[BrowserOS] LLM供应商集成 | 更新系统 | Sparkle框架 | 自动化构建系统 | Generate Ninja
LLM集成通信:使用`langchain_core`库。虽然该库(或类似代码)能抽象化部分供应商差异,但核心仍是==向API终端节点发送HTTP请求。==构建:==通过**Python脚本**(`build.py`)协调**GN**配置生成与**Autoninja**并行编译==,结合补丁应用和资源替换实现深度定制,最终产出各平台安装包。
第6章:大语言模型(LLM)供应商集成
欢迎回来!
在我们探索BrowserOS的旅程中,我们已经了解了专业型AI智能体(专项)、协调它们的指挥中枢(AI智能体编排器)、它们运行的核心浏览器(Nxtscape浏览器内核)、它们如何"观察"网页(浏览器状态管理),以及如何与之"互动"(浏览器交互层)。
现在,真正的"智能"从何而来?这些智能体如何决策行动、理解复杂请求或总结信息?
它们需要访问大语言模型(LLMs)!
什么是LLM供应商集成?
设想我们正在要求我们的专家团队(AI智能体)进行调研。它们能找到书籍(浏览器状态)、阅读内容(浏览器交互)并遵循指令(编排器)。但它们需要知识来理解我们的问题或总结书籍内容。这些知识来自强大的LLMs。
当前存在多种LLM选择,由不同公司(如OpenAI、Anthropic、Google)提供,甚至可以在本地计算机运行(如Ollama)。每个LLM供应商都有自己独特的通信方式,就像使用不同的语言(不同的API)。
如果每个AI智能体(专项)都需要学习所有LLM供应商的"语言",复杂度将急剧上升!就像要求每个专家必须掌握十门外语才能开展工作。
LLM供应商集成组件正是解决这一问题的关键。它充当通用翻译器或桥梁,为所有AI智能体提供标准化的LLM调用方式(例如"请补全这段文本"或"请总结这些信息"),同时处理不同LLM供应商的具体通信细节。
其工作原理可概括为:
- AI智能体编排器(管理者)向AI智能体(专项)(专家)下达指令
- 当专家需要调用"AI大脑"(LLM)时,它们以标准化方式发起请求
- 请求传递至LLM供应商集成组件
- 该组件读取用户设置(选择使用的LLM供应商)
- 将标准化请求转换为目标供应商的特定"语言"(API调用)
- 向外部或本地LLM服务发送请求
- 接收LLM响应(如补全的文本、摘要、步骤列表)
- 将响应转换回智能体理解的标准化格式
- 将结果返回专家智能体以继续执行任务
该组件确保AI智能体的核心逻辑保持简洁,不会因用户更换LLM模型或供应商而需要修改。
工作原理:通信流程
LLM供应商集成的通信流程:
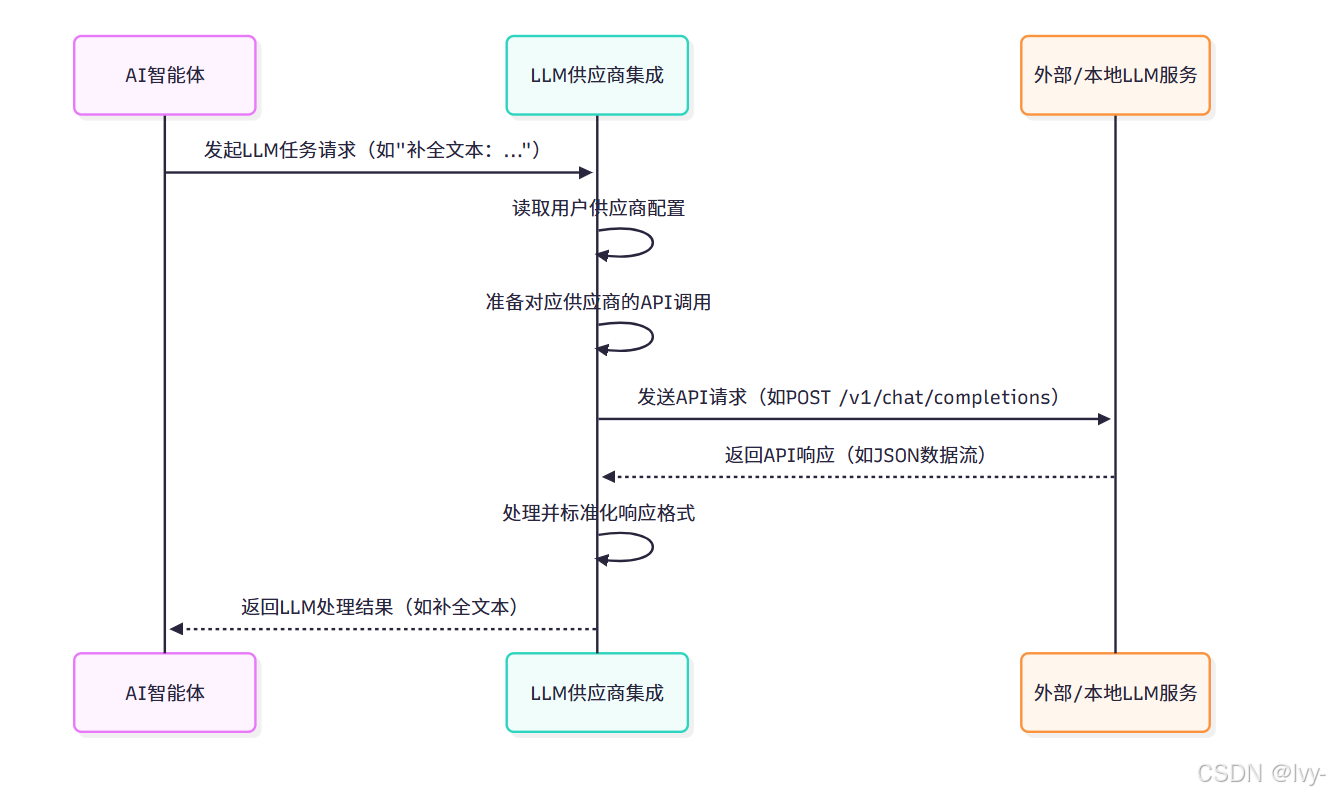
(该流程图展示AI智能体向LLM供应商集成发起请求。集成组件根据配置确定目标LLM服务,完成请求转换、发送、响应接收与格式标准化,最终将结果返回智能体。)
多供应商接入机制
本组件支持多种供应商接入,其选择逻辑基于:
用户偏好设置(通常存储于浏览器设置中,后续章节详述)。LLM供应商集成组件通过读取以下配置信息实现路由:
- 供应商选择:OpenAI、Anthropic、Gemini、Ollama等
- 认证信息:API密钥(适用于OpenAI等外部服务)或基础URL(适用于Ollama等本地服务)
- 模型名称:具体模型选择(如"gpt-4o"、“claude-3-5-sonnet”、“gemini-1.5-pro”、“llama3”)
当智能体发起请求时,集成组件
获取配置信息并使用正确的API终端节点和认证方式。
底层实现:API调用
与LLMs的实际通信通过标准Web技术(如Fetch)或LLM公司提供的专用客户端库实现。resources/files/ai_side_panel/background.js文件包含与AI模型交互相关的代码,特别是使用langchain_core库。
虽然该库(或类似代码)能抽象化部分供应商差异,但核心仍是向API终端节点发送HTTP请求。
以下概念性代码演示核心工作原理:
// 概念简化版,演示基于配置的路由逻辑
// 假设用户配置(来自偏好设置)
const userLLMSettings = {
