GEMeX-系列文章 GEMeX, GEMeX-ThinkVG
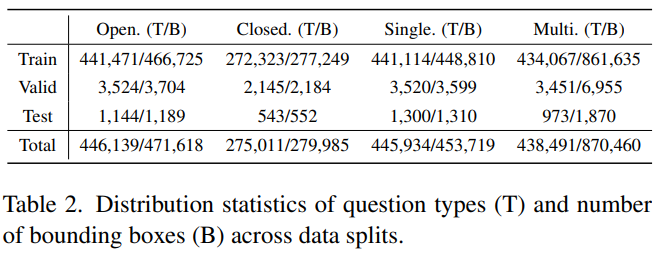
数据集构建步骤:首先通过Chest ImaGenome构建数据对。然后利用GPT-4o产生多样的回答;之后用OpenBioLLM-70B 对报告重构(aaditya/Llama3-OpenBioLLM-70B 是公认在医疗LLM上表现良好)数据集评估质量:抽取300个样本用GPT-4o去验证数据集评价指标:回答的准确率, 推理能力,定位能力,利用BLEU和ROUGE来评价文本部分。
**
数据集只开源测试数据集,但没开源训练数据
持续关注中,因为我对这个数据很感兴趣
不过 大概率不了了之,一直coming soon
until 2025.07.09
**
GEMeX-ThinkVG: Towards Thinking with Visual Grounding in Medical VQA via Reinforcement Learning
paper: https://arxiv.org/pdf/2506.17939v1
GEMeX: A Large-Scale, Groundable, and Explainable Medical VQA paper: Benchmark for Chest X-ray Diagnosis
paper:https://arxiv.org/pdf/2411.16778
2024 ICCV —> 2025.06 arixv 香港理工
主页:https://www.med-vqa.com/GEMeX

文章目录
