称"大道至简",其核心是冻结的预训练表征编码器与专属训练的轻量级解码器的高效配对。编码器直接选用DINOv2、SigLIP、MAE等经过海量数据训练的成熟模型——这些模型已具备强大的视觉表征能力,无需额外微调即可输出高质量特征;解码器则基于轻量级ViT架构构建,通过组合损失函数进行针对性训练,优化目标公式为:
L=λL1LL1+λLPIPSLLPIPS+λGANLGAN\mathcal{L} = \lambda_{\text{L1}} \mathcal{L}_{\text{L1}} + \lambda_{\text{LPIPS}} \mathcal{L}_{\text{LPIPS}} + \lambda_{\text{GAN}} \mathcal{L}_{\text{GAN}}L=λL1LL1+λLPIPSLLPIPS+λGANLGAN
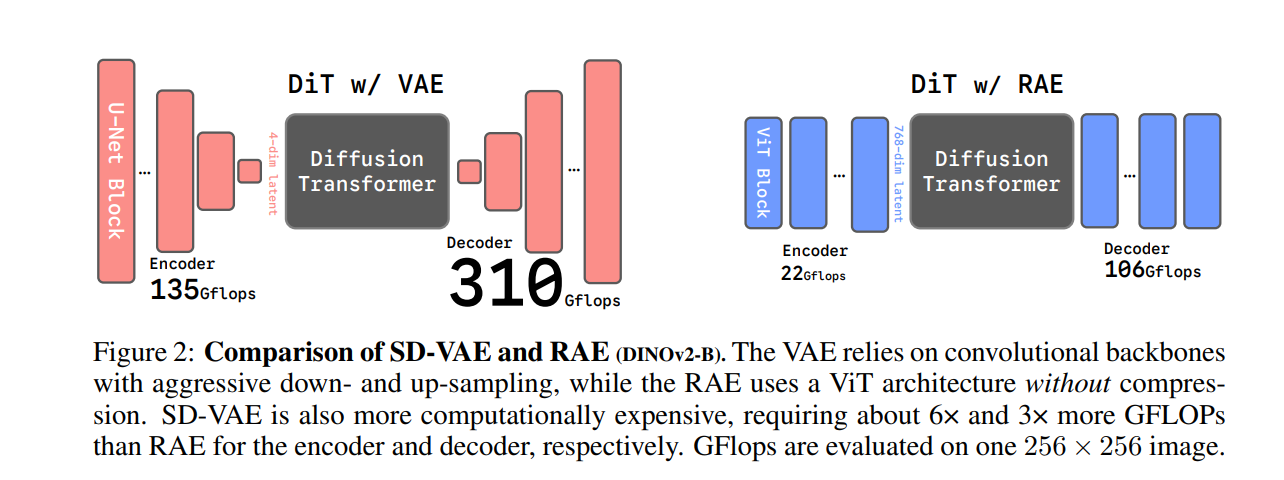
这种设计彻底摒弃了传统方法中的额外训练对齐阶段、辅助损失函数和重新压缩适配层,却实现了对SD-VAE的重建质量反超。例如使用MAE-B/16编码器的RAE,重建FID(rFID)仅为0.16,远优于传统VAE的表现。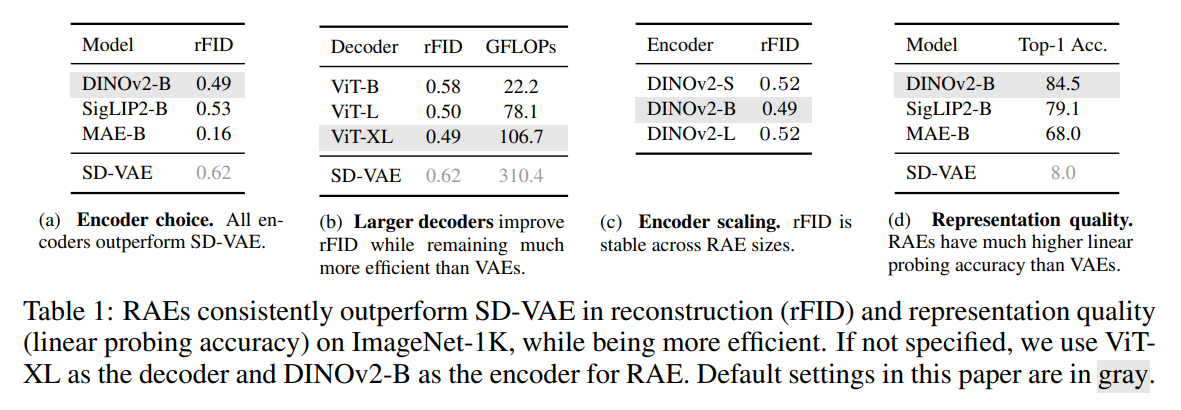
2. 认知颠覆:高维空间的"反常识"突破
在研究过程中,谢赛宁团队修正了两个关键认知误区:此前曾认为语义编码器会舍弃细粒度视觉细节,且担忧扩散模型在高维空间难以高效去噪,但RAE的实践证明这两种担忧均不成立。
由于RAE的潜空间本质为高维结构(通道数远高于VAE的4通道),扩散Transformer(DiT)需进行针对性适配,但仅需三项简单调整便实现了性能飞跃:
- 宽DiT设计:明确变换器宽度d必须至少等于潜表征维度n,这一约束是模型处理高维信息的基础,否则甚至无法过拟合单个样本;
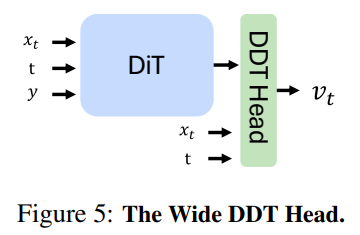
- 自适应噪声调度:借鉴高分辨率图像生成中的成熟策略,通过调整噪声分布参数,使扩散模型平滑适应高维输入通道的变化;
- 抗噪解码器训练:在解码器训练过程中主动注入微量噪声,大幅提升其对潜空间微小扩散误差的鲁棒性,使其能优雅处理重建中的细微瑕疵。
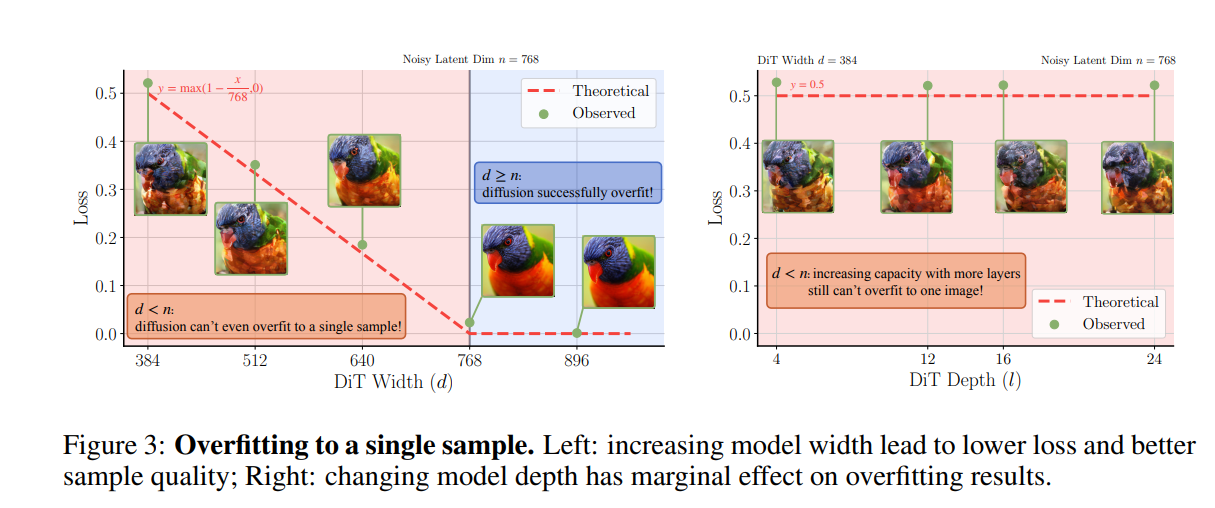
三、性能炸裂:16倍速收敛+SOTA级生成效果
RAE的极简设计背后,是足以改写行业标准的性能表现。在ImageNet数据集的严格测试中,配备轻量级宽型DDT头部的DiT变体(DiT^DH)取得了多项突破性成果,验证了RAE的技术价值。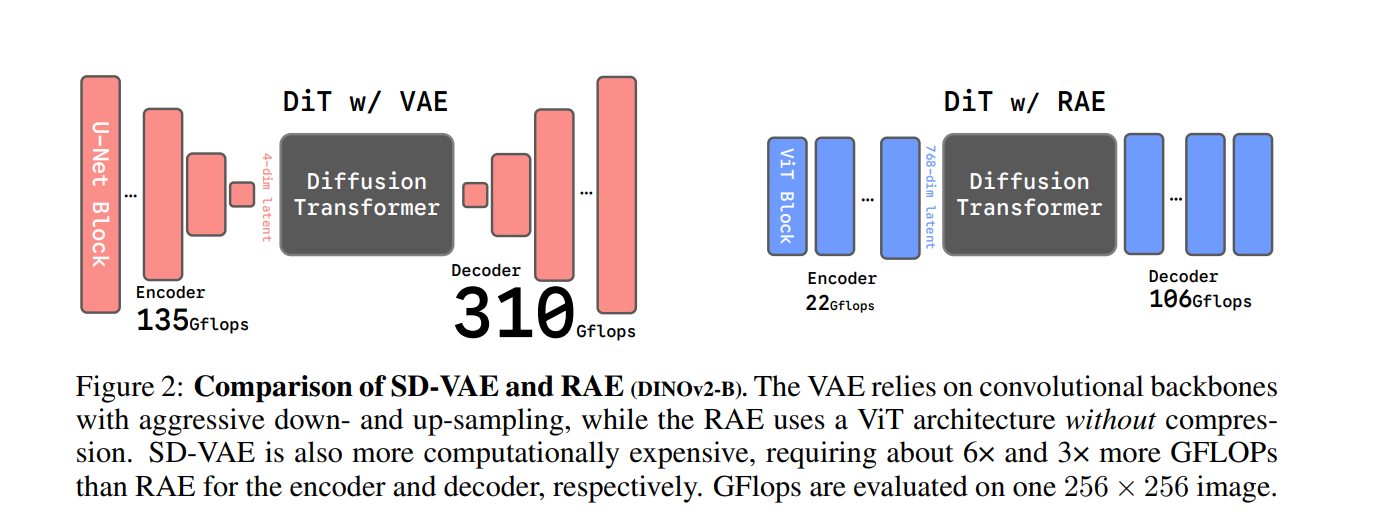
