探索大语言模型开源数据集
在大语言模型(LLM)的发展中,开源数据集起到了关键作用。本文介绍了四个具有代表性的开源数据集:Pile、ROOTS、RefinedWeb和SlimPajama。
在大语言模型(LLM)的发展进程中,开源数据集扮演着举足轻重的角色。随着基于统计机器学习的自然语言处理算法的发展,以及信息检索研究的需求,特别是近年来深度学习和预训练语言模型的研究,研究人员构建了多种大规模开源数据集。这些数据集涵盖网页、图书、论文、百科等多个领域,其质量和多样性对提升大语言模型性能至关重要。为推动大语言模型的研究和应用,学术界和工业界开放了多个针对大语言模型的开源数据集,本文将着重介绍 Pile、ROOTS、RefinedWeb 和 SlimPajama 这几个具有代表性的数据集。
一、Pile 数据集:多样文本的宝库
Pile 数据集是大语言模型训练的重要资源,它是一个多样性大规模文本语料库,由 22 个不同的高质量子集构成 。这些子集来源广泛,许多都来自学术或专业领域,像 Pile-CC(CommonCrawl 子集)、Wikipedia、OpenWebText2、ArXiv、PubMed Central 等。Pile 数据集合组成如下:
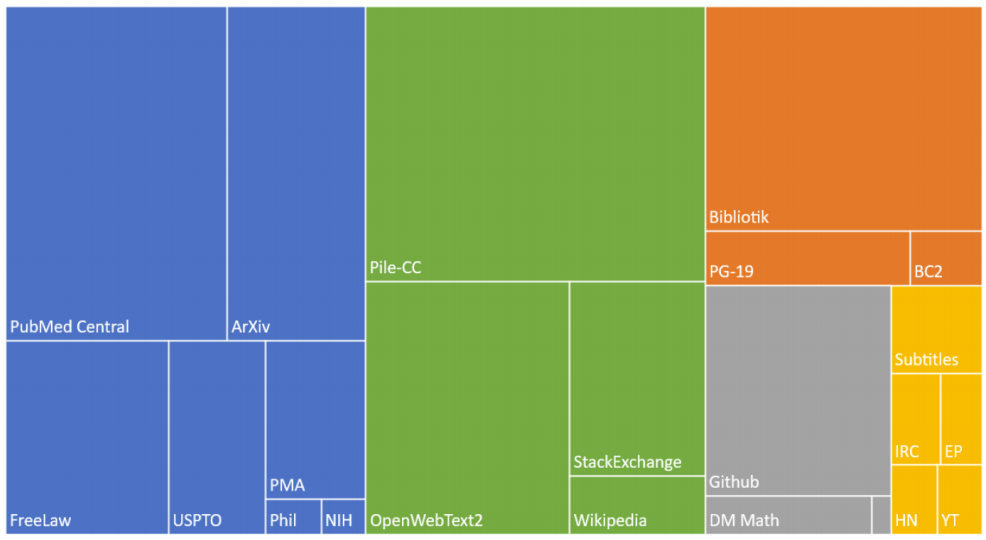
Pile 数据集最大的特点就是其丰富的多样性,涵盖了不同领域和主题的大量文本。这使得它能够极大地提高训练数据集的多样性和丰富性,为大语言模型提供全面且多元的学习素材。Pile 数据集包含 825GB 英文文本,从其数据类型组成图中可以直观地看到,不同类型的数据在整个数据集中所占规模各异,各个领域的文本相互补充,共同构建起一个庞大而丰富的知识体系。
| 类别 | 子集名称 | 简介 |
|---|---|---|