一. GEMeX: 大规模的,有定位的,可解释的医学问答的文章 benchmark
1.1. 研究背景
当前Med-VQA面临两个问题,这限制了开发可靠的和用户友好的Med-VQA:
(1) 目前的回答缺乏可解释性,限制了病人和初级医生的理解能力;
(2) 问题只通过固定的格式,不能适应实际多样的场景
GEMeX主要包括两个方面:
(1) 一种多模态的可解释性机制,为每个问题-答案提供详细的视觉和文本解释,从而提高答案的可解释性
(2) 四种类型的回答:open-ended, closed-ended, single-choice, multiple-choice
151,025 image 和 1,605,575 问答对,主要是数据集
1.2. 数据集介绍
-
数据集构建步骤:首先通过Chest ImaGenome构建数据对。然后利用GPT-4o产生多样的回答;之后用OpenBioLLM-70B 对报告重构(aaditya/Llama3-OpenBioLLM-70B 是公认在医疗LLM上表现良好)
-
数据集评估质量:抽取300个样本用GPT-4o去验证
-
数据集评价指标:回答的准确率, 推理能力,定位能力,利用BLEU和ROUGE来评价文本部分。
-
评估了12个有代表性LVLMs,其中包括7个通用架构(LLaVA, DeepSeek-VL, GPT-4o-mini),5个医疗架构(LLaVA-Med, XrayGPT, RadFM)
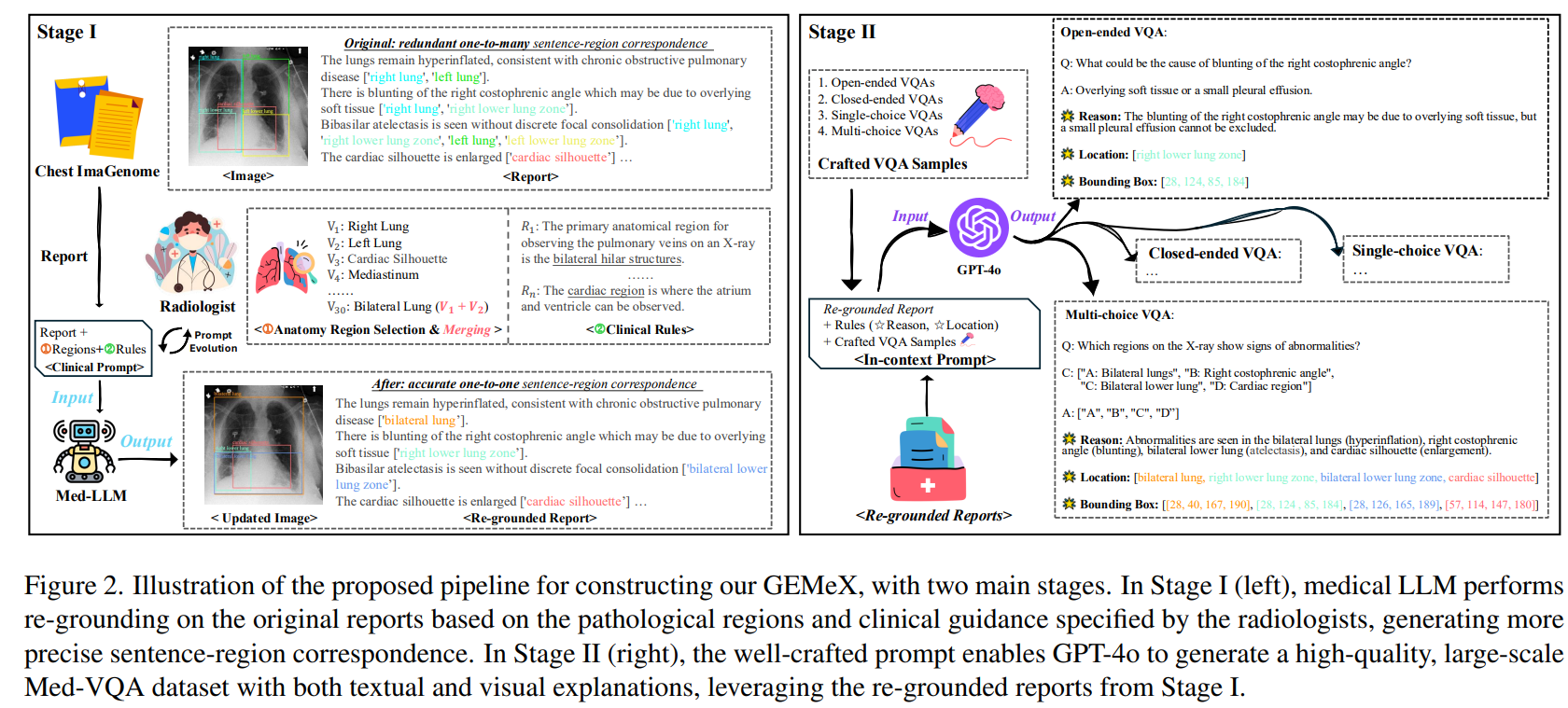
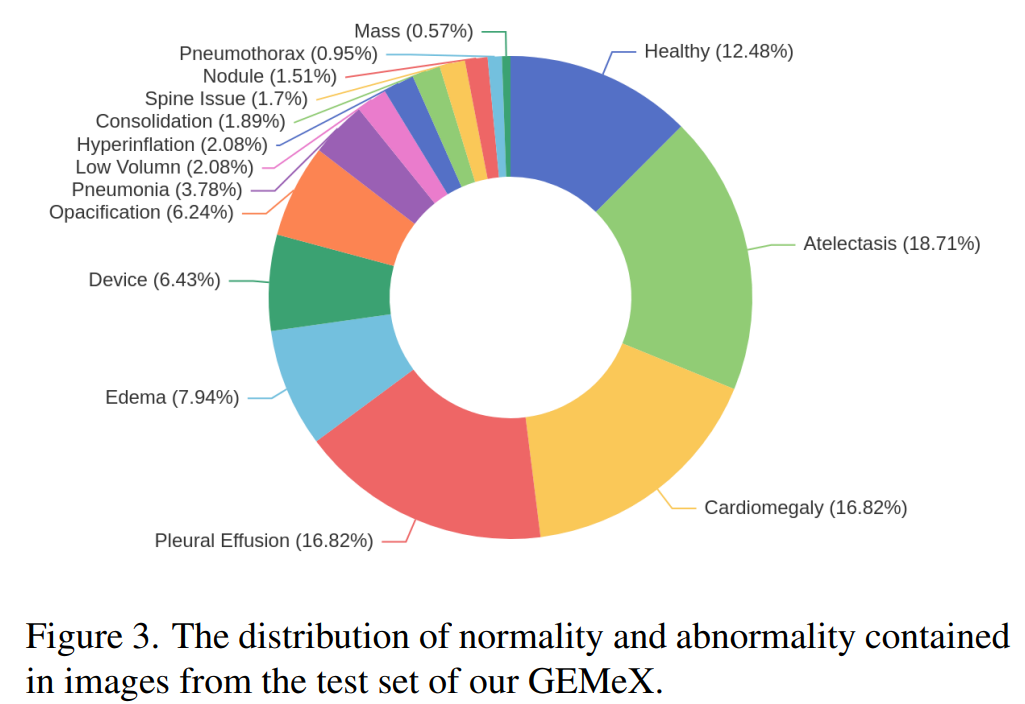
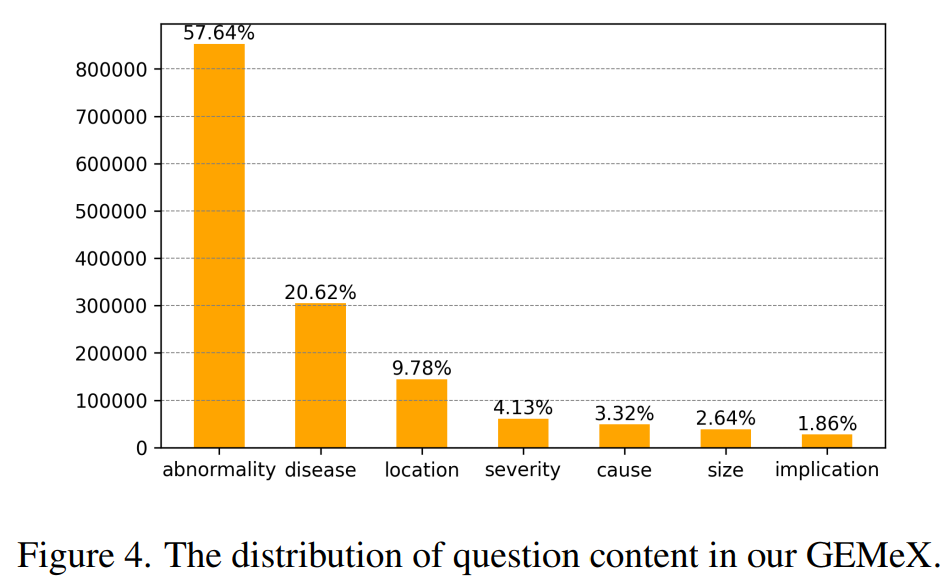
