Xinference部署
首先就是确认自己的python版本,建议使用3.10及以上,太低的安装过程会比较多的问题,我这里使用的python版本是3.10,如果不是也可以在当前的环境中创建镜像,然后在镜像上面进行部署安装。经过漫长的等待后,终于安装成功,在这过程中,如果遇到报某个包没装的话,就是pip install一下,或者问问千问或者dp会有对应的具体解决办法,我这里运气很好没有报错,之前其他地方的时候遇到过。),接下
前面两篇文章分别部署了Docker、Dify、Ollama(Dify平台私有化部署-CSDN博客,Ollama部署-CSDN博客),接下来就是在一个新的服务器上部署Xinference,然后在Xinference上面部署向量化模型和重排序模型。
首先就是确认自己的python版本,建议使用3.10及以上,太低的安装过程会比较多的问题,我这里使用的python版本是3.10,如果不是也可以在当前的环境中创建镜像,然后在镜像上面进行部署安装。创建镜像方法如下
# 创建一个环境
conda create -n Xinference python=3.10.14
# 激活环境,一定要激活环境,不然安装还是会有问题
conda activate Xinference接下来还是先学术资源加载一下,加载方法和Dify部署的时候是一样的

然后我们配置一下清华源,这样下载的时候会更加的方便
# 配置清华源
python -m pip install --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 使用清华源进行升级
