泄露机密:利用CPU缓存旁路信道泄露大型语言模型生成的令牌
共享硬件资源上的旁路攻击日益威胁到保密性,特别是随着大型语言模型(LLMs)的兴起。在这项工作中,我们介绍了“泄露机密”,这是一种通过缓存旁路信道泄露由LLM生成的令牌的新方法。通过在同一硬件上与受害模型并行运行攻击进程,我们刷新并重新加载嵌入层中的嵌入向量,其中每个令牌对应一个唯一的嵌入向量。在令牌生成过程中访问时,它会导致我们的攻击可检测到的缓存命中。一个重大挑战是LLMs的巨大规模,由于其计
安德鲁·阿迪莱塔
MITRE
伯克·苏纳尔
伍斯特理工学院
摘要
共享硬件资源上的旁路攻击日益威胁到保密性,特别是随着大型语言模型(LLMs)的兴起。在这项工作中,我们介绍了“泄露机密”,这是一种通过缓存旁路信道泄露由LLM生成的令牌的新方法。通过在同一硬件上与受害模型并行运行攻击进程,我们刷新并重新加载嵌入层中的嵌入向量,其中每个令牌对应一个唯一的嵌入向量。在令牌生成过程中访问时,它会导致我们的攻击可检测到的缓存命中。
一个重大挑战是LLMs的巨大规模,由于其计算密集型操作,会迅速将嵌入向量从缓存中驱逐。我们通过平衡监控的令牌数量与泄露的信息量来解决这一问题。监控更多令牌会增加潜在词汇表泄露的可能性,但也会因驱逐而错过缓存命中的机会;监控更少的令牌可以提高检测可靠性,但限制了词汇表覆盖范围。
通过广泛的实验,我们证明了通过缓存旁路信道泄露LLM令牌的可行性。我们的研究揭示了LLM部署中的新漏洞,强调即使复杂的模型也容易受到传统的旁路攻击。我们讨论了LLM服务基础设施对隐私和安全的影响,并提出了缓解此类威胁的考虑因素。作为概念验证,我们考虑了两个具体的攻击场景:我们的实验表明,攻击者可以通过一次性监控恢复高达80%-90%的高熵API密钥。至于英语文本,我们可以通过单次尝试达到40%的恢复率。我们应该注意,该比率高度依赖于监控的令牌集,这些比率可以通过针对更专业的输出域来改进。
1 引言
大规模语言模型(LLMs)的广泛部署彻底改变了自然语言处理任务,使金融、医疗保健和客户服务等各种领域的应用成为可能。然而,对这些模型的日益依赖引发了关于隐私和安全的重大担忧,特别是在多用户环境中,共享硬件资源可能会被利用。
对键值(KV)缓存的攻击。最近的研究发现了由于使用缓存机制如键值(KV)缓存[18, 27]而在LLM推理系统中出现的漏洞。KV缓存存储中间计算结果,特别是注意力键和值向量,以通过重用它们来加速相似输入序列的推理。然而,当这些缓存命中或未命中时,会出现细微的时间差异,允许攻击者根据LLM响应的速度推断敏感数据。
宋等人[18]表明,通过仔细测量生成输出所需的时间,可以检测KV缓存中的命中情况,从而重建私有提示令牌或系统指令。同样,郑等人[27]描述了一种基于时间的旁路攻击方法,通过操纵输入候选者并仔细分析响应延迟来破坏LLM推理。通过KV缓存泄露整个对话的能力推动了软件级防御的研究。最近发表的一项工作[11]提出了KV-Shield,它在初始化时打乱权重矩阵,从而使泄露的KV对变得难以识别。他们的方法通过将关键的打乱操作限制在可信执行环境(TEE)内,防止直接GPU访问未加密的KV数据,从而减轻KV基础泄漏。
输出令牌计数和网络泄露。其他最新研究表明,利用LLM在推理时生成多少令牌的时间和长度旁路信道所带来的风险。在[25]中,作者表明,测量响应延迟可以揭示LLM的输出令牌计数,泄露目标语言或输出类等敏感属性。他们提出的攻击利用了多语言翻译任务和文本分类情景中的令牌计数偏差,并扩展到远程、基于网络的时间测量。同样,[23]展示了实时LLM响应中的令牌长度旁路信道,通过加密浏览器或API连接泄露整个句子。通过利用大型语言模型根据观察到的令牌长度模式重建明文,这些攻击有效地实现了对受害者AI助手交互的远程键盘记录。尽管这两项努力都分享了我们的高层次动机——发现隐藏的令牌推理渠道,但我们的方法有所不同,因为它针对的是LLM嵌入的硬件级缓存,而它们则依赖于应用程序或网络堆栈中的时间和长度暴露。因此,旨在减弱令牌计数或响应长度信号的现有缓解措施可能无法直接阻止对共享CPU缓存的低级攻击。
硬件缓存与KV缓存泄露。尽管这些努力旨在保护软件级KV缓存,但据我们所知,没有先前的工作专注于LLM推理管道中的微架构缓存。现有的KV缓存防御不涉及发生在软件层以下的攻击,特别是针对存储嵌入矩阵和其他模型参数的CPU缓存层次结构。与通常在用户空间中管理且可以直接修补或打乱的KV缓存不同,硬件缓存受CPU微架构控制,使得通过传统软件方法保护它们变得极为困难。
LLMs通过将输入令牌映射到嵌入层中的嵌入向量来处理输入令牌[2, 13]。这种映射将高维、稀疏的数据转换为捕捉令牌之间语义关系的低维密集空间。嵌入层作为一个查找表,其中每个唯一令牌对应一个特定的嵌入向量。在推理过程中,当处理一个令牌时,其对应的嵌入向量从嵌入层检索出来以生成上下文适当的响应。在多用户系统或云环境中,这些嵌入矩阵可能驻留在共享缓存中,从而为旁路攻击创造了潜在途径。由于嵌入层访问与正在处理的令牌相对应的特定内存位置,位于同一硬件上的攻击者可以潜在地监控缓存访问模式,以推断受害者LLM使用的令牌。
缓存层次结构的普遍性和常见的内存优化功能(如页面去重)为旁路攻击创造了肥沃的土壤。执行任何这些技术的攻击者都有潜力提取有关受害者数据使用的高分辨率信息,从加密操作到LLM服务环境中的自然语言令牌。缓解措施通常集中在防止精细粒度的攻击者观察——要么通过禁止共享页面、掩盖内存访问模式,要么通过实现硬件缓存分区——然而,这些补救措施往往带来不可接受的性能或部署开销,使得缓存旁路信道成为一个持续的威胁。
这项工作首次演示了利用硬件级缓存旁路信道(例如通过Flush+Reload [24])攻击LLMs的方法。虽然KV-Shield、FHE或基于TEE的协议可能减轻KV泄露,但它们不会自然扩展到嵌入层访问或其他存储在物理缓存中的参数。我们的方法表明,即使软件级缓存得到保护,通过监控攻击者和受害者进程共享的低级内存资源,仍然可以泄露敏感令牌。这使得LLM部署容易受到硬件级泄露的影响,需要更广泛的防御策略,以同时解决KV级和硬件级旁路信道。
我们的贡献
在本文中,我们介绍了“泄露机密”,一种利用缓存旁路信道攻击泄露LLM生成的令牌的新方法。具体来说,我们:
- 引入了一种新的攻击向量,通过利用统一CPU/GPU内存中的数据一致性,针对托管在同一服务器上的LLM输出进行缓存访问;
-
- 不同于早期的旁路攻击,我们的方法即使在单次测量下也能精确恢复令牌;重复运行相同的提示词可以完全恢复LLM的输出。
-
- 根据LLM输出的主题,我们可以在单次尝试中恢复多达40%的普通英语令牌。至于高熵API密钥,由于API密钥中的受限令牌集可以实现更高的覆盖率,攻击者可以在单次监控中恢复多达80%-90%的密钥。
-