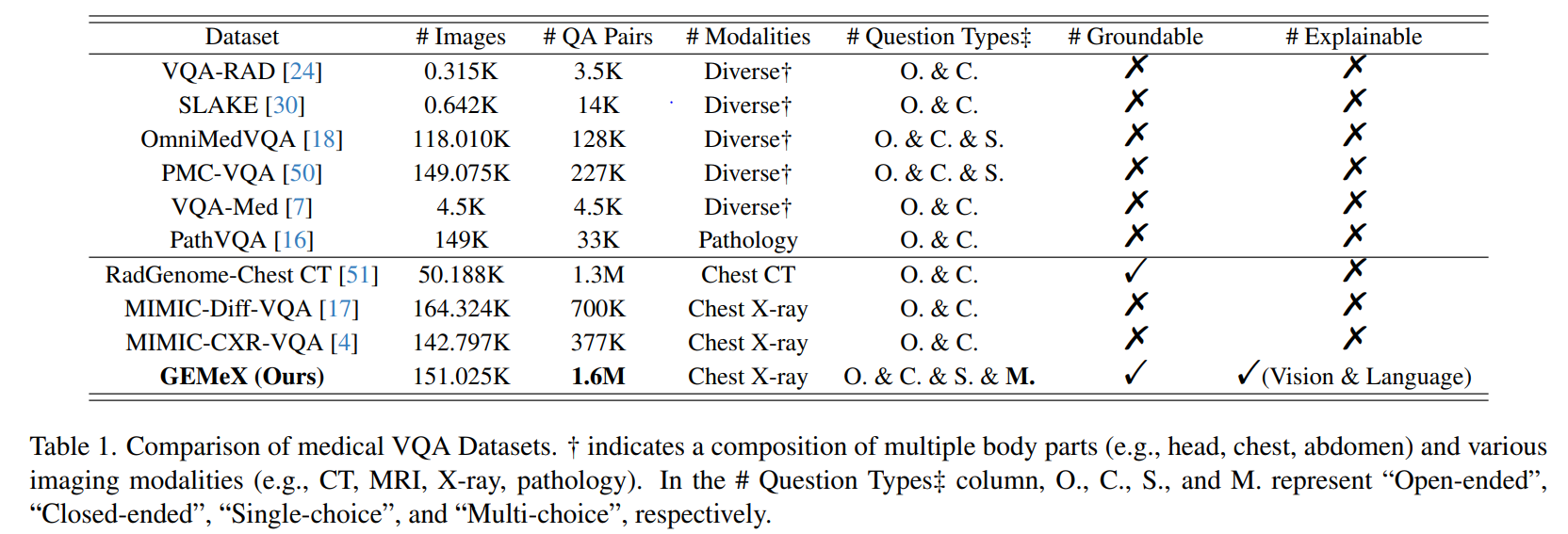
目前的开源数据集

训练数据集和LLaVA-Med微调的format
模型训练方法:问题类型感知的指令微调LLaVA-Med-v1-7B
1.3. 实验结果
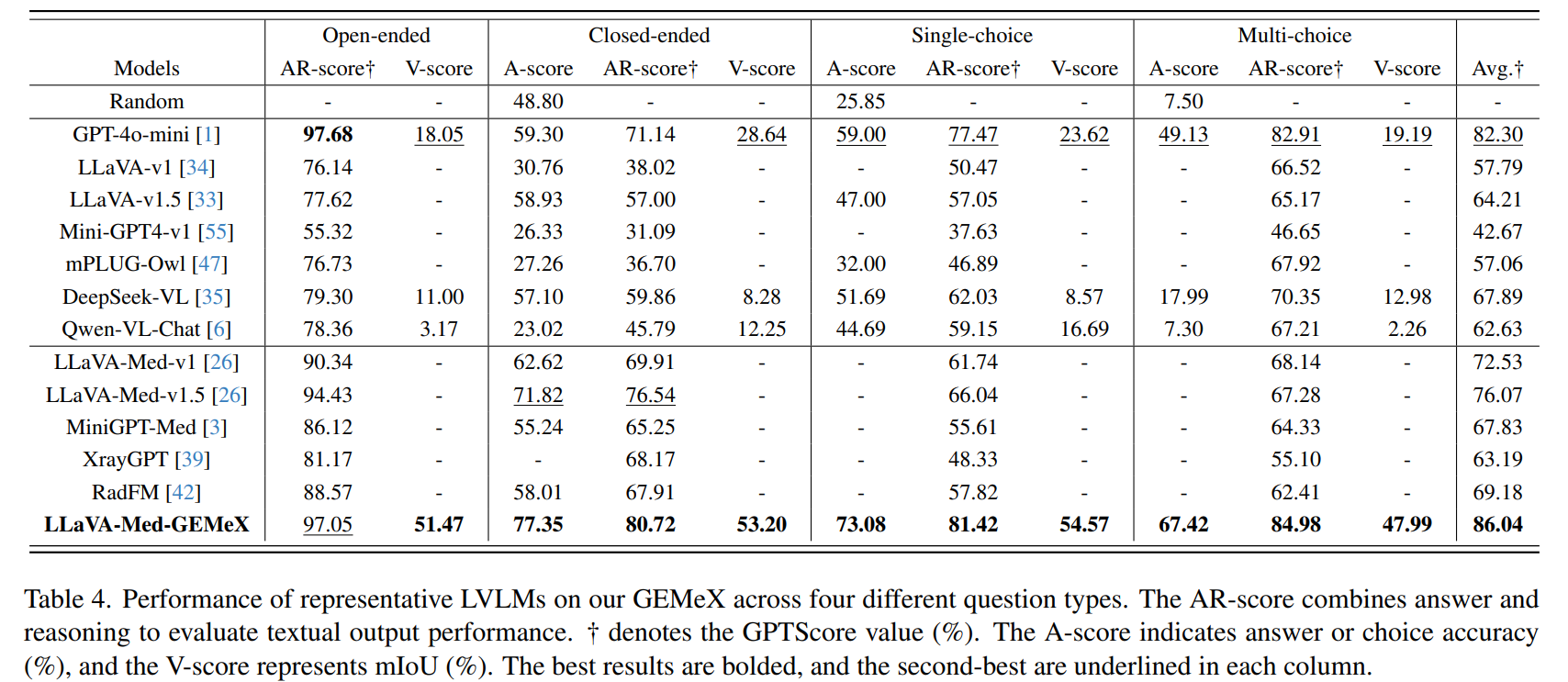
1.3.2. 评估LVLMs的进一步NLP表现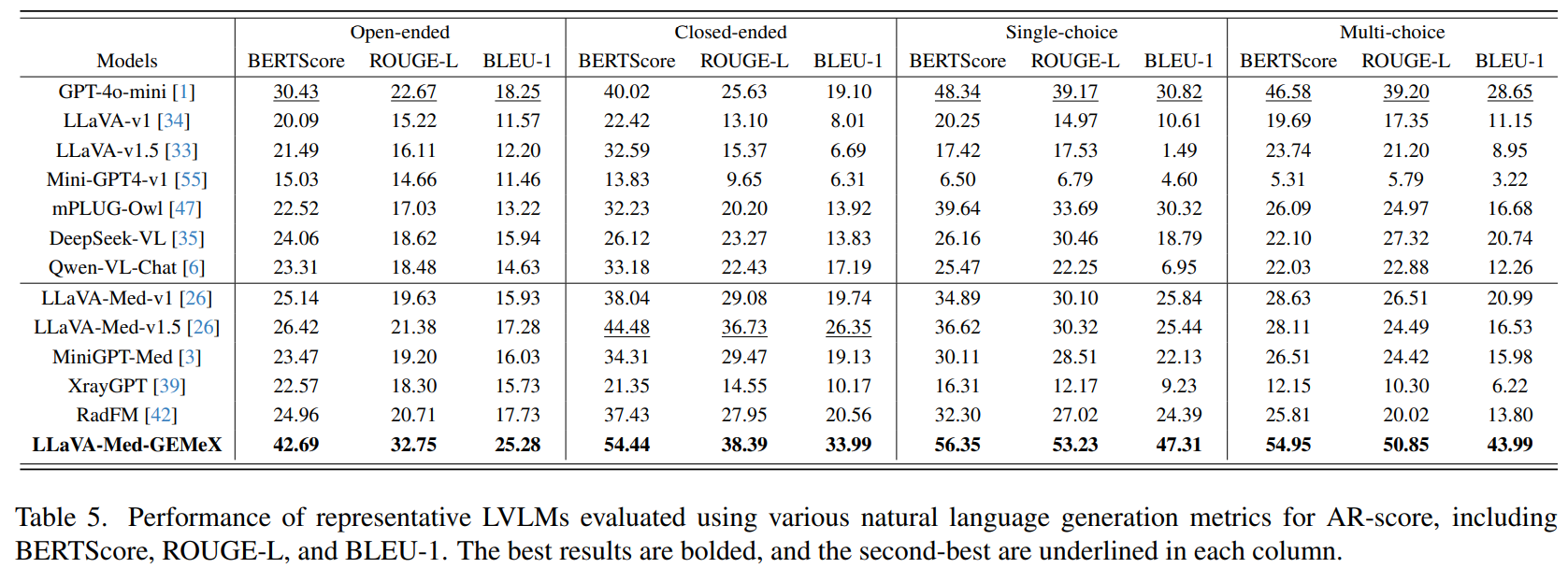
1.3.3.zero-shot performance表现,探究泛化性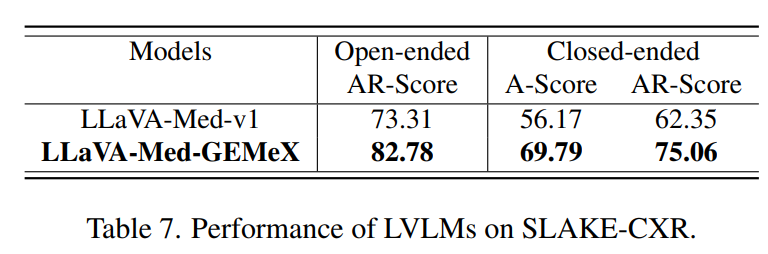
二. GEMeX-ThinkVG: Towards Thinking with Visual Grounding in Medical VQA via Reinforcement Learning
疑问:其实第一篇GEMeX 已经有reasoning的过程了,只是没有把它用语言描述出来,这篇跟上一篇有什么区别和联系?
2.1. 研究背景
目前,大多数方法生成答案时,都不会揭示其背后的推理过程或具体图像区域,而正是这些区域为模型决策提供了依据。这种缺乏透明度的情况削弱用户的信任,并阻碍这类系统进入临床工作流程
GEMeX-ThinkVG证明,仅仅依靠SFT不足以充分释放 large vision language models(LVLMs)能力。采用RL框架做post-training,引入可验证的奖励机制,以激励推理轨迹和相关视觉文本线索一致性。
跟上一篇的区别!!
