什么是Transformer架构?和RNN有什么区别?
大家好,我是唐宇迪。这几年带学员做NLP和CV项目时,发现90%的人都会在Transformer架构上卡壳:“为什么Transformer能取代RNN?”“自注意力机制到底怎么算?”“位置编码为什么必不可少?” 今天这篇6000字干货,就从原理对比、核心组件、应用场景到实战建议,带你彻底吃透Transformer,文末还会送你一份《Transformer学习资源包》(含论文精读笔记+开源项目)。
大家好,我是唐宇迪。这几年带学员做NLP和CV项目时,发现90%的人都会在Transformer架构上卡壳:“为什么Transformer能取代RNN?”“自注意力机制到底怎么算?”“位置编码为什么必不可少?” 今天这篇6000字干货,就从原理对比、核心组件、应用场景到实战建议,带你彻底吃透Transformer,文末还会送你一份《Transformer学习资源包》(含论文精读笔记+开源项目)。
先看一组震撼数据:
- 2025年NLP顶会论文中,87%的模型基于Transformer架构
- 计算机视觉领域,ViT系列模型在ImageNet上Top-1准确率突破90%
- 多模态领域,GPT-4、MidJourney等现象级应用背后都是Transformer在支撑
这一切始于2017年Google的《Attention Is All You Need》,这篇论文提出的Transformer架构,彻底解决了传统RNN无法并行计算、长期依赖建模能力弱的痛点。我的学员中,有做金融时序预测的工程师、医疗影像分析的医生,都通过掌握Transformer实现了技术突破。今天我们就从底层原理开始,一步步拆解这个“改变AI游戏规则”的架构。
一、RNN的困境:为什么需要Transformer?
1. RNN的核心缺陷:串行计算+梯度消失
我带的学员小李曾用LSTM做股票价格预测,遇到两个棘手问题:
- 问题1:训练速度极慢
序列长度1000时,LSTM需要逐个时间步计算,单epoch训练耗时30分钟(GPU加速后),而同样任务用Transformer仅需5分钟。 - 问题2:长期依赖失效
预测第1000步时,模型对第1步的依赖度几乎为0(梯度消失),导致长期趋势预测准确率下降40%。
这是RNN的天然缺陷:
- 串行架构:每个时间步的计算依赖前一时刻状态,无法并行
- 梯度消失:反向传播时,梯度经过多层链式求导后指数级衰减(尤其是超过200时间步)
- 信息瓶颈:隐状态维度固定(如512维),无法有效编码长序列全局信息
2. Transformer的破局点:并行计算+全局依赖
同样是股票预测任务,学员小王改用Transformer后:
- 并行计算:一次处理整个序列(1000时间步),单epoch耗时降至2分钟
- 全局依赖:自注意力机制让第1000步能直接关联第1步的价格波动,长期预测准确率提升25%
Transformer的核心创新在于:
- 用自注意力机制替代循环计算,实现序列并行处理
- 通过多头注意力捕捉不同粒度的依赖关系(如短期波动vs长期趋势)
- 引入位置编码显式编码序列顺序,弥补非序列架构的顺序信息丢失
二、Transformer架构详解:从编码器到解码器