| 网络数据类 | Pile-CC | 基于 Common Crawl,在 Web Archive 文件上用 jusText 方法提取,比直接使用 WET 文件输出质量更高 |
| 网络数据类 | OpenWebText2(OWT2) | 基于 WebText 和 OpenWebTextCorpus 的通用数据集,包含从 Reddit 提交到 2020 年的内容、多语言内容、文档元数据等 |
| 学术资源类 | PubMed Central(PMC) | 美国国家生物技术信息中心运营的 PubMed 生物医学在线资源库子集,提供近 500 万份出版物的开放全文访问 |
| 学术资源类 | ArXiv | 自 1991 年运营的研究论文预印版本发布服务,论文集中在数学、计算机科学和物理领域,用 LaTeX 编写,适合语言模型学习公式等内容表示 |
| 学术资源类 | PubMed Abstracts | 由 PubMed 的 3000 万份出版物摘要组成,PubMed 还包含 1946 年至今的生物医学摘要(MEDLINE) |
| 学术资源类 | NIH Grant Abstracts: ExPORTER | 包含 1985 年至今所有获得美国 NIH 资助的项目申请摘要,是高质量科学写作实例 |
| 图书资源类 | Books3 | 来自 Shawn Presser 提供的 Bibliotik,由小说和非小说类书籍组成,数据量约为 BookCorpus2 的十倍 |
| 图书资源类 | Project Gutenberg(PG-19) | 由 1919 年以前的西方经典文学书籍组成,风格与现代的 Book3 和 BookCorpus 不同 |
| 图书资源类 | BookCorpus2 | 原始 BookCorpus 的扩展版本,广泛用于语言建模,包含 “尚未发表” 书籍,与其他图书数据集重叠少 |
