Vivado中FFT IP核并多次叠加
但是项目有个需求,需要在较大的噪声中识别到目标频率,经过仿真发现,多次FFT叠加可以消除部分噪声,而目标频率分量可以在叠加中越来越大,达到凸显目标频率的目的,缺点也很明显,一个字,慢!第一个是输入位宽,第二个是相位因数宽度,相位因数宽度越大,计算精度越高,但同时也会需要消耗更多资源。:👆上面那个设置的使能信号,我只需要这个IP核一直做FFT,所以一直使能就行。: 串行总线输入FFT IP核进行运
项目中使用到了FFT IP核,记录一下例化方法,怕老了以后忘了。
原理就不说了,网上有好多文章能够说的比我更透彻,还是不误导了哈哈😂。对于我来说,FFT就是将时域的信号转化到频域,输出各个频率分量的值。
接下来配置FFT IP核。
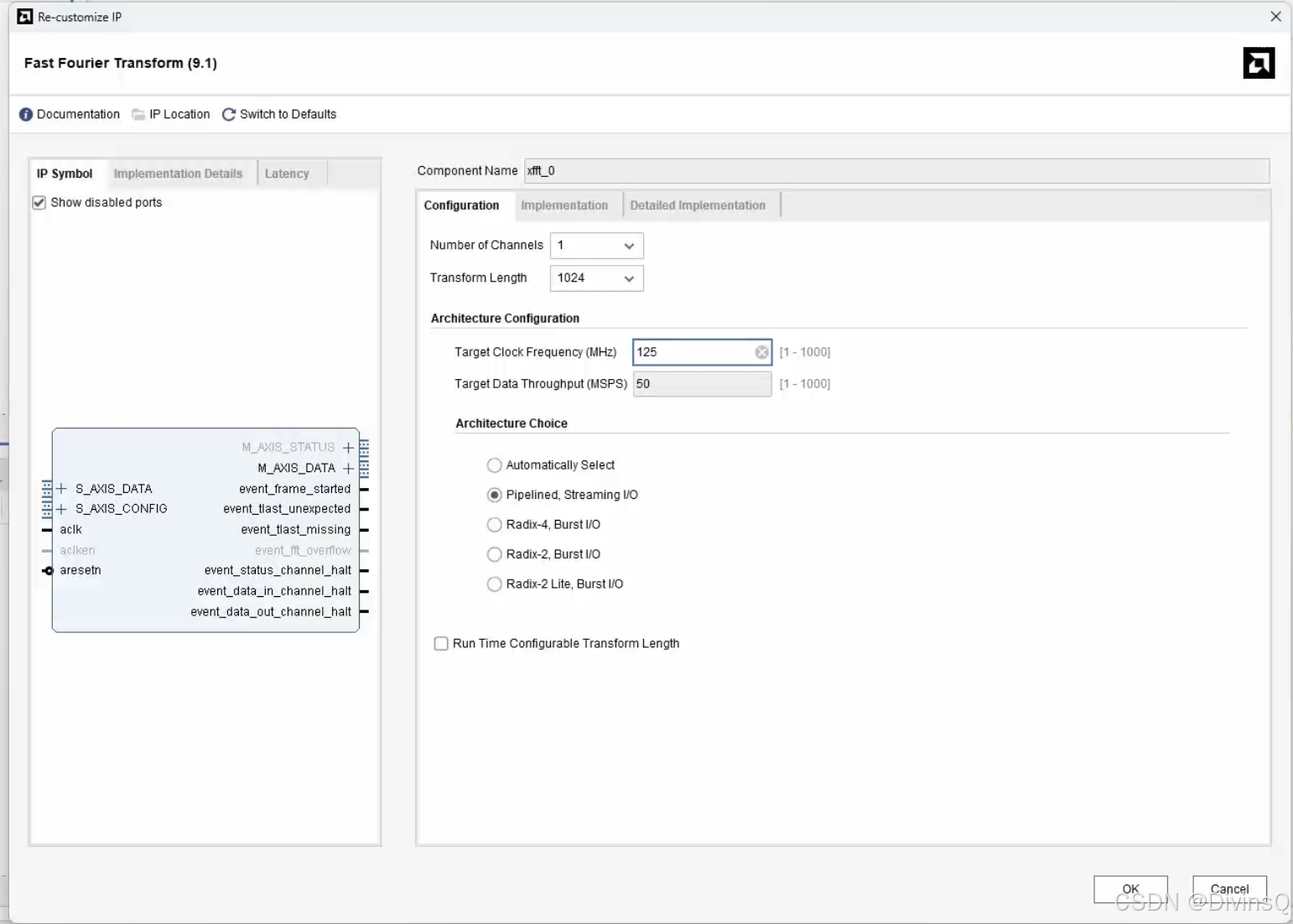
Number of Channels: FFT IP核的通道数,看需求,我只需要使用一个通道。
Transform Length: 快速傅立叶变化长度,我设置1024就是根据时钟采集1024个点进行 FFT。
Target Clock Frequency: 就是给FFT IP核的时钟。
Architecture Choice: Automatically selected就是自动选择所需要的;
pipelined streaming: 并行流水线结构;
radix-4, burst i/o: 基4 I/O突发结构;
radix-2, burst i/o: 基2 I/O突发结构;
radix-2 life, burst i/o: 基2 I/O突发结构。
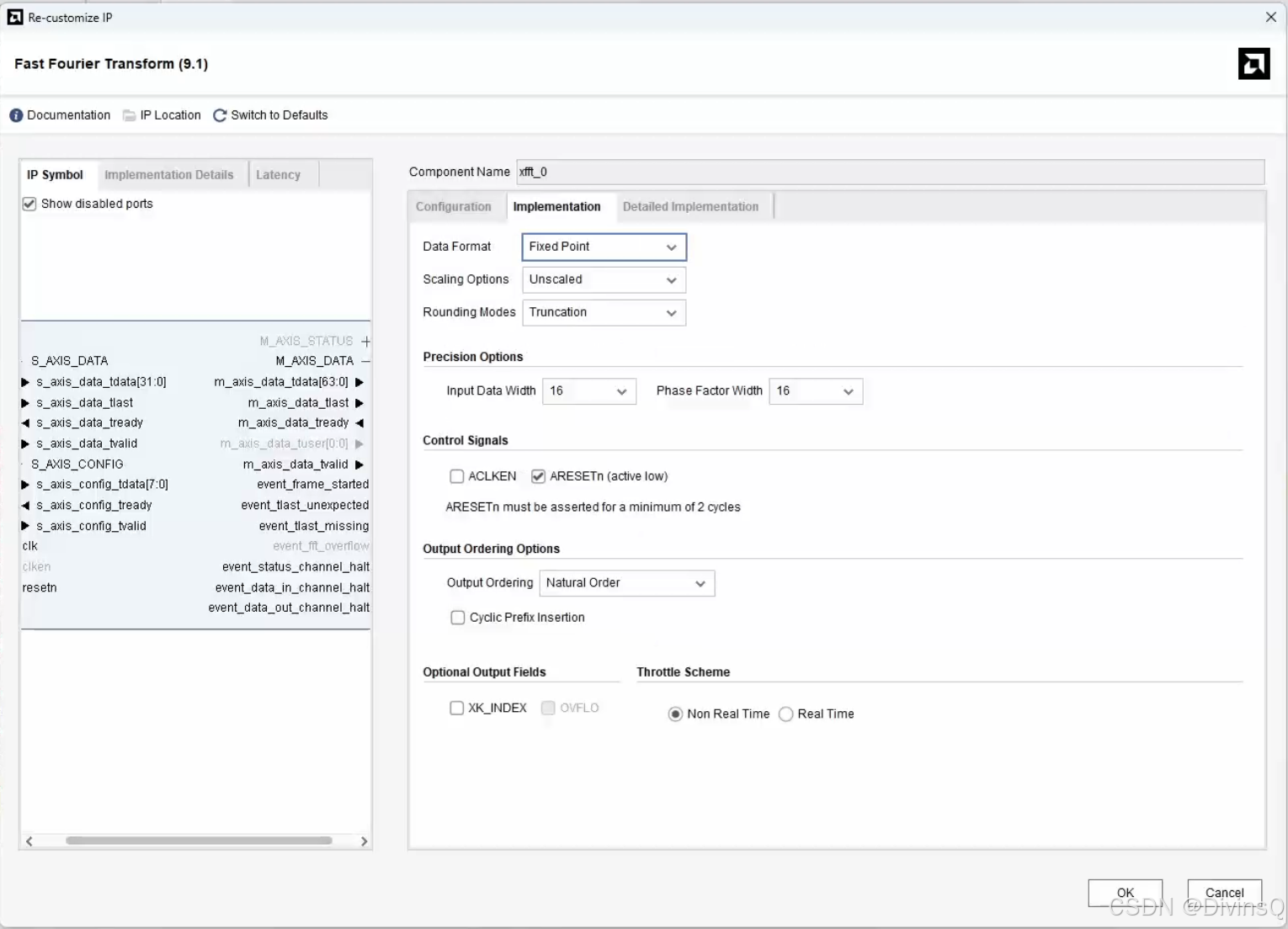
Data format: 数据格式,FixedPoint是定点全精度,FloatingPoint是定点缩减位宽。
Scaling Options: 缩放选项,block floating point的输入输出位宽一样,自动缩放;Scaled 没用过🤫;Unsacaled不会溢出,输入是16位,输出就是32位。
Precision Options: 第一个是输入位宽,第二个是相位因数宽度,相位因数宽度越大,计算精度越高,但同时也会需要消耗更多资源。
ARESETn (active low): 复位信号,低位有效,一定要勾😭,找了半天问题结果是复位的问题谁懂。
