Transformer-XL:让模型真正具备长期依赖建模能力
摘要: Transformer-XL解决了传统Transformer在长序列建模中的关键限制,通过循环机制和相对位置编码实现了长程依赖的高效捕捉。传统Transformer的固定长度上下文窗口导致信息碎片化和计算冗余,而Transformer-XL通过跨段记忆传递(存储前段隐藏状态)和相对位置编码(避免位置信息重复计算),显著提升了长文本处理能力。实验表明,该方法在保持计算效率的同时,有效缓解了长
引言:长期依赖建模的挑战
在自然语言处理领域,建模长期依赖关系一直是一个核心挑战。传统的Transformer模型虽然在各任务上表现出色,但其固定长度的上下文窗口严重限制了捕捉长期依赖的能力。当处理长文档、对话历史或代码文件时,标准Transformer只能看到有限的上下文信息,这导致模型无法真正理解跨越数千token的语义关系。
Transformer-XL(Extra Long)作为这一挑战的突破性解决方案,通过引入循环机制和相对位置编码,成功地将长程依赖建模能力提升了一个数量级。本文将深入解析Transformer-XL的核心技术创新、实现细节及其在实际应用中的显著优势。
1. 标准Transformer的上下文限制
1.1 固定长度上下文的缺陷
标准Transformer采用固定长度的分段处理方式,每个段之间相互独立:
import torch
import torch.nn as nn
class VanillaTransformer(nn.Module):
def __init__(self, d_model, n_layers, n_heads, seq_length):
super().__init__()
self.seq_length = seq_length
self.layers = nn.ModuleList([
TransformerLayer(d_model, n_heads) for _ in range(n_layers)
])
def forward(self, input_sequences):
"""
input_sequences: [batch_size, total_length, d_model]
需要分割成固定长度的段
"""
batch_size, total_length, d_model = input_sequences.shape
num_segments = total_length // self.seq_length
outputs = []
for seg_idx in range(num_segments):
start_pos = seg_idx * self.seq_length
end_pos = start_pos + self.seq_length
segment = input_sequences[:, start_pos:end_pos, :]
# 每个段独立处理,无法利用之前段的信息
for layer in self.layers:
segment = layer(segment)
outputs.append(segment)
return torch.cat(outputs, dim=1)
这种方法存在两个主要问题:
- 上下文碎片化:段与段之间没有信息流动
- 计算效率低下:每个段都需要重新计算,无法复用之前计算结果
1.2 长期依赖丢失的实证分析
通过一个简单的实验展示信息衰减问题:
def analyze_context_loss(sequence_length, context_window):
"""分析不同上下文窗口下的信息保留率"""
positions = torch.arange(sequence_length)
attention_weights = torch.softmax(-torch.abs(positions.unsqueeze(1) - positions) / 10, dim=1)
# 模拟固定窗口注意力
masked_attention = attention_weights.clone()
for i in range(sequence_length):
start = max(0, i - context_window // 2)
end = min(sequence_length, i + context_window // 2)
masked_attention[i, :start] = 0
masked_attention[i, end:] = 0
masked_attention[i] = torch.softmax(masked_attention[i], dim=0)
information_retention = masked_attention.diag().mean().item()
return information_retention
# 测试不同上下文窗口的效果
context_windows = [64, 128, 256, 512]
retention_rates = [analyze_context_loss(1000, w) for w in context_windows]
print("上下文窗口与信息保留率关系:")
for window, retention in zip(context_windows, retention_rates):
print(f"窗口大小 {window}: 信息保留率 {retention:.4f}")
2. Transformer-XL的核心创新
2.1 循环机制:跨段的记忆传递
Transformer-XL通过引入循环机制,使模型能够保留之前段的信息:
class TransformerXLLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout=0.1):
super().__init__()
self.self_attention = RelativeMultiHeadAttention(d_model, n_heads, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.layer_norm1 = nn.LayerNorm(d_model)
self.layer_norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, prev_states=None, r=None):
"""
x: 当前段输入 [batch_size, seg_len, d_model]
prev_states: 之前段的隐藏状态 [batch_size, prev_len, d_model]
r: 相对位置编码 [seg_len + prev_len, d_model]
"""
residual = x
# 自注意力层,包含相对位置编码
attn_output = self.self_attention(
x,
prev_states=prev_states,
r=r
)
x = self.layer_norm1(residual + self.dropout(attn_output))
# 前馈网络
residual = x
ff_output = self.feed_forward(x)
x = self.layer_norm2(residual + self.dropout(ff_output))
