使用 Elasticsearch 和 SigLIP-2 进行多模态山峰搜索
本文介绍了一个基于SigLIP-2嵌入和Elasticsearch kNN向量搜索的多模态混合搜索系统,支持文本到图像和图像到图像的搜索功能。系统采用两个Elasticsearch索引:peaks_catalog存储山峰原型向量,photos存储照片元数据和向量。通过Streamlit UI,用户可以进行文本查询搜索相关照片,或上传图片识别山峰并查找相似照片。项目展示了如何将多语言视觉编码器与El
作者:来自 Elastic Navneet Kumar

学习如何使用 SigLIP-2 嵌入和 Elasticsearch kNN 向量搜索来实现文本到图像和图像到图像的多模态搜索。项目重点:从珠峰徒步中找到阿玛达布朗峰的照片。
从向量搜索到强大的 REST API,Elasticsearch 为开发者提供了最全面的搜索工具包。前往 GitHub 上的示例笔记本深入探索,尝试一些新东西。你还可以立即开始免费试用或在本地运行 Elasticsearch。
你是否曾想根据含义搜索你的相册?试试这样的查询:“显示我穿着蓝色夹克坐在长椅上的照片”、“显示珠穆朗玛峰的照片” 或 “清酒和寿司”。拿上一杯咖啡(或你喜欢的饮料)继续阅读。在这篇博客中,我们将展示如何构建一个多模态混合搜索应用程序。多模态意味着该应用可以理解并跨不同类型的输入 —— 文本、图像和音频——进行搜索,而不仅仅是文字。混合则意味着它结合了关键字匹配、kNN 向量搜索和地理围栏等技术,以提供更精准的结果。
为实现这一点,我们使用 Google 的 SigLIP-2 为图像和文本生成向量嵌入,并将它们存储在 Elasticsearch 向量数据库中。在查询时,我们将搜索输入(文本或图像)转换为嵌入,并运行快速的 kNN 向量搜索以检索结果。此设置实现了高效的文本到图像和图像到图像搜索。Streamlit 界面让这个项目生动起来,它不仅提供了一个前端来进行基于文本的搜索,从相册中查找和查看匹配的照片,还可以识别上传图像中的山峰,并查看相册中该山峰的其他照片。
我们还介绍了为提高搜索准确性所采取的步骤,以及一些实用技巧。若要进一步探索,我们提供了一个 GitHub 仓库和一个 Colab 笔记本。
事情的起因
这篇博客的灵感来自一个 10 岁的孩子,他让我给他看我珠峰大本营徒步旅行中所有的阿玛达布朗峰照片。我们一起翻看相册时,他还让我辨认其他一些山峰,但有些我也叫不出名字。
这让我想到,这可以是一个有趣的计算机视觉项目。我们的目标是:
-
通过山峰名字找到相关的照片
-
通过图片猜出山峰名字,并在相册中找到相似的山峰
-
支持概念查询(人物、河流、经幡等)

组建梦之队: SigLIP-2、 Elasticsearch 和 Streamlit
很快我们就意识到,要让这一切实现,我们需要把文本(如 “Ama Dablam”)和图片(相册中的照片)都转换成可以有意义比较的向量,也就是放到同一个向量空间中。做到这一点后,搜索就变成了 “寻找最近邻”。

为了生成图像向量,我们使用了一个多语言视觉—语言编码器,这样山峰的照片和像 “Ama Dablam” 这样的短语就能落在同一个向量空间中。
谷歌最近发布的 SigLIP-2 在这里非常合适。它可以在无需特定任务训练的情况下(零样本模式)生成向量,非常适用于我们的场景:没有标签的照片和不同语言、不同名字的山峰。由于它专为文本 ↔ 图像匹配而训练,徒步途中拍摄的山峰照片与一个简短的文本提示在向量空间中会靠得很近,即使查询语言或拼写不同也能很好匹配。
SigLIP-2 在质量与速度之间取得了良好平衡,支持多种输入分辨率,并可运行在 CPU 和 GPU 上。与之前的型号(例如初代 CLIP)相比,SigLIP-2 的设计使其在处理户外照片时更加稳健。在我们的测试中, SigLIP-2 始终生成可靠的结果。它还拥有良好的支持,因此成为本项目的理想选择。
接下来,我们需要一个向量数据库来存储这些向量并支持搜索。它不仅要支持对图像向量进行余弦 kNN 搜索,还要能在同一个查询中结合地理范围和文本过滤。 Elasticsearch 非常适合这一点:它在处理向量( dense_vector 字段上的 HNSW kNN)方面表现出色,支持将文本、向量和地理查询结合的混合搜索,并自带过滤与排序功能。它还能水平扩展,从少量照片轻松扩展到成千上万张。官方的 Elasticsearch Python 客户端让集成变得简单,并与项目无缝衔接。
