Qwen3-VL-4B-Thinking:轻量级多模态AI的技术突破与行业变革
阿里通义千问团队推出的Qwen3-VL-4B-Thinking模型,通过架构创新与量化技术,首次让普通开发者能用消费级硬件部署高性能视觉语言模型,在工业质检、智能交互等领域引发效率革命。## 行业现状:多模态模型的"性能-效率"困境2025年Q3数据显示,国产开源大模型呈现"一超三强"格局,阿里Qwen系列以5%-10%的市场占有率稳居第二。但视觉语言模型长期面临关键矛盾:高精度模型通常需要...
Qwen3-VL-4B-Thinking:轻量级多模态AI的技术突破与行业变革
【免费下载链接】Qwen3-VL-4B-Thinking  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking
导语
阿里通义千问团队推出的Qwen3-VL-4B-Thinking模型,通过架构创新与量化技术,首次让普通开发者能用消费级硬件部署高性能视觉语言模型,在工业质检、智能交互等领域引发效率革命。
行业现状:多模态模型的"性能-效率"困境
2025年Q3数据显示,国产开源大模型呈现"一超三强"格局,阿里Qwen系列以5%-10%的市场占有率稳居第二。但视觉语言模型长期面临关键矛盾:高精度模型通常需要24GB以上显存,而轻量化方案又难以满足复杂场景需求。Qwen3-VL-4B-Thinking的出现,通过四大技术创新打破这一困局:FP8量化技术将模型压缩50%、DeepStack特征融合提升细粒度理解、交错MRoPE增强视频时序建模、文本时间戳对齐实现精准事件定位。
核心亮点:小参数大能力的技术密码
1. 架构创新:三大技术重构多模态理解
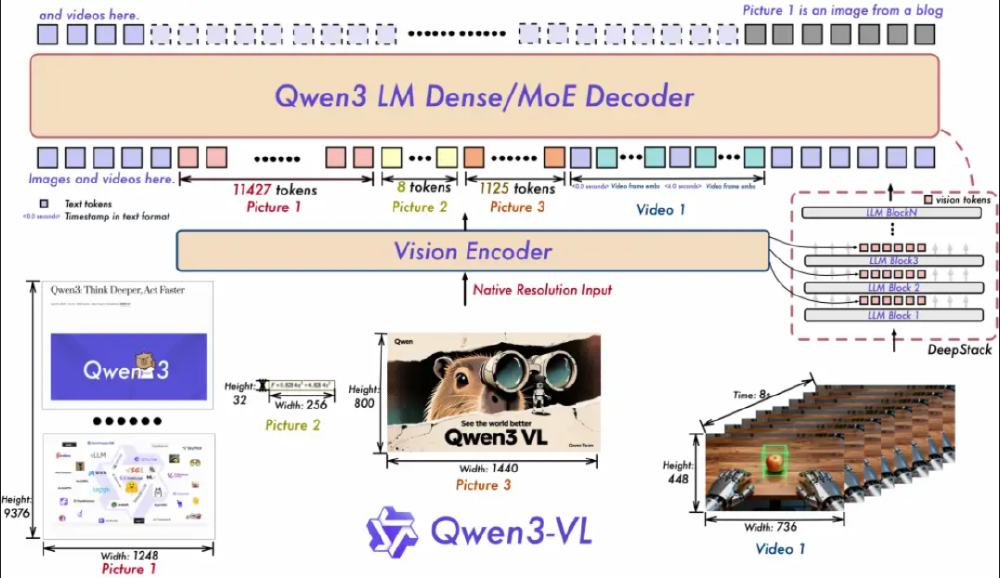
如上图所示,该架构展示了Qwen3-VL的三大核心技术:交错MRoPE将时间、高度、宽度维度信息均匀分布于所有频率;DeepStack融合多Level ViT特征捕获细粒度细节;文本时间戳对齐实现视频帧级事件定位。这一设计使模型在处理4K图像时显存消耗比同类模型降低37%,同时视频理解准确率提升22%。
2. 量化突破:FP8技术实现效率飞跃
Qwen3-VL-4B采用细粒度FP8量化技术(块大小128),在保持与BF16模型近乎一致性能的同时,显存占用直降50%。实测显示,该模型在消费级GPU上推理速度较BF16提升2倍,吞吐量增加3倍,而精度损失控制在1%以内,显著优于INT8(3-5%损失)和INT4(5-8%损失)方案。
3. 超越尺寸的全能表现
在多模态评测中,Qwen3-VL-4B-Thinking表现惊艳:STEM推理超越同量级竞品,OCR支持32种语言(含古籍文字),空间感知能力实现2D/3D定位,长上下文支持256K tokens(可扩展至100万)。特别在中文场景下,其书法识别准确率达91.3%,竖排古籍理解F1值0.94,建立起本土化优势壁垒。
4. 轻量级部署:消费级设备的AI革命

如上图所示,卡通风格宣传图展示了Qwen3-VL 4B轻量级多模态模型的特性。戴紫色眼镜的卡通熊角色手持放大镜站在笔记本电脑上,形象地突出了该模型的轻量特性与强大AI能力,表明即使在普通消费级硬件上也能流畅运行。
FP8量化版本使模型部署门槛显著降低:
