赋予具身智能体空间推理能力以实现视觉与语言导航
增强移动机器人的空间感知能力对于实现具身化的视觉与语言导航(VLN)至关重要。尽管在模拟环境中取得了显著进展,但直接将这些能力转移到现实场景中往往会导致严重的幻觉现象,使机器人失去有效的空间意识。为了解决这一问题,我们提出了BrainNav,这是一种受生物空间认知理论和认知地图理论启发的生物启发式空间认知导航框架。BrainNav集成了双地图(坐标地图和拓扑地图)和双方向(相对方向和绝对方向)策略
百倩倩 ⋆{ }^{\star}⋆
罗玲*
223081200055@smail.swufe.edu.cn
223081200059@smail.swufe.edu.cn
西南财经大学 (SWUFE)
中国四川省成都市
摘要
增强移动机器人的空间感知能力对于实现具身化的视觉与语言导航(VLN)至关重要。尽管在模拟环境中取得了显著进展,但直接将这些能力转移到现实场景中往往会导致严重的幻觉现象,使机器人失去有效的空间意识。为了解决这一问题,我们提出了BrainNav,这是一种受生物空间认知理论和认知地图理论启发的生物启发式空间认知导航框架。BrainNav集成了双地图(坐标地图和拓扑地图)和双方向(相对方向和绝对方向)策略,通过动态场景捕捉和路径规划实现实时导航。其五个核心模块——海马记忆中枢、视觉皮层感知引擎、顶叶空间构造器、前额决策中心和小脑运动执行单元——模仿生物认知功能,减少空间幻觉并增强适应性。在使用Limo Pro机器人进行的零样本现实实验室环境中验证,BrainNav兼容GPT-4,无需微调即可超越现有的连续环境视觉与语言导航(VLN-CE)方法。
CCS 概念
- 不使用此代码 →\rightarrow→ 为您的论文生成正确的术语;为您的论文生成正确的术语;为您的论文生成正确的术语;为您的论文生成正确的术语。
关键词
视觉与语言导航、具身人工智能、空间幻觉、模拟到现实、生物启发式导航
1 引言

road_map_dict: {0: [1], 1: [5, 7],5: [9,11]...
32[33, 34, 35, 36]}
思考:根据指示,我已经到达实验室中心,现在需要走向一排椅子。从候选节点的描述来看,图像35显示了一排椅子,位置35是可行走的路径。因此,我应该移向位置35。新规划:1
- 前往位置35并接近一排椅子。
-
- 靠近椅子并移向前门。
-
- 当距离前门小于0.5米时停止。
-
- 动作:B
图1:BrainNav代理在现实世界中的响应演示。根据人类指令,NaVid仅使用当前RGB作为输入,输出供机器人执行的语言动作。
- 动作:B
具身化的视觉与语言导航(VLN)[3] 是人工智能领域的一个关键研究方向,旨在使代理能够使用自然语言指令在复杂环境中导航。尽管近年来基于模拟环境的VLN研究取得了显著进展,但在将模型从模拟转移到现实世界时,具身化代理通常会面临严重的空间幻觉问题[11, 42]。这种现象发生在代理在导航过程中对环境的感知与实际周围环境不一致时,导致有效空间理解的丧失和无法完成导航任务。这些挑战极大地限制了VLN技术在现实世界中的应用,尤其是在动态和不确定环境中。
此外,连续环境中的视觉与语言导航(VLN-CE)扩展了传统的VLN任务,要求代理在连续动作空间和动态环境中导航[46]。与离散网格环境(如AI2-THOR [15])不同,VLN-CE需要在连续空间中导航,其中代理受到真实世界的物理约束(如地形
*两位作者对本研究贡献相等。
允许为个人或课堂教学目的制作本文的数字或硬拷贝,前提是副本不得为盈利或商业优势而制作或分发,并且副本须保留此通知和第一页上的完整引用。必须尊重属于他人而非作者的所有组成部分的版权。摘要附带信用许可。其他形式的复制、重新发布、上传至服务器或分发至列表,需事先获得具体许可和/或费用。请向permissions@ucm.org请求许可。
ACM MM, 2024, 墨尔本,澳大利亚
(c) 2025 版权由所有者/作者持有。出版权利授权给ACM。
ACM ISBN 978-x-xxxx-xxxx-x/YY/MM
https://doi.org/10.1145/umnmnn.umnmnn
和碰撞)以及动态障碍物(如行人和移动门)。这些因素进一步加剧了空间幻觉问题,使得现实世界部署更加困难。
当前视觉与语言导航(VLN)中空间幻觉的主要局限在于具身化代理在环境感知和决策过程中过度依赖单一提示系统。这种依赖导致缺乏多层次环境建模和动态更新能力,使得代理难以在复杂和动态的现实环境中稳定执行导航任务[1, 12, 23]。
- 首先,单一提示系统通常只保留与目标相关的信息,而忽略环境细节。这种遗漏可能导致代理在类似场景中随机选择方向,从而导致路径重复或与障碍物发生碰撞,最终降低导航稳定性。由于难以区分高度相似的现实世界环境,代理在导航任务中可能会变得困惑,影响路径选择的准确性。
-
- 其次,现有方法主要依赖于单一全局地图或局部路径规划策略[7, 29],缺乏对现实世界中空间关系的有效编码。在连续现实世界环境中,代理难以通过整合绝对和相对方向来实现稳定的方位感知,导致空间表示更新延迟。这种延迟进一步影响导航决策的准确性和适应性,使得代理难以灵活应对环境变化并做出适当调整。
- 为了解决这些问题,我们提出了BrainNav,这是一种受生物空间认知理论和认知地图理论[26]影响的生物启发式空间认知导航框架。与传统代理导航系统相比,生物导航系统表现出更强的环境适应能力,能够在动态场景中高效构建和更新空间认知。神经科学研究表明,生物空间认知依赖于海马体、视觉皮层和顶叶的协同工作。海马体通过认知地图编码空间关系,视觉系统提取局部环境特征,顶叶负责动态整合和更新环境信息[30, 36]。
具体来说,BrainNav模拟哺乳动物的多层次空间表示机制,并通过双地图架构(坐标地图和认知地图)复制海马体的路径整合功能。坐标地图对应于内嗅皮层中的网格细胞编码机制,用于精确位置计算。认知地图模拟海马体的场景记忆存储功能,描述环境中的空间关系[14, 24]。此外,我们引入了双方向策略(相对方向和绝对方向),受头部方向细胞和位置细胞的生物特性启发,允许系统
动态整合自我运动线索和环境感知信息[24, 38]。这一设计赋予BrainNav类似于生物神经系统的动态空间表示更新能力,显著增强了其在连续环境中的鲁棒性和适应性。
我们在一个零样本现实世界实验室环境中使用Limo Pro机器人验证了BrainNav。实验结果表明,BrainNav兼容大型模型如GPT-4,无需微调即可显著优于现有的连续环境视觉与语言导航领域的最先进(SOTA)方法。
我们的关键贡献有三点:
- 我们提出了BrainNav,这是第一个生物启发式的分层决策系统,包括海马体记忆模块、视觉皮层感知引擎、顶叶空间构造器、前额决策中心和小脑运动执行单元,提高了代理的空间感知和决策能力。
-
- 具体来说,我们提出了一种双地图双方向导航框架,整合了生物启发式空间认知理论。它结合坐标地图和认知地图进行多层次空间表示,并结合相对方向和绝对方向以增强空间感知。