defaultProvider: "openai", // 可选"anthropic"、"gemini"、"ollama"等
openai: {
apiKey: "sk-YOUR-OPENAI-API-KEY",
model: "gpt-4o",
baseUrl: "https://api.openai.com/v1" // 可选,通常有默认值
},
anthropic: {
apiKey: "sk-YOUR-ANTHROPIC-API-KEY",
model: "claude-3-5-sonnet-latest",
baseUrl: "https://api.anthropic.com"
},
ollama: {
baseUrl: "http://localhost:11434", // 本地URL
model: "llama3"
}
// ... 其他供应商
};
// LLM供应商集成组件内的假设函数
async function sendLLMRequest(prompt, options) {
const providerConfig = userLLMSettings[userLLMSettings.defaultProvider];
if (!providerConfig) {
throw new Error("LLM供应商未配置。");
}
const model = options.model || providerConfig.model;
if (!model) {
throw new Error(`供应商 ${userLLMSettings.defaultProvider} 未指定模型。`);
}
let endpoint;
let headers = {};
let body = {
model: model,
// ... 温度、最大token数等通用参数
};
// 根据配置路由请求
switch (userLLMSettings.defaultProvider) {
case "openai":
endpoint = `${providerConfig.baseUrl || "https://api.openai.com/v1"}/chat/completions`;
headers = {
"Content-Type": "application/json",
"Authorization": `Bearer ${providerConfig.apiKey}`
};
// OpenAI要求'messages'数组
body.messages = prompt;
break;
case "anthropic":
endpoint = `${providerConfig.baseUrl || "https://api.anthropic.com"}/v1/messages`;
headers = {
"Content-Type": "application/json",
"x-api-key": providerConfig.apiKey,
"anthropic-version": "2023-06-01" // Anthropic版本要求
};
// Anthropic要求'messages'数组及系统/用户区分
body.messages = prompt;
break;
case "gemini":
endpoint = `${providerConfig.baseUrl || "https://generativelanguage.googleapis.com"}/v1beta/models/${model}:generateContent?key=${providerConfig.apiKey}`;
headers = { "Content-Type": "application/json" };
// Gemini要求'contents'数组含'role'和'parts'
body.contents = prompt; // 假设prompt已符合谷歌格式
delete body.model; // 模型名称通过URL路径传递
break;
case "ollama":
endpoint = `${providerConfig.baseUrl || "http://localhost:11434"}/api/chat`;