最后,我们需要一个轻量级前端来输入搜索查询并查看结果。对于快速、基于 Python 的演示, Streamlit 是很好的选择。它提供了所需的基本组件 —— 文件上传、响应式图片网格、排序和地理范围的下拉菜单。它容易克隆并在本地运行,也能在 Colab 笔记本中使用。
实现
Elasticsearch 索引设计与索引策略
在这个项目中,我们将使用两个索引: peaks_catalog 和 photos。
peaks_catalog 索引
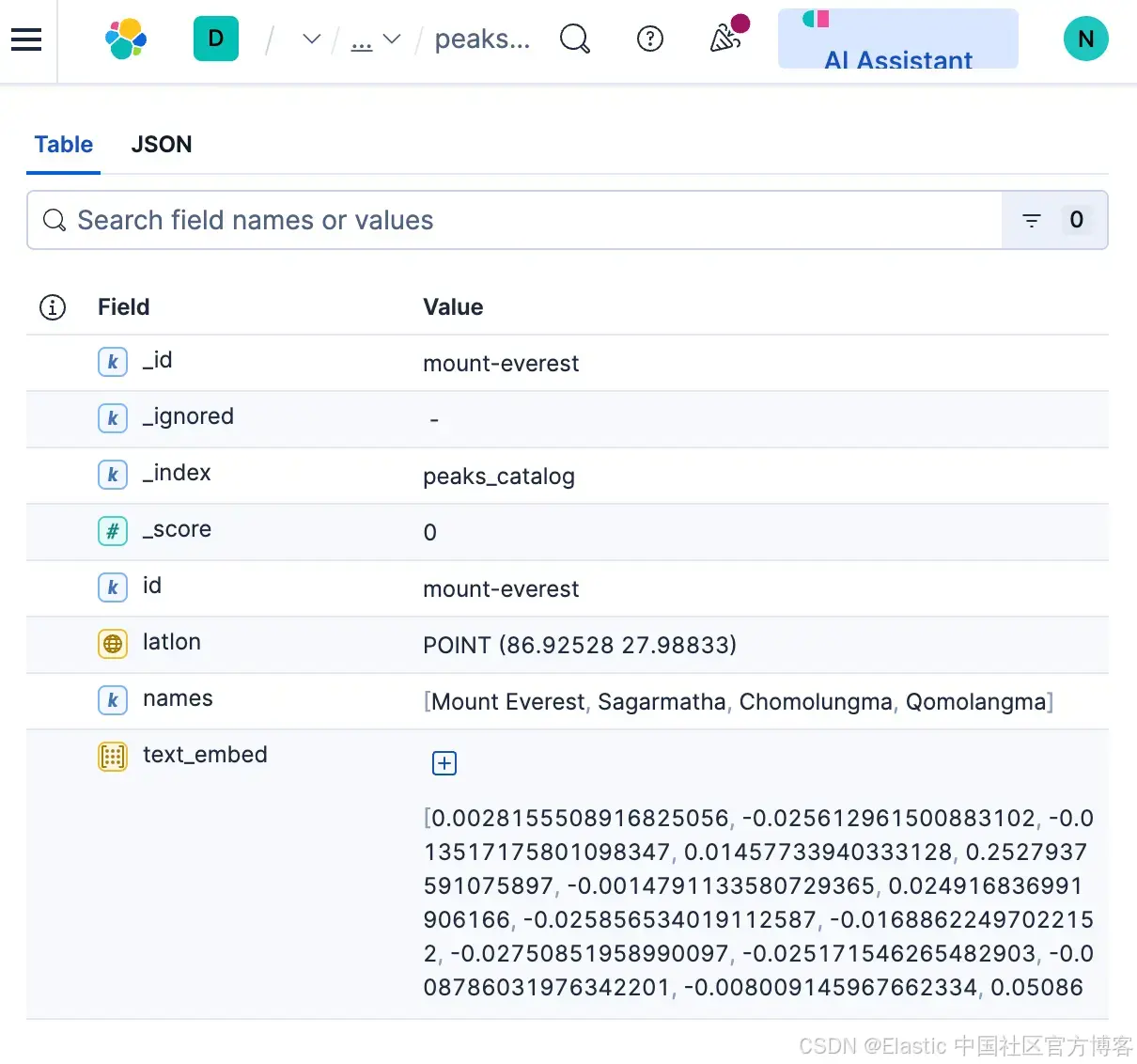
这个索引是珠峰大本营徒步路线中主要可见山峰的精简目录。索引中的每个文档对应一座山峰,如珠穆朗玛峰。对于每个山峰文档,我们会存储名称/别名、可选的经纬度坐标,以及一个原型向量(由 SigLIP-2 文本提示 + 可选的参考图像混合生成)。
索引映射:
| 字段 | 类型 | 示例 | 用途/说明 | 向量/索引 |
|---|---|---|---|---|
| id | keyword | ama-dablam | 稳定的标识符或短标签 | — |
| names | text + keyword 子字段 | ["Ama Dablam", "Amadablam"] | 别名 / 多语言名称;names.raw 用于精确过滤 |
— |
| latlon | geo_point | {"lat":27.8617,"lon":86.8614} | 山峰的 GPS 坐标(可选) | — |
| elev_m | integer | 6812 | 海拔高度(可选) | — |
| text_embed | dense_vector | 768 | 此山峰的混合原型向量(由文本提示 + 可选 1–3 张参考图像生成) | index:true, similarity:"cosine", index_options:{type:"hnsw", m:16, ef_construction:128} |
该索引主要用于图像到图像的搜索,例如通过照片识别山峰。我们也使用它来增强文本到图像的搜索结果。
总的来说,peaks_catalog 将 “这是什么山峰?” 的问题转化为一个专注的最近邻搜索问题,有效地将概念理解与图像数据的复杂性分离开来。
peaks_catalog 索引的索引策略:
为了生成稳健的向量,我们使用以下方法:
-
创建文本原型:
-
使用山峰名称
-
使用提示集合(多种不同提示尝试回答同一个问题),例如:
-
“a natural photo of the mountain peak {name} in the Himalayas, Nepal”
-
“{name} landmark peak in the Khumbu region, alpine landscape”
-
“{name} mountain summit, snow, rocky ridgeline”
-
-
可选反概念(告诉 SigLIP-2 不匹配的内容):对 “painting, illustration, poster, map, logo” 生成一个小向量并减去,以偏向真实照片。
-
-
可选创建图像原型:如果提供了山峰的参考照片。
然后将文本和图像原型融合生成最终向量。最后,将文档与所有必需字段一起索引:
def l2norm(v: np.ndarray) -> np.ndarray:
return v / (np.linalg.norm(v) + 1e-12)
def compute_blended_peak_vec(
emb: Siglip2,
names: List[str],
peak_id: str,
peaks_images_root: str,
alpha_text: float = 0.5,
max_images: int = 3,
) -> Tuple[np.ndarray, int, int, List[str]]:
"""
Build blended vector for a single peak.
