【文摘】DeepSeek本地部署与应用开发—基于Windows和Linux本地部署实操
【文摘】DeepSeek本地部署与应用开发—基于Windows和Linux本地部署实操
文章目录
本文节选自《DeepSeek本地部署与应用开发:政府与企业级实战案例解析》(北京大学出版社)第4章。若希望深入探讨相关内容,诚挚推荐您购买全书,深入阅读。
第4章 DeepSeek本地部署实操
在本章中,我们分别介绍Ollama、vLLM和LMStudio三种本地大模型运行工具,然后选择安装简单,新手友好的Ollama工具。
随后,我们将着重介绍Ollama工具,并手把手指导读者在Windows和Linux操作系统上通过Ollama工具部署DeepSeek大模型。
4.1 本地化部署工具对比
本地大模型运行工具常用的主要有三种:Ollama、vLLM、LM Studio。
- Ollama:轻量级本地大模型运行工具,适合个人开发和实验。部署简单,支持Mac、Linux、Windows(WSL),一键安装。硬件要求低,支持仅CPU运行大模型。缺点是推理效率不如vLLM,仅支持GGUF格式。
- vLLM:生产级大模型推理框架,适合企业级高并发场景。部署较复杂,依赖Python环境,需手动配置GPU驱动和CUDA。硬件要求高,必须使用NVIDIA GPU,依赖CUDA计算,环境配置负责,且不支持仅CPU运行。优点是高性能,支持分布式部署和多GPU并行。
- LM Studio:桌面端本地LLM GUI应用,适合非技术用户。部署简单,提供图形界面,无需命令行操作,对用户友好,适合离线使用。硬件要求低,支持GPU加速,适合桌面端。缺点是不适合大规模部署,自定义能力有限。
表4.1 本地大模型运行工具对比
| 工具 | Ollama | vLLM | LLM Studio |
|---|---|---|---|
| 部署难度 | 简单 | 复杂 | 简单 |
| 系统支持 | Mac/Linux/Windows | Docker、Kubernetes | Windows/Mac |
| 硬件要求 | 低(CPU/GPU支持) | 高(必须使用NVIDIA GPU) | 低(CPU/GPU支持) |
| 用户界面 | 命令行/API | API | 图形化界面(GUI) |
| 性能优化 | 轻量级 | 高性能,高吞吐量,支持连续批处理 | 轻量级 |
| 开源 | 开源(MIT) | 开源(Apache 2.0) | 闭源(免费) |
| 优点 | 安装简单,新手友好 | 高性能,支持分布式部署和多GPU并行 | GUI友好 |
| 缺点 | 推理效率不如vLLM | 不支持仅CPU运行,环境配置复杂 | 自定义能力有限 |
如表4.1所示,Ollama、vLLM和LM Studio三种工具的差异可总结为:Ollama 重本地灵活开发,vLLM 重生产性能,LMStudio 重用户体验。因此,推荐建议如下。