headers = {
"Content-Type": "application/json",
// Ollama根据配置可能需要认证头
};
// Ollama聊天API要求'messages'数组
body.messages = prompt;
break;
default:
throw new Error(`不支持的供应商:${userLLMSettings.defaultProvider}`);
}
// 使用fetch(简化版,实际需处理流式传输和错误)
try {
const response = await fetch(endpoint, {
method: "POST",
headers: headers,
body: JSON.stringify(body)
});
if (!response.ok) {
const errorBody = await response.text();
throw new Error(`LLM API错误 ${response.status}: ${response.statusText} - ${errorBody}`);
}
const data = await response.json();
// 处理数据并返回智能体期望的标准化格式
return data; // 简化版,实际处理依供应商/模型而定
} catch (error) {
console.error("调用LLM API出错:", error);
throw error;
}
}
// 智能体调用示例(简化)
/*
async function planTask(userRequest) {
const planningPrompt = [
{ role: "system", content: "您是一个生成分步计划的助手。" },
{ role: "user", content: `创建计划:${userRequest}` }
];
const llmResponse = await sendLLMRequest(planningPrompt, { model: "gpt-4o" }); // 可覆盖模型
// 处理llmResponse提取计划...
// return 提取的计划;
}
*/
该概念代码展示组件如何:
读取用户选择的供应商及配置(API密钥、基础URL、模型)构建正确的API终端URL设置必要请求头(如API密钥)- 按供应商API规范
格式化请求体(不同供应商要求不同JSON结构) - 使用fetch调用(或封装库如LangChain)发送请求
处理响应及潜在错误
项目中可见的Zod模式定义(如消息格式验证)可辅助处理API请求/响应的结构验证。
Fetch调用
是一种浏览器提供的JavaScript方法,用于从网络(如服务器)获取资源(如数据或文件),类似于"去网上拿东西"。
Zod模式
定义是通过代码直接描述数据结构(如对象、字符串、数字等)及其验证规则,像制作数据模板一样确保输入内容符合预期格式。
总结
LLM供应商集成组件至关重要,它通过抽象化不同AI模型的通信复杂度,为AI智能体(专项)提供标准化服务调用层。
该组件基于用户配置(如API密钥和基础URL)路由请求,在智能体的标准化格式与供应商的特定API格式间进行转换,是连接浏览器AI系统与外部/本地AI智能的"沟通桥梁"。
现在我们已经了解BrowserOS如何获取智能,接下来将探索系统自身的更新机制——更新系统。
第7章:更新系统
在前几章中,我们已经了解了AI智能体(专项)如何与AI智能体编排器协作,在定制的Nxtscape浏览器内核中运行。我们学习了它们如何通过浏览器状态管理"观察"网页,如何通过浏览器交互层"行动",以及如何从LLM供应商集成获取智能支持。
所有这些组件共同构建了一个强大的智能浏览器。但如同任何软件,BrowserOS也需要定期更新。
新功能的添加、缺陷修复以及重要的安全改进都需要通过更新系统实现。
这就是更新系统的职责所在。
前文回顾:es中我们专门针对 自动化更新讲到过[es自动化更新] Updatecli编排配置.yaml | dockerfilePath值文件.yml
什么是更新系统?