- 解释了如何利用LLM嵌入层的访问模式,通过CPU缓存监控推断模型正在处理的令牌;
-
- 通过实验权衡大模型中的缓存驱逐与开销以及监控的令牌数量和泄露的信息量之间的关系来应对挑战;
-
- 通过广泛的实验验证“泄露机密”的有效性,突出通过缓存旁路信道泄露LLM令牌的可行性,并提供了一个端到端的例子,我们在其中泄露了用户的敏感API密钥;
-
- 讨论共享硬件对LLM推理的整体安全影响及潜在的缓解措施。
2 背景
现代计算系统采用分层内存架构来弥合快速处理器和较慢主内存之间的性能差距。了解这种内存层次结构对于分析利用这些架构特征泄露敏感信息的缓存攻击至关重要。
此外,大型语言模型(LLMs)的内部机制,尤其是它们对嵌入层的使用,呈现出独特的漏洞,可能成为此类攻击的目标。
2.1 内存层次结构和缓存旁路信道攻击
现代处理器中的内存层次结构。当代CPU设计有多级缓存层次结构以提高计算效率。这种层次结构通常包括靠近CPU核心的小型、快速一级(L1)缓存、较大的二级(L2)缓存,甚至更大的共享三级(L3)缓存[7]。缓存层次结构通过将频繁访问的数据存储得更接近处理器来减少内存访问的延迟。
在多核处理器中,较低级别的缓存(如L3)通常在核心间共享,从而实现更快的进程间通信,但也引入了潜在的安全风险[24]。这些缓存的共享性质允许在不同核心上运行的进程相互影响缓存状态,形成了跨核心缓存旁路攻击的基础。
定时旁路攻击。定时旁路攻击利用某些操作所需的处理时间经常泄露系统内部状态的敏感信息这一事实。通过仔细测量目标操作的执行延迟,攻击者可以推断出是否采用了特定代码路径、访问了哪些数据结构或使用了哪些加密密钥。早期关于定时旁路攻击的研究主要集中在加密例程上[3, 9],其中指数运算或乘法时间的微小变化向远程攻击者泄露了秘密密钥。随后的研究扩大了范围,涵盖了操作系统、虚拟机监视器和各种微架构资源,如缓存、分支预测器和DRAM行缓冲区[16, 19]。
在旁路攻击的大背景下,定时分析尤其强大,因为它的成本低且适用范围广。与故障攻击或电磁(EM)分析不同,定时旁路攻击通常不需要专门的硬件或物理接近;测量通常是纯软件完成,无论是本地还是远程。当与其他微架构旁路攻击结合使用时——例如,在共享CPU缓存上的Flush+Reload或Prime+Probe——定时测量能够对受害者进程中的私人操作进行高分辨率观察[16, 24]。这些攻击可以泄露加密密钥、用户按键、网页浏览历史,正如我们的结果显示,还可以泄露敏感的语言模型令牌。
在多租户环境中,如公共云,定时旁路攻击变得更加令人担忧。在这里,攻击者只需租用或部署在同一物理硬件上的虚拟机即可与受害者共处。尽管虚拟化层提供了隔离保证,
共享硬件资源仍易受精确定时探测的影响,这些探测揭示了虚拟机间的交互[26]。现代防御措施通常围绕时间分区、内存混淆或硬件分区等策略,但每种策略都面临实际部署和性能权衡。因此,理解和缓解定时旁路攻击风险在从高性能数据中心到消费级硬件的广泛平台上都是至关重要的。
缓存旁路攻击。缓存旁路攻击利用内存访问在缓存中“命中”与“未命中”之间的定时差异[19]。通过仔细测量访问时间,攻击者可以推断出有关受害者内存访问模式的敏感信息。诸如Flush+Reload [24]、Prime+Probe [8]和Prime+Scope [17]之类的技术已被用来以高精度提取加密密钥、按键信息和其他机密数据。
Flush+Reload特别强大,因为它能提供受害者进程访问的确切内存行的细粒度洞察。它利用攻击者和受害者之间的共享页面,这些共享页面通常通过内存去重(例如Linux中的Kernel Same-Page Merging)或共享库引入。为了进行攻击,攻击者首先使用clflush指令在整个缓存层次结构中刷新特定的缓存行,然后测量重新加载所需的时间。如果重新加载速度快,则攻击者推断受害者必须在此期间访问了该行,从而将其重新缓存。这种机制是由许多现代CPU缓存架构的包容性特性启用的:当数据从最后一级缓存(LLC)中刷新时,它也会从更高层级的缓存中驱逐,确保整个层次结构中的一致驱逐[24]。Flush+Reload [24]技术在加密实现的背景下已被广泛研究[1],使攻击者能够恢复秘密密钥和其他机密数据。
Prime+Probe和Prime+Scope则不需要共享页面。Prime+Probe先填充(即填满)特定的缓存集,然后探测这些相同的缓存行,以检测受害者访问是否驱逐了任何行[8]。Prime+Scope通过缩小到更小的缓存片或方式进一步细化,提供一种更有效的方法来推断缓存使用,减少噪音[17]。尽管这些技术可以近乎实时地显示受害者缓存使用的详细信息,但它们通常需要对缓存索引和关联性有更详细的了解。然而,每种方法都利用了这样一个原则:缓存活动——可通过定时测量——泄露了受害者计算中涉及的确切内存地址或缓存集。
云环境中的缓存攻击。先前的研究还探索了云和多租户环境中的缓存旁路攻击[26]。这些研究表明,攻击者
可以利用共享缓存从共处的虚拟机或进程中提取敏感信息。此类攻击在基于云的LLM部署中构成了重大风险,其中多个用户共享物理硬件,可以被利用来推断敏感信息,如私人输入、输出或配置细节,从共处的进程中。
2.2 页面去重和内存共享
内核相同页合并(KSM)。页面去重,通常在Linux系统中称为内核相同页合并(KSM),是一种内存优化技术,它识别不同进程或虚拟机(VMs)之间的相同内存页,并将它们合并成一个物理页。此过程通过消除冗余数据减少了整体内存占用,这对运行多个类似应用程序或操作系统的环境特别有益。
KSM通过扫描主内存以查找具有相同内容的页面来运行。一旦找到这样的页面,它们就会被合并成一个页面,并且所有对原始页面的引用都会更新为指向这个共享页面。共享页面被标记为写时复制(COW),以确保如果任何进程试图修改该页面,则为该进程创建一个私有副本以保持数据完整性。
虚拟化环境中的好处。在虚拟化场景中,许多VM可能运行相同的客户操作系统或应用程序,存在大量的内存重复[21]。通过使用页面去重,虚拟机管理程序可以大大减少内存使用,允许在一个单一物理主机上运行更多的VM。KSM可以通过在它们之间共享常见页面来使运行数十个虚拟实例成为可能,即使物理内存有限。
安全影响。尽管页面去重提供了内存效率的好处,但它引入了可被旁路攻击利用的安全漏洞[5]。去重页面的共享特性使攻击者能够执行高分辨率缓存旁路攻击,如Flush+Reload [24]。由于攻击者和受害者进程共享物理内存页,攻击者可以监控缓存访问模式以推断来自受害者的敏感信息。
此外,页面去重可以被滥用以绕过地址空间布局随机化(ASLR),这是一种通过随机化内存地址来防止利用的安全机制[4]。通过检测页面是否已被合并,攻击者可以获得有关受害者进程内存布局的见解。
3 相关工作
