RAFT: Adapting Language Model to Domain Specific RAG
2024年6月UC Berkeley CoML2024。
**
带记忆的开卷考试
利用RAG微调LLM 使得在垂直任务上表现更好
**
2024年6月 UC Berkeley CoML2024
code: https://github.com/ShishirPatil/gorilla

文章目录
研究背景
在大规模的语料库中预训练LLM已经是标准化流程。但当LLM应用于许多下游任务时,通常需要通过RAG-base-prompt或者是微调合并新信息。那么到底哪种合并新信息的方式是最优的呢?
这篇文章提出了Retrieval Augmented Fine Tuning (RAFT) 检索生成微调的方法,可以提高模型在开卷域内回答问题的能力 in “open-book” in-domain settings。
在训练RAFT中,训练模型忽略对答案没有帮助的文档,即有害文档。RAFT通过逐字引用正确顺序来帮助回答问题。这与RAFT的CoT结合,能提高模型推理能力。 这是一种 post-training方法。
怎么忽略的? 这不改变其他也能实现吗?
文章主要回答一个问题:
如何为特定领域的检索增强生成(RAG)调整预训练的大语言模型(LLMs)
RAG based in-context learning

研究方法
结合 instruction fine-tuning(IFT) 和retrieval augmented generation(RAG) = Retrieval-Augmented
