GigaWorld-0:以世界模型为数据引擎赋能具身人工智能
25年11月来自极佳科技的论文“GigaWorld-0: World Models as Data Engine to Empower Embodied AI”。世界模型正逐渐成为可扩展、数据高效的具身智能的基础范式。本文提出 GigaWorld-0,一个统一的世界模型框架,专门设计为视觉-语言-动作 (VLA) 学习的数据引擎。GigaWorld-0 集成两个协同组件:GigaWorld-0-V
25年11月来自极佳科技的论文“GigaWorld-0: World Models as Data Engine to Empower Embodied AI”。
世界模型正逐渐成为可扩展、数据高效的具身智能的基础范式。本文提出 GigaWorld-0,一个统一的世界模型框架,专门设计为视觉-语言-动作 (VLA) 学习的数据引擎。GigaWorld-0 集成两个协同组件:GigaWorld-0-Video 和 GigaWorld-0-3D。GigaWorld-0-Video 利用大规模视频生成技术,在对外观、摄像机视角和动作语义进行精细控制的前提下,生成多样化、纹理丰富且时间连贯的具身序列;GigaWorld-0-3D 则结合 3D 生成建模、3D 高斯溅射重建、物理可微分系统辨识和可执行运动规划,以确保几何一致性和物理真实性。它们的联合优化能够实现可扩展的具身交互数据合成,这些数据在视觉上引人入胜、空间上连贯、物理上合理且与指令一致。高效的 GigaTrain 框架使得大规模训练成为可能。该框架利用 FP8 精度和稀疏注意机制,大幅降低内存和计算需求。全面的评估结果表明 GigaWorld-0 能够生成高质量、多样化且可控的多维度数据。
GigaWorld-0-Video
用于具身场景视频生成的基础模型必须对这类环境有深刻的理解,并能够根据各种控制信号高效地合成逼真的具身交互视频。与现有视频生成模型(Agarwal et al., 2025; Kong et al., 2024; Wang et al., 2025; Yang et al., 2024; Zheng et al., 2024)主要通过扩展模型参数来实现不同,GigaWorld-0-Video 系列模型通过结合稀疏注意机制、混合专家(MoE)架构、FP8精度训练和推理以及扩散步骤蒸馏,实现更低的训练成本和更短的推理延迟。
GigaWorld-0-Video-Dreamer
模型详情。GigaWorld-0-Video-Dreamer 是基础视频生成模型,能够实现IT2V 生成。其整体架构如图所示。其采用流匹配(Lipman,2022)公式来建模生成过程: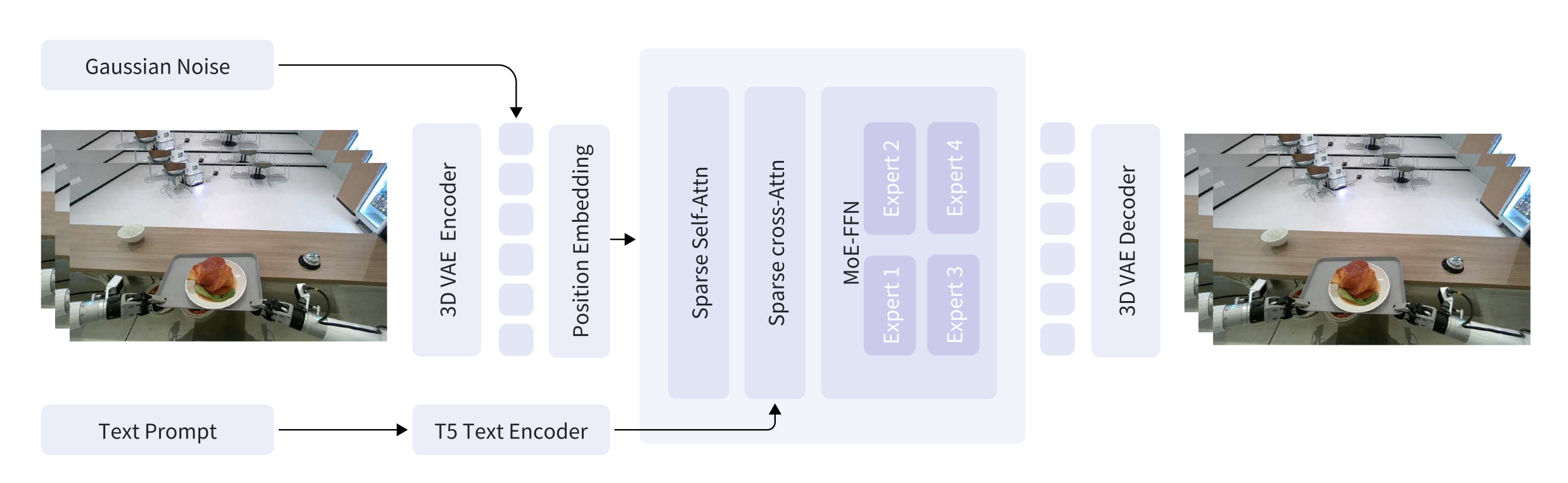
𝑑z_𝑡/dt = v_𝜃(z_𝑡, 𝑡, c), (1)
其中 z_𝑡 表示时间 𝑡 的潜特征,c 表示文本和图像条件,v_𝜃 是由模型参数化的速度。对于输入表示,采用 3D-VAE 架构(Wang,2025)高效地将原始视频压缩成潜特征,时空压缩比为 4、8、8(时间、高度、宽度),从而得到 16 通道的视频潜特征。在此表示之上,应用相同的 1 × 2 × 2 patch化策略来进一步压缩潜特征。用三维旋转位置嵌入(3D-RoPE)(Su,2023)对这些潜信息进行编码。对于文本条件化,利用 T5 编码器(Raffel,2020)提取文本嵌入。GigaWorld-0-Video-Dreamer 的核心生成主干网络是一个基于稀疏注意机制的 DiT(Hassani,2023)。此外,将混合专家(MoE)架构(Liu,2024)融入到 DiT 的前馈网络(FFN)模块中。令 𝑢_𝑡 表示第 𝑡 个token的 FFN 输入,计算 FFN 输出 h′_𝑡: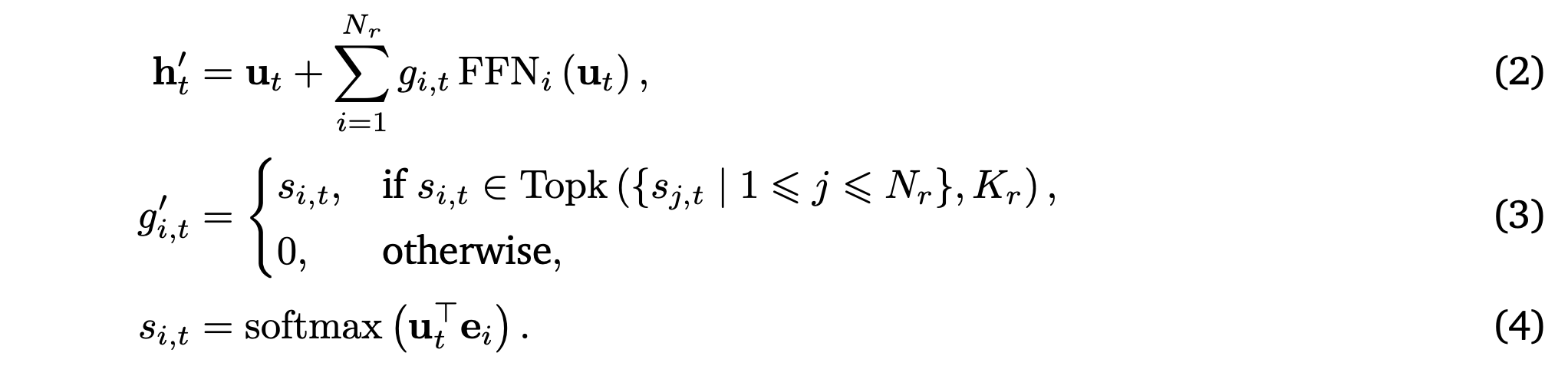