其实跟上一篇几乎相同,但补充了丰富实验,加了RL


左边是GEMeX, 双肺(过度充气)、右侧肋膈角(变钝)、双侧下肺(肺不张)和心脏轮廓(增大)出现异常。
右边是我们的ThinkVG:为了回答这个问题,我将首先检查胸部X光片(CXR)上的双肺区域([64, 42, 257, 262]),以查看是否有任何异常。局灶性实变(A)会表现为密集的斑片状不透明影,但此处的肺部没有这样的发现。胸腔积液(C)会表现为肋膈角变钝或半月征,但这些迹象并不存在。气胸(D)会显示出脏层胸膜线和周围透亮度增加,但没有看到这样的线条。由于肺部均匀充气,没有不透明影或胸膜不规则,正确答案是B:清晰。纵隔([122, 73, 218, 229])和心脏区域([122, 151, 218, 229])进一步证实了正常发现,支持这一结论。
GEMeX数据集是VQA triplets成对数据,文本推理和视觉区域相关。
** 但是文本和视觉提示是独立的,缺乏连贯性!!(唉,看看人家,这motivation写的。换我,我就只会说把GEMeX的结果用大模型从一些词组换成段落)。
** 进一步,文本推理只是对答案的解释,而不是基于图像提供解决问题的指导(有啥区别?,不都是因为膨大了,或弥散了,所以有什么症状)这就是GEMeX-ThinkVG。
总结来说,这篇文章的贡献主要三部分:
- 提出数据集,这个数据集提供逐步推理的区域语义标注的信息
- 在数据集上进行SFT,进一步利用RL采用一种新颖的可验证奖励机制来激励推理能力,从而能生成更准确的思考路径和最终答案
- 通过全面实验,证明了所提供了数据集和奖励机制的有效性,这些机制只用1/8回能达到利用全部数据集相同的性能水平