Fine Tuning (RAFT)
在RAFT中,我们训练模型从文档(D*)中回答问题(Q)以生成答案(A*),其中A*包括链式思维推理,并在存在干扰文档(Dk)的情况下进行。
评价方式:Top-k的检索文档
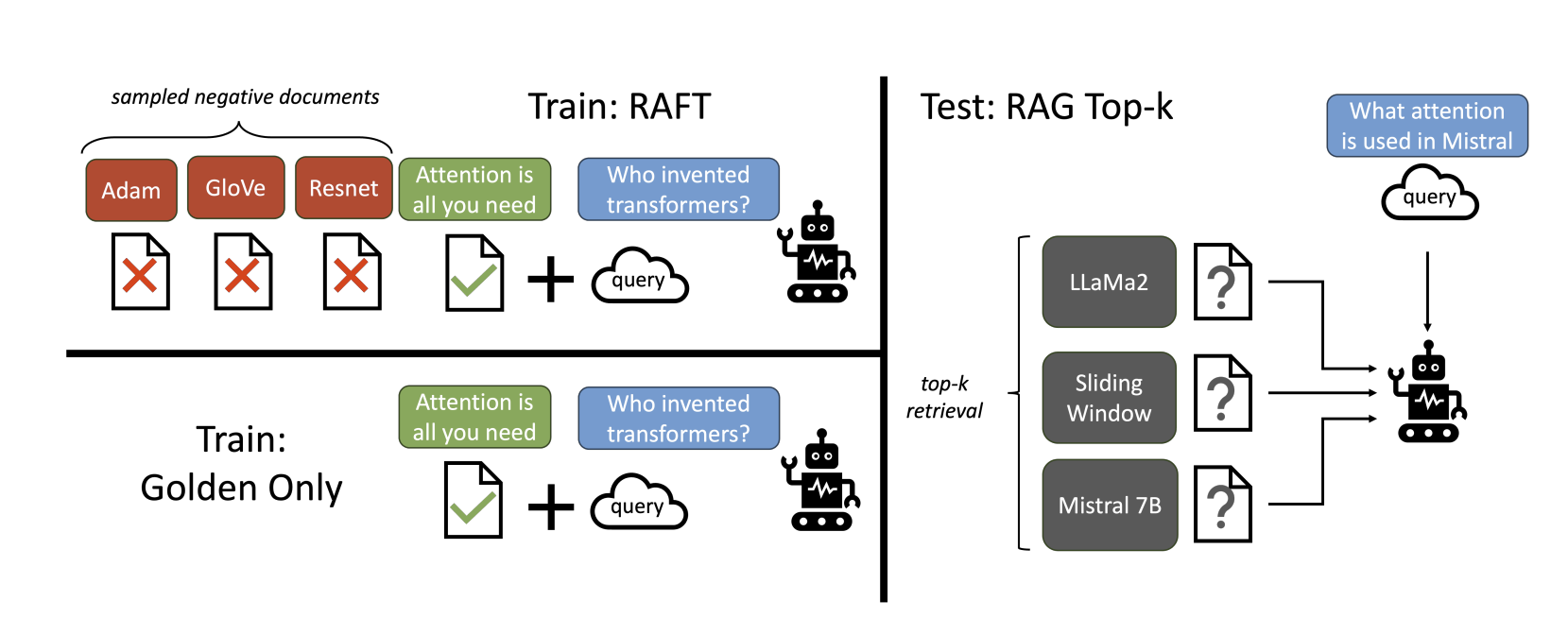
SFT的做法 回答和文档做检索生成
Q问题,A回答,D是训练文档
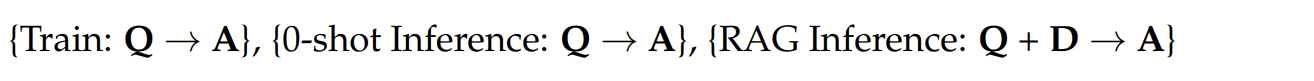
RAFT的做法:
D*是根据文档能推到出正确答案, D i D_i Di 是有害文档,不包含跟答案相关的信息
构造P%的数据有金标准文档,和(1-P)%的数据没有金标准文档。用(1-P)%的数据使得模型能记住答案???
