交大发布RadFM:全球首个放射科通用大模型 ,同时处理2D/3D医学图像,性能超越GPT-4V
面向放射学的通用基础模型 RadFM,通过构建包含1600万2D与3D医学图像的大规模多模态数据集 MedMD,设计支持视觉条件生成的统一架构,并建立综合评价基准 RadBench,显著提升了模型在多种放射学任务上的性能。
一、导读
当前医学人工智能领域在构建通用基础模型方面面临三大挑战:缺乏大规模多模态医学数据集、缺乏统一处理多种医学任务的架构、缺乏全面评估基准。本文针对这些挑战,首次提出了一个面向放射学的通用基础模型 RadFM,通过构建包含1600万2D与3D医学图像的大规模多模态数据集 MedMD,设计支持视觉条件生成的统一架构,并建立综合评价基准 RadBench,显著提升了模型在多种放射学任务上的性能。
该研究在模型架构上首次实现了对2D与3D医学图像的统一处理,并在多项任务中超越了包括GPT-4V在内的现有公开模型,为医学多模态基础模型的发展奠定了重要基础。
二、论文基本信息

-
论文标题:Towards Generalist Foundation Model for Radiology by Leveraging Web-scale 2D&3D Medical Data
-
作者与单位:Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, Weidi Xie;上海交通大学 & 上海人工智能实验室
-
发表日期与平台:2023年,发布于arXiv
-
论文链接:arXiv:2308.02463v5
原文、这里 还有各种籽、料👉交大发布RadFM:全球首个放射科通用大模型 ,同时处理2D/3D医学图像,性能超越GPT-4V
三、摘要精炼
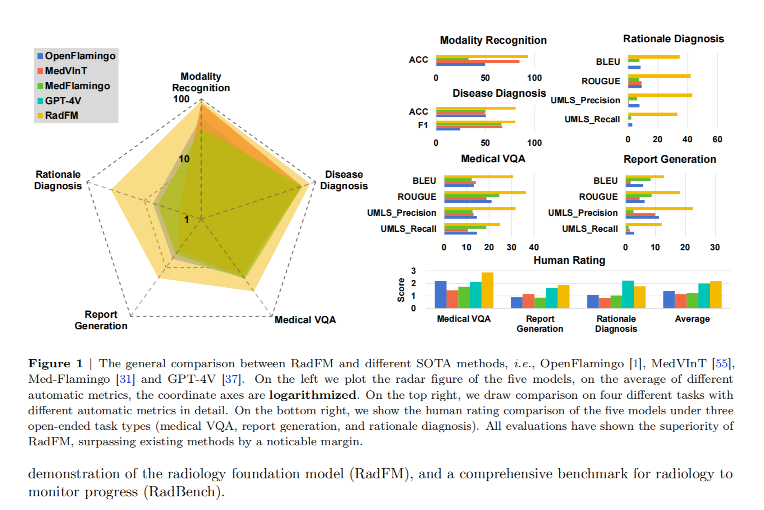
本文旨在构建一个面向放射学的通用基础模型RadFM,其核心贡献包括:构建了包含1600万2D与3D医学图像的大规模多模态数据集MedMD;提出了一种支持视觉条件生成的统一架构,能够处理2D与3D图像并生成自然语言响应;建立了包含五项任务的综合评价基准RadBench。实验表明,RadFM在RadBench上显著优于OpenFlamingo、MedVInT、Med-Flamingo和GPT-4V等公开模型,例如在疾病诊断任务中准确率达到80.62%,在医学视觉问答任务中UMLS_Precision提升至31.77%。此外,RadFM在多个公共基准测试中也取得了最优性能。
四、研究背景与相关工作
近年来,通用基础模型在自然语言处理与计算机视觉领域取得了显著成功,然而在医学领域,尤其是放射学中,其发展仍面临三大挑战:缺乏大规模、多模态、高质量的医学数据集;缺乏能够统一处理多种医学任务的通用架构;缺乏全面、专业的评估基准。
