大模型写 SQL 总翻车?只因漏了这一步!Context-Aware 双向检索拯救 Schema Linking
摘要:最新研究聚焦Text-to-SQL中的关键环节SchemaLinking,提出双向检索框架显著提升性能。传统方法面临全量Schema干扰或完美Schema依赖的两难,该研究通过"表优先+列优先"双路径协同检索,在BIRD数据集上将全量与完美Schema性能差距缩小50%。相比现有方案,该方法以仅6次LLM调用实现85%-93%召回率,误判率降低至19%-34%,推理延迟仅
家人们谁懂啊!现在用大模型做 Text-to-SQL,明明 prompt 写得超详细,结果生成的 SQL 要么执行报错,要么查出来一堆垃圾数据 —— 别骂模型菜,大概率是你没搞定 “Schema Linking” 这关键一环!
今天要唠的这篇顶会论文,直接把 Schema Linking 从 “边角料步骤” 抬成 “核心 C 位”,还搞出个双向检索框架,在 BIRD 和 Spider 两大硬核数据集上把全量 Schema 的性能差距缩小了 50%!咱先搞懂为啥 Schema Linking 这么重要:你让模型写 SQL 时,给全量数据库 Schema 吧,无关表和列会塞爆上下文,模型很容易 “ hallucination”(瞎编字段);给完美 Schema(只含必需元素)吧,又得先知道答案才能选,简直是 “先有鸡还是先有蛋”。之前那些方法要么靠多轮 LLM 调用堆性能(比如 CHESS 要 78 次调用,费钱又慢),要么只顾召回率不管误判(比如 RSL-SQL 召回 93% 但误判率 68%,等于白忙活)。

《ChatBI核心技术》是刚上市的新书,本书旨在为读者提供一个全面的ChatBI学习框架。从基础概念到核心技术,再到实际应用场景,书中详细介绍了ChatBI的定义、特点、与传统BI的区别,以及其在企业决策支持、数据分析民主化、即时数据洞察等多场景中的应用。书中还深入探讨了提示工程、AI智能体、检索增强生成、大模型微调等关键技术,并通过实战案例展示了如何构建AI智能体和业务知识库,以及实现数据智能查询与可视化等功能。此外,书中还讨论了对话理解、智能分析、用户交互等重要环节,帮助读者全面掌握ChatBI的技术实现和应用思路。
这篇论文的骚操作,是把 Schema Linking 拆成 “先找表再挑列” 和 “先找列再定表” 两条路,还加了问题拆解、关键词提取这些 buff,最后把两条路的结果合并 —— 相当于让两个专家分别审题,再汇总答案,既保证不漏关键信息,又能少踩坑。