-
- 在无需微调的情况下,BrainNav在各种导航任务中取得了SOTA结果,显著优于现有方法,充分展示了其在现实世界环境中的优越性。
2 相关工作
2.1 视觉与语言导航
视觉与语言导航 [3, 18, 27] 是具身智能领域的一个关键研究方向,旨在使代理能够基于人类指令和视觉观察在复杂环境中完成导航任务。早期研究主要集中在模拟环境中,其中平台如AI2THOR [15]、Matterport3D [5] 和 Habitat [33] 提供了丰富的3D场景和真实的物理交互,为开发和测试导航算法提供了理想的实验测试平台。近年来,随着大型语言模型 [9, 54] 和视觉语言模型 [8, 20, 47] 的快速发展,基于模拟环境的视觉与语言导航(VLN)研究取得了显著进展。例如,NaviLLM [51] 作为第一个通用的具身导航模型,通过模式化指令统一了多个导航任务,展示了强大的任务泛化能力。DiscussNav [21] 进一步通过引入多领域专家模型之间的协作讨论机制增强了导航性能。同时,NavGPT [52] 和 NavGPT2 [52] 采用两阶段纯文本系统,深度整合了LLM与导航策略网络,有效地弥合了传统VLN模型与基于LLM的导航范式之间的差距。此外,LM-Nav [34] 和 ImagineNav [50] 分别利用地标提取和未来观察生成技术,充分
解锁视觉语言模型的空间感知和规划能力,显著提升了代理的空间理解和决策性能。
然而,这些方法主要侧重于利用模拟器数据来提高性能,常常忽视了现实世界部署的挑战。模拟环境中理想化的假设——如完美的感知、静态的周围环境和高精度的地图——在现实世界场景中往往是不可行的,导致代理在转移到物理环境时性能显著下降。正如研究[11, 31, 43, 48]揭示的那样,大型语言模型(LLMs)在理解空间信息方面存在缺陷,导致代理在现实世界环境中频繁遭遇空间幻觉问题。为了解决这些挑战,我们提出了BrainNav框架,增强了代理的环境理解能力,使其能够在复杂的动态环境中高效构建和实时更新地图。这显著提高了代理在复杂现实场景中的适应性和鲁棒性。
2.2 视觉提示工程
视觉提示工程通过设计有效的视觉提示来增强代理对环境的感知和理解,使用图像作为输入,从而改进其在复杂任务中的表现。早期研究主要依赖于传统的图像处理技术,如边缘检测和特征提取。然而,这些方法的泛化能力有限,难以满足复杂场景的需求。随着[19]引入多模态注意力机制和[28]的工作,通过将图像和文本嵌入到同一语义空间中实现跨模态语义对齐,新的视觉提示设计方法出现了。例如,CLIP[35]证明了标记图像(如画圆)可以帮助模型在没有预先训练的情况下理解图像内容。DPT [45, 53] 引入了动态提示调整策略,能够生成针对特定任务和实例的提示,以适应不同的环境需求。此外,Multimodal-CoT[49] 提出了一个两阶段框架,融合文本和视觉信息以指导多模态推理,从而提升模型性能。SAA+ [4] 将领域特定知识和目标图像中的上下文信息纳入正则化提示技术,改善提示并促进更准确的异常区域识别。
然而,现有方法在灵活性和适应性方面仍面临局限,阻碍了其充分利用视觉信息的潜力,特别是在需要解决多样化需求的复杂导航任务中。在具身化导航任务中,我们创新性地将自然地标、路径标记和相对位置距离等动态元素融入视觉提示的设计中。这种方法帮助代理在未知环境中获得对环境的更深入理解,促进定位和导航。
2.3 带在线制图的导航
带在线制图的导航涉及移动机器人或代理在未知环境中实时构建和更新环境地图,以完成各种具身化导航任务,如点目标导航、对象目标导航和图像目标导航 [44]。根据所构建地图的表示方式,现有方法主要可分为度量地图 [6,13,25][6,13,25][6,13,25] 和拓扑地图。度量地图主要使用显式的几何表示,用点、线和面等几何元素描述环境 [10, 32, 39],或者通过神经网络参数化场景的几何和外观信息 [37, 41, 55]。然而,这些方法高度依赖精确的几何信息,导致存储开销较高,不太适合大规模环境。拓扑地图作为一种替代方案,使用节点和边来表示环境,其中节点表示重要位置或区域,边表示节点之间的连接。拓扑地图更关注环境的连通性而非精确的几何信息。常见方法包括基于图的拓扑制图和导航 [22] 和带有对象级特征的移动机器人语义拓扑制图 [40]。
然而,这些方法通常针对特定任务设计,要求目标以特定格式指定(如姿态、对象类别标签)。在连续环境中的视觉语言导航任务中,如何基于提示构建地图以适应任务规划尚未得到充分探索。为了解决这些问题,本文借鉴生物空间认知映射理论,提出了双地图架构(坐标地图和拓扑地图)以复制海马体的路径整合功能。此外,通过结合双方向策略(相对方向和绝对方向),系统通过相机动态捕获场景图像,匹配坐标,并实时生成和更新多层次路径信息,实现高效和稳健的实时导航。
3 方法论
在本节中,我们将介绍BrainNav的设计架构。如图2所示,包括海马体记忆中心(第3.1节)用于存储和回忆历史信息,视觉皮层感知引擎(第3.2节)用于提取环境数据,顶叶空间构造器(第3.3节)负责空间地图构建,前额决策中心(第3.4节)用于高级任务规划,以及小脑运动执行单元(第3.5节)用于将高级命令转换为精确动作。
3.1 海马体记忆中心
海马体记忆中心在BrainNav框架中扮演两个核心角色:路径回溯和历史经验重用,以及记忆召回。这两个功能显著增强了具身代理的空间认知能力,协助前额决策中心做出更精确的决策,从而优化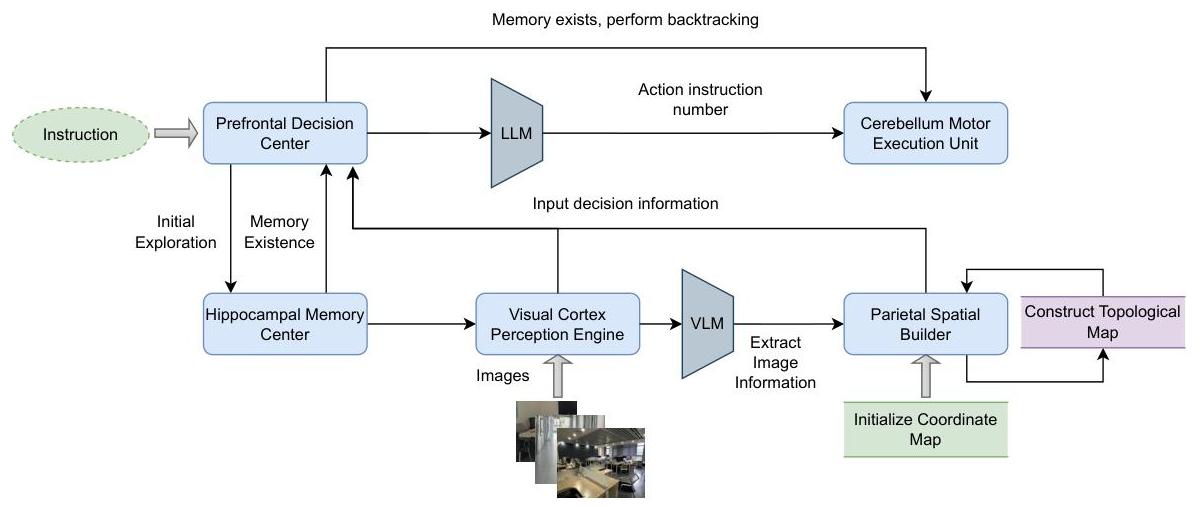
图2:BrainNav的整体架构
代理在复杂环境中的导航效率和适应性。
3.1.1 路径回溯和历史经验重用。海马体记忆中心的主要功能是支持路径回溯和历史经验重用。当代理到达未知位置时,系统检索历史动作记录以辅助路径回溯。每次指令执行后,系统更新历史导航数据,包括运动轨迹、路径选择和环境信息。历史动作序列 HtH_{t}Ht 表示为:
Ht={a1,a2,…,ak} H_{t}=\left\{a_{1}, a_{2}, \ldots, a_{k}\right\} Ht={a1,a2,…,ak}
其中 ata_{t}at 表示单个历史动作,HtH_{t}Ht 是时间步 ttt 的历史动作集合。当代理需要回溯到之前访问过的位置时,系统检查拓扑地图以确认是否存在有效路径。如果找到路径,系统加载历史轨迹并执行相应动作以引导代理回到目标位置。路径回溯过程可以表示为:
Pbacktrack ={a1,a2,…,ak},ai∈Ht P_{\text {backtrack }}=\left\{a_{1}, a_{2}, \ldots, a_{k}\right\}, \quad a_{i} \in H_{t} Pbacktrack ={a1,a2,…,ak},ai∈Ht
通过重用历史数据,代理可以高效规划路径并避免冗余探索已知区域,从而提高导航速度和准确性。