1. 生成质量刷新纪录
作为衡量生成模型性能的核心指标,FID(弗雷歇 inception 距离)数值越低代表生成质量越高。谢赛宁团队的实验显示:
- 256×256分辨率下,无引导(no guidance)条件FID=1.51;
- 256×256和512×512分辨率下,有引导(with guidance)条件FID均达到1.13。
这一成绩不仅远超基于VAE的传统方法,也优于此前的表征对齐技术(REPA),处于当前领域的领先水平。
2. 训练效率指数级提升
除了生成质量,RAE在训练效率上的提升更为惊人。采用RAE的模型收敛速度比基于SD-VAE的REPA快达16倍——这意味着原本需要数周的训练任务,如今仅需数天即可完成,大幅降低了扩散模型的研发成本和时间周期。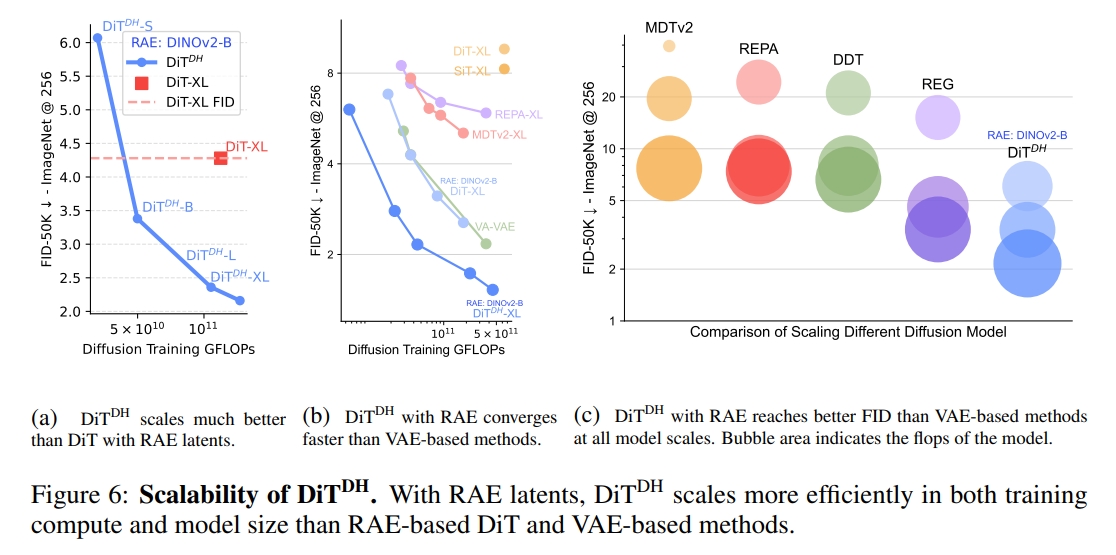
3. 可扩展性实现质的飞跃
针对"暴力扩展DiT宽度导致效率低下"的行业痛点,团队设计了创新的DiTDH架构:以原始DiT作为条件化骨干网络,驱动一个极宽但极浅的扩散头部,该头部直接以含噪潜变量x_t为输入预测速度向量。借助RAE潜变量的特性。DiT DH在训练计算量和模型大小方面的扩展效率,均显著优于基于RAE的标准DiT以及基于VAE的传统方法。
四、行业洗牌:生成模型迈入"表征优先"新时代
RAE的诞生不仅是一项技术突破,更标志着生成模型领域迎来范式转换。其成功印证了"表征质量决定生成上限"的核心规律,与谢赛宁团队此前提出的REPA技术形成呼应,共同指向"外部高质量表征赋能生成模型"的发展方向。

对于行业而言,RAE的开源发布将产生多重深远影响:首先,扩散模型训练将告别对VAE的路径依赖,RAE有望成为DiT训练的全新默认方案;其次,预训练表征编码器的价值将进一步凸显,DINO、SigLIP等模型或将成为生成领域的基础组件;最后,高效训练与高质量生成的平衡难题得到缓解,将加速生成模型在工业设计、数字内容创作等领域的落地应用。
正如谢赛宁在推文中所言,RAE的突破源于对传统认知的质疑与验证。这一成果不仅为生成模型的发展提供了新路径,更激励着学界以更开放的视角重新审视现有技术框架——AI生成的下一个黄金时代,或许正由此开启。
五、项目入门:快速上手,先人一步!
1 环境配置
创建环境并通过uv进行安装:
conda create -n rae python=3.10 -y
conda activate rae
pip install uv
