[具身智能 Affordance 论文精读] RGBManip: Monocular Image-based Robotic Manipulation through Active Object P
<ICRA 2024>RGBManip: Monocular Image-based Robotic Manipulation through Active Object Pose Estimation
<ICRA 2024> RGBManip: Monocular Image-based Robotic Manipulation through Active Object Pose Estimation
- 论文地址:https://arxiv.org/abs/2310.03478
- 项目地址:https://rgbmanip.github.io/
- 代码地址:https://github.com/hyperplane-lab/RGBManip
论文做了什么件事
提出了一种基于RGB的机器人框架,改框架利用安装在机器人平行抓手上的单目机器人,通过多机械臂的移动从多角度,多个视点主动感知物体,用于估计物体的6D姿态。并且通过强化学习的方式,对齐操纵和感知。
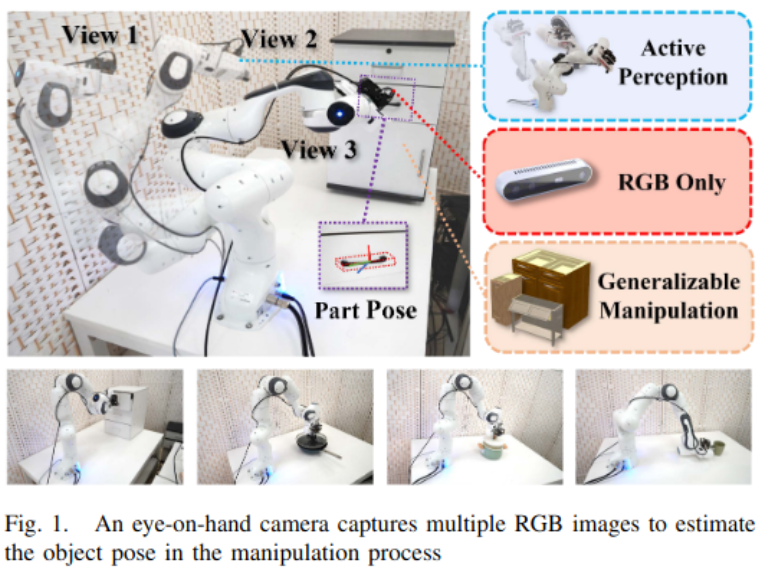
局限性和优势:
图像类型
RGB图像:虽然具有丰富的纹理信息,但是缺乏对机器人操作需要的深度和3D信息。
点云: 由于发射-接收成像的原理限制,会出现采样稀疏和输出噪声等问题。
方法过程
1) 全局调度,第一个过程为机器人自适应地提出探索环境的路径点。在强化学习的支持下,这个过程使机器人能够适应不同的任务(开门、撬杯等)并从不同的视图收集信息,避免遮挡,从而在下一个过程中实现 3D 表示。
2) 主动感知,第二个过程将来自不同视点的 RGB 图像作为输入,这些图像是在抓手接近要纵的物体时捕获的,并学习估计整个物体或特定物体部分的 6D 姿势,例如,在杯子拾取任务中杯子在桌子上的姿势, 或开门任务中门把手的姿势。这个过程为第3个过程奠定基础。
3)操纵,作者使用基于控制的方法来操纵给定姿态估计的物体。采用闭环阻抗控制器,可靠性更高。这三个流程在 Global Scheduling 流程下进行处理。
区别于其他工作的独特性:
1.在基于视觉的机器人操纵上: 输入仅为RGB,不含深度,且不依赖深度恢复的方法。而是直接使用运动学引导的多视图姿态估计直接估计对象的6D姿态。
2。在物体姿态估计上:从机器人轨迹上多个视点捕获的图像中恢复物体姿势,为减少单目图像的姿态模糊性,利用机器人运动学数据融合多视图图像特征。