更新系统是BrowserOS中负责保持应用程序自身处于最新安全状态的核心组件。
它如同BrowserOS应用大厦的维护团队,其工作原理可类比为:
- 当前BrowserOS版本如同您正在使用的大厦
- 包含改进功能或修复的新版本如同更新的建筑蓝图或新设备
- 更新系统则是检查新蓝图/设备可用性并协助安装的流程,确保大厦(BrowserOS应用)始终保持最佳状态
该系统的核心价值在于:无需用户手动下载安装新版本,即可确保始终运行最稳定、功能最完善的BrowserOS版本。
macOS实现机制
BrowserOS基于Chromium内核的Nxtscape浏览器核心构建。
虽然Chromium自带更新机制,但BrowserOS在macOS平台上采用了不同的实现方案——整合Sparkle开源框架。
Sparkle框架解析
Sparkle是专为macOS应用设计的知名更新管理库,其核心功能包括:
- 后台版本检测
- 更新文件下载
- 数字签名验证
- 用户引导安装流程(通常需要应用重启)
在macOS版BrowserOS中,Sparkle作为内建的专属更新管家发挥作用。
应用播送源(Appcast Feed)
Sparkle通过定期查询特定的应用播送源XML文件获取更新信息。该文件包含:
版本号更新日志更新文件下载地址(如macOS的.dmg文件)防篡改数字签名
BrowserOS配置中指定了专属的应用播送源URL。以下为docs/appcast.xml文件片段示例:
<item>
<title>Nxtscape - 0.12.0</title>
<sparkle:version>7183.69</sparkle:version>
<sparkle:shortVersionString>0.12.0</sparkle:shortVersionString>
<pubDate>Fri, 11 Jul 2025 16:49:23 -0700</pubDate>
<enclosure
url="http://cdn.browseros.com/dmg/BrowserOS_v0.12.1_arm64.dmg"
sparkle:edSignature="ylPrjpTj2JPFGdfqh3/DUSzTJxdlskrlORbZOqlsQsC04Euc1ovyzkKNBA=="
length="126839083"
type="application/octet-stream" />
<sparkle:minimumSystemVersion>10.15</sparkle:minimumSystemVersion>
</item>
(此XML片段展示了版本0.12.0的技术版本号(7183.69)、用户可见版本(0.12.0)、发布日期,以及包含下载地址和数字签名的标签)
更新流程概览
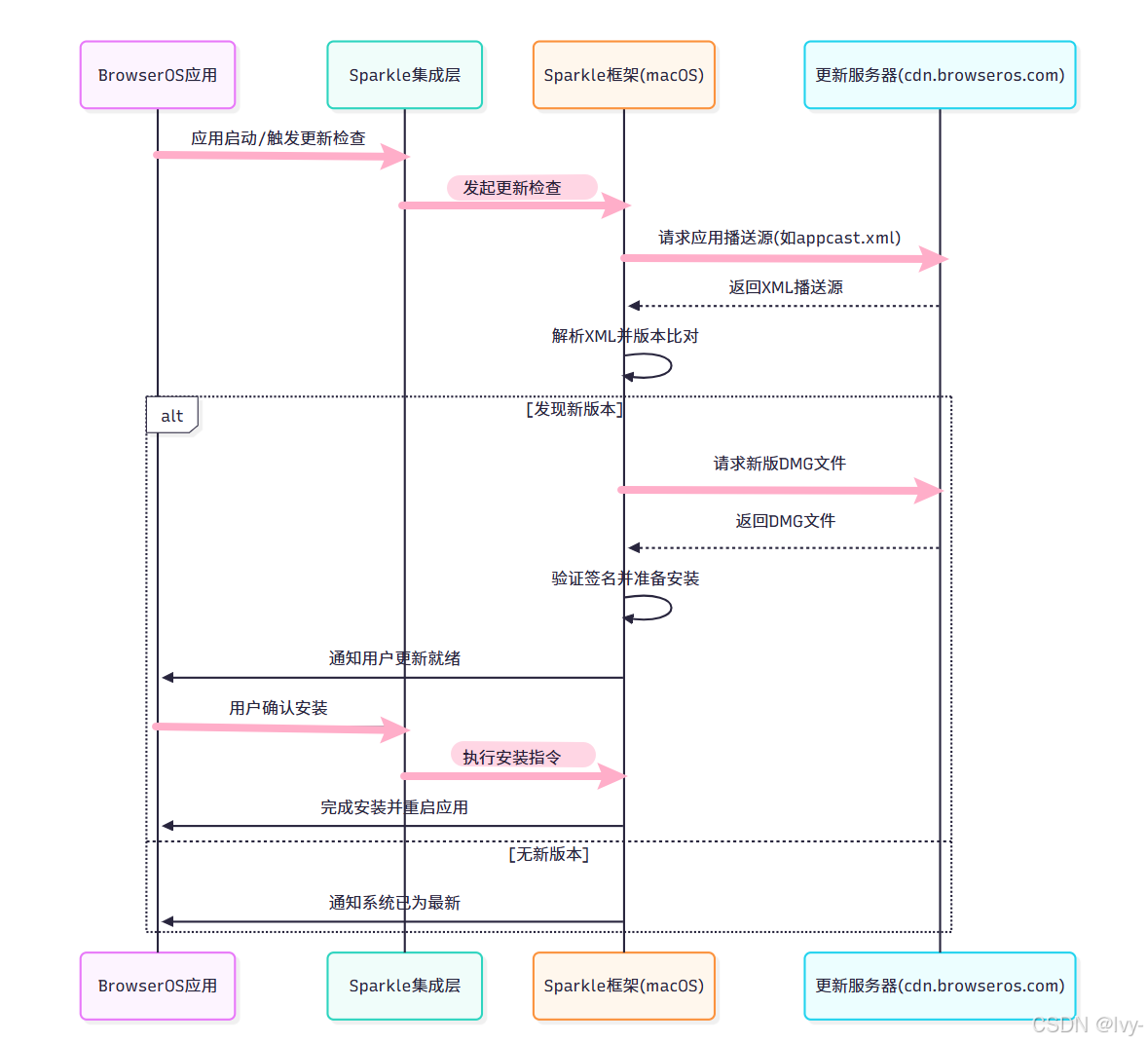
(BrowserOS触发检查→Sparkle获取播送源→版本比对→下载验证→用户引导安装)
技术实现细节
将Sparkle整合至基于Chromium的BrowserOS涉及以下关键技术步骤(可见于patches/nxtscape/nxtscape-updater-sparkle.patch等代码文件):
-
框架集成
- 修改构建配置(
chrome/BUILD.gn)将Sparkle添加为macOS构建依赖 - 更新应用元数据(
Info.plist)添加Sparkle专用配置项:
(配置项包含<key>SUPublicEDKey</key> <string>LzQmcNuTsdB3/dsivo0eeN+jPfDoriRHAkkEJcfFs2A=</string> <key>SUEnableAutomaticChecks</key> <true/> <key>SUScheduledCheckInterval</key> <integer>1080</integer> <!-- 1080秒=18分钟 --> <key>SUAllowsAutomaticUpdates</key> <true/> <key>SUAutomaticallyUpdate</key> <true/>签名公钥、自动检查间隔等关键参数)
- 修改构建配置(
-
桥接层开发
- 创建Objective-C桥接代码(