具体而言,与 DeepSeek-V2(Liu,2024)不同,没有引入共享专家。相反,配置 𝑁_𝑟 = 4 个路由专家,并为每个 token 激活 𝐾_𝑟 = 2 个专家。这种设计使得专家能够在视频的不同语义区域之间动态地进行专业化,而无需冗余的参数共享。e_𝑖 是第 𝑖 个路由专家的可学习向量。此外,为了确保 MoE 的负载均衡,采用来自 DeepSeek-V3 (Liu et al., 2024) 的补充均衡损失: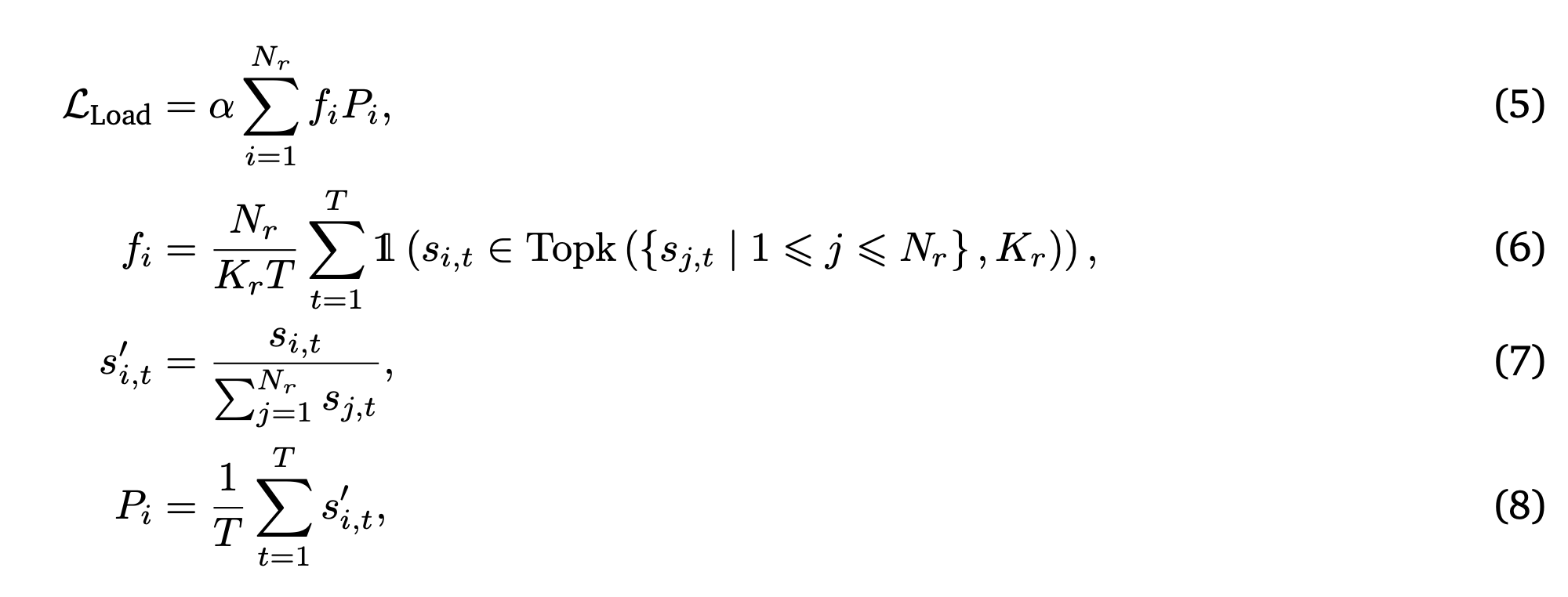
均衡损失旨在使每个序列上的专家负载保持均衡。
作为数据引擎函数。GigaWorld-0-Video-Dreamer 可作为训练下游可控视频生成系统的通用基础模型。此外,它还可作为训练 VLA 模型的强大数据引擎。GigaWorld-0-Video-Dreamer 可以在相同的初始帧条件下,根据不同的文本提示生成不同的未来视频。然后,训练一个逆动力学模型 GigaWorld-0-IDM,以从这些生成的视频中推断相应的机械臂动作。具体来说,给定一个生成的视频序列 V = {v_1 , v_2 , . . . , v_𝑇 },其中 v_𝑡 表示时间 𝑡 的 RGB 帧,GigaWorld-0-IDM 估计关节角度轨迹:
𝜃_1:𝑇 =𝑓_IDM(V), (9)
其中 𝜃_t = [𝜃(1)_t, 𝜃(2)_t, . . . , 𝜃(𝐷)_t]⊤ 表示机械臂所有 𝐷 个关节在时间步 𝑡 的旋转角度。与之前的IDM(Tan,2025)不同,GigaWorld-0-IDM采用掩码训练。具体来说,使用(Ravi,2024)的方法从输入视频中分割出机械臂,并在训练过程中仅将分割后的机械臂区域输入到IDM中,从而降低杂乱背景对预测精度的不利影响。该策略显著提高模型在真实世界视觉模糊情况下的鲁棒性和预测精度。如图所示,收集来自未见过的任务的操作数据进行评估。GigaWorld-0-IDM成功推断出与真实轨迹高度吻合的动作序列,准确预测所有12个机械臂关节和2个夹爪自由度的状态。由此生成的视频和预测动作的配对数据集(V,𝜃_1:𝑇)为训练VLA模型提供丰富、多样且时间上一致的监督信息,而无需进行真实世界的机器人交互。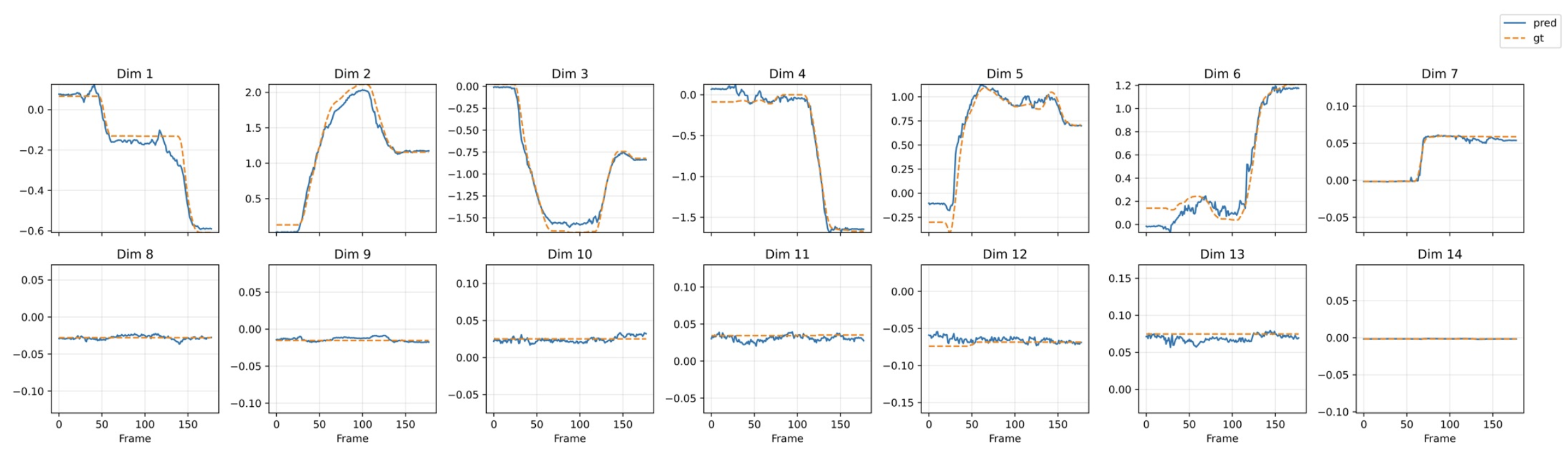
GigaWorld-0-Video-AppearanceTransfer
用于训练 VLA 模型的真实世界数据通常存在纹理、颜色和光照条件多样性不足的问题。这种局限性会降低训练模型在复杂、视觉丰富的真实世界环境中的鲁棒性。虽然传统的仿真流程可以生成大量具有多样化纹理、颜色和光照的数据,但渲染后的外观仍然存在显著的仿真到现实差距,导致实际机器人部署的成功率较低。为了应对这一挑战,提出 GigaWorld-0-Video-AppearanceTransfer,这是一个高效的框架,它支持通过文本驱动的方式修改真实世界视频的外观,并促进从仿真到现实的风格迁移,从而缩小仿真到现实的差距。
