FastGPT实战:从0搭建AI知识库与MCP AI Agent系统
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,将智能对话与可视化编排完美结合,让 AI 应用开发变得简单自然

一、安装
-
• FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,将智能对话与可视化编排完美结合,让 AI 应用开发变得简单自然
-
• 开源开放,功能强大丰富,支持MCP、多渠道模型接入,且使用简单灵活,易于扩展和集成
-
• 功能特点在于全能知识库、可视化工作流编排、数据智能解析 、强大的 API 集成
-
• 开源地址参考:https://github.com/labring/FastGPT
-
• 官方文档参考:https://doc.tryfastgpt.ai/docs/
- • FastGPT知识库核心流程图参考下图
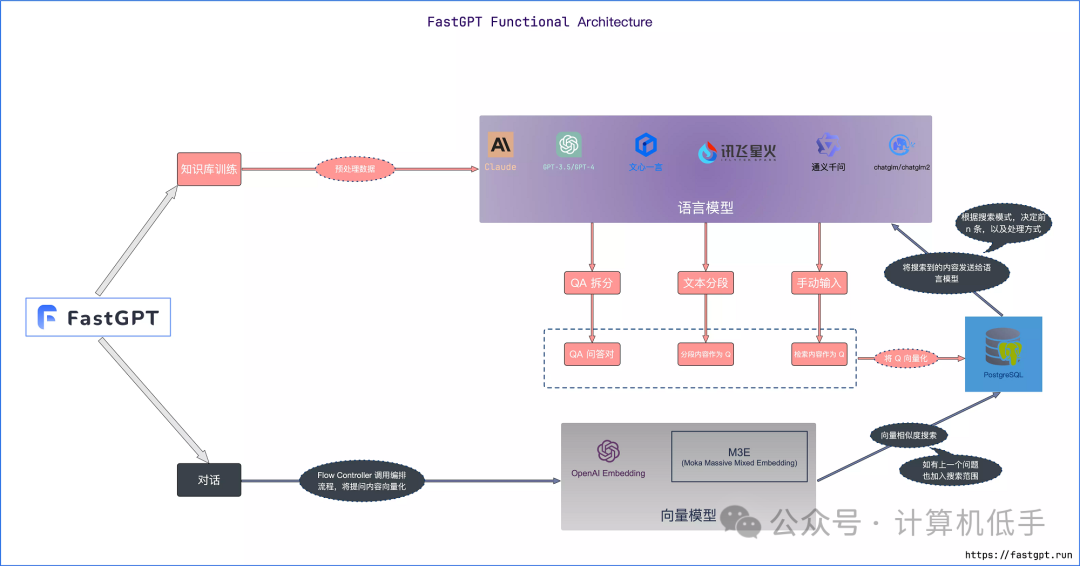
二、安装
1. 参考官方的部署结构图,如下:

2. 使用docker-compose快速启动项目(建议)
-
• 服务器要求:2核4G,当然越高越好
-
• 提前安装准备好Docker、docker-compose环境(自行安装,这里不再赘述)
-
• 官方提供多种不同向量数据库的启动方案,包括:pgvector版本、oceanbase版本、milvus 版本、zilliz 版本,相关启动配置文件参考:https://github.com/labring/FastGPT/tree/main/deploy/docker
-
• 这里以pgvector版本为例,需要新建两个文件,一个是config.json、一个是docker-compose.yml,配置内容如下
config.json,源文件地址:https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
// 已使用 json5 进行解析,会自动去掉注释,无需手动去除
{
"feConfigs": {
"lafEnv": "https://laf.dev", // laf环境。 https://laf.run (杭州阿里云) ,或者私有化的laf环境。如果使用 Laf openapi 功能,需要最新版的 laf 。
"mcpServerProxyEndpoint": "" // mcp server 代理地址,例如: http://localhost:3005
},
"systemEnv": {
"vectorMaxProcess": 10, // 向量处理线程数量
"qaMaxProcess": 10, // 问答拆分线程数量
"vlmMaxProcess": 10, // 图片理解模型最大处理进程
"tokenWorkers": 30, // Token 计算线程保持数,会持续占用内存,不能设置太大。
"hnswEfSearch": 100, // 向量搜索参数,仅对 PG 和 OB 生效。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
"hnswMaxScanTuples": 100000, // 向量搜索最大扫描数据量,仅对 PG生效。
"customPdfParse": {
"url": "", // 自定义 PDF 解析服务地址
"key": "", // 自定义 PDF 解析服务密钥
"doc2xKey": "", // doc2x 服务密钥
"price": 0 // PDF 解析服务价格
}
}
}docker-compose.yml,源文件地址:https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml
# 数据库的默认账号和密码仅首次运行时设置有效
# 如果修改了账号密码,记得改数据库和项目连接参数,别只改一处~
# 该配置文件只是给快速启动,测试使用。正式使用,记得务必修改账号密码,以及调整合适的知识库参数,共享内存等。
# 如何无法访问 dockerhub 和 git,可以用阿里云(阿里云没有arm包)
version: '3.3'
services:
# db
pg:
image: pgvector/pgvector:0.8.0-pg15 # docker hub
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
container_name: pg
restart: always
# ports: # 生产环境建议不要暴露
# - 5432:5432
networks:
- fastgpt
environment:
# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果
- POSTGRES_USER=username
- POSTGRES_PASSWORD=password
- POSTGRES_DB=postgres
volumes:
- ./pg/data:/var/lib/postgresql/data
healthcheck:
test: ['CMD', 'pg_isready', '-U', 'username', '-d', 'postgres']
interval: 5s
timeout: 5s
retries: 10
mongo:
image: mongo:5.0.18 # dockerhub
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云
# image: mongo:4.4.29 # cpu不支持AVX时候使用
container_name: mongo
restart: always
# ports:
# - 27017:27017
networks:
- fastgpt
command: mongod --keyFile /data/mongodb.key --replSet rs0
environment:
- MONGO_INITDB_ROOT_USERNAME=myusername
- MONGO_INITDB_ROOT_PASSWORD=mypassword
volumes:
- ./mongo/data:/data/db
entrypoint:
- bash
- -c
- |
openssl rand -base64 128 > /data/mongodb.key
chmod 400 /data/mongodb.key
chown 999:999 /data/mongodb.key
echo 'const isInited = rs.status().ok === 1
if(!isInited){
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo:27017" }
]
})
}' > /data/initReplicaSet.js
# 启动MongoDB服务
exec docker-entrypoint.sh "$$@" &
# 等待MongoDB服务启动
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')"; do
echo "Waiting for MongoDB to start..."