- 如果是本地部署,用户群体有限,推荐使用Ollama,因为它安装简单,资源占用低,适合快速上手。
- 如果是企业级应用,用户量大且需要高并发,推荐使用vLLM,其高性能和分布式部署能力更适合生产环境。
- 如果是非技术的新手用户,LM Studio是一个不错的选择,因为它提供友好的GUI界面。
由于我们的需求是将 DeepSeek 进行本地化部署,以便在内部局域网环境中供企业或政府工作人员使用,经过综合考量,最终选定了 Ollama 工具。
4.2 基于Windows系统部署Ollama
Ollama 是一个开源的本地大语言模型运行框架,专为简化大型语言模型(LLM)的本地部署和管理而设计。
Ollama 的设计目标是降低大语言模型的使用门槛,同时提供强大的本地化支持和灵活性。
本节介绍如何基于Windows系统部署Ollama工具。
4.2.1 下载Ollama
如图4.1所示,打开浏览器,访问Ollama官网首页(https://ollama.com/),单击中间或右上角的“Download”按钮,进入Ollama官方下载页面。
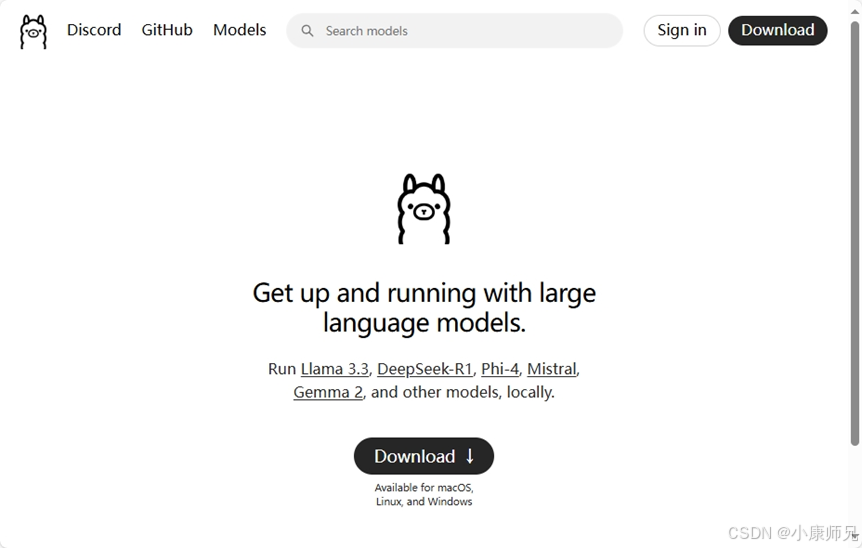
如图4.2所示,在Ollama官方下载页面中,单击页面中间的”Download for Windows”按钮,下载最新版本的Ollama for Windows。
Ollama for Windows作为原生 Windows 应用程序运行,支持 NVIDIA 和 AMD Radeon GPU(支持列表详情见:https://ollama.readthedocs.io/gpu/)。
4.2.2 安装Ollama
双击已经下载完成的Ollama安装包(OllamaSetup.exe),如图4.3所示,按照安装向导的提示逐步完成安装。
安装完成后,在开始菜单中即可找到Ollama应用程序,单击运行后,Ollama将在后台运行, Ollama 命令行工具将在 CMD、Powershell 或你最喜欢的终端应用程序中可用。
需特别说明的是,目前 Ollama 安装向导功能尚不完善,安装过程中并无安装路径选择选项。
因此,采用此方式安装,Ollama 将安装至 C 盘路径:C:\Users\weijian\AppData\Local\Programs\Ollama 。
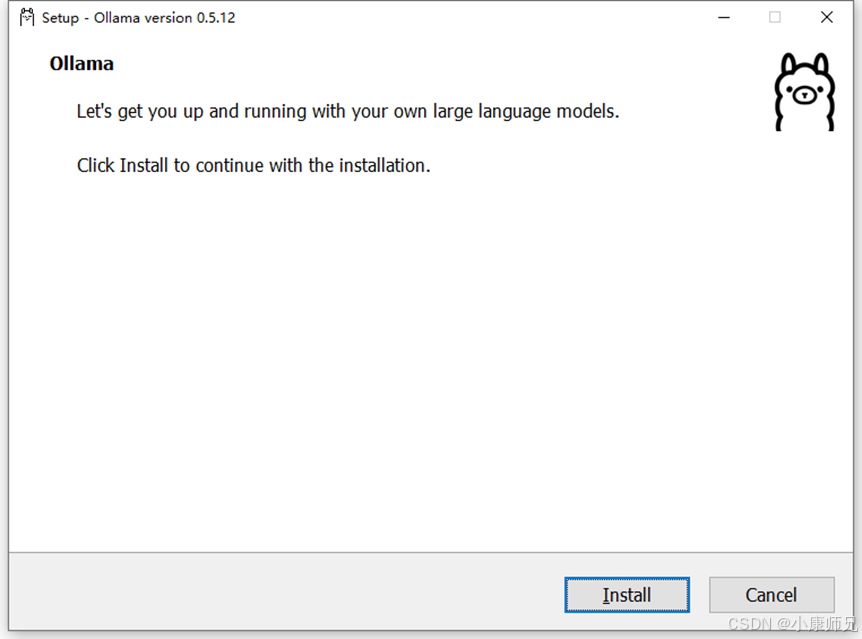
4.2.3 指定Ollama安装路径
如图4.4所示,通过命令行的方式可以指定Ollama的安装路径。
具体命令如下,其中/dir=后接指定的Ollama安装路径,比如如下的命令是将Ollama安装到D盘路径”D:\Program Files\Ollama”中。
D:\Program Files>OllamaSetup.exe /dir=“D:\Program Files\Ollama”
