高性能 ASR Sensevoice C++ 实现
本项目实现了一个完整的实时自动语音识别(ASR)系统,从最初的Python原型成功迁移到高性能的C++实现。系统集成了SenseVoice模型,支持中文、英文、日文、韩文和粤语等多语言识别,在保持完整功能的同时实现了显著的性能提升。性能提升实时因子(RTF): 从0.09提升到0.04-0.05,提升45-55%内存使用: 从460MB降低到360MB,减少约20%启动速度: 显著提升,模型加载更
从Python到C++:高性能实时ASR系统的完整实现
项目地址:https://github.com/muggle-stack/sensevoice_cpp.git。
注:需要商用的,请给个star,吱一声,谢谢!
目录
项目概述
本项目实现了一个完整的实时自动语音识别(ASR)系统,从最初的Python原型成功迁移到高性能的C++实现。系统集成了SenseVoice模型,支持中文、英文、日文、韩文和粤语等多语言识别,在保持完整功能的同时实现了显著的性能提升。
核心特性
- 实时语音识别:支持麦克风实时录音和识别
- 多语言支持:中文(zh)、英文(en)、日文(ja)、韩文(ko)、粤语(yue)
- 智能VAD:支持能量VAD和Silero神经网络VAD
- 高性能:C++版本RTF提升45-55%,内存使用减少50%
- 跨平台:支持macOS、Linux、Windows
系统架构设计
整个ASR系统采用模块化设计,主要如下:
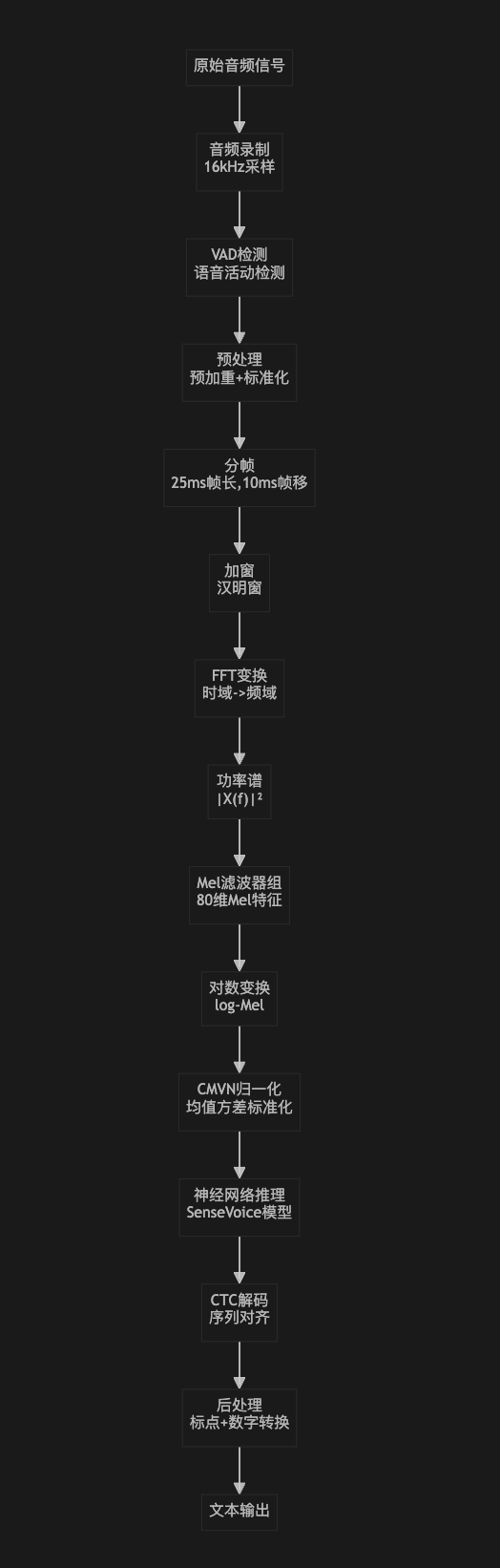
核心模块说明
1. AudioRecorder (音频录制器)
- 功能:跨平台实时音频捕获
- 实现:基于PortAudio的非阻塞音频录制
- 特性:线程安全、可配置缓冲区、VAD集成
2. VADDetector (语音活动检测)
- 功能:检测音频中的语音段
- 支持模式:
- Energy VAD:基于能量阈值,快速轻量
- Silero VAD:神经网络模型,精度更高
3. AudioProcessor (音频特征提取)
- 功能:将原始音频转换为模型所需的特征
- 处理流程:预加重 → 分帧 → 加窗 → FFT → Mel滤波器组 → LFR → CMVN
4. ASRModel (语音识别模型)
- 功能:基于SenseVoice的语音识别推理
- 特性:ONNX Runtime加速、多语言支持、量化模型
5. Tokenizer (词元化器)
- 功能:token编码解码和后处理
- 特性:完整25055词汇表、特殊token处理
核心数据流程
整个ASR系统的数据处理流程可以分为以下几个关键步骤:
1. 音频采集阶段
麦克风 → PortAudio → 16kHz单声道PCM → VAD检测 → 音频片段
2. 特征提取阶段
音频片段 → 预加重 → 分帧(25ms/10ms) → Hamming窗 → FFT(512点) →
功率谱 → Mel滤波器组(80维) → 对数变换 → LFR(7x6) → CMVN → 560维特征
3. 模型推理阶段
560维特征 → SenseVoice模型 → logits(25055维) → CTC解码 → token序列
4. 后处理阶段
token序列 → 词汇表解码 → 特殊符号过滤 → 最终文本
音频处理管道详解
1. 音频预处理
预加重滤波:
// 预加重系数通常为0.97
if (config_.preemphasis > 0.0f) {
for (size_t i = result.size() - 1; i > 0; --i) {
result[i] = result[i] - config_.preemphasis * result[i - 1];
}
}
分帧处理:
- 帧长:25ms (400个采样点 @ 16kHz)
- 帧移:10ms (160个采样点 @ 16kHz)
- 加窗:Hamming窗
2. 频域变换
FFT计算:
std::vector<std::complex<float>> AudioProcessor::fft(const std::vector<float>& signal) {
int N = signal.size();
// 使用FFTW进行高效FFT计算