sleep 2
done
# 执行初始化副本集的脚本
mongo -u myusername -p mypassword --authenticationDatabase admin /data/initReplicaSet.js
# 等待docker-entrypoint.sh脚本执行的MongoDB服务进程
wait $$!
redis:
image: redis:7.2-alpine
container_name: redis
# ports:
# - 6379:6379
networks:
- fastgpt
restart: always
command: |
redis-server --requirepass mypassword --loglevel warning --maxclients 10000 --appendonly yes --save 60 10 --maxmemory 4gb --maxmemory-policy noeviction
healthcheck:
test: ['CMD', 'redis-cli', '-a', 'mypassword', 'ping']
interval: 10s
timeout: 3s
retries: 3
start_period: 30s
volumes:
- ./redis/data:/data
# fastgpt
sandbox:
container_name: sandbox
image: ghcr.io/labring/fastgpt-sandbox:v4.9.11 # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.9.11 # 阿里云
networks:
- fastgpt
restart: always
fastgpt-mcp-server:
container_name: fastgpt-mcp-server
image: ghcr.io/labring/fastgpt-mcp_server:v4.9.11 # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-mcp_server:v4.9.11 # 阿里云
ports:
- 3005:3000
networks:
- fastgpt
restart: always
environment:
- FASTGPT_ENDPOINT=http://fastgpt:3000
fastgpt:
container_name: fastgpt
image: ghcr.io/labring/fastgpt:v4.9.11 # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.9.11 # 阿里云
ports:
- 3000:3000
networks:
- fastgpt
depends_on:
- mongo
- pg
- sandbox
restart: always
environment:
# 前端外部可访问的地址,用于自动补全文件资源路径。例如 https:fastgpt.cn,不能填 localhost。这个值可以不填,不填则发给模型的图片会是一个相对路径,而不是全路径,模型可能伪造Host。
- FE_DOMAIN=
# root 密码,用户名为: root。如果需要修改 root 密码,直接修改这个环境变量,并重启即可。
- DEFAULT_ROOT_PSW=1234