先前工作的局限性。对LLM的先前攻击主要集中于软件层面的漏洞,例如利用API行为、提示操控或应用层缓存机制中的时间差异[18]。这些方法通常依赖于特定的软件配置或假设,通常只提取部分或语义信息而非确切的令牌序列,而且还需要多次尝试。相比之下,我们的工作是第一个利用硬件级别微架构漏洞来泄露LLM令牌的攻击,一次即可完成。通过直接使用Flush+Reload技术瞄准嵌入层,我们能够以高精度恢复确切的令牌。这种基于硬件的攻击比以前的方法处于更低的级别,绕过了软件防御,并揭示了LLM中之前未被探索的信息泄露矢量。
4 泄露机密
“泄露机密”攻击利用缓存旁路技术提取大型语言模型(LLMs)在推理过程中生成的令牌。图1说明了高级别的攻击流程。对手通过利用Flush+Reload旁路技术监控受害者LLM进程嵌入层的内存访问模式。此方法检测特定嵌入向量——对应于唯一令牌——何时被访问和缓存。通过观察这些模式,攻击者可以逐个重构受害者LLM推理的输出。
在典型情况下,受害者运行一个进程以访问托管在共享硬件上的LLM,例如在云计算环境中。LLM的推理操作在附加的GPU上执行,而攻击者和受害者都位于同一个CPU上。重要的是,我们怀疑该攻击利用了Nvidia Cuda 8中引入的统一CPU/GPU内存,它确保了数据一致性,并允许嵌入向量驻留在CPU内存中,使其容易受到旁路监控。
攻击按以下步骤进行:
- 设置:攻击者在同一物理CPU上与受害者进程共处,从而获得对共享CPU内存空间的访问。
-
- 校准:攻击者使用元数据识别模型文件(例如GGUF文件)中的嵌入层内存位置,并计算目标令牌的偏移量。
-
- 刷新:攻击者使用clflush指令将与嵌入向量相对应的特定内存地址从缓存中驱逐。
-
- 监控:在受害者LLM推理过程中,攻击者测量内存访问时间以检测缓存命中。缓存命中表示受害者访问了特定令牌的嵌入向量。
-
- 推理重构:攻击者将检测到的缓存命中与令牌ID相关联,逐个重构受害者LLM推理的输出。
-
- 迭代:攻击者重复此过程以监控多个令牌,优化检测可靠性和词汇覆盖范围之间的权衡。
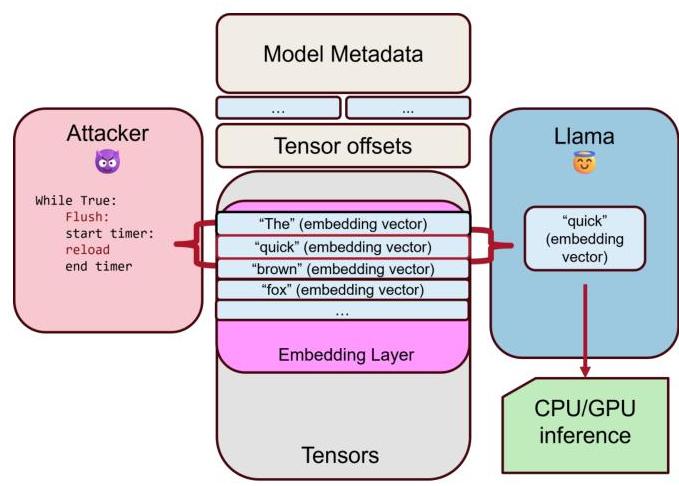
图1:“泄露机密”攻击概述。
威胁模型 我们假设目标系统没有任何软件/硬件漏洞和逻辑保护,例如通过进程和虚拟机隔离实现的沙箱。我们假设与受害者共处,攻击者仅在处理器或内存系统上有软件访问权限。另一个限制是我们假设攻击者无法访问受害者的GPU,仅需物理共享CPU内存空间,而逻辑上仍隔离。此外,攻击者不能执行低级物理旁路或故障攻击,例如电磁(EM)故障或使用任何物理手段监控受害者的系统,例如连接示波器或探针。实际上,攻击者无需物理接近,只需在CPU内存空间与受害者共处即可。
虽然LLM的用例不断演变,但在许多场景中可以发起拟议的攻击。目前,LLM正被集成到我们的计算基础设施中,例如网站、移动助手和企业软件中。例如,
- 由LLM后端支持的面向消费者的的应用程序可能成为共处敌人的受害者;
-
- 在企业环境中,共享服务器运行LLM时,员工可能会针对他人窃听他们的LLM查询;
-
- 通过将缓存监控扩展到浏览器设置,浏览器标签页可能会在本地桌面窥探LLM查询。
Nvidia Cuda 8+中的CPU/GPU内存一致性。“泄露机密”攻击者与受害者一起运行在
- 通过将缓存监控扩展到浏览器设置,浏览器标签页可能会在本地桌面窥探LLM查询。
CPU上监控受害者(CPU)的内存访问。这就引出了一个问题:既然实际推理是在GPU上运行的,那么实际的令牌嵌入表物理上在哪里?很自然地期望令牌嵌入向量会被加载到GPU内存中,因为GPU用于在LLM推理的开始和结束时分别计算令牌编码和解码。如果是这样,那么如何能在仅限于CPU的攻击者监控GPU内存上的访问?
随着2017年Nvidia Cuda 8的发布[15],许多新功能被引入以简化CPU/GPU编码并提高内存管理效率。统一内存[6]首次被扩展,允许GPU代码超订阅,即分配超过GPU物理可用的内存,类似于我们在CPU中使用虚拟内存的方式。此外,GPU内存上引入的页面错误确保了即使没有显式同步(和昂贵的等待),CPU/GPU数据一致性也能得到保证。这意味着只要嵌入向量保留在统一内存中,由于数据一致性,两个设备都会保留同步副本。因此,在我们的威胁模型中,攻击者可以通过在本地CPU内存上运行flush+reload来监控GPU内存上的嵌入表,这得益于一致性和可缓存的表。
令牌表示和嵌入层。在自然语言处理中,单词或令牌通常表示为高维、稀疏的向量。嵌入层将这些令牌转换为捕获语义关系的密集向量[2]。在嵌入层中,每一行对应于一个独特令牌的嵌入向量。
在推理过程中,当LLM处理输入文本时,它从嵌入层检索每个令牌的嵌入向量[20]。然后将这些向量输入到模型的后续层以生成上下文适当的响应。嵌入向量在输入处理和生成阶段频繁访问。
嵌入层中的内存访问模式。访问嵌入向量涉及读取嵌入层中与输入令牌相对应的特定内存位置。此过程生成可被旁路攻击利用的特定内存访问模式。嵌入层是一个庞大而密集的数据结构,当多个令牌顺序处理时,会对缓存状态产生显著变化。
LLM通常拥有多达128 K个令牌的词汇表,导致嵌入向量占用大量内存空间。这些矩阵的庞大尺寸通常导致缓存行的快速驱逐,使得攻击者在不遗漏缓存命中的情况下监控特定令牌变得具有挑战性。
监控嵌入层的挑战。大型LLM中嵌入层的大小和复杂性对缓存旁路攻击构成了重大挑战。具体来说:
- 缓存驱逐:嵌入矩阵的巨大尺寸导致缓存行快速周转,增加了错过监控令牌缓存命中的可能性。
-
- 可扩展性权衡:监控更广泛的令牌范围会增加潜在词汇表泄露的可能性,但也会增加因驱逐而错过缓存命中的风险。相反,专注于较少的令牌可以提高检测可靠性,但限制了攻击的范围。
-
- 高维度:令牌在嵌入向量中的密集表示使得基于缓存访问模式区分令牌变得复杂。
4.1 检测模型访问
为了建立检测嵌入层中内存访问的基础,我们开始通过复制[24]中的Flush+Reload旁路方法。这些初步实验的目标是测量在GGUF(GPT生成的统一格式)文件中访问特定地址时缓存命中和缓存未命中之间的延迟差异。这种校准步骤对于区分后续涉及令牌泄露实验中的缓存状态非常重要。
我们使用Intel指令集中的clflush指令明确地从缓存中刷新特定内存地址。通过随后访问这些已刷新的地址,我们使用高分辨率RDTSC计时寄存器测量访问延迟。这些测量提供了缓存命中(地址保留在缓存中)和缓存未命中(地址从缓存中驱逐)之间的清晰区别。
我们的实验产生了两种不同的访问时间分布,分别对应缓存命中和缓存未命中。缓存命中始终表现出比缓存未命中显著更低的延迟,使我们能够定义一个可靠的阈值来区分这两种状态。
为了最小化误报,一个捕捉99%缓存命中延迟加上一个标准差的阈值可能是一个不错的选择。这一选择确保阈值牢固地位于两个分布之间,有效消除了重叠,允许准确检测缓存状态而不发生误分类。