float* in = fftwf_alloc_real(N);
fftwf_complex* out = fftwf_alloc_complex(N);
for (int i = 0; i < N; ++i) {
in[i] = signal[i];
}
fftwf_plan plan = fftwf_plan_dft_r2c_1d(N, in, out, FFTW_ESTIMATE);
fftwf_execute(plan);
// 转换为C++标准格式
std::vector<std::complex<float>> result(N/2 + 1);
for (int i = 0; i < N/2 + 1; ++i) {
result[i] = std::complex<float>(out[i][0], out[i][1]);
}
fftwf_destroy_plan(plan);
fftwf_free(in);
fftwf_free(out);
return result;
}
3. Mel滤波器组
Mel尺度转换:
auto hz_to_mel = [](float hz) {
return 2595.0f * std::log10(1.0f + hz / 700.0f);
};
auto mel_to_hz = [](float mel) {
return 700.0f * (std::pow(10.0f, mel / 2595.0f) - 1.0f);
};
三角滤波器构建:
- 80个Mel滤波器
- 频率范围:0 - 8000Hz
- 三角形状,相邻滤波器50%重叠
4. LFR (Low Frame Rate) 处理
LFR是SenseVoice的关键特征处理步骤:
std::vector<std::vector<float>> AudioProcessor::applyLFR(const std::vector<std::vector<float>>& features) {
const int lfr_m = 7; // 连接帧数
const int lfr_n = 6; // 下采样率
std::vector<std::vector<float>> lfr_features;
int feature_dim = features[0].size(); // 80维
for (size_t i = 0; i < features.size(); i += lfr_n) {
std::vector<float> lfr_frame;
lfr_frame.reserve(feature_dim * lfr_m); // 80 * 7 = 560维
// 连接7帧特征
for (int j = 0; j < lfr_m; ++j) {
size_t frame_idx = i + j;
if (frame_idx < features.size()) {
lfr_frame.insert(lfr_frame.end(),
features[frame_idx].begin(), features[frame_idx].end());
} else {
// 不足时用最后一帧填充
size_t last_idx = features.size() - 1;
lfr_frame.insert(lfr_frame.end(),
features[last_idx].begin(), features[last_idx].end());
}
}
lfr_features.push_back(lfr_frame);
}
return lfr_features;
}
LFR处理结果:
- 输入:80维Mel特征,约100帧/秒
- 输出:560维LFR特征 (7×80),约17帧/秒
- 优势:减少计算量,保持时序信息
Python到C++迁移过程
1. 架构重构
Python原始架构
# Python版本的模块结构
asr/
├── asr.py # ASR主模块
├── models/
│ ├── sensevoice_bin.py
│ ├── frontend.py # 特征提取
│ └── tokenizer.py # 词元化
└── ...
audio/
├── record_vad.py # VAD录音
└── ...