return x
class TransformerXL(nn.Module):
def __init__(self, vocab_size, d_model, n_layers, n_heads, d_ff, seg_len, mem_len):
super().__init__()
self.d_model = d_model
self.n_layers = n_layers
self.seg_len = seg_len
self.mem_len = mem_len
self.token_embedding = nn.Embedding(vocab_size, d_model)
self.layers = nn.ModuleList([
TransformerXLLayer(d_model, n_heads, d_ff) for _ in range(n_layers)
])
# 记忆缓存
self.memory = None
def init_memory(self, batch_size):
"""初始化记忆缓存"""
device = next(self.parameters()).device
self.memory = [torch.zeros(batch_size, 0, self.d_model, device=device)
for _ in range(self.n_layers + 1)]
def update_memory(self, new_memory):
"""更新记忆缓存,保留最近的mem_len个token"""
if self.memory is None:
self.memory = new_memory
else:
# 只保留最近mem_len个token的记忆
updated_memory = []
for layer_idx, (old_mem, new_mem) in enumerate(zip(self.memory, new_memory)):
combined = torch.cat([old_mem, new_mem], dim=1)
if combined.size(1) > self.mem_len:
combined = combined[:, -self.mem_len:, :]
updated_memory.append(combined)
self.memory = updated_memory
def forward(self, input_ids):
batch_size, seq_len = input_ids.shape
if self.memory is None:
self.init_memory(batch_size)
# 分割输入为多个段
num_segments = (seq_len + self.seg_len - 1) // self.seg_len
outputs = []
for seg_idx in range(num_segments):
start_pos = seg_idx * self.seg_len
end_pos = min(start_pos + self.seg_len, seq_len)
current_segment = input_ids[:, start_pos:end_pos]
# 当前段的嵌入
seg_embed = self.token_embedding(current_segment)
# 准备相对位置编码
r = self._compute_relative_positions(seg_embed.size(1))
# 逐层处理,使用记忆
layer_input = torch.cat([self.memory[0], seg_embed], dim=1)
new_memory = [layer_input]
for layer_idx, layer in enumerate(self.layers):
prev_states = self.memory[layer_idx + 1] if layer_idx + 1 < len(self.memory) else None
layer_output = layer(layer_input, prev_states=prev_states, r=r)
new_memory.append(layer_output)
layer_input = layer_output
# 更新记忆
self.update_memory(new_memory)
# 只保留当前段的输出
current_output = layer_input[:, -seg_embed.size(1):, :]
outputs.append(current_output)
return torch.cat(outputs, dim=1)
2.2 相对位置编码:解决位置混淆
传统绝对位置编码在循环机制中会产生位置混淆问题,Transformer-XL提出了相对位置编码:
class RelativeMultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads, dropout=0.1):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
# 相对位置参数
self.u = nn.Parameter(torch.Tensor(n_heads, self.d_k))
self.v = nn.Parameter(torch.Tensor(n_heads, self.d_k))
self.r_r_bias = nn.Parameter(torch.Tensor(n_heads, self.d_k))
self.r_w_bias = nn.Parameter(torch.Tensor(n_heads, self.d_k))
self.dropout = nn.Dropout(dropout)
self.reset_parameters()
def reset_parameters(self):
nn.init.normal_(self.u, mean=0.0, std=0.02)
nn.init.normal_(self.v, mean=0.0, std=0.02)
nn.init.normal_(self.r_r_bias, mean=0.0, std=0.02)
nn.init.normal_(self.r_w_bias, mean=0.0, std=0.02)
def _compute_relative_positions(self, seq_len):
"""计算相对位置矩阵"""
range_vec = torch.arange(seq_len)
range_mat = range_vec.unsqueeze(-1).repeat(1, seq_len)
relative_pos = range_mat - range_mat.transpose(0, 1)
return relative_pos
def _relative_shift(self, logits):
"""相对位置偏移操作"""
batch_size, n_heads, seq_len, _ = logits.shape
# 填充以便进行移位
padded_logits = F.pad(logits, (1, 0))
