2024-2025年大模型架构完全指南:从DeepSeek-V3到Kimi K2,14个主流LLM架构对比与收藏级趋势分析
本文详细对比分析了2024-2025年间14个主流LLM架构的创新设计,包括DeepSeek V3的MLA与MoE、OLMo 2的归一化层优化、Gemma 3的滑动窗口注意力等。文章总结了当前LLM架构的五大趋势:MoE成为大模型标配、注意力机制持续降成本、归一化层精细化、位置嵌入简化、场景化优化日益明确。这些精准优化旨在提升内存效率、推理速度和训练稳定性,为开发者提供实用参考。
1、文章背景与核心目标
从最早的GPT架构到现在,满打满算已经7年了(截至2025年)。说真的,LLM的“骨架”没怎么变,但“细节装修”一直在优化:比如表示位置的方式,从“绝对嵌入”改成了更灵活的RoPE(旋转位置嵌入);注意力机制从MHA(多头注意力)换成了更省资源的GQA(分组查询注意力);激活函数也从GELU更成了效率更高的SwiGLU。
不过有个麻烦事儿:想对比LLM性能太难了——数据集、训练方法、超参数这些关键信息要么不公开,要么差异太大。所以这篇文章没纠结“谁跑分更高”,而是专门盯着2024-2025年主流开源LLM的架构设计细节讲,一共覆盖了14个代表性模型,核心就是想弄明白:现在的LLM开发者都在“折腾”哪些技术?
2、 主流LLM架构核心特点
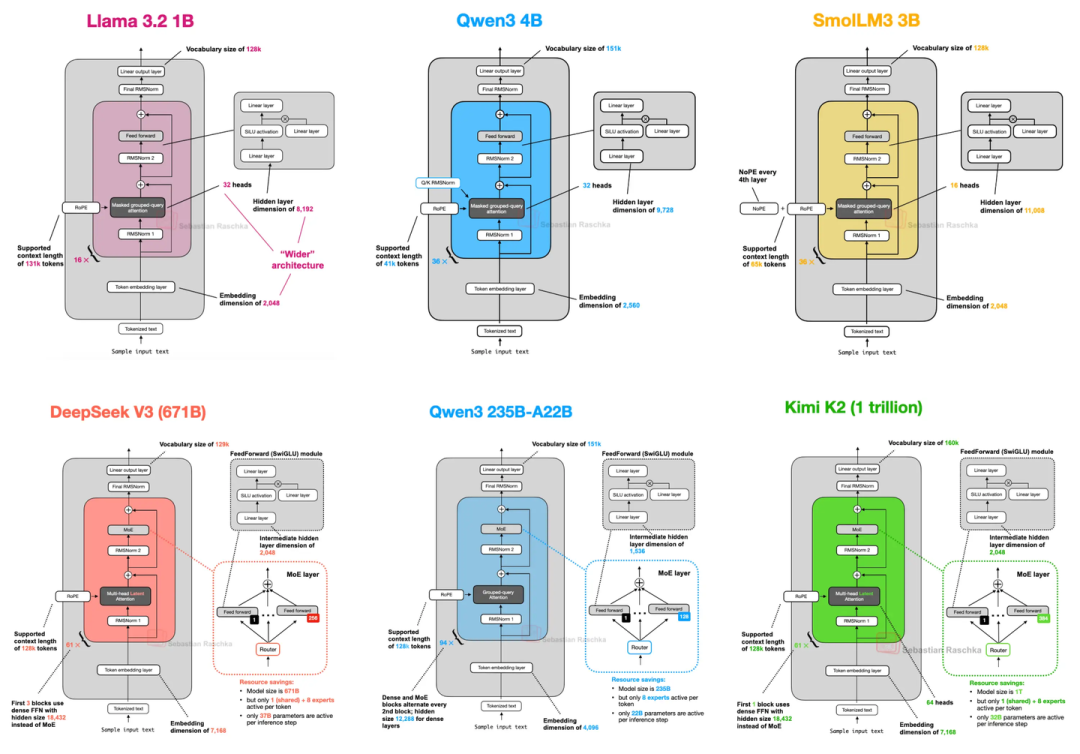
1. DeepSeek V3/R1(2024年底-2025年初火起来的)
这模型最大的亮点是两个技术(MLA和MOE),既省内存又保性能:
1.1 MLA(多头潜在注意力)
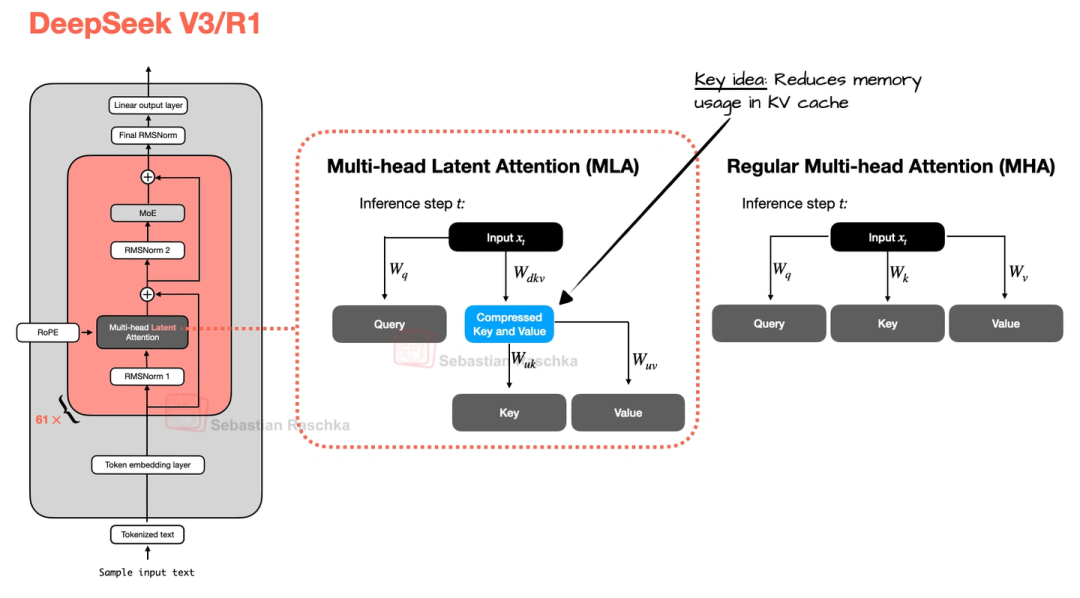
之前的注意力机制存KV缓存(就是存之前的键和值,方便后续推理)时,K和V占内存不小。MLA的办法是先把K、V压缩到低维空间存着,推理的时候再恢复成原来的大小——相当于“压缩文件”存,用的时候再“解压”,不仅省内存,实测性能还比MHA和GQA好一点。
1.2 MoE(混合专家系统)
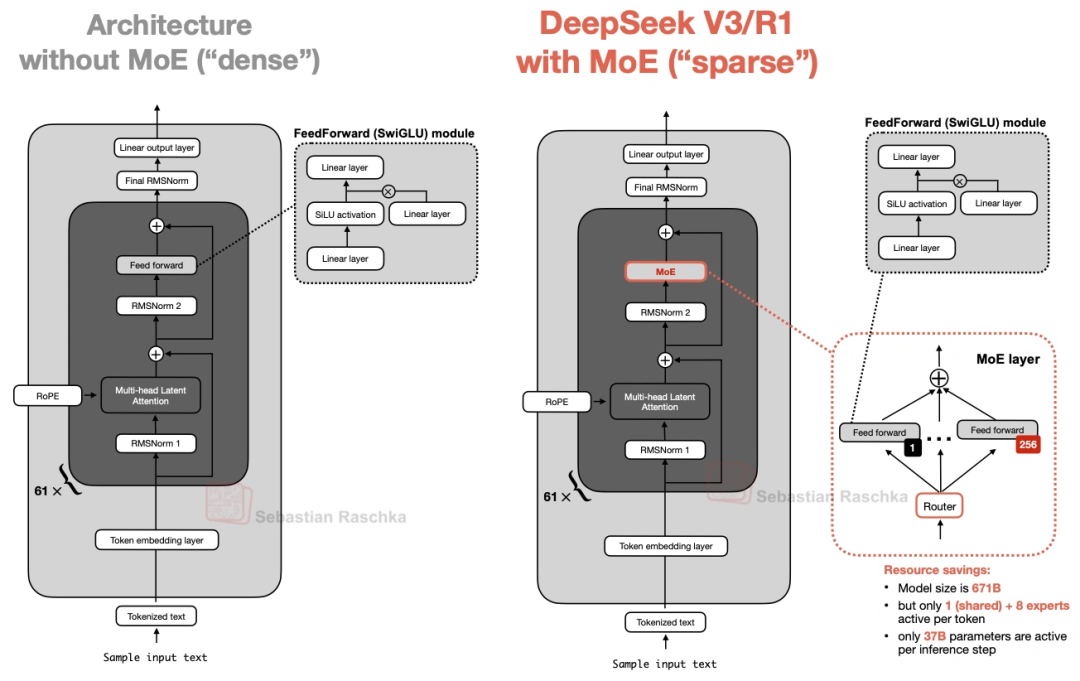
它总共6710亿参数,但不是所有参数都用。每个MoE模块里有256个“专家”(其实就是小的FeedForward模块),推理时只激活9个——1个是所有人都用的“共享专家”,另外8个是按token选的。算下来每次推理只用370亿参数,既保持了大模型的“知识面”,又没那么费资源。
它发布的时候,性能直接超过了Llama 3 405B这些开源模型,算是当时的“开源天花板”之一。
2. OLMo 2(艾伦人工智能研究所2025年1月出的,主打“透明”)
这模型不算跑分最顶的,但胜在训练数据、代码全公开,是个很好的“学习案例”,核心玩的是“归一化层”的花样:
归一化层位置改了:
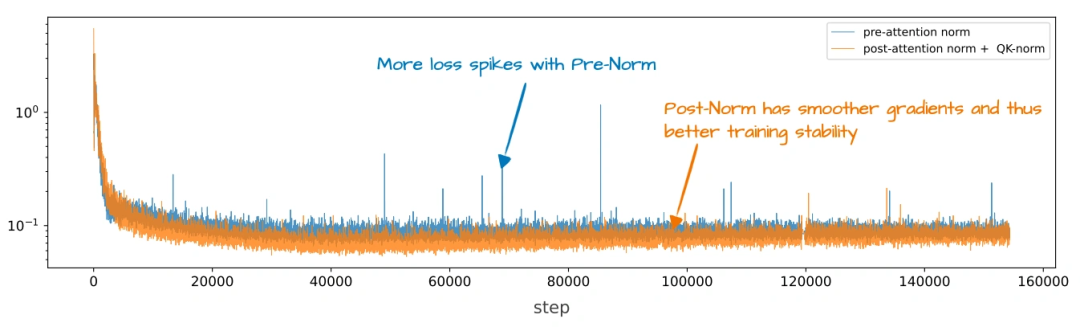