# 安装支持CUDA 12.1的PyTorch 2.2.0
uv pip install torch==2.2.0 torchvision==0.17.0 torchaudio --index-url https://download.pytorch.org/whl/cu121
# 安装其他依赖
uv pip install timm==0.9.16 accelerate==0.23.0 torchdiffeq==0.2.5 wandb
uv pip install "numpy<2" transformers einops omegaconf
2 数据与模型准备
2.1 下载预训练模型
该项目提供三类模型:RAE解码器、DiTDH扩散转换器以及用于潜在归一化的统计数据。如需一次性下载所有模型:
cd RAE
pip install huggingface_hub
hf download nyu-visionx/RAE-collections \
--local-dir models
若只需下载特定模型,运行:
hf download nyu-visionx/RAE-collections \
<remote_model_path> \
--local-dir models
2.2 准备数据集
下载ImageNet-1k数据集,并通过–data-path参数在第一阶段和第二阶段的脚本中指向训练集分割路径。
3 基于配置的初始化
所有训练和采样入口点均由OmegaConf YAML文件驱动。单个配置文件描述第一阶段自编码器、第二阶段扩散模型以及训练或推理过程中使用的求解器。
3.1 配置文件说明
- stage_1:实例化冻结的编码器和可训练的解码器。在第一阶段训练时,可通过stage_1.ckpt指向现有检查点,或从pretrained_decoder_path开始。
- stage_2:定义扩散转换器。采样时必须提供ckpt;训练时通常省略,以便权重随机初始化。
- transport、sampler和guidance:选择前向/后向SDE/ODE积分器以及可选的无分类器或自动引导调度。
- misc:收集两个阶段都使用的形状、类别计数和缩放常数。
- training:包含训练脚本使用的默认值(轮次、学习率、EMA衰减、梯度累积等)。
第一阶段训练配置还额外包含顶级的gan块,用于配置鉴别器架构以及LPIPS/GAN损失调度。
3.2 提供的配置文件
- 第一阶段:在configs/stage1/pretrained/下提供了适用于DINOv2-B、SigLIP-B、MAE-B的解码器。此外,还有一个在DINOv2-B上训练ViT-XL解码器的训练脚本:configs/stage1/training/DINOv2-B_decXL.yaml。
