大模型之强化学习篇——基本概念、传统强化学习介绍、R1模型介绍
早期训练一个大模型只需要预训练和监督微调就行,比如GPT2,这个时候的大模型效果并不好,在市场上并没有犯起大浪花,但是在GPT-3之后,随着InstructGPT和ChatGPT的发布而被广泛引入和应用的强化学习,大模型才开始爆火,所以有必要了解强化学习的概念。
写在前面
早期训练一个大模型只需要预训练和监督微调就行,比如GPT2,这个时候的大模型效果并不好,在市场上并没有犯起大浪花,但是在GPT-3之后,随着InstructGPT和ChatGPT的发布而被广泛引入和应用的强化学习,大模型才开始爆火,所以有必要了解强化学习的概念。
基本概念
强化学习与监督学习的区别
区别主要有4点,如下:
- 环境未知,需要探索特征;
监督学习:在监督学习中,模型是在一个已知且静态的数据集上进行训练的。每个样本都有明确的输入(特征)和输出(标签),比如“这张图片是猫”或“这句话的情感是正面”。模型的任务是学习从输入到输出的映射关系,不需要“探索”新数据。
强化学习:在强化学习中,智能体(agent)处于一个未知或部分可观测的环境中。它必须通过与环境的交互来学习:采取行动 → 观察结果 → 获得奖励或惩罚。由于环境的状态空间可能非常大甚至未知,智能体必须主动探索(exploration)以发现哪些行为能带来高回报,同时也要利用(exploitation)已知的好策略。这种“探索-利用”的权衡是强化学习的核心挑战之一。
- 环境变化;
同上,监督学习的训练数据都是静态的,一旦训练完成,模型便不会主动适应环境变化,如果环境发生变化,往往模型性能会下降。
而强化学习应用环境是动态的、随时间变化的,智能体必须持续与环境交互,并根据反馈调整策略。
- 延迟反馈;
监督学习:每个输入都有即时、明确的标签反馈。比如输入一张猫的图片,立刻知道正确答案是“猫”。模型可以立即计算损失并更新参数。
强化学习:反馈(即奖励)往往是延迟的、稀疏的。智能体可能在采取一系列动作后很久才获得奖励。例如,在一局围棋中,只有在游戏结束时才知道输赢。这导致“信用分配问题”(credit assignment problem):如何判断是哪一步动作导致了最终的结果?
- 马尔可夫性
监督学习:通常假设样本之间是独立同分布,不考虑顺序或上下文依赖。每个预测是孤立的,比如预测下一句话时,虽然可能用到前面内容(如在RNN或Transformer中),但训练机制本身不依赖“状态转移”。