原来的GPT、Llama这些模型,归一化层(RMSNorm,比老的LayerNorm省参数)都放在注意力/FeedForward模块“前面”(叫Pre-Norm);OLMo 2反过来,放在“后面”,但还保留在残差连接里面(叫“类Post-Norm”)。这么改是为了让训练更稳定——看上就能发现,它的训练损失波动比Pre-Norm小多了。
加了QK-Norm:
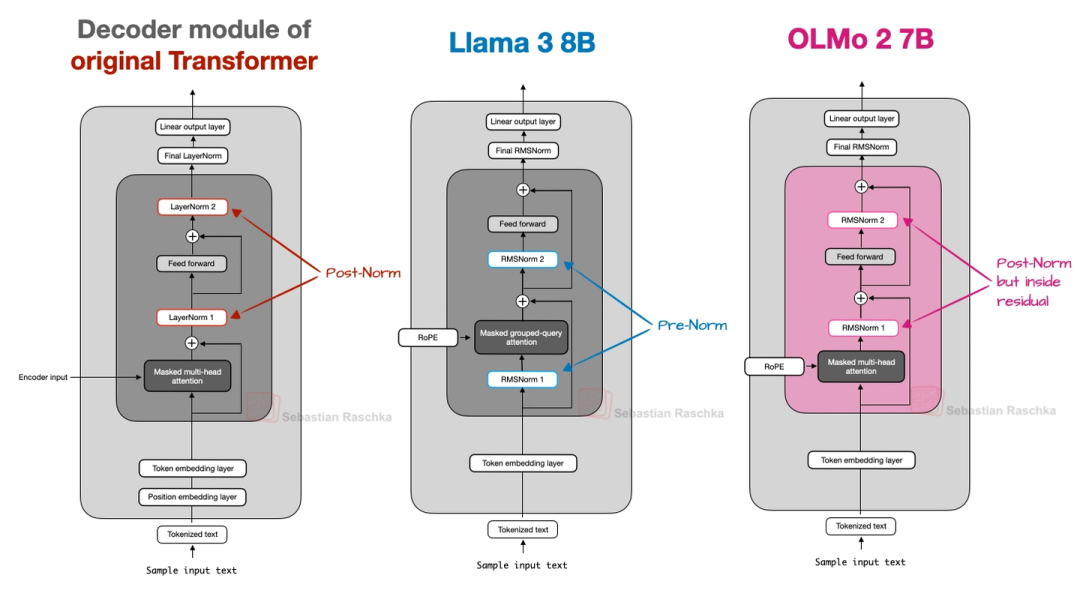
在MHA模块里,给查询(Q)和键(K)单独加了一层RMSNorm,而且是在做RoPE之前。这技术不是它原创的,但加上之后训练稳定性又上了一个台阶(上图对比了Post-Norm、Pre-Norm和OLMo 2的设计,能清楚看到差异)。
另外这个图也很关键:
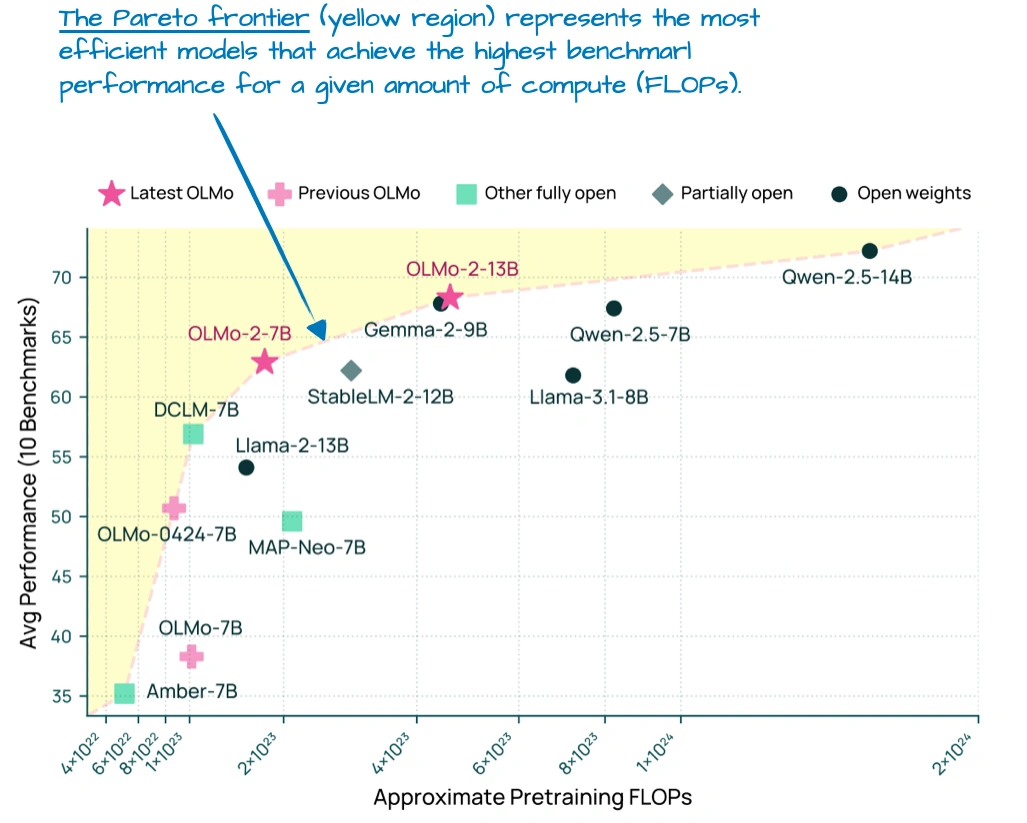
它显示OLMo 2在“性能-计算成本”图上处于“帕累托前沿”——意思是同计算成本下,它性能最好;同性能下,它最省计算,这对想搭高效模型的人很有参考价值。不过它初期用的还是老的MHA,后来才出了32B的GQA版本。
3. Gemma 3(谷歌的,有点被低估)
谷歌这模型主打“27B参数甜点”——比8B模型强不少,又没70B那么费资源,在Mac Mini上都能跑。核心亮点是“滑动窗口注意力”:
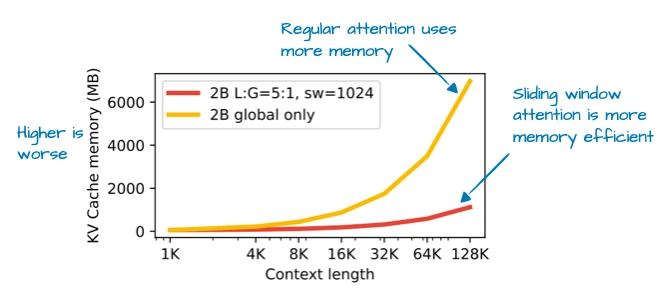
普通注意力是“全局的”,每个token能看所有其他token,但长序列下特费内存。滑动窗口是“局部的”,每个token只看周围一小片(窗口),窗口还会跟着token“滑动”。Gemma 3更狠,搞了5:1的比例——5层局部窗口注意力,才插1层全局注意力,窗口尺寸还从Gemma 2的4096缩到了1024。上图能看到,这么改之后KV缓存内存省了一大截;
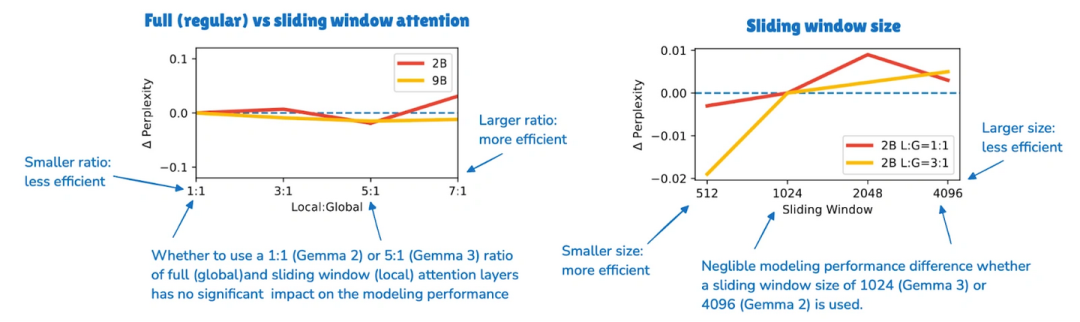
上图可以看到,改了之后性能没怎么掉(生成文本的困惑度几乎没变)。
归一化层“前后都加”:
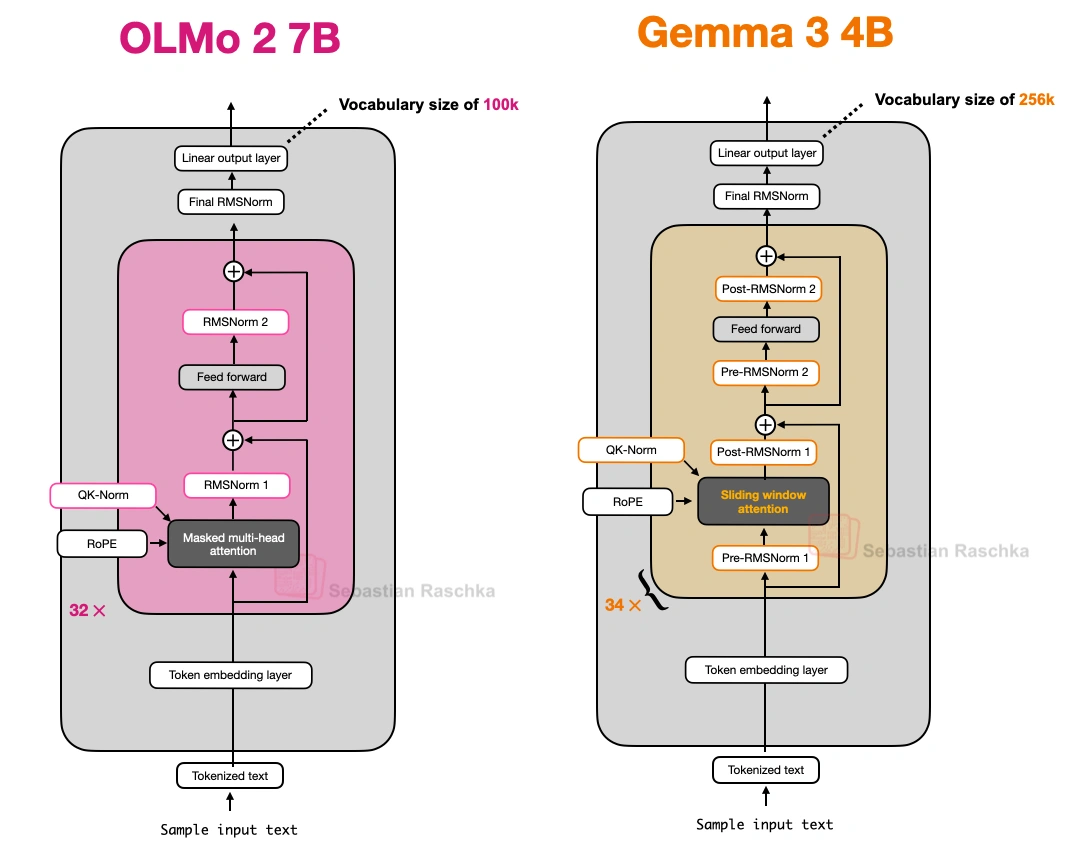
别的模型要么只在模块前(Pre-Norm),要么只在后面(Post-Norm),Gemma 3偏不——注意力/FeedForward模块前后都放RMSNorm,相当于“双重保险”,兼顾两种设计的优点(上图对比OLMo 2和它,能看到多出来的归一化层)。
后来还出了个Gemma 3n,专门给手机用的:
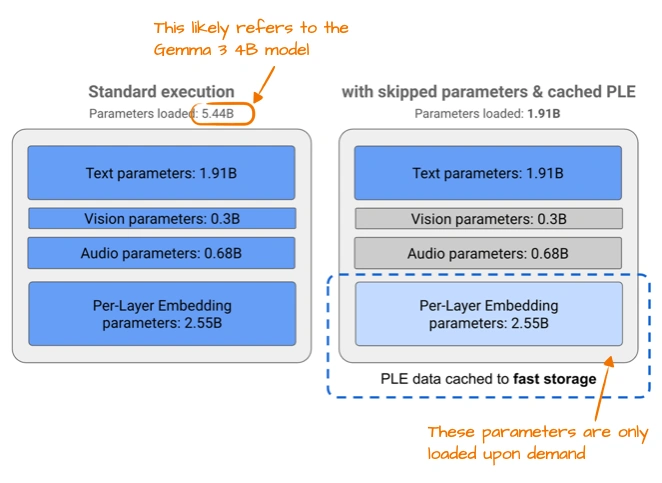
一是用了PLE(逐层嵌入),需要哪个模态的嵌入(文本、音频这些)再从CPU/SSD调,不占内存;二是MatFormer(套娃Transformer),一个大模型能切成多个小模型用,想用多大切多大。
4. Mistral Small 3.1(2025年3月出的,24B参数,主打“快”)
这模型有意思,前代还用滑动窗口注意力,到它这儿直接弃了,改用普通GQA。但它比Gemma 3 27B还快,性能除了数学题差点,其他都更好——秘诀在细节:
- 自定义了Tokenizer(分词器),切词更高效;
- 缩减了KV缓存和Transformer层数,省了不少计算。
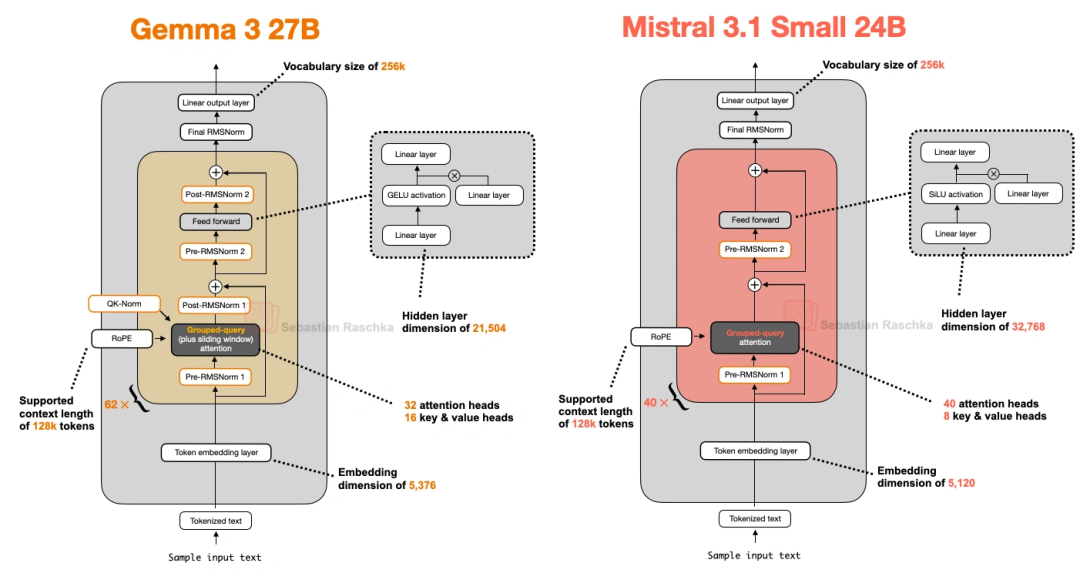
上图对比了它和Gemma 3 27B的架构,能明显看到层数、头数这些差异。推测它弃用滑动窗口,是因为GQA能兼容FlashAttention这种优化代码,虽然滑动窗口省内存,但不如GQA跑得快。
5. Llama 4(Meta的,继续玩MoE)
Llama 4也用了MoE架构,整体和DeepSeek V3很像,但有几个关键差异:
- 注意力用的是GQA,不是DeepSeek V3的MLA;
- MoE是“少而大的专家”——每个token只激活2个专家,每个专家的隐藏层尺寸有8192;而DeepSeek V3是“多而小的专家”,激活9个,隐藏层才2048;
- 它不是所有层都用MoE,而是隔一层用一个MoE模块、隔一层用稠密模块(DeepSeek V3除了前3层,全是MoE)。
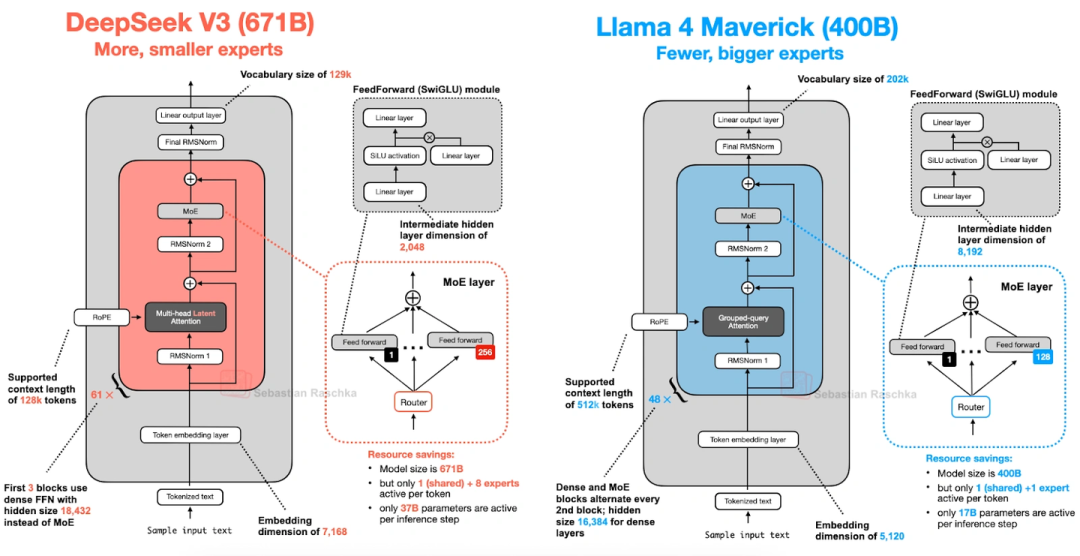
上图把DeepSeek V3(6710亿参数)和Llama 4 Maverick(4000亿参数)放一起比,架构细节一目了然。另外Llama 4还支持多模态,但文章只聊了它的文本部分。
6. Qwen3(阿里云的,型号特别全)
Qwen3分“Dense版”和“MoE版”,覆盖了从0.6B到235B的参数规模,特别灵活:
Dense版:
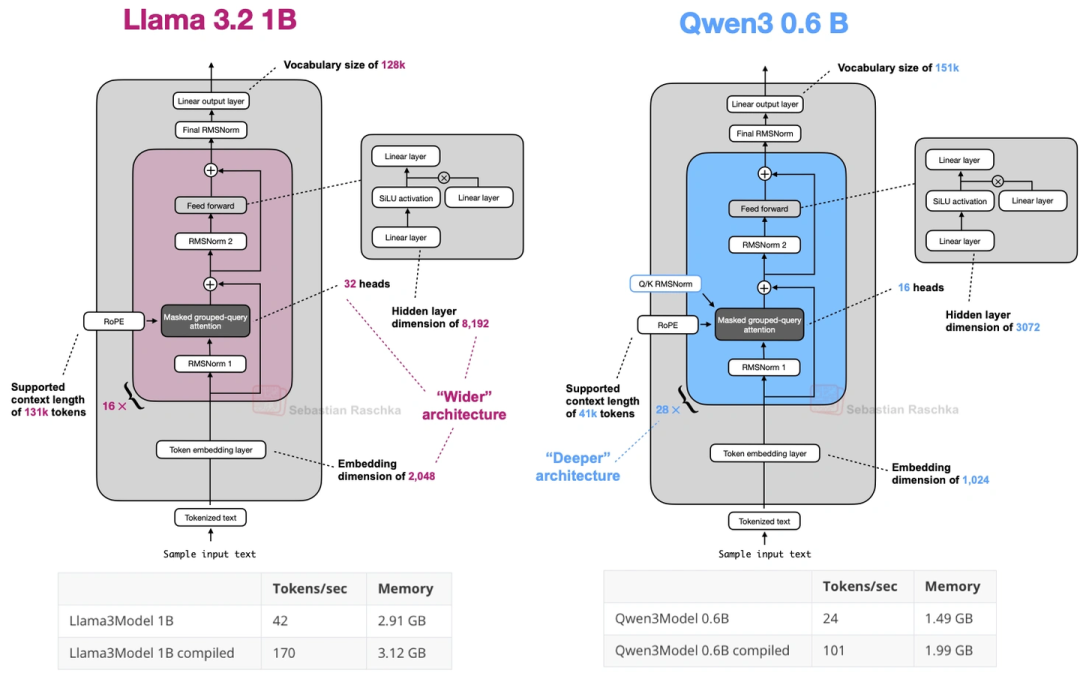
最小的0.6B模型,可能是目前最小的主流开源LLM——比Llama 3 1B还小,但设计上更“深”(Transformer块更多)、更“窄”(注意力头少、隐藏层小)。上图对比了它和Llama 3 1B,能看到Qwen3 0.6B内存占用更低,但生成速度稍慢(因为层多)。我自己试了试,本地训练、推理都很方便,已经把Llama 3 1B换成它了。
MOE版:
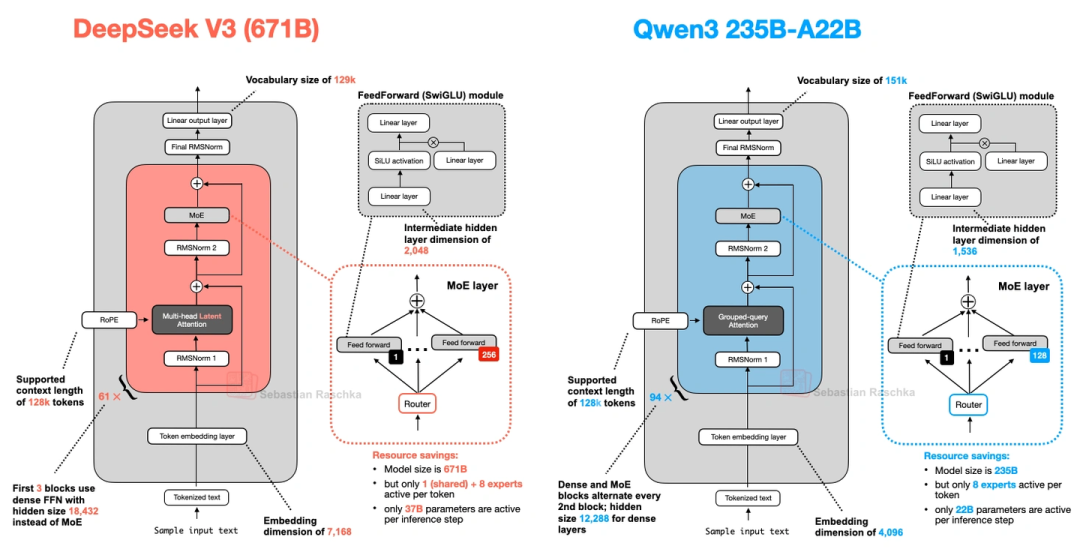
有30B-A3B(30亿总参数,每次激活3.3亿)和235B-A22B(2350亿总参数,每次激活220亿)两种。有意思的是,它没像DeepSeek V3那样加“共享专家”——前代Qwen2.5-MoE是有的。后来问了Qwen3的开发者,说是没发现共享专家有明显提升,还怕影响推理优化,就给去掉了。上图对比了DeepSeek V3和Qwen3 235B-A22B,除了共享专家,两者架构其实很像。
7. SmolLM3(3B参数,小而强)
这模型没那么火,但性能很能打——比同规模的Qwen3 1.7B、Llama 3 3B都好,而且训练细节公开,很良心。最特别的是它用了NoPE(无位置嵌入):
- 一般LLM会用RoPE这种显式的位置信号,但SmolLM3偏不——它完全不加任何位置嵌入,全靠“因果注意力掩码”(每个token只能看前面的token)隐含时序信息。而且它每4层才会省略RoPE,不是所有层都省。