模型详情。GigaWorld-0-Video-AppearanceTransfer 允许用户使用自然语言提示对真实世界视频序列中的纹理、材质和光照进行可控编辑,同时保持几何和运动的一致性。具体来说,GigaWorld-0-Video-AppearanceTransfer 构建于预训练的 GigaWorld-0-Video-Dreamer 模型之上,并扩展一个轻量级的控制分支。如图所示,没有使用 ControlNet(Zhang,2023),因为它参数开销过大,尤其是在基础模型采用 MoE 架构时,复制 MoE 层会显著增加模型规模。因此,引入一种参数效率更高的控制机制。对于多个视频条件(例如深度、表面法线),首先使用 3D VAE(Wang,2025)提取它们的潜表示。然后,将这些控制潜表示与扩散过程中使用的噪声潜表示按通道连接起来。组合后的张量经过一系列通道压缩的 MLP 层,生成后续 Transformer 模块的最终潜输入。这种设计显著减少参数数量,同时保持对各种视频条件的灵活性。为了实现外观控制,利用文本提示独立操控前景和背景属性,例如纹理、材质和光照。为了获取几何先验信息,用 VideoDepthAnything (Chen et al., 2025) 和 LOTUS (He et al., 2024) 从真实世界或模拟视频中提取深度图和法线图。这些图经过归一化处理,重复生成三通道输入,然后按照 (Dong et al., 2025; Liu et al., 2025) 中的方法,由 3D VAE 进行编码。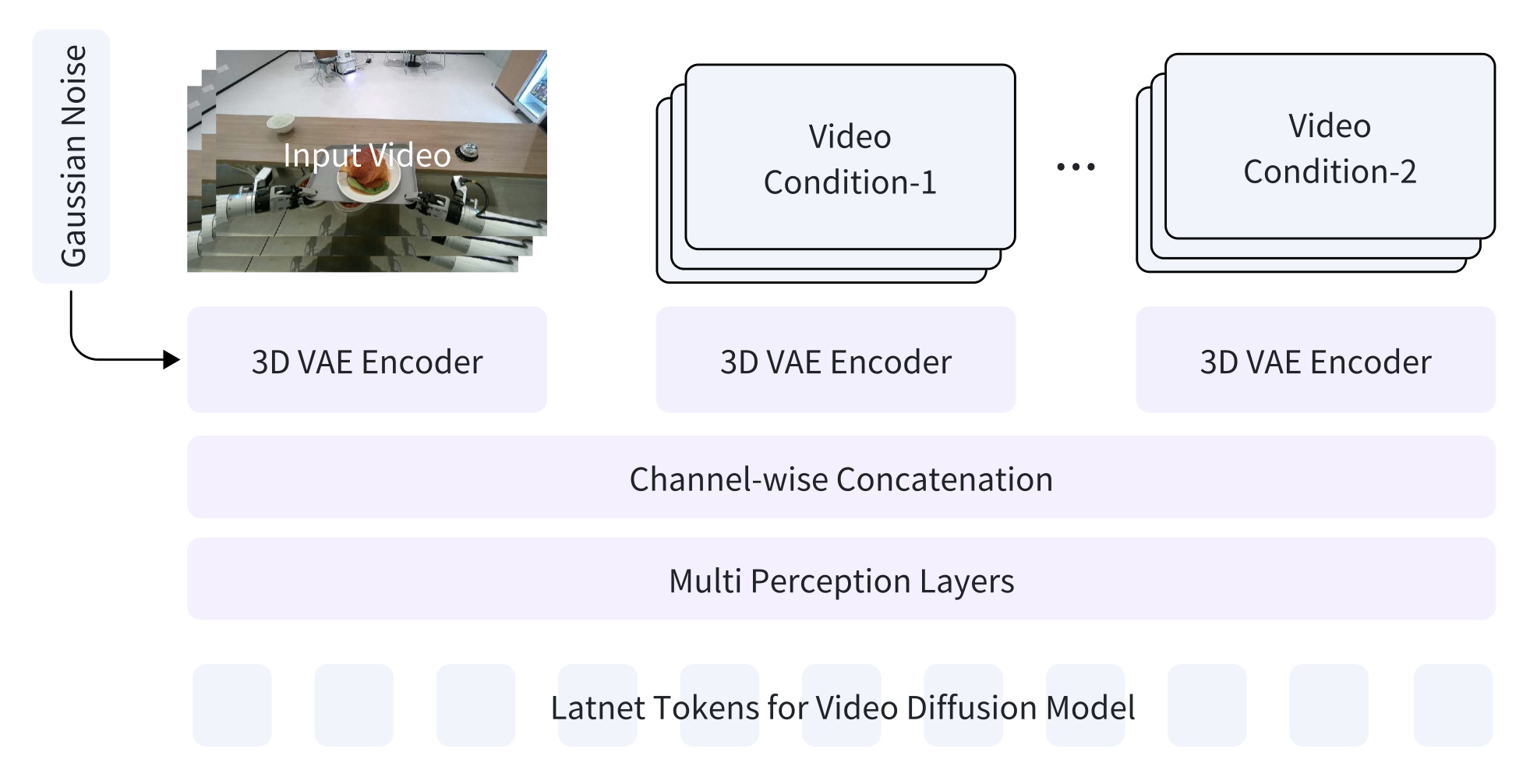
作为数据引擎函数。GigaWorld-0-Video-AppearanceTransfer 作为一个强大的数据引擎,能够实现多样化的视觉泛化。该模型支持真实-到-真实 (real2real) 和模拟-到-真实 (sim2real) 的外观迁移:给定一个真实世界的具身交互视频或一段模拟轨迹,该模型可以通过文本提示,合成具有用户指定的纹理、颜色和光照条件的逼真变体。这种能力使得大规模生成视觉多样化的训练数据成为可能,而无需额外的真实世界数据采集或昂贵的模拟渲染。在生成的数据集上训练的 VLA 模型在外观变化方面表现出显著增强的鲁棒性。
GigaWorld-0-Video-ViewTransfer
除了外观泛化之外,视角泛化仍然是VLA模型面临的一项关键挑战。基于视角A采集的数据训练的模型通常无法泛化到视角B。虽然多视角数据采集可以缓解这个问题,但它会带来高昂的实际标注和运维成本。为了解决这个问题,提出GigaWorld-0-Video-ViewTransfer框架,该框架从现有的单视角机器人交互视频中合成各种新的视角,同时转换相关的机器人动作以保持任务一致性。
模型详情。形式上,考虑一个在世界坐标系𝒲_𝐴中运行的机器人,它采集一个以机器人自身为中心的视频V_A,以及一系列相对于机器人基座的末端执行器位姿 {Tee→base_t} 目标是合成一个新的观测值 V_𝐵,如同从不同的世界坐标系 𝒲_𝐵 中捕获一样,其中机器人基座已重定位(即 Tbase_𝒲𝐴 →𝒲𝐵 ̸= I)。关键在于,世界坐标系中末端执行器的绝对位姿必须保持不变,以保持任务语义:
Tee→𝒲_t = Tbase→𝒲𝐴_t · Tee→base_t = Tbase→𝒲𝐵_t · K_t, (10)
其中 K_𝑡 表示末端执行器相对于重定位的基座在 𝒲_𝐵 中的新位姿。求解 K_t 得到:
K_t = (︁ Tbase→𝒲𝐵 )︁−1 ·Tbase→𝒲𝐴·Tee→base_t. (11)