# AI Proxy 的地址,如果配了该地址,优先使用
- AIPROXY_API_ENDPOINT=http://aiproxy:3000
# AI Proxy 的 Admin Token,与 AI Proxy 中的环境变量 ADMIN_KEY
- AIPROXY_API_TOKEN=aiproxy
# 数据库最大连接数
- DB_MAX_LINK=30
# 登录凭证密钥
- TOKEN_KEY=any
# root的密钥,常用于升级时候的初始化请求
- ROOT_KEY=root_key
# 文件阅读加密
- FILE_TOKEN_KEY=filetoken
# MongoDB 连接参数. 用户名myusername,密码mypassword。
- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin
# pg 连接参数
- PG_URL=postgresql://username:password@pg:5432/postgres
# Redis 连接参数
- REDIS_URL=redis://default:mypassword@redis:6379
# sandbox 地址
- SANDBOX_URL=http://sandbox:3000
# 日志等级: debug, info, warn, error
- LOG_LEVEL=info
- STORE_LOG_LEVEL=warn
# 工作流最大运行次数
- WORKFLOW_MAX_RUN_TIMES=1000
# 批量执行节点,最大输入长度
- WORKFLOW_MAX_LOOP_TIMES=100
# 自定义跨域,不配置时,默认都允许跨域(多个域名通过逗号分割)
- ALLOWED_ORIGINS=
# 是否开启IP限制,默认不开启
- USE_IP_LIMIT=false
# 对话文件过期天数
- CHAT_FILE_EXPIRE_TIME=7
volumes:
- ./config.json:/app/data/config.json
# AI Proxy
aiproxy:
image: ghcr.io/labring/aiproxy:v0.1.7
# image: registry.cn-hangzhou.aliyuncs.com/labring/aiproxy:v0.1.7 # 阿里云
container_name: aiproxy
restart: unless-stopped
depends_on:
aiproxy_pg:
condition: service_healthy
networks:
- fastgpt
environment:
# 对应 fastgpt 里的AIPROXY_API_TOKEN
- ADMIN_KEY=aiproxy
# 错误日志详情保存时间(小时)
- LOG_DETAIL_STORAGE_HOURS=1
# 数据库连接地址
- SQL_DSN=postgres://postgres:aiproxy@aiproxy_pg:5432/aiproxy
# 最大重试次数
- RETRY_TIMES=3
# 不需要计费
- BILLING_ENABLED=false
# 不需要严格检测模型
- DISABLE_MODEL_CONFIG=true
healthcheck:
test: ['CMD', 'curl', '-f', 'http://localhost:3000/api/status']
