【Lora】Comfyui Lora 第一丹,小米 SU7 丹生记全流程
本文主要用来记录第一个Lora的生成吧,这个炼制来来回回折腾了一整天,虽然看起很容易上手,但是在炼制的过程中还是多多少少碰到了一些问题的,然后lora的质量后续也需要进一步的提升,具体的方法的话需要进一步去探索,应该算是进阶训练了,后续如果进阶部分有结果也会记录分享,感兴趣的伙伴可以关注下更新哈哈哈。还有就是初步体验下来Lora的使用场景还是蛮多的,比如IP形象设计啥的,具体的内容大家可以多多找应
先看看效果 ;这些都是根据 lora 生成出来的图片,相似度其实已经在 90 % 以上了,目前是基于 SD1.5 模型进行炼制的,如果基于SDXL或者FLUX效果应该可以更好,当然现在也是初步接触,记录下本次炼制的过程吧。

硬件配置
GPU:N卡,4060ti 16G,建议8G以上,数据处理
内存:32G,建议至少16G
硬盘:推荐固态,速度会稍微快一些,成本又有限也可以使用机械硬盘,数据传输
炼丹工具
kohya脚本,更偏向于熟练使用者或者专业人员;
秋叶大佬整合包;适合初学者,今天也是重点记录基于此进行Lora训练的过程
项目地址 https://github.com/Akegarasu/lora-scripts