图2中的图表说明了缓存命中和未命中之间的延迟分布以及选定的阈值。这一阈值优化使我们在校准实验中能够稳健地检测缓存命中。
4.2 检测内存访问时的噪声和核心亲和力
在这个研究阶段,我们考察了在监控GGUF文件中特定位置的缓存命中时引入的噪声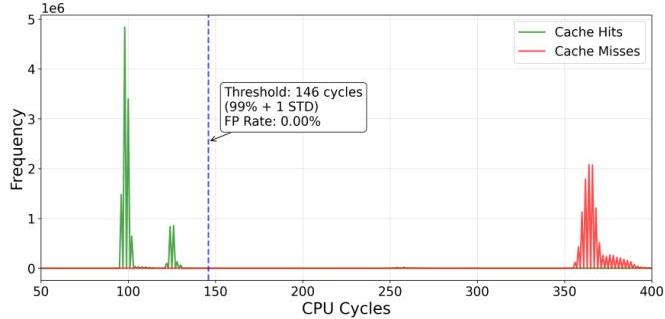
图2:校准实验展示缓存命中(100周期)与缓存未命中(370周期)之间的时间差异
我们运行了两个单独的过程:一个主动从GGUF文件内的特定内存地址读取,另一个使用Flush+Reload监控该地址周围的缓存命中。请注意,我们尚未引入推理,或实际运行模型——我们只是从另一个进程读取模型文件中的字节。目标是评估系统噪声(如预取器活动)的影响,并探讨进程分配到具有不同程度缓存共享的核心时的行为差异。
考虑了两种核心亲和力配置:
- 兄弟核心:进程放置在共享L2和L3缓存但具有独立L1缓存的兄弟核心上。
-
- 同一核心:两个进程都在同一核心上运行,共享L1、L2和L3缓存。
通过在这些配置中监控延迟分布,我们寻求识别观察到的缓存命中中的模式和噪声源。
- 同一核心:两个进程都在同一核心上运行,共享L1、L2和L3缓存。
兄弟核心上的结果。当进程在兄弟核心上运行时,我们观察到缓存命中主要集中在(但不在直接访问的地址上),如图3所示。这一结果表明,虽然监控的地址没有被兄弟核心明确重新加载到缓存中,但共享的L2和L3缓存促成了附近的地址命中,可能是受到了推测执行或预取机制的影响。
观察到的缓存命中遵循集中于目标地址附近(但并非完全在目标地址上)的分布。这种行为表明,当进程仅共享较高层级的缓存时,缓存访问检测周围存在一定噪声。
同一核心上的结果。当两个进程放在同一核心上时,模式发生了变化,如图4所示。缓存命中既发生在实际访问的精确内存地址上,也发生在周围的地址上。有趣的是,这种分布在兄弟核心配置中填补了观察到的间隙,表明L1缓存的更细粒度访问模式增强了内存访问的检测。几乎完美的缓存命中与实际访问的对齐确认了在相同核心上运行两个进程提供了一种更精确的检测内存活动的机制。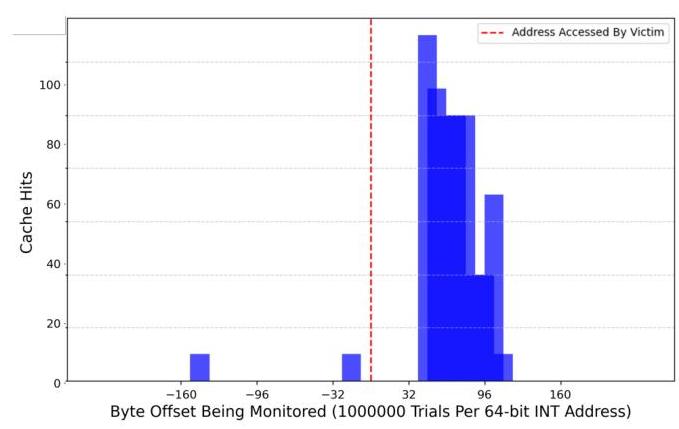
图3:通过Flush+Reload检测由兄弟核心上另一个进程访问的字节地址周围的缓存命中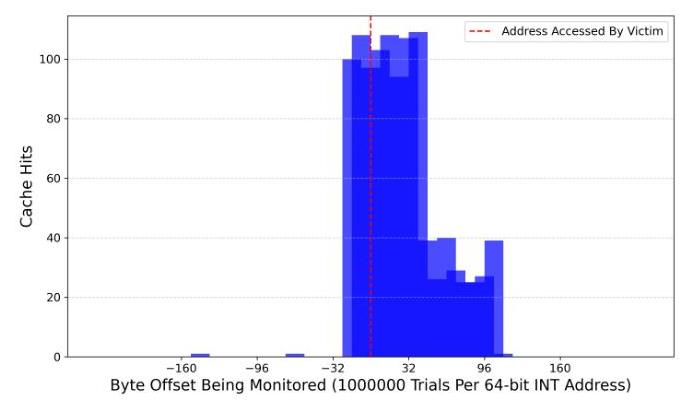
图4:通过Flush+Reload检测由同一核心上另一个进程访问的字节地址周围的缓存命中
4.3 在哪里监控GGUF以泄露令牌
GGUF文件包含四个不同的部分:标题、元数据&张量信息、嵌入层和其他张量
GGUF文件的元数据&张量信息部分提供了定位和监控特定令牌所需的信息。这部分除了其他内容外,还包含嵌入层的字节偏移量、嵌入层的大小以及模型中的总令牌数。为了确定特定嵌入向量对应的字节偏移量,我们使用以下公式:
Offset token =_{\text {token }}=token = Offset KaTeX parse error: Expected 'EOF', got '_' at position 19: …text {embedding_̲layer }}+( Token ID ×\times× Size token _{\text {token }}token )
-
Offset KaTeX parse error: Expected 'EOF', got '_' at position 19: …text {embedding_̲layer: }} 嵌入层的字节偏移量,从元数据&张量信息部分获取。
-
- Size token _{\text {token }}token : 每个令牌的嵌入向量大小,计算如下:
KaTeX parse error: Expected 'EOF', got '_' at position 72: …text {embedding_̲layer }}}{\text…
- Size token _{\text {token }}token : 每个令牌的嵌入向量大小,计算如下:
-
Token ID: 令牌的唯一标识符。
这个公式允许识别模型中任意给定令牌对应的内存位置。通过在GGUF文件中监控这些计算出的偏移量,攻击者可以在模型处理令牌时观察到特定嵌入向量的缓存命中。为了演示这种效果,我们尝试通过Meta的Llama模型仅使用一个令牌进行提示,并监控我们预期嵌入向量所在位置及其附近位置的缓存命中。正如第4.2节所述,当使用特定令牌时,我们预计嵌入向量周围会有缓存命中的分布。我们对5个令牌重复了这个实验,并将结果绘制成图5。你可以清楚地看到不同令牌之间的缓存命中差异,这表明据我们所知,这是首个通过CPU缓存旁路信道泄露LLM令牌的效果。
4.4 多令牌轮询监控
虽然监控单个令牌偏移量直接展示了Flush+Reload技术,但实际攻击通常需要跟踪多个令牌以推断更丰富的语言信息。将我们的方法扩展到大量令牌时,考虑到LLM词汇表的庞大和缓存行被驱逐前的有限时间窗口,这带来了可扩展性和时间方面的考虑。
为了并行化令牌监控,我们首先从模型的词汇表中识别感兴趣的令牌ID。一旦我们
有了这些ID,我们将每个ID转换为其在嵌入层中的相应偏移量。这个转换过程与第4.3节中描述的相同。这产生了一份绝对偏移量列表,每个待监控的令牌对应一个。
有了这些偏移量集合后,我们的攻击者进程固定在运行LLM的CPU的一个兄弟核心上,以快速轮询的方式迭代每个目标令牌的内存位置。对于每个令牌偏移量,攻击者执行以下步骤:
- 访问:加载GGUF文件中计算出的偏移量处的缓存行。
-
- 时间测量:使用高精度计时源(如RDTSC指令)记录完成此加载所需的时间。
-
- 刷新:立即使用clflush刷新相同的缓存行,确保该行从所有层级的缓存层次结构中驱逐。
-
- 记录:如果令牌访问在指定的时间约束内,尽可能减少开销地记录缓存命中。
-
- 下一个令牌:继续轮询到下一个令牌以执行Flush+Reload。
- 如果记录的访问时间低于预定阈值(例如200个CPU周期),攻击者得出结论认为该令牌最近被模型访问,因此在缓存中“命中”。该命中随后被记录下来,将低延迟读取映射到相应的令牌ID。为了在检测事件期间最小化开销,我们在监控循环完成后才进行大量处理或磁盘I/O。这种策略降低了错过其他令牌的后续缓存命中的风险,同时仍然能够稳健地重建令牌。
在令牌命中期间的开销 我们定义令牌命中开销为从检测到令牌到轮询Flush+Reload可以继续之间的时间。例如,如果检测到一个令牌,该令牌可以在我们继续监控更多令牌之前写入文件——但由于写入文件在Flush+Reload的上下文中需要相当长的时间,攻击者在写入文件时可能会错过后续令牌。
或者,攻击者可能希望根据收到的令牌更改她正在监控的令牌。在这种情况下,在理解上下文并选择一组新的监控令牌之间需要花费非可忽略的计算时间,并且在选择时间可能会错过令牌。因此,我们想要量化你可能错过多少令牌与令牌之间的开销计算时间的关系。