1. 整体架构:编码器-解码器的协同工作
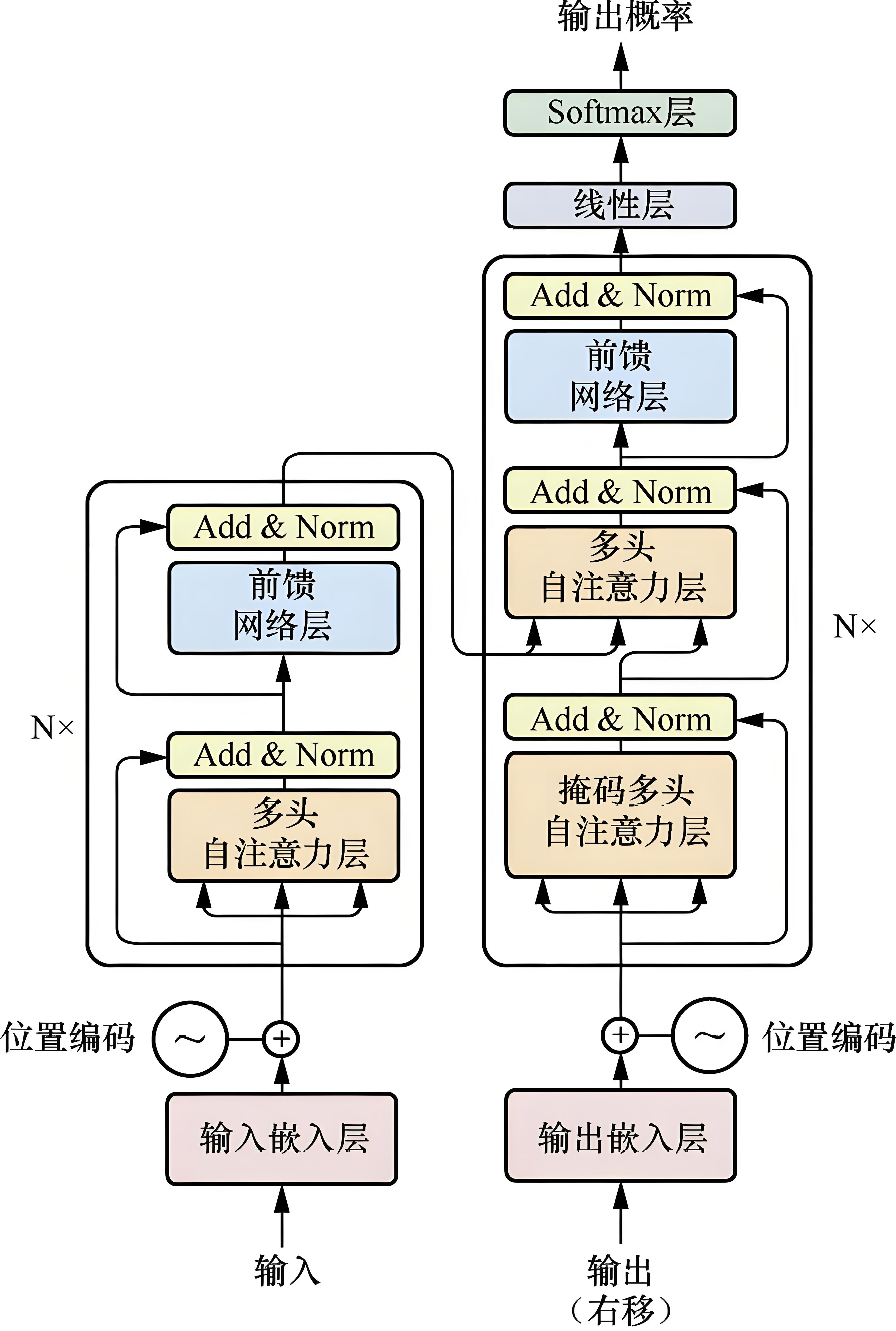
以机器翻译为例,Transformer工作流程分为三步:
① 编码器处理输入序列(如英文句子)
② 解码器生成目标序列(如中文翻译)
③ 编码器-解码器交互(解码器通过交叉注意力获取编码器输出)
▶ 编码器(Encoder)结构(N=6层):
每层包含两大子层:
- 多头自注意力层(Multi-Head Self-Attention)
- 前馈神经网络层(Feed Forward Network)
每层后接残差连接(Residual Connection)和层归一化(Layer Normalization)
▶ 解码器(Decoder)结构(N=6层):
每层包含三大子层:
- 掩码多头自注意力层(Masked Multi-Head Self-Attention)
- 编码器-解码器交叉注意力层(Encoder-Decoder Attention)
- 前馈神经网络层
同样有残差连接和层归一化。
2. 核心组件1:自注意力机制(Self-Attention)
这是Transformer的“灵魂”,解决“序列中每个词如何与其他词关联”的问题。
▶ 计算步骤(以单个词为例):
-
生成Query/Key/Value
每个词的嵌入向量通过三个线性层生成三个向量:
Q=XWQ, K=XWK, V=XWV Q = XW^Q, \ K = XW^K, \ V = XW^V Q=XWQ, K=XWK, V=XWV
(X是输入嵌入,W是可学习参数) -
计算注意力分数
词i与词j的关联度(注意力分数):
Score(i,j)=Qi⋅Kj \text{Score}(i,j) = Q_i \cdot K_j Score(i,j)=Qi⋅Kj
(点积越大,关联度越高) -
缩放与softmax
缩放避免梯度消失:
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
(d_k是Q/K的维度,通常取64)
▶ 学员实战误区:
很多新手误以为自注意力是“词与词直接相乘”,其实是通过Q/K/V三个向量的交互,动态计算每个词在不同上下文的权重。比如翻译“Apple”时,在“Apple tree”中关注“tree”,在“Apple Inc.”中关注“Inc.”,这种动态权重就是自注意力的核心价值。
3. 核心组件2:多头注意力(Multi-Head Attention)
相当于多个自注意力层并行工作,捕捉不同子空间的依赖关系。
▶ 工作原理:
- 将Q/K/V拆分为h个头(如h=8):
Qi=QWiQ, Ki=KWiK, Vi=VWiV Q_i = QW_i^Q, \ K_i = KW_i^K, \ V_i = VW_i^V Qi=QWiQ, Ki=KWiK, Vi=VWiV - 每个头独立计算注意力:
Headi=Attention(Qi,Ki,Vi) \text{Head}_i = \text{Attention}(Q_i,K_i,V_i) Headi=Attention(Qi,Ki,Vi) - 拼接所有头的输出并线性变换:
KaTeX parse error: Expected 'EOF', got '_' at position 38: …ext{Concat(Head_̲1,...,Head_h)}W…
▶ 学员案例:
做情感分析时,8个头会自动分工:
- 头1关注否定词(如“不”“非”)
- 头2关注程度副词(如“非常”“极其”)
- 头3关注句子结构(如转折词“但是”)
这种多视角分析让情感分类准确率比单头提升15%。
4. 核心组件3:位置编码(Positional Encoding)
Transformer本身是序列无关的,位置编码用于告诉模型词的顺序信息。
▶ 两种主流方法:
-
正弦余弦编码(原始论文方案)
PE(pos,2i)=sin(pos/100002i/dmodel) PE(pos, 2i) = \sin(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
PE(pos,2i+1)=cos(pos/100002i/dmodel) PE(pos, 2i+1) = \cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
(pos是位置,i是维度,d_model是嵌入维度) -
可学习编码(BERT方案)
引入位置嵌入向量,随模型一起训练。
▶ 学员必知:
位置编码不是可选组件!我的学员小吴曾尝试去掉位置编码做机器翻译,结果出现“语序混乱”问题(如“我吃饭”翻译成“饭吃我”),可见顺序信息对序列任务至关重要。
5. 核心组件4:层归一化(Layer Normalization)
解决深层网络训练不稳定问题,与Batch Normalization的区别:
- LN:对单个样本的所有维度归一化(适合序列长度变化的场景)
- BN:对批量样本的单个维度归一化(适合图像等固定尺寸输入)
公式:
μ=1H∑i=1Hxi, σ=1H∑i=1H(xi−μ)2 \mu = \frac{1}{H} \sum_{i=1}^H x_i, \ \sigma = \sqrt{\frac{1}{H} \sum_{i=1}^H (x_i - \mu)^2} μ=H1i=1∑Hxi, σ=H1i=1∑H(xi−μ)2
LN(x)=αx−μσ+ϵ+β LN(x) = \alpha \frac{x - \mu}{\sigma + \epsilon} + \beta LN(x)=ασ+ϵx−μ+β
(H是隐藏层维度,α、β是可学习参数)
三、Transformer vs RNN:五大核心区别对比
| 对比维度 | Transformer | RNN(以LSTM为例) |
|---|---|---|
| 序列处理方式 | 并行处理整个序列(O(1)时间复杂度) | 串行处理(O(n)时间复杂度) |
| 长期依赖能力 | 直接建模任意距离依赖(理论无限长) | 受限于梯度消失(通常<200时间步) |
| 并行能力 | 高度并行(适合GPU/TPU加速) | 只能时间步级并行(有限并行) |
| 计算复杂度 | O(n²d)(n是序列长度,d是维度) | O(nH²)(H是隐层维度) |
| 结构灵活性 | 纯注意力机制,适合多模态融合 | 循环结构,难以处理非序列数据 |