interval: 5s
timeout: 5s
retries: 10
aiproxy_pg:
image: pgvector/pgvector:0.8.0-pg15 # docker hub
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.8.0-pg15 # 阿里云
restart: unless-stopped
container_name: aiproxy_pg
volumes:
- ./aiproxy_pg:/var/lib/postgresql/data
networks:
- fastgpt
environment:
TZ: Asia/Shanghai
POSTGRES_USER: postgres
POSTGRES_DB: aiproxy
POSTGRES_PASSWORD: aiproxy
healthcheck:
test: ['CMD', 'pg_isready', '-U', 'postgres', '-d', 'aiproxy']
interval: 5s
timeout: 5s
retries: 10
networks:
fastgpt:-
• 在同一个目录下建好上面两个文件后,直接运行命令启动
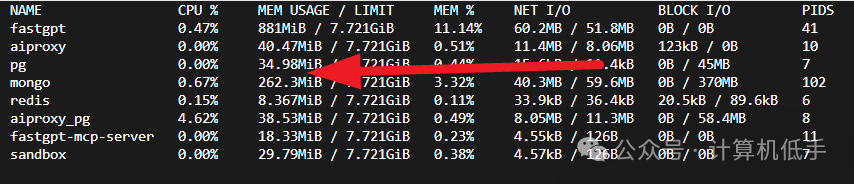
docker-compose up -d确保所有服务正常运行,如下

初始内存占用情况,如下
三、使用示例
1. 登录后台系统,访问:http://127.0.0.1:3000/
- • 默认登录账号密码:root/1234,要修改密码需要编辑docker-compose.yml中的环境变量 DEFAULT_ROOT_PSW 并重启