Returns:
vec : np.ndarray (L2-normalized)
found_count : number of reference images discovered
used_count : number of references used (<= max_images)
used_filenames: list of filenames used (for logging)
"""
# 1) TEXT vector
tv = embed_text_blend(emb, names)
# 2) IMAGE refs: prefer folder by id; fallback to slug of the primary name
root = Path(peaks_images_root)
candidates = [root / peak_id]
if names:
candidates.append(root / slugify(names[0]))
all_refs: List[Path] = []
for c in candidates:
if c.exists() and c.is_dir():
all_refs = list_ref_images(c)
if all_refs:
break
found = len(all_refs)
used_list = all_refs[:max_images] if (max_images and found > max_images) else all_refs
used = len(used_list)
img_v = embed_image_mean(emb, used_list) if used_list else None
# 3) Blend TEXT and IMAGE vectors, clamp alpha to [0,1]
a = max(0.0, min(1.0, float(alpha_text)))
vec = l2norm(tv if img_v is None else (a * tv + (1.0 - a) * img_v)).astype("float32")
return vec, found, used, [p.name for p in used_list]peaks_catalog 索引示例文档:
Photos 索引
这个主索引存储相册中所有照片的详细信息。每个文档代表一张照片,包含以下信息:
-
照片在相册中的相对路径,可用于查看匹配的图片或在搜索 UI 中加载图片。
-
图片的 GPS 和时间信息。
-
由 SigLIP-2 生成的图像编码密集向量。
-
predicted_peaks,用于按山峰名称过滤。
索引映射:
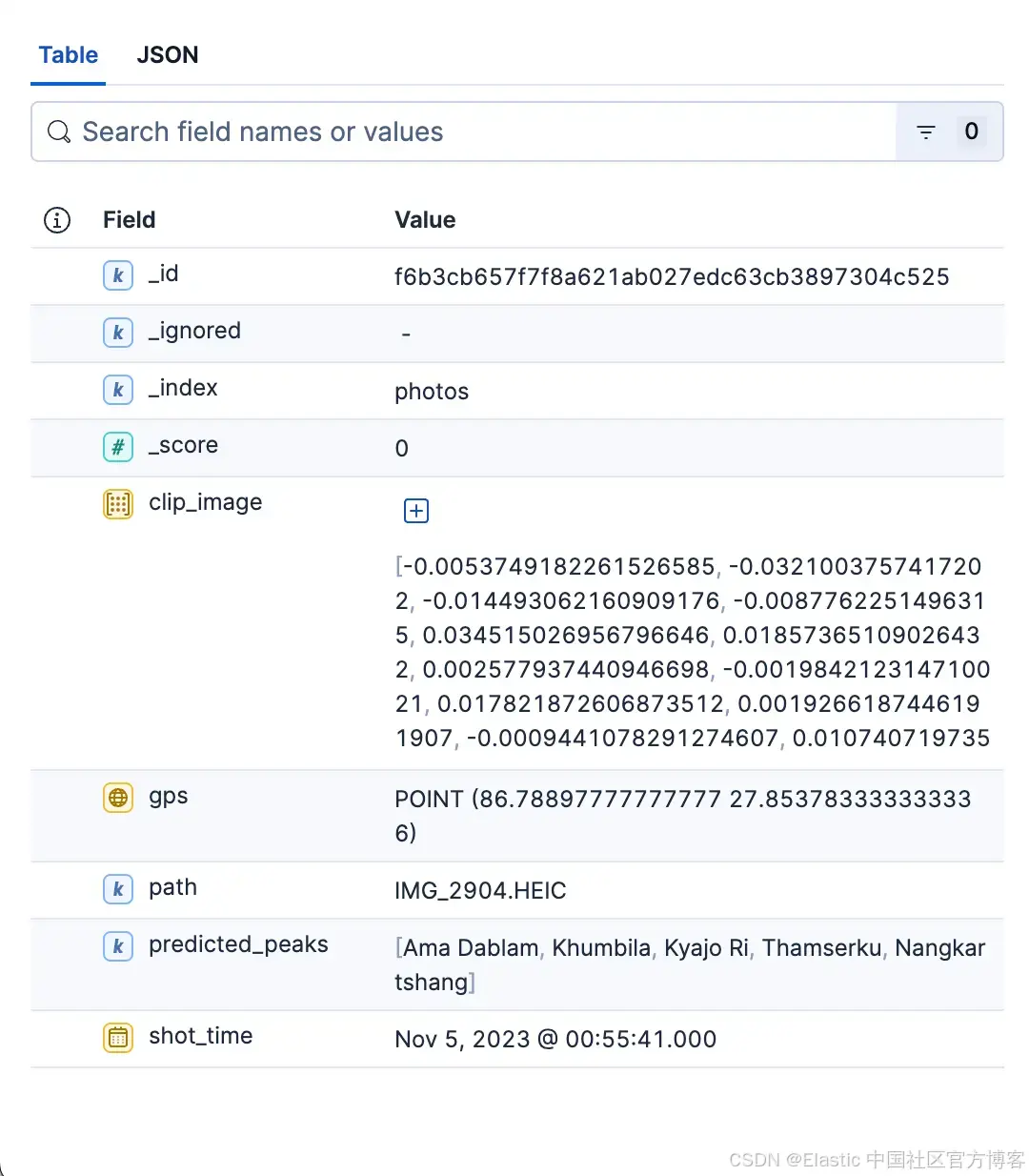
| 字段 | 类型 | 示例 | 用途/说明 | 向量 / 索引 |
|---|---|---|---|---|
| path | keyword | data/images/IMG_1234.HEIC | UI 打开缩略图/完整图片的路径 | — |
| clip_image | dense_vector | 768 | SigLIP-2 图像向量 | index:true, similarity:"cosine", index_options:{type:"hnsw", m:16, ef_construction:128} |
| predicted_peaks | keyword | ["ama-dablam","pumori"] | 索引时的 Top-K 猜测(便宜的 UX 过滤/分面) | — |
| gps | geo_point | {"lat":27.96,"lon":86.83} | 支持地理过滤 | — |
| shot_time | date | 2023-10-18T09:41:00Z | 拍摄时间:排序/过滤 | — |
photos 索引的索引策略:
对于相册中的每张照片,我们执行以下操作:
-
从图片元数据中提取 shot_time 和 gps 信息。
-
SigLIP-2 图像向量:将图片输入模型,并对向量进行 L2 归一化。将生成的向量存储在 clip_image 字段中。
-
预测山峰并存储在 predicted_peaks 字段:
-
首先使用上一步生成的图片向量
-
对 peaks_catalog 索引中的 text_embed 字段进行快速 kNN 搜索
-
保留前 3–4 个山峰,其余忽略
-
-
通过对图片名称和路径进行哈希生成 _id 字段,确保多次运行后不会产生重复记录。
-
确定照片的所有字段后,通过 批量索引(bulk indexing) 将照片文档索引入库。
def bulk_index_photos(
es: Elasticsearch,
images_root: str,
photos_index: str = "photos",
peaks_index: str = "peaks_catalog",
topk_predicted: int = 5,
batch_size: int = 200,
refresh: str = "false",
) -> None:
"""Walk a folder of images, embed + enrich, and bulk index to Elasticsearch."""