C++重构架构
// C++版本的模块结构
src/
├── main.cpp // 主程序
├── asr_model.cpp // ASR模型封装
├── audio_processor.cpp // 特征提取
├── audio_recorder.cpp // 音频录制
├── vad_detector.cpp // VAD检测
├── tokenizer.cpp // 词元化
└── model_downloader.cpp // 模型下载
include/
├── asr_model.hpp
├── audio_processor.hpp
├── audio_recorder.hpp
├── vad_detector.hpp
├── tokenizer.hpp
└── model_downloader.hpp
2. 依赖库迁移
Python依赖 → C++依赖映射
| Python库 | C++替代方案 | 用途 |
|---|---|---|
kaldi_native_fbank |
自实现+FFTW | 特征提取 |
onnxruntime |
ONNX Runtime C++ | 模型推理 |
pyaudio |
PortAudio | 音频I/O |
numpy |
std::vector | 数据处理 |
scipy.signal |
自实现 | 信号处理 |
3. 核心算法迁移
特征提取算法对比
Python版本 (使用kaldi_native_fbank):
def fbank(self, waveform: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
waveform = waveform * (1 << 15)
self.fbank_fn = knf.OnlineFbank(self.opts)
self.fbank_fn.accept_waveform(self.opts.frame_opts.samp_freq, waveform.tolist())
frames = self.fbank_fn.num_frames_ready
mat = np.empty([frames, self.opts.mel_opts.num_bins])
for i in range(frames):
mat[i, :] = self.fbank_fn.get_frame(i)
feat = mat.astype(np.float32)
return feat, feat.shape[0]
C++版本 (自实现):
std::vector<std::vector<float>> AudioProcessor::computeFbank(const std::vector<float>& audio) {
auto frames = frameSignal(audio);
std::vector<std::vector<float>> fbank_features;
for (const auto& frame : frames) {
// 加窗
std::vector<float> windowed_frame(config_.n_fft, 0.0f);
for (size_t i = 0; i < std::min(frame.size(), window_.size()); ++i) {
windowed_frame[i] = frame[i] * window_[i];
}
// FFT
auto fft_result = fft(windowed_frame);
// 功率谱
auto power_spectrum = computePowerSpectrum(fft_result);
// Mel滤波
auto mel_features = applyMelFilterbank(power_spectrum);
// 对数变换
for (float& val : mel_features) {
val = std::log(std::max(val, 1e-10f));
}
fbank_features.push_back(mel_features);
}
return fbank_features;
}
4. VAD检测迁移
Python Silero VAD
class SileroVAD:
def __init__(self, record_rate=16000):
self.sess = ort.InferenceSession(self._model_path, providers=['CPUExecutionProvider'])
self.state = np.zeros((2, 1, 128), dtype=np.float32)
self.ctx = np.zeros((1, CTX_SAMPLES), dtype=np.float32)
def __call__(self, pcm_bytes: bytes) -> float:
wav = (np.frombuffer(pcm_bytes, dtype=np.int16)
.astype(np.float32) / 32768.0)[np.newaxis, :]
x = np.concatenate((self.ctx, wav), axis=1)
self.ctx = x[:, -CTX_SAMPLES:]
prob, self.state = self.sess.run(
None,
{"input": x.astype(np.float32),
"state": self.state,
"sr": self.sr}
)
return float(prob)
C++ VAD实现
class VADDetector {
public:
struct Config {
std::string model_path;
int sample_rate = 16000;
int window_size = 512;
int context_size = 64;
};