强化学习:强化学习通常基于马尔可夫决策过程,其核心假设是:当前状态包含了做出最优决策所需的全部信息,即未来只依赖于当前状态,而与过去无关(马尔可夫性)。智能体根据当前状态选择动作,环境转移到新状态,并给出奖励。
一个例子
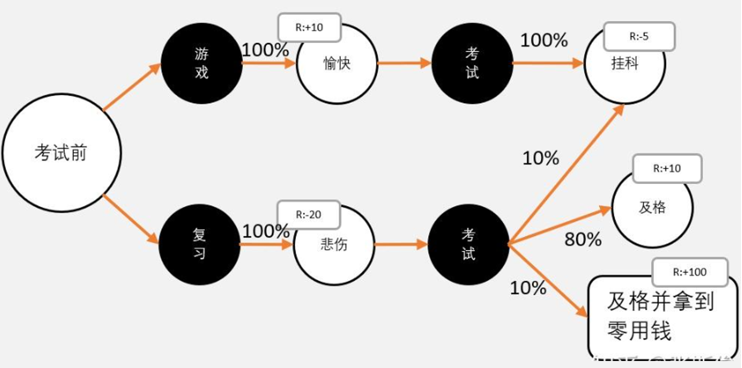
人的学习也可以作为强化学习例子。价值可以分为状态价值和动作价值,价值的产生 来自于动作和 发出动作的状态,而不是状态本身。比如打游戏可以加分,并非愉快才加分,最后计算打游戏的分数=10-5=5;复习的分数为=-20+(-0.5)+8+10=17.5.所以最好我们还是考前复习。
传统强化学习:Q-Learning、Sarsa、DQN、蒙特卡洛
我主要做粗略的了解,后续用到再深究。
Q-Learning
Q-Learning通过边探索边学习的方法,得到一个Q表,根据这个表之后选取动作。Q-Learning是作为最乐观的估计,他是学习一个“完全贪婪”的最优策略。比如上一个例子中,我可能只会看到复习了就会拿到钱,不会考虑复习了也会挂科的情况。
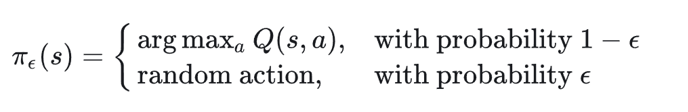
Sarsa