root = Path(images_root)
if not root.exists():
raise SystemExit(f"Images root not found: {images_root}")
emb = Siglip2()
batch: List[Dict[str, Any]] = []
n_indexed = 0
for p in iter_images(root):
rel = relpath_within(root, p)
_id = id_for_path(rel)
# 1) Image embedding (and reuse it for predicted_peaks)
try:
with Image.open(p) as im:
ivec = emb.image_vec(im.convert("RGB")).astype("float32")
except (UnidentifiedImageError, OSError) as e:
print(f"[skip] {rel} — cannot embed: {e}")
continue
# 2) Predict top-k peak names
try:
top_names = predict_peaks(es, ivec.tolist(), peaks_index=peaks_index, k=topk_predicted)
except Exception as e:
print(f"[warn] predict_peaks failed for {rel}: {e}")
top_names = []
# 3) EXIF enrichment (safe)
gps = get_gps_decimal(str(p))
shot = get_shot_time(str(p))
# 4) Build doc and stage for bulk
doc = {"path": rel, "clip_image": ivec.tolist(), "predicted_peaks": top_names}
if gps:
doc["gps"] = gps
if shot:
doc["shot_time"] = shot
batch.append(
{"_op_type": "index", "_index": photos_index, "_id": _id, "_source": doc}
)
# 5) Periodic flush
if len(batch) >= batch_size:
helpers.bulk(es, batch, refresh=refresh)
n_indexed += len(batch)
print(f"[photos] indexed {n_indexed} (last: {rel})")
batch.clear()
# Final flush
if batch:
helpers.bulk(es, batch, refresh=refresh)
n_indexed += len(batch)
print(f"[photos] indexed {n_indexed} total.")
print("[done] photos indexing")photos 索引示例文档:
总的来说,photos 索引是相册中所有照片的快速、可过滤、可用于 kNN 的存储。它的映射设计简洁 —— 仅保留快速检索、干净显示以及按空间和时间切分结果所需的结构。这个索引服务于两种搜索场景。创建两个索引的 Python 脚本可以在这里找到。
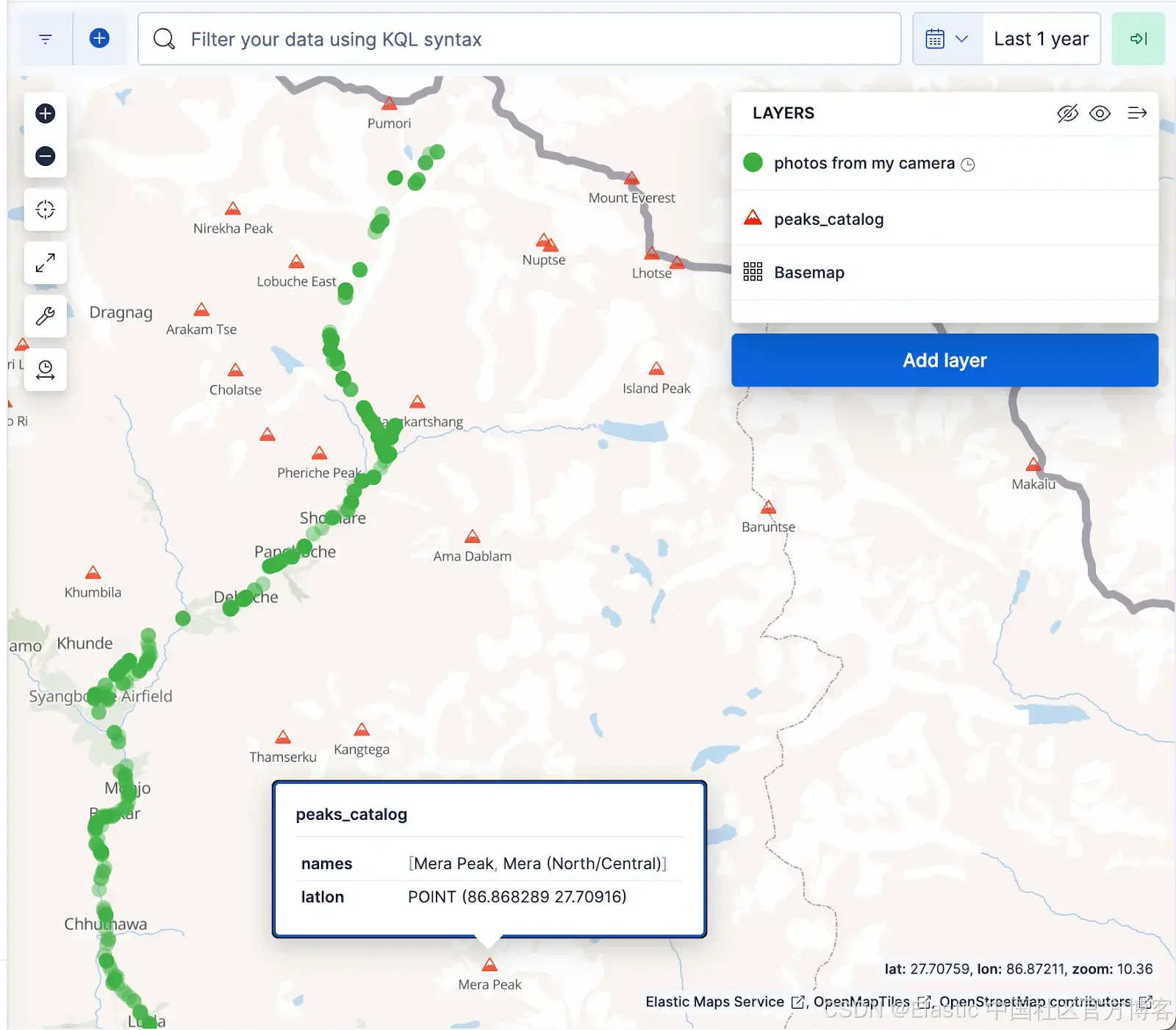
下图的 Kibana 地图可视化将相册中的文档显示为绿色点,将 peaks_catalog 索引中的山峰显示为红色三角形,绿色点与珠峰大本营徒步路线对齐良好。
搜索用例
按名称搜索(text-to-image):此功能使用户能够通过文本查询定位山峰照片(甚至抽象概念,如 “prayer flags”)。为实现这一点,文本输入会通过 SigLIP-2 转换为文本向量。
为了生成稳健的文本向量,我们采用与 peaks_catalog 索引中文本嵌入创建相同的策略:将文本输入与小型提示集合结合,减去一个小的反概念向量,并进行 L2 归一化,生成最终查询向量。
然后,在 photos.clip_image 字段上执行 kNN 查询,基于余弦相似度检索最匹配的山峰图片。可选地,通过应用地理和日期过滤,和/或在查询中使用 photos.predicted_peaks 词项过滤器,使搜索结果更相关(见下方查询示例)。这有助于排除徒步路线中实际上不可见的相似山峰。
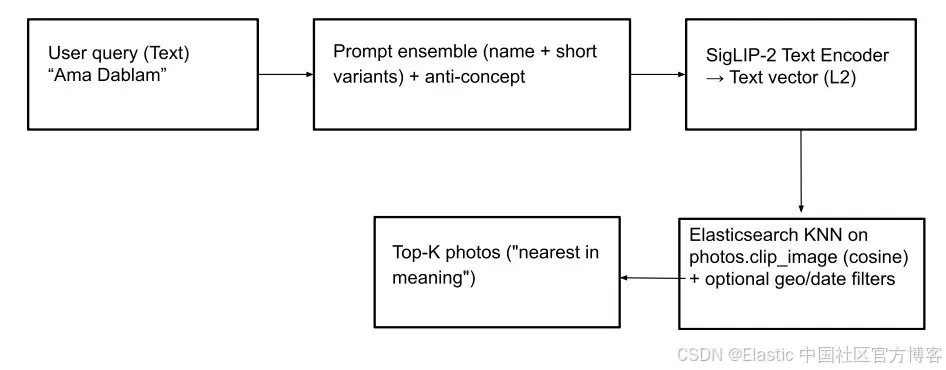
带地理过滤的 Elasticsearch 查询:
POST photos/_search
{
"knn": {
"field": "clip_image",
"query_vector": [ ... ],
"k": 60,
"num_candidates": 2000
},
"query": {
"bool": {
"filter": [
{ "geo_bounding_box": { "gps": { "top_left": "...", "bottom_right": "..." } } }
]
}
},
"_source": ["path","predicted_peaks","gps","shot_time"]
}
Response (first two documents):
{
"hits": {
"total": {
"value": 56,
"relation": "eq"
},
"max_score": 0.5779596,
"hits": [
{
"_index": "photos",
"_id": "d01da3a1141981486c3493f6053c79e92a788463",
