学习周报二十五
本周通过深入研究三项紧密相关的技术,系统掌握了视觉信息高效处理与模型优化的前沿方法。当然也有阅读源码,提升代码能力。
摘要
本周重点研究了视觉信息高效压缩与大规模语言模型优化的前沿技术。系统学习了美团新发布的上下文级联压缩技术(C3),深入分析了其分层压缩机制;全面复习了DeepSeek-OCR的视觉编码器架构,重点理解了其高分辨率轻量压缩的三模块设计;同时探讨了DeepSeek-V3.2的最新进展。研究聚焦于视觉特征压缩与模型效率优化的核心技术,建立了从视觉压缩到语言模型优化的完整技术认知。
Abstract
This week focused on cutting-edge technologies for efficient visual information compression and large-scale language model optimization. Systematically studied the newly released Contextual Cascade Compression (C3) technology from Meituan, conducting in-depth analysis of its hierarchical compression mechanism; comprehensively reviewed the visual encoder architecture of DeepSeek-OCR, emphasizing the three-module design for high-resolution lightweight compression; simultaneously explored the latest advancements of DeepSeek-V3.2. The research centered on core technologies of visual feature compression and model efficiency optimization, establishing a complete technical cognition from visual compression to language model optimization.
1、学习了美团新发布的技术并与复习了DeepSeek-OCR
美团发布的新上下文级联压缩技术(C3) - 学AI的小勇的文章 - 知乎
主要复习了DeepSeek-OCR模型结构设计: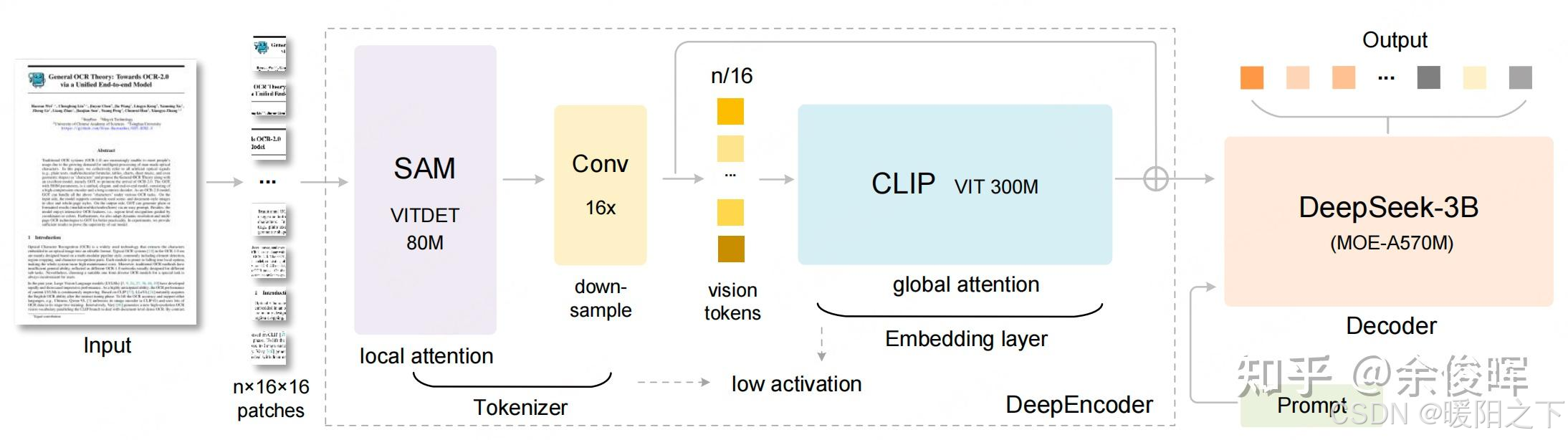
DeepEncoder是DeepSeek-OCR的最核心部分(高分辨率下的轻量视觉压缩器),专门解决现有VLMs视觉编码器(如Vary、InternVL2.0)的痛点:高分辨率输入时token过多、激活内存大、不支持多分辨率。包含三个组件:
模块1:视觉感知(窗口注意力主导)
采用SAM-base(Segment Anything Model,80M参数),输入图像被分割为16×16的patch(如1024×1024图像生成4096个patch token)。这个在vary和got中均使用。
作用:通过窗口注意力(局部注意力)捕捉图像细节(如文本位置、字体),避免全局注意力的高内存消耗。
模块2:16×卷积压缩器
位于SAM和CLIP之间,由2层卷积构成(核大小3×3,步长2,通道数从256→1024),实现视觉token的16倍下采样。
作用:将SAM输出的4096个token压缩为256个(1024×1024输入场景),大幅减少后续全局注意力模块的计算量,控制激活内存。
模块3:视觉知识(全局注意力主导)
采用CLIP-large(300M参数),但移除第一层patch嵌入层(输入改为压缩后的token)。
作用:通过全局注意力整合压缩后的token,提炼图像全局语义(如文档布局、文本逻辑),为解码提供结构化视觉知识。
2、学习DeepSeek-V3.2
ChatGPT三岁生日这一天,DeepSeek-V3.2来了! - 学AI的小勇的文章 - 知乎
总结
本周通过深入研究三项紧密相关的技术,系统掌握了视觉信息高效处理与模型优化的前沿方法。当然也有阅读源码,提升代码能力。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)