2.2. 研究方法
2.2.1 数据集构建过程
数据集构建过程:
1.DeepSeek-R1根据VQA写出推理过程(table1是prompt)。但DS-R1是text模型,所以利用GEMeX生成病变区域。
2.stage2-DS-R1确认生成答案,stage3-利用三个额外的agent作为reviewer,stage4-后处理,去除明显错误,包括区域错误或引用错误
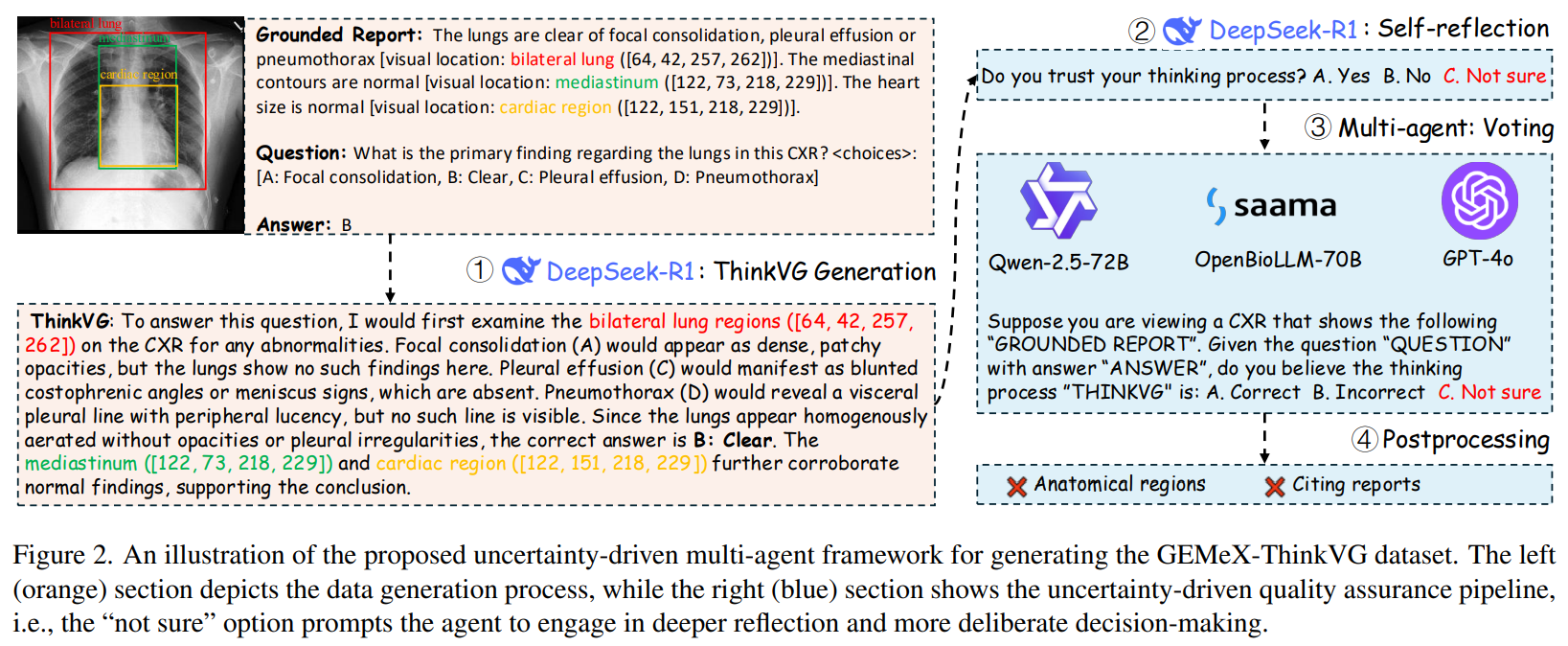
2.2.2 训练过程
训练过程
SFT和RFT过程(Fig3). SFT 需要 < t h i n k > . . . < t h i n k > < r e s p o n s e > < a n s w e r > . . . < a n s w e r > < l o c a t i o n > . . . < l o c a t i o n > < r e s p o n s e > <think>...<think> <response> <answer>...<answer><location>...<location><response> <think>...<think><response><answer>...<answer><location>...<location><response>


Fig3左边是 SFT和RFT阶段,右边是GRPO步骤
虽然SFT已经能显著提高性能,但它:
1.因为任务的复杂性,模型有时产生错误的思维过程在SFT之后,比如错误分析图像,这可能因为SFT更有助于LVLMs记忆,而不是真正理解(RL就真正理解了??? 什么鬼)