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip 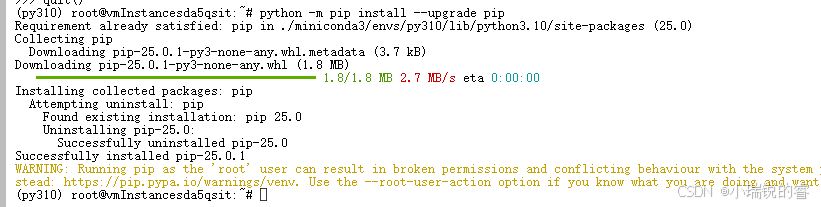

 这里在安装Xinference的时候,会遇到一个LIama.cpp的包下载有问题,所以我们就手动下载这个包,然后先把这个包安装好之后再装Xinference就可以了。这个包的下载地址: https://github.com/abetlen/llama-cpp-python/releases/tag/v0.2.88,假如你的python版本是3.11的,那就选择cp311的版本,我是因为我的python是3.10的,所以用3.10的包
这里在安装Xinference的时候,会遇到一个LIama.cpp的包下载有问题,所以我们就手动下载这个包,然后先把这个包安装好之后再装Xinference就可以了。这个包的下载地址: https://github.com/abetlen/llama-cpp-python/releases/tag/v0.2.88,假如你的python版本是3.11的,那就选择cp311的版本,我是因为我的python是3.10的,所以用3.10的包
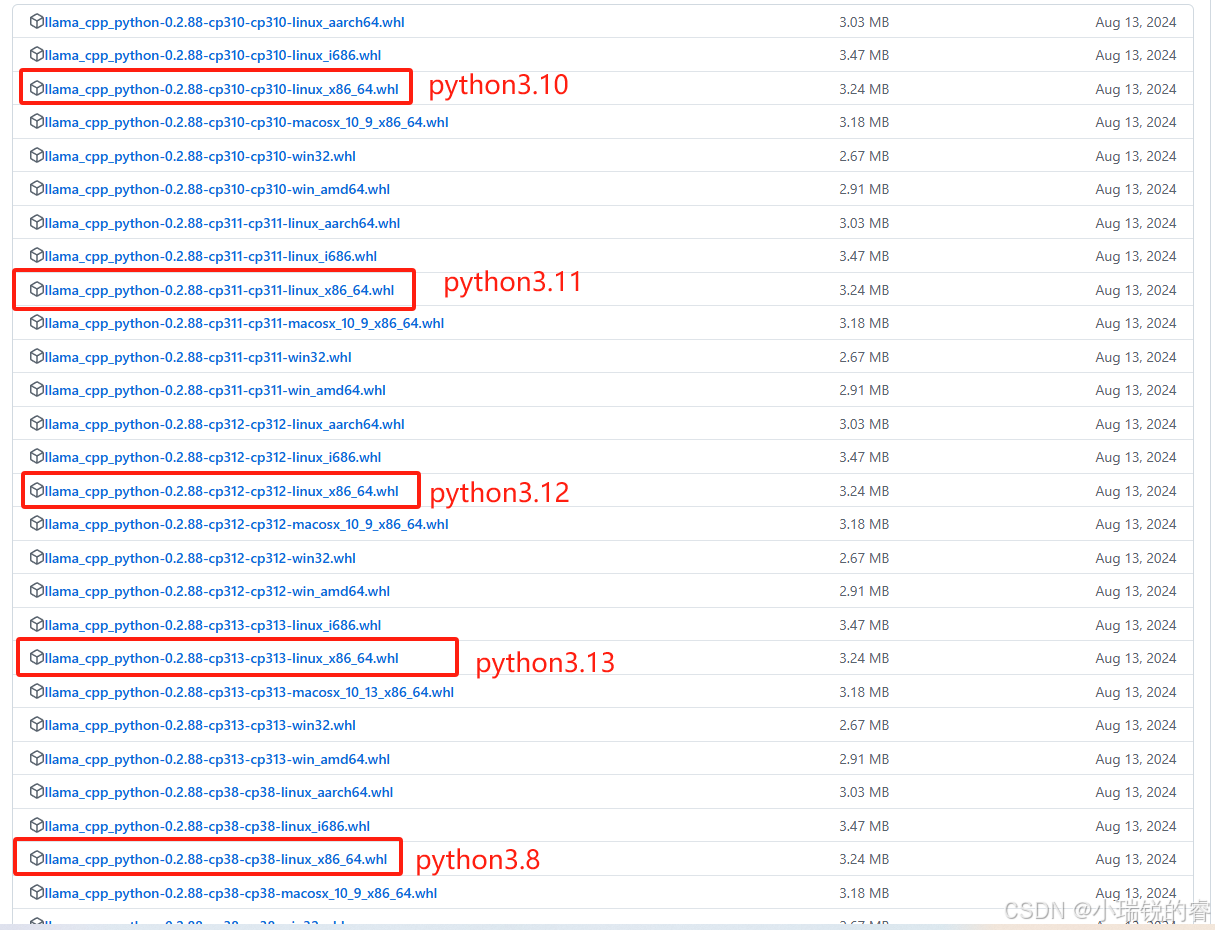
下载到本地后,上传到根目录,然后安装就行,安装就是pip install 文件名