"_score": 0.5779596,
"_source": {
"path": "IMG_2738.HEIC",
"predicted_peaks": [
"Pumori",
"Kyajo Ri",
"Khumbila",
"Nangkartshang",
"Kongde Ri"
],
"gps": {
"lat": 27.97116388888889,
"lon": 86.82331111111111
},
"shot_time": "2023-11-03T08:07:13"
}
},
{
"_index": "photos",
"_id": "c79d251f07adc5efaedc53561110a7fd78e23914",
"_score": 0.5766071,
"_source": {
"path": "IMG_2761.HEIC",
"predicted_peaks": [
"Kyajo Ri",
"Makalu",
"Baruntse",
"Cho Oyu",
"Khumbila"
],
"gps": {
"lat": 27.975558333333332,
"lon": 86.82515
},
"shot_time": "2023-11-03T08:51:08"
}
}
}按图片搜索(image-to-image):此功能允许我们识别图片中的山峰,并在相册中找到该山峰的其他照片。上传图片后,它会被 SigLIP-2 图像编码器处理,生成图像向量。然后在 peaks_catalog.text_embed 字段上执行 kNN 搜索,以识别最匹配的山峰名称。随后,从这些匹配的山峰名称生成文本向量,并在 photos 索引上进行另一轮 kNN 搜索,以定位对应的照片。
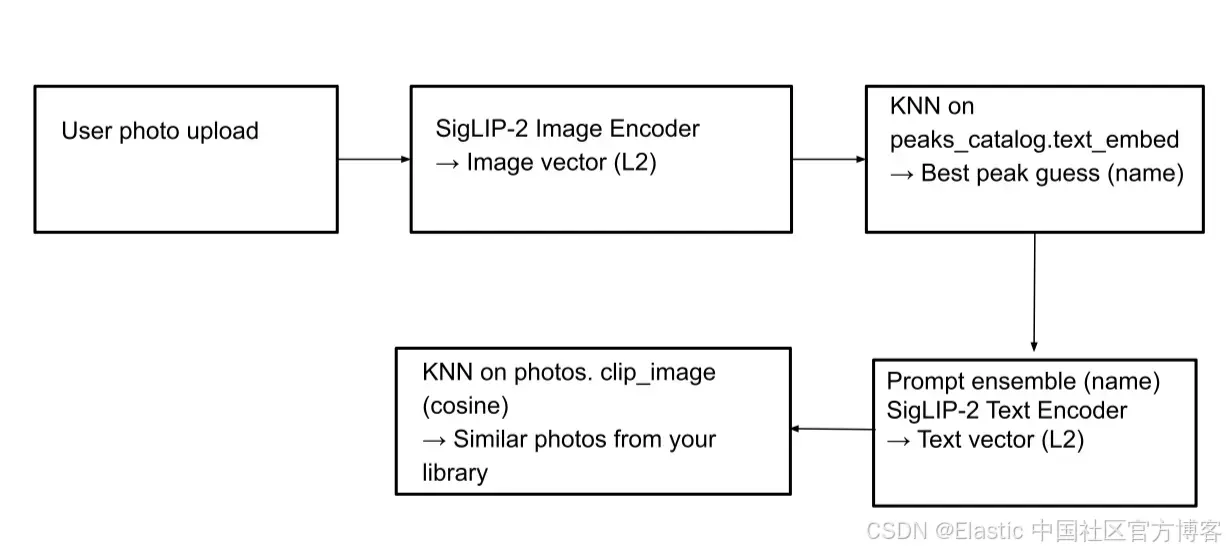
Elasticsearch 查询:
步骤 1:查找匹配的山峰名称
GET peaks_catalog/_search
{
"knn": {
"field": "text_embed",
"query_vector": [...image-vector... ],
"k": 3,
"num_candidates": 500
},
"_source": [
"id",
"names",
"latlon",
"text_embed"
]
}
Response (first two documents):
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.58039916,
"hits": [
{
"_index": "peaks_catalog",
"_id": "pumori",
"_score": 0.58039916,
"_source": {
"id": "pumori",
"names": [
"Pumori",
"Pumo Ri"
