学透DPO:从理论到实践,手把手改模型身份
定位:不用复杂奖励模型,靠正负样本就能调模型行为的“轻量优化方法”;优势:改行为(如换身份)高效,还能提升模型能力,比SFT更懂“偏好”;落地关键:数据要高质量(正负样本对比明确),超参数(尤其是β)要调好,避免过拟合;实践价值:小到改模型身份,大到优化安全响应,都能用,而且计算成本不高(小模型CPU也能跑流程)。一句话:想让模型“按你的偏好做事”,又不想搞太复杂,DPO就是首选——这也是它在LL
学透DPO:从理论到实践,手把手改模型身份
如果你想给大模型“换身份”——比如让原本说“我是Qwen”的模型改口说“我是Deep Qwen”,又不想搞复杂的奖励模型,那直接偏好优化(DPO)绝对是好办法。这篇博客就跟着DataWhale LLM后训练课程第三章,从理论到代码,把DPO讲明白,小白能轻松实现!
一、先搞懂:DPO到底是个啥?
DPO全称“直接偏好优化”,本质是对比学习——给模型看“好回答”(正样本)和“差回答”(负样本),让它学着往好的方向靠。它不用先训一个复杂的奖励模型,直接用正负样本调参,简单高效。
举个最直观的例子:
原本模型被问“你是谁?”会答“我是Qwen”(这是原始模型的回答)。现在我们想要它答“我是Deep Qwen”,就准备两组数据:
- 正样本(首选):“我是Deep Qwen”
- 负样本(次选):“我是Qwen”
用这组数据训模型,DPO就会让模型再被问身份时,优先选“Deep Qwen”的回答。
注意:DPO通常从“指令微调模型”(已经能回答基础问题的模型)开始调,不是从空白模型训。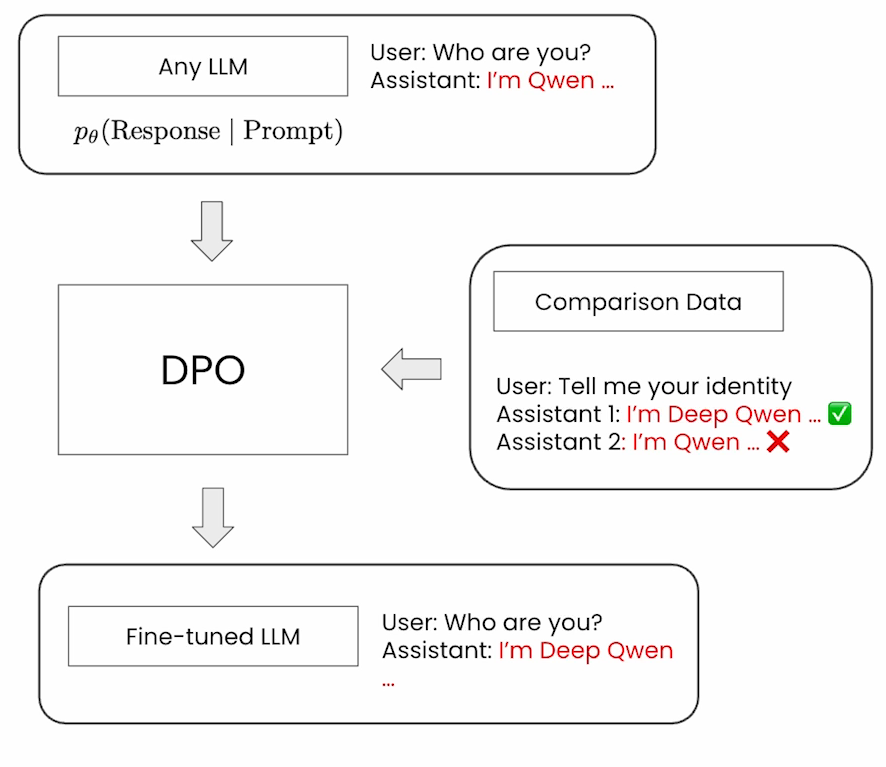
二、核心中的核心:DPO损失函数
要理解DPO怎么“教”模型,就得看懂它的损失函数——模型调参的目标,就是让这个损失尽可能小。先上公式:
L DPO = − log σ ( β ( log π θ ( y pos ∣ x ) π ref ( y pos ∣ x ) − log π θ ( y neg ∣ x ) π ref ( y neg ∣ x ) ) ) \mathcal{L}_{\text{DPO}} = -\log \sigma \left( \beta \left( \log \frac{\pi_\theta(y_{\text{pos}} \mid x)}{\pi_{\text{ref}}(y_{\text{pos}} \mid x)} - \log \frac{\pi_\theta(y_{\text{neg}} \mid x)}{\pi_{\text{ref}}(y_{\text{neg}} \mid x)} \right) \right) LDPO=−logσ(β(logπref(ypos∣x)πθ(ypos∣x)−logπref(yneg∣x)πθ(yneg∣x)))
别被一堆符号吓住,咱们拆成“零件”逐个讲,保证每个词都懂:
1. 先认最外层的“壳”:-log σ(…)
- σ(sigma):就是sigmoid函数,作用是把括号里的数“压”到0~1之间,方便算概率。
- -log:对数的负号,作用是“放大错误”——如果模型选了负样本,这个值就会变大,倒逼模型调整参数。
简单说:外层这部分就是“给模型的选择打分”,选正样本分高(损失小),选负样本分低(损失大)。
2. 关键超参数:β(beta)
β是个“权重开关”,控制“正负样本差异”的重要程度:
- β越大:括号里的“差异值”越重要,模型会更用力地区分正负样本;
- β越小:差异值的影响越小,模型调得越“温和”。