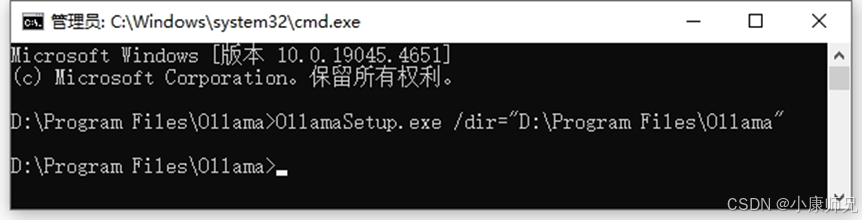
当执行相应命令行后,呈现效果如图 4.5 所示,此时系统仍会弹出 Ollama 安装界面,但与默认安装不同的是,文件路径已被更改为上文指定的D盘路径。
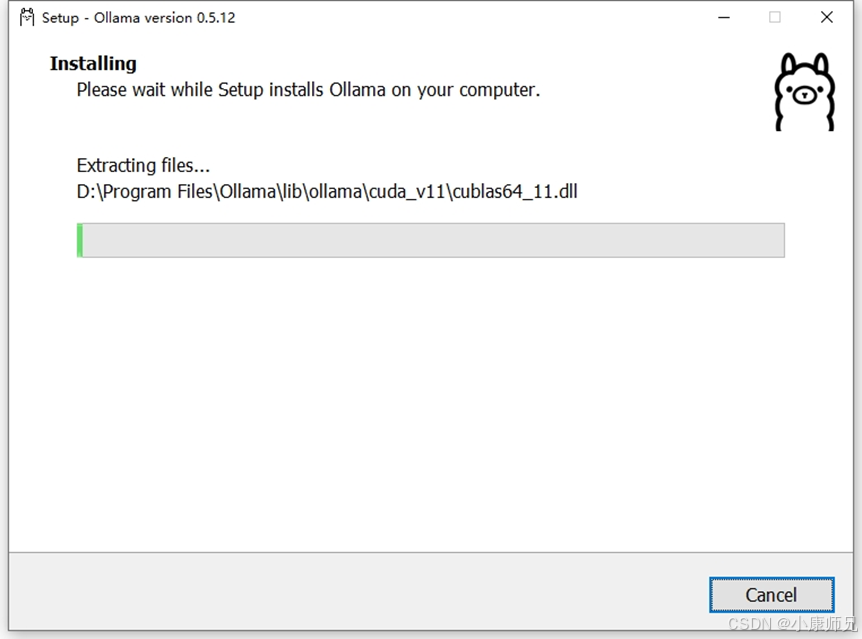
4.2.4 指定大模型存储路径
在安装 Ollama 并使用 DeepSeek 大模型时,除了需要指定Ollama安装路径外,还需要指定DeepSeek大模型的存储路径,Ollama默认的大模型存储路径是“C:\Users\<用户名>\.ollama\models\blobs”。
因为大模型通常占据较大的存储空间,所以合理指定其存储路径十分必要。可依照以下步骤进行操作。
- 打开“开始”菜单,在搜索框中输入“环境变量”,随后点击“编辑系统环境变量”选项。
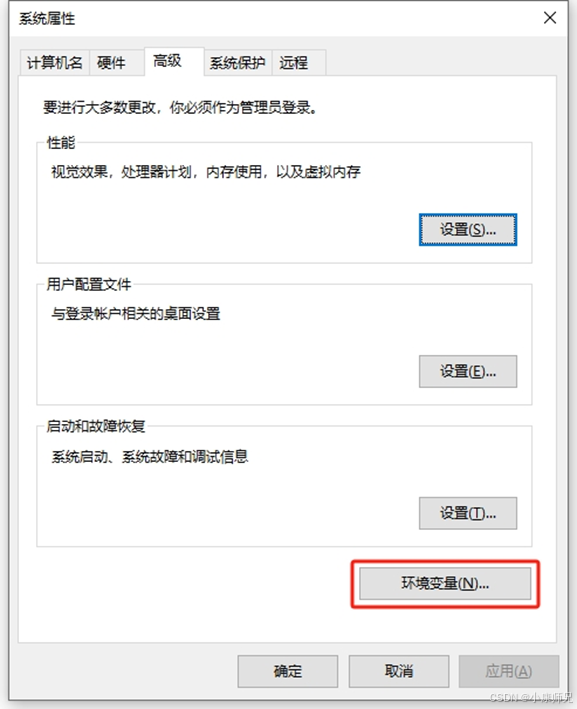
- 如图4.6所示,在弹出的“系统属性”窗口上,找到并单击“环境变量”按钮。
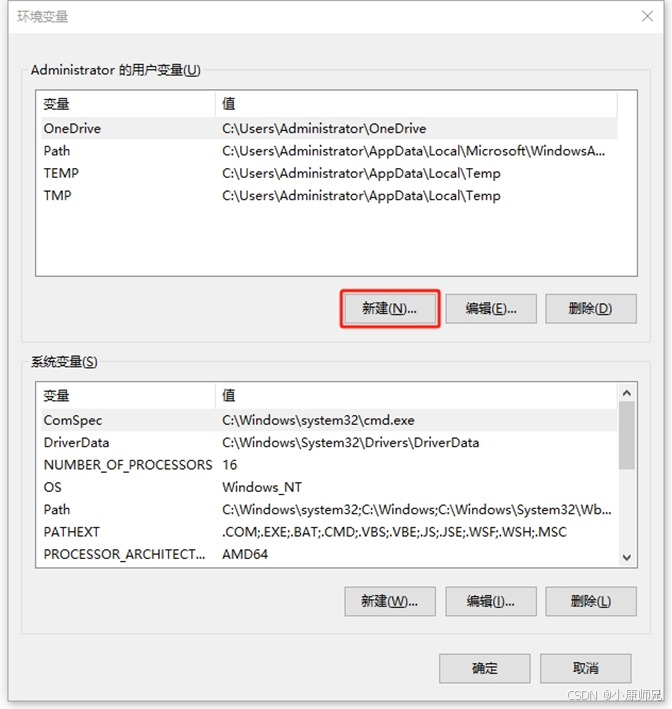
- 如图4.7所示,在弹出的“环境变量”窗口上,在“用户变量”区域中,找到并单击“新建”按钮。
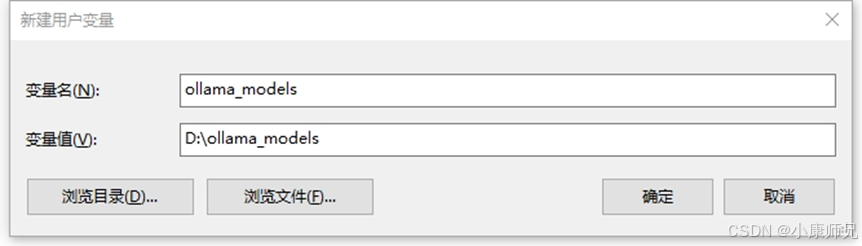
- 如图4.8所示,在弹出的“新建用户变量”窗口中,输入变量名“ollama_models”,在变量值一栏填写你期望存储模型的目录路径,例如“D:\ollama_models”,完成后点击“确定”以保存设置变更。
- 特别提醒:此设置变更需重启 Ollama 方可生效。若 Ollama 当前处于运行状态,需先关闭其应用程序,若它隐藏在底部系统托盘中,也需右键选择退出。然后,再从开始菜单重新启动 Ollama即可。
4.3 基于Linux系统部署Ollama
本节介绍如何基于Linux系统部署Ollama工具。
4.3.1 下载Ollama
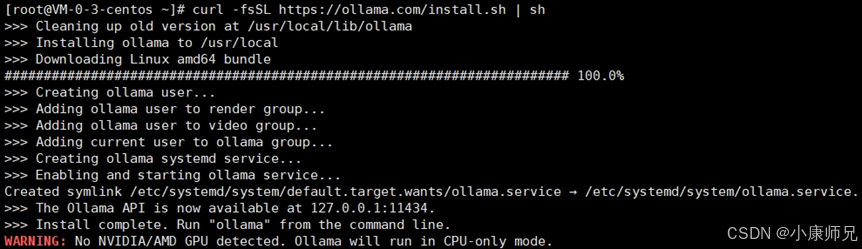
在Linux系统的终端运行如下脚本,该脚本是Ollama官方提供的安装脚本。
curl -fsSL https://ollama.com/install.sh | sh
运行效果如图4.10所示,该脚本执行的步骤如下
- 自动检测系统架构。
- 创建专用用户Ollama。
- 设置systemd服务。
- 下载最新版本二进制文件,需要时间请耐心等待。
- 配置环境变量。
4.3.2 启动Ollama
Ollama安装完成后,可以通过如下命令,启动Ollama。
“–host 127.0.0.1:11434”参数是为了安全,限制服务监听范围,仅限本机访问。
ollama serve --host 127.0.0.1:11434
Ollama启动完成后,可以通过如下命令,查询Ollama运行状态。