output odering options: 输出顺序,Nature Order就是从1到1024;Bit/Digital Reserved Order就是从1024到1;cyclic perfix insertion就是... 不懂没用过。
再接下来就是IP核的各个接口。
xfft_0 fft (
.aclk(clk), // input wire aclk
.aresetn(rst_n), // input wire aresetn
.s_axis_config_tdata('b1), // input wire [7:0] s_axis_config_tdata
.s_axis_config_tvalid('b1), // input wire s_axis_config_tvalid
.s_axis_config_tready(s_axis_config_tready), // output wire s_axis_config_tready
.s_axis_data_tdata({16'b0,data_in,4'b0}),// input wire [31 : 0] s_axis_data_tdata
.s_axis_data_tvalid(s_axis_data_tvalid), // input wire s_axis_data_tvalid
.s_axis_data_tready(s_axis_data_tready), // output wire s_axis_data_tready
.s_axis_data_tlast(s_axis_data_tlast), // input wire s_axis_data_tlast
.m_axis_data_tdata({i,r}), // output wire [63 : 0] m_axis_data_tdata
.m_axis_data_tvalid(m_axis_data_tvalid), // output wire m_axis_data_tvalid
.m_axis_data_tready('b1), // input wire m_axis_data_tready
.m_axis_data_tlast(m_axis_data_tlast), // output wire m_axis_data_tlast