合成视频 𝐵 必须与新摄像机视角和变换后的动作序列 K = {K_t} 保持一致。
GigaWorld-0-Video-ViewTransfer 基于预训练的 GigaWorld-0-Video-Dreamer,通过训练后自适应构建,并具有双条件控制分支(如上图所示)。为了确保视角变化下的 3D 一致性,将控制信号分解为两个分量:(i)背景 3D 一致性,通过视频条件 1 强制执行;(ii)机械臂 3D 一致性,通过视频条件 2 强制执行。由于无法获得成对的多视角真实世界视频(V_A,V_B),采用双重重投影策略(Xu et al., 2025)构建自监督训练对。对于视频条件-1,首先使用MoGe(Wang et al., 2025)估计𝒲_𝐴中的缩放深度,然后将V_A扭曲到目标视角𝒲_B,最后将其重投影回原始视角。重投影后的视频作为输入条件,而原始V_A作为真实值。为了将场景几何与移动机器人隔离,在扭曲过程中对机械臂进行掩码(Ravi et al., 2024)。对于视频条件-2,用物理感知模拟器(Xiang,2020)渲染变换后的动作序列 K,生成仅包含手臂的视频,该视频反映 𝒲_𝐵 中的正确姿态和运动学。该渲染序列为手臂运动的一致性提供明确的 3D 指导。模型经过训练,能够生成基于视频条件-1(新视角下的背景几何形状)和视频条件-2(变换后的运动学下手臂姿态)的真实视频 V_A。更多实现细节遵循类似的框架(Xu,2025)。
作为数据引擎函数。训练完成后,GigaWorld-0-Video-ViewTransfer 可作为可扩展的视点增强引擎。给定一段真实世界的交互视频,该方法可以从任意新视角生成逼真的观测结果,并伴随几何一致的机器人动作 K。这使得无需额外收集真实世界数据,即可通过各种以自我为中心的视角大幅扩展有效数据集。基于此增强数据训练的 VLA 模型在部署过程中对视角转换表现出显著增强的鲁棒性,从而弥合仿真和真实世界泛化之间的关键差距。
GigaWorld-0-Video-MimicTransfer
通过远程操作收集真实世界的机器人数据成本高昂。一种更高效的替代方法是利用第一人称视角的演示视频。然而,第一人称视角的人类演示视频与实际机器人执行视频之间存在显著差异,最突出的是人手和机械臂的外观差异。为了解决这个问题,提出 GigaWorld-0-Video-MimicTransfer 方法,该方法将第一人称视角的人手操作视频转换为机械臂操作视频,从而缩小上述外观差异,并提高以自我为中心的操作数据的可用性。
模型详情。GigaWorld-0-Video-MimicTransfer 是一个基于 GigaWorld-0-Video-Dreamer 的后训练模型,其控制分支如上图所示。在训练过程中,由于同时包含人手和机械臂操作的对齐视频对较少,仅使用机械臂操作视频构建训练数据。具体而言,采用两种视频条件:视频条件-1 控制操作场景,而视频条件-2 则强制机械臂的运动模仿人手的运动。为了生成视频条件-1,从原始操作视频中遮盖掉机械臂,仅保留背景。对于视频条件-2,使用原始机械臂的运动轨迹驱动一个模拟机械臂,生成一个模拟人手操作的合成视频。该模型经过训练,能够根据这两种条件重建原始(未掩码)的机械臂操作视频。其他训练细节和数据构建过程参见 (Li et al., 2025)。