systemctl status ollama
可以通过如下命令,查询Ollama软件版本。
ollama –version
可以通过如下命令,查看Ollama服务日志的命令。
journalctl -e -u ollama
4.4 Ollama安全设置
4.4.1 Ollama的风险隐患
使用Ollama本地部署DeepSeek等大模型时,会默认在本地启动一个无鉴权机制的Web服务,并开放11434端口。
将存在一些安全上的风险隐患。
- 未授权访问风险
- 攻击者无需认证即可调用模型接口,执行模型操作、参数查询及文件删除。
- 通过/api/show等接口可获取模型License、部署配置等敏感元数据。
- 利用pull/delete等接口可破坏模型文件完整性,甚至植入恶意代码。
- 数据泄露风险
- 模型训练数据、推理结果等可通过接口直接提取。
- 历史对话记录、微调参数等核心资产存在未加密传输风险。
- 攻击者可结合社会工程学手段,通过精心构造的prompt诱导模型输出敏感信息。
- 历史漏洞利用风险,存在CVE-2024-39720/39722/39719/39721等高危漏洞。
- 攻击者可通过数据投毒篡改模型推理逻辑。
- 攻击者可窃取模型权重参数等知识产权资产。
- 攻击者可上传恶意文件破坏容器运行环境。
- 攻击者可删除modelfile等关键配置文件导致服务崩溃。
4.4.2 Ollama的安全防护
因此,我们需要安全的使用Ollama,构建5维安全防护体系的方案策略如下。
1. 网络层隔离
- 限制服务监听范围:仅限本机访问。
ollama serve --host 127.0.0.1:11434
- 配置防火墙策略:
# 禁止公网访问11434端口
iptables -A INPUT -p tcp --dport 11434 -j DROP
# 内网访问需IP白名单
iptables -A INPUT -p tcp --dport 11434 -s 10.0.1.0/24 -j ACCEPT
2. 访问控制强化
- 动态认证体系:通过Nginx反向代理增加Basic认证。启用JWT令牌认证,设置令牌有效期≤24小时。
location /api {
auth_basic "Ollama API";
auth_basic_user_file /etc/nginx/conf.d/ollama.htpasswd;
proxy_pass http://127.0.0.1:11434;
}
- 零信任架构:基于设备指纹的访问控制,仅允许注册MAC地址访问服务端口。
3. 接口安全治理
- 高危接口禁用:通过反向代理屏蔽/api/push、/api/delete等危险端点。
- 频率熔断机制:启用速率限制防御DDoS,对/api/chat接口实施滑动窗口限流(≤100次/分钟)。
4. 漏洞生命周期管理