3.1.2 决策中的记忆召回。海马体记忆中心的第二个功能是在决策过程中支持记忆召回。当代理接收到任务信息时,系统检索拓扑地图和历史轨迹以支持决策中心。拓扑地图由字典表示,显示位置之间的连通性,例如:
road_map_dict ={0:[3,4],4:[6,8],6:[9,11,12]}=\{0:[3,4], 4:[6,8], 6:[9,11,12]\}={0:[3,4],4:[6,8],6:[9,11,12]}.
该字典记录了位置之间的连通性,表明位置0连接到位置3和4,位置4连接到位置6和8,依此类推。
此信息帮助代理快速理解环境的连通性。此外,系统还回忆历史轨迹,包括已执行的动作及相关图像信息,例如:
历史:步骤0:左转到位置4(图像4),步骤1:右转到位置6(图像6)
这些被回忆的信息作为决策过程的一部分传递给前额决策中心,帮助代理在动态环境中做出理性决策。通过记忆召回机制,海马体记忆中心显著减少了因空间错觉引起的决策错误,增强了代理的稳定性和适应性。
3.2 视觉皮层感知引擎
视觉皮层感知引擎(VCPE)集成大型语言模型(如GPT-4)分析图像,识别障碍物、可导航路径和地标,同时生成环境的语义描述。其结构化输出为后续模块提供数据支持,确保机器人基于全面的环境感知做出决策。
3.2.1 多层次决策机制。现有的单一专家系统(如MapGPT [7])直接使用GPT-4V作为核心决策模块来处理多模态信息并生成导航决策。虽然这种方法在仿真环境中有效地降低了成本并取得了良好的性能,但在现实世界环境中往往会导致空间错觉,导致有效的空间感知丢失。仿真环境中的导航任务被简化。如果目标存在或可能存在于下一个环境中,代理可以直接朝目标移动。相比之下,在现实世界环境中,代理在从一个位置移动到另一个位置时需要精确的方向控制和动作执行。此外,现实世界环境中的导航是一个连续过程,代理通过相机感知的环境可能是同一场景的不同视角,这些视角可能非常相似。单一专家系统通常忽略详细的环境分析,导致代理随机选择方向,可能与障碍物发生碰撞或重复探索同一区域。缺乏详细的图像信息阻止了代理有效规划路径,影响导航效率和方向感。
相比之下,本文提出的分层决策机制通过模块化设计和多级别的感知与决策分离,提高了代理在复杂环境中的导航能力。关键特点包括:(1) 分层决策过程。复杂的导航任务被分解为五个模块,每个模块专注于特定任务,确保高效运行并避免信息丢失。(2) 多级别细粒度视觉信息提取。大型语言模型分析多方向场景图像,提取障碍物、可行走路径和地标的信息,这增强了代理的空间感知能力,并避免了因信息不足而导致的障碍物碰撞或重复探索。(3) 多模态信息融合。分层决策机制通过大型语言模型整合视觉、历史数据、路径信息和任务描述,形成对环境的深刻理解,并提供丰富的上下文信息以确保在动态环境中准确决策。
3.2.2 场景图像处理和多模态信息提取。视觉皮层感知引擎(VCPE)从机器人周围的四个方向捕捉场景图像,并将其与分析提示一起输入大型语言模型(LLM)以提取路径规划和决策所需的关键信息。具体而言,它包括图像信息捕捉、物体识别和清单生成、可行走路径标记和相对距离估计。例如,VCPE可以识别图像中的“蓝色垃圾桶”或“纸板箱”等物体,并标记可行走路径如“可行走路径”,表示路径节点之间的可行走区域(例如,道路:[17, 19])。同时,模型估计机器人与物体之间的相对距离,如“image17距离当前位置约2.5米”,为路径规划提供空间信息。通过这种处理,VCPE生成结构化的语义输出,不仅包括图像分析结果,还包括深入理解的环境信息,如路径节点序列和障碍物距离,支持高效的导航决策。
3.3 顶叶空间构造器
顶叶空间构造器(PSB)结合坐标地图和拓扑地图进行环境建模。坐标地图提供精确的位置信息,而拓扑地图描述环境内的连通性。它们共同作用以支持感知、规划和导航。
3.3.1 坐标地图的构建和更新。坐标地图基于机器人的运动轨迹构建。每次移动都会更新当前位置周围的四个候选点,并记录在地图中。机器人的初始位置定义为(x0,y0)=\left(x_{0}, y_{0}\right)=(x0,y0)= (0,0)(0,0)(0,0),在任意给定时间,其当前位置为(xc,yc)\left(x_{c}, y_{c}\right)(xc,yc)。四个候选点表示为:
(xi,yi)=(xc+Δxi,yc+Δyi),i∈{0,1,2,3} \left(x_{i}, y_{i}\right)=\left(x_{c}+\Delta x_{i}, y_{c}+\Delta y_{i}\right), \quad i \in\{0,1,2,3\} (xi,yi)=(xc+Δxi,yc+Δyi),i∈{0,1,2,3}
其中Δxi,Δyi\Delta x_{i}, \Delta y_{i}Δxi,Δyi表示在不同方向上移动一个单位时的坐标增量。候选点的计算取决于机器人的方向θ\thetaθ,方向向量由以下公式确定:
D(θ)={(cos(θ),sin(θ)),(cos(θ+90∘),sin(θ+90∘)),(cos(θ+180∘),sin(θ+180∘)),(cos(θ+270∘),sin(θ+270∘))} D(\theta)=\left\{\begin{array}{l} \left(\cos (\theta), \sin (\theta)\right), \\ \left(\cos \left(\theta+90^{\circ}\right), \sin \left(\theta+90^{\circ}\right)\right), \\ \left(\cos \left(\theta+180^{\circ}\right), \sin \left(\theta+180^{\circ}\right)\right), \\ \left(\cos \left(\theta+270^{\circ}\right), \sin \left(\theta+270^{\circ}\right)\right) \end{array}\right\} D(θ)=⎩ ⎨ ⎧(cos(θ),sin(θ)),(cos(θ+90∘),sin(θ+90∘)),(cos(θ+180∘),sin(θ+180∘)),(cos(θ+270∘),sin(θ+270∘))⎭ ⎬ ⎫
例如,当θ=0∘\theta=0^{\circ}θ=0∘(面向前方)时,方向向量为{(0,1),(1,0),(0,−1),(−1,0)}\{(0,1),(1,0),(0,-1),(-1,0)\}{(0,1),(1,0),(0,−1),(−1,0)}。
每次移动或旋转后,系统使用以下公式更新候选点坐标和方向:
θi=(θ+i×90) mod 360 \theta_{i}=(\theta+i \times 90) \quad \bmod 360 θi=(θ+i×90)mod360
此外,每个候选点都被分配一个唯一的ID,由一个全局变量在整个探索过程中动态增加维护。