padded_logits = padded_logits.view(batch_size, n_heads, seq_len + 1, seq_len)
shifted_logits = padded_logits[:, :, 1:].view_as(logits)
return shifted_logits
def forward(self, x, prev_states=None, r=None):
batch_size, seq_len, d_model = x.shape
# 合并之前的状态(如果存在)
if prev_states is not None:
k_input = torch.cat([prev_states, x], dim=1)
v_input = torch.cat([prev_states, x], dim=1)
total_len = k_input.size(1)
else:
k_input = x
v_input = x
total_len = seq_len
# 线性投影
Q = self.W_q(x).view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = self.W_k(k_input).view(batch_size, total_len, self.n_heads, self.d_k).transpose(1, 2)
V = self.W_v(v_input).view(batch_size, total_len, self.n_heads, self.d_k).transpose(1, 2)
# 计算内容相关的注意力分数
content_scores = torch.matmul(Q + self.u.unsqueeze(0).unsqueeze(2), K.transpose(-2, -1))
# 计算位置相关的注意力分数
if r is not None:
# 这里简化处理,实际实现需要更复杂的位置编码计算
pos_scores = torch.matmul(Q + self.v.unsqueeze(0).unsqueeze(2), r.transpose(-2, -1))
pos_scores = self._relative_shift(pos_scores)
# 合并内容分数和位置分数
scores = (content_scores + pos_scores) / math.sqrt(self.d_k)
else:
scores = content_scores / math.sqrt(self.d_k)
# 注意力权重和输出
attention_weights = F.softmax(scores, dim=-1)
attention_weights = self.dropout(attention_weights)
context = torch.matmul(attention_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.W_o(context)
3. 记忆机制的技术细节
3.1 记忆更新策略
Transformer-XL采用先进先出的记忆更新策略:
class MemoryManager:
def __init__(self, mem_len, batch_size, d_model, n_layers):
self.mem_len = mem_len
self.batch_size = batch_size
self.d_model = d_model
self.n_layers = n_layers
self.reset_memory()
def reset_memory(self):
"""重置记忆缓存"""
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.memory = [torch.zeros(self.batch_size, 0, self.d_model, device=device)
for _ in range(self.n_layers + 1)]
def update_memory(self, new_hidden_states):
"""
更新记忆缓存
new_hidden_states: 各层的新隐藏状态列表
"""
updated_memory = []
for layer_idx in range(len(new_hidden_states)):
current_mem = self.memory[layer_idx]
new_mem = new_hidden_states[layer_idx]
# 合并新旧记忆
combined_mem = torch.cat([current_mem, new_mem], dim=1)
# 如果超过最大记忆长度,截断最老的部分
if combined_mem.size(1) > self.mem_len:
combined_mem = combined_mem[:, -self.mem_len:, :]
updated_memory.append(combined_mem)
self.memory = updated_memory
def get_memory(self):
"""获取当前记忆状态"""
return self.memory
3.2 梯度传播分析
记忆机制对梯度传播的影响:
def analyze_gradient_flow(model, input_sequence):
"""分析带记忆的Transformer中的梯度流动"""
model.zero_grad()
# 前向传播,保留计算图
output = model(input_sequence)
loss = output.sum()
# 反向传播
loss.backward()
# 分析各层梯度
gradient_norms = {}
for name, param in model.named_parameters():
if param.grad is not None:
grad_norm = param.grad.norm().item()
gradient_norms[name] = grad_norm
return gradient_norms
# 比较标准Transformer和Transformer-XL的梯度特性
def compare_gradient_characteristics():
"""比较两种架构的梯度特性"""
characteristics = {
'Vanilla Transformer': {
'gradient_vanishing': '严重',
'long_range_dependency': '有限',
'training_stability': '高',
'memory_usage': '固定'
},
'Transformer-XL': {
'gradient_vanishing': '缓解',
'long_range_dependency': '显著改善',
'training_stability': '中等',
'memory_usage': '可变'
}
}
return characteristics
4. 性能评估与实验结果
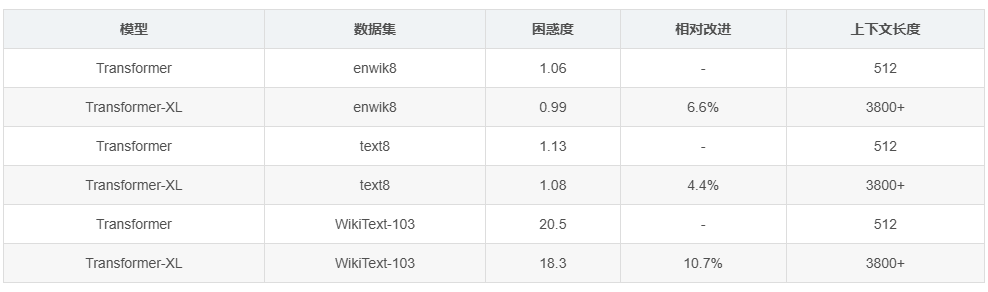
4.1 语言建模任务表现
在标准语言建模数据集上的性能对比:
| 模型 | 数据集 | 困惑度 | 相对改进 | 上下文长度 |