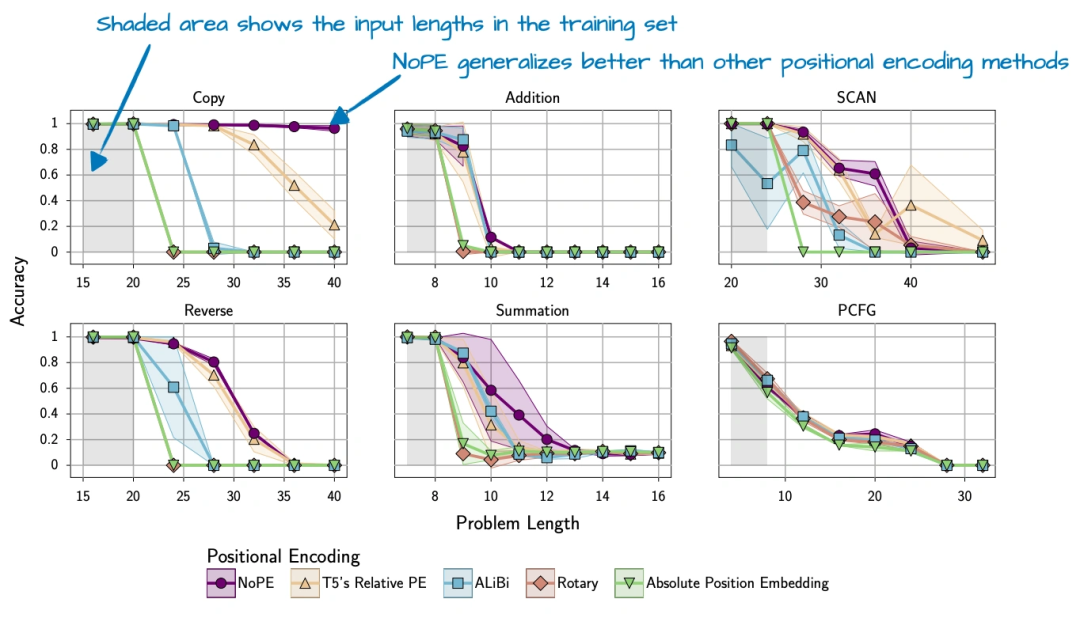
上图是NoPE论文里的图,能看到用NoPE的模型,长序列泛化更好(序列越长,性能掉得越少)。不过要说明的是,NoPE原来只在1亿参数的小模型上测过,SmolLM3把它用到3B模型上,算是个尝试。
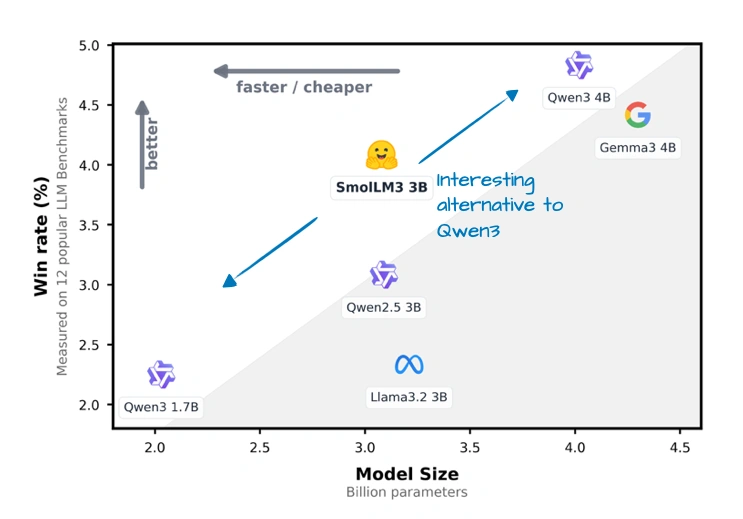
上图对比了SmolLM3和其他同规模模型的“胜率”(就是在测试里赢其他模型的比例),它确实比Qwen3 1.7B、Llama 3 3B这些都高。
8. Kimi K2( moonshot AI的,1万亿参数,开源“巨无霸”)
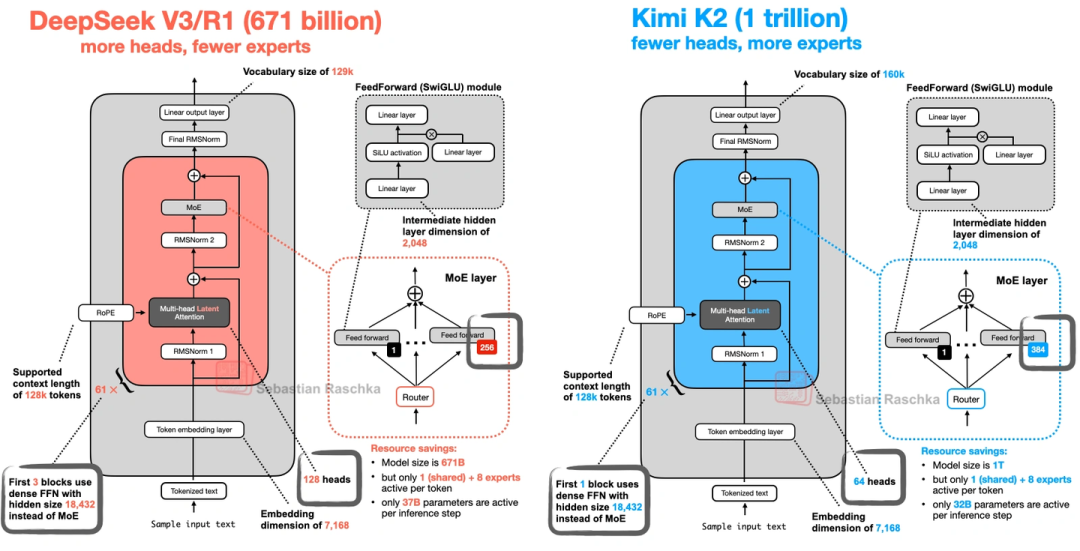
这模型一出来就炸了——1万亿参数,是目前最大的开源LLM(截至2025年中),性能直接对标闭源的Gemini、Claude、ChatGPT。
- 架构其实是在DeepSeek V3基础上改的,主要调了两个地方:MoE专家数量更多了,MLA的头数更少了。
- 它还用了个叫Muon的优化器——之前最多只在16B模型上用过,这是第一次用在这么大的生产模型上。文中对比了它和OLMo 2的训练损失,Kimi K2的损失曲线又平又低,说明训练很稳定,学得也扎实。
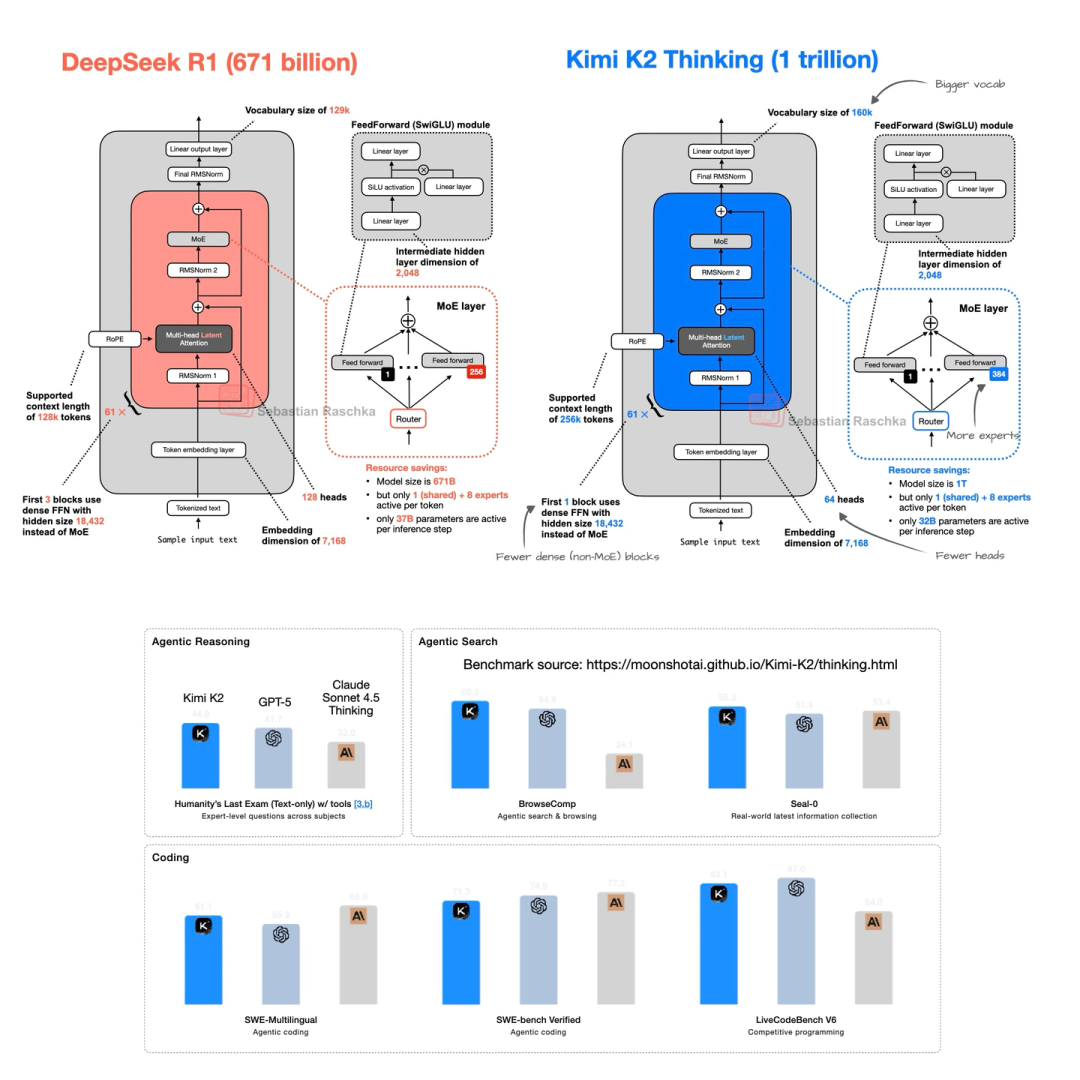
后来还出了Kimi K2 Thinking,架构没变,就是把上下文长度从128k扩到了256k——能处理更长的文本了。上图显示它的基准性能甚至超过了一些闭源LLM,就是没和DeepSeek R1直接比,有点可惜。
9. GPT-OSS(OpenAI的,多年来第一次开源模型)
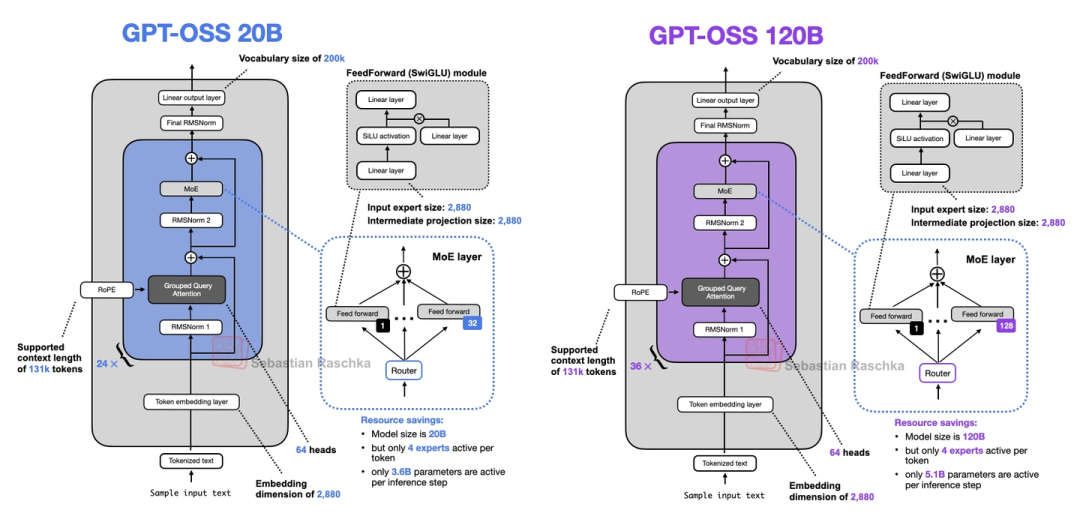
OpenAI自从2019年GPT-2之后,终于又开源了两个模型:20B和120B参数,都是MoE架构。这俩模型有几个有意思的点:
- 宽架构vs深架构:它走的是“宽”路线——嵌入维度2880(Qwen3才2048),专家的中间层维度也更大;而Qwen3是“深”路线(层更多)。宽架构的好处是推理时并行性好,生成速度快,但内存占用会高一点。
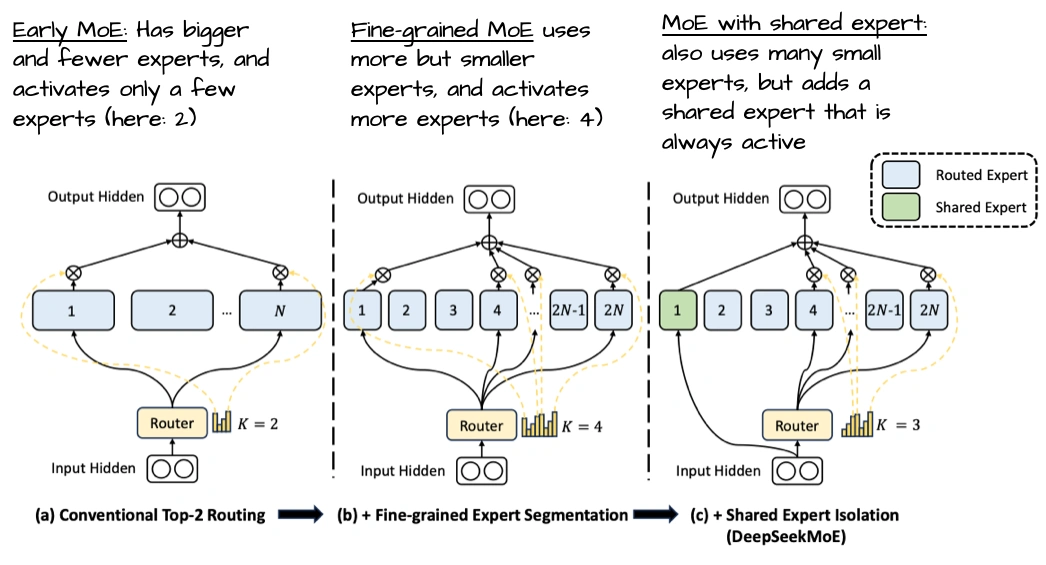
- 少而大的专家:它只有32个专家,每次激活4个——和现在“多小专家”的趋势反着来。上图是DeepSeekMoE论文的图,能看到多小专家其实更优,但OpenAI这么选可能有自己的考量。
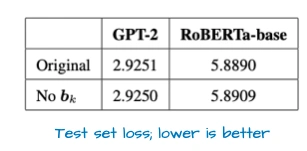
- 细节上还有三个小设计:用了滑动窗口注意力(每间隔1层用);加了GPT-2时代的“注意力偏置”,但上图显示这玩意儿对性能影响不大;搞了“注意力Sink”——不是在输入里加特殊token,而是学一个头级的偏置,稳定长上下文的注意力。
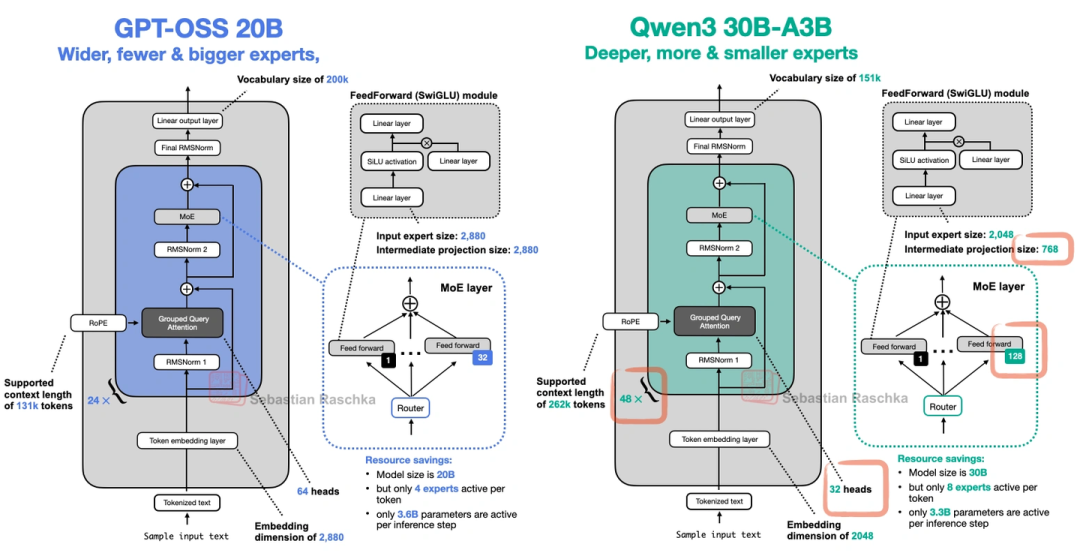