.event_frame_started(event_frame_started), // output wire event_frame_started
.event_tlast_unexpected(event_tlast_unexpected), // output
.event_tlast_missing(event_tlast_missing), // output
.event_status_channel_halt(event_status_channel_halt), // output
.event_data_in_channel_halt(event_data_in_channel_halt), // output
.event_data_out_channel_halt(event_data_out_channel_halt) // output
);s_axis_config_tdata: 扣1是FFT,扣0是IFFT。
s_axis_config_tvalid:👆上面那个设置的使能信号,我只需要这个IP核一直做FFT,所以一直使能就行。
s_axis_config_tready: 设置完毕后两个时钟周期拉高。
s_axis_data_tdata: 串行总线输入FFT IP核进行运算,高16位是虚数,低16位是实数。
s_axis_data_tvalid: 👆上面串行输入数据的使能信号。
s_axis_data_tready: IP核已准备好可以接受输入数据。
s_axis_data_tlast: 串行总线信号输入完毕时拉高。
m_axis_data_tdata: 输出FFT结果,高32为虚部,低32位为实部。 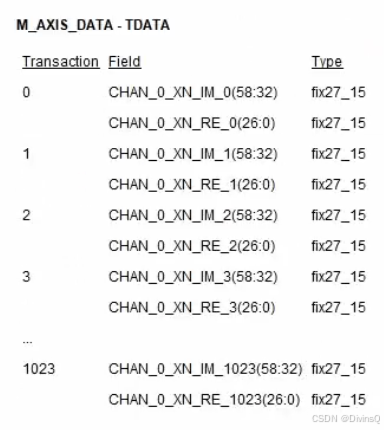
从此处可知,实数和虚数各自的低15位为小数,高12位为整数。
m_axis_data_tvalid: 输出数据可读信号,拉高时开始输出。
m_axis_data_tready: 拉高就完事了。
m_axis_data_tlast: 串行数据输出到最后一个数时拉高,下一个时钟周期就拉低。
例化完毕。
但是项目有个需求,需要在较大的噪声中识别到目标频率,经过仿真发现,多次FFT叠加可以消除部分噪声,而目标频率分量可以在叠加中越来越大,达到凸显目标频率的目的,缺点也很明显,一个字,慢!