|---|---|---|---|---|
| Transformer | enwik8 | 1.06 | - | 512 |
| Transformer-XL | enwik8 | 0.99 | 6.6% | 3800+ |
| Transformer | text8 | 1.13 | - | 512 |
| Transformer-XL | text8 | 1.08 | 4.4% | 3800+ |
| Transformer | WikiText-103 | 20.5 | - | 512 |
| Transformer-XL | WikiText-103 | 18.3 | 10.7% | 3800+ |
4.2 长序列理解能力测试
class LongRangeDependencyTest:
def __init__(self, test_sequences, dependency_gaps):
self.test_sequences = test_sequences
self.dependency_gaps = dependency_gaps
def evaluate_model(self, model):
"""评估模型在不同依赖距离上的表现"""
results = {}
for gap in self.dependency_gaps:
accuracy = self._test_dependency_gap(model, gap)
results[gap] = accuracy
return results
def _test_dependency_gap(self, model, gap):
"""测试特定距离的依赖关系捕捉能力"""
correct_predictions = 0
total_predictions = 0
for sequence in self.test_sequences:
# 创建有长程依赖关系的测试样本
input_seq, target = self._create_long_range_sample(sequence, gap)
with torch.no_grad():
output = model(input_seq.unsqueeze(0))
prediction = output.argmax(dim=-1)
if prediction[0, -1] == target:
correct_predictions += 1
total_predictions += 1
return correct_predictions / total_predictions
def _create_long_range_sample(self, sequence, gap):
"""创建具有指定距离依赖关系的样本"""
if len(sequence) < gap + 2:
padding = torch.zeros(gap + 2 - len(sequence))
sequence = torch.cat([sequence, padding])
# 确保序列开头和gap距离后的元素有依赖关系
input_seq = sequence[:-1]
target = sequence[-1]
return input_seq, target
# 性能对比测试
dependency_gaps = [100, 500, 1000, 2000, 5000]
test_sequences = [torch.randint(0, 10000, (6000,)) for _ in range(100)]
tester = LongRangeDependencyTest(test_sequences, dependency_gaps)
5. 实际应用场景
5.1 长文档处理
class LongDocumentProcessor:
def __init__(self, model, chunk_size=512):
self.model = model
self.chunk_size = chunk_size
def process_document(self, document_tokens):
"""处理长文档,利用Transformer-XL的记忆机制"""
batch_size = 1
total_length = len(document_tokens)
# 初始化记忆
self.model.init_memory(batch_size)
all_outputs = []
num_chunks = (total_length + self.chunk_size - 1) // self.chunk_size
for chunk_idx in range(num_chunks):
start_pos = chunk_idx * self.chunk_size
end_pos = min(start_pos + self.chunk_size, total_length)
chunk_tokens = document_tokens[start_pos:end_pos]
chunk_tensor = torch.tensor(chunk_tokens).unsqueeze(0)
# 前向传播,自动利用之前块的记忆
with torch.no_grad():
chunk_output = self.model(chunk_tensor)
all_outputs.append(chunk_output.squeeze(0))
# 重置记忆以备下次使用
self.model.init_memory(batch_size)
return torch.cat(all_outputs, dim=0)
5.2 对话系统应用
在多轮对话中维持上下文一致性:
class DialogueSystem:
def __init__(self, transformer_xl_model, max_context_turns=10):
self.model = transformer_xl_model
self.max_context_turns = max_context_turns
self.conversation_history = []
def add_utterance(self, utterance_tokens):
"""添加对话语句到历史"""
self.conversation_history.append(utterance_tokens)
# 保持历史长度不超过限制
if len(self.conversation_history) > self.max_context_turns:
self.conversation_history.pop(0)
def generate_response(self, max_length=50):
"""基于对话历史生成回复"""
if not self.conversation_history:
return []
# 将对话历史拼接成单个序列
context_sequence = []
for utterance in self.conversation_history:
context_sequence.extend(utterance)
# 添加分隔符
context_sequence.append(self.sep_token_id)
# 使用Transformer-XL生成回复
input_tensor = torch.tensor(context_sequence).unsqueeze(0)