- 紧急补丁升级:强制升级至安全版本。
- 自动化漏洞扫描:部署漏洞扫描工具,建立每日安全基线检查机制。
- 攻击特征监测:针对端口扫描、异常模型哈希变更等行为设置实时告警。
5. 应急响应流程预案
- 发现异常访问立即启用端口隔离。
- 通过“netstat -tulnp | grep 11434”核查端口暴露情况。
- 检查“~/.ollama/logs/server.log”分析攻击痕迹。
- 保留系统日志、网络流量包等取证材料。
- 第一时间向属地网安部门报送网络安全事件
4.5 部署DeepSeek模型
Ollama安装完成后,便能够基于 Ollama 进行 DeepSeek 模型的本地部署与运行。
4.5.1 选择DeepSeek-R1模型
DeepSeek-R1是DeepSeek推出的第一代推理模型,在性能上可与OpenAI-o1模型比肩。
DeepSeek-R1包含完整版671B参数模型和6个经知识蒸馏的轻量级子模型(如图4.10所示)。
这6个轻量级子模型是基于Llama和Qwen架构,从DeepSeek-R1进行知识蒸馏出来的。
通过这种方式蒸馏出来的模型主要有如下3个优点:
- 推理能力迁移:通过知识蒸馏技术,大型模型(如DeepSeek-R1)的复杂推理能力(如数学推导、代码生成)被有效迁移至小模型。例如,Qwen-32B模型经蒸馏后,在代码生成任务中的Pass@1准确率从47%(RL训练)提升至72.6%。
- 成本效益比:蒸馏模型的训练成本远低于直接训练小模型。DeepSeek的案例显示,其蒸馏模型的成本仅为传统大模型的1/20,却能实现对标顶级模型的性能。
- 技术突破:采用动态稀疏路由算法和混合专家架构(MoE),显存占用降低至传统架构的5%-13%,使模型更适配资源受限场景(如移动端部署)。
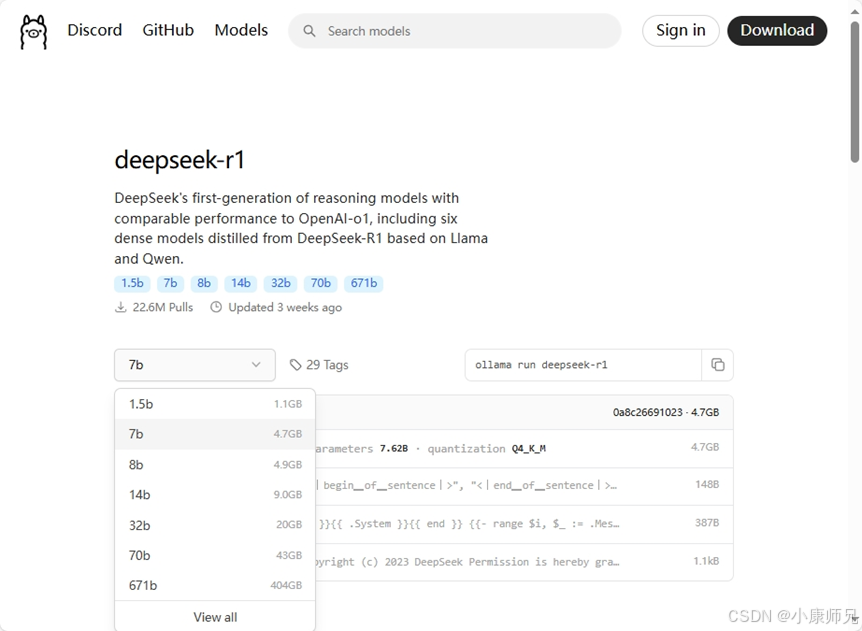
DeepSeek-R1 提供了合计7个参数版本的模型,这些模型主要用来适配不同的硬件配置和不同的适用场景。
适用场景从嵌入式设备到超算集群的全场景覆盖,而硬件要求主要以GPU的显存为核心依据。注意是GPU的专用内存,而非计算机的主内存 。
表4.2 deepseek-r1不同参数版本对应的硬件要求和适用场景表
| 版本 | 参数量 | 最低显存 | 推荐显存 | 推荐GPU | 内存 CPU | 适用场景 |
|---|---|---|---|---|---|---|
| 1.5b | 15亿 | 1.1GB | 4GB+ | 非必须 | 8GB+ 4核及以上 | 嵌入式设备 |
| 7b | 70亿 | 4.7GB | 8GB+ | RTX3060 | 16GB+ | 8核及以上 |
| 8b | 80亿 | 4.9GB | 8GB+ | RTX3060 | 16GB+ | 8核及以上 |
| 14b | 140亿 | 9.0GB | 16GB+ | RTX3090 | 32GB+ | 12核及以上 |