现有研究如MedVInT、Med-Flamingo等大多仅支持2D图像,且任务范围有限,难以满足真实临床需求。本文在此基础上,首次构建了包含2D与3D图像的大规模数据集MedMD,提出了支持多图像输入、多任务统一的生成式架构RadFM,并建立了综合评价基准RadBench,显著推动了医学基础模型的发展。
五、主要贡献与创新
-
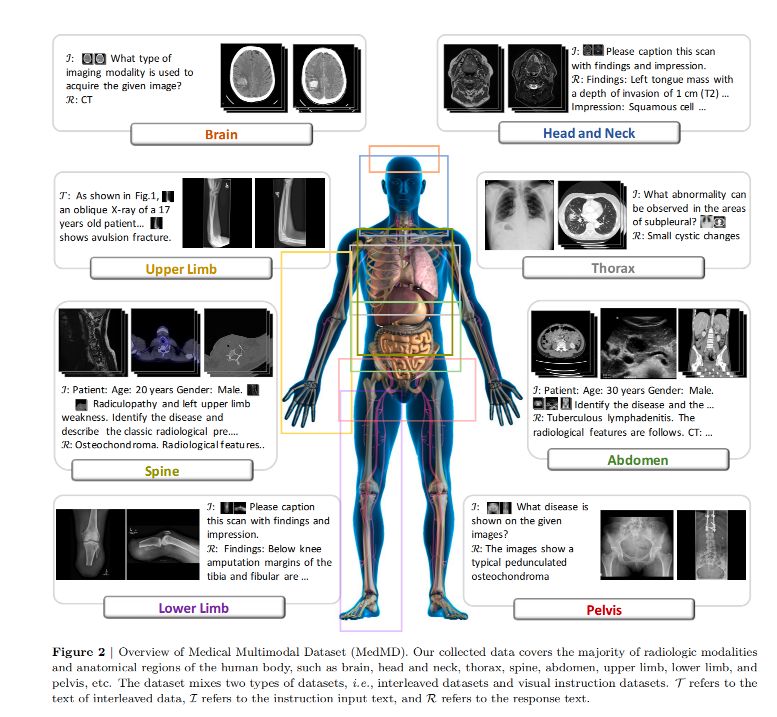
构建大规模多模态医学数据集MedMD:包含1600万2D与3D医学图像,涵盖17个解剖系统和5000多种疾病,首次实现了2D与3D图像的统一标注。
-
提出统一生成式架构RadFM:基于视觉编码器、感知器模块和大语言模型,支持2D与3D图像的多图像输入与自然语言生成,参数规模达140亿。
-
建立综合评价基准RadBench:包含模态识别、疾病诊断、视觉问答、报告生成和诊断归因五项任务,共涵盖13个数据集,并引入UMLS_Precision与UMLS_Recall等医学专用评价指标。
-
在多项任务中显著超越现有模型:在RadBench上,RadFM在疾病诊断任务中准确率达80.62%,在视觉问答任务中UMLS_Precision提升至31.77%,在人类评价中也优于GPT-4V。
六、研究方法与原理
统一学习范式
RadFM采用生成式建模方法,将每个训练样本表示为 ,其中 为文本部分, 为图像集合。模型目标为最大化条件概率:
$$p(\mathcal{T}|\mathcal{V}) = \prod p(\mathcal{T}_l | \mathcal{V}_{<l}, \mathcal{t}_{<l})="" $$=""
训练目标为负对数似然:$$\mathcal{L}_{\text{reg}} = -\sum w_l \log \Phi_{\text{RadFM}}(\mathcal{T}_l | \mathcal{V}_{<l}, \mathcal{t}_{<l})="" $$="" 其中 为词权重,对医学关键词赋予更高权重。
模型架构
RadFM由三部分组成:
-
**视觉编码器 **:采用3D ViT,将2D图像通过深度维度扩充为3D输入,输出图像嵌入 。
-
**感知器模块 **:将变长视觉嵌入聚合为固定长度 。
-
**大语言模型 **:将视觉与文本嵌入拼接后输入,生成响应:
训练流程
-
预训练阶段:使用全部MedMD数据(1600万样本)。
-
领域微调阶段:使用RadMD数据(300万放射学样本)。
原文、这里 还有各种籽、料👉交大发布RadFM:全球首个放射科通用大模型 ,同时处理2D/3D医学图像,性能超越GPT-4V
七、实验设计与结果分析
实验设置
-
