LLM基础架构-硬件综述
整理了大语言模型对于硬件方面的诉求和硬件各个部件指标的梳理归纳总结。希望从硬件的各个参数指标对于不同场景下的大语言模型的影响。
一、背景介绍
近年来,大语言模型(LLM)取得了突破性进展,其强大的自然语言理解、生成、问答和代码完成等能力,正在深刻改变从科研到工业的各个领域。LLM的参数规模经历了从数百万到数万亿的指数级增长,例如GPT-1的参数量不足1.2亿,而GPT-3则达到了1750亿,GPT-4更是据估计拥有约1.8万亿参数。这种规模的扩张带来了模型能力的“涌现”,但也对计算能力提出了前所未有的渴求。LLM的快速发展不仅是算法创新的结果,更是硬件算力与模型规模相互促进、螺旋式上升的体现。也进一步推动了专用AI芯片的发展
二、训练和推理对硬件的需求
2.1 训练流程及其对硬件的要求
LLM的训练通常包括数据处理、模型配置、模型训练、评估与微调等阶段。
-
2.1.1 数据处理与模型配置 LLM的训练始于大规模数据集的收集、清洗、预处理和Token化。这些数据集可能来源于书籍、文章、网页内容和开源数据集等多种渠道。数据预处理的效率直接影响整体训练周期和成本。虽然这一阶段对AI芯片的峰值算力要求不如模型训练阶段那么极致,但它需要芯片具备良好的通用计算能力和高I/O带宽,以快速处理和加载海量数据。模型配置阶段则涉及Transformer架构参数(如层数、注意力头数)和各种超参数的选择与实验
-
2.1.2 模型训练 模型训练是LLM开发中计算量最大的环节。在这个阶段,模型通过处理大量文本数据,学习预测序列中的下一个词,并根据预测结果不断调整内部权重,这一过程需要重复数十亿甚至数万亿次。因此,LLM训练对AI芯片的计算能力提出了极高的要求。 为了有效缩短训练时间,并行计算策略至关重要。常见的并行技术包括:
数据并行(Data Parallelism): 将训练数据分成多个批次,分配给不同的计算单元(如GPU)并行处理,每个计算单元都拥有完整的模型副本。梯度在每个批次计算完成后进行同步。
模型并行(Model Parallelism): 当模型规模过大,无法在单个芯片内容纳时,需要将模型的不同部分(如网络层)分布到多个芯片上执行。
张量并行(Tensor Parallelism): 模型并行的一种形式,将单个网络层内的张量操作(如矩阵乘法)也切分到多个芯片上并行计算,这需要更精细的编码和配置。