3.3.2 拓扑地图的构建和更新。拓扑地图表示为图 G=(V,E)G=(V, E)G=(V,E),其中 VVV 表示环境中的关键位置,EEE 表示可通行路径。当机器人访问新位置 viv_{i}vi 时,它被添加到节点集中,并更新邻接表如下:
E=E∪{(vc,vi)} E=E \cup\left\{\left(v_{c}, v_{i}\right)\right\} E=E∪{(vc,vi)}
如果 viv_{i}vi 尚未包含在图 GGG 中,则将其添加到节点集 VVV 中以保持空间结构完整性。
拓扑地图基于路径可通行性动态更新。每次探索新的可通行路径时,系统更新路径映射:
KaTeX parse error: Expected 'EOF', got '_' at position 14: \text { road_̲graph }\left[v_…
更新后的信息存储在全球路径映射 road_map_dict 中,以支持未来的路径规划。在导航过程中,机器人根据拓扑连通性选择最佳候选点,优化路径规划策略。
3.4 前额决策中心
前额决策中心(PDC)模拟人类前额皮质的高级决策功能,负责根据输入信息生成高层次任务规划和行动策略。PDC接收来自多个模块的输入,包括海马体记忆中心提供的历史任务信息、视觉皮层感知引擎提取的环境数据以及顶叶空间构造器生成的空间地图信息。此外,小脑运动执行单元提供预定义的指令映射表,确保生成的指令与代理的执行单元兼容。这些输入共同构成了PDC决策过程所需的上下文数据。PDC利用大型语言模型(如GPT-4)全面处理当前任务描述、空间地图、环境信息和历史数据,生成行动思路和行动计划。最终,PDC的输出不仅包括当前任务的决策结果,还包括下一步行动的具体计划和可执行指令代码。此指令代码精确指定了具身代理需要执行的具体动作,确保代理能够根据环境变化和任务需求在复杂和动态环境中做出有效决策并准确执行动作。
3.5 小脑运动执行单元
小脑运动执行单元(CMEU)模拟小脑的运动协调功能,确保由前额决策中心生成的运动指令能够准确执行。它将高层自然语言指令转换为低层机器人动作。
3.5.1 宏动作转换。CMEU使用预定义的宏集将高层指令(如“前进”、“左转”、“回退”等)转换为可执行的低层动作。这些宏动作通过标准化设计,例如将“前进”命令转换为具体的电机控制信号以驱动机器人移动,或将“左转”命令转换为旋转动作以调整机器人的方向。这些预定义的宏动作提高了执行效率,简化了命令解析,并确保机器人在各种环境中精确移动。
3.5.2 绝对方向和相对方向。CMEU的运动控制基于绝对方向和相对方向的结合。绝对方向指的是机器人相对于固定坐标系(例如,全局地图的xxx轴和yyy轴)的方向,通常以度数表示(例如,0∘0^{\circ}0∘代表北,90∘90^{\circ}90∘代表东,180∘180^{\circ}180∘代表南,270∘270^{\circ}270∘代表西)。相对方向则是指机器人相对于其当前方向的方向。例如,当机器人面向北方时,“左”表示西方,“右”表示东方。在执行前额决策中心的指令时,CMEU主要使用相对方向,将“前进”、“后退”、“左”和“右”等相对方向绑定到具体动作。
在回溯过程中,CMEU依赖绝对方向以减少空间幻觉。具体而言,机器人根据目标视点与当前视点在xxx轴和yyy轴上的坐标差值确定移动方向,计算公式为Δx=xtarget −xcurrent \Delta x=x_{\text {target }}-x_{\text {current }}Δx=xtarget −xcurrent 和Δy=ytarget −ycurrent. \Delta y=y_{\text {target }}-y_{\text {current. }}Δy=ytarget −ycurrent. 。结合当前绝对方向Hcurrent H_{\text {current }}Hcurrent ,机器人计算偏移角度Δθ\Delta \thetaΔθ。例如,若Δx>0\Delta x>0Δx>0,
表示沿正xxx轴移动,偏移角度为Δθ=90∘\Delta \theta=90^{\circ}Δθ=90∘。然后机器人将其绝对方向更新为Hnew =(Hcurrent +Δθ) mod 360∘H_{\text {new }}=\left(H_{\text {current }}+\Delta \theta\right) \bmod 360^{\circ}Hnew =(Hcurrent +Δθ)mod360∘。通过这一过程,机器人逐步沿着回溯路径执行动作,更新其方向,并最终到达目标视点。
4 实验
为了验证提出的仿生空间认知导航框架(BrainNav)在现实世界环境中的有效性,设计并实施了一系列现实世界实验。实验旨在评估BrainNav在具身化视觉-语言导航(VLN)任务中的性能,尤其是在零样本学习设置下。
4.1 实验设置
4.1.1 机器人设置。在本研究中,我们使用了AgileX Limo PRO移动机器人进行实验,其外部尺寸为322×220×251 mm322 \times 220 \times 251 \mathrm{~mm}322×220×251 mm。机器人配备了一个Orbbec DaBai相机以捕捉当前观察的RGB图像。相机安装在Limo PRO机器人前面,距地面约17厘米,捕捉的RGB图像分辨率为640×480×3640 \times 480 \times 3640×480×3像素。我们实现了五种基本动作:“前进”使机器人前进0.5厘米,“后退”使机器人底座旋转180度并后退0.5厘米,“左转”和“右转”分别使机器人底座旋转90度,“停止”使机器人保持静止。需要注意的是,我们的实验框架仅依赖于RGB图像,不依赖任何算法、深度图像、LiDAR或其他传感器信息,使其易于在现实世界环境中部署。
4.1.2 基线。我们选择MapGPT [7]作为基线模型,主要因为它最接近我们的研究目标。MapGPT通过将地图拓扑关系转换为文本提示系统地探索多个潜在目标,构建地图信息以指导GPT进行全局探索,并使用其自适应规划机制激活GPT的多步路径规划能力,以解决VLN-CE任务(连续环境中的视觉与语言导航)[17]。然而,MapGPT的实验仅在模拟器中进行,具有某些理想化的假设,这限制了其在现实世界环境中的直接适用性。相比之下,我们的方法提供了两个关键优势:(1)它不依赖模拟器进行训练,(2)像MapGPT一样,它在现实世界环境中不需要额外的微调。这些特性赋予BrainNav在实用性和泛化能力方面的显著优势。
我们使用四种标准视觉与语言导航指标来评估我们方法在具身化导航任务中的性能[16]。轨迹长度(TL)表示机器人在完成导航任务期间所采取路径的平均长度,以步数衡量。导航误差(NE)测量机器人停止位置与目标点之间的平均距离,也以米为单位。成功率(SR)表示机器人成功停在距离目标点1米范围内的比例。此阈值设置为有效平衡导航精度和空间尺度。加权路径长度的成功率(SPL)是一种效率指标,定义在[2]中,给出如下公式:
SPL=1N∑i=1Nsi⋅limax(pi,li) \mathrm{SPL}=\frac{1}{N} \sum_{i=1}^{N} s_{i} \cdot \frac{l_{i}}{\max \left(p_{i}, l_{i}\right)} SPL=N1i=1∑Nsi⋅max(pi,li)li
其中NNN表示事件总数,SiS_{i}Si是事件iii的二进制成功指示器(成功为1,失败为0),lil_{i}li是从起始位置到目标位置的最短路径距离,pip_{i}pi是机器人在实际导航过程中经过的路径长度。SPL值越高,表示机器人导航效率越高。
4.1.3 环境设置。实验在ROS 2 Foxy Fitzroy环境中进行和管理。实验场景涵盖了各种室内环境,如图3所示,包括实验室、走廊、会议室和开放区域,以测试所提方法对不同空间布局和语义的适应性。多样化的环境用于评估我们方法在处理不同空间配置和语义上下文方面的鲁棒性。
(a) 会议室
© 开放区域
(d) 实验室
图3:现实世界场景。
4.2 实验结果
总共设置了50个不同难度水平的命令,分为25个简单命令和25个复杂命令,其中一些详细列于表1。每个命令执行5次,取平均值作为最终实验数据。为了保持环境的真实性,在机器人和目标物体之间的路径上随机添加障碍物,以评估机器人在复杂环境中的导航性能。
4.2.1 简单指令任务。简单指令主要分为路径导航和目标搜索导航。路径导航要求机器人执行基本的路径规划任务,而目标搜索导航则着重评估机器人识别和定位单个目标物体的能力。在目标搜索导航任务中,目标物体随机放置在机器人周围5米范围内的不同位置,以测试其对各种空间布局的适应能力。
如表2所示,相同的简单指令(15条指令)用于评估不同场景下的零样本性能。在目标搜索导航任务中,BrainNav的成率为87.5%87.5 \%87.5%,显著优于MapGPT的0%0 \%0%。这类任务依赖于机器人识别和定位目标物体的能力。BrainNav通过其视觉皮层感知模块(gpt-4-vision-preview)提取场景的关键特征,并结合前额决策模块(gpt-4o-2024-05-13)生成行动策略。这使得有效识别目标物体并动态调整导航路径成为可能,从而使机器人逐渐接近目标。相比之下,MapGPT的导航策略导致机器人在接近目标附近时提前终止导航,无法完成精确的目标搜索任务。
对于基于路径的导航任务,BrainNav的成率为71%71 \%71%,SPL为55%55 \%55%。这些任务更强调全局路径规划和环境适应能力。尽管BrainNav采用了双地图策略(坐标地图和拓扑地图)和双方向策略(相对方向和绝对方向),但由于大型模型的空间推理能力有限,当环境变化细微时,机器人可能会陷入局部探索,这降低了成功率并导致较长的导航路径,从而影响SPL指标。相比之下,由于MapGPT依赖于模拟器中的理想化假设,缺乏在现实世界环境中的适应能力,导致在简单指令任务中的成功率较低。显然,我们提出的仿生空间认知和分层决策机制显著减少了空间幻觉现象,增强了代理在现实世界环境中的适应能力。BrainNav在目标搜索和基于路径的导航任务中的出色表现展示了其在现实世界场景中的实用性和泛化能力。
4.2.2 复杂指令任务。复杂指令的特点是任务的高复杂性,机器人无法从初始位置直接观察到目标位置,必须逐步探索并调整路径以完成任务。基于任务特征,复杂指令主要分为以下四类:多步导航、动态障碍物规避、多目标搜索和环境交互。这些类别全面测试了机器人在现实世界环境中的整体性能。我们在表3中定量展示了所提方法的结果,并与基线模型MapGPT进行了比较。
请移动到实验室中心的交叉口,然后右转并移动到一排椅子处,最后走到前门。
图4:现实世界探索中复杂指令的成功案例。我们提供了机器人的视角和第三人称视角,展示其有效的多任务导航能力。
结果显示,即使没有预先构建的地图,我们的方法通过借鉴生物空间认知理论和认知地图理论实时构建感知地图,也能处理长距离导航任务。BrainNav在复杂指令任务中显著优于基线模型MapGPT。
在多步导航任务中,BrainNav通过整合视觉皮层感知模块和前额决策模块,无需依赖全局地图即可有效构建局部地图并进行路径规划和调整。这种方法使机器人能够在复杂环境中逐步接近目标位置。尽管轨迹长度(TL)较长,但成功率(SR)和按路径长度加权的成功率(SPL)仍保持在高水平。
在动态障碍物规避任务中,BrainNav实现了显著的87.5%的成功率,显著优于其他任务类别。特别是,机器人不依赖传统的雷达基础障碍物规避方法。相反,它利用仿生空间认知导航框架(BrainNav)中各模块的协同互动,有效规避障碍物并实现自主导航。这一突破性表现
进一步验证了结合视觉感知与仿生决策机制的有效性,为动态环境中的自主导航提供了新的解决方案。
多目标搜索任务要求机器人在同一环境中依次定位多个目标物体。为此,BrainNav利用海马体记忆模块存储和检索历史动作信息,并结合前额决策模块生成多目标搜索策略。然而,由于目标物体可能存在分散的空间分布,机器人在某些情况下可能会经历路径冗余,导致轨迹长度增加或陷入局部最优路径,阻止其依次接近目标。
在不同导航类别中,环境交互任务的成功率(SR)仅为25%,显著低于其他任务类别。这些任务要求机器人在导航过程中跟随人到达指定位置。虽然看似简单,但复杂性在于机器人需要实时感知和适应人的运动轨迹。由于人类运动的高度随机性和不可预测性,机器人可能会偏离路径或在跟随过程中失去目标,导致任务失败。尽管BrainNav在路径规划和动态障碍物规避方面表现出色
表1:命令分为简单(1 - 6)和复杂(7 - 15),并突出相应的导航任务。
| 编号 | 类别 | 指令 |
|---|---|---|
| 1 | 定位搜索导航 | 找到蓝色垃圾桶。 |
| 2 | 定位搜索导航 | 走向放置花盆的桌子。 |
| 3 | 定位搜索导航 | 移向灰色窗帘。 |
| 4 | 路径导航 | 走到左前方的柜子。 |
| 5 | 路径导航 | 在箱子和椅子之间移动。 |
| 6 | 路径导航 | 移动到房间中央并停止。 |
| 7 | 多目标导航 | 请先沿着走廊走到蓝色垃圾桶,然后寻找一盆绿色植物,最后在楼梯旁停下。 |
| 8 | 多目标导航 | 首先,前往实验室中心的十字路口,然后右转并移动到一排椅子,最后走到主入口。 |
| 9 | 多目标导航 | 请先走到窗户旁边,然后继续前往一张椅子。 |
| 10 | 多步导航 | 进入会议室后,首先直走到第三步,然后右转绕过桌子。 |
| 11 | 多步导航 | 沿着走廊前进,经过一间房间,然后右转进入实验室的主门。 |
| 12 | 多步导航 | 请按照以下步骤操作:前进,后退,左转,右转,然后停下来。 |
| 13 | 障碍规避导航 | 左转以避开障碍物以找到蓝色垃圾桶。 |
| 14 | 障碍规避导航 | 绕过箱子并找到椅子上的书。 |
| 15 | 交互导航 | 找到一个人并跟随他们。 |
表2:单指令任务下的实验结果。
| 方法 | 路径导航 | 定位搜索导航 | ||||||