方法
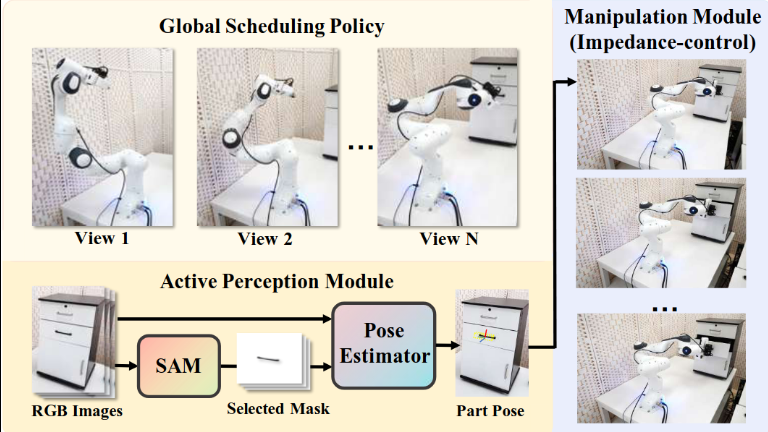
- Global Scheduling Policy:调度 Active Perception Module 和 Manipulation Module 的高级决策策略
- Active Perception Module:在预先训练的分割模型 (SAM [1])的帮助下学习感知环境以预测姿态信息。
- Manipulation Module (Impedance-control):用于通过阻抗控制完成纵任务。
A: 通过 Global Scheduling Policy 探索
输入:在时间间隔 t 内 ,输入所有先前的视图 V 1 V_1 V1 , — V t − 1 V_{t-1} Vt−1 和来自Active Perception Module的当前预测
输出: p t p_t pt 和 f t f_t ft , 其中, f t f_t ft 决定是否终止视点规划的过程,并尝试根据当前信息完成任务,我的理解就是视点规划的flag中断标签。 f t = 0 f_t=0 ft=0:机器人继续探索到 way-point p t p_t pt 以获得视图 V t V_t Vt。否则,操纵模块Manipulation Module会接管控制权。
这个过程使用 Proximal Policy Optimization [2] 训练。
B: 运动学引导的多视图对象姿态估计
Active Perception Module:核心作用是根据探索期间收集的所有信息来估计感兴趣物体的姿势。在时间间隔 t 内,安装在机械臂上的摄像头会为目标物体捕获RGB图像 I t I_t It 。利用SAM分割模型[1:1]分割目标对象区域。为实现类别级的部件姿态估计,采用NOCS[3]的方法,基于 F t F_t Ft(即 I t I_t It 的深度特征)预测了一个归一化的坐标图 M t M_t Mt (normalized coordinate map)。预测坐标图 M t M_t Mt 对相机和物体坐标系之间的密集 2D-3D 对应关系进行编码。
但是这种2D-3D之间存在深度模糊性,导致单目RGB相机无法完全恢复出类别级的部件姿态。
作者采用运动学引导的深度感知模块来融合多视图图像特征,来解决这个问题。