我们使用CUDA后端在Nvidia 2070S GPU上运行了一个小型的100M参数模型,并针对给定提示符轮询监控了200个令牌。需要注意的是,我们根据提示符输出中能看到的内容选择了这200个令牌,因此假设在轮询中没有错过任何令牌,它们都将被攻击者捕获。我们跟踪了每次试验中接收到的200个令牌的数量,并记录了响应的准确性与开销的关系。如图6所示的结果表明,每次令牌命中期间每增加100微秒的开销,大约会有5%的令牌泄露损失。这可能在不同模型或平台之间有所变化,但最终它驱动了我们尽量减少开销以最大化令牌泄露的决定。
最大轮询令牌数 找到覆盖面(监控的令牌广度)和响应性(在令牌出现时捕获它的可能性)之间的正确平衡是至关重要的。极端情况下,仅监控少量令牌——比如只有五个——可以让攻击者快速循环通过它们,减少错过缓存命中的可能性。如果这五个令牌中有任何一个是由模型产生的,它更有可能被检测到,因为轮询循环可以在嵌入向量从缓存中驱逐之前返回到每个令牌的偏移量。然而,如此狭窄的关注极大地限制了可以泄露的信息范围。由于观察到的令牌很少,即使检测率接近完美,对受害者秘密提示或文本的洞察也非常有限。
另一方面,将监控集扩展到一千个令牌或更多可以改善覆盖面,提供泄露更广泛语言内容的潜力。然而,这种更大的覆盖面是有代价的。对于大量令牌,轮询扫描需要显著更长的时间,增加返回到任何给定令牌偏移量所需的时间。如果模型在包含1000个令牌的列表中的第10个偏移量处访问一个令牌,但攻击者当前正在监控第22个偏移量,那么循环必须遍历近一千个令牌才能返回到第10个偏移量。到那时,原始令牌的数据很可能已经
聊天交互涉及敏感数据的系列示例
用户:请编写一个脚本来检查我的比特币钱包价值。
我的API密钥是:“b81132e3-2129-42e3-91f4d8b64c93fbec”。请只给我代码。
Llama:
import requests
def get_bitcoin_balance():
api_key =
“b81132e3-2129-42e3
-91f4-d8b64c93fbec”
response = requests.get(
f"https://pro-api.coin
gecko.com/api/v3/coins/bitcoin?
图7:聊天交互示例,显示提示中可能共享的敏感信息。
从缓存中驱逐,导致未检测到。监控集越大,某个给定令牌访问未被检测到的概率越高。
这种权衡表明存在一个最佳集大小——足够大的令牌数量以捕捉有意义的语言细节,但又不足以超过缓存保留窗口。为了找出这个最佳点,我们使用已知的提示输出进行了实验,并改变了监控的令牌数量。通过尝试不同的集大小并测量成功泄露的令牌比例,我们确定了大约200个令牌的最佳点。在这种规模下,攻击者可以快速循环监控的令牌,以检测大部分访问的令牌,同时仍然覆盖足够的词汇表部分以产生信息泄露。
实际上,最佳监控令牌数量将取决于具体模型的嵌入大小、系统的缓存特性以及令牌生成的时间模式等因素。然而,我们的研究结果表明,无论过于关注少数令牌还是试图跟踪数千个令牌都不是理想的。相反,适度的集大小达到了正确的平衡,通过结合覆盖面和及时检测来最大化泄露。
5 泄露API密钥
在现代开发工作流中,终端用户经常将API密钥或其他凭据直接嵌入到他们的LLM提示中,信任模型生成相应的代码片段或集成到他们的应用程序中的指令。不幸的是,这种做法带来了关键的漏洞。即使在严格的软件隔离下,利用“泄露机密”的旁路攻击者也可以在生成过程中恢复这些敏感令牌,因为他们出现在共享硬件内存中。如图7所示,我们的演示表明,“泄露机密”可以揭示嵌入在LLM生成代码片段中的完整API密钥,使攻击者轻松假扮受害者的身份在下游服务中。
UUID中的随机性和熵。通用唯一标识符(UUID),特别是符合RFC 4122 [10]中定义版本的那些,旨在统计上跨时空唯一。典型的UUID,表示为36字符字符串(包括4个连字符),例如b81132e3-2129-42e3-91f4-d8b64c93fbec,由随机位和固定位(取决于UUID版本)组合而成,作为原始二进制数据解释时提供极低的碰撞概率和高熵。尽管两个独立生成的UUID碰撞的概率天文数字般小,但从旁路角度来看,这种唯一性和随机性显著改变了代表UUID的令牌分布。
LLM分词器主要在自然语言上训练,结果是分词分布反映了常见的单词和语言模式。像UUID这样的高熵字符串不符合标准的自然语言分布,因此被分成较少见的令牌序列。例如,十六进制字符字符串b81132e3可能被分词成几个低频令牌,而不是几个常见的令牌。这种属性实际上增强了侧信道泄露:攻击者只需要轮询监控一组稀疏的候选令牌,而不是一个大的常见子字符串或单词词汇表。UUID的特殊分词有效地减少了搜索空间,一旦攻击者识别出一些与UUID不常见子字符串相对应的罕见令牌。
与自然语言令牌的对比。在自然语言响应中,令牌通常代表部分单词、标点符号或模型训练数据中频繁遇到的常见序列。监控大量词汇既耗时又更容易导致缓存驱逐。然而,当目标是一个随机的、高熵密钥时,攻击者可以通过专注于不太可能出现在日常文本中的令牌来优化其监控策略。这些令牌由于使用频率低,在模型访问它们时更有可能在特定偏移量处命中缓存。这种概率偏差简化了攻击者的挑战:与其监控一个广泛的可能令牌(如Python代码中的def、and、or、import等单词),攻击者可以专注于映射到不太常见令牌的一组较小的内存位置。因此,识别UUID令牌的存在更为直接,而在模型生成代码时提取它们显著更高效且可靠。
凭据泄露的影响。泄露随机、高熵凭据(如基于UUID的API密钥)的能力突显了严重的隐私和安全风险。这些密钥中的字符随机分布,曾被认为对暴力破解攻击提供自然保护,但在面对直接的硬件泄露时却成为LLM的隐患。恢复API密钥的攻击者可以冒充用户或服务,可能获得对云资源、数据库、金融交易或其他由暴露的API端点管理的敏感操作的未经授权访问。
这种威胁不仅限于UUID。任何类似的高熵秘密——例如密码、SSH密钥或嵌入LLM提示中的加密nonce——都可能同样易受攻击。使用LLM进行代码生成和指令编写带来的便利性必须与这些敏感信息可能通过硬件级侧信道无意中泄露的风险相平衡。
5.1 令牌监控
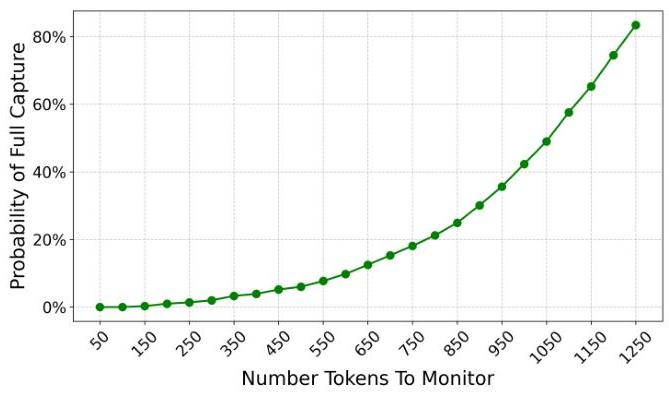
图8:给定一定数量的监控令牌时捕获整个API密钥的概率,在128K令牌模型上使用Spill The Beans
由于API密钥具有高熵,我们需要监控更少的整体令牌来捕获整个密钥,相比捕获完整的英文文本。为了确定我们需要监控的令牌数量的近似值,我们根据GGUF模型生成了10万个随机UUID,并对其进行了分词。然后我们又生成了一组新的10万个UUID,并确定需要监控多少令牌