流水线并行(Pipeline Parallelism): 将模型的不同层分配到不同的计算单元上,形成流水线作业,以提高硬件利用率。 在训练参数量达到万亿级别的LLM时,单颗AI芯片的算力和内存容量已远不能满足需求,必须依赖由成千上万颗芯片组成的大规模集群。此时,芯片间的互联带宽、网络拓扑结构以及支持高效并行计算的软件栈,其重要性甚至超过了单芯片的峰值算力。
-
2.1.3 模型评估与微调 预训练完成后,模型需要在测试集上进行评估,衡量其在一致性、困惑度、多任务准确性、事实性等方面的表现。根据评估结果,可能需要对模型进行微调,例如调整超参数、修改模型结构或利用特定领域数据进行额外训练。微调虽然计算量通常小于预训练,但对硬件的灵活性和快速迭代能力要求较高。因此,支持高效加载不同规模模型、快速切换任务、并且与预训练阶段有良好软硬件兼容性的芯片和软件生态系统,在微调场景中更具优势。
2.2 LLM推理流程及其对硬件的要求
LLM推理是将训练好的模型应用于实际任务,生成预测或响应的过程。其对硬件的核心需求聚焦于低延迟、高吞吐和成本效益。
-
2.2.1 推理的两个阶段:Prefill与Autoregressive Sampling LLM的推理过程通常包含两个主要阶段:
Prefill(预填充)阶段: 在此阶段,模型并行处理用户输入的整个提示(prompt)序列,计算并填充键值缓存(Key-Value Cache, KV Cache)。这一阶段的计算量与输入序列长度相关,通常是计算密集型(compute-bound)的 。
Decoding(解码)/ Autoregressive Sampling(自回归采样)阶段: 在此阶段,模型利用已填充的KV Cache,逐个生成输出序列中的token。每生成一个token,都需要访问模型权重和KV Cache。由于模型参数量巨大,这一阶段通常是访存密集型(memory-bound)的,尤其是在batch size较小的情况下。 Prefill和Decode阶段对芯片能力的侧重有所不同。Prefill阶段受益于芯片的高计算吞吐量,而Decode阶段则更依赖于高内存带宽和低访问延迟。这意味着理想的推理芯片需要在这两方面取得良好平衡,或者可以针对特定应用场景(如交互式应用侧重低延迟,离线批量处理侧重高吞吐)进行优化。
-
2.2.2 KV Cache的关键作用与管理 KV Cache在LLM推理中扮演着至关重要的角色。它存储了注意力机制在前序token计算过程中产生的键(Key)和值(Value)张量,避免了在生成每个新token时对历史序列的重复计算,从而显著提升了自回归采样阶段的效率。 KV Cache的大小与序列长度(上下文窗口)和批处理大小(batch size)成正比 。对于长序列或大批量推理任务,KV Cache可能占据大量的显存空间,甚至超过模型参数本身所需的显存。为了缓解KV Cache带来的显存压力,研究人员探索了多种优化技术,如KV Cache量化,即将KV Cache数据从FP16压缩到INT8甚至更低精度,以减少显存占用和带宽需求。