用这种方式训练数据,包括向模型提供问题,上下文和经过验证的答案,然后请求它形成一个恰当的引用原始上下文的推理链。
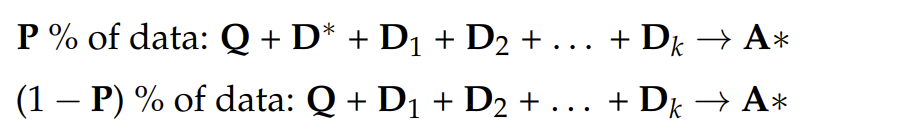
实验设计
- RAFT提高RAG的性能在私域上
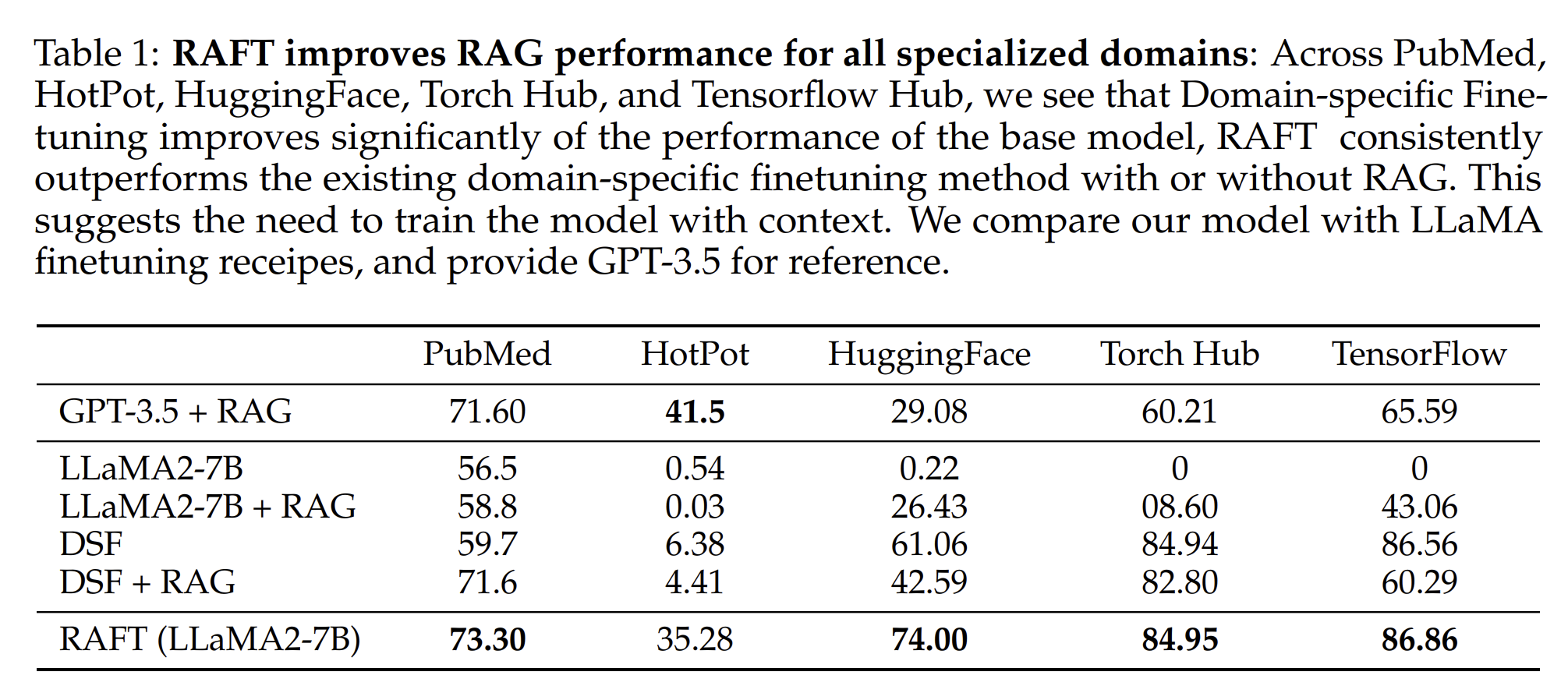
- RAFT加入CoT能提高性能

- 消融实验
- 3.1. 多少金标准文档训练效果比较好?P的取值讨论.
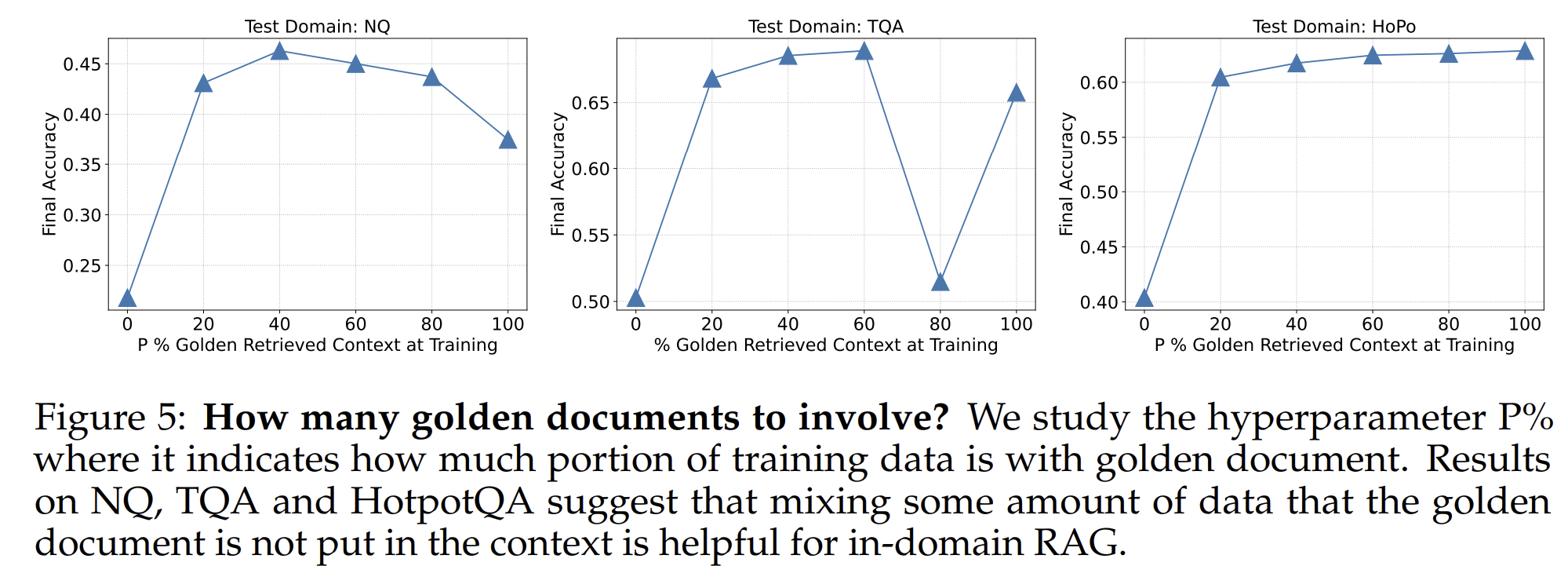
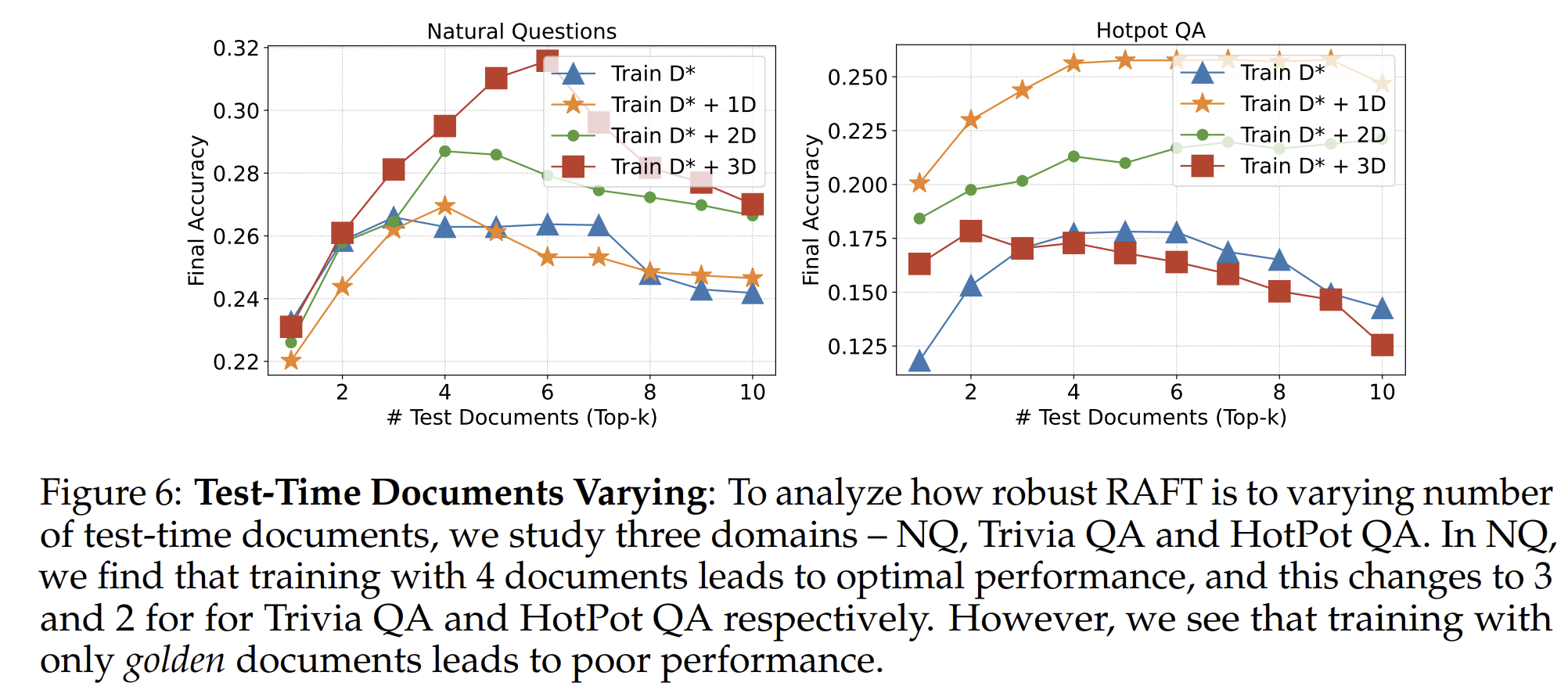
- 3.2. RAFT 加入多少有害的文档效果最好?