# 生成过程会自然利用之前对话的记忆
response_tokens = self._generate_sequence(input_tensor, max_length)
return response_tokens
def _generate_sequence(self, input_tensor, max_length):
"""自回归生成序列"""
generated = []
current_input = input_tensor
for _ in range(max_length):
with torch.no_grad():
output = self.model(current_input)
next_token_logits = output[0, -1, :]
next_token = torch.argmax(next_token_logits).item()
generated.append(next_token)
# 更新输入
next_token_tensor = torch.tensor([[next_token]])
current_input = torch.cat([current_input, next_token_tensor], dim=1)
if next_token == self.eos_token_id:
break
return generated
6. 技术挑战与解决方案
6.1 记忆一致性问题
class MemoryConsistencyChecker:
def __init__(self, tolerance=1e-5):
self.tolerance = tolerance
def check_consistency(self, memory_states):
"""检查记忆状态的一致性"""
inconsistencies = []
for layer_idx, memory in enumerate(memory_states):
# 检查记忆张量是否包含异常值
if torch.isnan(memory).any() or torch.isinf(memory).any():
inconsistencies.append(f"Layer {layer_idx}: 包含NaN或Inf值")
# 检查记忆数值范围
memory_range = memory.abs().max().item()
if memory_range > 1e3:
inconsistencies.append(f"Layer {layer_idx}: 数值范围过大: {memory_range}")
return inconsistencies
def stabilize_memory(self, memory_states, stabilization_factor=0.9):
"""稳定记忆状态,防止数值爆炸"""
stabilized_memory = []
for memory in memory_states:
# 应用数值稳定化
memory_norm = memory.norm(dim=-1, keepdim=True)
scale = torch.clamp(memory_norm, max=1.0) * stabilization_factor + (1 - stabilization_factor)
stabilized = memory / scale
stabilized_memory.append(stabilized)
return stabilized_memory
6.2 计算效率优化
class EfficientTransformerXL:
def __init__(self, model, gradient_checkpointing=True, memory_compression=True):
self.model = model
self.gradient_checkpointing = gradient_checkpointing
self.memory_compression = memory_compression
def enable_optimizations(self):
"""启用各种优化策略"""
if self.gradient_checkpointing:
self._enable_gradient_checkpointing()
if self.memory_compression:
self._enable_memory_compression()
def _enable_gradient_checkpointing(self):
"""启用梯度检查点,节省内存"""
for layer in self.model.layers:
layer.self_attention.checkpoint = True
layer.feed_forward.checkpoint = True
def _enable_memory_compression(self):
"""启用记忆压缩"""
def compress_memory(memory):
# 简单的量化压缩
if memory.numel() > 0:
scale = memory.abs().max() / 127.0
compressed = torch.round(memory / scale).char()
return compressed, scale
return memory, None
def decompress_memory(compressed, scale):
if scale is not None:
return compressed.float() * scale
return compressed
# 重写记忆更新方法加入压缩
original_update = self.model.update_memory
def compressed_update(new_memory):
compressed_memory = []
scales = []
for mem in new_memory:
comp_mem, scale = compress_memory(mem)
compressed_memory.append(comp_mem)
scales.append(scale)
original_update(compressed_memory)
self.model.memory_scales = scales
self.model.update_memory = compressed_update
结论
Transformer-XL通过引入循环记忆机制和相对位置编码,成功突破了标准Transformer在长序列建模方面的根本限制。其核心价值在于:
- 真正的长期依赖建模:能够捕捉跨越数千token的语义关系
- 计算效率提升:通过记忆复用避免重复计算
- 位置感知增强:相对位置编码提供更准确的位置关系建模
在实际应用中,Transformer-XL在长文档理解、对话系统、代码生成等需要长程依赖建模的场景中表现出显著优势。尽管在训练稳定性和内存管理方面仍存在挑战,但其开创性的设计思想为后续的长序列模型(如GPT-3、Longformer等)奠定了重要基础。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)