即通过相邻的两个RGB图像 I t I_t It 和 I t + 1 I_{t+1} It+1之间的运动学数据,求得他们的之间的相对外参( R t t + 1 R^{t+1}_t Rtt+1 , t t t + 1 t^{t+1}_t ttt+1) 。然后通过multi-homography映射将 F t F_t Ft 扭曲至 F t + 1 F_{t+1} Ft+1 来融合相邻图像特征。具体而言,作者在 d min d_{\min} dmin 和 d max d_{\max} dmax 之间均匀采样一组假设深度平面 { d i } i = 1 N \{d_i\}_{i=1}^N {di}i=1N。在每个假设深度平面上,基于对应的单应性矩阵将特征 F t F_t Ft 扭曲至 F t + 1 F_{t+1} Ft+1,其计算公式如下:
H ( d i ) = K ⋅ R t + 1 ⊤ ( I + t t + 1 ⊤ ⋅ n ⊤ d i ) ⋅ K − 1 ( 1 ) H(d_i) = \mathbf{K} \cdot \mathbf{R}_{t+1}^{\top} \left( \mathbf{I} + \frac{\mathbf{t}_{t+1}^{\top} \cdot \mathbf{n}^{\top}}{d_i} \right) \cdot \mathbf{K}^{-1} \quad (1) H(di)=K⋅Rt+1⊤(I+ditt+1⊤⋅n⊤)⋅K−1(1)
其中:
- K \mathbf{K} K 表示相机内参矩阵
- n \mathbf{n} n 表示 t + 1 t+1 t+1 时刻相机的主光轴方向向量
下图中形象的表述了该方法过程,利用合并后的特征预测物体的位姿[4]。

扭曲后的特征在不同深度平面 d i d_i di 上会表现出不同的相似性。通过连接不同深度的特征,可构建4D深度感知特征体,然后通过体积正则化层[5]对该特征体进行处理,最终输出融合图像特征 F ^ t + 1 \hat{F}_{t+1} F^t+1 。 F ^ t + 1 \hat{F}_{t+1} F^t+1 与从 M t + 1 M_{t+1} Mt+1 提取的特征拼接后,输入基于MLP的网络分支,分别预测:物体尺寸、旋转参数、平移向量。
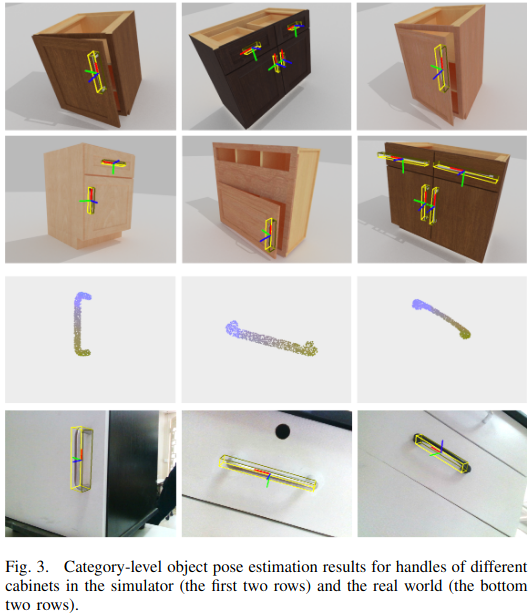
normalized coordinate map:归一化的坐标图,通常是将图像中每个像素的位置用相对于图像尺寸的归一化坐标(如在 [−1,1][−1,1] 或 [0,1][0,1] 范围内)表示;
C: 域随机化
为了更好地适应真实场景,作者在训练环境中添加了域随机化。在训练主动感知模块时,物体的纹理(包括透明、镜面和漫反射材质,这对点云相机来说是一个挑战,但对 RGB 相机来说不是挑战)、光源的位置和强度以及物体的初始姿态都会发生变化.