| 代码数据类 | GitHub | 大型开源代码库,对语言模型完成代码生成、代码补全等任务至关重要 |
| 法律数据类 | Free Law 项目(CourtListener) | 美国注册的非营利组织,CourtListener 包含美国联邦和州法院数百万法律意见,提供批量下载服务 |
| 问答数据类 | Stack Exchange | 围绕用户提供问题和答案的网站集合,其数据转储包含大量用户贡献的匿名数据集,涵盖从编程到园艺等广泛主题 |
| 专利数据类 | USPTO Backgrounds | 美国专利商标局授权的专利背景部分数据集,来源于公布的批量档案,包含大量技术文章 |
| 百科数据类 | Wikipedia (English) | 维基百科的英文部分,由全球志愿者协作创建和维护的免费在线百科全书,提供各种主题知识 |
| 字幕数据类 | OpenSubtitles | 由英文电影和电视的字幕组成,可增强模型对虚构格式的理解,对创造性写作任务有帮助 |
| 数学数据类 | DeepMind Mathematics | 包含代数、算术、微积分等数学问题,以自然语言提示形式给出,用于增强语言模型数学能力 |
| 聊天数据类 | Ubuntu IRC | 从 Freenode IRC 聊天服务器上所有与 Ubuntu 相关频道的公开聊天记录中提取,可用于语言模型建模人类交互 |
| 多语言语料库类 | EuroParl | 多语言平行语料库,最初为机器翻译构建,Pile 数据集中的版本包含 1996 - 2012 年欧洲议会 21 种欧洲语言的议事录 |
| 字幕数据类 | YouTube Subtitles | 从 YouTube 上人工生成的字幕中收集的文本平行语料库,提供多语言数据,也是教育内容等的来源 |
| 哲学数据类 | PhilPapers | 由 University of Western Ontario 数字哲学中心维护的国际数据库中的哲学出版物组成,文本写作质量高 |