数据集:RadBench包含五项任务,共13个子数据集,总计约14.4万样本。
-
对比模型:OpenFlamingo、MedVInT、Med-Flamingo、GPT-4V。
-
评价指标:ACC、F1、BLEU、ROUGE、BERT-Sim、UMLS_Precision、UMLS_Recall。
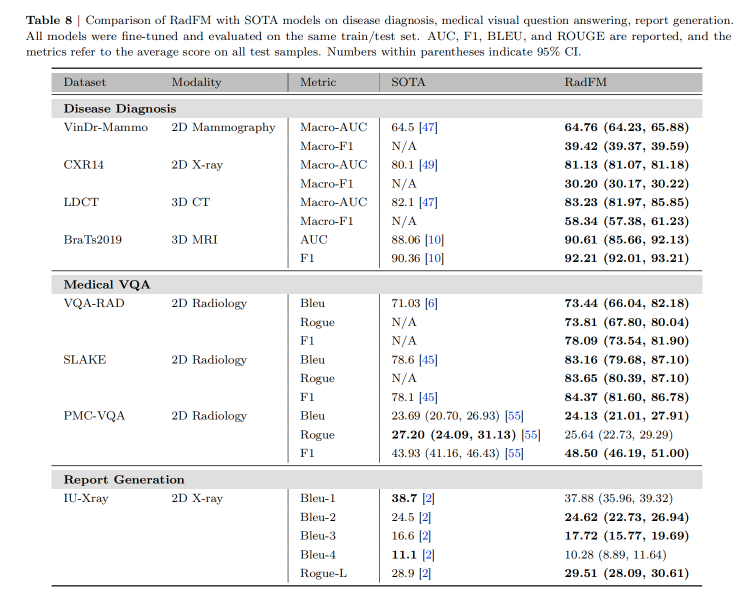
关键结果
-
模态识别:RadFM准确率达92.95%,显著优于其他模型。
-
疾病诊断:RadFM平均准确率达80.62%,F1为80.10%。
-
医学视觉问答:RadFM在UMLS_Precision上达到31.77%,BERT-Sim为67.82%。
-
报告生成:RadFM在UMLS_Precision上为22.49%,UMLS_Recall为12.07%。
-
诊断归因:RadFM在BLEU上为34.60%,ROUGE为41.89%。
-
人类评价:RadFM在VQA、报告生成和诊断归因任务中均优于GPT-4V。
局限性
-
生成长文本的准确性与完整性仍不足;
-
3D图像在训练数据中占比较低;
-
自动评价指标在医学文本上仍有局限;
-
缺乏图像间距等关键元数据;
-
模型规模大,调优成本高。
八、论文结论与启示
本文通过构建大规模数据集MedMD、提出统一架构RadFM和建立评估基准RadBench,显著推动了放射学基础模型的发展。RadFM在多项任务中表现出色,尤其是在处理2D与3D图像、多图像输入和自然语言生成方面具备明显优势。该研究为医学多模态模型的开发提供了完整的技术路线与评估标准,未来可进一步优化长文本生成能力、增加3D数据比例、开发更精准的自动评价指标,并探索模型在更多临床场景中的应用。
九、整体评价与讨论
优点
-
首次实现了对2D与3D医学图像的统一处理;
-
构建了目前最大规模的医学多模态数据集;
-
提出了支持多图像输入与自然语言生成的通用架构;
-
建立了全面、专业的评估基准RadBench;
-
在多项任务中显著优于现有公开模型。
不足与改进方向
-
生成长文本的准确性与临床可用性仍有待提升;
-
3D图像比例不足,限制了模型对三维结构的理解;
-
自动评价指标未能完全反映医学文本的语义准确性;
-
缺乏关键元数据(如图像间距)限制了某些诊断任务的精度;
-
模型规模大,训练与调优成本高,限制了可复现性与扩展性。
未来研究可着重于提升生成质量、增加3D数据、开发医学专用评价指标,并探索模型在更多临床任务中的迁移能力。
原文、这里 还有各种籽、料👉交大发布RadFM:全球首个放射科通用大模型 ,同时处理2D/3D医学图像,性能超越GPT-4V

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)