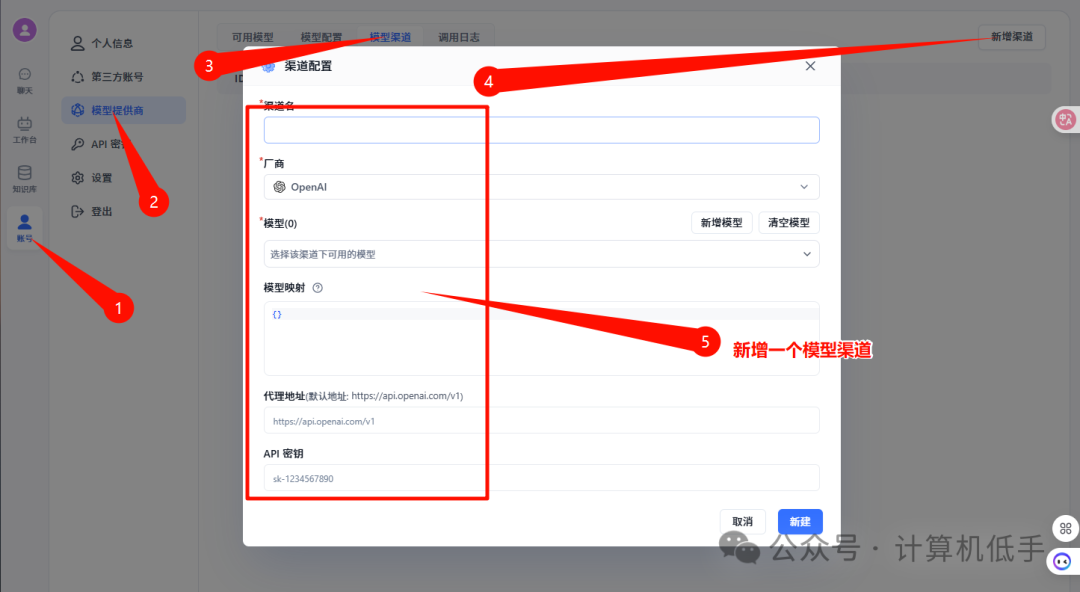
2. 新增一个可用的模型渠道
- • 新增渠道如下,可以接入多种模型厂商渠道,自定义模型和代理地址
- • 最基本需要接入两个模型,一个是语言模型(这里使用Deepseek-v3),一个文本索引模型(这里使用bge-m3)
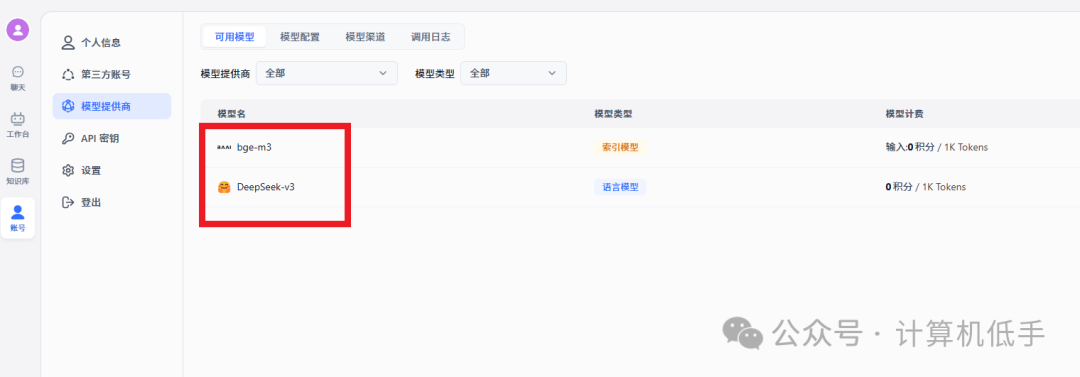
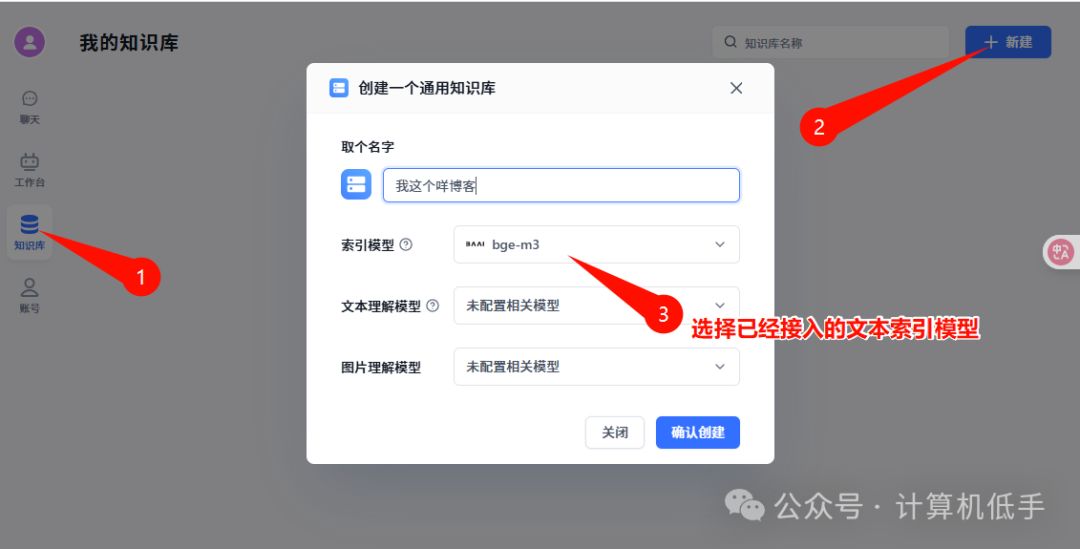
3. 搭建一个知识库并应用起来(以我的博客内容作为知识库为例)
- • 新增知识库,指定使用已经接入的文本索引模型
- • 新增或者导入数据
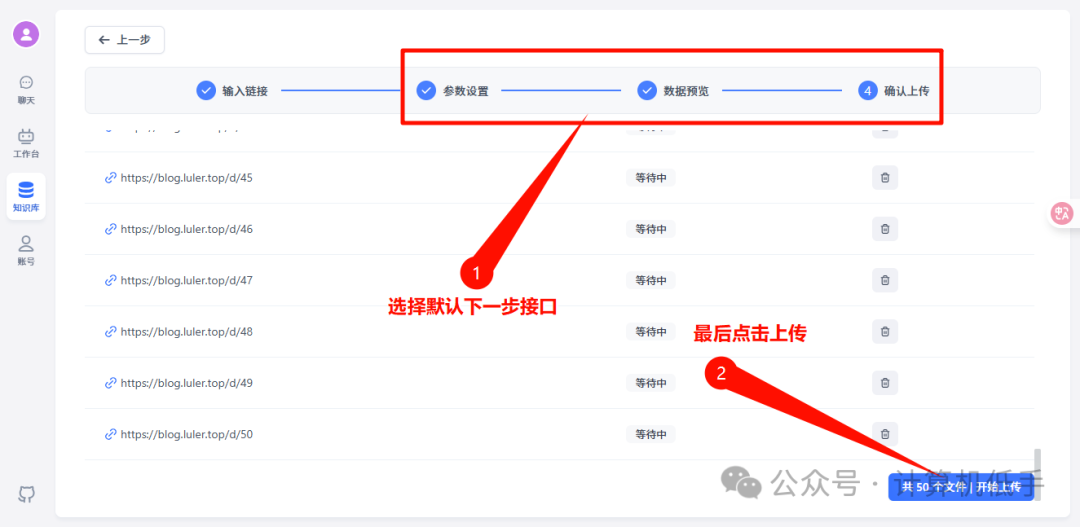
这里选择自动读取网页链接作为数据集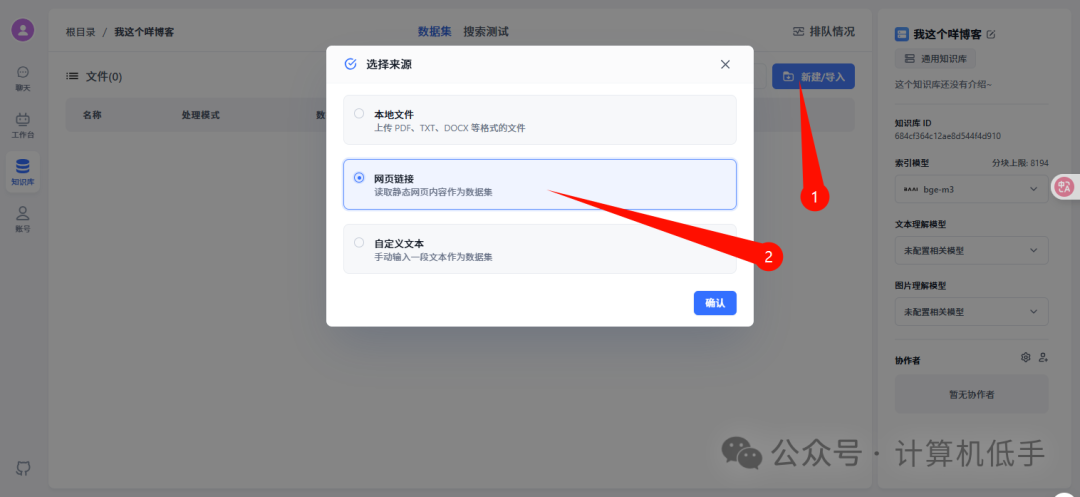
输入所有链接和指定获取网页内容区域即可
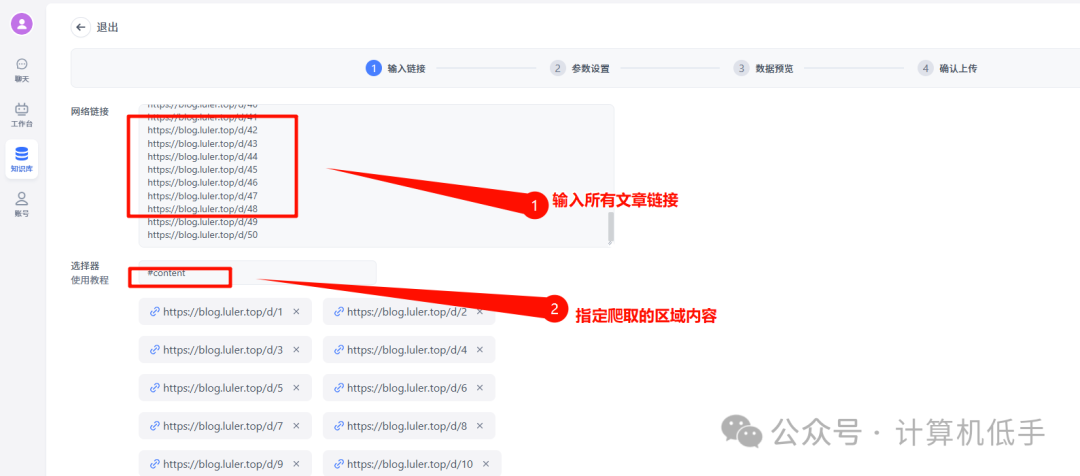
设置完毕,最后点击上传即可,后台会自动爬取所有链接的数据并存入知识库
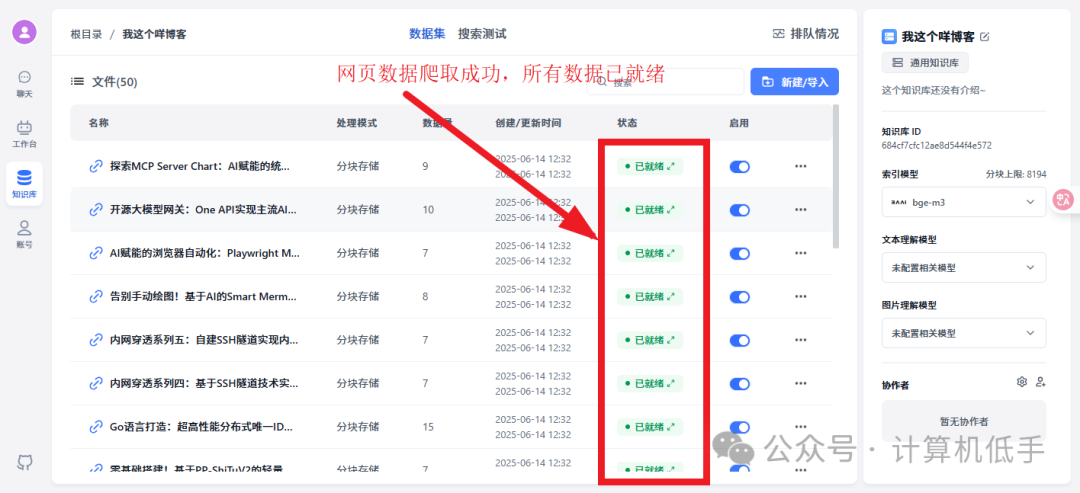
网页数据爬取成功并存入后端向量数据库,知识库就绪
- • 新建一个简易应用,使用已经就绪的知识库
如下,选择”知识库+对话引导“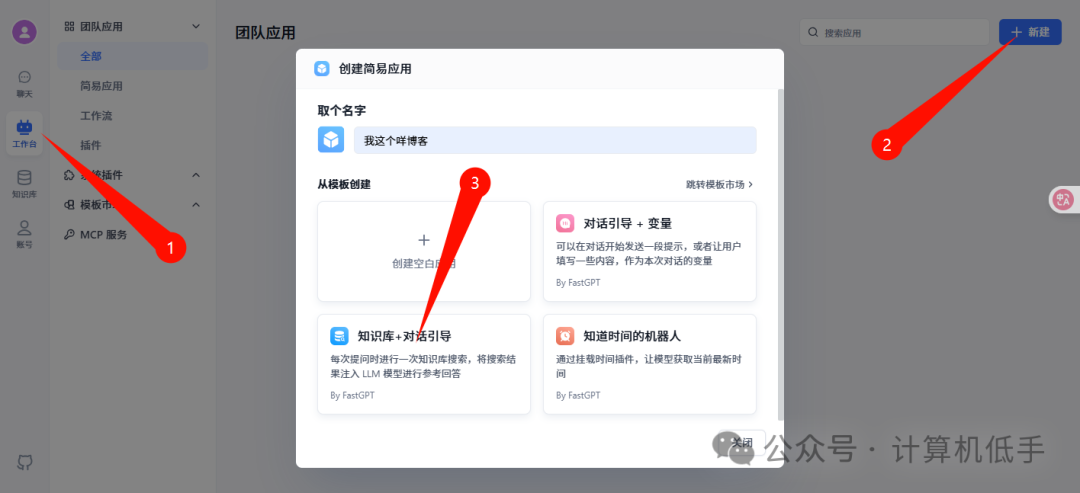
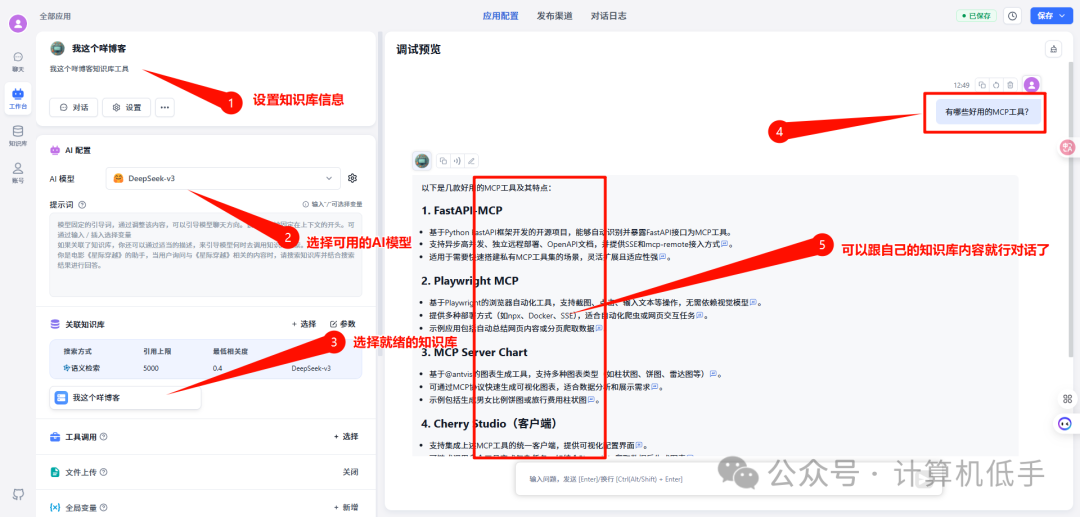
配置选择好知识库、AI模型,就可以跟自己的知识库对话了
- • 设置发布渠道,把自己的知识库应用分享使用或者集成到第三方