(按频率排序)以高概率泄露整个密钥。基于这些测试,在图8中清晰地显示出监控令牌数量与捕获高熵凭据(如基于UUID的API密钥)所有令牌的概率之间的关系。
尽管在1250个令牌时完全捕获的概率为83.4%已经显著,但一个警觉的攻击者可以进一步优化其策略。一种潜在的策略是利用高熵密钥或凭据在长时间交互过程中多次重复的趋势。例如,用户可能会将他们的API密钥粘贴到提示中,要求LLM将其集成到代码片段中,稍后又要求LLM重构代码,这将导致API密钥的第二次泄露。这种重复自然增加了攻击者观察和完全重建密钥的总机会。
一种实际的攻击策略可以如下进行:最初,攻击者监控一组广泛的令牌(例如前250个,提供86.3%的平均覆盖率和1.4%的完全捕获概率)。即使第一次出现的API密钥没有产生完整的重建,攻击者也能获得有价值的情报。未检测到的令牌现在已知属于凭证较少使用的分词化子字符串。在密钥的后续出现中,攻击者可以剔除已经捕获的子集,并轮换进入来自嵌入空间略微不同区域的令牌——那些之前未监控的不太常见的令牌。这种自适应方法利用了许多用户-模型交换的迭代性质。每次密钥的重复都提供了改进监控集的新机会。最初,攻击者可能不知道API密钥中最难检测的是哪些令牌。然而,一旦获得部分信息,攻击者可以在下一次尝试中战略性地从不同的令牌选择中采样,逐步填补缺失的部分,直到恢复整个密钥。随着对话中凭证的多次出现,这种轮换策略以高概率收敛到完整的令牌集。值得注意的是,这种方法不要求攻击者事先了解内容。攻击者只需在密钥首次曝光期间监控嵌入空间的一组广泛令牌。已识别的令牌将从搜索空间中“划掉”。在下一次曝光时,攻击者用之前未观察到的令牌替换被监控的令牌。在两到三次曝光中重复这一过程,可以迅速将完全捕获概率推近100%。为了实现这种批处理方法,我们需要确定在轮询准确性损失的情况下可以监控的最大令牌数。
5.2 API密钥泄露结果
为了评估我们提出的攻击策略的实际有效性,我们在配备Intel Comet Lake服务器CPU和NVIDIA 2070S GPU的llama.cpp基础上进行了实验。尽管我们的实验专注于llama.cpp,但这些发现适用于其他流行的前端,如ollama,因为它们都使用类似的GGUF模型后端。我们测试了各种配置,监控不同数量的令牌,并测量理论预测和实际所需的用户-模型交互次数,以完全重建基于UUID的API密钥。
我们在每个实验开始时选择了一定数量的令牌进行监控,这些选择基于前面章节讨论的覆盖权衡。理论上的交互次数代表从令牌覆盖率的统计分析得出的估计值。实际次数反映了我们在端到端攻击场景中提取整个密钥前所需的经验用户查询和响应次数。细微的提示变化、分词差异和低级微架构定时等因素都会影响实际结果与理论预期的接近程度。
表1显示了五个实验的结果,每个实验使用了不同数量的监控令牌和相应的模型配置。随着监控令牌数量的增加,理论上在更少的交互中完全捕获的概率也会提高。我们的实验确认,通过结合精心选择的令牌集大小、自适应旋转策略和多次提示曝光,攻击者可以在少量交互中可靠地泄露整个API密钥。
| 交互次数 | |||
|---|---|---|---|
| 集合大小 | 泄露 50%\mathbf{5 0 \%}50% 所需 | 泄露 80%\mathbf{8 0 \%}80% 所需 | 泄露 100%\mathbf{1 0 0 \%}100% 所需 |
| 50 | 1 | 7 | 66 |
| 100 | 1 | 4 | 33 |
| 200 | 1 | 1 | 18 |
| 250 | 1 | 1 | 15 |
| 300 | 1 | 1 | 12 |
| 350 | 1 | 2 | 12 |
| 400 | 1 | 2 | 9 |
表1:攻击者监控令牌数量与泄露完整API密钥不同百分比所需交互次数的关系结果。
结果表明,虽然完美的单次恢复可能不太可能,但平均可以泄露约80%-90%的API密钥。通过结合监控覆盖率、重复提示曝光和动态令牌选择,可以形成一种高度有效的泄露策略。即使在基于UUID的API密钥这样的高熵领域,现代硬件和推理管道也提供了许多机会来拼凑敏感信息,最终证实了缓存侧信道攻击对LLM部署的强大效力。
6 泄露纯英语
虽然我们的初步实验集中在泄露高熵令牌如API密钥上,接下来我们考察了一个仅交换纯英语文本与LLM的情况。基本前提是,尽管攻击者对用户的查询或响应内容缺乏先验知识,仍然可以通过选择性监控最常用的单词来推断出大量生成的英语令牌。
构建监控集。为了构建一个有代表性的令牌集,我们利用了康奈尔电影对话语料库并提取原始剧本行进行频率分析。通过根据单词在整个数据集中出现的频率进行排序,我们识别出了1000个最常见的令牌,主要由冠词、连词、介词和其他常见英语单词组成(例如and、the、it、to)。重要的是,LLM分词通常将单词拆分为子单词单元,因此我们将分析中的每个高级单词与其对应的GGUF令牌ID对齐,以确保监控集对目标模型准确无误。这种对高频英语令牌的依赖直接与众所周知的齐夫定律相关,该定律描述了自然语言中单词频率的逆幂律分布。具体来说,齐夫定律认为第n个最常见的单词的频率大致与1/n成正比。有趣的是,即使是随机文本生成也可以表现出类似的排名-频率关系[12],其中单词长度转换为其排名有效地将指数分布拉伸为幂律。这一现象意味着少数几个单词往往构成大量书面材料的主要部分。因此,关注1000个最常见的令牌捕捉到了大量可能的英语文本,增强了通过Flush+Reload在实际侧信道攻击情景中监控这些令牌的可行性。
使用Quora问题的攻击设置。然后我们选择了几个Quora问题集中的随机问题,以模拟现实的用户查询(例如,“学习Python的最佳方法是什么?”)。这些问题作为单一提示传递给通过llama.cpp的Meta-Llama-3.1-8B-Instruct-Q8_0.gguf模型。同时,另一个固定在兄弟核心上的攻击者进程以轮询方式对对应于1000个目标令牌的嵌入层偏移量执行Flush+Reload。假设没有任何关于查询内容的额外上下文或先验知识。
可变令牌集大小和单次约束。为了评估监控集大小对泄露效果的影响,我们多次重复实验,将令牌数量从50增加到650。对于每次试验,轮询扫描速率和时间阈值保持不变,允许公平比较在每种条件下成功检测到的令牌数量(以百分比表示)。与我们的API密钥分析不同,这些实验仅为单次:提示只提供一次,模型响应生成,不考虑重复或多回合对话。
6.1 结果与分析
图9展示了根据监控的令牌数量成功泄露的LLM响应中令牌的百分比。值得注意的是,超过大约150-250个令牌增加监控集大小回报递减。随着轮询循环变长,攻击者进程在返回到特定令牌偏移量时会遇到更大的延迟。这种延迟增加导致共享缓存中的驱逐率更高,导致攻击者错过一部分令牌访问。此外,由于模型的响应包含频繁和不频繁的令牌混合,专注于前150-250个英语令牌就足以捕捉到用户提问和随后简短回答的大部分内容。监控较小的集合(例如50个)会遗漏更多内容,而扩展超过250个会产生过多的开销和缓存未命中。