作为数据引擎函数。训练完成后,GigaWorld-0-Video-MimicTransfer 可以作为数据引擎,将第一人称视角的人体演示视频转换为机械臂操作视频。具体而言,从输入视频中掩码人手作为视频条件-1,从而保留场景上下文。同时,利用标注的人手末端执行器姿态,通过逆运动学(IK)求解机械臂相应的关节角度,并在模拟器中渲染得到的机械臂姿态,生成视频条件-2。基于这两个输入,该模型合成一个逼真的机械臂操作视频,该视频能够模拟原始的人类动作,从而实现可扩展且经济高效的机器人学习数据增强。
此外,为了更好地支持具身操作场景,GigaWorld-0-Video 集成多视角视频生成和生成加速技术。对于多视角合成,借鉴近期的一些方法(Dong et al., 2025; Liu et al., 2025; Zhao et al., 2025),将多个视角的图像沿宽度方向拼接成一个全景输入。该设计保留原始扩散模型架构,并利用上下文学习能力:在少量多视角数据上进行微调后,该模型无需架构修改即可生成跨多个视角的时空一致的视频。生成的输出表现出很强的跨视角一致性,使其适用于训练需要以自我为中心和第三人称视角观察的视觉系统。为了加速视频生成,GigaWorld-0-Video 采用去噪步骤蒸馏(Yin,2024),将采样过程从数十步简化为一步。结合 FP8 精度的推理,这些优化相比标准扩散模型实现50 倍以上的加速,从而能够在部署时实现可扩展的数据生成。尽管取得这些进展,生成的视频仍然可能包含幻觉或伪影,这可能会影响下游策略的学习。为确保数据质量,GigaWorld-0-Video 引入一套全面的评估流程,从多个维度评估每个视频:几何一致性、多视角连贯性(Liu,2025)、文本-到-视频的对齐(Azzolini,2025)以及物理合理性(Azzolini,2025)。系统会为每个序列计算一个综合质量评分,以确定其是否适合预训练、微调或剔除。
GigaWorld-0-3D
GigaWorld-0-Video 利用视频生成模型合成纹理丰富的具身场景数据,但高质量的具身操作也需要强大的几何一致性和物理精度。为了满足这些要求,GigaWorld-0-3D 采用 3D 高斯溅射 (3DGS) (Kerbl,2023) 作为其核心场景表示,从而能够构建空间连贯且物理基础扎实的 3D 环境。
GigaWorld-0-3D-FG
传统的 3DGS 重建流程通常需要密集的多视图输入才能生成高保真度的模型。然而,近年来生成式建模技术的进步(Feng et al., 2025; Xiang et al., 2025; Yang et al., 2024; Zhang et al., 2024; Zhao et al., 2025)使得从极其稀疏的输入(例如单张图像甚至文本提示)进行目标-级三维重建成为可能。Trellis (Xiang et al., 2025) & Hunyuan3D (Yang et al., 2024,Zhao et al., 2025)是这方面的典型代表。尽管 Trellis 具有强大的几何建模能力,但它也存在一些缺陷,限制其在具身人工智能场景中的应用:生成的纹理通常视觉保真度较差,尤其是由于镜面高光过饱和,导致烘焙到网格上时出现不自然的泛白现象。此外,生成的模型纯粹是视觉构造,缺乏真实世界的比例、物理上合理的几何形状或材质属性,因此与基于物理的模拟器不兼容(Mittal et al., 2023; Todorov et al., 2012; Xiang et al., 2020)。