该项目是将kohya核心脚本+环境配置+汉化+标签编辑器+训练监控进行整合在一起了,方便炼丹人员使用。
炼丹步骤
确定Lora类型
确认你所需要炼制的Lora类型;一般常见的Lora类型分为以下几种
-
具象概念的Lora:具体人物或者物体Lora,某个卡通形象的Lora或者某个具体物体的Lora(评判条件:生成的结果要具有一致性)
-
类型概念Lora:某个类别的物体, 椅子家具类(评判条件:生成的结果不能太过相似,需要具有泛化性)
-
风格类Lora:某种风格,比如 水墨风,吉卜力风格
-
功能性Lora:比如怎加图像细节Lora,加速图像生成Lora等
选择底模
底模也就是我们炼制Lora需要的基础模型;可以选择和需要训练的对象类似的模型,汽车选择汽车类型的底模;
目前SD生态中使用的比较多的一般为 SD1.5, SDXL , FLUX
还有一类为Novel,这个模型是基于大量的二次元图片进行微调后再融合其他二次元风格的模型而来,最常用来作为二次元Lora训练的底模
在这三大类中又分为各种方式生成的模型:
-
训练模型(Trained):该类又分为预训练模型和微调模型
-
-
预训练模型:个人电脑难以训练;基于上亿数据集进行训练而来的模型
-