单次攻击与多次攻击。如果LLM在对话的多个回合中重用或重复内容,攻击者可以通过在每个回合中轮换不同的令牌子集来弥补覆盖面限制,如第5节所述。因此,尽管单次攻击已经捕获了大量频繁的令牌,多次曝光会放大攻击者重建更广泛词汇的能力。实际上,许多用户查询涉及澄清或后续问题,从而在更长的对话中创造了多次泄露令牌的机会。
对用户隐私的影响。我们的研究结果证实,天真的假设——只有“随机数据”才对攻击者感兴趣——并不成立。即使普通的英语查询也可能揭示私人或敏感的背景信息,例如个人细节、医疗信息或公司机密,当大量令牌被推断出来时。这种暴露突显了即使只交换英语数据,也需要采用强大的微架构防御或混淆策略的重要性。
7 进一步改进
本文中概述的方法虽然通过Flush+Reload成功泄露了相当比例的令牌,但可以通过几种方式进行优化以进一步提高泄露覆盖率和检测可靠性。我们简要介绍了以下三个有希望的方向。
替代缓存侧信道。尽管Flush+Reload在共享内存条件下已被证明有效且简单明了,但其他微架构攻击如Prime+Probe和Prime+Scope [8, 17]可能增强对受害者访问的长期可见性。例如,在Prime+Probe中,攻击者用自己的数据填充缓存集,然后测量探测该集所需的时间,无需共享页面即可检测受害者访问导致的驱逐。Prime+Scope将探测的粒度缩小到单独的方式或切片,进一步提高信号质量。这两种方法都可以潜在地提供更稳定的观察,并允许在不冒频繁驱逐风险的情况下监控更大范围的目标令牌。然而,这些策略需要更深入地了解缓存索引和关联参数,增加了攻击的复杂性。此外,考虑到CPU型号间的硬件差异,大规模实施Prime+Probe或Prime+Scope可能会变得复杂。
上下文感知的旋转监控器。第二种改进途径是一种自适应方案,其中监控的令牌集根据从受害者文本中已获取的部分信息而改变。作为一个简单的例子,检测到句界标记(如句号)可能会触发攻击者转向句子开头可能出现的令牌,如大写字母单词。更先进的机制可以使用概率语言模型或马尔可夫链来动态预测哪些令牌具有最高出现的可能性,随后用上下文中更可能的令牌替换很少使用的监控器。尽管这种自适应性需要针对每个检测到的令牌进行额外计算,但如果能仔细平衡附加开销,它可能会显著提高恢复的令牌比例。
使用语言模型进行后处理。最后,即使攻击者错过了一些令牌或获得了部分损坏的序列,现代LLM本身也可以用来执行自动文本重建。例如,在收集所有泄露的令牌并将未知或不确定的位置标记为占位符符号后,可以要求LLM或更小的专业模型“填补空白”,使用已知上下文来插入最有可能缺失的令牌。后续的细化步骤可以根据相对可能性进一步对每个空白令牌的备选答案进行排名,从而提高整体重建的质量。尽管这种后处理增加了计算成本,但它是在离线状态下进行的,因此不会干扰实时侧信道测量。这种策略可以显著提高泄露概率,特别是在原始文本遵循语法丰富结构或包含可识别语义线索时。
8 对策
缓解LLM的缓存侧信道攻击需要硬件、系统和应用级别的综合策略。这些策略旨在减少共享资源的竞争、掩盖内存访问模式并限制攻击者将缓存命中与令牌生成事件相关联的能力。
时间和空间随机化。在LLM的内存访问模式中引入噪声和不可预测性可以大大提高攻击者的门槛。例如,在推理过程中随机访问未使用的嵌入层段破坏了观察到的缓存命中与实际令牌使用之间的相关性。通过定期注入对当前模型未生成的令牌的随机读取操作,LLM可以有效地淹没攻击者依赖的信号。另一种方法是为LLM向量访问实施“恒定时间”策略,类似于在加密库中使用的方法,其中统一的访问模式阻止了时间分析。还需要更多的研究来确定这是否是一个实用的方法,因为额外的访问会导致推理延迟。确保攻击者和受害进程不共享包含模型参数的内存页是另一种强有力的防御措施,但可能会对性能造成损害。在虚拟机监视器或容器级别强制进程隔离,并避免在不受信任的租户之间共享库和模型,可以防止跨进程的Flush+Reload攻击[26]。
基于硬件的隔离和分区。一种有效的缓解方法是使用缓存分区技术,
如英特尔的缓存分配技术(CAT)[14],或类似的硬件隔离功能,限制攻击者对受害者缓存行的可见性。通过按进程或虚拟机隔离缓存方式,这些机制确保攻击者观察到的驱逐和时间差异不会泄露有意义的信息。此外,新兴的硬件具有严格的时空分区功能,可以帮助防止跨核或跨虚拟机的干扰[22]。像Flush+Reload这样的缓存侧信道攻击通常依赖于页面去重来创建攻击者和受害者之间的共享内存页[5]。禁用内核相同页合并或去重功能消除了这种机会。尽管这可能会增加内存使用,但在多租户环境如公共云中,安全态势的改善将是显著的。然而,由于性能损失,这通常不被推荐。
9 结论
本工作介绍了Spill The Beans,这是对最先进的大型语言模型仍容易受到硬件级侧信道攻击的一个实际演示。通过嵌入层中的缓存时间变化,我们展示了攻击者可以恢复LLM使用的令牌,包括敏感密钥和高熵凭据。我们的实验强调了仔细监控和战略性选择令牌如何使对手克服缓存驱逐和时间限制,最终实现从实时推理会话中提取私有数据,如API密钥。通过广泛的试验,我们验证了这种方法在LLM上的可行性,并探讨了调整监控令牌数量如何影响泄露数据的广度和检测的可靠性。除了仅仅暴露漏洞外,我们的研究还贡献了对模型复杂性、时间粒度和缓存资源共享之间基本张力的更好理解。我们提醒注意需要更强的防御措施来对抗微架构威胁,并强调通常建议的缓解措施——如禁用页面去重或执行随机未使用令牌访问——可能是必要的,以在多租户环境中保护用户隐私。Spill The Beans提醒我们,现代硬件设计和AI模型的交汇引入了新的和微妙的风险。为了保护机密互动和私人知识产权,社区必须追求全面的硬件-软件协同设计解决方案、隔离技术和适应性混淆策略,以有效应对不断演变的微架构侧信道景观。
10 免责声明
安德鲁·阿迪莱塔与MITRE公司的关系仅用于身份识别目的,无意传达或暗示MITRE对作者立场、意见或观点的认同或支持。所有参考均为公共领域。
11 伦理考量
我们采取措施确保所有实验均安全进行,并征得所述系统用户的同意。我们计划负责任地向英特尔和英伟达披露该漏洞。
12 开放科学政策
我们计划在作者雇主允许的情况下发布代码、数据和图表。
参考文献
[1] Endre Bangerter, David Gullasch 和 Stephan Krenn. 缓存游戏——将基于访问的缓存攻击AES带到实践中。密码学电子印刷档案,论文2010/594,2010年。
[2] Yoshua Bengio, Réjean Ducharme 和 Pascal Vincent. 神经概率语言模型。神经信息处理系统进展,13,2000年。