D: 平衡精度和效率 (A & E)
为增加姿态估计精度,就需要增加视图和更长的视图运动路径点,就会导致效率变低。反之,则降低估计精度。为了平衡精度和效率,作者通过在Active Perception Module中引入一个参数 α \alpha α。定义
α = r pen r prec \alpha = \frac{r_{\text{pen}}}{r_{\text{prec}}} α=rprecrpen
其中:
- r pen r_{\text{pen}} rpen:移动距离惩罚(负向指标)
- r prec r_{\text{prec}} rprec:姿态估计精度奖励(正向指标)
参数特性
| 参数范围 | 系统倾向性 | 优化目标 |
|---|---|---|
| α \alpha α较小时 | 更高精度 | 提升姿态估计准确性 |
| α \alpha α较大时 | 更短时间 | 减少运动耗时 |
E: 阻抗控制器
在主动感知任务中,基于视觉的闭环控制常因关键状态观测不足而受限。例如:当单目机器人近距离操作门把手时,相机视野过近导致难以观测门体旋转状态。利用机器人运动学信息,通过机械臂受力信号实时调整操作。末端执行器可以自由移动,但往往会返回到其目标姿势,确保其对小误差的容忍度。
每个机器人关节的扭矩 τ 计算如下:
设 X \mathbf{X} X和 R \mathbf{R} R分别为末端执行器相对目标位姿的平移/旋转误差,各关节扭矩 τ \tau τ由下式计算:
τ = J T ( − k ( X R ) − b ( J q ˙ ) ) + N ( 2 ) \tau=\mathbf{J}^{T}\left(-k\left(\begin{array}{c}\mathbf{X}\\\mathbf{R}\end{array}\right)-b(\mathbf{J}\dot{\mathbf{q}})\right)+\mathbf{N}\quad(2) τ=JT(−k(XR)−b(Jq˙))+N(2)
- J \mathbf{J} J:机器人雅可比矩阵
- k , b k,b k,b:刚度与阻尼系数
- q \mathbf{q} q:当前关节状态
- N \mathbf{N} N:包含零空间雅可比项和科里奥利力
将操纵轨迹视为一个与时间相关的函数,作者可以动态预测轨迹上的后续点,从而产生可靠的操纵策略,该策略对干扰保持弹性,并且可以有效地管理旋转和棱柱形铰接物体。让 p 表示末端执行器随时间变化的姿态。然后作者确定当前目标姿势为:
p ∗ = p + k 1 p ˙ + k 2 p ¨ ( 3 ) \mathbf{p}^{*}=\mathbf{p}+k_{1}\dot{\mathbf{p}}+k_{2}\ddot{\mathbf{p}}\quad(3) p∗=p+k1p˙+k2p¨(3)
- k 1 k_1 k1:轨迹方向修正系数
- k 2 k_2 k2:轨迹曲率修正系数
该策略可稳定处理:旋转关节物体(如门轴)、平移关节物体(如抽屉)
实验
作者设计了六项具有挑战性的任务来评估该方法。在所有任务中,都需要机械臂来完成不同物体的特定作目标,分别是Open Door 、 Open Door 45° 、Open Drawer、Open Drawer 30cm、Open Pot、Pick Mug