|---|---|---|---|---|---|---|---|---|
| NE ↓\downarrow↓ | TL ↓\downarrow↓ | SR ↑\uparrow↑ | SPL ↑\uparrow↑ | NE ↓\downarrow↓ | TL ↓\downarrow↓ | SR ↑\uparrow↑ | SPL ↑\uparrow↑ | |
| BrainNav | 0.69 | 6.52 | 71 | 55 | 0.60 | 7.96 | 88 | 89 |
| MapGPT[7] | 2.95 | 4.52 | 14 | 6 | 3.27 | 3.25 | 0 | 0 |
任务通过其仿生空间认知框架,其在需要同时跟随和障碍规避的任务中的表现仍需改进。这一结果表明未来研究应着重优化机器人的目标跟踪能力和动态路径规划策略,以增强其在复杂环境中的整体性能。
4.2.3 回溯率。回溯率通过分析每个案例的轨迹计算得出。如果机器人重新访问之前访问过的位置,则视为回溯。表4展示了BrainNav与MapGPT之间的回溯率和回溯成功修正率(BSCR)比较。
BrainNav的回溯率为 10%10 \%10%,显著低于MapGPT的 75%75 \%75%。这表明BrainNav在导航过程中较少依赖回溯机制来纠正路径
表3:复杂指令任务下的实验结果
| 方法 | 多步 | 规避 | 多目标 | 交互 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NE ↓\downarrow↓ | TL ↓\downarrow↓ | SR ↑\uparrow↑ | SPL ↑\uparrow↑ | NE ↓\downarrow↓ | TL ↓\downarrow↓ | SR ↑\uparrow↑ | SPL ↑\uparrow↑ | NE ↓\downarrow↓ | TL ↓\downarrow↓ | SR ↑\uparrow↑ | SPL ↑\uparrow↑ | NE ↓\downarrow↓ | TL ↓\downarrow↓ | SR ↑\uparrow↑ | SPL ↑\uparrow↑ | ||
| BrainNav | 0.53 | 19.67 | 67 | 55 | 0.32 | 11.17 | 87.5 | 72 | 2.95 | 16.78 | 35 | 28.5 | 1.74 | 7.45 | 25 | 26.4 | |
| MapGPT[7] | 3.71 | 9.21 | 0 | 0 | 4.43 | 10.60 | 0 | 0 | 3.78 | 12.5 | 0 | 0 | 1.13 | 13.78 | 8 | 3 |
表4:回溯率和回溯成功修正率比较
| 方法 | BTR | BSCR |
|---|---|---|
| BrainNav | 10%\mathbf{1 0 \%}10% | 73.3%\mathbf{7 3 . 3 \%}73.3% |
| MapGPT[7] | 75%75 \%75% | 0%0 \%0% |
在导航过程中。然而,当回溯确实发生时,BrainNav有 73.3%73.3 \%73.3% 的概率成功修正导航路径,从而能够到达目标位置,从而显著提高任务成功率。这种性能归因于BrainNav的仿生空间认知框架,该框架实时更新环境信息并动态调整路径规划策略。相比之下,MapGPT表现出更高的回溯率,但其回溯成功修正率为 0%0 \%0%。这表明虽然MapGPT在导航过程中频繁需要回溯,但无法有效修正其路径。尽管MapGPT在模拟环境中表现出更好的回溯能力,但在直接过渡到现实世界场景时,环境的复杂性和动态性导致严重的幻觉现象,阻止MapGPT正确执行回溯机制。
4.3 案例研究
在图4中,我们展示了机器人根据指令完成一系列导航动作的过程:‘请移动到实验室中心的交叉口,然后右转并移动到一排椅子处,最后走到前门。’ 这个例子属于高复杂度指令中的多目标搜索类别,对BrainNav构成了重大挑战。机器人需要在一个狭小的空间内进行多次转弯,并准确识别和定位目标位置(例如交叉口、椅子和门)。
在本案例研究中,BrainNav的各个模块协同高效地完成了导航任务。接收到指令后,系统首先查询海马体记忆中心以检索与当前任务相关的任何历史路径信息。如果存在此类信息,系统直接调用小脑控制模块执行存储的路径规划,从而减少计算开销。在此案例中,由于是第一次探索实验室环境,未检索到相关的历史信息,促使系统启动皮层感知引擎。该引擎利用机器人的视觉传感器捕捉实时环境图像并提取周围
物体(如墙壁、红色门、椅子、白色背包等)的特征以及场景中物体与机器人之间的相对距离。这些信息用于构建环境的语义地图,为后续路径规划提供基础数据。随后,顶叶空间生成器基于感知引擎提供的数据构建并更新实验室的双地图表示(坐标地图和拓扑地图),提供支持高效路径规划的多层次环境表示。前额决策中心根据指令生成分步导航策略,包括:(1) 从起点移动到实验室中心的交叉口;(2) 在交叉口右转并移动到椅子处;(3) 在椅子处左转并移动到主门,确保逐步实现任务目标。最后,小脑运动执行单元将高层导航命令转换为具体的运动控制信号,包括前进、转弯和停止。通过精确的运动控制,机器人能够在狭小空间内进行多次转弯并准确停在目标位置。经过一系列迭代步骤后,机器人成功完成了从起点到交叉口、椅子和主门的导航任务,验证了BrainNav在复杂环境中的导航能力和任务执行效率。
5 结论
本文提出了BrainNav,这是一种受生物启发的分层决策框架,通过神经科学启发的多模块协作架构(海马体记忆、视觉皮层感知、顶叶空间构造、前额策略规划和小脑运动控制)处理视觉与语言导航(VLN)任务。实验表明,我们的方法在现实世界导航任务中实现了最先进的(SOTA)性能,取得了两个关键突破:1)提出绝对-相对方向融合机制,有效解决了从模拟器转移到现实世界场景时的空间错觉问题;2)设计混合地图(坐标地图+拓扑地图)以增强空间认知的鲁棒性。
然而,当前研究存在两个局限性:首先,在涉及多个对象参考(+3地标)的复合指令场景中,成功率显著下降(与单地标或更少地标任务相比);其次,动态障碍环境中的长期导航稳定性仍然不足。未来工作将集中于增强多模态语义理解和优化动态环境适应能力。
参考文献
[1] Michael Ahn, Debidatta Dwibedi, Chelsea Finn, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Karol Hausman, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, et al. 2024. Autort: Embodied foundation models for large scale orchestration of robotic agents. arXiv preprint arXiv:2401.12963 (2024).