- RAFT 举例

Reviewer问题
我的问题:
- 就这? 正负样本一起训练,目标检测不是一直在用吗? CoT有效 这不也是常识吗?
投稿过程中reviewer的问题:
https://openreview.net/forum?id=rzQGHXNReU
-
#Reviewer1
Reasons To Accept:
1.1. RAFT方法不仅易于实现,而且在开放书设置的各种领域特定问答数据集中,其性能始终显著优于基线模型。
1.2. 论文组织良好,并包含图表和示例,使核心概念更加直观和易于理解。
(写的好,会比喻,说清楚确实是论文加分项)
[3] 除了在训练过程中使用oracle文档外,作者还有效地结合了干扰文档,并系统地展示了它们对模型性能的影响。
Reasons To Reject:
1.1. 数据使用不一致:作者似乎专注于PubMed和Huggingface等特定领域的数据集,如标题所示。然而,他们在第5节中没有明确说明包括NQ和TQA等通用领域数据集。这种数据使用的不一致性可能会让读者质疑“领域特定”设置的分析。
1.2.术语不一致:论文中使用了几个关键术语,但前后不一致,这可能降低可读性和清晰度。不一致之处包括:
Is it ‘Retrieval Augmented Fine Tuning’ or ‘Retrieval Aware Fine-Tuning’? Is it ‘golden documents’ or ‘oracle documents’?
Is it ‘sampled negative documents’ or ‘distractor documents’?
Rating: 7: Good paper, accept -
#Reviewer2
Reasons To Accept:
2.1. The authors introduce and demonstrate RAFT as an effective training strategy for RAG-style tasks. Introducing distractor documents during instruction fine-tuning improves these models’ ability at inference time.
2.2.There is a clear hypothesis, good experimental design, and reasonable ablations
2.3.Results are provided over a good range of datasets and demonstrate the effectiveness of the technique
2.4.The paper is well written and organized
(有效的性能,清晰假设,良好实验,可信消融,多个数据有效性,写的很好组织的很好) 牛啊,以后写reviewer夸夸词
Reasons To Reject:
No obvious reasons
Rating: 9: Top 15% of accepted papers, strong accept -
#Reviewer3
Reasons To Accept:
3.1.The proposed method achieves strong performance compared to baselines.
3.2.Useful results to prepare domain-specific fine-tuning data in a specific domain, including various baselines and datasets.
Reasons To Reject:
3.1.想法缺乏新颖性,特定领域微调和RAG已经被广泛认为是解决特定领域任务的有效方法,所以本文将两者结合优于基线是预期的结果。没有适当提示的DSF是一个无意义的基线
3.2.将RAFT与没有领域特定微调的基线进行比较时,性能提升也是预期的
3.3.证明RAFT有效的一种可能方法是将其应用于除开放域QA之外的任务,即当领域特定注释未知或检索不是必要步骤时。你是否考虑过尝试诸如文本到SQL或基于推理的QA等任务?
Rating: 6: Marginally above acceptance threshold
回答: 3.1.虽然两者分别都有,但我们进行了彻底研究,并在小模型和CoT等领域都做了实验
3.2. DSF微调了!
3.3. SQL跟RAG关注的不是一个问题,RAFT会在编码(text-to-SQL)或推理(推理QA)都提高新能。RAFT关注在创建专家RAG模型,而不是为了探究一种通用的后训练策略
看paper的提纲
提问(解决了什么问题?)
理解(怎么解决的?)
验证(结果怎么样?)
反思
1.为什么能解决?为什么有效?为什么某个方法在这个任务上表现这么好?
2.它和传统方法相比,核心改进在哪?局限性是什么?
3.这个方法是否可以迁移到我的问题上?

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)