-
2.2.3 推理的关键性能指标 评估LLM推理性能的关键指标主要包括:
-
延迟(Latency):
-
Time To First Token (TTFT):从接收输入到生成第一个输出token所需的时间。TTFT主要受Prefill阶段计算效率和模型加载速度的影响,对于交互式应用(如聊天机器人)的用户体验至关重要 。
-
Time Per Output Token (TPOT) 或 Inter-Token Latency (ITL):生成后续每个token所需的时间。TPOT主要受Decode阶段的访存效率和KV Cache性能影响,决定了后续内容的生成速度 。
-
-
吞吐量(Throughput):
-
Tokens per second (TPS):每秒生成的token数量,衡量系统的整体处理能力 。
-
Queries per second (QPS):每秒处理的查询请求数量,常用于评估并发服务能力
-
-
并发用户数(Concurrency): 系统能够同时处理的用户请求数量 。
-
能效(Energy Efficiency): 通常以每焦耳生成的token数(Tokens/Joule)或每瓦特每秒生成的token数(Tokens/s/Watt)来衡量,对于大规模部署和边缘设备尤为重要
-
2.3 训练与推理需求的差异与共性
LLM的训练和推理对AI芯片硬件的需求既有显著差异,也存在一些共性。
差异性:
-
计算精度要求: 训练过程通常需要较高的计算精度(如FP32或BF16)以保证模型参数的精确更新和梯度累积的稳定性,避免训练过程中的数值溢出或下溢问题 。而推理过程对精度要求相对较低,可以使用FP16、INT8甚至FP8等低精度格式,以换取更高的计算速度和更低的显存占用 。
-
显存需求: 训练阶段需要存储模型参数、梯度、优化器状态以及中间激活值,显存需求巨大,尤其是对于大模型和较大的批处理大小(batch size)。推理阶段虽然也需要存储模型参数和KV Cache,但通常不需要存储梯度和优化器状态,因此在相同模型下,推理的显存需求通常小于训练。然而,长序列推理时,KV Cache的显存占用可能非常显著 。
-