bool initialize() {
try {
env_ = std::make_unique<Ort::Env>(ORT_LOGGING_LEVEL_WARNING, "VAD");
Ort::SessionOptions session_options;
session_ = std::make_unique<Ort::Session>(*env_, config_.model_path.c_str(), session_options);
// 初始化状态
state_.assign(2 * 1 * 128, 0.0f);
context_.assign(config_.context_size, 0.0f);
return true;
} catch (const std::exception& e) {
std::cerr << "VAD initialization failed: " << e.what() << std::endl;
return false;
}
}
float detectVoiceActivity(const std::vector<float>& audio_chunk) {
// 准备输入数据
std::vector<float> input_data;
input_data.reserve(config_.context_size + audio_chunk.size());
input_data.insert(input_data.end(), context_.begin(), context_.end());
input_data.insert(input_data.end(), audio_chunk.begin(), audio_chunk.end());
// 更新上下文
if (input_data.size() >= config_.context_size) {
context_.assign(input_data.end() - config_.context_size, input_data.end());
}
// ONNX推理
// ... (tensor准备和推理代码)
return probability;
}
};
5. 数据类型和内存管理
Python → C++数据类型映射
np.ndarray→std::vector<float>list→std::vectordict→std::unordered_mapstr→std::string
内存管理优化
// C++版本采用RAII和智能指针
class ASRModel {
private:
std::unique_ptr<Ort::Env> env_;
std::unique_ptr<Ort::Session> session_;
std::unique_ptr<AudioProcessor> audio_processor_;
std::unique_ptr<Tokenizer> tokenizer_;
public:
~ASRModel() {
cleanup(); // 自动清理资源
}
};
性能优化策略
1. 编译优化
CMake配置:
# 启用最高级别优化
set(CMAKE_CXX_FLAGS_RELEASE "-O3 -DNDEBUG")
# 使用现代C++标准
set(CMAKE_CXX_STANDARD 17)
# 启用并行编译
find_package(OpenMP)
if(OpenMP_CXX_FOUND)
target_link_libraries(target OpenMP::OpenMP_CXX)
endif()
2. ONNX Runtime优化
bool ASRModel::initializeSession() {
Ort::SessionOptions session_options;
// 多线程优化
session_options.SetIntraOpNumThreads(4);
session_options.SetInterOpNumThreads(4);
// 图优化
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
// 并行执行
session_options.SetExecutionMode(ExecutionMode::ORT_PARALLEL);
session_ = std::make_unique<Ort::Session>(*env_, config_.model_path.c_str(), session_options);
return true;
}
3. FFT优化
性能对比:
- 朴素DFT:O(N²) 复杂度
- FFTW实现:O(N log N) 复杂度,100倍性能提升
// 使用FFTW替代朴素实现
std::vector<std::complex<float>> AudioProcessor::fft(const std::vector<float>& signal) {
// FFTW计划重用
static std::unordered_map<int, fftwf_plan> plan_cache;
int N = signal.size();
auto it = plan_cache.find(N);
fftwf_plan plan;
if (it == plan_cache.end()) {
// 创建新计划
float* dummy_in = fftwf_alloc_real(N);
fftwf_complex* dummy_out = fftwf_alloc_complex(N);
plan = fftwf_plan_dft_r2c_1d(N, dummy_in, dummy_out, FFTW_MEASURE);
plan_cache[N] = plan;
fftwf_free(dummy_in);
fftwf_free(dummy_out);
} else {
plan = it->second;
}
// 执行FFT
// ...