为了弥补这一差距,GigaWorld-0-3D-FG 通过严格的数据管理提升模型质量,而其后续模块 GigaWorld-0-3D-Phys 则赋予模型适用于模拟的物理语义。如图所示,GigaWorld-0-3D-FG 流程可接受真实世界照片或通过文本到图像模型生成的合成图像。在生成 3D 模型之前,自动化预处理阶段会对输入进行质量控制。具体而言,采用一个基于 Aesthetic-Checker(Ma et al., 2025)的美学评估模块,该模块与纹理丰富度呈正相关。鉴于前景分割精度对 3D 输出质量至关重要,引入基于 GPT-4o 的图像分割检查器 (ImageSegChecker) 来评估分割可靠性。为了确保系统在不同对象类别上的鲁棒性,集成三个分割后端(AI., 2025; Gatis, 2025; Ravi et al., 2024)。如果图像分割检查器检测到分割失败,流程将触发重试,方式包括提示用户拍摄新图像或使用其他文本到图像模型重新生成输入。
对于图像-到- 3D 的转换,采用开源生成模型,以便与未来的社区发展无缝集成。在众多可用模型中,选择 Trellis(Xiang et al., 2025),因为它具有卓越的几何一致性,并且同时支持网格和 3DGS 表示。生成完成后,一个名为 MeshGeoChecker 的后处理检测模块会从四个正交视角渲染模型,以评估其几何完整性和合理性。只有通过所有质量检测的模型才会以 URDF 格式导出并存档;任何检测环节失败的模型都会自动使用修改后的参数和随机种子重新提交到相应的生成步骤进行重新合成。更多实现细节,包括纹理烘焙策略,参见 (Wang et al., 2025)。
GigaWorld-0-3D-BG
3DGS(Kerbl,2023)已成为一种成熟的场景重建技术。传统的 3DGS 依赖于椭圆加权平均 (EWA) 投影,它通过雅可比矩阵计算来近似投影,并且仅限于针孔相机模型。相比之下,3DGRUT(Wu,2025)通过将每个 3D 高斯函数与七个代表点(一个中心点和六个边界点)关联起来,增强相机兼容性,从而能够精确建模非针孔相机,例如常用于具身人工智能场景的卷帘快门相机。这使得此类场景下的重建保真度更高。
然而,传统的 3DGS 通常需要密集的多视图输入才能实现高质量的重建,而这在现实世界的具身环境中往往难以实现。为了克服这一局限性,借鉴近期一些生成式方法(Ni et al., 2024; Wu et al., 2025; Zhao et al., 2024, 2025),这些方法通过合成新视角来丰富稀疏观测数据。GigaWorld-0-3D-BG流程以稀疏视角输入为起点,并采用3DGRUT进行初始场景重建。然而,在稀疏视角条件下,新视角合成(NVS)常常会受到几何和光度伪影的影响。
为了缓解这一问题,采用一种受(Ni et al., 2024)启发的视角复原策略,训练一个专门的视角细化模型来生成合理的中间视角。细化后的视角显著减少伪影,并提供密集且一致的视觉观测数据。这些合成的视角随后作为增强输入,用于第二阶段的密集3DGS重建,从而得到高保真度的背景高斯表示。最后,使用泊松曲面重建将生成的密集高斯斑点转换为水密网格,从而生成逼真且几何一致的背景资源,适用于具身操作场景。
GigaWorld-0-3D-Phys
虽然 GigaWorld-0-3D-FG 和 GigaWorld-0-3D-BG 使用 3DGS 和网格表示构建前景和背景资源,但这些资源缺乏交互式仿真所需的物理属性。为了实现基于物理的交互,GigaWorld-0-3D-Phys 为机器人智体和被操作目标赋予了真实的物理属性。