pip install llama_cpp_python-0.2.88-cp310-cp310-linux_x86_64.whl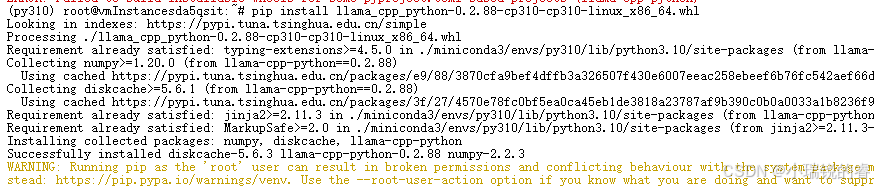 上面的安装成功之后,接下来就是安装Xinference了,这个过程很漫长。。。
上面的安装成功之后,接下来就是安装Xinference了,这个过程很漫长。。。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "xinference[all]" 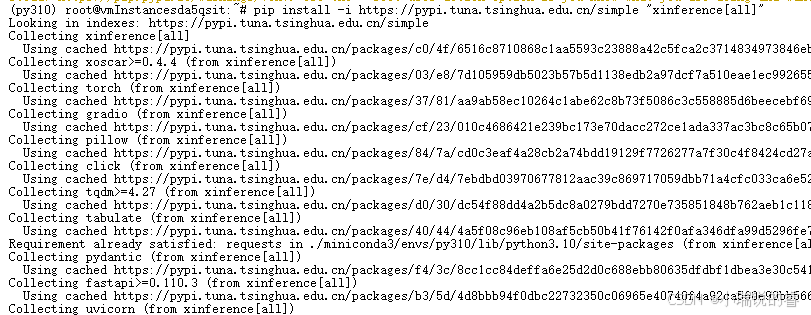