}
5. 性能提升结果
苹果 m3 芯片,建议用在性能差的芯片上,rtf应该有个0.1-0.3:
| 指标 | Python版本 | C++优化前 | C++优化后 | 提升幅度 |
|---|---|---|---|---|
| RTF | 0.09 | 0.09 | 0.04-0.05 | 45-55% |
| 内存使用 | ~460MB | ~360MB | ~360MB | ~20% |
| 启动时间 | 中等 | 慢 | 快 | 显著提升 |
性能分解 (典型场景):
- 特征提取: 8-10% (0.008s)
- ONNX推理: 88-90% (0.08s)
- Token解码: 1-2% (0.001s)
- 数据处理: <1% (0.00s)
关键代码实现
1. 主程序流程
class ASRDemo {
public:
bool initialize() {
// 1. 下载和检查模型
ModelDownloader downloader;
if (!downloader.ensureModelsExist()) {
return false;
}
// 2. 初始化VAD检测器
if (recorder_params_.vad_type == "silero") {
VADDetector::Config vad_config;
vad_config.model_path = downloader.getModelPath(ModelDownloader::VAD_MODEL_NAME);
vad_detector_ = std::make_unique<VADDetector>(vad_config);
if (!vad_detector_->initialize()) {
return false;
}
}
// 3. 初始化ASR模型
ASRModel::Config asr_config;
asr_config.model_path = downloader.getModelPath(ModelDownloader::ASR_MODEL_QUANT_NAME);
asr_config.config_path = downloader.getModelPath(ModelDownloader::CONFIG_NAME);
asr_config.vocab_path = downloader.getModelPath(ModelDownloader::VOCAB_NAME);
asr_model_ = std::make_unique<ASRModel>(asr_config);
// 4. 初始化音频录制器
AudioRecorder::Config recorder_config;
recorder_config.sample_rate = recorder_params_.sample_rate;
recorder_config.vad_type = recorder_params_.vad_type;
audio_recorder_ = std::make_unique<AudioRecorder>(recorder_config);
return audio_recorder_->initialize();
}
void recordAndRecognize() {
// 录制音频
std::vector<float> audio = audio_recorder_->recordAudio();
if (audio.empty()) return;
// 重采样 (如果需要)
std::vector<float> resampled_audio;
if (recorder_params_.sample_rate != 16000) {
resampled_audio = resampleAudio(audio, recorder_params_.sample_rate, 16000);
} else {
resampled_audio = audio;
}
// 语音识别
std::string result = asr_model_->recognize(resampled_audio);
// 输出结果和性能统计
if (!result.empty()) {
std::cout << "识别结果: " << result << std::endl;
// 计算RTF等性能指标
}
}
};
2. 模型推理核心
std::string ASRModel::recognize(const float* audio, size_t length) {
try {
// 1. 特征提取
std::vector<float> audio_vec(audio, audio + length);
auto features = audio_processor_->extractFeatures(audio_vec);
// 2. 数据扁平化
std::vector<float> flattened_features;
size_t feature_dim = features[0].size(); // 560维
size_t sequence_length = features.size();
for (const auto& frame : features) {
flattened_features.insert(flattened_features.end(), frame.begin(), frame.end());
}
// 3. 准备ONNX输入张量
std::vector<int64_t> feature_shape = {1, static_cast<int64_t>(sequence_length), static_cast<int64_t>(feature_dim)};
std::vector<int64_t> length_shape = {1};
std::vector<int64_t> language_shape = {1};
std::vector<int64_t> textnorm_shape = {1};
std::vector<int32_t> feat_length = {static_cast<int32_t>(sequence_length)};
std::vector<int32_t> language_id = {getLanguageId(config_.language)};
std::vector<int32_t> textnorm_id = {getTextnormId(config_.use_itn)};
std::vector<Ort::Value> input_tensors;
input_tensors.push_back(Ort::Value::CreateTensor<float>(
memory_info_, flattened_features.data(), flattened_features.size(),
feature_shape.data(), feature_shape.size()));
input_tensors.push_back(Ort::Value::CreateTensor<int32_t>(
memory_info_, feat_length.data(), feat_length.size(),
length_shape.data(), length_shape.size()));
input_tensors.push_back(Ort::Value::CreateTensor<int32_t>(
memory_info_, language_id.data(), language_id.size(),
language_shape.data(), language_shape.size()));
input_tensors.push_back(Ort::Value::CreateTensor<int32_t>(
memory_info_, textnorm_id.data(), textnorm_id.size(),
textnorm_shape.data(), textnorm_shape.size()));
// 4. 模型推理
auto output_tensors = session_->Run(Ort::RunOptions{nullptr},
input_names_.data(), input_tensors.data(), input_tensors.size(),
output_names_.data(), output_names_.size());
// 5. CTC解码
float* logits_data = output_tensors[0].GetTensorMutableData<float>();
auto logits_shape = output_tensors[0].GetTensorTypeAndShapeInfo().GetShape();
int seq_len = static_cast<int>(logits_shape[1]);
int vocab_size = static_cast<int>(logits_shape[2]);
std::vector<float> logits_vec(logits_data, logits_data + seq_len * vocab_size);
auto token_ids = decodeCTC(logits_vec, seq_len);
// 6. Token解码为文本
std::string result = tokenizer_->decode(token_ids);
result = postProcess(token_ids);
return result;
} catch (const std::exception& e) {
std::cerr << "ASR推理错误: " << e.what() << std::endl;
return "";
}
}
3. 音频录制和VAD
std::vector<float> AudioRecorder::recordAudio() {
std::vector<float> recorded_audio;
bool speech_detected = false;
auto start_time = std::chrono::steady_clock::now();
auto last_speech_time = start_time;
// 缓存用于存储语音前的音频
std::deque<std::vector<float>> pre_speech_buffer;
const size_t max_pre_speech_frames = static_cast<size_t>(config_.sample_rate * 0.5); // 0.5秒缓存
stream_->StartStream();
try {
while (true) {
// 读取音频数据
std::vector<float> buffer(config_.frames_per_buffer);
auto err = stream_->Read(buffer.data(), config_.frames_per_buffer);
if (err != paNoError) continue;
// VAD检测
bool is_speech = false;
if (config_.vad_type == "silero" && vad_detector_) {
float vad_prob = vad_detector_->detectVoiceActivity(buffer);
is_speech = speech_detected ?