计算吞吐与延迟敏感度: 训练过程更侧重于整体的计算吞吐量(throughput),目标是在可接受的时间内完成整个训练任务。而推理过程,特别是交互式应用,对延迟(latency)非常敏感,要求快速响应用户请求 。
-
扩展性与容错性: 大规模训练通常在包含成百上千个AI芯片的集群上进行,对系统的扩展性和容错性要求极高。推理任务的扩展性需求也存在,但通常可以通过复制多个推理实例来实现负载均衡,对单点故障的容忍度相对训练集群要高一些。
共性:
-
Transformer架构优化: 无论是训练还是推理,LLM的核心都是Transformer架构。因此,AI芯片对Transformer中关键操作(如自注意力机制、矩阵乘法)的硬件优化能力都至关重要。
-
大模型支持能力: 随着模型参数量的不断增加,训练和推理都需要AI芯片具备处理超大规模模型的能力,这包括足够的片上内存、高带宽内存以及高效的多芯片/多节点扩展能力。
-
内存带宽的重要性: 尽管侧重点不同,但训练和推理都对内存带宽有较高要求。训练时需要快速读写大量参数和梯度,推理时则需要快速加载模型权重和读写KV Cache 。
尽管训练和推理对硬件的具体侧重点不同,但两者都越来越依赖于芯片的存储能力(包括容量和带宽)和高效的片上/片间互联技术。随着模型规模的持续膨胀,“内存墙”和“功耗墙”问题日益突出 。单纯追求峰值计算性能已不足以应对挑战,“存算一体”(或近存计算)和“高效互联”成为AI芯片发展的共同趋势,旨在减少数据搬运开销,提升整体能效比
三、GPU 硬件指标
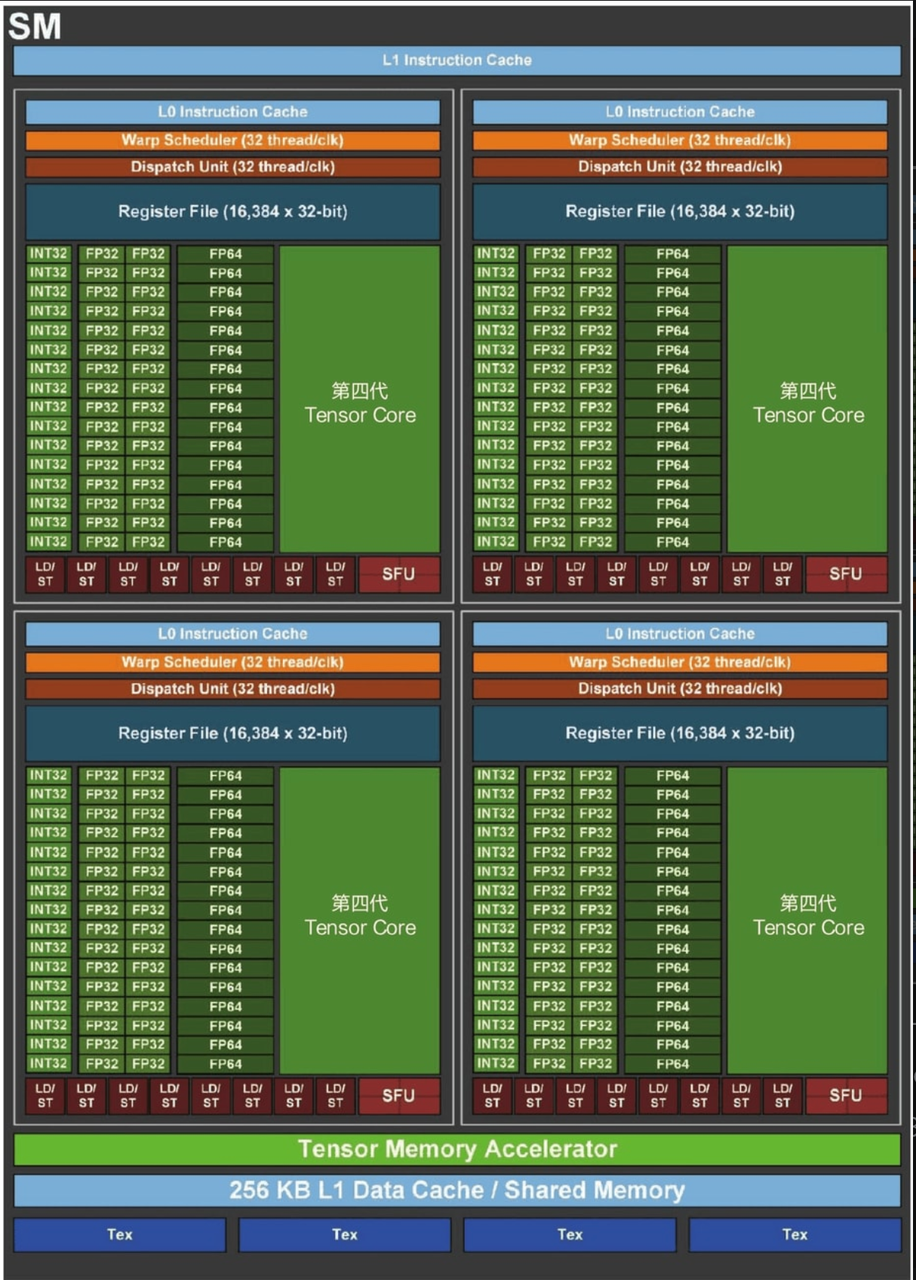
3.1 计算性能与精度
AI芯片通常会针对不同的数值精度提供专门的计算单元和优化。常见的精度格式及其在LLM中的应用包括:
-
FP32 (单精度浮点): 具有较高的动态范围和精度,传统上用于科学计算和部分深度学习模型的训练,但显存占用和计算开销较大 。
-
TF32 (TensorFloat-32): NVIDIA引入的一种格式,具有FP32的动态范围和FP16的精度,能在几乎不损失模型准确性的前提下提升计算速度 。
-
BF16 (BFloat16): 由Google提出,具有与FP32相似的动态范围,但尾数精度较低(7位尾数,8位指数)。在LLM训练中广泛应用,因其能较好地维持训练稳定性,同时减少显存占用和提升计算速度 。
-
FP16 (半精度浮点): 具有较小的动态范围(5位指数,10位尾数),在训练和推理中均有应用,能有效减少显存占用并提升计算速度,但可能面临数值溢出或下溢的风险,有时需要混合精度训练来维持模型精度 。
-