 经过漫长的等待后,终于安装成功,在这过程中,如果遇到报某个包没装的话,就是pip install一下,或者问问千问或者dp会有对应的具体解决办法,我这里运气很好没有报错,之前其他地方的时候遇到过。
经过漫长的等待后,终于安装成功,在这过程中,如果遇到报某个包没装的话,就是pip install一下,或者问问千问或者dp会有对应的具体解决办法,我这里运气很好没有报错,之前其他地方的时候遇到过。
接下来启动服务即可
xinference-local --host 0.0.0.0 --port 8890 
最终的页面就是这个样子的了
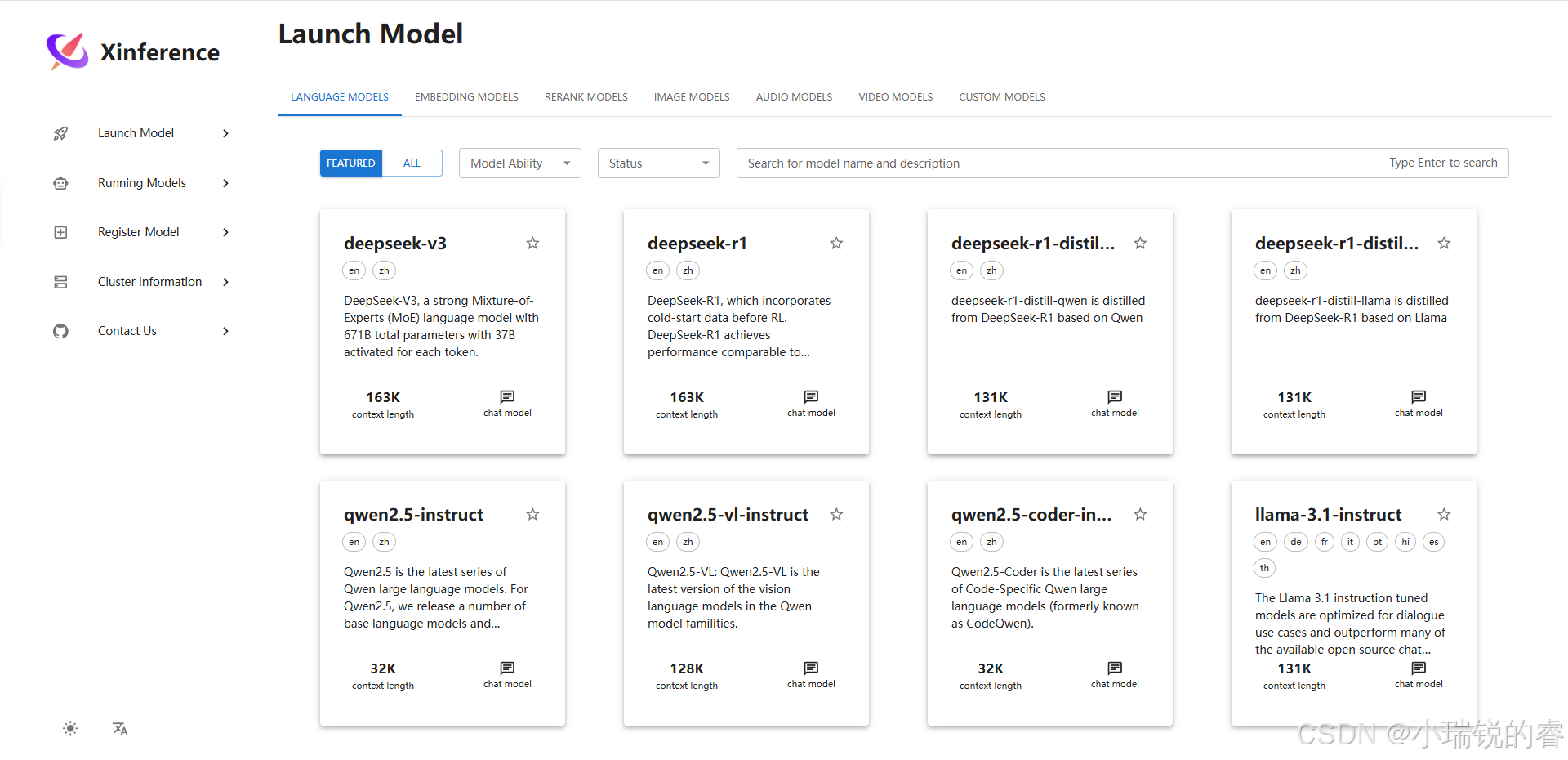
接下来部署重排序模型和向量化模型,这两个都用直接用魔搭里面的模型,也可以使用其他的。我这里直接把对应的模型git clone到服务器上