],
"latlon": {
"lat": 28.01472,
"lon": 86.82806
},
"text_embed": [
... embeddings...
]
}
},
{
"_index": "peaks_catalog",
"_id": "kyajo-ri",
"_score": 0.57942784,
"_source": {
"id": "kyajo-ri",
"names": [
"Kyajo Ri",
"Kyazo Ri"
],
"latlon": {
"lat": 27.909167,
"lon": 86.673611
},
"text_embed": [
... embeddings...
]
}
}
]
}
}步骤 2:在 photos 索引上执行搜索以找到匹配的照片(使用与 text-to-image 搜索用例相同的查询):
POST photos/_search
{
"knn": {
"field": "clip_image",
"query_vector": [ ...image-vector... ],
"k": 30,
"num_candidates": 2000
},
"_source": [
"path",
"gps",
"shot_time",
"predicted_peaks",
"clip_image"
],
"query": {
"bool": {
"filter": [
{
"term": {
"predicted_peaks": "Pumori"
}
}
]
}
}
}
Response (first two documents):
{
"hits": {
"total": {
"value": 56,
"relation": "eq"
},
"max_score": 0.5779596,
"hits": [
{
"_index": "photos",
"_id": "d01da3a1141981486c3493f6053c79e92a788463",
"_score": 0.5779596,
"_source": {
"path": "IMG_2738.HEIC",
"predicted_peaks": [
"Pumori",
"Kyajo Ri",
"Khumbila",
"Nangkartshang",
"Kongde Ri"
],
"gps": {
"lat": 27.97116388888889,
"lon": 86.82331111111111
},
"shot_time": "2023-11-03T08:07:13"
}
},
{
"_index": "photos",
"_id": "c79d251f07adc5efaedc53561110a7fd78e23914",
"_score": 0.5766071,
"_source": {
"path": "IMG_2761.HEIC",
"predicted_peaks": [