INT8 (8位整数): 主要用于推理加速,能极大降低模型大小和计算量,显著提升推理速度。但INT8量化对模型精度有一定影响,通常需要量化感知训练(QAT)或后训练量化(PTQ)技术来弥补精度损失 。
-
FP8 (8位浮点): 作为一种新兴的低精度浮点格式,FP8旨在进一步降低显存占用和计算量,同时尽可能保持浮点数的动态范围优势。FP8通常包含E4M3(4位指数,3位尾数)和E5M2(5位指数,2位尾数)两种子格式,分别适用于权重/激活和梯度
-
稀疏计算(Sparsity)支持:
许多LLM的权重和激活值具有稀疏性,即存在大量零值或接近零值。支持结构化稀疏(Structured Sparsity)计算的AI芯片,可以通过跳过对零值的乘法和加法操作,在不显著影响模型精度的情况下,提升计算效率和有效吞吐量 。例如NVIDIA的Ampere和Hopper架构GPU支持2:4的结构化稀疏,理论上可以将特定运算的性能提升一倍。评估芯片的稀疏计算能力及其配套的软件支持
3.2 内存系统
内存系统是AI芯片的另一个核心组成部分,其容量、带宽和类型直接制约着LLM的训练和推理效率。
-
内存容量 (HBM, SRAM, DDR): LLM参数量巨大,训练过程中还需要存储梯度、优化器状态和激活值,推理过程中则需要存储模型参数和KV Cache。因此,AI芯片的内存容量至关重要。
-
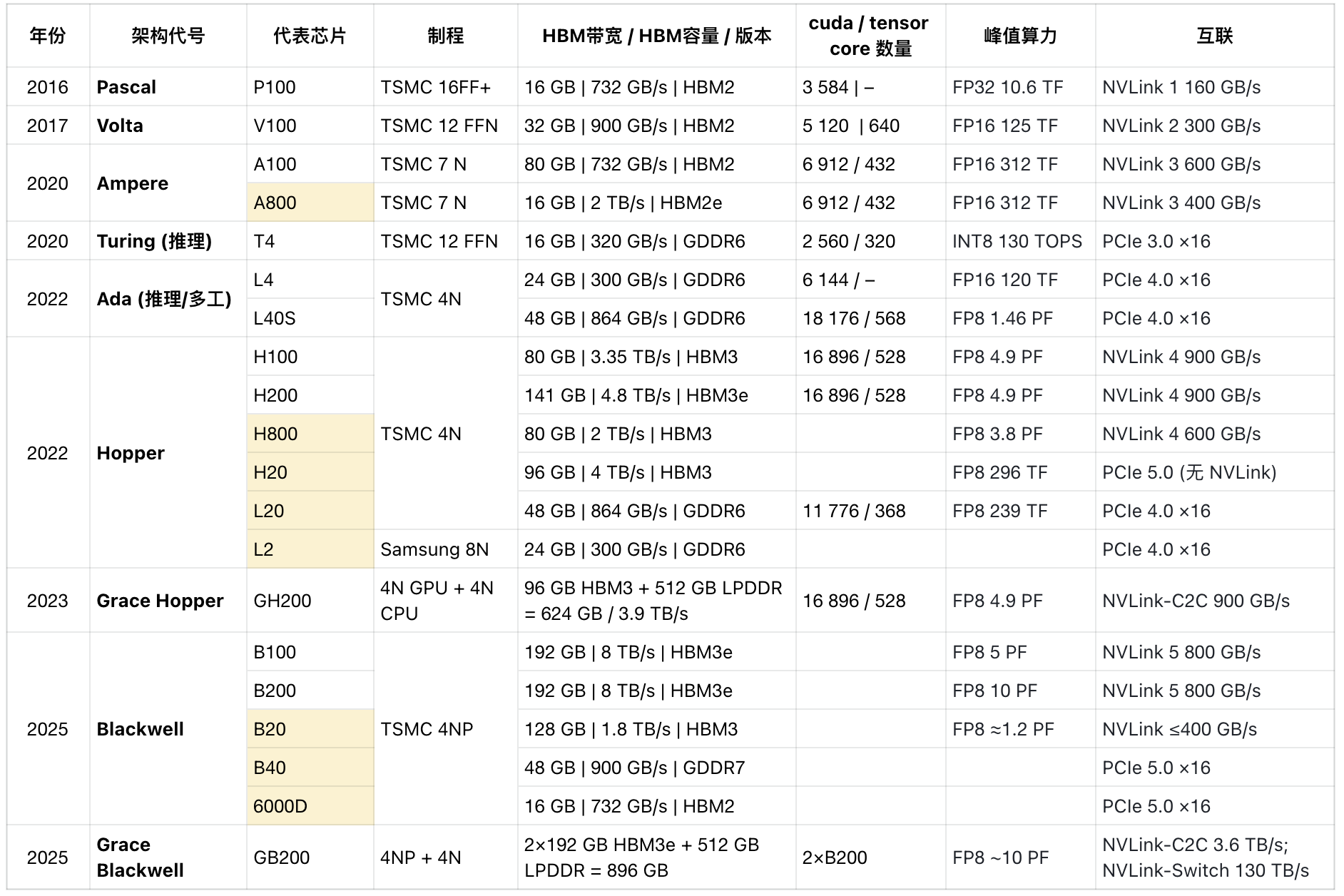
高带宽内存 (High Bandwidth Memory, HBM): HBM通过硅通孔(TSV)技术将多层DRAM芯片堆叠,并与处理器封装在同一基板上,提供了极高的内存带宽和较大的容量。HBM已成为高端AI芯片(如NVIDIA H100/H200/GB200, AMD MI300X/MI325X, Intel Gaudi 3, Google TPU v5p/Ironwood, AWS Trainium2/Inferentia2)的主流配置 。HBM的容量通常在几十GB到几百GB不等,例如NVIDIA H100 SXM提供80GB HBM3,而AMD MI300X则提供192GB HBM3 。最新的NVIDIA H200更是将HBM3e容量提升至141GB 。
-
片上静态随机存取存储器 (On-chip SRAM): SRAM具有极低的访问延迟,通常用作高速缓存(如L1/L2 Cache)或特定计算单元的暂存空间 。例如,Intel Gaudi 3拥有96MB SRAM 。Cerebras的WSE芯片则集成了高达44GB的片上SRAM 。
-