对于机械臂而言,精确的物理参数(例如关节摩擦力和 PD 控制器增益)至关重要,但在实践中却很难测量。传统的系统辨识方法(例如手动调整或模拟退火算法 (Li et al., 2024))速度慢且耗时。相比之下,GigaWorld-0-3D-Phys 利用基于物理信息神经网络 (PINN) 的可微分物理框架,实现高效的基于梯度的参数估计。如图所示,该流程分三个阶段运行:(1) 将真实世界的轨迹 (a_𝑡−1, s_𝑡−1) 与随机采样的物理参数 (𝑓, 𝑝, 𝑑) 配对,这些参数分别表示摩擦力、刚度和阻尼,并用于生成模拟展开轨迹。(2) 训练一个智体模型 M_𝑓,𝑝,𝑑,通过最小化预测的下一状态与模拟的下一状态之间的均方误差 (MSE) 来近似模拟器的动力学,从而得到一个可微的动力学模型。(3) 在智体模型固定的情况下,通过梯度下降法优化物理参数,以最小化模拟轨迹与真实轨迹之间的差异,最终收敛到一组最优参数 (𝑓*,𝑝*,𝑑*),该参数能够精确地复现真实世界的行为。更多细节请参见 (Wang et al., 2025)。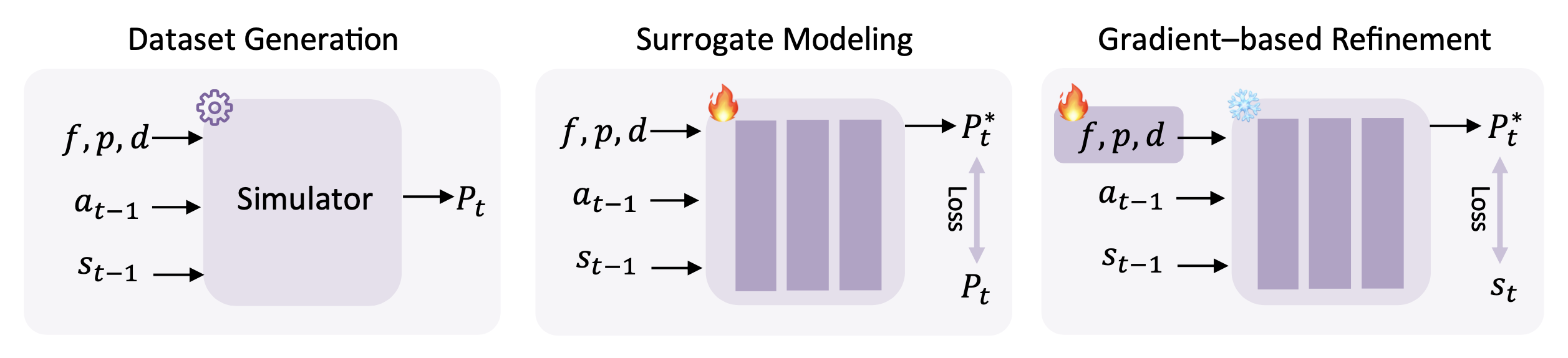
对于可操控物体,采用基于 Qwen3-VL (Team, 2025) 构建的多模态物理专家智体,该智体能够从渲染的正交视图中推断物理属性。该智体首先通过分析文本引导约束下的正面视图来估计物体的真实尺寸,从而消除物体尺寸的歧义。缩放完成后,它会预测质量、摩擦系数和其他物理属性,并将它们与语义类别关联起来以供后续使用,更多实现细节参见 (Wang et al., 2025)。
对于可变形体,借鉴 PhysTwin (Jiang et al., 2025) 的思路,通过将弹簧-质量系统绑定到高斯粒子来扩展 3DGS 表示。然而,与 PhysTwin 的逐场景优化不同,探索一种前馈方法,该方法直接从单目视频推断弹簧质量参数,从而实现快速、通用的软体模拟。
GigaWorld-0-3D-Act
尽管业界已开发出众多基于仿真的自动动作生成方法,实现任务执行和机器人操作数据集的大规模扩展,但这些方法通常缺乏对复杂场景的适应性或对新物体配置的泛化能力。为了解决这个问题,GigaWorld-0-3D-Act 引入一个两级动作生成流程,该流程可同时适用于简单和复杂的操作场景,如图所示。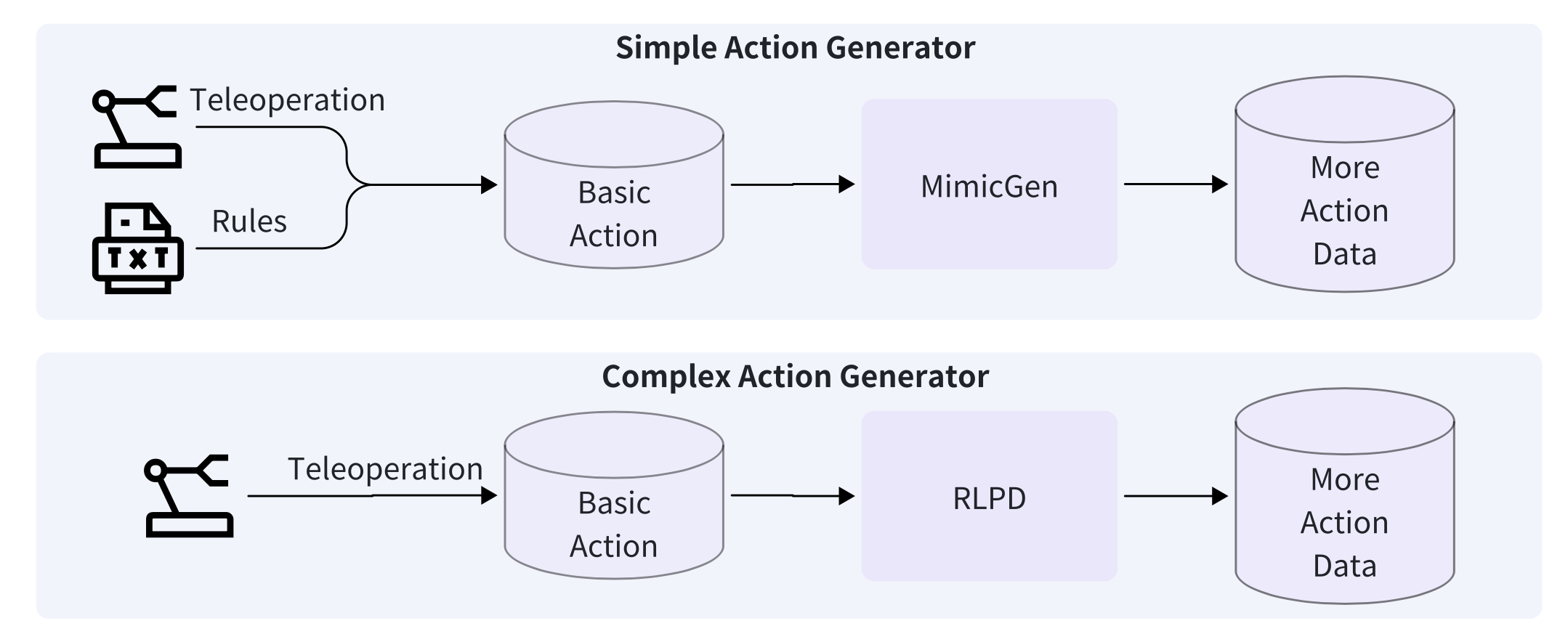
对于简单场景,GigaWorld-0-3D-Act 首先通过远程操作或基于规则的策略(Chen,2025)获取少量基础演示。然后,使用 MimicGen 框架(Mandlekar,2023)将这些初始轨迹系统地扩展到新物体姿态和场景布局,从而在无需额外人工干预的情况下实现可扩展且几何一致的动作增强。
对于涉及多步骤推理或接触丰富的交互的复杂场景,GigaWorld-0-3D-Act 利用远程操作演示作为强化学习的冷启动数据。然后,它采用快速在线强化学习(例如 RLPD (Ball,2023))来快速启动策略训练。一旦收敛,学习的策略将被部署以生成大规模、物理上合理且多样化的操作轨迹,从而有效地将高层任务结构与低层运动控制连接起来。
作为数据引擎函数