上图对比了它和Qwen3的MoE设计,差异很明显。
10. Grok 2.5(xAI的,生产级模型开源)
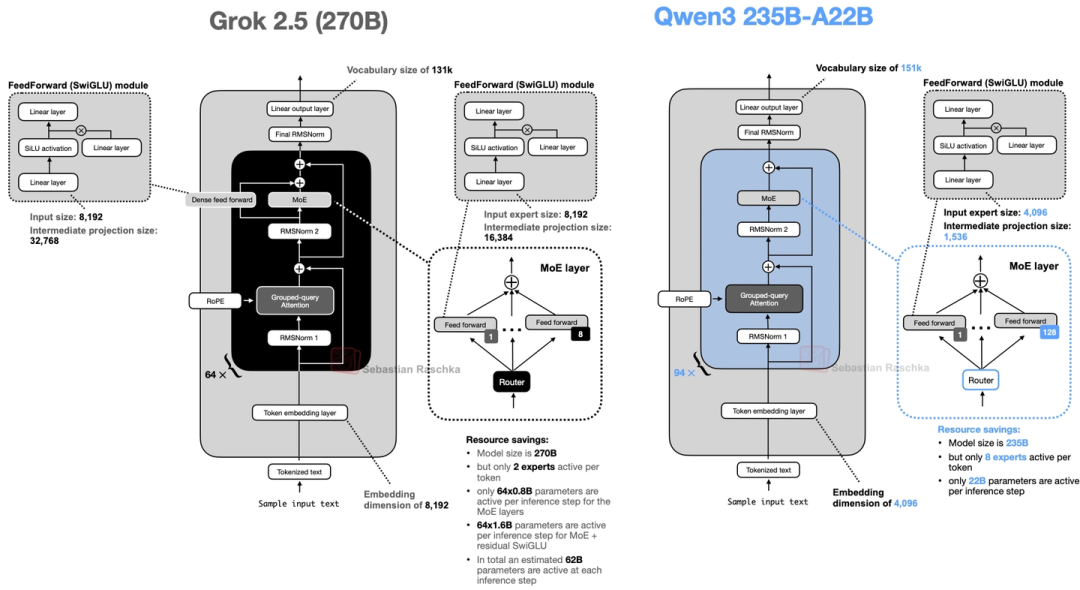
xAI把去年的旗舰生产模型开源了,270B参数,架构不算特别花,但有个细节值得说:
- 它用了8个“大专家”,还加了个“共享专家”——这个共享专家其实是个额外的SwiGLU模块,中间维度翻了倍,和传统的共享专家不太一样,但思路是相通的:让通用模式只学一次,省得每个专家都学一遍。
上图对比了它和Qwen3的架构,能看到共享专家的设计。它整体更贴近早期MoE的思路,说明xAI还是优先保证训练稳定。
11. GLM-4.5(智谱AI的,优化函数调用和智能体)
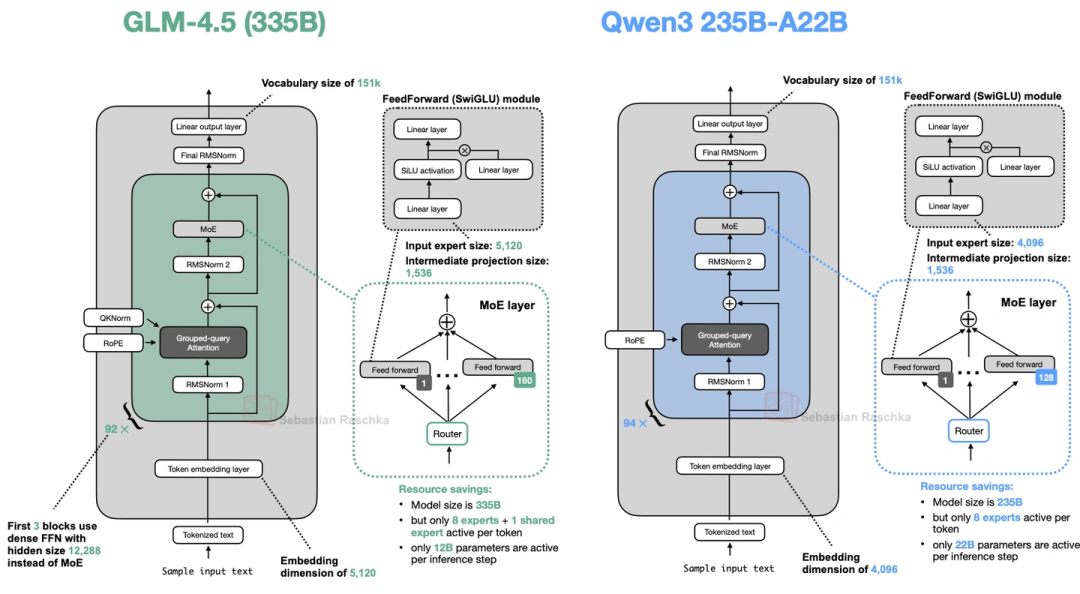
GLM-4.5有两个版本:355B参数的能超过Claude 4 Opus,106B的性能居然快追上355B了,特别适合做智能体、函数调用这些场景。核心亮点是:
- 前3层用稠密层:它不是一上来就用MoE,而是先放3层稠密层——这么做是为了避免早期MoE的“专家选择不稳定”干扰低阶特征(比如语法、基础语义)的学习,让后续MoE训练更稳。
- 加了共享专家(和DeepSeek V3一样),还保留了GPT-2式的注意力偏置。
上图对比了它和Qwen3的架构,前3层的稠密层很显眼。
12. Qwen3-Next(阿里云9月出的,Qwen3的升级版)
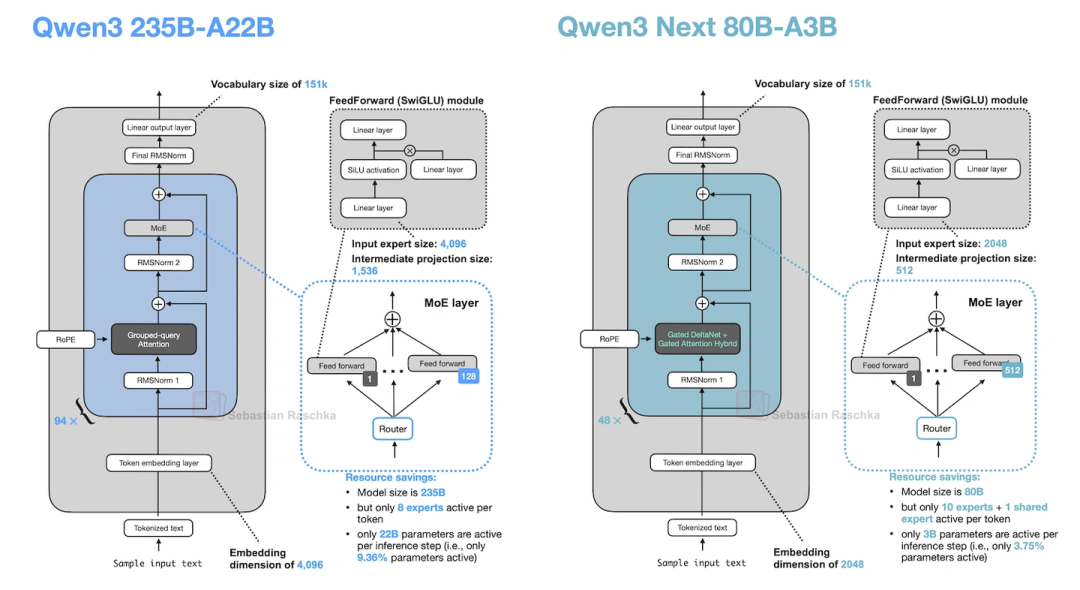
Qwen3-Next是80B-A3B参数,在Qwen3基础上做了三个大升级,专门优化长上下文和效率:
- 专家数量翻4倍+加共享专家:原来Qwen3 MoE版专家少,还没共享专家;这次专家数加了4倍,还加了共享专家,容量和效率都提上去了。
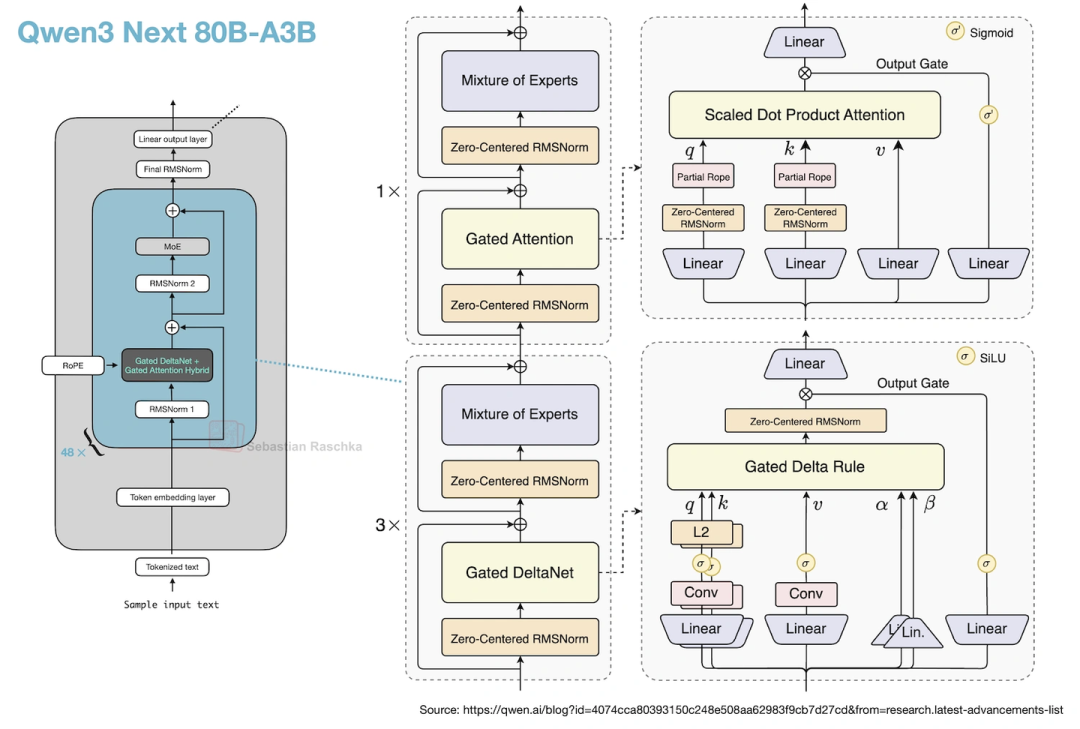
- Gated DeltaNet+Gated Attention混合:3层Gated DeltaNet(线性注意力变体)配1层Gated Attention(优化过的GQA)——图36能看到这个混合机制。这么改是为了支持262k的原生上下文(原来Qwen3 235B只能支持32k,靠YaRN才能扩到131k),线性注意力的复杂度是O(n),不是O(n²),长序列下省太多内存了。
- 多token预测(MTP):训练时让模型一次预测t+1到t+k个token,不是只预测t+1——这样推理时用“投机解码”(先猜几个token再验证)的接受率更高,生成速度也更快。
上图对比了原版Qwen3和Qwen3-Next,专家数量和注意力机制的变化很明显。
13. MiniMax-M2(当前开源基准榜首,放弃线性注意力)
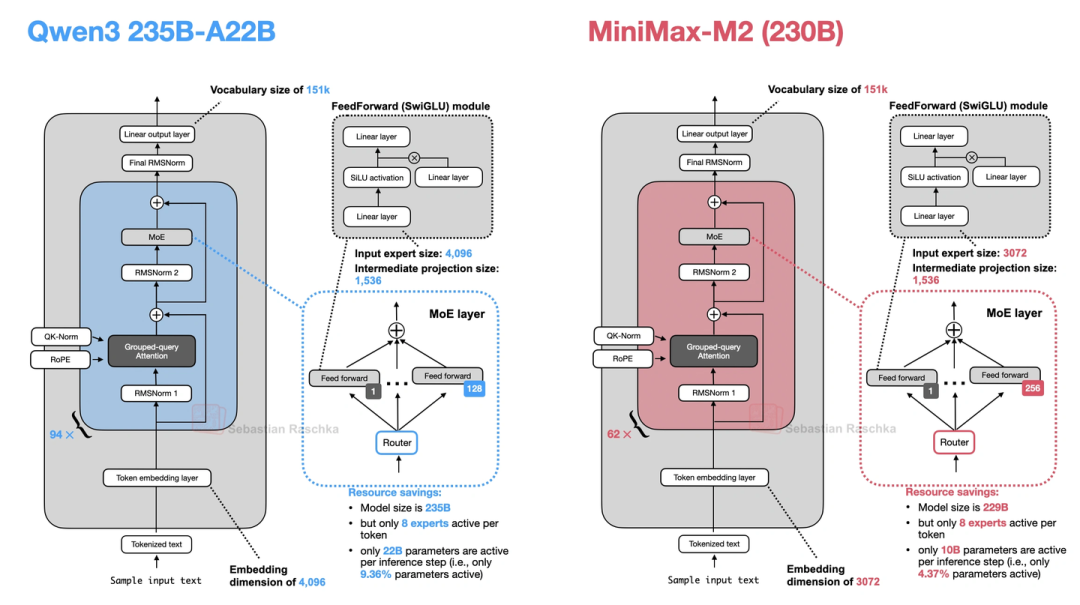
MiniMax-M2现在是开源模型里跑分最高的,230B参数,它最有意思的是“走回头路”——前代MiniMax-M1用了线性注意力(Lightning Attention),到M2又换回全注意力了,说是线性注意力在推理、多轮对话里表现不好。它的核心设计有三个:
- Per-Layer QK-Norm:之前的QK-Norm是所有注意力头共享一层RMSNorm,M2改成每个头单独用一层——相当于每个头有自己的“归一化规则”,能更好地捕捉不同头的特异性。
- MoE更稀疏:230B总参数,每次只激活10亿——比Qwen3 235B的22亿还少,推理更省资源。
- 部分RoPE:只给注意力头的一半维度加RoPE,另一半不加——怕长序列下RoPE旋转太“极端”,模型没见过,反而掉性能。
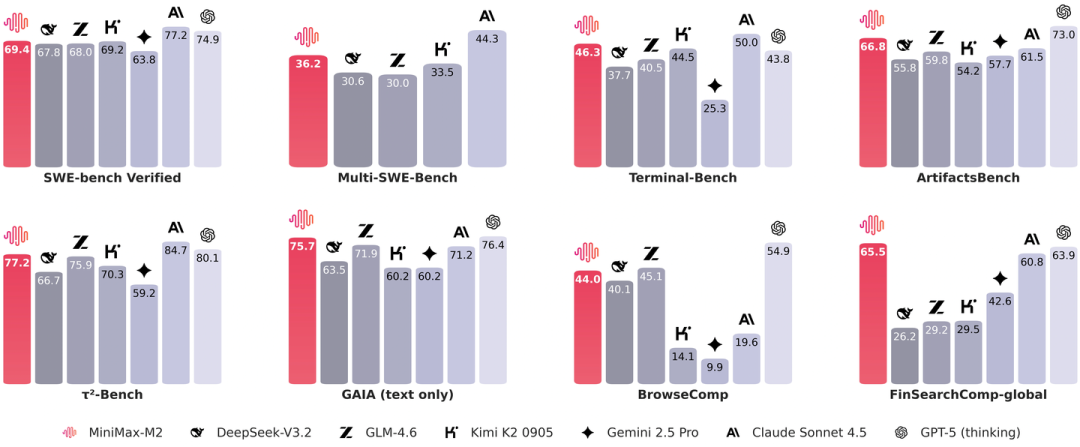
上图是它的基准性能图,比其他开源模型都高;前面对比了它和Qwen3的架构,Per-Layer QK-Norm和稀疏MoE很突出。
14. Kimi Linear(10月出的,线性注意力又活了)
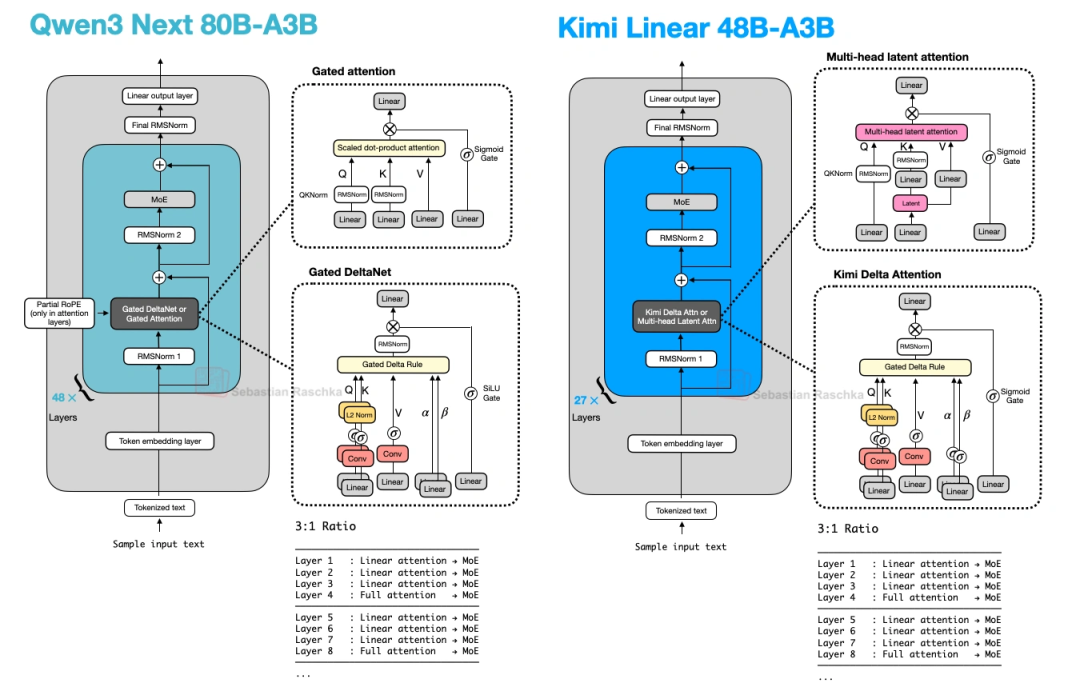
MiniMax-M2刚放弃线性注意力,Kimi就出了Kimi Linear,48B参数,把线性注意力又捡起来了,还做了改进:
- 3:1混合注意力:3层Gated DeltaNet(线性注意力)配1层MLA(多头潜在注意力,替代全注意力)——和Qwen3-Next的比例一样,但用MLA比Qwen3-Next的Gated Attention更省内存。
- KDA(Kimi Delta Attention):Qwen3-Next的Gated DeltaNet用的是“标量门控”(一个值控制一个头),Kimi Linear改成“通道级门控”(每个特征维度都有自己的门控)——对内存的控制更精细,长上下文推理更好。
- NoPE:在MLA层完全不加位置嵌入,避免长序列下RoPE需要重新调参的麻烦。
上图显示,它的生成速度和Gated DeltaNet差不多,但性能比DeepSeek V3这种MLA架构还好——算是给线性注意力正名了。不过它只有48B参数,比Kimi K2小20倍,后续能不能用到更大模型上,还得看。
3、2024-2025年LLM架构的关键趋势
- MoE成了大模型的“标配”:只要参数过千亿,基本都用MoE——核心就是“总参数搞大(保证知识面),活跃参数搞小(省推理资源)”。不过共享专家的设计有分歧,有的加(DeepSeek V3、GLM-4.5),有的不加(Qwen3、MiniMax-M2)。
- 注意力机制一直在“降成本”:从MHA到GQA是省参数,到MLA是省KV缓存,到滑动窗口是省局部计算,再到线性注意力(DeltaNet、KDA)是把复杂度从O(n²)降到O(n)——全是为了在长序列下还能跑得动。
- 归一化层越玩越细:RMSNorm已经完全替代LayerNorm了,位置也从“只在前面”或“只在后面”,变成“前后都加”(Gemma 3)、“后面但在残差里”(OLMo 2);QK-Norm也成了注意力模块的“必选项”,甚至还出了Per-Layer QK-Norm(MiniMax-M2)。