| 32b | 320亿 | 20GB | 24GB+ | RTX4090 | 64GB+ | 16核及以上 |
| 70b | 700亿 | 43GB | 70GB+ | 2xA100 | 128GB+ | 32核及以上 |
| 671b | 6710亿 | 404GB | 300GB+ | 8xA100 | 512GB+ | 64核(集群) |
DeepSeek-R1不同参数版本对应的硬件要求和适用场景如表4.2所示,主要可以划分为3大类。
- 轻量级部署(1.5B-8B) :最低需要 4GB 显存(如 RTX 3060 级别)即可运行,甚至1.5b版本在仅CPU的嵌入式设备中也能够顺畅运行。这一级别的模型适用于嵌入式设备和中等复杂度的自然语言处理(NLP)任务,为资源受限的环境提供了高效的解决方案。
- 企业级应用(14B-32B) :需要 16-24GB 显存(如 RTX 3090/4090)。这一级别的模型适用于企业级的复杂任务处理和多模态场景,能够满足企业在实际业务中对模型性能和功能的多样化需求。比如在金融领域,对大量金融交易数据进行深度分析,挖掘潜在风险与投资机会;在医疗行业,协助医生对海量病历文本进行智能分析,辅助疾病诊断与治疗方案制定。
- 科研级计算(70B-671B) :依赖多 A100 显卡集群(显存 70GB+)。这些超大规模的模型专攻超大规模的人工通用智能(AGI)研究,为科研人员提供了强大的计算能力和模型支持,以探索更前沿的人工智能领域。
DeepSeek-R1 通过「完整版+蒸馏版」双轨架构实现了性能与成本的平衡,其动态稀疏路由和 MoE 技术显著降低硬件门槛,而 7 个参数版本精准覆盖从移动端到超算中心的部署场景,为不同规模用户提供灵活的高性能推理解决方案。
然而,在实际部署过程中还有很多细节需要注意,比如:
- 显存碎片影响:实际显存需求可能比理论值高 10%-20%,建议预留余量以确保模型稳定运行。
- 量化技术影响:4-bit 量化可将显存需求降低至原模型的 1/4,但会导致约 3% 的 MMLU 精度损失。在精度敏感场景中,建议使用 8-bit 量化,尽管这会使显存需求翻倍。
- 框架开销影响:PyTorch 等深度学习框架基础占用约 1-2GB 显存,这在模型部署时需要额外考虑。
- 多卡部署注意:双 RTX 4060 Ti 16GB 方案存在 PCIe 带宽瓶颈,吞吐量增益仅为理论值的 65%,需谨慎选择。
- 企业级配置差异:对于 70B 及以上版本,推荐使用专业计算卡(如 RTX 5880 Ada),其显存带宽(1.05 TB/s)比消费级显卡高 40%,能有效提升模型性能。
- 性价比选择:32b模型可选用二手 RTX 3090 24GB(约 6500 元),相比新卡节省 50% 预算,是性价比之选。
4.5.2 拉取DeepSeek-R1模型