sparkle_glue.mm)实现Chromium/C++与Sparkle/Objective-C的交互:
(该代码段展示如何@implementation SparkleGlue - (void)registerWithSparkle { // 设置播送源URL NSString* feedURLString = GetUpdateFeedURL(); NSURL* feedURL = [NSURL URLWithString:feedURLString]; [_updater performSelector:@selector(setFeedURL:) withObject:feedURL]; // 配置自动更新参数 [_updater setUpdateCheckInterval:1080]; } @end配置Sparkle的更新源URL和检查间隔)
- 创建Objective-C桥接代码(
桥接层:连接不同系统或组件的中间层,负责转换和协调两者之间的数据或协议差异,确保它们能无缝协作。eg. VFS
-
状态机对接
- 开发C++接口类(
SparkleVersionUpdater)将Sparkle状态映射至BrowserOS通用更新状态:
(实现Sparkle状态到BrowserOS标准状态的转换)void SparkleVersionUpdater::OnSparkleStatusChange(SparkleUpdateStatus status) { switch (status) { case kSparkleStatusChecking: update_status = CHECKING; break; case kSparkleStatusNoUpdate: update_status = UPDATED; break; case kSparkleStatusUpdateFound:update_status = UPDATING; break; // 其他状态处理... } status_callback_.Run(update_status, ...); }
- 开发C++接口类(
-
安全验证机制
- 通过
ED25519算法对下载包进行签名验证,防止中间人攻击 - 在应用启动时
预加载Sparkle框架并进行完整性检查
- 通过
ED25519: 一种高效且安全的数字签名算法,基于椭圆曲线密码学(直观理解ECC椭圆曲线加密算法),用于快速生成和验证签名,抗量子计算攻击,广泛应用于SSH、TLS等安全协议。
总结
BrowserOS的更新系统通过深度整合Sparkle框架,实现了:
- 静默
后台更新检查(默认每18分钟) - 增量
更新包下载(优化带宽使用) 无缝用户更新体验(可视化进度提示)- 企业级
安全验证(数字签名+传输加密)
这种分层架构设计(Sparkle框架→Objective-C桥接→C++接口)既保持了Chromium核心的稳定性,又为macOS平台提供了原生级的更新体验。
理解更新系统让我们洞悉应用程序的持续进化机制。
但如此复杂的系统是如何从源代码构建成可执行文件的呢?这就是我们下一章要探讨的主题——构建系统(Autoninja/GN/脚本)。
第8章:构建系统(Autoninja/GN/脚本)
我们已探索了BrowserOS的核心组件,从智能体及其编排器到浏览器内核、网页感知与交互机制,甚至了解了应用更新机制(第7章:更新系统)。
但在这一切运行之前,整个BrowserOS应用需要从源代码完成构建。构建如此复杂的浏览器项目涉及数百万行代码、数十万文件及错综的依赖关系,其难度堪比建造摩天大楼——需要精密的设计方案、专业工具、优质建材和熟练的工程团队。
在软件领域,将
原始代码转化为可用应用的"工程团队"被称为构建系统。
由于BrowserOS基于庞大复杂的Chromium项目,我们采用以**GN、Autoninja和定制Python脚本**为核心的专用构建系统。
本章将深入解析该构建系统——它的核心作用、技术原理,以及如何将BrowserOS源代码转化为最终可执行程序。
什么是BrowserOS构建系统?
BrowserOS构建系统是用于实现以下目标的定制化基础设施:
- 从Chromium源码编译Nxtscape浏览器
- 应用BrowserOS专属修改