DDR内存: 部分AI加速方案(如一些ASIC或FPGA方案,以及作为CPU系统内存)仍会使用DDR内存,其成本较低但带宽和延迟性能不如HBM和SRAM 。 对于LLM训练,尤其是万亿参数级别模型,单个AI芯片的内存容量远不足以容纳整个模型及其相关状态。因此,需要通过多芯片并行来扩展有效内存容量。对于推理而言,虽然模型参数是固定的,但KV Cache的大小会随序列长度和批处理大小动态变化,对内存容量提出挑战。一个70亿参数的LLM在FP16精度下约需14GB显存加载模型参数,而KV Cache的占用则取决于具体应用 。
-
-
内存带宽 (GB/s or TB/s): 内存带宽决定了处理器从内存中读取数据和向内存中写入数据的速率。对于LLM这类访存密集型应用,内存带宽是关键的性能瓶颈 。
-
-
HBM带宽高: HBM技术(如HBM2e, HBM3, HBM3e)能够提供数TB/s级别的内存带宽。例如,NVIDIA H100 SXM的HBM3带宽高达3.35TB/s ,AMD MI300X的HBM3带宽为5.3TB/s ,Intel Gaudi 3的HBM2E带宽为3.7TB/s ,Google TPU v5p的HBM2e带宽为2.765TB/s ,Ironwood TPU的HBM带宽更是达到7.37TB/s 。
-
SRAM带宽高: 片上SRAM的带宽高于HBM,但容量有限 。
-
内存带宽利用率 (Memory Bandwidth Utilization, MBU): 衡量实际达到的内存带宽与理论峰值带宽的比率。MBU接近100%表明推理系统有效利用了可用内存带宽 。在LLM推理的解码阶段,由于操作通常是访存密集型的,高MBU对于提升token生成速度至关重要。 “内存墙”问题,即处理器计算速度远超内存访问速度的现象,在LLM应用中尤为突出 。LLM的大量参数和中间激活值需要在内存和计算单元之间频繁传输。如果内存带宽不足,计算单元将长时间处于等待数据的空闲状态,导致整体性能下降。因此,选择具有高内存带宽和优良内存层次结构的AI芯片至关重要。一些研究通过在AI加速器的内存控制器中引入无损压缩技术(如LZ4, ZSTD)来压缩模型权重和KV Cache,从而减少内存容量和带宽占用,缓解内存瓶颈
-
3.3 互联技术 (Interconnect Technology)
对于需要多芯片协作的LLM训练和大规模推理,芯片间的互联技术直接影响系统的扩展性和整体性能。
-
片间互联 (Inter-chip Interconnect / Die-to-Die Interconnect):
-