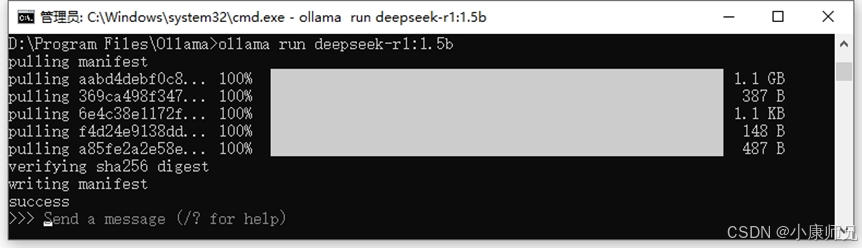
打开 Windows PowerShell或者CMD,在其中输入以下命令,从服务器拉取DeepSeek-R1模型(以1.5b参数版本为例)。
ollama pull deepseek-r1:1.5b
也可以输入如下命令,拉取并运行DeepSeek-R1模型(以1.5b参数版本为例)。
ollama run deepseek-r1:1.5b
完成上述操作后,请耐心等待下载过程。待 DeepSeek-R1 模型下载完毕,模型将自动启动运行。此时,您能够在终端中与模型展开交互,输入各类问题或任务指令,模型会即刻给出相应的回应, 如图4.11所示。
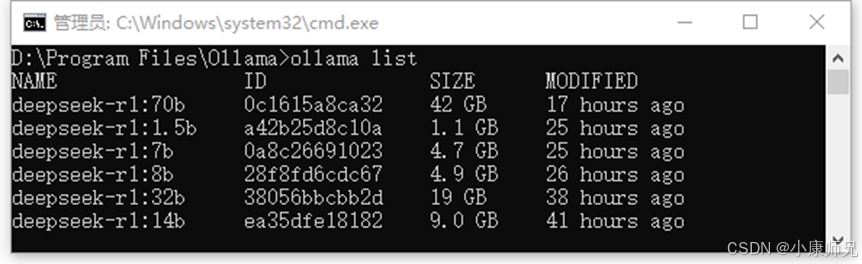
模型下载完成后,可以通过如下命令查看当前计算机上的模型,如图4.12所示。
ollama list
模型下载完成后,如果想要删除模型,可以输入如下命令删除模型(以1.5b参数版本为例)。
ollama rm deepseek-r1:1.5b
4.5.3 运行DeepSeek-R1模型
如果需要再次进入DeepSeek-R1模型的交互界面,则同样打开Windows PowerShell 或者CMD,在其中输入以下命令(以32b参数版本为例)。
ollama run deepseek-r1:32b
如图 4.13所示,倘若该模型此前已完成下载,系统将不会重复执行下载操作,而是直接启动运行模型,快速进入交互状态 。
在交互状态下,我们输入指令,比如“写一个蛇年的新年祝福语”,等待片刻,DeepSeek-R1就会输出其思考过程(在标签之间展开)和最终的回复内容。
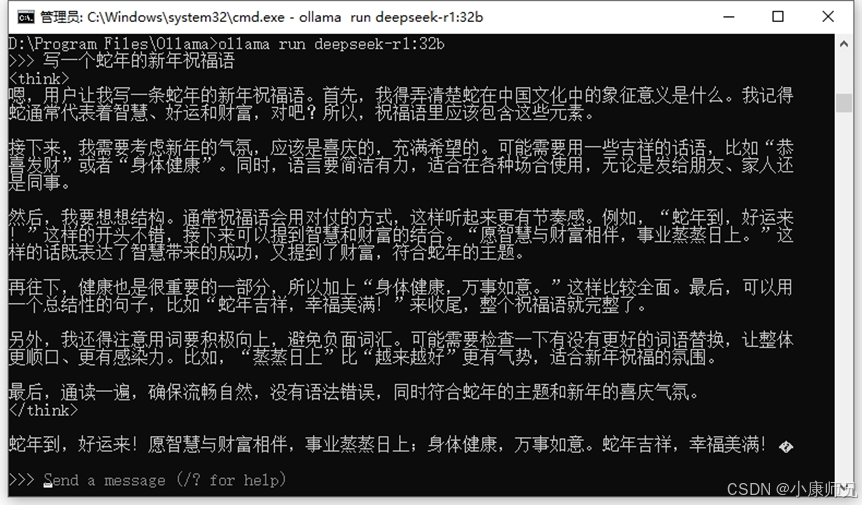
输入如下命令,查看当前正在运行的模型的运行状态。
ollama ps
如图4.14所示,deepseek-r1:32b模型正在运行,分别占用3%的CPU和97%的GPU,模型如果保持空闲,则预计4分钟后停止运行。
-
NAME:模型名称,deepseek-r1:32b 是当前运行的模型名称。 -
ID:模型 ID ,38056bbcbb2d 是模型的唯一标识符,用于区分不同的模型实例。 -
SIZE:模型大小,21 GB是该模型在内存中占用的空间大小。 -
PROCESSOR:处理器使用比例,10%/90% CPU/GPU表示模型有 10% 的部分在 CPU 上运行,而 90% 的部分在 GPU 上计算。这种使用率是正常的,表明了当 Ollama 正确识别并启用 GPU 时,模型推理的计算负载会优先由 GPU 承担。此时 GPU 使用率接近满载(90%),而 CPU 仅负责少量调度和通信任务(10%)。 -
UNTIL:预计停止时间,模型预计在4分钟后停止运行。Ollama 默认会在模型空闲一段时间后自动卸载模型,以节省系统资源。您可以通过设置环境变量 OLLAMA_KEEP_ALIVE 来调整模型在内存中的存活时间