微调模型:基于预训练模型微调而成的模型,常用的方法为Dreambooth
-
-
融合模型(Merge):该类模型就是将两个或者多个训练模型进行 merge (在SD和Comfyui中均有相应的方法) 而成的,融合了多个模型的特征
数据准备
确定好炼制Lora的类型后,我们基本就确定了我们需要炼制的Lora是什么,比如我们这里需要训练一个小米SU7的Lora,那么我们就要基于此目的进行数据收集
数据收集一般分为一下步骤
-
主题图片收集: 一般物体或者任务炼制20-30张左右,风格30-40张左右
-
-
好的数据集标准
A. 统一的图片尺寸;如果不处理,会自动压缩至对应分辨率 512512 or 512768,会导致某些图片压缩后主物体失真,影响质量
B. 主体明确,占图片的70%以上
C. 多样性,不同角度,环境的图片
D. 剔除低质量模糊的图片
-
-
数据标注:标注就是对收集的图片进行描述,将重要的单词(tag)进行标注成.txt文件,方便模型进行学习
-
-
确定图片尺寸:一般SD1.5(512512,512768,768512);SDXL(10241024,7681024,1024768),对于Flux则两种尺寸都可以建议使用512尺寸;
-
初步打标:一般借助提示词反推工具快速完成