先看 Text-to-SQL 的基本流程,左边是常规 pipeline:先把问题和 Schema 关联,再生成 SQL,最后可能还要纠错。但右边这张图才是重点 —— 用全量 Schema(FULL)和完美 Schema(PERFECT)的性能差能有一大截,而 Schema Linking 的目标,就是把检索到的 Schema 往 “完美” 上靠,直接拉满 SQL 生成的准确率。
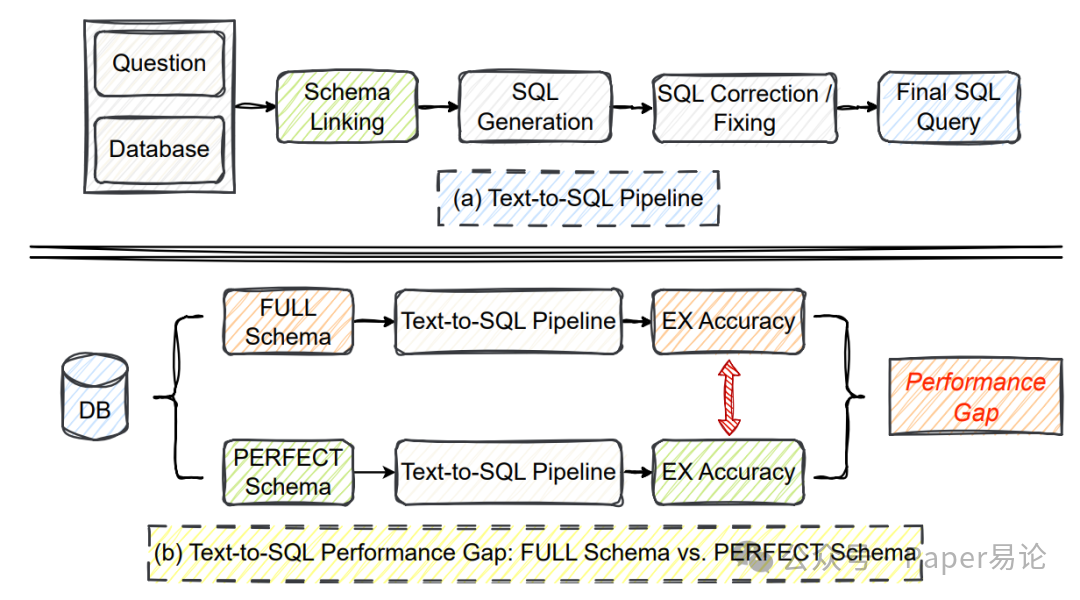
图 1:Text-to-SQL 流程及全量与完美 Schema 性能差距
那具体咋实现的?第一步先做 “问题增强”(Question Augmentation),比如用户问 “总胆固醇超标的患者里,有多少凝血程度检测为阴性?”,模型会先把问题拆成小问题:“正常胆固醇范围是多少?”“哪些患者超标?”“他们的凝血检测结果是啥?”,再提取 “总胆固醇”“凝血程度”“T-CHO”“KCT” 这些关键词 —— 相当于给模型划重点,避免它抓错核心。
《ChatBI核心技术》是刚上市的新书,本书旨在为读者提供一个全面的ChatBI学习框架。从基础概念到核心技术,再到实际应用场景,书中详细介绍了ChatBI的定义、特点、与传统BI的区别,以及其在企业决策支持、数据分析民主化、即时数据洞察等多场景中的应用。书中还深入探讨了提示工程、AI智能体、检索增强生成、大模型微调等关键技术,并通过实战案例展示了如何构建AI智能体和业务知识库,以及实现数据智能查询与可视化等功能。此外,书中还讨论了对话理解、智能分析、用户交互等重要环节,帮助读者全面掌握ChatBI的技术实现和应用思路。
接着是核心的 “双向 Schema Linking”,两条路并行走。先看 “表优先检索”(Table-First):比如问 “ bond id TR001_1_8 有没有氯和碳元素”,模型先根据 “bond”“element” 定位到 Atom、Bond、Connected 这三张表,再从里面挑出 bond_id、atom_id、element 这些列。而 “列优先检索”(Column-First)则反过来,先找 “element”“bond_id” 这些列,再对应到所属的表。最后把两条路的结果合并,像这个例子里,表优先和列优先分别覆盖了不同的表和列,合并后就和完美 Schema 几乎一致了。