2.推导过程不正确的定位框,可能会导致性能下载
RL的奖励函数
1.semantic reward:语义奖励. 对于choice-based和closed-ended问题来说,奖励设计是准确率奖励,而对于open-ended问题是缺乏固定答案的。不同于传统的BLEU作为奖励,本文将GT回答和模型产生的回答都输入OpenBioLLM-70B,能提供两个正确率分数。如果这两个分数接近,奖励是1,否则是0
2.grounding reward: 定位奖励. mIoU


左边是产生Think VG数据,右边是semantics reward
对右边的翻译
“{
“role”: “user”,
“content”: “我们希望您对两个AI助手在回答上述用户问题时的表现提供反馈。供您参考,图像中的视觉内容通过描述同一图像的标题来表示。请根据答案和理由(如果有)评估它们回答的准确性(最重要)和相关性。每个助手将获得一个1到10的总分,分数越高表示整体表现越好。请以JSON格式输出两个分数和您的理由 { assistant1: score, assistant2: score, reason:your_reason }。”
}”
2.2.3 训练数据集和模型结果
GEMeX-Full包含1.59M VQA问题对
GEMeX-ThinkVG-200K
GEMeX-test数据包含 300图和3960问题(1,144 open-ended questions, 543 closed-ended questions, 1,300 single-choice questions, and 973 multiple-choice questions).