[2] Peter Anderson, Angel Chang, Devendra Singh Chaplot, Alexey Douvitskiy, Saurabh Gupta, Vludlen Koltun, Jana Kosecka, Jitendra Malik, Rouzbeh Mottaghi, Manolis Savva, et al. 2018. On evaluation of embodied navigation agents. arXiv preprint arXiv:1807.06757 (2018).
[3] Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sinderhard, Ian Reid, Stephen Gould, and Anton Van Den Hengel. 2018. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In Proceedings of the IEEE conference on computer vision and pattern recognition, 3674-3683.
[4] Yunkang Cao, Xiaohan Xu, Chen Sun, Yuqi Cheng, Zongwei Du, Liang Gao, and Weiming Shen. 2023. Segment any anomaly without training via hybrid prompt regularization. arXiv preprint arXiv:2305.10724 (2023).
[5] Angel Chang et al. 2017. Matterport3D: Learning from RGB-D Data in Indoor Environments. arXiv preprint arXiv:1709.06158 (2017).
[6] Devendra Singh Chaplot, Dhiraj Gandhi, Saurabh Gupta, Abhinav Gupta, and Ruslan Salakhutdinov. 2020. Learning to explore using active neural slam. arXiv preprint arXiv:2004.05155 (2020).
[7] Jiaqi Chen, Bingqian Lin, Ran Xu, Zhenhua Chai, Xiaodan Liang, and Kwan-Yee K Wong. 2024. Maggpt: Map-guided prompting for unified vision-and-language navigation. arXiv e-prints (2024), arXiv-2401.
[8] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xiifuou Zhu, Lewei Lu, et al. 2024. Internv0. Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 24185-24198.
[9] Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yongluo Zhuang, Joseph E Gonzales, et al. 2023. Vicuna: An open-source chatbot improving gpt-4 with 90%90 \%90% " chatgpt quality. See https://vicuna. Imeys. org (accessed 14 April 2023) 2, 3 (2023), 4.
[10] Adam Dai, Greg Lund, and Grace Gao. 2022. Planeslam: Plane-based LiDAR SLAM for motion planning in structured 3D environments. arXiv preprint arXiv:2209.08248 (2022).
[11] Peng Gao, Peng Wang, Feng Gao, Fei Wang, and Buyuy Yuan. 2024. Vision-Language Navigation with Embodied Intelligence: A Survey. arXiv preprint arXiv:2402.14304 (2024).
[12] Siyuan Huang, Zhenghai Jiang, Hao Dong, Yu Qiao, Peng Gao, and Hongsheng Li. 2023. InstructGact: Mapping multi-modality instructions to robotic actions with large language model. arXiv preprint arXiv:2305.11176 (2023).
[13] Peter Karkus, Shaojun Cai, and David Hsu. 2021. Differentiable slamnet: Learning particle slam for visual navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 28132825.
[14] Minun Kim and Eleanor A Maguire. 2019. Can we study 3D grid codes non-invasively in the human brain? Methodological considerations and MRI findings. Neurolmage 184, 20195, 667-678.
[15] Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weibo, Alvaro Herrasti, Matt Dotke, Kiana Ehuani, Daniel Gordon, Yuke Zhu, et al. 2017. Ai2-thor: An interactive 3d environment for visual ai. arXiv preprint arXiv:1712.05474 (2017).
[16] Jacob Krantz, Stefan Lee, Jitendra Malik, Dhruv Batra, and Devendra Singh Chaplot. 2022. Instance-specific image goal navigation: Training embodied agents to find object instances. arXiv preprint arXiv:2211.13876 (2022).
[17] Jacob Krantz, Erik Wijnsans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. 2020. Beyond the nav-graph: Vision-and-language navigation in continuous environments. In Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XXVIII 16. Springer, 104-120.
[18] Alexander Ku, Peter Anderson, Roma Patel, Eugene le, and Jason Baldridge. 2020. Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding. arXiv preprint arXiv:2010.07954 (2020).
[19] Federico Landi, Lorenzo Baraldi, Marcella Cornia, Massimiliano Corsini, and Rita Cucchiara. 2021. Multimodal attention networks for low-level vision-and-language navigation. Computer vision and image understanding 210 (2021), 103255.
[20] Haotian Liu, Chonyuan Li, Qingyang Wu, and Yong Jie Lee. 2023. Visual instruction tuning. Advances in neural information processing systems 36 (2023), 34892-34916.
[21] Yuxing Long, Xiaogi Li, Wenzhe Cai, and Hao Dong. 2024. Discuss before moving: Visual language navigation via multi-expert discussions. In 2024 IEEE International Conference on Robotics and Automation (ICRA).
IEEE, 17380-17387.
[22] Laurin Lux, Alexander H Berger, Alexander Weers, Nico Stucki, Daniel Rueckert, Ulrich Bauer, and Johannes C Paetzold. 2024. Topograph: An efficient Graph-Based Framework for Strictly Topology Preserving Image Segmentation. arXiv preprint arXiv:2411.03228 (2024).