"Kyajo Ri",
"Makalu",
"Baruntse",
"Cho Oyu",
"Khumbila"
],
"gps": {
"lat": 27.975558333333332,
"lon": 86.82515
},
"shot_time": "2023-11-03T08:51:08"
}
}
}Streamlit UI
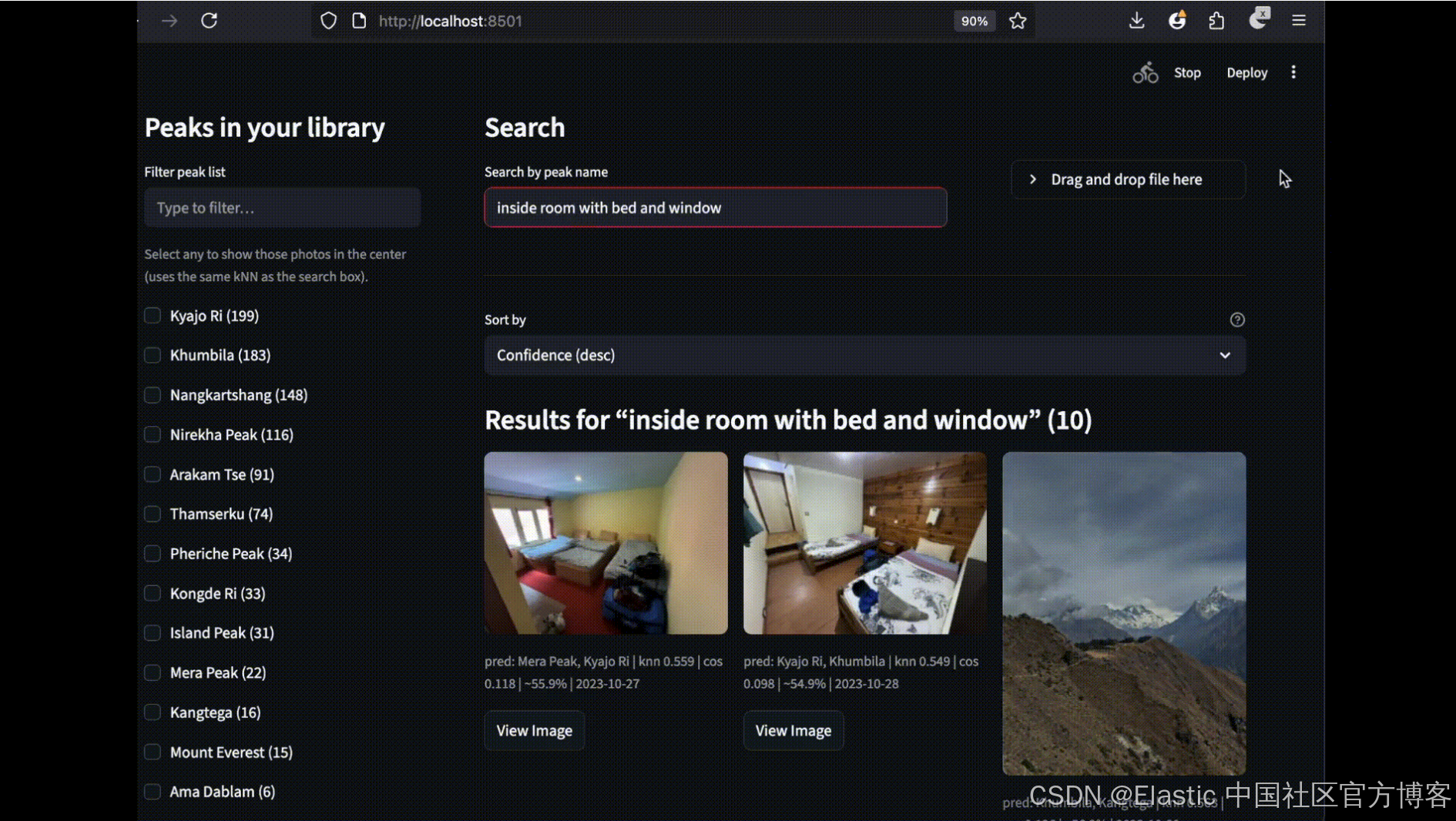
为了整合所有功能,我们创建了一个简单的 Streamlit UI,支持两种搜索用例。左侧栏显示一个可滚动的山峰列表(从 photos.predicted_peaks 聚合),带复选框和迷你地图/地理过滤器。顶部有按名称搜索框和从照片上传识别按钮。中间面板显示响应式缩略图网格,展示 kNN 分数、预测山峰徽章和拍摄时间。每张图片都包含一个 “view image - 查看图片” 按钮,可预览全分辨率图像。
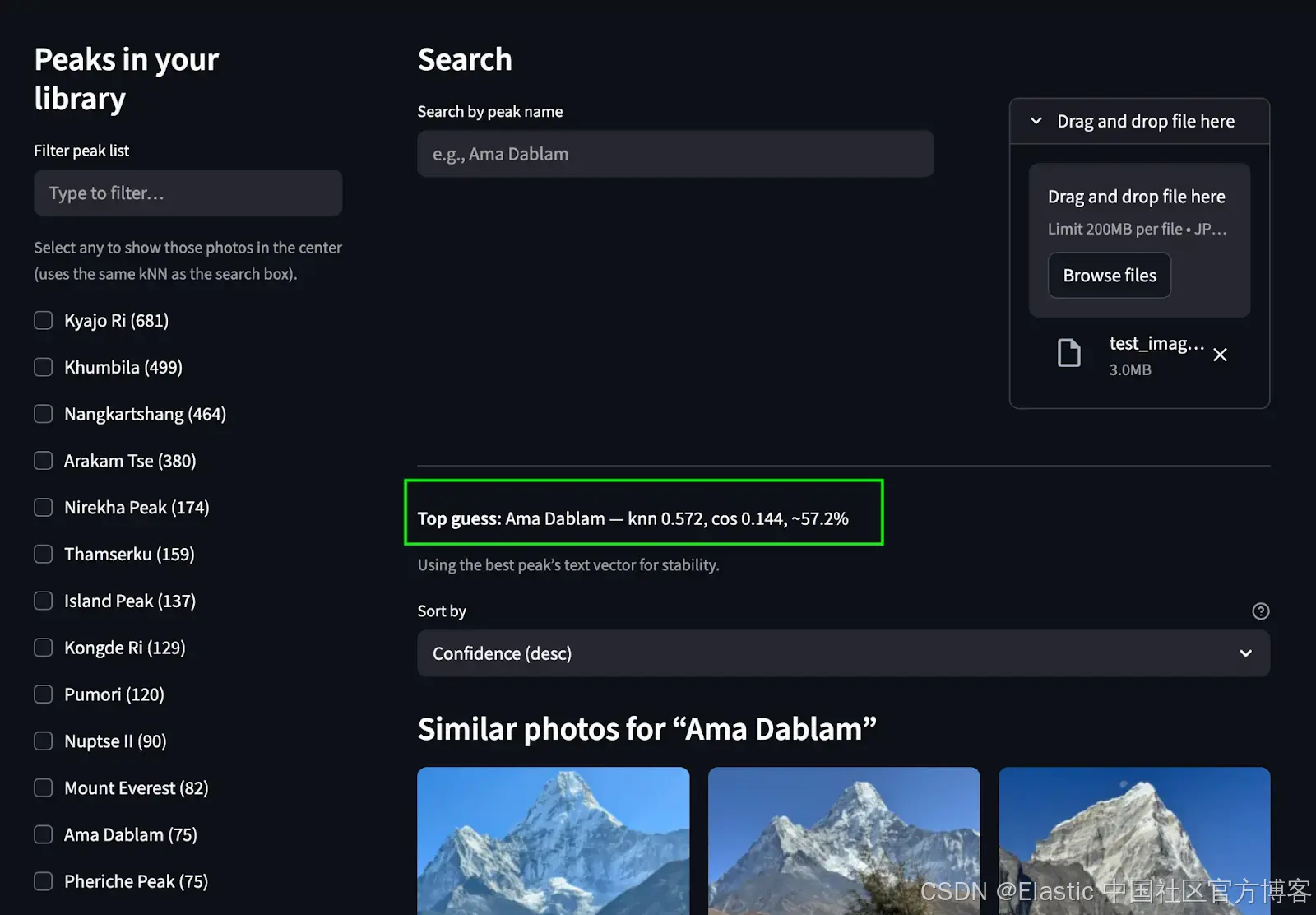
通过上传图片搜索:我们预测山峰并从相册中找到匹配的山峰。
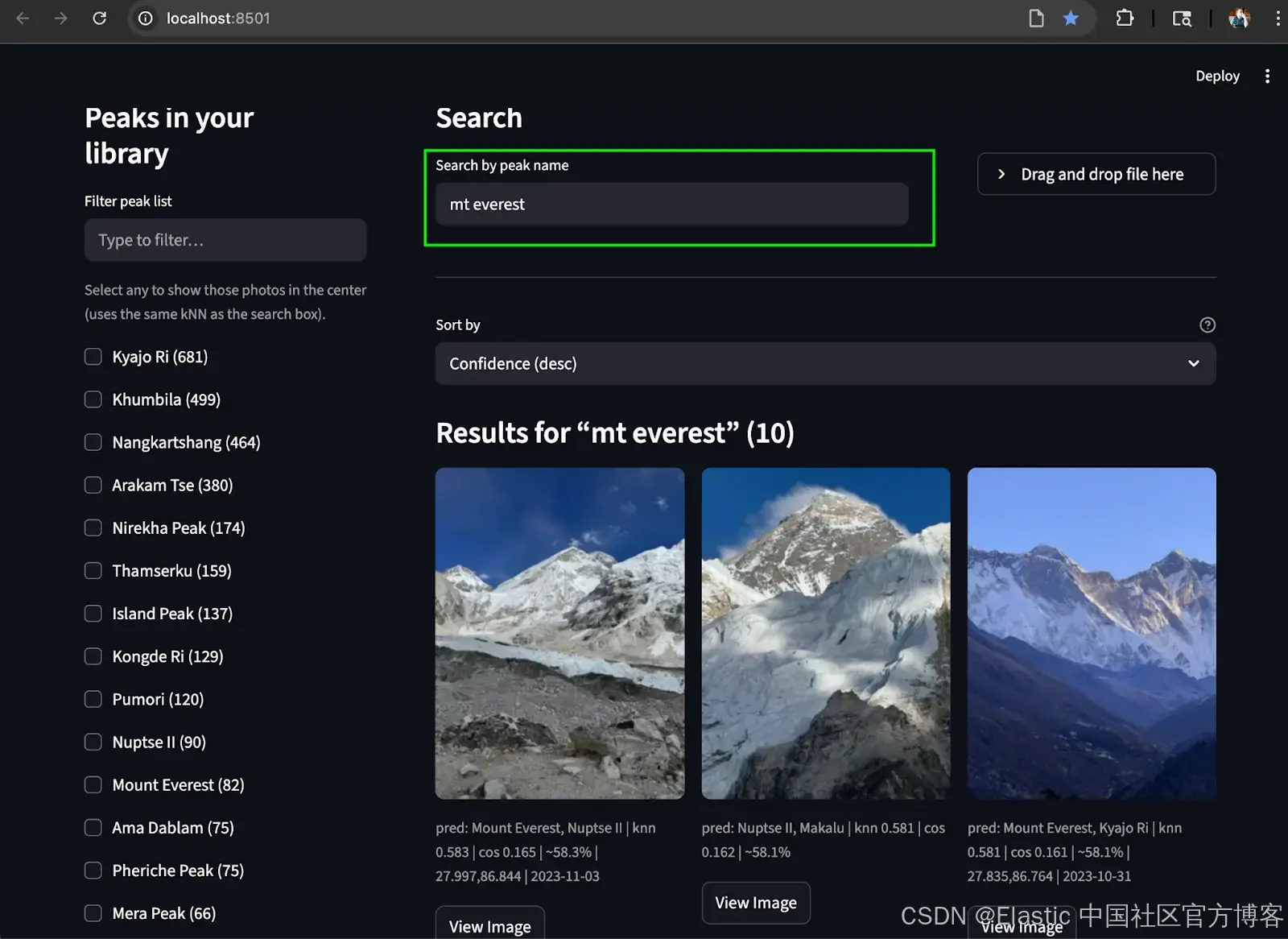
通过文本搜索:从文本中找到相册中匹配的山峰
结论
最初只是想看看 Ama Dablam 的照片,最终变成了一个小型、可用的多模态搜索系统。我们将原始徒步照片转换为 SigLIP-2 向量,并使用 Elasticsearch 对向量进行快速 kNN 搜索,同时结合简单的地理/时间过滤,根据意义呈现正确的图片。在此过程中,我们通过两个索引将关注点分离:一个小型 peaks_catalog 用于混合原型(用于识别),一个可扩展的 photos 索引存储图像向量和 EXIF 信息(用于检索)。它实用、可复现且易于扩展。
如果你想调整系统,有几个设置可以尝试:
-
查询时设置:k(希望返回的邻居数量)和 num_candidates(最终评分前搜索的范围)。这些设置在博客中有讨论。
-
索引时设置:m(图连接度)和 ef_construction(构建时精度与内存的权衡)。对于查询,也可尝试 ef_search——数值越高通常召回率越好,但可能增加延迟。有关这些设置的更多细节,请参见博客。
展望未来,多模态和多语言搜索的原生模型/重排序器很快将进入 Elastic 生态系统,这将使图像/文本检索和混合排序开箱即用效果更强。
如果你想自己尝试:
至此,我们的旅程结束,该返回家中了。希望这对你有帮助,如果你改进或破坏了它,我很想知道你做了哪些改变。

原文:https://www.elastic.co/search-labs/blog/multimodal-search-siglip-2-elasticsearch

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献283条内容
已为社区贡献283条内容

所有评论(0)