[3] David Brumley 和 Dan Boneh. 远程时间攻击是可行的。计算机网络,48(5):701-716,2005年。
[4] Herbert Bos Erik Bosman, Kaveh Razavi 和 Cristiano Giuffrida. Dedup est machina: 内存去重作为一种高级利用向量。IEEE第37届安全与隐私研讨会(Symposium on Security and Privacy)论文集,美国加州圣何塞,2016年5月。IEEE出版社。
[5] Daniel Gruss, David Bidner 和 Stefan Mangard. 沙盒JavaScript中的实际内存去重攻击。计算机安全-ESORICS 2015: 第20届欧洲计算机安全研究研讨会论文集,奥地利维也纳,2015年9月21-25日,第一部分20篇,第108-122页。Springer出版社,2015年。
[6] Mark Harris. CUDA初学者的统一内存。Nvidia技术博客,2017年。
[7] John L. Hennessy David A. Patterson. 计算机体系结构定量方法。2012年。
[8] Mehmet Kayaalp, Nael Abu-Ghazaleh, Dmitry Ponomarev 和 Aamer Jaleel. 最后一级缓存的高分辨率侧信道攻击。设计自动化会议第53届年度会议论文集,第1-6页,2016年。
[9] Paul C Kocher. 实现Diffie-Hellman、RSA、DSS及其他系统的计时攻击。密码学进展-CRYPTO’96: 第16届国际密码学会议论文集,美国加利福尼亚州圣巴巴拉,1996年8月18-22日,第16卷,第104-113页。Springer出版社,1996年。
[10] P Leach, Michael Mealling 和 Rich Salz. RFC 4122: 通用唯一标识符(UUID)URN命名空间,2005年。
[11] Qinfeng Li, Yangfan Xie, Tianyu Du, Zhiqiang Shen, Zhenghan Qin, Hao Peng, Xinkui Zhao, Xianwei Zhu, Jianwei Yin 和 Xuhong Zhang. Coreguard: 在边缘部署中防范模型窃取的LLMs基础能力保护。arXiv预印本arXiv:2410.13903,2024年。
[12] Wentian Li. 随机文本展示类似齐夫定律的词频分布。IEEE信息理论汇刊,38(6):1842-1845,1992年。
[13] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado 和 Jeff Dean. 单词和短语的分布式表示及其组合性。神经信息处理系统进展,26,2013年。
[14] Khang T Nguyen. 英特尔®至强®处理器E5 v4系列的缓存分配技术简介,2016年。
[15] NVIDIA. Nvidia CUDA工具包8.0.61 Windows、Linux和Mac OS发行说明。Nvidia开发者网站,2017年。
[16] Dag Arne Osvik, Adi Shamir 和 Eran Tromer. 缓存攻击与对策:AES案例。密码学专题-CT-RSA 2006: RSA会议2006年密码学家论坛论文集,美国加州圣何塞,2005年2月13-17日。论文集,第1-20页。Springer出版社,2006年。
[17] Antoon Purnal, Furkan Turan 和 Ingrid Verbauwhede. Prime+ Scope: 克服高精度缓存竞争攻击的观察者效应。ACM SIGSAC计算机和通信安全会议论文集,第2906-2920页,2021年。
[18] Linke Song, Zixuan Pang, Wenhao Wang, Zihao Wang, XiaoFeng Wang, Hongbo Chen, Wei Song, Yier Jin, Dan Meng 和 Rui Hou. 早鸟捕漏:揭开LLM服务系统中的时间侧信道。arXiv预印本arXiv:2409.20002,2024年。
[19] Eran Tromer, Dag Arne Osvik 和 Adi Shamir. AES高效缓存攻击及对策。密码学期刊,23(1):37-71,2010年。
[20] A Vaswani. 注意就是你所需要的。神经信息处理系统进展,2017年。
[21] Carl A Waldspurger. VMware ESX服务器中的内存资源管理。ACM SIGOPS操作系统评论,36(SI):181-194,2002年。
[22] Kai Wang, Fengkai Yuan, Rui Hou, Jingqiang Lin, Zhenzhou Ji 和 Dan Meng. CacheGuard: 抵御连续攻击的安全增强型目录架构。ACM计算前沿国际会议论文集,第32-41页,2019年。
[23] Roy Weiss, Daniel Ayzenshteyn, Guy Amit 和 Yisroel Mirsky. 你的提示是什么?对AI助手的远程键盘记录攻击。arXiv预印本arXiv:2403.09751,2024年。
[24] Yuval Yarom 和 Katrina Falkner. 刷新+加载:一种高分辨率、低噪音、13级缓存侧信道攻击。第23届USENIX安全研讨会论文集,第719-732页,2014年。
[25] Tianchen Zhang, Gururaj Saileshwar 和 David Lie. 时间会告诉你:通过大型语言模型输出令牌计数的时间侧信道。arXiv预印本arXiv:2412.15431,2024年。
[26] Yinqian Zhang, Ari Juels, Michael K Reiter 和 Thomas Ristenpart. 跨VM侧信道及其用于提取私钥的用途。ACM计算机和通信安全会议论文集,第305-316页。ACM出版社,2012年。
[27] Xinyao Zheng, Husheng Han, Shangyi Shi, Qiyan Fang, Zidong Du, Qi Guo 和 Xing Hu. InputSnatch: 通过时间侧信道攻击窃取1LM服务输入。arXiv预印本arXiv:2411.18191,2024年。
参考论文:https://arxiv.org/pdf/2505.00817

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)