[23] Jacob P Macdonald, Robit Mallick, Allan B Woldwin, Jaime D Peña, Nathan McNesse, and Ho Chit Siu. 2024. Language, camera, autonomy! prompt-engineered robot control for rapidly evolving deployment. In Companion of the 2024 ACM/IEEE International Conference on HumanRobot Interaction. 717-721.
[24] Edvard I Moser, Emilio Kropll, and May Britt Moser. 2008. Place cells, grid cells, and the brain’s spatial representation system. Annu. Rev. Neurosci. 31, 1 (2008), 69-89.
[25] Raul Mur-Artal, Jose Maria Martinez Montiel, and Juan D Tardos. 2015. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE transactions on robotics 31, 5 (2015), 1147-1163.
[26] Michael O’Neill. 1991. A biologically based model of spatial cognition and wayfinding. Journal of Environmental Psychology 11, 4 (1991), 299-320.
[27] Yuankai Qi, Qi Wu, Peter Anderson, Xin Wang, William Yang Wang, Chunhua Shen, and Anton van den Hengel. 2020. Reverse: Remote embodied visual referring expression in real indoor environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9982-9991.
[28] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastre, Amanda Askell, Pamela Niskkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning. PMLR, 8748-8763.
[29] Krishan Rana, Jesse Haviland, Sourav Garg, Jad Abou-Chakra, Ian Reid, and Niko Sunderhard. 2023. Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning. arXiv preprint arXiv:2307.06135 (2023).
[30] Alexander T Sack. 2009. Parietal cortex and spatial cognition. Behavioural brain research 202, 2 (2009), 153-161.
[31] Pramah Saboo, Prabhush Meharia, Akash Ghosh, Sriparna Saha, Vinija Jain, and Aman Chadha. 2024. A comprehensive survey of hallucination in large language, image, video and audio foundation models. arXiv preprint arXiv:2405.09589 (2024).
[32] Erik Sandström, Yue Li, Luc Van Gool, and Martin R Oswald. 2023. Point-slam: Dense neural point cloud-based slam. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 18453-18444.
[33] Manolis Savva et al. 2019. Habitat: A Platform for Embodied AI Research. arXiv preprint arXiv:1904.11201 (2019).
[34] Dhruv Shah, Bkazi Osinkki, Sergey Levine, et al. 2023. Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action. In Conference on robot learning. PMLR, 492-504.
[35] Aleksandar Sitedeitski, Christian Ruppecht, and Andrea Vedaldi. 2023. What does clip know about a red circle? visual prompt engineering for vlms. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 11987-11997.
[36] Kimberly I. Stachenfeld, Matthew M Botvinick, and Samuel J Gershman. 2017. The hippocampus as a predictive map. Nature neuroscience 20, 11 (2017), 1643-1653.
[37] Edgar Sucar, Shikun Liu, Joseph Ortiz, and Andrew J Davison. 2021. imap: Implicit mapping and positioning in real-time. In Proceedings of the IEEE/CVF international conference on computer vision, 6229-6238.
[38] Jeffrey S Taube. 1998. Head direction cells and the neurophysiological basis for a sense of direction. Progress in neurobiology 55, 3 (1998), 225−256225-256225−256.
[39] Zachary Teed and Jia Deng. 2021. Droid-slam: Deep visual slam for monocular, stereo, and tgf-of-cameras. Advances in neural information processing systems 34 (2021), 16558-16569.
[40] Fan Wang, Chaslan Zhang, Folin Tang, Hongkui Jiang, Yihong Wu, and Yong Liu. 2022. Lightweight object-level topological semantic mapping and long-term global localization based on graph matching. arXiv preprint arXiv:2201.00977 (2022).
[41] Hengyi Wang, Jingwen Wang, and Lourdes Agapito. 2023. Co-slam: Joint coordinate and sparse parametric encodings for neural real-time slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13293-13302.
[42] Sean Williams and James Huckle. 2024. Easy Problems That LLMs Get Wrong. arXiv preprint arXiv:2405.19616 (2024). https://arxiv.org/abs/ 2405.19616
[43] Sean Williams and James Huckle. 2024. Easy problems that llms get wrong. arXiv preprint arXiv:2405.19616 (2024).
[44] Qaoyun Wu, Jun Wang, Jing Liang, Xiaoni Gong, and Dimeh Manocha. 2022. Image-goal navigation in complex environments via modular learning. IEEE Robotics and Automation Letters 7, 3 (2022), 6902-6909.
[45] Xiaojun Yang, Wei Cheng, Xujiang Zhao, Wenchao Yu, Linda Petzold, and Haifeng Chen. 2023. Dynamic prompting: A unified framework for prompt tuning. arXiv preprint arXiv:2305.02909 (2023).
[46] Lu Yue, Dongliang Zhou, Liang Xie, Feitian Zhang, Ye Yan, and Erwei Yin. 2024. Safe-vln: Collision avoidance for vision-and-language navigation of autonomous robots operating in continuous environments. IEEE Robotics and Automation Letters (2024).
[47] Renrui Zhang, Jiaming Han, Chris Liu, Aojun Zhou, Pan Lu, Yu Qiao, Hongsheng Li, and Peng Gao. 2024. LLaMA-adapter: Efficient finetuning of large language models with zero-initialized attention. In The Twelfth International Conference on Learning Representations.
[48] Yue Zhang, Yufu Li, Leyang Cui, Deng Cui, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. 2023. Siren’s song in the ai ocean: A survey on hallucination in large language models. arXiv preprint arXiv:2309.01219 2, 5 (2023).
[49] Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. 2023. Multimodal chain-of-thought reasoning in language models. arXiv preprint arXiv:2302.00923 (2023).
[50] Xinxin Zhao, Wenzhe Cai, Likun Tang, and Teng Wang. 2024. ImagineNav: Prompting Vision-Language Models as Embodied Navigator through Scene Imagination. arXiv preprint arXiv:2410.09874 (2024).
[51] Duo Zheng, Shijia Huang, Lin Zhao, Yiwu Zhong, and Liwei Wang. 2024. Towards learning a generalist model for embodied navigation. In
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13624-13634.
[52] Gengue Zhou, Yicong Hong, and Qi Wu. 2024. Naregpt: Explicit reasoning in vision-and-language navigation with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 7641-7649.
[53] Kanyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. 2022. Learning to prompt for vision-language models. International Journal of Computer Vision 150, 9 (2022), 2337-2348.
[54] Deyao Zhu, Jun Chen, Kilichhek Haydarov, Xiaoqian Shen, Wenxuan Zhang, and Mohamed Elhoseiny. 2023. Chatgpt asks, blip-2 answers: Automatic questioning towards enriched visual descriptions. arXiv preprint arXiv:2303.06594 (2023).
[55] Zihan Zhu, Songyou Peng, Viktor Larsson, Weiwei Xu, Hujun Bao, Zhaopeng Cui, Martin R Oswald, and Marc Pollefeys. 2022. Nicedam: Neural implicit scalable encoding for slam. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 1278612796.
参考论文:https://arxiv.org/pdf/2504.08806

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)