-
添加关键词:极为Lora的触发词,此类词语一般自定义,不要用常规的词语尽可能生僻且模型无法识别
-
标注修复:对每张图片进行标注校准,去掉初步打标中不准确的词语,提升模型的学习质量,有助于提升Lora质量;删除标签:误标或者模型需要学习的特征,增加标签:提升模型的可控制性
-
关于标注:
标注的内容就是模型学习的变量,没有标注的内容就是模型特有的内容;
比如我们需要控制汽车灯的颜色,那么我们就应该在标注中体现出来,比如某张图片的尾灯是红色的;
要控制汽车的视角,也可以在标注中添加视角相关的词语标注;
这样模型就能识别红色尾灯不是该物体的特有内容,而是可以根据提示词变化的,方便我们使用提示词改变尾灯颜色。
标注方法

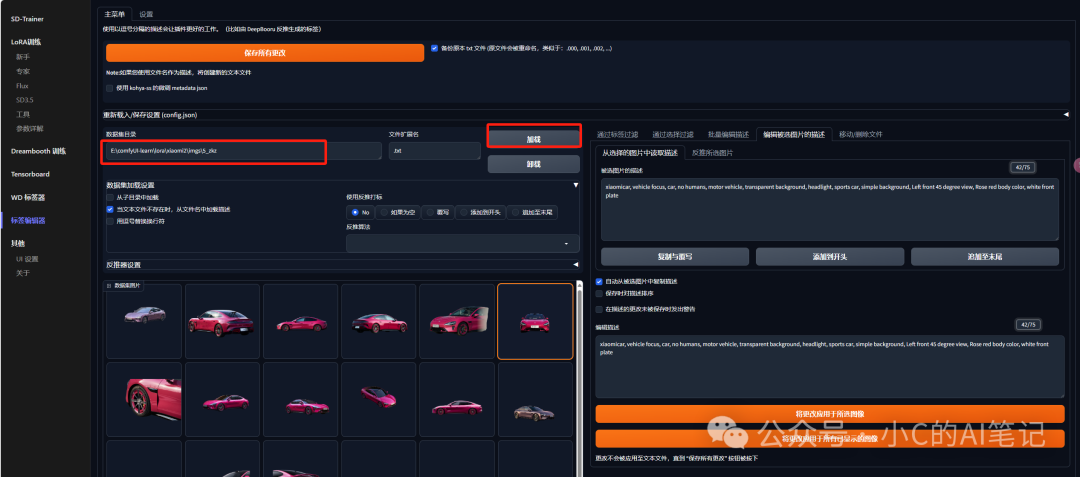
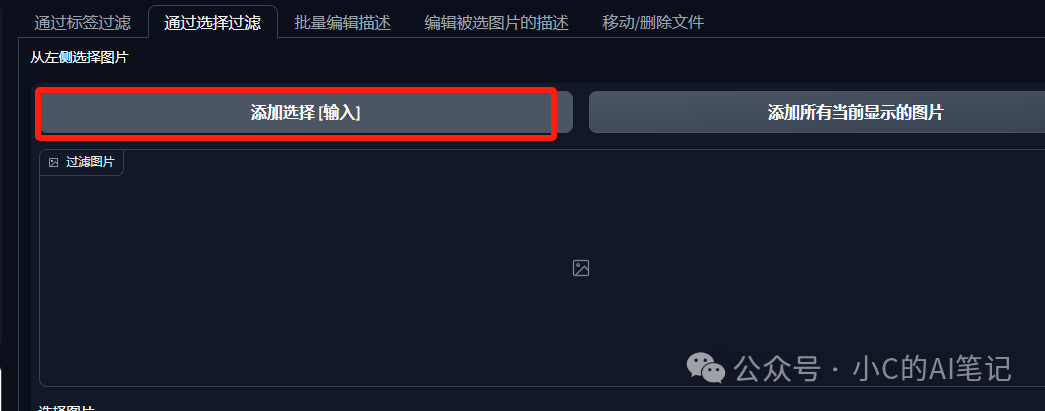
进入lora训练器,选择 WD 标签器,分别填入 收集的图片路径,需要添加的触发词(xiaomicar 该词语模型是不是别的,也就是无意义的)点击右下角的启动即可,完成后会在目录下多出现x.txt 文件,且每个触发文件都以触发词 xiaomicar 开头

标注编辑可以在此界面操作;填入刚才打标的目录地址,点击加载即可;