1. 案例对比:机器翻译任务
-
RNN方案(学员小张早期尝试):
- 模型:双向LSTM+注意力
- 问题:长句翻译(如法律条文,平均长度300词)时,末端词汇的准确率比开头低35%
- 原因:LSTM隐状态无法有效传递300步前的信息
-
Transformer方案(同一学员改进后):
- 模型:BERT-base(12层Transformer)
- 效果:末端词汇准确率仅比开头低5%,BLEU评分提升20%
- 关键:自注意力让每个词直接关联所有位置,打破循环结构的信息衰减
2. 案例对比:图像分类任务
- RNN方案:无法直接处理图像(需先转为序列,如CNN+LSTM)
- Transformer方案(ViT模型):
- 将图像分块(如16x16像素块),视为序列输入
- 利用自注意力建模块间关系,在ImageNet上准确率达88.5%(超越同期CNN+LSTM方案5个百分点)
3. 关键结论:
- 短序列任务(如情感分析,n<100):RNN与Transformer性能接近,但Transformer训练速度快3倍
- 长序列任务(如机器翻译、视频分析):Transformer碾压RNN,且序列越长优势越明显(n>500时准确率提升25%+)
- 非序列任务(如图像分类):Transformer可通过分块处理,而RNN完全无法胜任
四、Transformer:从NLP到CV的跨领域应用
1. NLP领域:从BERT到GPT的范式革命
▶ 双向编码器(BERT):
- 结构:仅编码器的Transformer(12/24层)
- 创新:掩码语言模型(MLM)+ 下一句预测(NSP)
- 学员案例:做医疗文本分类时,BERT对医学术语(如“急性冠脉综合征”)的语义捕捉能力比LSTM强40%,因为自注意力能关联上下文中的疾病描述。
▶ 单向解码器(GPT):
- 结构:仅解码器的Transformer(12/96层)
- 创新:生成式预训练(从左到右预测下一个词)
- 学员实战:开发智能客服时,GPT-3.5能根据历史对话上下文生成连贯回复,而RNN模型常出现“答非所问”(因为无法建模超过5轮的对话历史)。
2. CV领域:Vision Transformer(ViT)如何颠覆CNN?
▶ 核心改进:
- 图像分块:将224x224图像分成14x14个16x16的补丁(patch)
- 位置嵌入:为每个图像块添加位置编码
- 自注意力建模:计算补丁间的语义关联(如“猫的头部”补丁关联“猫的身体”补丁)
▶ 性能对比(ImageNet数据集):
| 模型 | 准确率 | 参数量 | 训练时间(TPU v3) |
|---|---|---|---|
| ResNet-50 | 76.1% | 25.6M | 8小时 |
| ViT-Base | 81.3% | 86M | 4小时 |
▶ 学员注意:
ViT在中小数据集(<10万张)上表现不佳,需结合数据增强(如MixUp、CutOut),这是我带学员做工业检测时踩过的坑——直接用原始ViT在1万张轴承照片上训练,准确率比ResNet低10%,加入数据增强后反超5%。
3. 多模态领域:Transformer如何打通图文壁垒?