详细的训练过程: Qwen2.5-VL-7B-Instruct对基础
在SFT/RFT阶段,微调 visual projection layers and the LLM components预测ThinkVG路径
| SFT | - | RFT | - |
|---|---|---|---|
| 2 epoch | 8 NVIDIA H100 GPUs | 1 epoch | NVIDIA H100 GPUs |
| batch size 256 | AdamW | batch size 128 | AdamW |
| warmup 0.05 epochs with a linear learning rate from 3e-7 to 1e-4 by cosine schedule | learning rate 2e-6 | ||
| generate 8 outputs | set β and ϵ to 1e − 3 and 0.2 |
2.3. 实验结果
2.3.1 主要实验结果
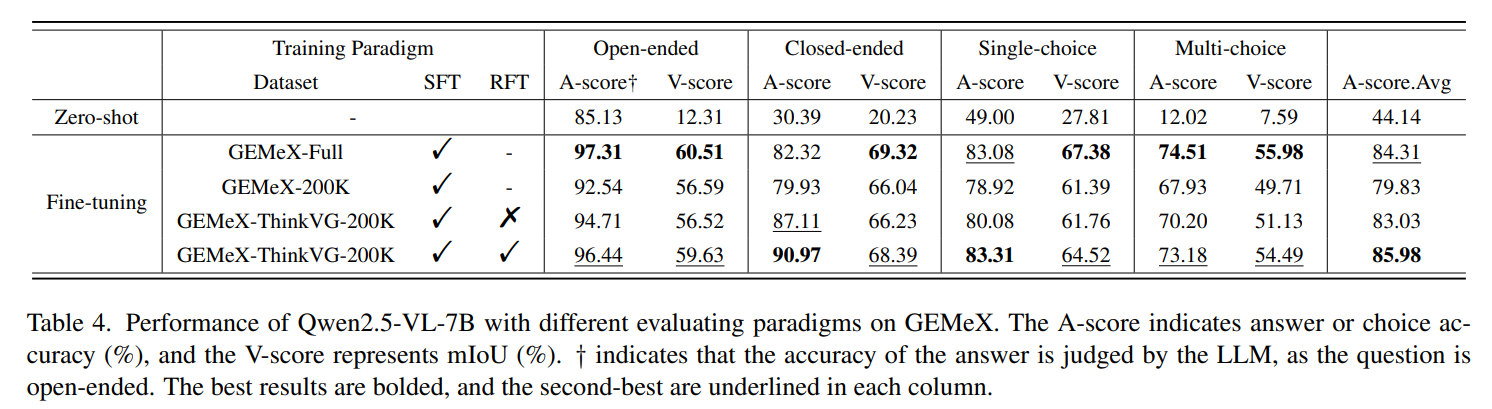
SFT数据越多,效果越好,RL有效
2.3.2 抗干扰能力评估
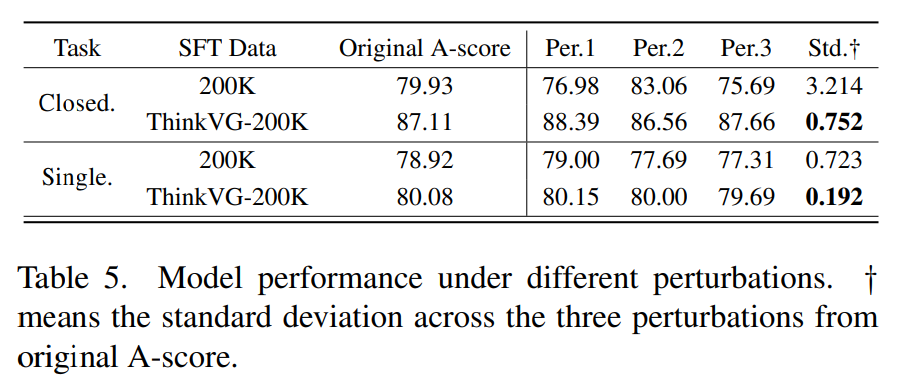