- 为不同操作系统(如macOS/Windows)打包最终应用
我们可以将其视为BrowserOS的自动化工厂流水线:
- 原材料:Chromium与BrowserOS的
源代码文件(C++、Python、JS、HTML等) - 设计图纸:指导构建流程的配置文件(如
args.gn) - 专业工具:编译器(如Clang)、链接器及专用构建工具(
gn、ninja、autoninja) - 定制化工位:应用BrowserOS
专属修改(补丁应用、资源替换) - 封装车间:将编译产物打包为最终应用(
.app、.dmg、.exe) - 总控系统:协调全流程的Python脚本(
build.py及build/目录脚本)
手动构建如此规模的项目几乎不可能。构建系统通过自动化确保高效性与一致性。
核心组件
BrowserOS构建系统由以下关键组件构成:
- Python脚本:流程总控入口(
build.py),定义全生命周期操作(清理、配置、编译、打包、签名等) - GN (Generate Ninja):Chromium采用的构建文件生成工具,通过解析配置文件确定构建规则
- Ninja:底层构建执行器,基于GN生成的
build.ninja文件高速执行编译指令(较传统Make工具更高效) - Autoninja:Ninja的智能封装脚本,根据CPU核心数自动优化并行任务数量
- 配置文件:
.gn格式文件(如args.gn)定义构建参数(调试/发布模式、目标架构、功能开关等) - 补丁与资源:将标准Chromium转化为Nxtscape BrowserOS的修改文件(
.patch文件及专属资源)
以下为各组件协同工作流程解析。
Generate Ninja
GN(Generate Ninja)是Google开发的元构建系统,用于快速生成Ninja构建文件。它专注于高性能和跨平台支持,常用于Chromium等大型项目。
基于C++构建的,源码分析可见Generate Ninja专栏~
Autoninja
Autoninja是Google开发的一个高效构建工具,用于快速编译大型代码项目(如Chromium),通过并行处理任务显著提升构建速度。
构建系统入口:build.py脚本
build.py是与构建系统交互的主要入口。该脚本作为项目总控,接收高层级任务指令(如"清理"、“应用补丁”、“编译打包”),并自动调度底层操作。
典型使用示例如下:
# 进入BrowserOS项目根目录
cd /path/to/browseros
# 示例1:清理历史构建产物
python build.py --clean
# 示例2:对Chromium源码应用BrowserOS补丁
# (假设Chromium源码存放于chromium_src目录)
python build.py --apply-patches --chromium-src ./chromium_src
# 示例3:配置+编译+打包发布版(当前OS/架构)
python build.py --configure --build --package --build-type release --chromium-src ./chromium_src
# 示例4:使用配置文件(如build/config/build.yaml)
python build.py --config build/config/build.yaml --chromium-src ./chromium_src
(这些命令展示了如何通过命令行参数执行清理、补丁应用、全量构建打包等操作,--chromium-src指定Chromium源码路径)
build.py内部通过BuildContext对象管理构建上下文(源码路径、架构类型、构建模式等),并调度各子模块执行具体任务。以下是其核心逻辑的简化示意:
# 摘自build/build.py的简化代码
def build_main(...):
# 初始化构建上下文
ctx = BuildContext(
root_dir=root_dir,
chromium_src=chromium_src,
architecture=arch_name, # 如"x64"、"arm64"
build_type=build_type, # 如"release"、"debug"