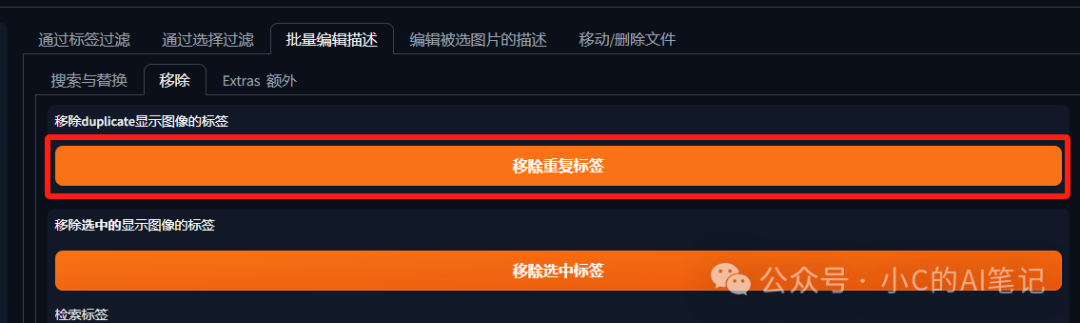
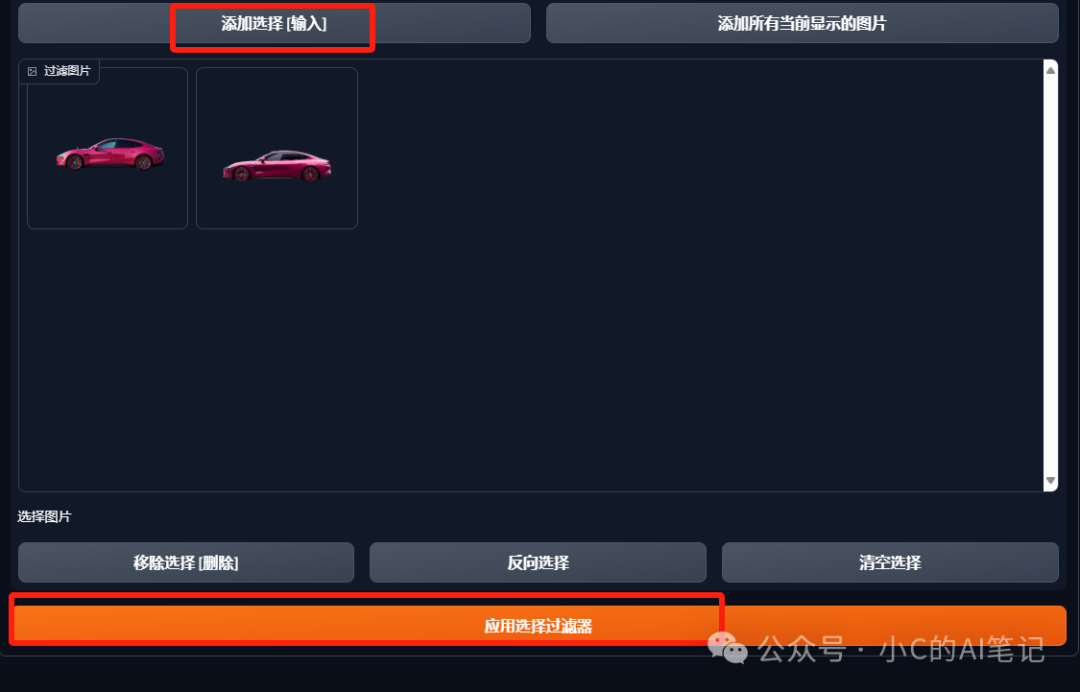
- 移除重复标签
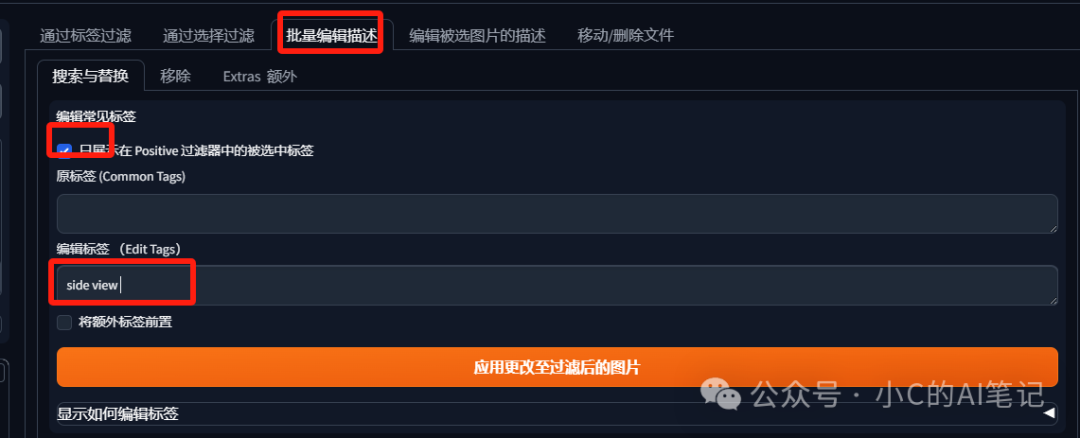
**2. 新增标签;**Lora 控制汽车角度,在标签中添加角度相关的标签
3. 单张编辑
点击复制与覆写,选中自动从被选中图片中复制描述即可在文本框中编辑单张图片的标注;完成后点击 将更改应用于所选图像即可
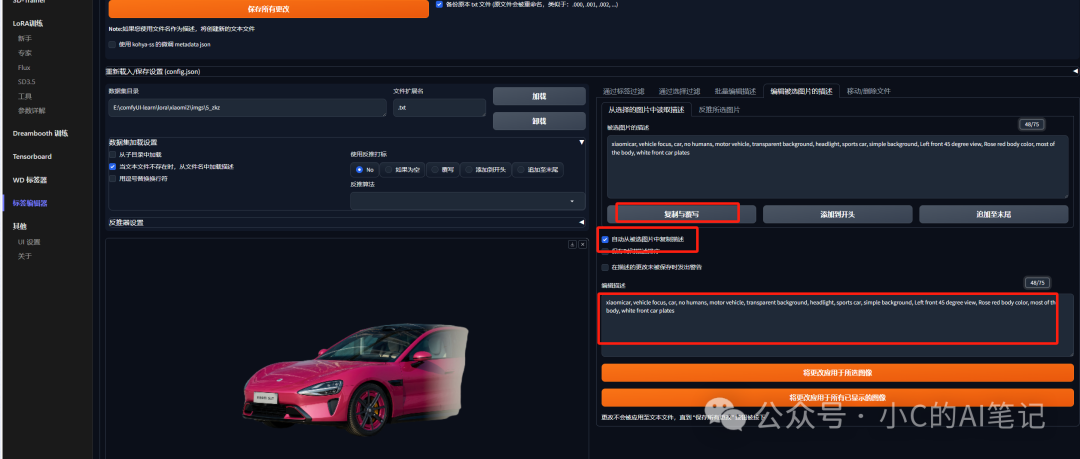
主要作用:
- 整体删标:移除重复标签
- 批量增标:为需要控制的元素添加标签
- 单张编辑:逐个编辑单张图片.
开始炼丹
完成上述准备后即可开始进行Lora炼制
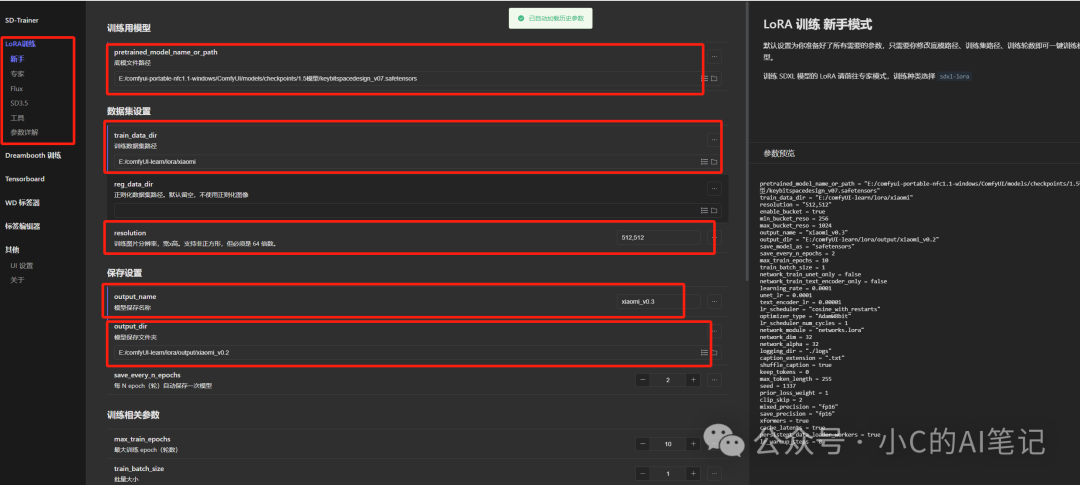
如同所示:第一次炼丹首先选择新手模式进行开始
主要需要填入的内容为:
- 底模路径
- 打标的数据集路径
- 图片分辨率选择
- 输出的Lora的名称
- 输出的Lora保持的目录
填写完后点击右下角的开始训练即可;后面就是等待Lora炼制完成了。
其他参数了解:
-