最后,输入“/bye”即可退出与DeepSeek的交互。
或者在CMD窗口输入如下命令停止当前正在运行的模型(以32b参数版本为例)。
ollama stop deepseek-r1:32b
4.6 部署过程的常见问题
在使用 Ollama 部署运行 DeepSeek-R1 模型或其他相关操作过程中,可能会遇到以下各类问题,对应解决方案如下。
4.6.1 模型加载时间过长
在下载 Ollama 或 DeepSeek 模型时,可能会遇到镜像同步失败的问题。这通常是由于网络连接不稳定或镜像源不可用导致的。
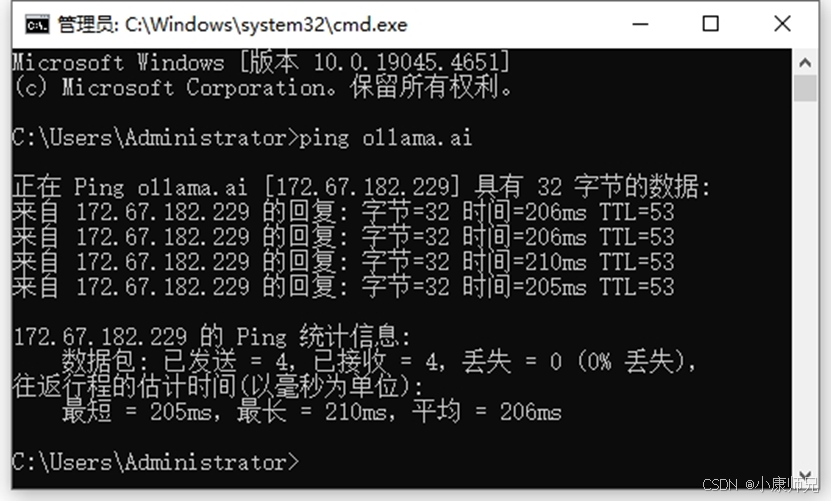
首先,检查网络连接是否正常。可以通过 ping 命令测试与镜像源服务器的连通性, 如图4.15所示。
ping ollama.ai
如果无法 ping 通,可能是网络配置错误或防火墙限制了访问,则需要检查网络配置和防火墙规则,确保网络连接正常。
4.6.2 启动Ollama报错
启动Ollama的报错如下。
Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.
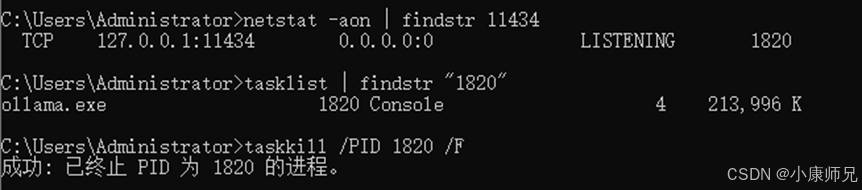
该报错信息表明端口 11434 已被其他进程占用,Ollama 无法正常绑定该端口启动。此时可按以下步骤解决,实际操作如图4.16所示。
- netstat -aon | findstr 11434:查找占用端口的进程,此处进程号为1820。
- tasklist | findstr “1820”:查看该进程号为1820的详细信息。
- taskkill /PID 1820 /F:杀死进程号为1820的进程。
4.6.3 内存不足错误
当出现内存不足错误时,建议您优先考虑选用参数规模较小的模型版本,以此降低内存占用。
若条件允许,也可对硬件配置进行升级,如增加内存条提升系统内存容量,或者更换性能更强劲的 GPU 以满足模型运行对显存的需求。
4.6.4 模型响应不准确
为确保模型给出准确响应,务必严格按照推荐的配置参数使用模型。
以温度参数为例,建议将其设置在 0.5 - 0.7 这个区间范围内,该参数主要用于控制模型输出的随机性,在此区间能使模型生成较为合理、稳定的回复。
同时,要避免在输入内容中添加不必要的系统提示符,以免干扰模型对用户意图的理解,进而影响回复的准确性。

本文节选自《DeepSeek本地部署与应用开发:政府与企业级实战案例解析》(北京大学出版社)第4章。若希望深入探讨相关内容,诚挚推荐您购买全书,深入阅读。
若觉得文章对你有帮助,随手『点赞』、『收藏』、『关注』,也是对我的支持。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)