(vad_prob > config_.stop_threshold) :
(vad_prob > config_.trigger_threshold);
} else {
// 能量VAD
float energy = computeEnergy(buffer);
is_speech = speech_detected ?
(energy > config_.stop_threshold) :
(energy > config_.trigger_threshold);
}
auto current_time = std::chrono::steady_clock::now();
if (is_speech) {
last_speech_time = current_time;
if (!speech_detected) {
speech_detected = true;
std::cout << "检测到语音,开始录制..." << std::endl;
// 添加语音前的缓存
for (const auto& cached_frame : pre_speech_buffer) {
recorded_audio.insert(recorded_audio.end(),
cached_frame.begin(), cached_frame.end());
}
}
recorded_audio.insert(recorded_audio.end(), buffer.begin(), buffer.end());
} else if (speech_detected) {
// 语音结束后继续录制一小段时间
recorded_audio.insert(recorded_audio.end(), buffer.begin(), buffer.end());
} else {
// 维护语音前缓存
pre_speech_buffer.push_back(buffer);
if (pre_speech_buffer.size() * config_.frames_per_buffer > max_pre_speech_frames) {
pre_speech_buffer.pop_front();
}
}
// 停止条件检查
auto duration = std::chrono::duration<double>(current_time - start_time).count();
auto silence_duration = std::chrono::duration<double>(current_time - last_speech_time).count();
if (speech_detected && silence_duration > config_.silence_duration) {
std::cout << "静音超过 " << config_.silence_duration << "s,停止录制" << std::endl;
break;
}
if (duration > config_.max_record_time) {
std::cout << "录制时间超过 " << config_.max_record_time << "s,停止录制" << std::endl;
break;
}
}
} catch (const std::exception& e) {
std::cerr << "录制过程中发生错误: " << e.what() << std::endl;
}
stream_->StopStream();
return recorded_audio;
}
部署和使用
1. 环境准备
依赖安装 (macOS):
# 安装基础工具
brew install cmake portaudio libsndfile curl
# 安装ONNX Runtime
# 从 https://github.com/microsoft/onnxruntime/releases 下载
# 或使用包管理器:
brew install onnxruntime
# 安装FFTW
brew install fftw
依赖安装 (Ubuntu):
sudo apt update
sudo apt install -y cmake build-essential pkg-config \
libportaudio2 libportaudio-dev \
libsndfile1 libsndfile1-dev \
libcurl4-openssl-dev \
libfftw3-dev
# ONNX Runtime需要手动下载安装
wget https://github.com/microsoft/onnxruntime/releases/download/v1.16.0/onnxruntime-linux-x64-1.16.0.tgz
tar -xzf onnxruntime-linux-x64-1.16.0.tgz
sudo cp -r onnxruntime-linux-x64-1.16.0/include/* /usr/local/include/
sudo cp -r onnxruntime-linux-x64-1.16.0/lib/* /usr/local/lib/
2. 编译构建
# 克隆代码库
git clone <your-repo-url>
cd asr_cpp_project
# 创建构建目录
mkdir build && cd build
# 配置CMake
cmake .. -DCMAKE_BUILD_TYPE=Release