- 第二阶段:在configs/stage2/sampling/下提供了最佳模型DiTDH-XL及其在256×256和512×512分辨率上的引导模型。同时,在configs/stage2/training/下提供了DiTDH的训练配置。
4 第一阶段:表征自编码器(RAE)
4.1 训练解码器
src/train_stage1.py在保持表征编码器冻结的情况下微调ViT解码器。使用PyTorch DDP(单GPU或多GPU)启动:
torchrun --standalone --nproc_per_node=N \
src/train_stage1.py \
--config <config> \
--data-path <imagenet_train_split> \
--results-dir results/stage1 \
--image-size 256 --precision bf16/fp32 \
--ckpt <optional_ckpt> \
其中,N指可用的GPU卡数量,–ckpt用于从现有检查点恢复训练。
4.2 日志记录
要启用wandb,首先将WANDB_KEY、ENTITY和PROJECT设置为环境变量:
export WANDB_KEY="key"
export ENTITY="entity name"
export PROJECT="project name"
然后在训练命令中添加–wandb标志。
4.3 采样/重建
使用src/stage1_sample.py对单张图像进行编码/解码:
python src/stage1_sample.py \
--config <config> \
--image assets/pixabay_cat.png \
对于批量重建和.npz导出,运行DDP变体:
torchrun --standalone --nproc_per_node=N \
src/stage1_sample_ddp.py \
--config <config> \
--data-path <imagenet_val_split> \
--sample-dir recon_samples \
--image-size 256
该脚本会生成每张图像的PNG文件以及适合FID的打包.npz文件。
5 第二阶段:潜在扩散转换器
5.1 训练
src/train.py使用PyTorch DDP训练第二阶段扩散转换器。编辑configs/training/下的某个配置文件并启动:
torchrun --standalone --nnodes=1 --nproc_per_node=N \
src/train.py \
--config <training_config> \