Epoch 参数:训练的轮次
-
重复次数:每张图片重复训练的次数,完成一轮后(epoch)会打乱顺序进行下一轮训练
-
BatchSize:每次训练的图片数;一般为2的n次方,越大资源消耗越多,越难找到合适的临界点,速度较快,缺少泛化性

\4. 学习率:代表lora学习的步长,一般设置为 0.00008 以下即可

\5. 优化器:辅助lora训练,好的优化器能提高lora训练的质量;一般使用 adamw

最终的训练步骤:
总步数 = (图片数epcho重复次数)/ batchsize

本例中:
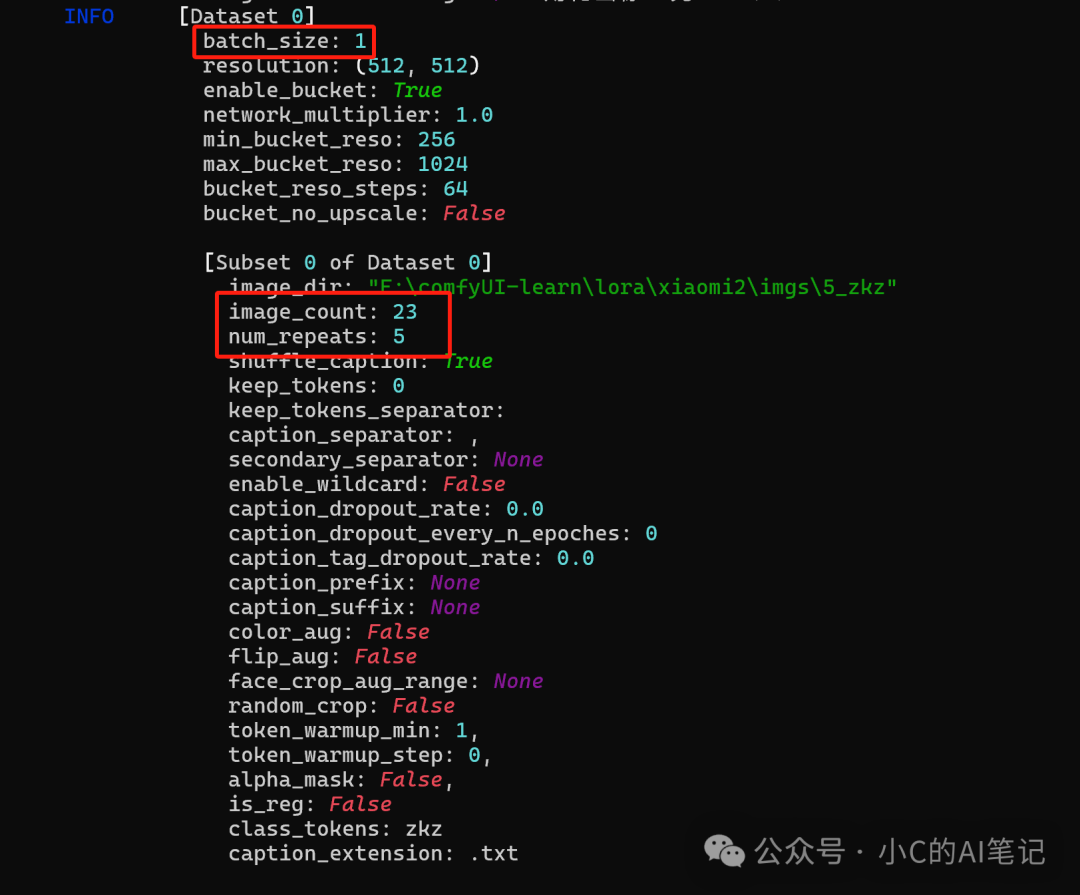
总步数 = (23105)/1 = 1150 步
训练完成后在输出文件夹中可以找到训练的结果文件也就是我们的lora 文件
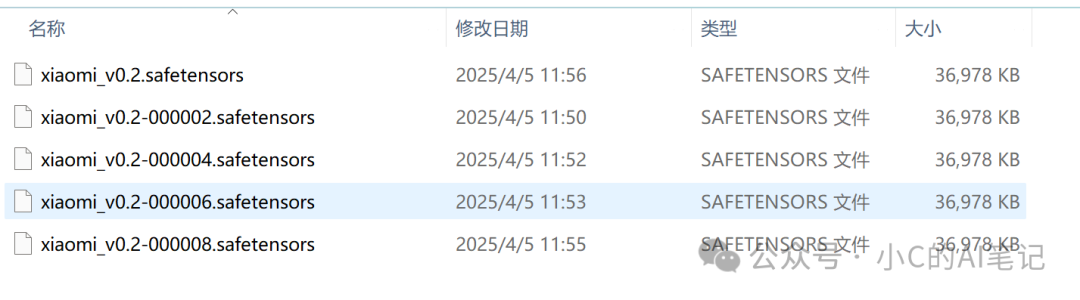
为什么有5个;在配置中有配置 没N轮保存一次模型
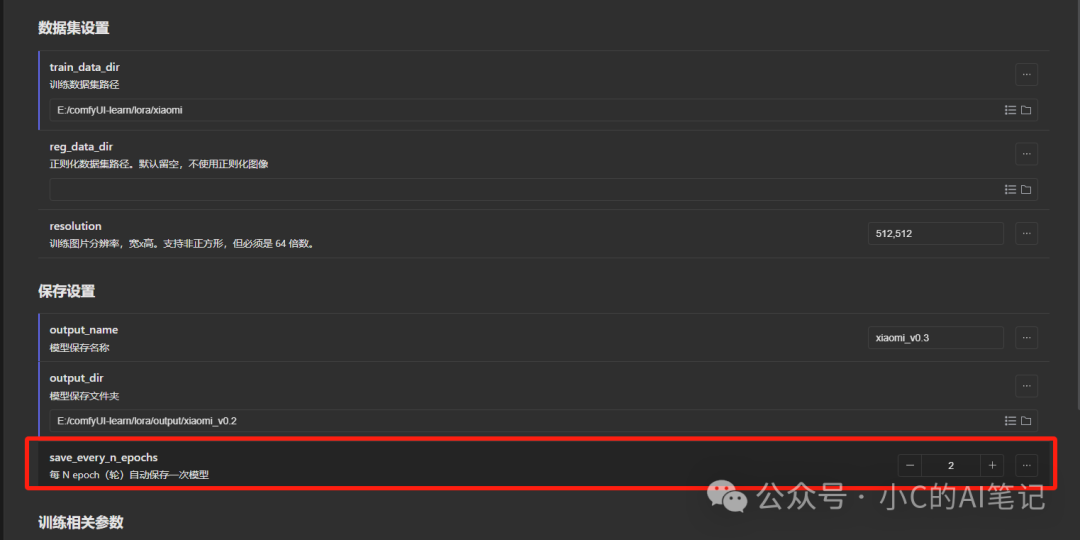
这里设置的为2,而我们的训练轮次为10;所以 10/2=5个
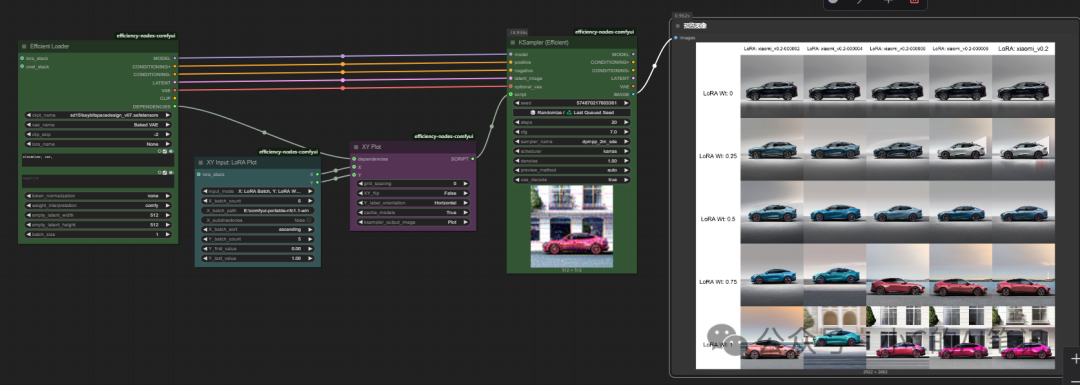