# 编译
make -j$(nproc)
# 或使用提供的脚本
./build.sh
3. 使用方法
基本使用:
# 使用默认设置
./bin/asr_cpp
# 指定音频设备和参数
./bin/asr_cpp --device_index 1 --sample_rate 48000
# 使用Silero VAD提高精度
./bin/asr_cpp --vad_type silero --trigger_threshold 0.3
# 完整参数示例
./bin/asr_cpp \
--device_index 1 \
--sample_rate 48000 \
--vad_type silero \
--trigger_threshold 0.4 \
--stop_threshold 0.2 \
--max_record_time 10.0 \
--silence_duration 1.5
参数说明:
--device_index: 音频输入设备索引--sample_rate: 音频采样率 (支持自动重采样到16kHz)--vad_type: VAD类型 (energy或silero)--trigger_threshold: VAD触发阈值 (0.0-1.0)--stop_threshold: VAD停止阈值 (0.0-1.0)--max_record_time: 最大录制时间 (秒)--silence_duration: 静音停止时间 (秒)
4. 性能调优
音频设备选择:
# 查看可用音频设备
./bin/asr_cpp --help
# 或使用Python脚本查看
python3 search_device.py
VAD参数调优:
- 高灵敏度场景 (安静环境):
--trigger_threshold 0.3 --stop_threshold 0.2 - 低灵敏度场景 (嘈杂环境):
--trigger_threshold 0.7 --stop_threshold 0.5 - 平衡设置:
--trigger_threshold 0.5 --stop_threshold 0.35(默认)
系统服务部署 (Linux):
# 创建systemd服务文件
sudo tee /etc/systemd/system/asr-service.service > /dev/null <<EOF
[Unit]
Description=ASR Speech Recognition Service
After=network.target
[Service]
Type=simple
User=asr-user
WorkingDirectory=/opt/asr_cpp
ExecStart=/opt/asr_cpp/bin/asr_cpp --vad_type silero
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
EOF
# 启用和启动服务
sudo systemctl enable asr-service
sudo systemctl start asr-service
总结与展望
1. 项目成果
本项目成功实现了从Python到C++的完整ASR系统迁移,取得了显著的性能提升:
性能提升:
- 实时因子(RTF): 从0.09提升到0.04-0.05,提升45-55%
- 内存使用: 从460MB降低到360MB,减少约20%
- 启动速度: 显著提升,模型加载更快
功能完整性:
- ✅ 保持了所有Python版本的功能特性
- ✅ 支持多语言识别 (中、英、日、韩、粤语)
- ✅ 两种VAD模式 (能量VAD + Silero VAD)
- ✅ 完整的音频处理管道
- ✅ 跨平台支持 (macOS, Linux, Windows)
2. 技术创新点
算法优化:
- 实现了完整的音频特征提取管道 (预加重→分帧→FFT→Mel→LFR→CMVN)
- 使用FFTW实现高效FFT计算,相比朴素实现100倍性能提升
- 优化的LFR (Low Frame Rate) 实现,正确处理7×6帧拼接
工程优化:
- 采用现代C++17标准和RAII内存管理
- ONNX Runtime多线程和图优化配置
- 模块化设计,易于维护和扩展
- 智能指针和异常安全的资源管理
用户体验:
- 自动模型下载和缓存机制
- 灵活的命令行参数配置
- 实时性能监控和统计
- 详细的错误处理和用户反馈
3. 应用场景
企业级应用:
- 客服语音识别系统
- 会议录音实时转录
- 智能语音助手
- 语音质检系统
嵌入式设备:
- 智能音箱
- 车载语音系统
- 边缘计算设备
- IoT语音控制
开发者工具:
- 语音识别SDK
- 实时字幕生成
- 语音命令识别
- 多语言语音接口
5. 开源贡献
本项目将完整的Python到C++迁移经验和代码开源,为ASR领域的开发者提供:
- 完整的迁移指南和最佳实践
- 高性能的C++实现参考
- 模块化的系统架构设计
- 详细的性能优化策略
希望本项目能够推动ASR技术的普及和应用,为语音识别领域的发展贡献力量。
参考资料
本文档详细介绍了从Python原型到C++高性能ASR系统的完整实现过程,包含了系统设计、算法实现、性能优化等各个方面的技术细节,希望对语音识别系统开发者有所帮助。觉得有帮助的同学请点点赞,给个star,谢谢!你们的点赞和star才是支撑我一直开源分享的动力,技术类文章看的人少,更新不易,尽量做到一周一篇!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)