GigaWorld-0-3D 模型套件作为一个整体流程集成后,能够构建几何一致且物理上真实的具身操作场景,这些场景可作为 VLA 模型的高质量训练数据。具体而言,GigaWorld-0-3D-FG 和 GigaWorld-0-3D-BG 分别生成互补表示形式的前景和背景资源:3DGS 用于照片级真实感渲染,网格用于精确的碰撞检测、动力学模拟和物理交互。GigaWorld-0-3D-Phys 随后赋予机器人机械臂和场景目标物理属性(例如质量、摩擦力、弹性),并执行可微系统辨识以校准驱动动力学。最后,GigaWorld-0-3D-Act 合成可执行的、无碰撞的操作轨迹,以完成用户指定的任务。生成的渲染数据可直接用于端到端的 VLA 训练。为了进一步增强数据多样性,集成 GigaWorld-0-Video-AppearanceTransfer,用于对渲染场景中的纹理、颜色、材质和光照进行文本引导式编辑。这实现零样本域扩展,同时保持几何和物理一致性,从而在无需创建额外 3D 资源的情况下,显著提升训练分布的视觉和上下文丰富度。
训练数据结合公开数据集和从自己机器人平台收集的专有数据。公开数据集包括 AgiBotWorld (Bu et al., 2025) 和 RoboMind (Wu et al., 2024),它们提供操作和运动任务的基础数据。此外,用 Agilex Cobot Magic 和 AgiBot G1 平台,在总面积达 3100 平方米的区域内收集数千小时的专有数据,涵盖五大环境类别:工业、商业、办公、住宅和实验室环境。这些环境类别进一步细分为 14 个不同的真实场景,包括超市、酒店大堂、咖啡店、奶茶店、便利店、餐厅、仓库物料搬运区、工业装配线、食品储藏室、私人住宅、公寓室内、会议室、办公工作站和实验室。收集的任务范围从基本的取放操作到长时程序列活动,移动训练视频基础模型的计算量很大。为了实现高效且经济的训练,GigaWorld-0-Video-Dreamer 采用稀疏注意机制和 FP8 精度训练。此外,由于大多数当代 VLA 模型(Black,2024;GigaAI,2025;Intelligence,2025)都使用 480p 输入,因此以 480×768 的分辨率训练 61 帧序列的模型,从而在视觉保真度和训练效率之间取得平衡。
训练基础设施 GigaTrain(GigaAI,2025)是一个统一的分布式框架,旨在实现可扩展性和灵活性。它支持无缝的多 GPU/多节点执行,并集成领先的大模型训练策略,包括:
• 分布式框架:DeepSpeed ZeRO(阶段 0-3)、FSDP2;
• 混合精度训练(FP16、BF16、FP8);
• 梯度累积、梯度检查点和指数移动平均 (EMA);
• 可配置的优化器、学习率调度器和其他训练模块。
这种设计既支持大规模预训练,也支持资源受限的后训练(例如,在计算资源有限的情况下进行微调)。为了便于社区采用,报告在适中硬件配置(例如,8 个 H20 GPU,批大小为 32)下各种后训练配置的资源消耗。
在分布式训练框架中,FSDP-2 的内存效率最高,其次是 DeepSpeed ZeRO-2,最后是 ZeRO-0。然而,更强的内存优化是以增加通信开销和略微延长每步延迟为代价的。在所有框架中,使用 FP8 精度都能持续降低内存消耗和训练时间,证明其在可扩展视频基础模型训练方面的有效性。为了提高注意效率,采用 NATTEN(Hassani,2023)作为稀疏注意算子,因为它比 SageAttention(Zhang,2024)具有更高的加速比。尽管如此,在缺乏自适应的情况下,它仍需要进行微调以避免性能下降。最后,当扩展到4-专家 MoE 架构时,增加的参数量需要应用激活检查点机制,尤其是在前馈网络上,以在训练过程中保持合理的内存使用,从而在硬件资源受限的情况下实现稳定的收敛。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献215条内容
已为社区贡献215条内容

所有评论(0)