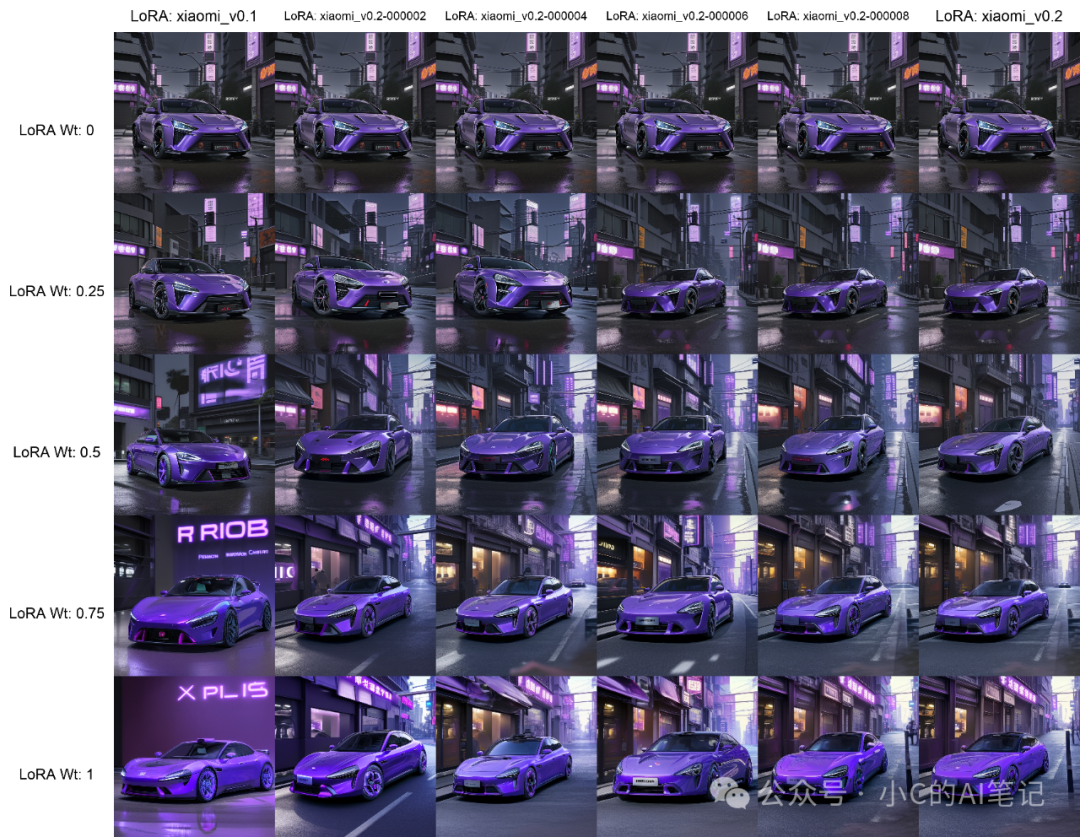
Lora 测试
lora训练完成后我们需对lora进行测试,看是否符合我们的预期,如果发现结果不满意则需要调整参数进行重新训练;
测试方式一般使用XY图进行图像生成对比
工作流和结果如下所示,我们需要在XY图中找到和我们的目标物体最象的 lora文件的权重大小,即为我们的最终产物;
最终就可以基于我们的Lora,结合模型提示词生成我们开头的效果,帮我们完成物体或者人物IP的建设及扩展。

总结
本文主要用来记录第一个Lora的生成吧,这个炼制来来回回折腾了一整天,虽然看起很容易上手,但是在炼制的过程中还是多多少少碰到了一些问题的,然后lora的质量后续也需要进一步的提升,具体的方法的话需要进一步去探索,应该算是进阶训练了,后续如果进阶部分有结果也会记录分享,感兴趣的伙伴可以关注下更新哈哈哈。还有就是初步体验下来Lora的使用场景还是蛮多的,比如IP形象设计啥的,具体的内容大家可以多多找应用场景。
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 30
30 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)