| 新闻数据类 | Hacker News | 由初创企业孵化器和投资基金 Y Combinator 运营的链接聚合器,文章多聚焦计算机科学和创业主题,包含小众话题的高质量对话和辩论 |
| 邮件数据类 | Enron Emails | 用于电子邮件使用模式研究的数据集,可帮助语言模型建模电子邮件通信特性 |
二、ROOTS 数据集:多语言与多数据源的融合
ROOTS(Responsible Open-science Open-collaboration Text Sources)数据集是 Big-Science 项目在训练具有 1760 亿参数的 BLOOM 大语言模型时所使用的。该数据集一大亮点是语言种类丰富,包含 46 种自然语言和 13 种编程语言,总计 59 种语言,数据集大小约 1.6TB。ROOTS 数据集合中各语言所占比例如下:
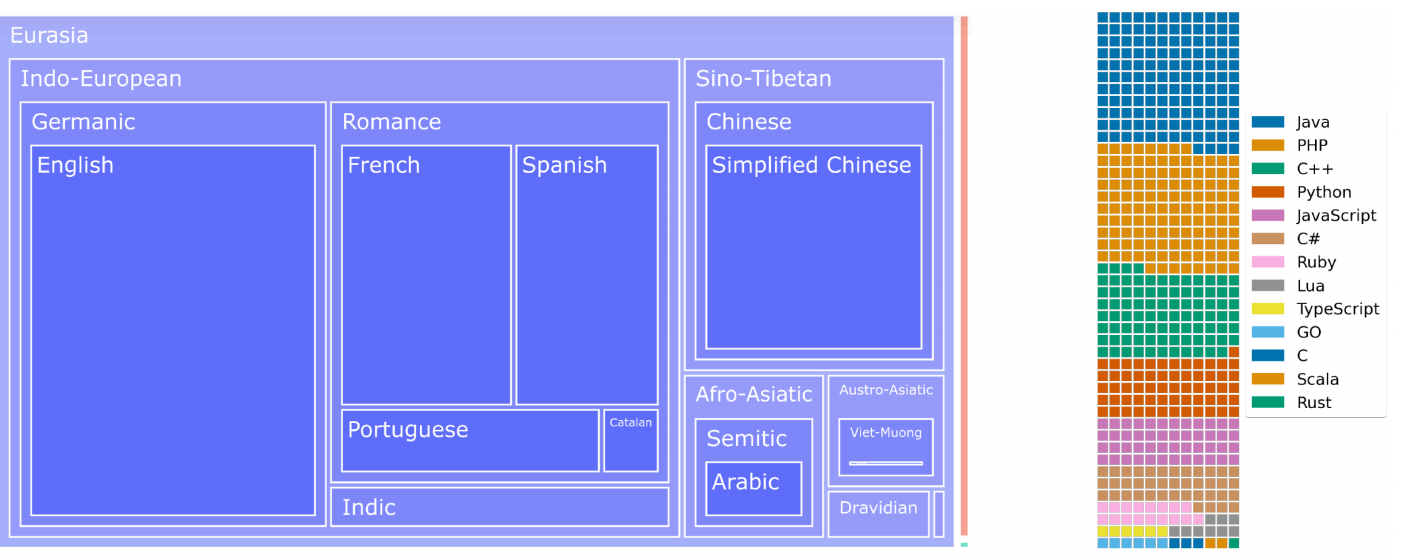
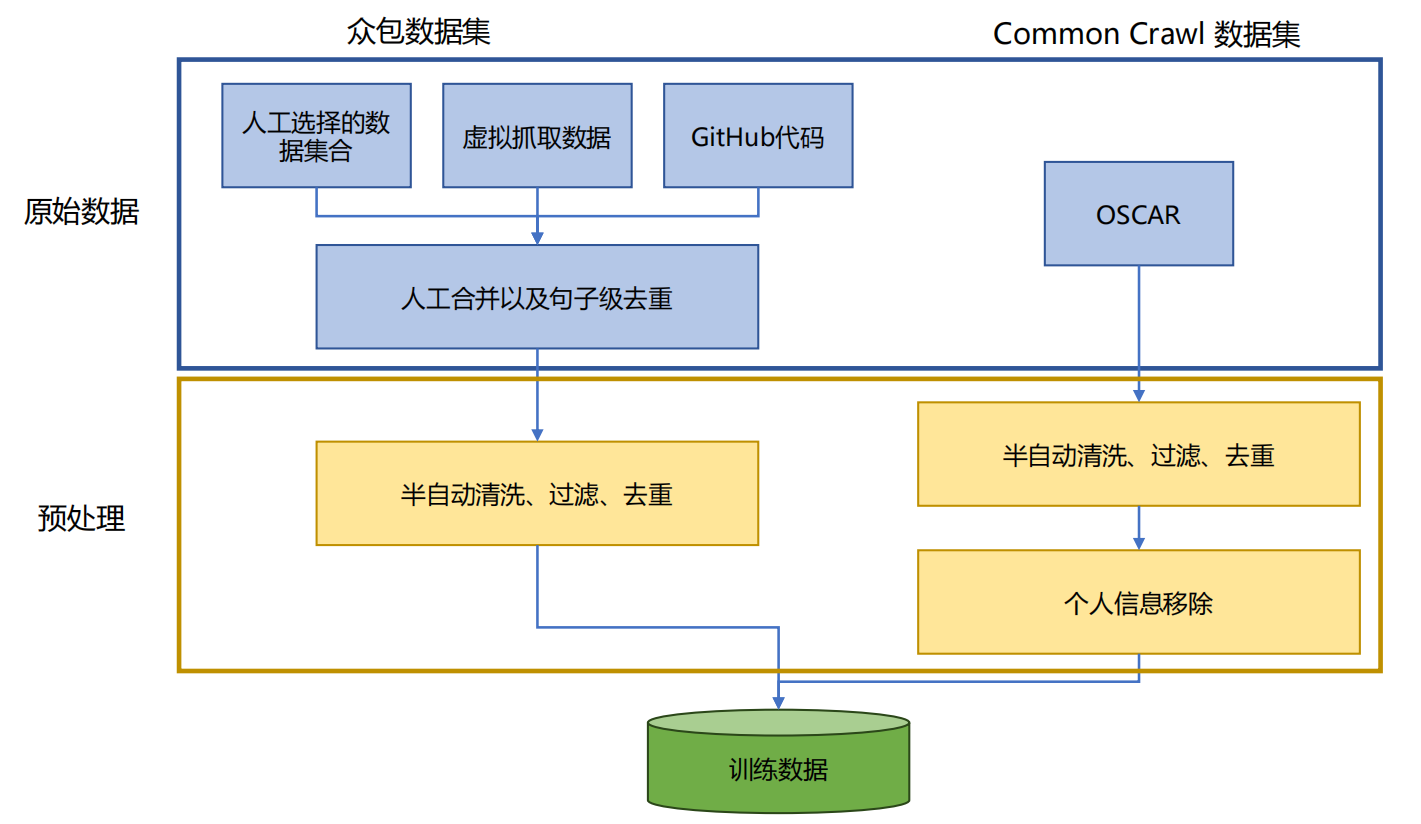
ROOTS 的数据来源十分广泛,主要包括公开语料、虚拟抓取、GitHub 代码和网页数据这四个方面:
- 公开语料:BigScience Data Sourcing 工作组致力于收集尽可能多的各类数据,涵盖自然语言处理数据集和各种文档数据集合,为数据集奠定了坚实的基础。
- 虚拟抓取:通过采用 CommonCrawl 网页镜像,选取 614 个域名,从这些域名下的网页中提取文本内容,进一步丰富了数据的多样性,让数据集能够涵盖更广泛的语言表达和知识领域。