# ... 其他配置参数 ...
)
# 任务调度流程
if clean_flag:
clean(ctx) # 清理模块
if apply_patches_flag:
inject_version(ctx) # 版本注入
replace_chromium_files(ctx) # 文件替换
apply_patches(ctx) # 补丁应用
copy_resources(ctx) # 资源复制
if build_flag:
configure(ctx, gn_flags_file) # 配置模块
build(ctx) # 编译模块
if package_flag:
package(ctx) # 打包模块
# ... 其他后处理 ...
(此代码展示build.py如何通过BuildContext协调各模块:清理→补丁→配置→编译→打包)
GN配置解析(args.gn)
构建前需通过GN明确构建目标:调试版或发布版?启用哪些功能?目标架构为何?这些配置存于args.gn文件中。
build.py的配置模块(build/modules/configure.py)根据构建类型和架构生成args.gn,通常继承预设模板(如flags.macos.release.gn)并添加target_cpu参数。以下是典型args.gn内容:
# 摘自out/Default_x64/args.gn的配置片段
is_debug = false # 调试模式开关
is_component_build = false # 单体构建模式(非组件化)
is_official_build = true # 官方构建(启用优化)
symbol_level = 0 # 调试符号级别(0为发布版)
target_cpu = "x64" # 目标架构(x64/arm64)
proprietary_codecs = true # 启用私有编解码器(如MP3)
# ... 其他数百项配置参数 ...
(此配置定义构建类型为x64架构的发布版,启用私有编解码器支持)
GN读取args.gn后生成build.ninja文件(包含数万条构建指令),为后续编译提供蓝图。
Autoninja编译引擎
GN生成构建指令后,Autoninja接管编译工作。该工具解析build.ninja文件,调用Clang等编译器并行执行任务,其并行度根据CPU核心数自动优化。
build.py的编译模块(build/modules/compile.py)核心逻辑如下:
# 摘自build/modules/compile.py的简化代码
def build(ctx: BuildContext) -> bool:
os.chdir(ctx.chromium_src) # 进入Chromium源码目录
# 构建Autoninja命令
cmd = [
"autoninja" if IS_MAC else "autoninja.bat",
"-C", ctx.out_dir, # 指定输出目录(如out/Default_x64)
"chrome" # 编译主目标(浏览器本体)
]
run_command(cmd) # 执行编译命令
(此代码展示如何调用Autoninja编译chrome目标,run_command封装了命令执行与日志记录)
编译完成后,产出浏览器可执行文件及依赖库,进入打包阶段。
定制化处理流程