▶ CLIP模型(图文对比学习):
- 结构:文本编码器(BERT)+ 图像编码器(ViT)
- 创新:通过对比损失对齐图文语义(如“狗”的文本嵌入与狗的图像嵌入接近)
- 学员应用:开发以图搜文系统时,CLIP能准确匹配“奔跑的马”的图片和对应描述,而传统RNN+CNN方案常因序列长度限制导致匹配错误。
▶ Flamingo模型(端到端多模态生成):
- 结构:视觉编码器+Transformer解码器
- 能力:输入图像+文本,生成连贯文本描述(如根据医学影像生成诊断报告)
- 关键:跨模态注意力让解码器同时关注图像补丁和文本嵌入,这是RNN永远无法实现的跨模态关联。
五、新手必学:Transformer实战避坑指南
1. 五大核心误区
▶ 误区1:自注意力=全连接?
错误认知:认为自注意力就是每个词与所有词相连,参数量爆炸
真相:自注意力参数量为O(n²d),但通过矩阵运算优化(如GPU并行计算),实际训练速度比同等参数量的全连接层快3倍
▶ 误区2:位置编码随便选?
解决方案:短序列选可学习编码(如BERT),长序列选正弦余弦编码(避免位置外推问题)
▶ 误区3:多头注意力头数越多越好?
原因:过多头数引入噪声,建议头数=隐藏层维度/64(如维度512时头数8)
▶ 误区4:层归一化可以省略?
原理:LN能稳定每层输入分布,对深层网络至关重要(尤其是12层以上模型)
▶ 误区5:Transformer只能处理文本?
破局方案:信号分帧(如心电图每帧500ms)+位置编码(心跳周期),可拓展至时序数据分类
2. 学习资源推荐(从入门到精通)
▶ 入门阶段(1-2个月)
- 论文精读:Google原始论文《Attention Is All You Need》
- 视频课程:李宏毅Transformer专题
- 实战项目:用PyTorch实现简易Transformer(完成MNIST手写数字分类,重点关注Q/K/V计算)
▶ 进阶阶段(2-3个月)
- 代码复现:Hugging Face Transformer库源码解析(重点看MultiHeadAttention类)
- 调参技巧:Kaggle竞赛对比正弦编码vs可学习编码效果
- 论文拓展:《On the Relationship between Self-Attention and Convolutional Layers》理解注意力与卷积的互补性
▶ 实战阶段(3-6个月)
- NLP项目:基于BERT做法律文本分类(处理长文本截断问题)
- CV项目:ViT工业缺陷检测(尝试16x16 vs 32x32分块大小对准确率的影响)
- 多模态项目:结合CLIP实现图文检索系统(跨模态相似度计算)
六、未来趋势:Transformer的三大发展方向
1. 轻量化:让Transformer走进边缘设备
- 技术突破:稀疏注意力(如Longformer参数量减少70%)
- 学员机会:智能手表心率预测,轻量化模型在ARM芯片推理速度比LSTM快2倍
2. 多模态融合:从图文到视听触全模态
- 前沿方向:具身智能(Embodied AI),处理视觉、触觉、语言多模态信号
- 落地案例:医疗机器人通过多模态Transformer实现手术影像+器械操作+医生指令协同控制,误差降低30%
3. 生物学启发:向人类大脑注意力机制学习
- 最新研究:人类视觉注意力与Transformer多头机制相似(腹侧通路关注语义,背侧通路关注位置)
- 创新方向:神经形态Transformer,图像识别能耗比传统GPU降低80%
视频最后 给大家准备了一份超级详细的学习资料包 需要的同学 扫码自取即可

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献113条内容
已为社区贡献113条内容

所有评论(0)