NVIDIA NVLink & NVSwitch: NVLink是NVIDIA的高速GPU互联技术,提供远高于PCIe的带宽。例如,H100 SXM上的第四代NVLink提供900GB/s的双向带宽 。NVSwitch则用于构建更大规模的多GPU通信网络,连接多个NVLink域 。NVIDIA Grace Hopper Superchip (GH200) 通过NVLink-C2C实现CPU和GPU的高速缓存一致性互联,带宽高达900GB/s,远超PCIe Gen5 。第五代NVLink在Blackwell架构中进一步提升了带宽至1.8TB/s
-
-
节点间互联 (Inter-node Interconnect): 当LLM训练或推理扩展到多个服务器节点时,节点间的网络互联性能成为关键。
InfiniBand: 提供极高带宽和极低延迟,是许多大规模HPC和AI集群的首选网络技术,如NVIDIA的Quantum-2 InfiniBand 。
Ethernet (RoCE): 高速以太网(如200GbE, 400GbE, 800GbE)结合RDMA over Converged Ethernet (RoCE)技术,也广泛应用于AI集群,提供有竞争力的性能和成本效益 。Intel Gaudi系列和一些新兴AI芯片强调基于开放以太网标准的扩展性
3.4 功耗与散热 (Power Consumption and Cooling)
随着AI芯片算力的飙升,功耗和散热已成为数据中心面临的严峻挑战,直接影响运营成本和可持续性。
-
热设计功耗 (Thermal Design Power, TDP): AI芯片的TDP值通常较高,例如NVIDIA H100 SXM TDP可达700W ,AMD MI300X TDP为750W ,MI325X TDP更是高达1000W 。Intel Gaudi 3 OAM模块TDP为900W,PCIe版本为600W 。高TDP意味着巨大的能源消耗和散热压力。
-
能效 (Performance per Watt): 衡量AI芯片在单位功耗下能提供的计算性能,是评估芯片经济性和环保性的重要指标。例如,有研究指出,通过优化,NVIDIA H100 PCIe的FP8/FP16 TFLOPS/W表现优于A100 。Google Ironwood TPU据称能效比上一代Trillium提升2倍,比初代Cloud TPU提升近30倍 。AWS Trainium2的能效据称比第一代Trainium提升3倍 。
-