- GitHub 代码:针对程序语言,ROOTS 数据集采用与 AlphaCode 相同的方法,从 BigQuery 公开数据集中精心筛选文件长度在 100 到 20 万字符之间、字母符号占比在 15% 至 65%、最大行数在 20 至 1000 行之间的代码。这些代码数据为大语言模型在编程相关领域的学习提供了专业素材。
- 网页数据:ROOTS 数据集中包含了 OSCAR 21.09 版本,这是 CommonCrawl 在 2021 年 2 月的快照,其占整体 ROOTS 数据集规模的 38%,是数据集中重要的组成部分。
在数据准备完成后,ROOTS 数据集还会进行清洗、过滤、去重及隐私信息删除等工作,以确保数据的高质量和安全性。ROOTS 数据集处理流程如下
三、RefinedWeb 数据集:聚焦高质量数据
RefinedWeb 是由位于阿布扎比的技术创新研究院(Technology Innovation Institute,TII)在开发 Falcon 大语言模型时同步开源的大语言模型预训练集合。它主要由从 CommonCrawl 数据集过滤的高质量数据组成。
RefinedWeb 的处理流程较为复杂,在文档准备阶段,会进行 URL 过滤、文本提取和语言识别三个任务;过滤阶段主要包含重复去除、文档过滤、逐行纠正三个任务;冗余去除阶段包含模糊冗余去除、严格冗余去除及 URL 冗余去除三个任务 。
RefinedWeb 中 CommonCrawl 数据集过滤流程和数据过滤百分比如下
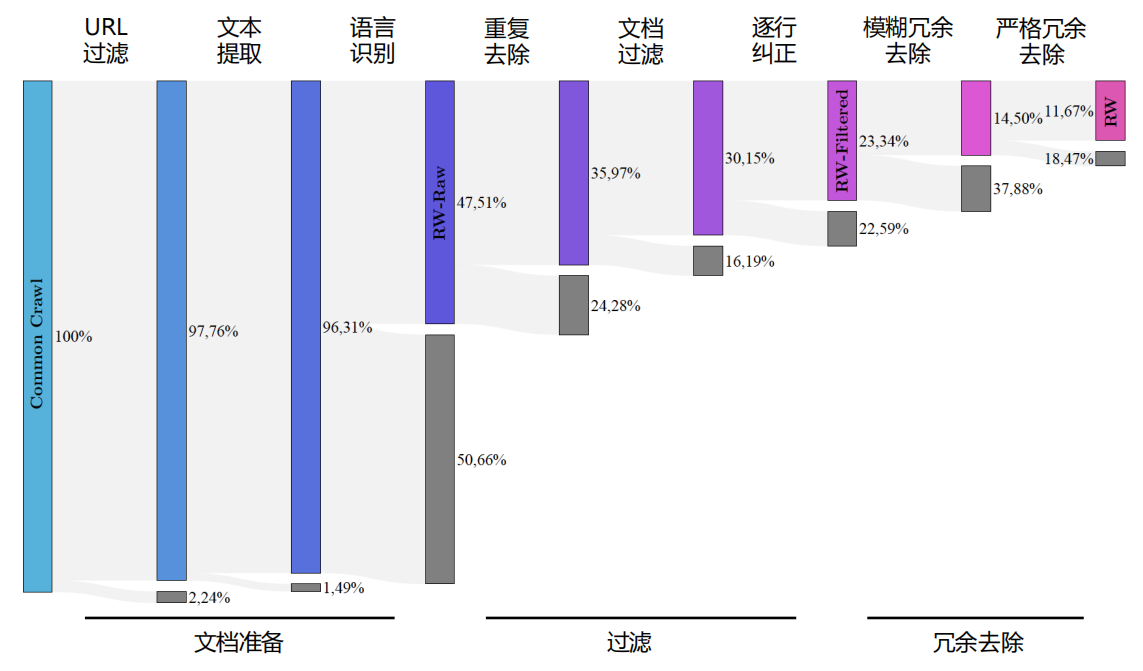
研究人员对三个阶段所产生的数据分别训练 10 亿和 30 亿模型,并使用零样本泛化能力对模型结果进行评测。结果发现 REFINEDWEB 的效果远好于 RW-RAW 和 RW-FILTERED,这充分说明了高质量数据集对语言模型的重要影响,也体现了 RefinedWeb 数据集在提升模型性能方面的优势。
四、SlimPajama 数据集:优化数据质量的实践