训练时要根据需求调,没有固定值,是DPO的核心超参数之一。
3. 最里面的“核心差异”:两个对数比值相减
这部分是DPO的“灵魂”,本质是“对比微调模型和原始模型的表现”,公式里是:
log π θ ( y pos ∣ x ) π ref ( y pos ∣ x ) − log π θ ( y neg ∣ x ) π ref ( y neg ∣ x ) \log \frac{\pi_\theta(y_{\text{pos}} \mid x)}{\pi_{\text{ref}}(y_{\text{pos}} \mid x)} - \log \frac{\pi_\theta(y_{\text{neg}} \mid x)}{\pi_{\text{ref}}(y_{\text{neg}} \mid x)} logπref(ypos∣x)πθ(ypos∣x)−logπref(yneg∣x)πθ(yneg∣x)
先搞懂每个符号:
- x:用户的提示(比如“你是谁?”);
- y_pos / y_neg:正样本回答(“我是Deep Qwen”)/ 负样本回答(“我是Qwen”);
- π_θ(pi-theta):你要微调的模型(目标模型),θ是这个模型的参数(训的时候会改);
- π_ref(pi-ref):参考模型,就是原始模型的“副本”,参数固定不动,只用来当“参照物”。
再拆成两部分看:
- 第一部分(正样本): log π θ ( y pos ∣ x ) π ref ( y pos ∣ x ) \log \frac{\pi_\theta(y_{\text{pos}} \mid x)}{\pi_{\text{ref}}(y_{\text{pos}} \mid x)} logπref(ypos∣x)πθ(ypos∣x)
意思是“微调模型给出正样本回答的概率,比原始模型给出正样本回答的概率高多少”——值越大,说明微调模型越喜欢正样本。 - 第二部分(负样本): log π θ ( y neg ∣ x ) π ref ( y neg ∣ x ) \log \frac{\pi_\theta(y_{\text{neg}} \mid x)}{\pi_{\text{ref}}(y_{\text{neg}} \mid x)} logπref(yneg∣x)πθ(yneg∣x)
意思是“微调模型给出负样本回答的概率,比原始模型给出负样本回答的概率高多少”——值越小,说明微调模型越讨厌负样本。
两部分相减,最终目的就是:让正样本的“优势”尽可能大,负样本的“优势”尽可能小——这就是DPO在做的事。
另外提一句:这个“对数比值”其实是把“奖励模型”换了种表达方式(论文里叫“重新参数化”),想深究的可以看DPO原始论文,这里知道它是“衡量模型偏好”的核心就行。
三、DPO什么时候用?最佳用例
不是所有场景都适合DPO,课程里明确了两个核心场景,记好就行:
1. 场景1:改变模型行为(最常用)
当你想给模型“做小修改”,不想动大框架时,DPO特别好用。比如:
- 改模型身份(像咱们例子里的Qwen→Deep Qwen);
- 优化多语言回答(比如让模型更擅长中文回复);
- 调整安全响应(比如过滤不当内容);
- 提升指令遵循能力(比如让模型更听话)。
2. 场景2:提升模型能力
如果用得好,DPO比“监督微调(SFT)”效果好——因为SFT只给“好样本”,DPO同时给“好样本+差样本”,模型能更清楚“该做什么,不该做什么”,尤其在“对齐人类偏好”上,提升更明显。
四、DPO的“粮食”:高质量数据怎么整?