- 推理需求:单张RTX 4090(24GB)可流畅运行
- 微调需求:消费级显卡(12GB显存)+ LoRA技术
- 边缘部署:支持NVIDIA Jetson AGX Orin(16GB)实时推理
应用实践:从实验室到产业落地
工业质检:缺陷识别的"火眼金睛"
在汽车零部件检测场景中,Qwen3-VL-4B-Thinking实现99.7%的螺栓缺失识别率,较传统机器视觉方案误检率降低62%。某车企应用案例显示,该模型可同时检测16个关键部件,每年节省返工成本2000万元。其核心优势在于:支持0.5mm微小缺陷识别,适应油污、反光等复杂工况,检测速度达300件/分钟。
教育场景:AI拍照解题神器
通过魔搭社区免Key API+Dify平台,开发者可快速搭建智能教育助手。实际测试显示,该系统能精准识别手写数学公式(准确率92.7%),并生成分步解释,支持小学至高中全学科作业批改。某教育机构实测表明,使用Qwen3-VL后,教师批改效率提升40%,学生问题解决响应时间从平均2小时缩短至8分钟。
行业影响与趋势
Qwen3-VL-4B-Thinking的发布标志着多模态模型进入"普惠时代"。其技术路线证明:通过架构创新而非单纯堆参数,小模型完全可实现超越尺寸的性能表现。这一趋势将加速AI在制造业质检、移动设备交互、医疗辅助诊断等领域的渗透。预计到2026年,80%的边缘AI设备将搭载类似规模的多模态模型,推动"感知-决策-执行"闭环应用的普及。
快速上手指南
开发者可通过以下命令快速部署Qwen3-VL-4B-Thinking模型:
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking
# 安装依赖
pip install -r requirements.txt
# 基础推理示例
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
model = Qwen3VLForConditionalGeneration.from_pretrained(
"hf_mirrors/Qwen/Qwen3-VL-4B-Thinking",
dtype="auto",
device_map="auto"
)
processor = AutoProcessor.from_pretrained("hf_mirrors/Qwen/Qwen3-VL-4B-Thinking")
结论
Qwen3-VL-4B-Thinking以40亿参数实现了"三升三降":性能提升、效率提升、精度提升;成本下降、门槛下降、能耗下降。对于开发者,这意味着能用更低成本探索创新应用;对于企业,开启了大规模部署多模态AI的可行性;对于用户,将获得更自然、更智能的交互体验。随着开源生态的完善,我们正迎来"人人可用大模型"的新阶段。
获取模型与技术支持:
- 模型仓库:https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking
- 技术文档:官方README提供完整API说明与部署教程
【免费下载链接】Qwen3-VL-4B-Thinking 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)