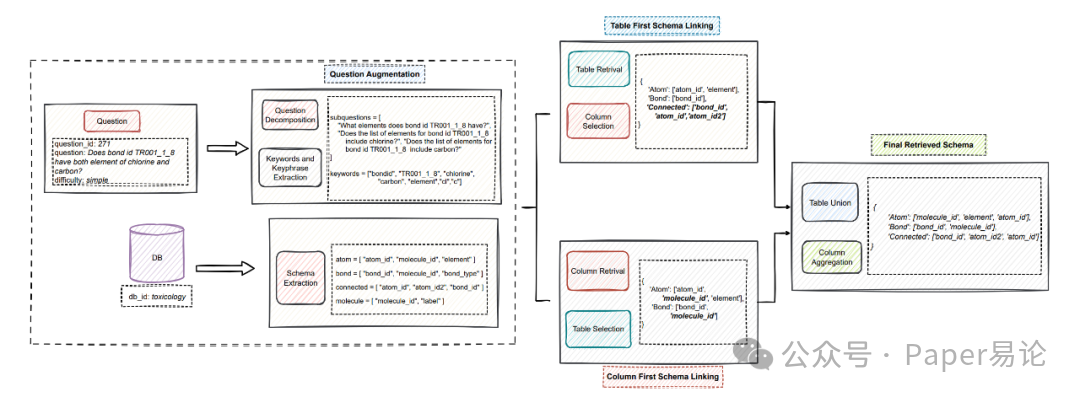
图 2:双向 Schema Linking 流程示例
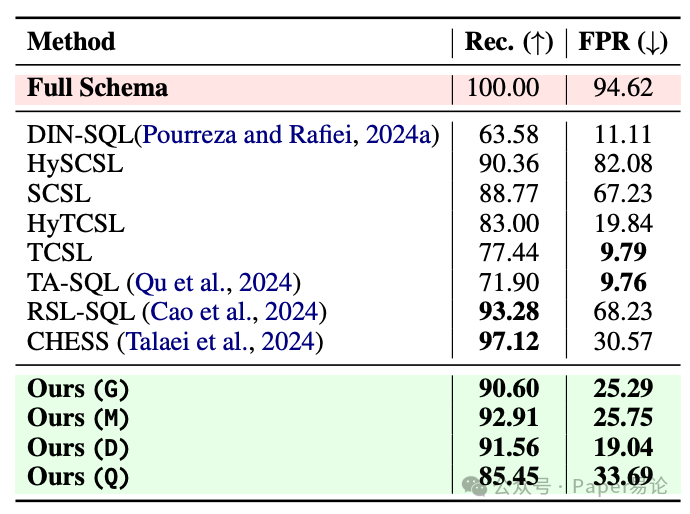
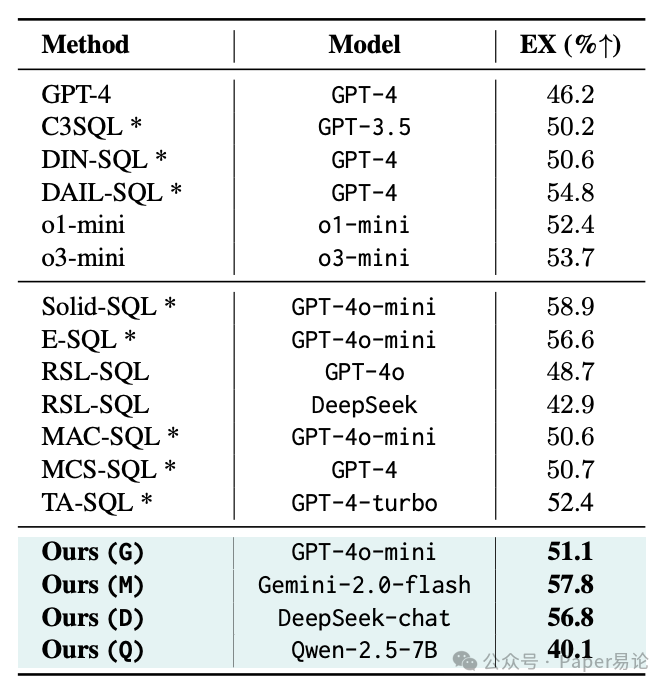
光说不练假把式,看数据说话!在 BIRD 数据集的 Schema Linking 性能表上,咱能清晰看到:CHESS 虽然召回率最高(97.12%),但误判率(FPR)也飙到 30.57%,还得 78 次 LLM 调用;RSL-SQL 召回 93.28%,误判率直接 68.23%,等于一半多列都是瞎选的。而这篇论文的方法(Ours)不管用 GPT-4o-mini、Gemini 还是 DeepSeek,召回率都稳定在 85%-93%,误判率却压到 19%-34%,妥妥的 “又准又稳”。
表 1:BIRD 开发集上的 Schema Linking 性能(G=GPT-4o-mini,M=Gemini-2.0-flash,D=DeepSeek,Q=Qwen-2.5-7B-Instruct)
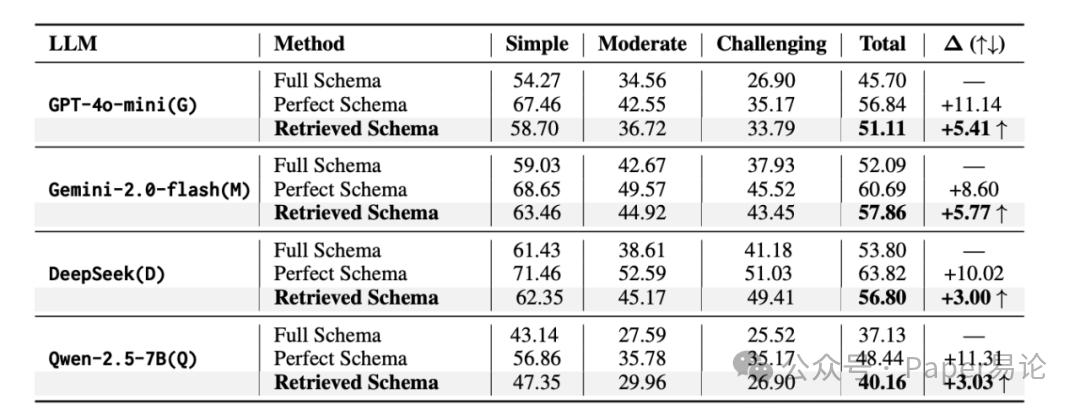
再看对 SQL 生成的实际影响。在 BIRD 数据集按 SQL 难度分的表格里,不管是简单、中等还是复杂查询,用这篇论文的 “检索到的 Schema”(Retrieved Schema)都比全量 Schema(Full Schema)表现好。比如用 Gemini-2.0-flash 时,全量 Schema 总执行准确率 52.09%,用检索到的 Schema 直接涨到 57.86%,和完美 Schema(60.69%)就差一点点,关键是没搞任何 SQL 纠错 —— 要知道很多方法都是靠后处理才提分的,这波属于 “从源头解决问题”。
表 2:BIRD 开发集上不同 SQL 难度的零样本执行准确率
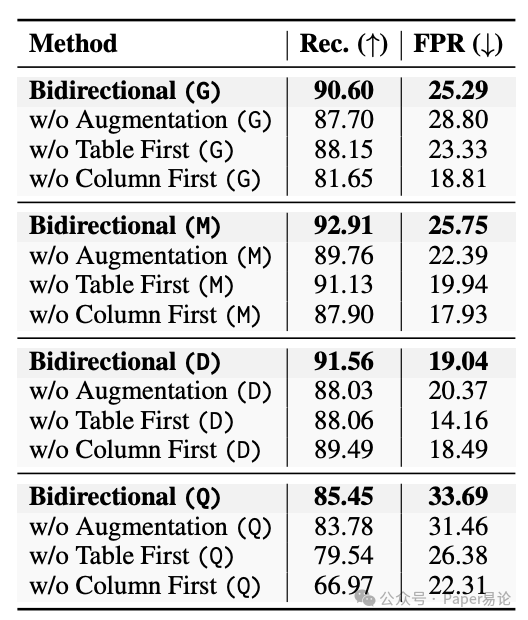
有人可能会问:少了表优先或列优先其中一条路行不行? ablation study(消融实验)给出了答案。比如用 GPT-4o-mini 时,去掉列优先步骤,召回率从 90.60% 掉到 81.65%,虽然误判率也降了点,但漏了关键列反而会让 SQL 生成翻车;去掉表优先步骤,召回率也会小幅度下降。这说明两条路缺一不可,表优先负责 “抓大方向”(定位核心表),列优先负责 “抠细节”(精准找列),合并后才能实现 1+1>2 的效果。