“Is the heart size abnormal in this CXR?” 会随机 “is"被"isn’ t"替代, 或由"abnormal"代替"normal”,每个问题50%几率被修改成这两种模式的一个
所有的三轮测试都在SFT之后,表明ThinkVG对模型微调后,其抗干扰能力显著提高
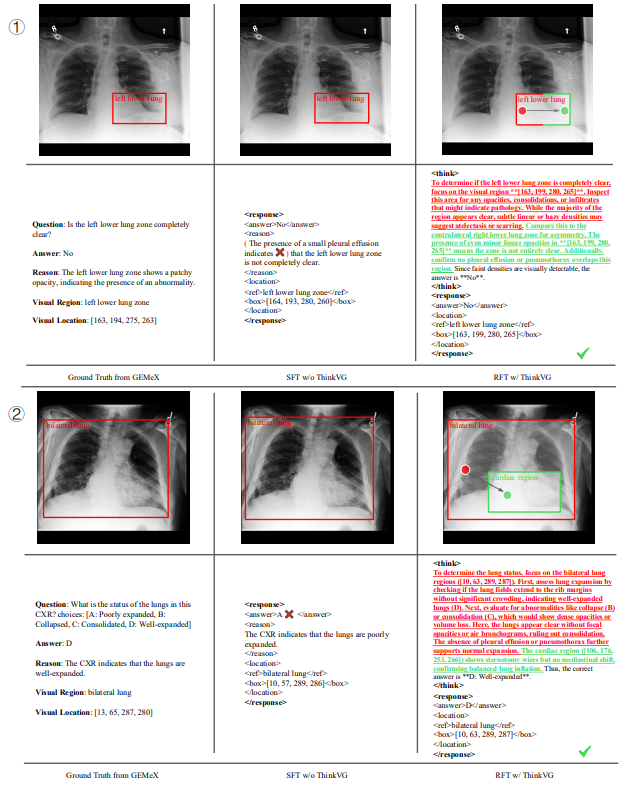

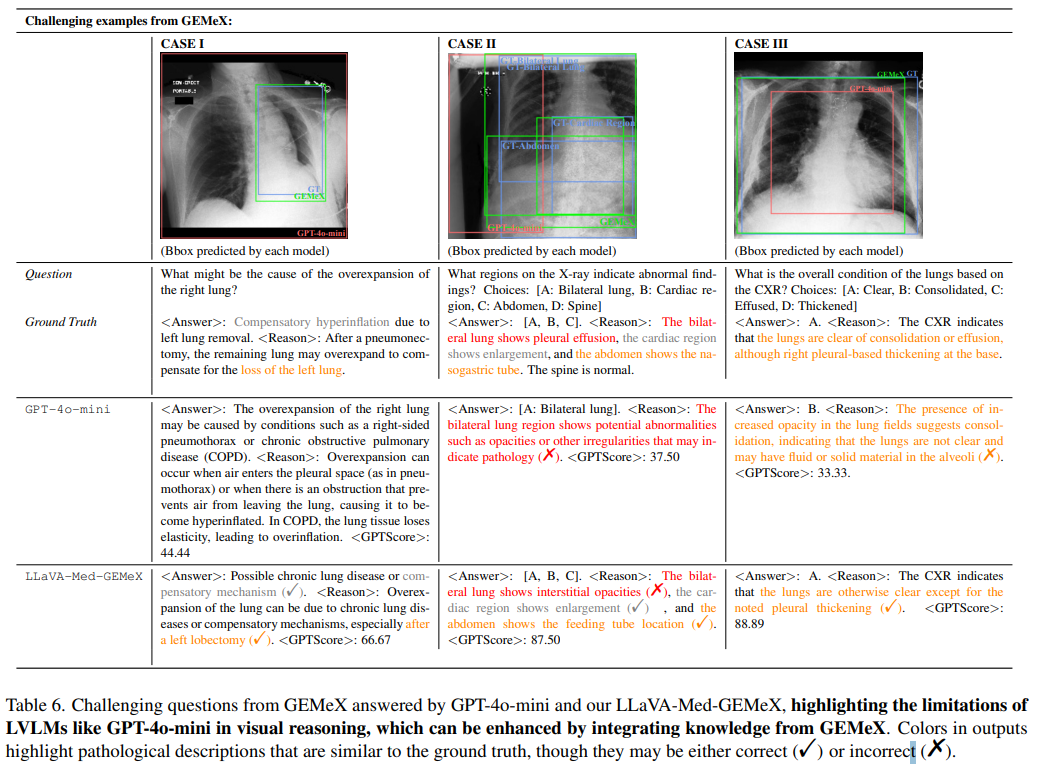
由使用和未使用ThinkVG训练的模型回答的来自GEMeX的具有挑战性的示例。(✓)或(✗)在输出中突出显示正确或错误的原因或答案。彩色单词表示带有视觉定位过程的思考。
Reviewer问题
我的问题:
- RL 一点的提升,到底RL从原理上来说是真的有效吗? 我都不知道RL是一种训练策略,还是一种新优化目标?SFT是记忆,那RL就能理解了?
- CoT真的有效吗?CoT是把大问题分解 成小问题,但这么长的思维链 能提升的任务类型也很有限。
看paper的提纲
提问(解决了什么问题?)
理解(怎么解决的?)
验证(结果怎么样?)
反思
1.为什么能解决?为什么有效?为什么某个方法在这个任务上表现这么好?
2.它和传统方法相比,核心改进在哪?局限性是什么?
3.这个方法是否可以迁移到我的问题上?```bash

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)