# 向量化模型 bge-large-zh-v1.5
git clone https://www.modelscope.cn/BAAI/bge-large-zh-v1.5.git
# 重排序 bge-reranker-large
git clone https://www.modelscope.cn/BAAI/bge-reranker-large.git下载成功后,Xinference上开始部署向量化模型
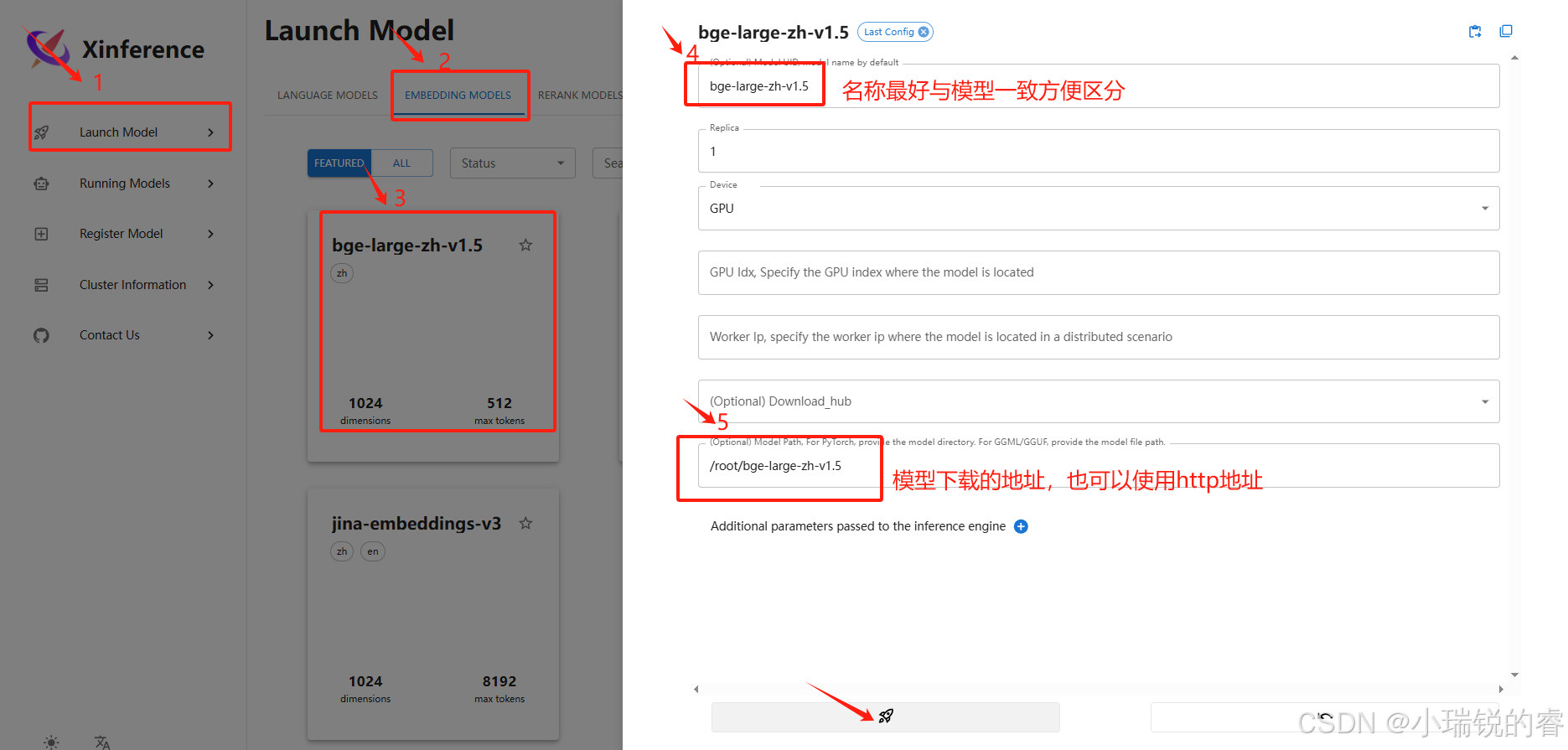
点击小火箭部署成功后,就会自动跳转到下面这个页面,说明已经部署成功了