附上例化IP核加80次叠加的代码:
`timescale 1ns / 1ps
module FFT(
input clk,
input clk_50m,
input rst_n,
input flag,
input [11:0] data_in,
output m_axis_data_tvalid,
output [26:0] r1,
output [26:0] i1,
output [61:0] p_tune_ave,
output [61:0] p_tune_prev,
output fft_done,
output [7:0] data,
input tx_data_ready
);
parameter N = 1023;
parameter Fs_N = 125;
parameter aim_fq = 13000;
parameter fft_times = 80;
reg s_axis_data_tlast;
reg s_axis_data_tvalid;
reg fq_tvalid;
wire [31:0] r;
wire [31:0] i;
reg [13:0] cnt;
reg [9:0] cnt_fq;
wire [53:0] r1_square;
wire [53:0] i1_square;
(* MARK_DEBUG="true" *)wire [16:0] x;
reg [55:0] p_tune;
reg [59:0] p_tune_prev;
reg [9:0] start_cnt;
reg start;
reg [6:0] ave_cnt;
reg [61:0] p_tune_ave;
reg fft_done;
xfft_0 fft (
.aclk(clk), // input wire aclk
.aresetn(rst_n), // input wire aresetn
.s_axis_config_tdata('b1), // input wire [7 : 0] s_axis_config_tdata
.s_axis_config_tvalid('b1), // input wire s_axis_config_tvalid
.s_axis_config_tready(s_axis_config_tready), // output wire s_axis_config_tready
.s_axis_data_tdata({16'b0,data_in,4'b0}), // input wire [31 : 0] s_axis_data_tdata
.s_axis_data_tvalid(s_axis_data_tvalid), // input wire s_axis_data_tvalid
.s_axis_data_tready(s_axis_data_tready), // output wire s_axis_data_tready
.s_axis_data_tlast(s_axis_data_tlast), // input wire s_axis_data_tlast
.m_axis_data_tdata({i,r}), // output wire [63 : 0] m_axis_data_tdata
.m_axis_data_tvalid(m_axis_data_tvalid), // output wire m_axis_data_tvalid
.m_axis_data_tready('b1), // input wire m_axis_data_tready
.m_axis_data_tlast(m_axis_data_tlast), // output wire m_axis_data_tlast
.event_frame_started(event_frame_started), // output wire event_frame_started
.event_tlast_unexpected(event_tlast_unexpected), // output wire event_tlast_unexpected
.event_tlast_missing(event_tlast_missing), // output wire event_tlast_missing
.event_status_channel_halt(event_status_channel_halt), // output wire event_status_channel_halt
.event_data_in_channel_halt(event_data_in_channel_halt), // output wire event_data_in_channel_halt
.event_data_out_channel_halt(event_data_out_channel_halt) // output wire event_data_out_channel_halt
);
wire [26:0] r1;
assign r1 = r[26:0];
wire [26:0] i1;
assign i1 = i[26:0];
//always@(posedge clk or negedge rst_n)
//begin
// if(!rst_n) start_cnt <= 0;
// else begin
// if(start_cnt < 1023) start_cnt <= start_cnt + 1;
// end
//end
//always@(posedge clk or negedge rst_n)
//begin
// if(!rst_n) start <= 0;
// else begin
// if(start_cnt == 1022) start <= 1;
// else if(start == 1) start <= 0;
// end
//end
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) cnt <= 0;
else begin
if(flag) cnt <= 0;
else if(ave_cnt != fft_times - 1 && m_axis_data_tlast) cnt <= 0;
else if(cnt < N) cnt <= cnt + 1;
else cnt <= cnt;
end
end
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) s_axis_data_tvalid <= 0;
else begin
if(flag) s_axis_data_tvalid <= 1;