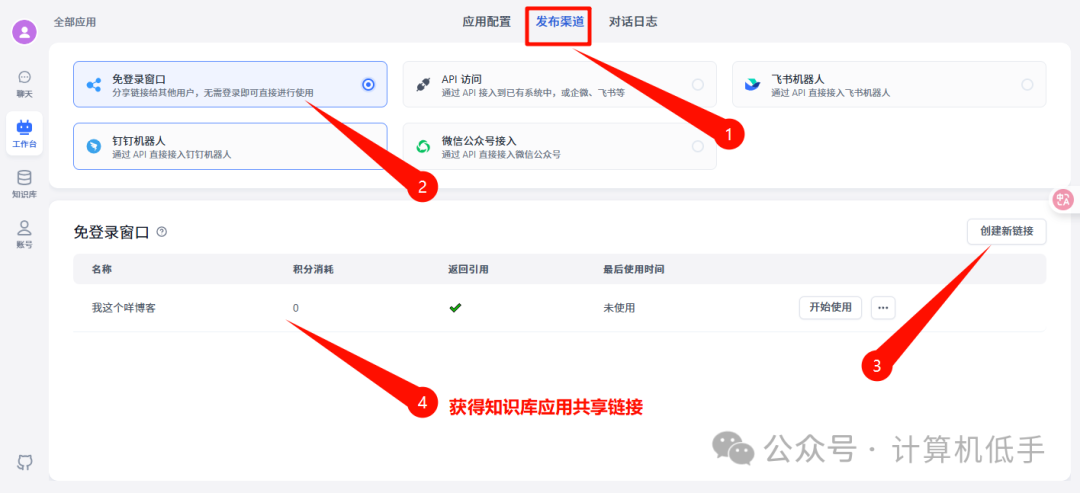
- • 嵌入自己的网站,作为智能助手使用,参考网站:https://blog.luler.top/
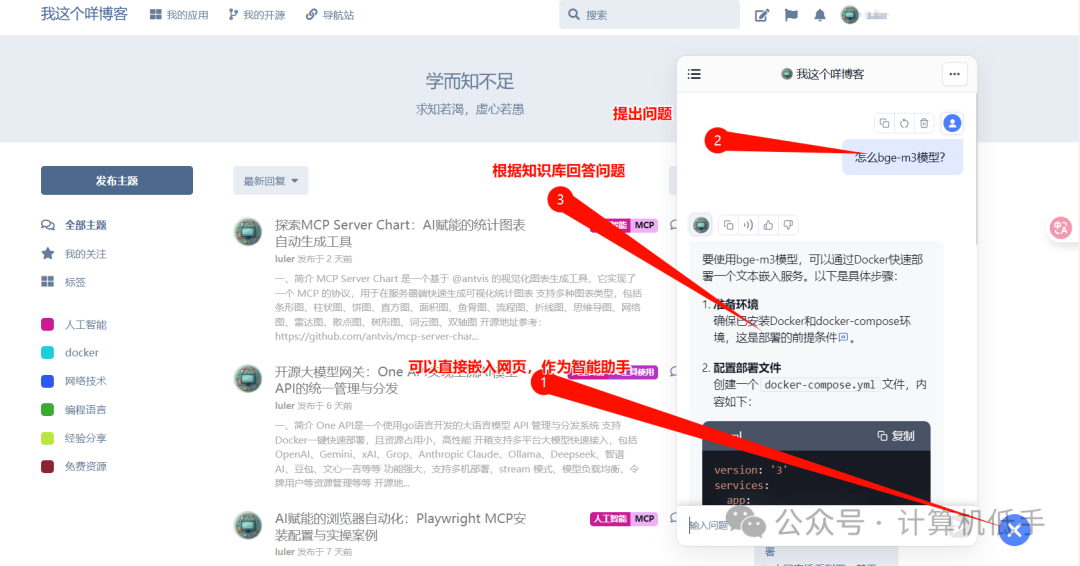
4. 搭建一个支持MCP工具的AI Agent
-
• 以mcp-server-chart工具为例,使用SSE传输模式运行mcp-server-chart工具,参考使用:https://blog.luler.top/d/50
- • 新增一个MCP工具集
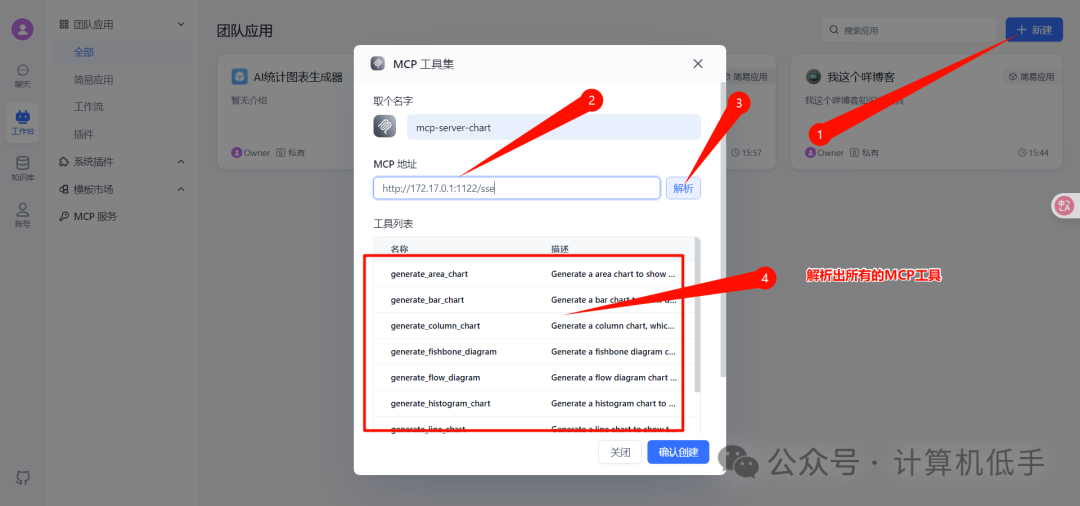
- • 新建一个空白应用,引用这个MCP工具集
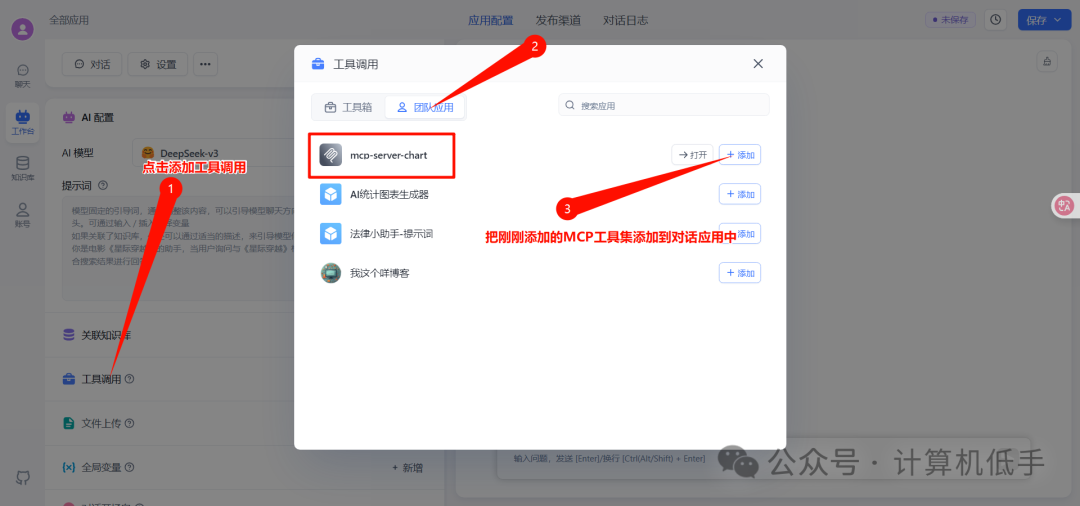
- • 模型要正常使用MCP工具,需要开启工具调用支持
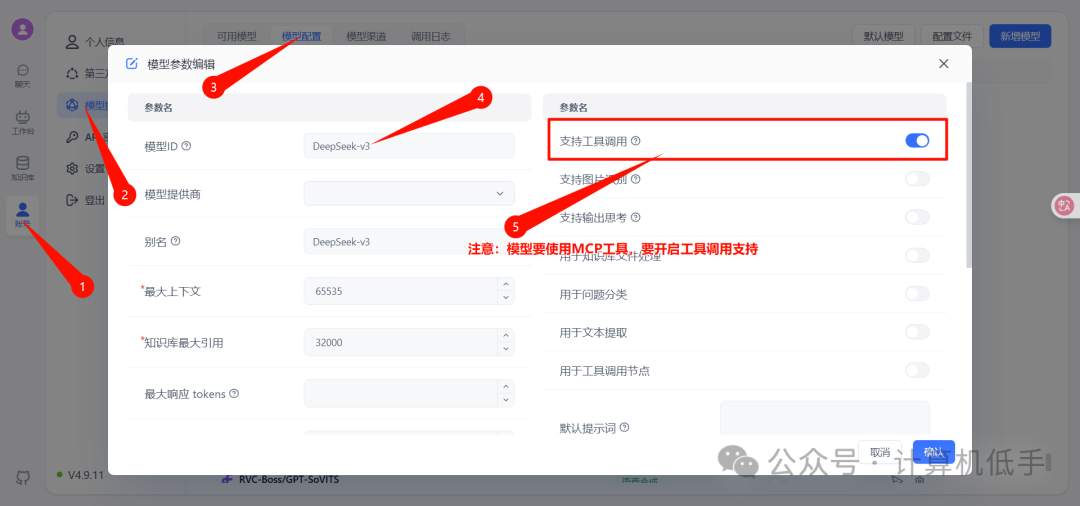
- • 都配置好后,在AI对话中,就可以自动调用相关的MCP的工具
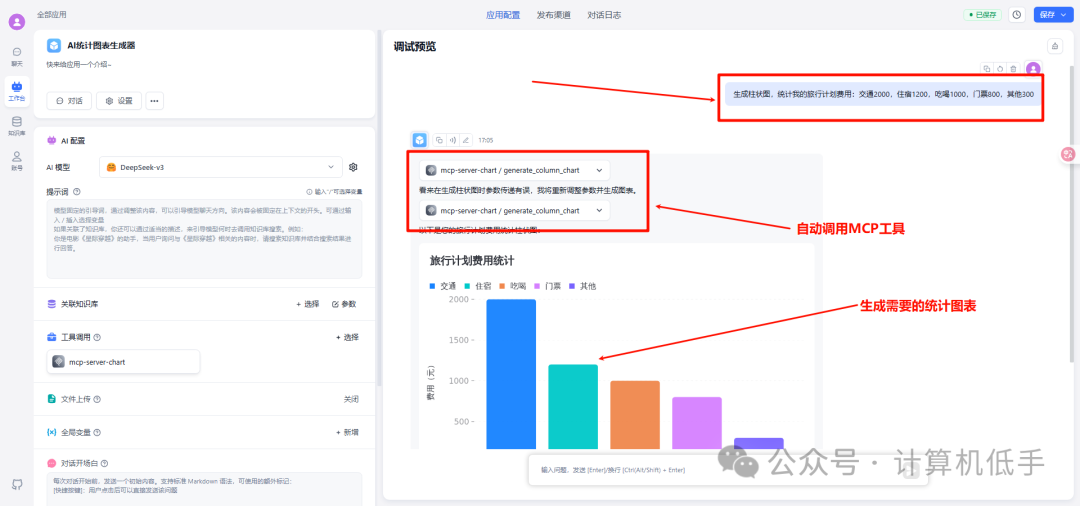
四、总结
-
• fastgpt是个非常好用的AI知识库开源项目,可以轻松搭建自己的在线知识库系统
-
• 新版的fastgpt支持了多模型与渠道管理,也开始支持MCP工具的调用了,有了更多的玩法和应用前景
-
• 感觉部署一个fastgpt应用就能玩转大语言模型的各种应用场景,非常值得部署尝试
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献481条内容
已为社区贡献481条内容

所有评论(0)