--data-path <imagenet_train_split> \
--results-dir results/stage2 \
--precision bf16
5.2 采样
src/sample.py使用相同的配置模式在单个设备上绘制一小批图像,并将其保存到sample.png:
python src/sample.py \
--config <sample_config> \
--seed 42
5.3 用于评估的分布式采样
src/sample_ddp.py在GPU间并行采样,生成PNG文件和适合FID的.npz文件:
torchrun --standalone --nnodes=1 --nproc_per_node=N \
src/sample_ddp.py \
--config <sample_config> \
--sample-dir samples \
--precision bf16 \
--label-sampling equal
–label-sampling {equal,random}:equal为每个类别恰好使用50张图像用于FID-50k;random则均匀采样标签。默认使用equal,因其能使FID值始终比random低约0.1。
自动引导和无分类器引导通过配置中的guidance块进行控制。
6 评估
6.1 ADM Suite FID设置
使用ADM评估套件对生成的样本进行评分:
克隆仓库:
git clone https://github.com/openai/guided-diffusion.git
cd guided-diffusion/evaluation
创建环境并安装依赖:
conda create -n adm-fid python=3.10
conda activate adm-fid
pip install 'tensorflow[and-cuda]'==2.19 scipy requests tqdm
下载ImageNet统计数据(此处显示256×256):
wget https://openaipublic.blob.core.windows.net/diffusion/jul-2021/ref_batches/imagenet/256/VIRTUAL_imagenet256_labeled.npz
进行评估:
python evaluator.py VIRTUAL_imagenet256_labeled.npz /path/to/samples.npz

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)