else if(ave_cnt != fft_times - 1 && m_axis_data_tlast) s_axis_data_tvalid <= 1;
else if(cnt == N) s_axis_data_tvalid <= 0;
end
end
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) s_axis_data_tlast <= 0;
else begin
if(flag) s_axis_data_tlast <= 0;
else if(ave_cnt != fft_times - 1 && m_axis_data_tlast) s_axis_data_tlast <= 0;
else if(cnt == N && s_axis_data_tvalid) s_axis_data_tlast <= 1;
end
end
mult_gen_0 mult_r (
.CLK(clk), // input wire CLK
.A(r1), // input wire [26 : 0] A
.B(r1), // input wire [26 : 0] B
.P(r1_square) // output wire [53 : 0] P
);
mult_gen_1 mult_i (
.CLK(clk), // input wire CLK
.A(i1), // input wire [26 : 0] A
.B(i1), // input wire [26 : 0] B
.P(i1_square) // output wire [53 : 0] P
);
mult_gen_2 mult_x (
.CLK(clk), // input wire CLK
.A(cnt_fq), // input wire [9 : 0] A
.P(x) // output wire [16 : 0] P
);
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) cnt_fq <= 0;
else begin
if(m_axis_data_tlast) cnt_fq <= 0;
else if(m_axis_data_tvalid) cnt_fq <= cnt_fq + 1;
else cnt_fq <= cnt_fq;
end
end
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) p_tune <= 0;
else begin
if(m_axis_data_tlast) p_tune <= 0;
else if(x == aim_fq||x == aim_fq + Fs_N||x == aim_fq + Fs_N*2) p_tune <= p_tune + fq;
end
end
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) ave_cnt <= 0;
else begin
if(ave_cnt == fft_times) ave_cnt <= 0;
if(m_axis_data_tlast) ave_cnt <= ave_cnt + 1;
end
end
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) p_tune_ave <= 0;
else begin
if(fft_done) p_tune_ave <= 0;
else if(m_axis_data_tlast) p_tune_ave <= p_tune_ave + p_tune;
end
end
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) fft_done <= 0;
else begin
if(fft_done) fft_done <= 0;
else if(ave_cnt == fft_times) fft_done <= 1;
end
end
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) p_tune_prev <= 0;
else begin
if(fft_done) p_tune_prev <= p_tune_ave;
end
end
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) fq_tvalid <= 0;
else fq_tvalid <= m_axis_data_tvalid;
end
reg [59:0] fft_ave [0:1023];
reg [10:0] a;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) begin
for(a=0;a<='d1023;a=a+1) begin
fft_ave[a] <= 0;
end
end
else
begin
if(ave == 'd1023) begin
for(a=0;a<='d1023;a=a+1) begin
fft_ave[a] <= 0;
end
end
else if(fq_tvalid) begin
fft_ave[cnt_fq-1] <= fft_ave[cnt_fq-1] + fq;
end
end
end
(* MARK_DEBUG="true" *)reg [10:0] ave;
(* MARK_DEBUG="true" *)reg [59:0] ave_value;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) ave <= 0;
else begin
if(fft_done) ave <= 0;
else if(ave < 'd1024) begin
ave <= ave + 1;
end
end
end
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) ave_value <= 0;
else begin
if(ave == 'd1023) ave_value <= 0;
else if(ave < 'd1024) begin
ave_value <= fft_ave[ave+1];
end
end
end
(* MARK_DEBUG="true" *)wire [55:0] fq;
assign fq = r1_square + i1_square;
endmodule

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 35
35 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)