- 位置嵌入开始“做减法”:RoPE还是主流,但NoPE(SmolLM3)、部分RoPE(MiniMax-M2)这些“少加甚至不加位置信号”的设计开始冒头——目的都是让模型在长序列下泛化更好,不用每次都重新调RoPE。
- 场景化优化越来越明确:专门给手机做的(Gemma 3n)、专门搞长上下文的(Kimi K2 Thinking、Qwen3-Next)、专门做智能体的(GLM-4.5)——不再追求“一个模型包打天下”,而是针对具体场景优化。
总的来说,现在的LLM架构没什么“颠覆性突破”,但全是“精准优化”——怎么更省内存、更快推理、更稳训练、更适配场景,这些才是开发者最关心的。后续就看线性注意力能不能用到更大模型上,以及MoE的共享专家设计会不会有更优解了。
4、如何从零学会大模型?小白&程序员都能跟上的入门到进阶指南
当AI开始重构各行各业,你或许听过“岗位会被取代”的焦虑,但更关键的真相是:技术迭代中,“效率差”才是竞争力的核心——新岗位的生产效率远高于被替代岗位,整个社会的机会其实在增加。
但对个人而言,只有一句话算数:
“先掌握大模型的人,永远比后掌握的人,多一次职业跃迁的机会。”
回顾计算机、互联网、移动互联网的浪潮,每一次技术革命的初期,率先拥抱新技术的人,都提前拿到了“职场快车道”的门票。我在一线科技企业深耕12年,见过太多这样的案例:3年前主动学大模型的同事,如今要么成为团队技术负责人,要么薪资翻了2-3倍。
深知大模型学习中,“没人带、没方向、缺资源”是最大的拦路虎,我们联合行业专家整理出这套 《AI大模型突围资料包》,不管你是零基础小白,还是想转型的程序员,都能靠它少走90%的弯路:
- ✅ 小白友好的「从零到一学习路径图」(避开晦涩理论,先学能用的技能)
- ✅ 程序员必备的「大模型调优实战手册」(附医疗/金融大厂真实项目案例)
- ✅ 百度/阿里专家闭门录播课(拆解一线企业如何落地大模型)
- ✅ 2025最新大模型行业报告(看清各行业机会,避免盲目跟风)
- ✅ 大厂大模型面试真题(含答案解析,针对性准备offer)
- ✅ 2025大模型岗位需求图谱(明确不同岗位需要掌握的技能点)
所有资料已整理成包,想领《AI大模型入门+进阶学习资源包》的朋友,直接扫下方二维码获取~

① 全套AI大模型应用开发视频教程:从“听懂”到“会用”
不用啃复杂公式,直接学能落地的技术——不管你是想做AI应用,还是调优模型,这套视频都能覆盖:
- 小白入门:提示工程(让AI精准输出你要的结果)、RAG检索增强(解决AI“失忆”问题)
- 程序员进阶:LangChain框架实战(快速搭建AI应用)、Agent智能体开发(让AI自主完成复杂任务)
- 工程落地:模型微调与部署(把模型用到实际业务中)、DeepSeek模型实战(热门开源模型实操)
每个技术点都配“案例+代码演示”,跟着做就能上手!

课程精彩瞬间

② 大模型系统化学习路线:避免“学了就忘、越学越乱”
很多人学大模型走弯路,不是因为不努力,而是方向错了——比如小白一上来就啃深度学习理论,程序员跳过基础直接学微调,最后都卡在“用不起来”。