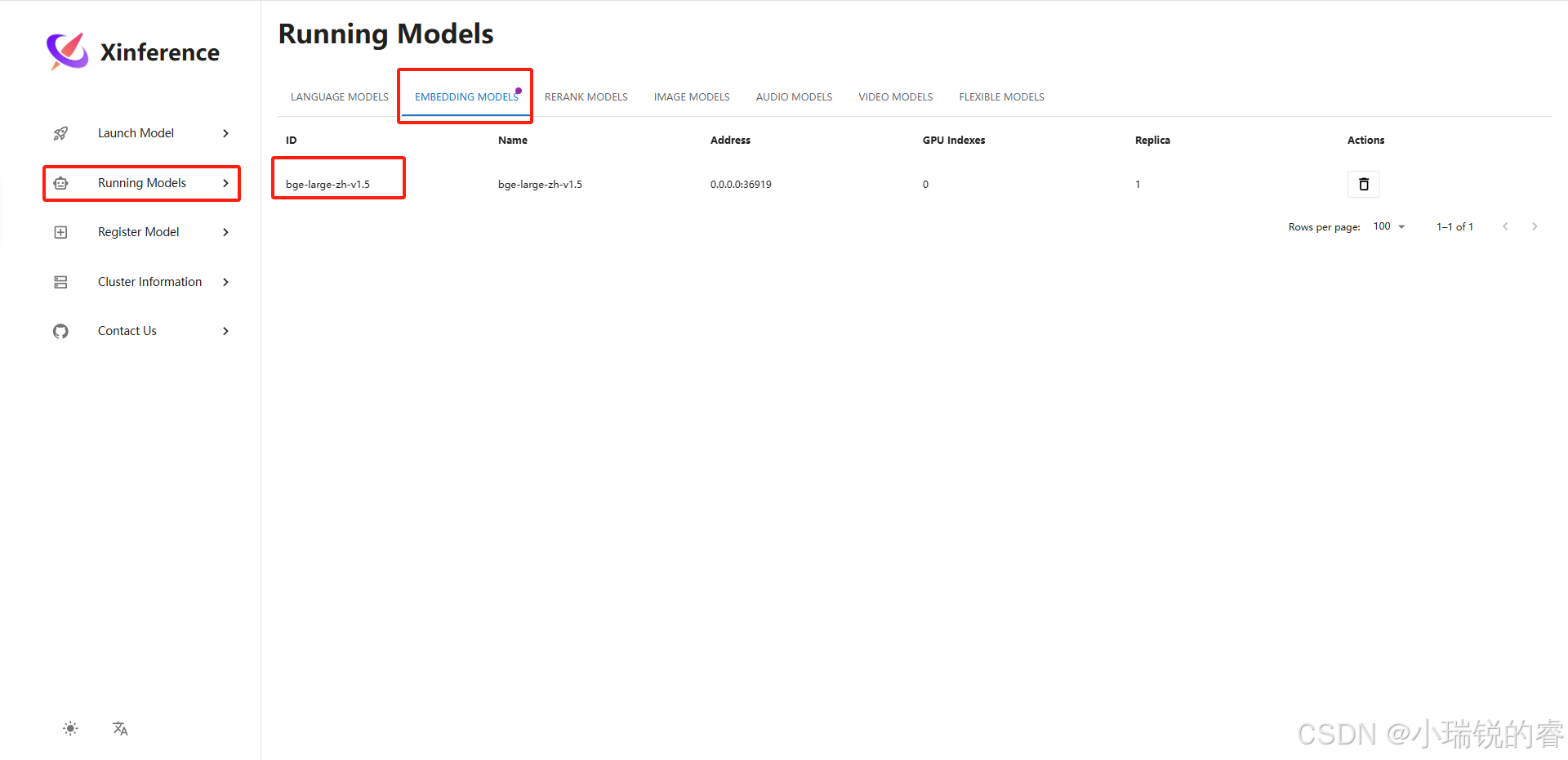
接下来部署重排序模型
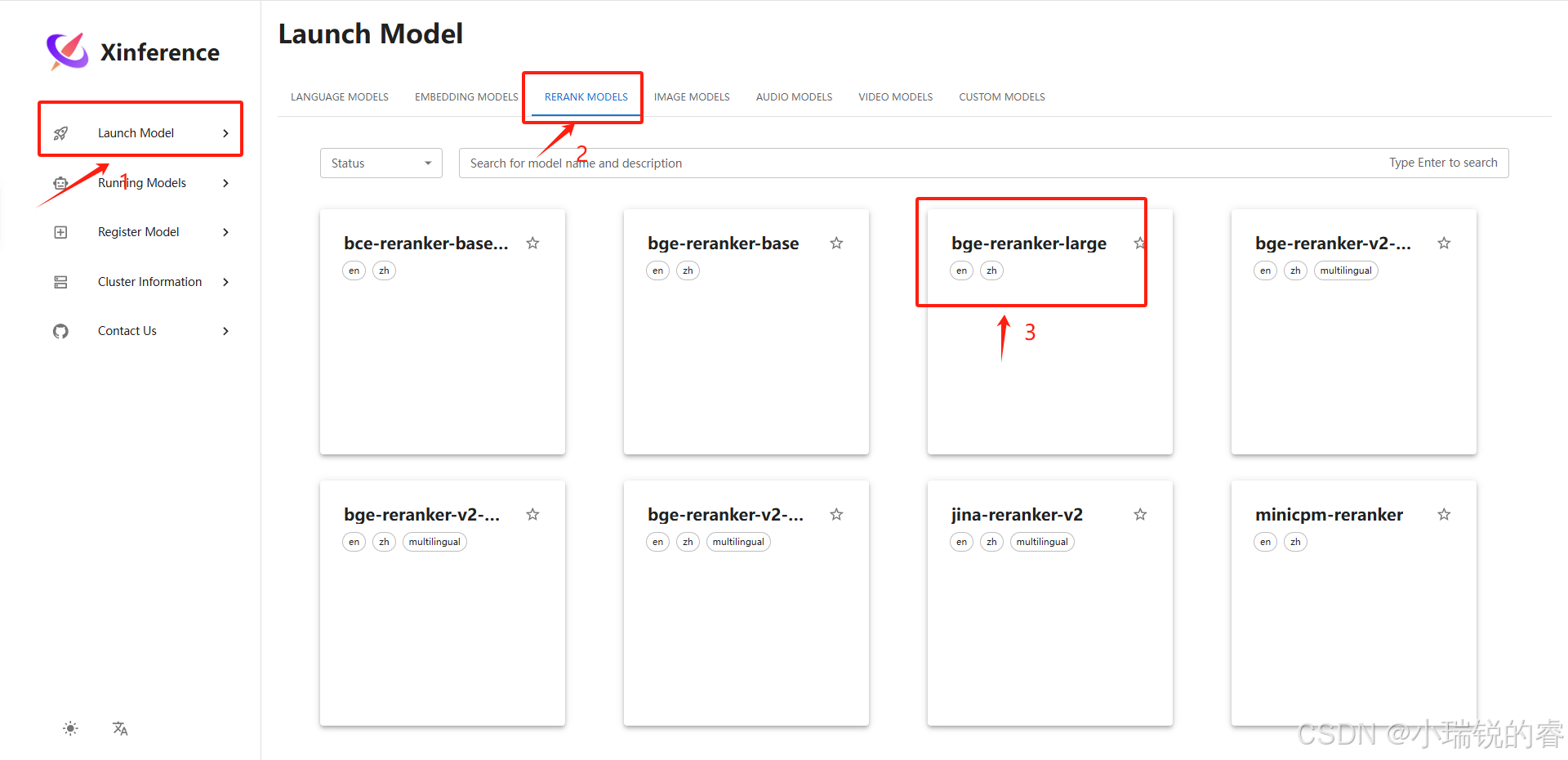
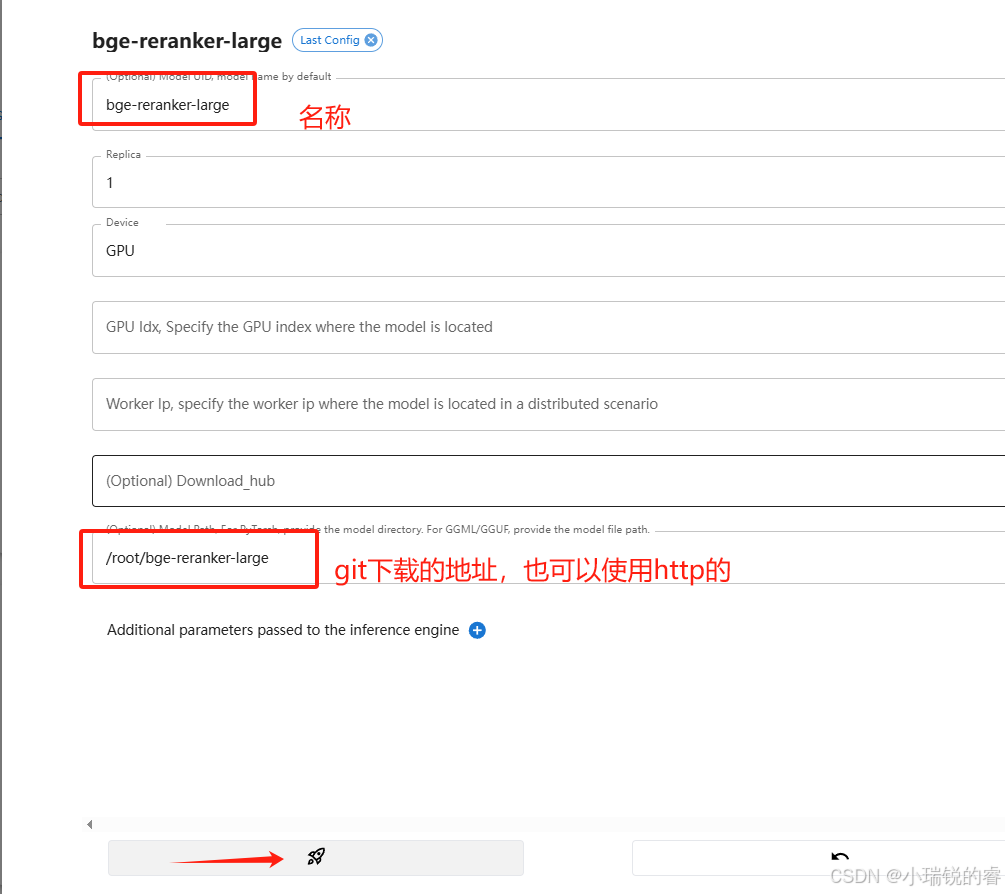 点击小火箭,部署成功后会跳转到下面这个页面
点击小火箭,部署成功后会跳转到下面这个页面
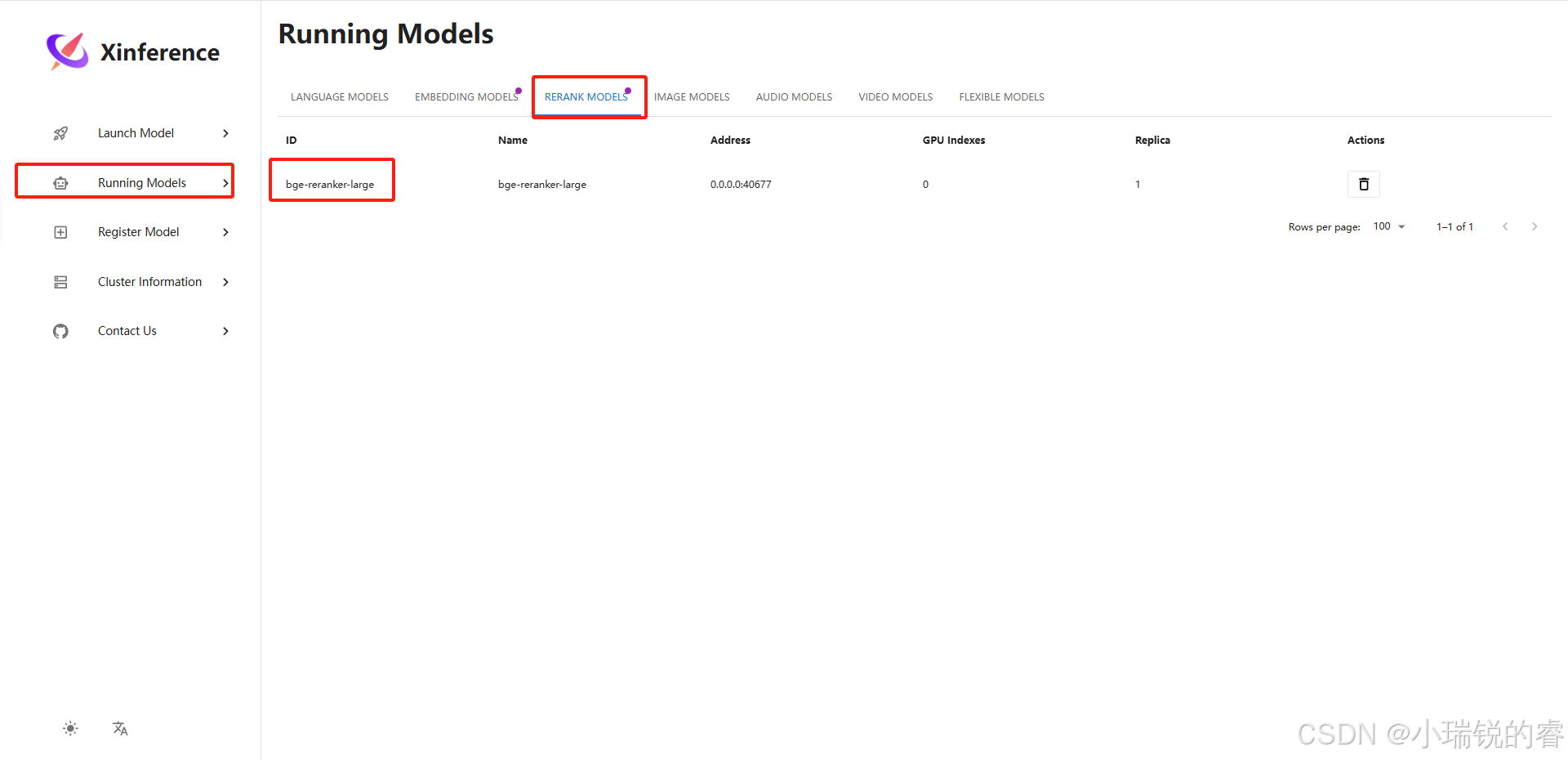
这样就说明全部部署成功了,可以在Dify里面把Xinference插件安装好后就可以把这两个模型加载进去,在设计工作流或者智能体的时候均可以使用了。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)