SlimPajama 是 CerebrasAI 公司针对 RedPajama 进行清洗和去重后得到的开源数据集。RedPajama 是由 TOGETHER 联合多家公司发起的开源大语言模型项目,它试图严格按照 LLaMA 模型论文中的方法构造大语言模型训练所需数据,本身数据质量较好。SlimPajama 数据集处理过程如下: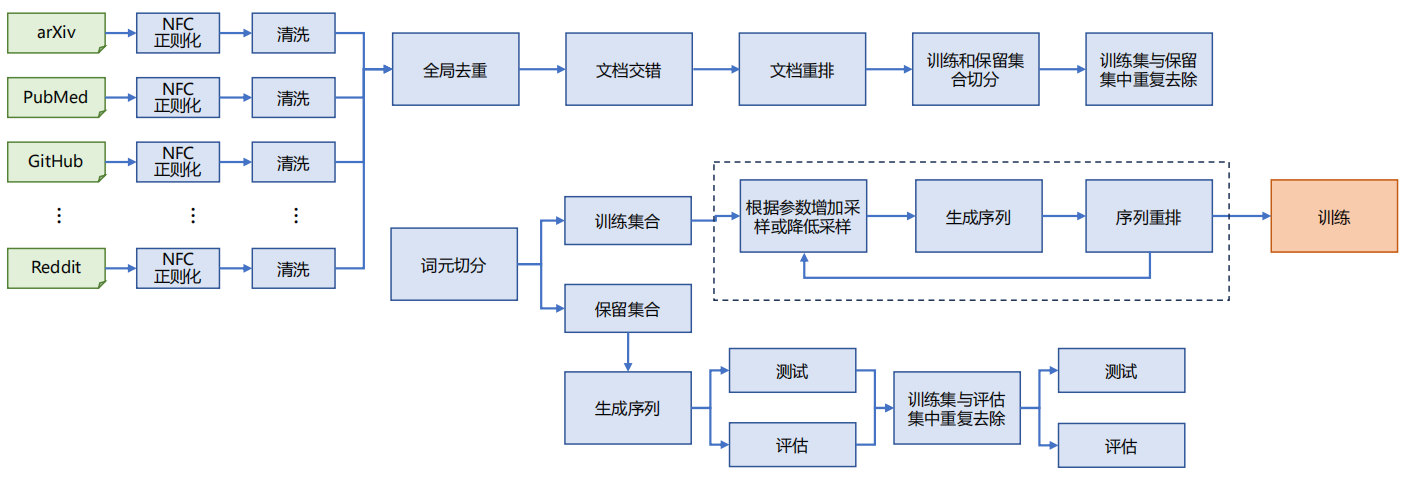
然而,CerebrasAI 的研究人员发现 RedPajama 数据集存在一些问题,比如一些语料中缺少数据文件,并且数据集中包含大量重复数据 。为了解决这些问题,便有了 SlimPajama 数据集。经过处理后的 SlimPajama 数据集包含 670 亿词元(627B Token),并且还开源了用于对数据集进行端到端预处理的脚本。
SlimPajama 的整体处理过程考虑到数据集规模庞大,无法全部装载到内存中,所以分布在多个进程中进行处理。使用 64 个 CPU,大约花费 60 多个小时就可以完成 1.21 万亿词元处理,在整个处理过程中所需要内存峰值为 1.4TB 。这种处理方式高效地解决了大规模数据处理的难题,为其他类似数据集的处理提供了借鉴。
总结
大语言模型的发展离不开这些开源数据集的支持。Pile 数据集的丰富多样、ROOTS 数据集的多语言融合、RefinedWeb 数据集的高质量特性以及 SlimPajama 数据集在数据优化方面的实践,都为大语言模型的训练和性能提升提供了有力保障。随着研究的不断深入,相信会有更多优质的开源数据集涌现,推动大语言模型技术迈向新的高度。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 31
31 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)