我们整理的这份「学习路线图」,按“基础→进阶→实战”分3个阶段,每个阶段都明确:
- 该学什么(比如基础阶段先学“AI基础概念+工具使用”)
- 不用学什么(比如小白初期不用深入研究Transformer底层数学原理)
- 学多久、用什么资料(精准匹配学习时间,避免拖延)
跟着路线走,零基础3个月能入门,有基础1个月能上手做项目!

③ 大模型学习书籍&文档:打好理论基础,走得更稳
想长期在大模型领域发展,理论基础不能少——但不用盲目买一堆书,我们精选了「小白能看懂、程序员能查漏」的核心资料:
- 入门书籍:《大模型实战指南》《AI提示工程入门》(用通俗语言讲清核心概念)
- 进阶文档:大模型调优技术白皮书、LangChain官方中文教程(附重点标注,节省阅读时间)
- 权威资料:斯坦福CS224N大模型课程笔记(整理成中文,避免语言障碍)
所有资料都是电子版,手机、电脑随时看,还能直接搜索重点!

④ AI大模型最新行业报告:看清机会,再动手
学技术的核心是“用对地方”——2025年哪些行业需要大模型人才?哪些应用场景最有前景?这份报告帮你理清:
- 行业趋势:医疗(AI辅助诊断)、金融(智能风控)、教育(个性化学习)等10大行业的大模型落地案例
- 岗位需求:大模型开发工程师、AI产品经理、提示工程师的职责差异与技能要求
- 风险提示:哪些领域目前落地难度大,避免浪费时间
不管你是想转行,还是想在现有岗位加技能,这份报告都能帮你精准定位!
⑤ 大模型大厂面试真题:针对性准备,拿offer更稳
学会技术后,如何把技能“变现”成offer?这份真题帮你避开面试坑:
- 基础题:“大模型的上下文窗口是什么?”“RAG的核心原理是什么?”(附标准答案框架)
- 实操题:“如何优化大模型的推理速度?”“用LangChain搭建一个多轮对话系统的步骤?”(含代码示例)
- 场景题:“如果大模型输出错误信息,该怎么解决?”(教你从技术+业务角度回答)
覆盖百度、阿里、腾讯、字节等大厂的最新面试题,帮你提前准备,面试时不慌!

以上资料如何领取?
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么现在必须学大模型?不是焦虑,是事实
最近英特尔、微软等企业宣布裁员,但大模型相关岗位却在疯狂扩招:
- 大厂招聘:百度、阿里的大模型开发岗,3-5年经验薪资能到50K×20薪,比传统开发岗高40%;
- 中小公司:甚至很多传统企业(比如制造业、医疗公司)都在招“会用大模型的人”,要求不高但薪资可观;
- 门槛变化:不出1年,“有大模型项目经验”会成为很多技术岗、产品岗的简历门槛,现在学就是抢占先机。
风口不会等任何人——与其担心“被淘汰”,不如主动学技术,把“焦虑”变成“竞争力”!

最后:全套资料再领一次,别错过这次机会
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献338条内容
已为社区贡献338条内容

所有评论(0)