实际功耗波动: LLM工作负载具有快速、瞬态的动态功耗特性,峰值功耗与空闲功耗差异巨大 。训练任务可能瞬间从冷启动达到数十兆瓦的峰值负载,而推理任务的功耗模式也因模型和配置而异 。
-
散热技术: 传统风冷技术在应对高密度、高功耗AI芯片集群时面临瓶颈。液冷技术(直接液冷DLC、浸没式液冷)因其更高的散热效率,正成为AI数据中心的重要发展方向 。液冷不仅能有效控制芯片温度,还能降低数据中心PUE(Power Usage Effectiveness),减少风扇噪音,并可能支持更高的机柜功率密度 。例如,Supermicro的DLC-2液冷方案宣称可将数据中心功耗降低40%,TCO降低20% 。
3.5 存储性能与容量
LLM的训练数据集通常达到TB级别,需要高速存储设备(如NVMe SSD)来保证数据加载速度,避免因I/O瓶颈而使GPU处于等待状态 。此外,模型训练过程中需要定期保存模型状态的检查点(Checkpointing),这些检查点文件本身可能就达到数GB甚至更大,因此需要大容量、高可靠性的存储解决方案,如分布式文件系统或云存储服务 。
四、主流厂商算力服务器对比
4.1 英伟达系列
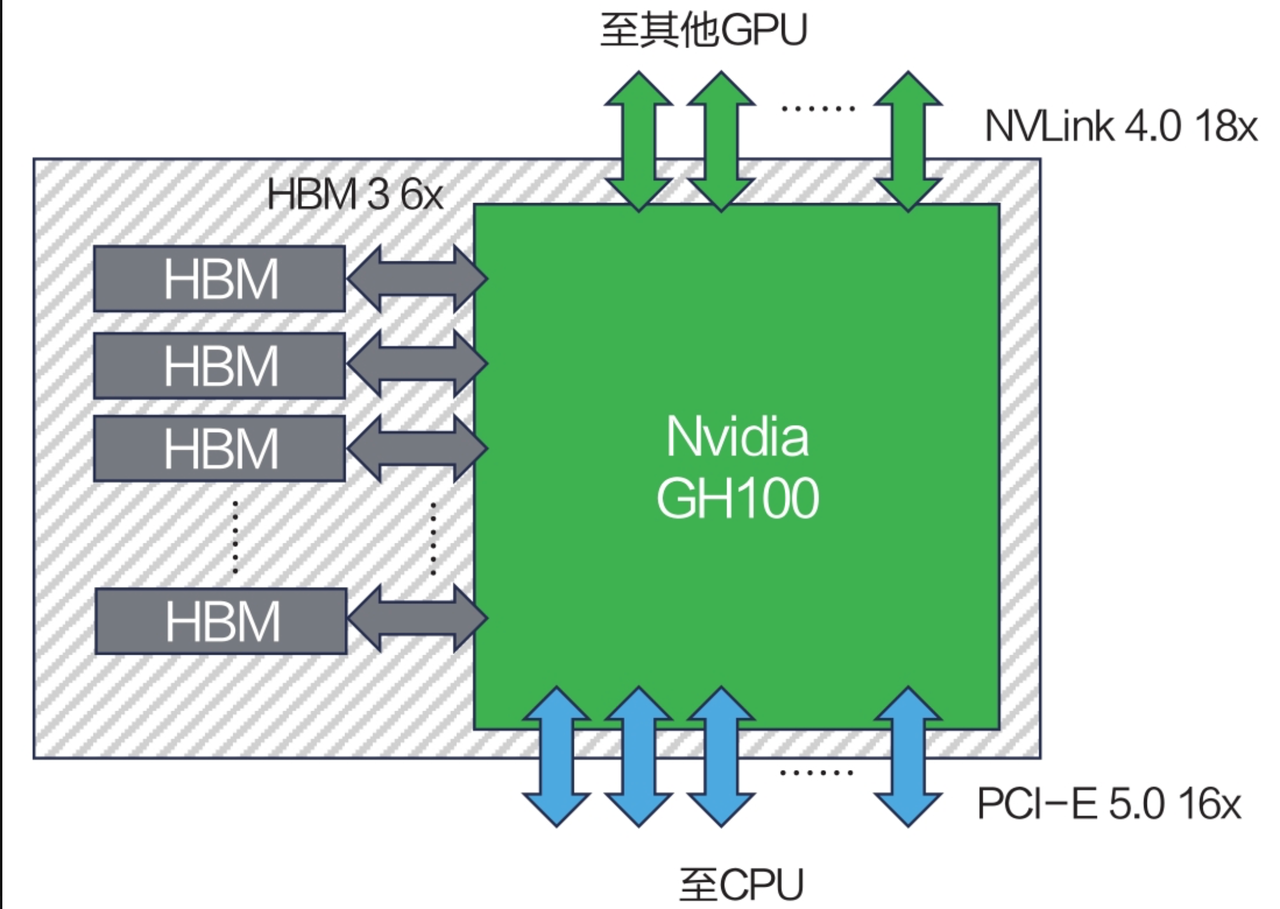
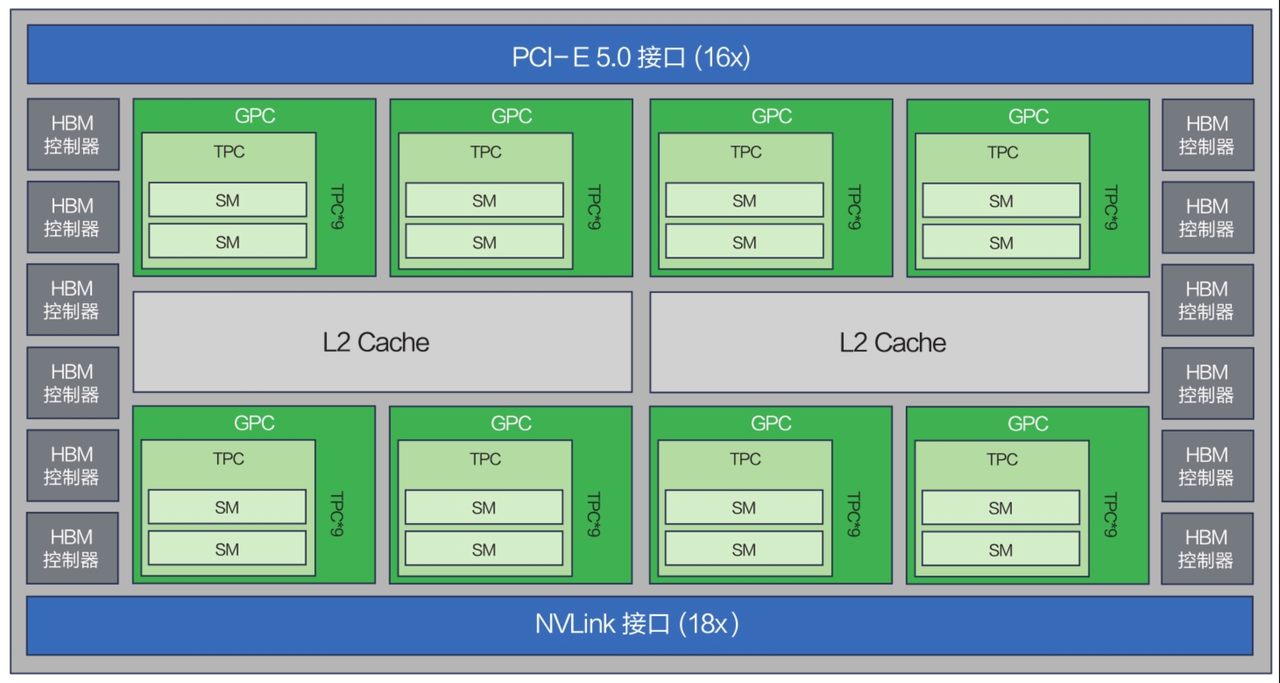
网络拓扑结构如下:
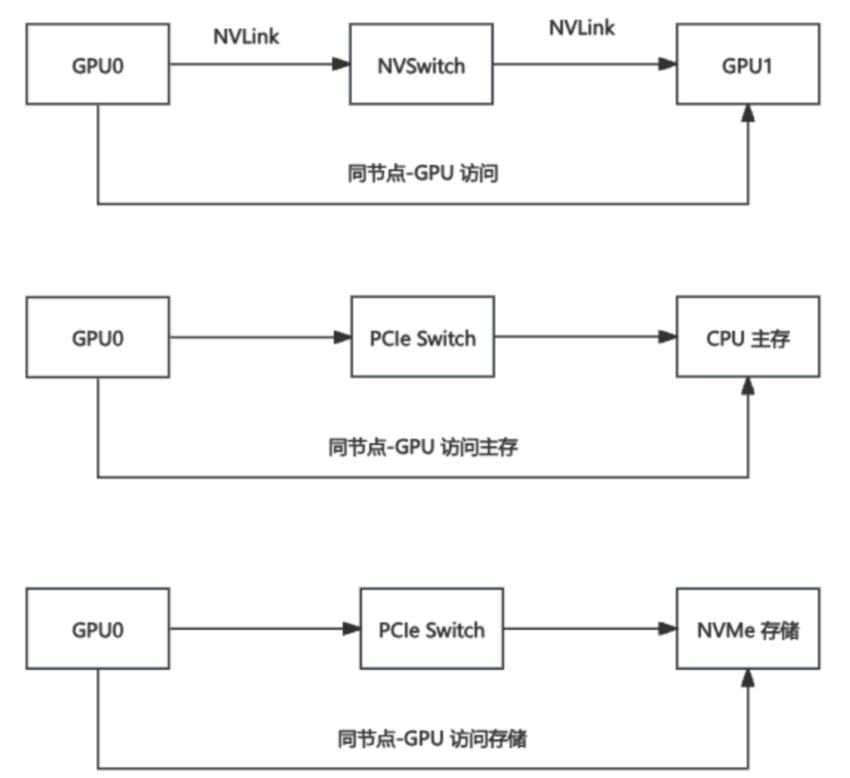
同节点互联:
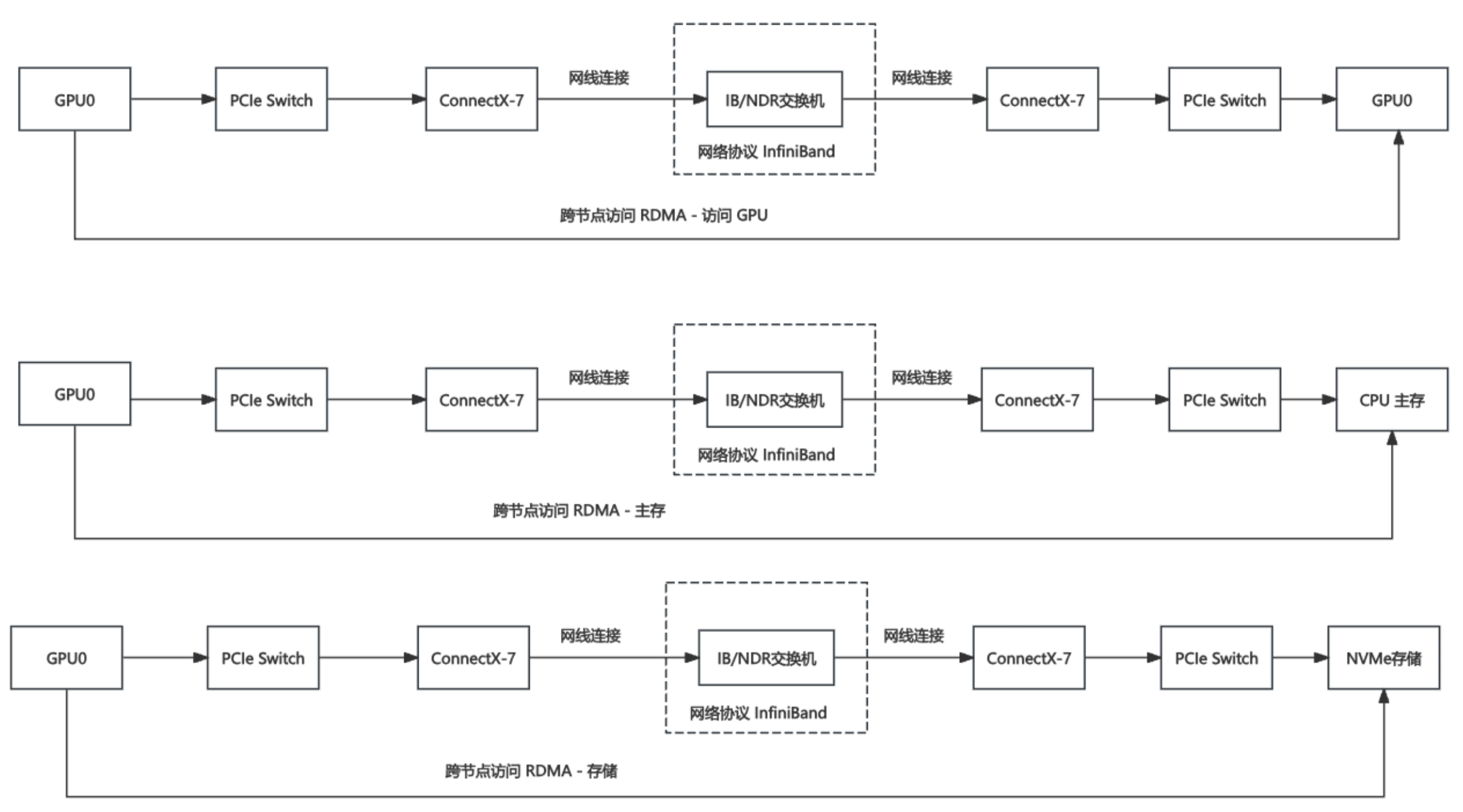
跨节点互联:
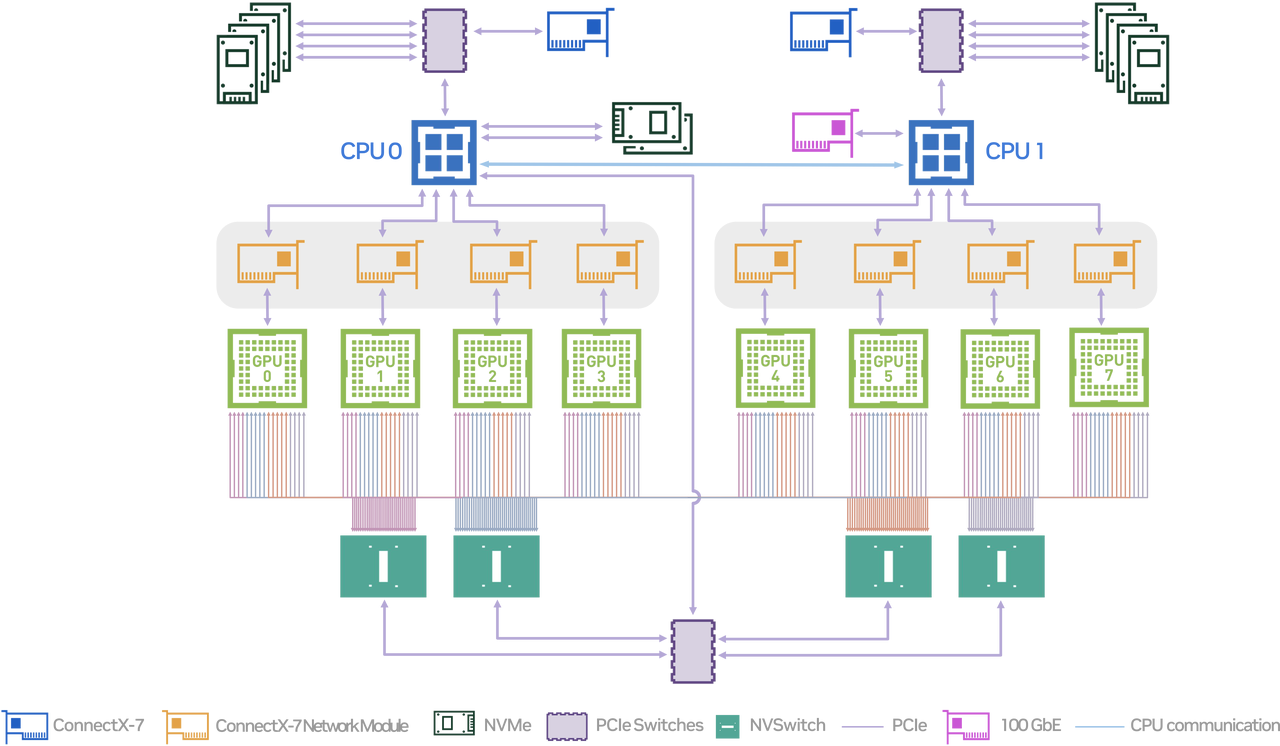
A100 服务器逻辑架构参考图:
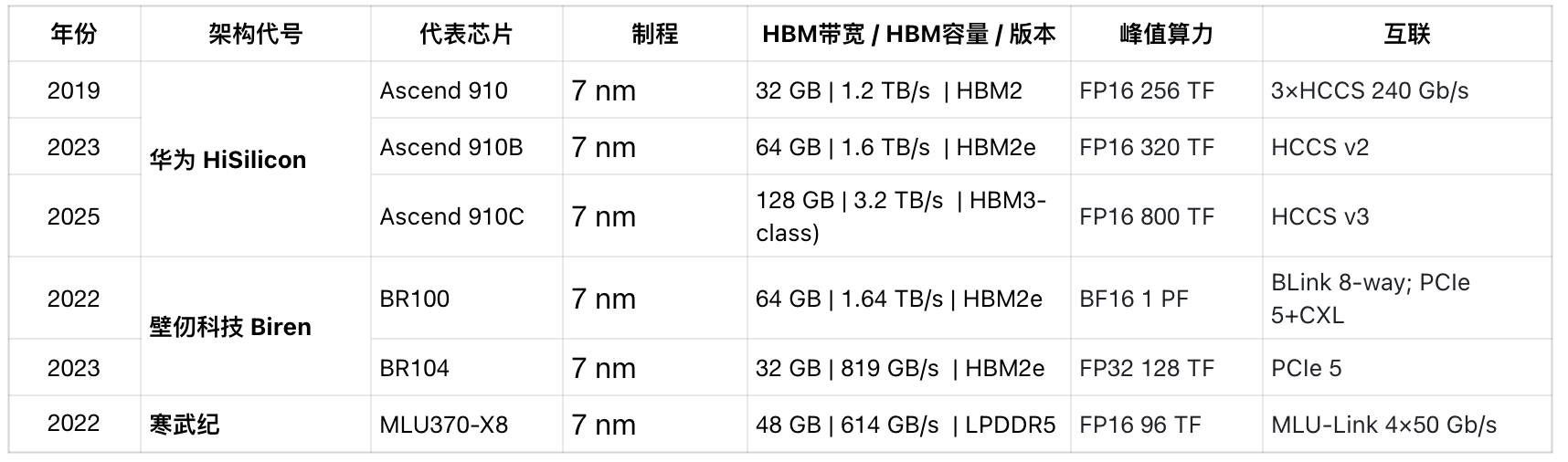
4.2 国产系列
 五、小结
五、小结
整理了大语言模型对于硬件方面的诉求和硬件各个部件指标的梳理归纳总结。以此做个笔记参考。
参考:
NVIDIA DGX B200 System User Guide — NVIDIA DGX B200 User Guide
NVIDIA DGX H100/H200 System User Guide — NVIDIA DGX H100/H200 User Guide
DGX A100 System User Guide — NVIDIA DGX A100 User Guide
书籍《大模型时代的基础架构:大模型算力中心建设指南》作者: 方天戟

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)