Sarsa倾向于保守主义,它学习的是“带探索的策略”本身,而不是理想的贪婪策略。
DQN
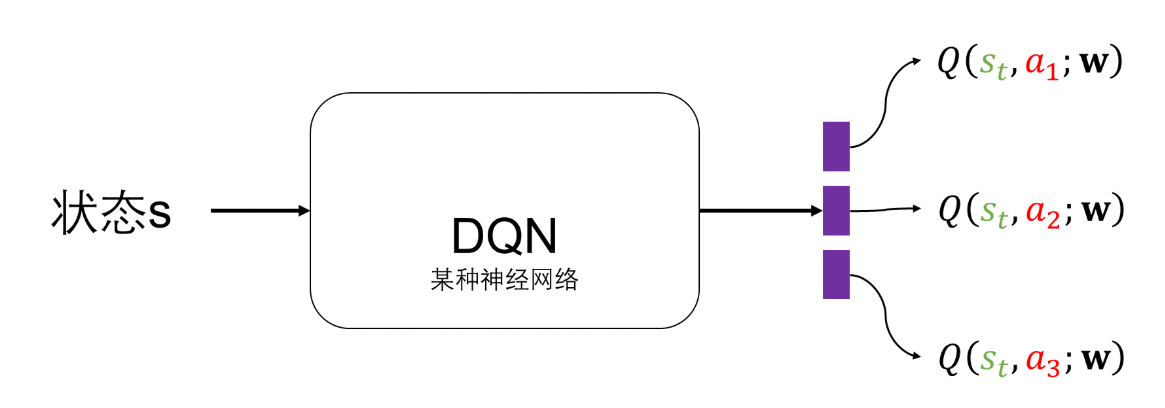
上诉的两种方法实际上还是有穷举的嫌疑,一旦环境变得复杂,比如下围棋走法用穷举的方法列出来比可观测宇宙的原子太多,计算器处理大规模的数据用表格方法步可取。DQN引入了神经网络,让强化学习具备高维输入性质,可泛化性。
蒙特卡洛
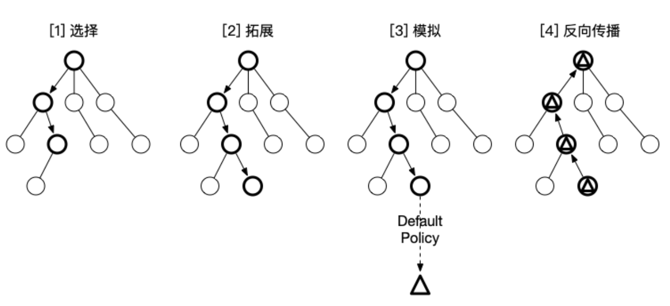
1987年Bruce Abramson在他的博士论文中提出了基于蒙特卡洛方法的树搜索这一想法。这种算法简而言之是用蒙特卡洛方法估算每一种走法的胜率。如果描述的再具体一些,通过不断的模拟每一种走法,直至终局,该走法的模拟总次数N,与胜局次数W,即可推算出该走法的胜率为 W/N。 通过随机的对游戏进行推演来逐渐建立一棵不对称的搜索树的过程
DeepSeekV3-R1 一种新的强化学习范式
强化学习的必要性
训练大模型时预训练得到的模型只能预测下一个词,SFT微调之后能够学习说话,比如我喜欢吃什么,模型能够回答“肉”而不是“呢”。但是SFT无法提供负反馈,也就是说,SFT训练的数据越来越多时,会出现幻觉,比如“我喜欢吃什么”,模型可能回答“肉”,我问“我不喜欢吃什么”,模型也可能回答“肉”。