NV GT750M部署Deepseek模型
ollama运行在低版本cuda硬件 NV 750M notebook显卡。
手头刚好有台旧笔记本安装的win10 8GB + 4GB 750m独显, 过年无事刚好deepseek火爆, 用ollama部署1.5b模型玩玩。结果发现只能用CPU运行,于是开始折腾,势要挪到GPU里。
查了一下750M只能到cuda v10.1版本(CUDA Toolkit 10.1 Original Archive | NVIDIA Developer),于是安装了一系列软件:
1 Vstudio2022: win10SDK + 2022编译器, 2017编译器(cuda v10.1需要)
2 构建环境: mingw64 (go cgo链接需要)
3 ollama 0.5.7版本源文件
4 cuda toolkit 10.1
开始使用2017版本编译器,删掉了代码中低版本nvcc不支持的特性,结果死活编译不过去,卡在一个模板定义上, 这个模板定义只2022编译器支持。直接使用2022编译器,结果一堆头文件阻止你,提示“必须是12版本以上的nvcc”。期间安装了高版本nvcc, 编译倒是成功了,但不支持编译CUDA_ARCHITECTURES="30" 的 750M。
幸好nvcc支持--use-local-env(解决vcvars64.bat找不到),-allow-unsupported-compiler(支持高版本的编译器)。 自定义了一个怪胎VC编译环境: 采用2022版的二进制 + 2017版本的头文件 + 2022版本的库文件。增加cuda_v10的编译脚本, make cuda_v10,通过!
剩下就简单了,需要修改ollama中的GPU发现,将"_v10" 依据查询到的driver特性附加上去,重新编译ollama
make CUDA_ARCHITECTURES="30" EXTRA_GOLDFLAGS="\"-X=github.com/ollama/ollama/discover.CudaComputeMajorMin=3\" \"-X=github.com/ollama/ollama/discover.CudaComputeMinorMin=0\"" exe
编译完成后, 替换掉原来的ollama.exe,且将cuda_v10_avx目录拷贝到与ollama安装的cuda_v11_avx同级即可。
开始运行我的模型 ollama run deepseek-r1:1.5b, 结果
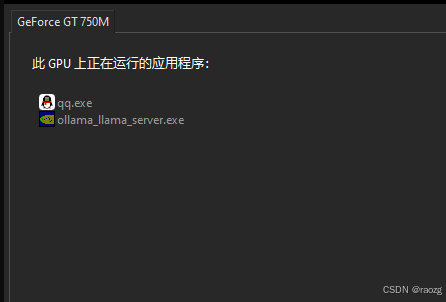
遗憾的是, 居然没有CPU运行快 T_T ;只是帮我省了内存。算了,几天后要开班了,又得996没空玩。
(利用了各种免费大模型询问解决各种编译问题,完全涉足一个不太熟悉的cuda领域,不得不说AI真是太强大了。)
建立了编译项目: https://gitee.com/Q22954230/ollama-0.5.13-for-old-nvdevice
基于最新版0.5.13 内含编译好的动态库, 还有一个未经验证的Tesla K80动态库;可以先安装0.5.13再用编译好的覆盖上去,包括ollama.exe(正常版本会有个compute能力验证限制)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)