构建系统的核心任务之一是将Chromium转化为Nxtscape BrowserOS,涉及以下定制步骤:
- 版本信息注入:写入BrowserOS专属版本号
- 文件替换:替换Chromium默认文件(如品牌标识、UI资源)
- 补丁应用:通过
.patch文件修改Chromium源码(如集成Sparkle更新模块) - 资源复制:添加BrowserOS专属资源(如AI侧边栏脚本)
补丁应用模块(build/modules/patches.py)的简化逻辑如下:
# 摘自build/modules/patches.py的代码片段
def apply_patches(ctx: BuildContext):
# 读取补丁列表(build/patches/series)
patches = parse_series_file(ctx.patches_dir)
for patch in patches:
# 执行git apply应用补丁
cmd = ['git', 'apply', '-p1', str(patch)]
run_command(cmd, cwd=ctx.chromium_src)
(此代码遍历补丁文件,在Chromium源码目录应用修改)
应用打包与分发
编译产出需经打包模块转化为用户友好的安装包。不同平台处理方式不同:
- macOS:生成
.app应用包并打包为.dmg镜像 - Windows:生成
.exe安装程序或便携版.zip
macOS打包模块(build/modules/package.py)的简化逻辑:
# 摘自build/modules/package.py的代码片段
def package(ctx: BuildContext):
app_path = ctx.get_app_path() # 获取.app路径
dmg_path = ctx.get_dmg_path() # 目标.dmg路径
# 调用pkg-dmg工具打包
cmd = [
ctx.pkg_dmg_path,
"--source", app_path,
"--target", dmg_path,
"--volname", "BrowserOS",
"--format", "UDBZ"
]
run_command(cmd)
(此代码展示如何使用Chromium的pkg-dmg工具生成压缩版dmg镜像)
Windows平台则使用NSIS等工具生成安装程序,流程类似但工具链不同。
全流程总览
整合上述步骤,BrowserOS构建流程可概括为:
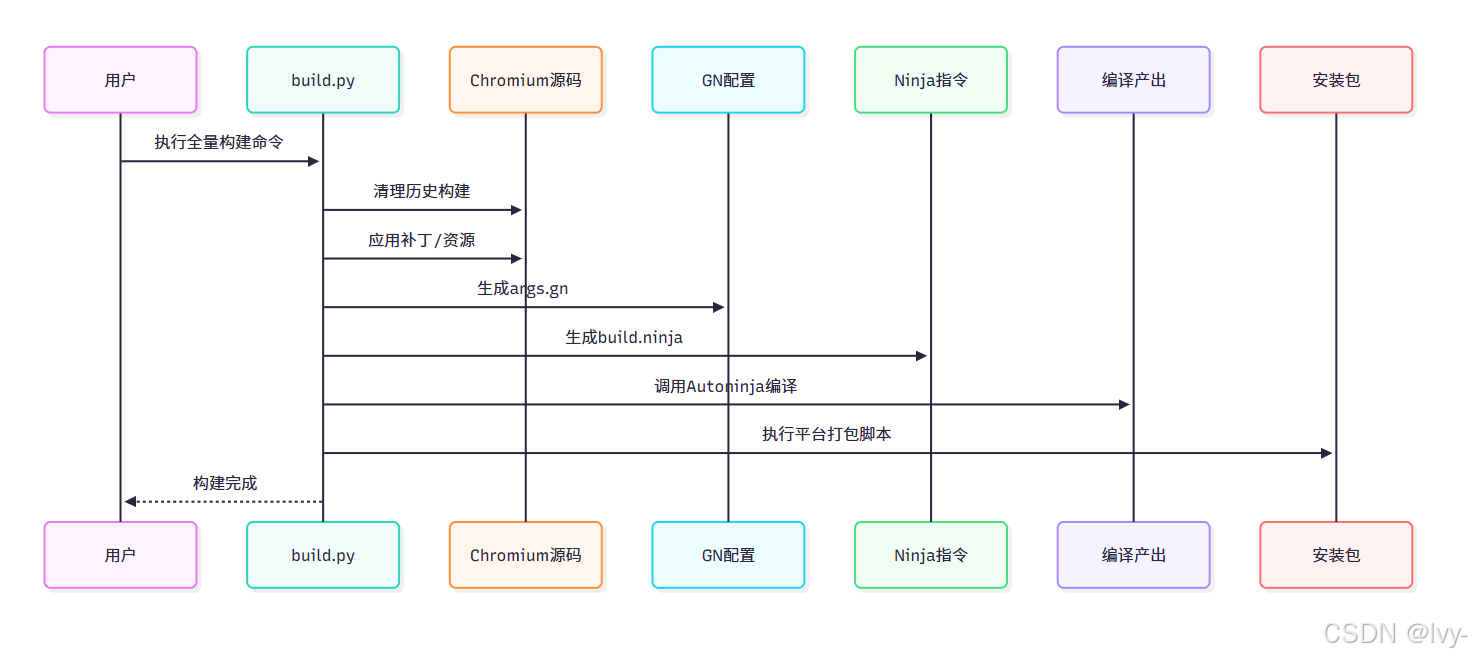
(该流程图展示从用户触发构建到产出安装包的完整流程:清理→定制→配置→编译→打包)
总结
BrowserOS构建系统是将Chromium源码转化为专属浏览器的核心基础设施。
通过Python脚本(build.py)协调GN配置生成与Autoninja并行编译,结合补丁应用和资源替换实现深度定制,最终产出各平台安装包。
该系统通过全流程自动化,使维护和迭代如此复杂的项目成为可能。
至此,我们已完成BrowserOS核心组件的技术解析。现在已大概理解了构成这款AI驱动浏览器的关键系统及其协作机制。
END ★,°:.☆( ̄▽ ̄).°★ 。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)