评估
使用两个数据集来训练模型:PartNetMobility 和 ShapeNet,一个全面的刚性 3D 形状数据集 。所有培训均在 SAPIEN 模拟器内进行。在模拟器中,实验跨越了 4 个不同对象类别的 184 个形状。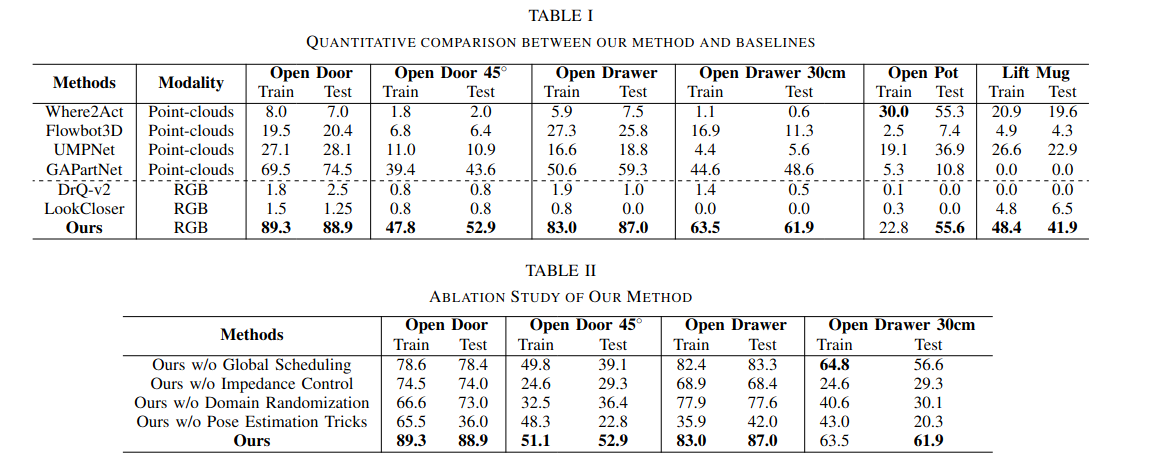
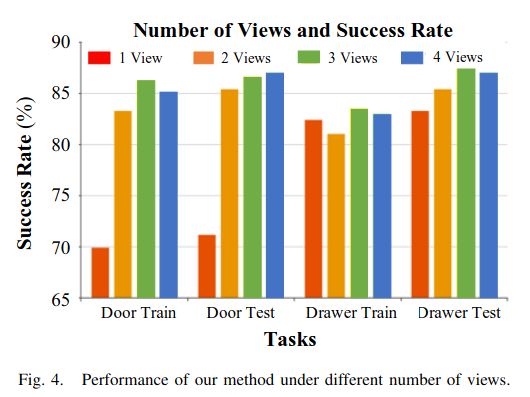
如下图:视图点的增加与作平均成功率的提高直接相关。然而,增加更多的路径点不可避免地会导致收益递减。当多达 4 个视图点时,没有明显的改进。这些结果强调了在准确性和效率之间找到和谐的重要性。
最后,下图为在不同α下平衡 A&E 的方法。x 轴表示 α 的值,红色曲线对应于姿势估计的误差,蓝色曲线是作过程中的平均移动距离。点和条形分别是 5 个不同评估策略的平均值和标准差。该图说明了当 Pose 估计精度过大时 α 会降低。同时,平均移动距离随着α的增加而下降。不直观的 U 形误差曲线可能是由于奖励设计不完善,当 α 太小时,除误差和距离惩罚以外的项在整体奖励中占主导地位,导致次优策略。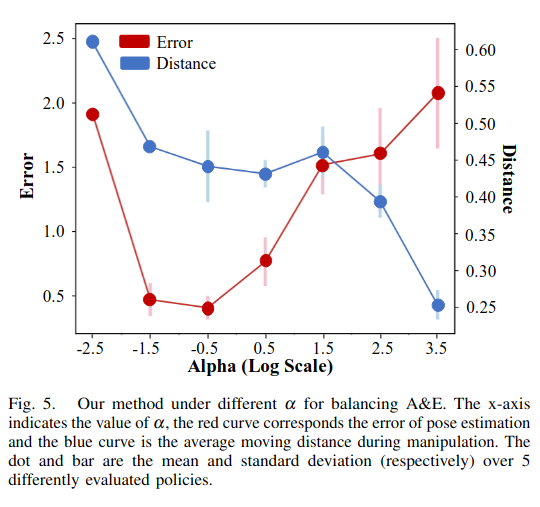
结论
作者提出了一种用于单目机器人作的主动姿势估计的开创性方法。使机器人能够处理单目 RGB 输入的不同任务。这是通过三管齐下的过程实现的。1) 机器人主动探索环境。2) 感兴趣的物体的姿态信息是从探索中得出的。3) 通过闭环阻抗控制策略实现操纵。
-
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. arXiv preprint arXiv:2304.02643, 2023. ↩︎ ↩︎
-
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017. ↩︎
-
He Wang, Srinath Sridhar, Jingwei Huang, Julien Valentin, Shuran Song, and Leonidas J Guibas. Normalized object coordinate space for category-level 6d object pose and size estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2642–2651, 2019. ↩︎
-
[ICRA 2024 | RGBManip:仅基于单目RGB相机的机器人自主环境感知和操纵]
https://mp.weixin.qq.com/s/JIvXFT7oZkmHIygbbNPmRA ↩︎ -
Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European conference on computer vision (ECCV), pages 767–783, 2018. ↩︎

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)