sft的反馈粒度是token,rlhf(强化学习) 的反馈粒度是整个文本。 所以sft 只能教会模型做正确的事,每条样本都赋予同样权重的惩罚,rlhf更倾向于考虑整体影响。加了rlhf之后模型具备了向后看的能力。
DeepSeekV3-R1创新点:
1.一种新的强化学习范式GRPO 取代PPO
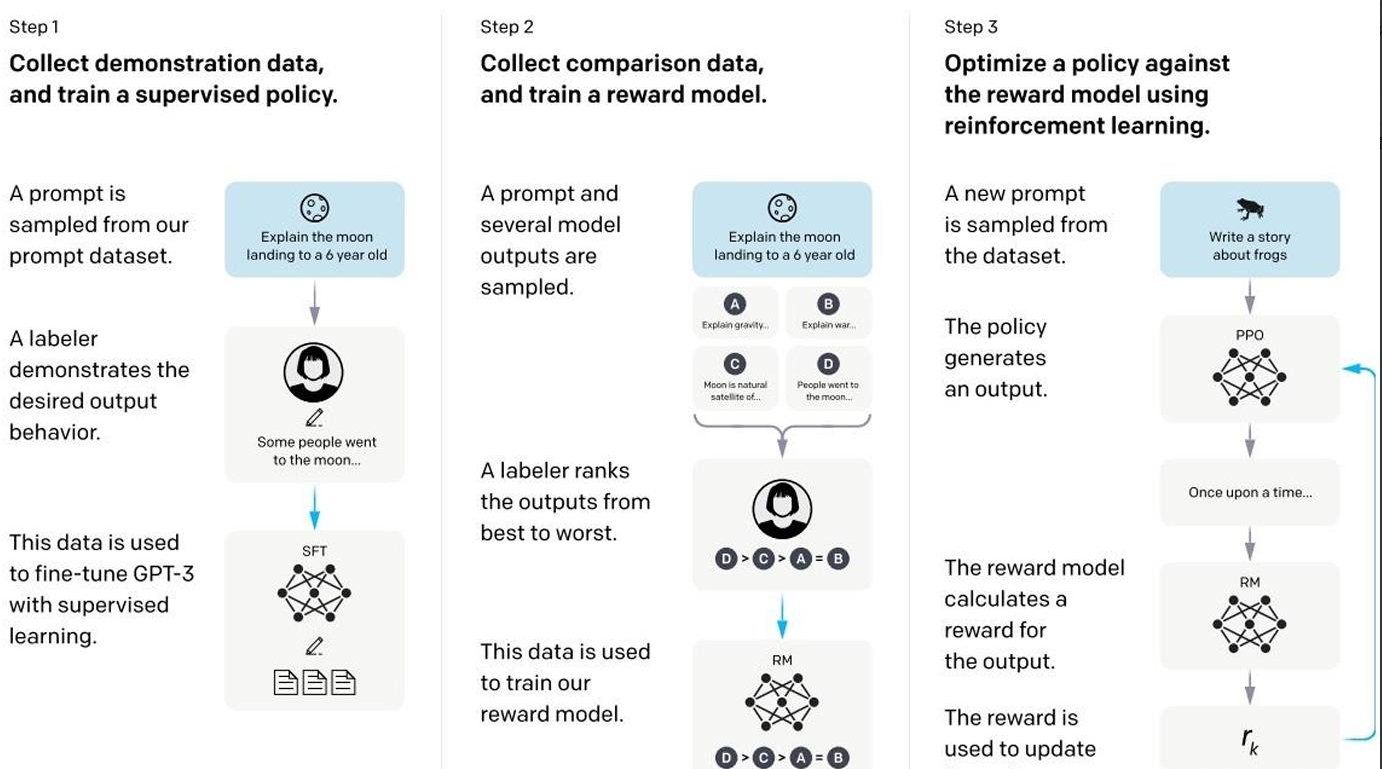

2.一种新的学习流程,取代RLHF
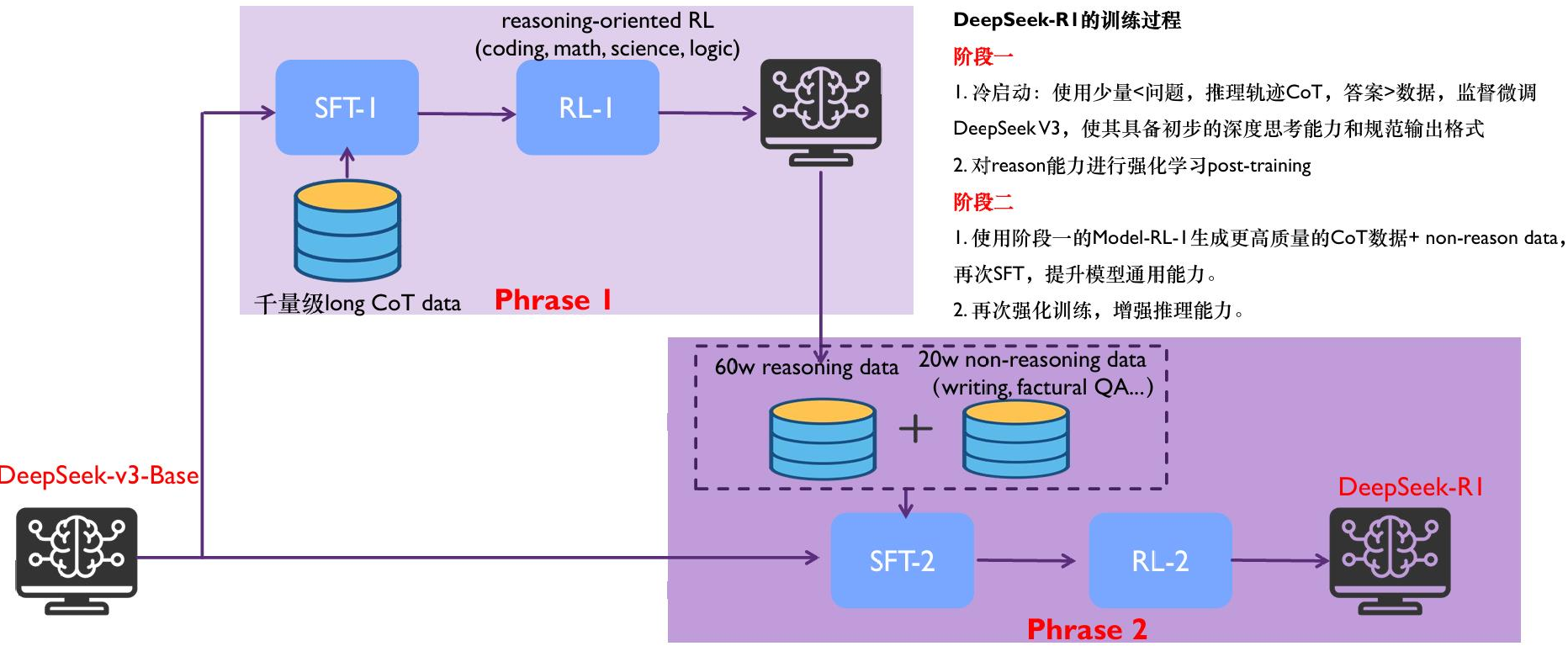
3.一种新的蒸馏模式
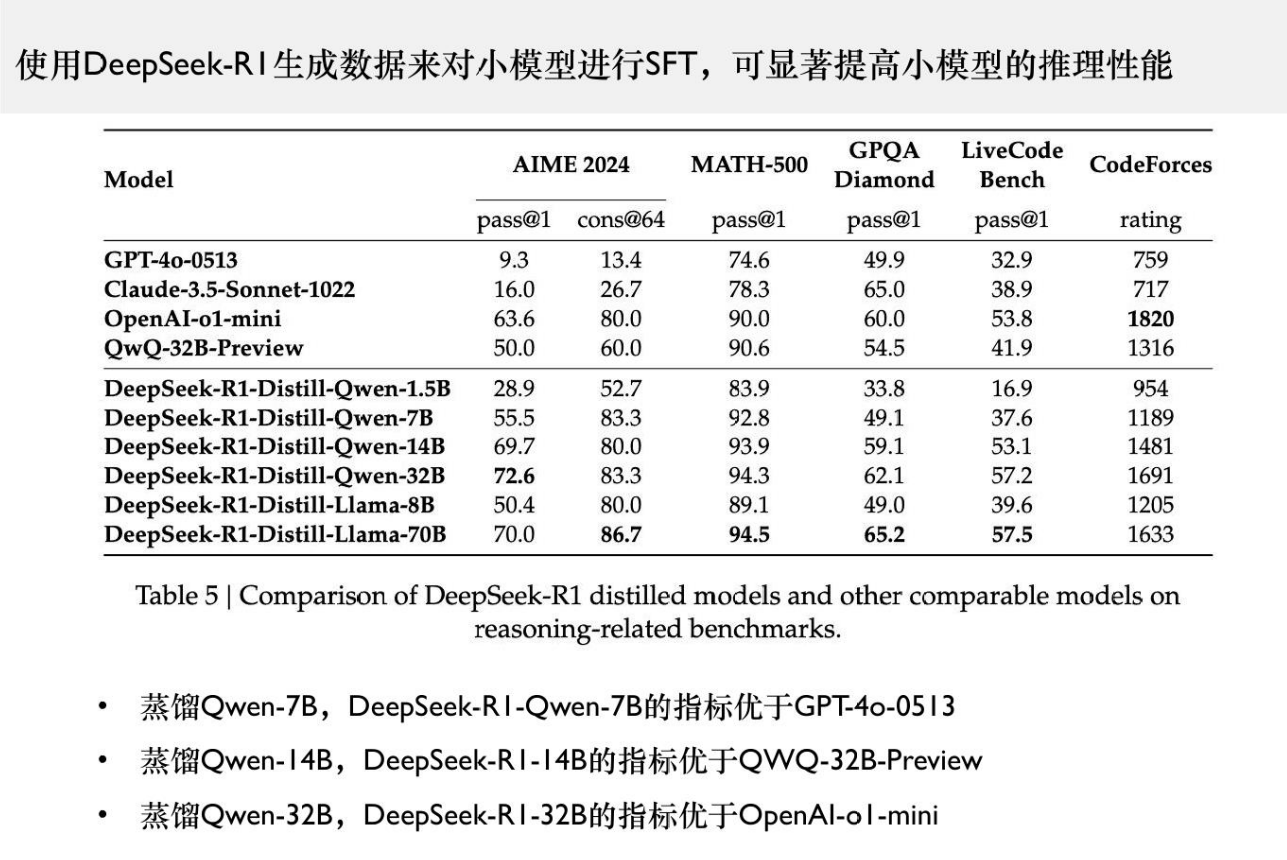
可以看到下面的图,通过R1模型蒸馏的到的训练数据对小模型进行SFT,效果的到急剧上升,再一些领域反而能够超过一些大模型。说明小模型能力差不是因为参数少,而是因为不好训练。
openai-o1与deepseek-r1对比
deepseek-r1是对标openai-o1模型的。区别见下图。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)