表 3:不同 Schema Linking 策略的消融实验结果(SLR=Schema Linking Recall,FPR = 误判率)
除了准,这方法还很 “轻量”。看推理成本对比表,CHESS 要 78 次 LLM 调用,每次处理 339k tokens, latency(延迟)快 47 秒;而这篇论文的方法只要 6 次调用,10.5k tokens,延迟 2.6 秒 —— 不管是小公司落地还是个人开发者用,都不会有太大成本压力。
表 4:BIRD 数据集上的推理成本对比(LLM 调用次数、tokens 数、延迟)
当然,这方法也不是完美的。比如遇到表名相似、列名模糊的数据库(比如多个表都有 “id” 列),还是可能选错;而且依赖 LLM 的稳定性,偶尔会出现 “同个问题两次检索结果不一样” 的情况。但瑕不掩瑜,它把 Schema Linking 从 “依附于 SQL 生成的步骤” 变成了 “可独立部署的模块”—— 不管你用 DIN-SQL 还是 MCS-SQL,把原来的 Schema Linking 换成这个双向检索框架,都能提分。比如给 DIN-SQL 用,执行准确率从 50.6% 涨到 55.4%;给 MCS-SQL 用,从 52.8% 涨到 54.7%,妥妥的 “通用外挂”。
最后再放个实际案例感受下:比如问 “数据库里有多少被认定为致癌的化合物?”,完美 Schema 是 molecule 表的 molecule_id 和 label 列。表优先检索只挑了 label 列,漏了 molecule_id;但列优先检索同时找到了这两列,合并后就和完美 Schema 一致,生成的 SQL 也能准确统计数量。要是只靠表优先,最后 SQL 里没 molecule_id 可能还得关联其他表,大概率会出错 —— 这就是双向检索的价值,总能补全对方漏的关键信息。
这篇论文最牛的不是搞了多复杂的模型,而是把 “Schema Linking” 的重要性说透了:之前大家都在卷 SQL 生成的后处理,却忽略了 “选对 Schema” 才是第一步。现在用这个双向检索框架,既能少花钱少费时间,又能让 SQL 生成准确率上一个台阶,不管是做企业级数据查询接口,还是个人用大模型处理数据,都值得试试!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)