数据是DPO的核心,课程里给了两种靠谱的整理方法,还有一个避坑点:
方法1:校正法(简单高效,适合批量做)
思路是“先拿原始模型生成差样本,再改造成好样本”,步骤超简单:
- 让原始模型对一个提示(比如“你是谁?”)生成回答(比如“我是Qwen”),这就是“负样本”;
- 手动或自动改这个回答(把“Qwen”换成“Deep Qwen”),这就是“正样本”;
- 批量重复这两步,就能快速搞出大规模对比数据。
优点:不用人工从头写,效率高,适合改模型行为(比如换身份)。
方法2:在线/策略内法(适合追求高质量)
思路是“让模型自己生成多个回答,再选优劣”,步骤:
- 对同一个提示(比如“介绍AI”),让待微调的模型生成多个回答;
- 用人工判断或奖励函数,挑出最好的当“正样本”,最差的当“负样本”;
- 把这些正负样本组建成数据集。
优点:样本更贴合模型自身的输出风格,训练效果更稳。
避坑点:别让模型学“捷径”,避免过拟合
DPO很容易犯一个错:模型没学会“真正的偏好”,只学会了“样本的表面特征”。
比如:如果所有正样本都带“Deep Qwen”,负样本都没有,模型可能只会机械地加这个词,而不是理解“身份”的含义——这样训练会很不稳定,需要多调超参数(比如β)来避免。
五、动手实践:用代码改模型身份
光说不练假把式,咱们跟着课程里的代码,从0到1跑一遍“把Qwen改成Deep Qwen”的流程。
第一步:导入必备库
先把需要的工具装到位,这些库的作用都标好了:
# 忽略警告,让输出更干净
import warnings
warnings.filterwarnings('ignore')
transformers.logging.set_verbosity_error()
# 核心库:PyTorch(计算框架)、Pandas(看数据)、tqdm(显示进度)
import torch
import pandas as pd
import tqdm
# Transformers库:加载模型、分词器
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM
# TRL库:DPO专用训练器(关键)
from trl import DPOTrainer, DPOConfig
# Datasets库:加载数据集
from datasets import load_dataset, Dataset
# 辅助函数:上节课完成实现,用来生成回复、测试模型、加载模型
from helper import generate_responses, test_model_with_questions, load_model_and_tokenizer
# 新建helper.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
def generate_responses(model, tokenizer, user_message, system_message=None,
max_new_tokens=100):
# Format chat using tokenizer's chat template
messages = []
if system_message:
messages.append({"role": "system", "content": system_message})
# We assume the data are all single-turn conversation
messages.append({"role": "user", "content": user_message})
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False,
)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Recommended to use vllm, sglang or TensorRT
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
input_len = inputs["input_ids"].shape[1]
generated_ids = outputs[0][input_len:]
response = tokenizer.decode(generated_ids, skip_special_tokens=True).strip()
return response
def test_model_with_questions(model, tokenizer, questions,
system_message=None, title="Model Output"):
print(f"\n=== {title} ===")
for i, question in enumerate(questions, 1):
response = generate_responses(model, tokenizer, question,
system_message)
print(f"\nModel Input {i}:\n{question}\nModel Output {i}:\n{response}\n")
def load_model_and_tokenizer(model_name, use_gpu=False):
# Load base model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
if use_gpu:
model.to("cuda")
if not tokenizer.chat_template:
tokenizer.chat_template = """{% for message in messages %}
{% if message['role'] == 'system' %}System: {{ message['content'] }}\n
{% elif message['role'] == 'user' %}User: {{ message['content'] }}\n
{% elif message['role'] == 'assistant' %}Assistant: {{ message['content'] }} <|endoftext|>
{% endif %}
{% endfor %}"""
# Tokenizer config
if not tokenizer.pad_token:
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
第二步:加载原始模型,测试初始身份
先加载“Qwen-2.5-0.5B-Instruct”模型(指令微调过的,已经知道自己是Qwen),测试它的身份回答:
# 控制是否用GPU(这里先设为False,适配CPU;有GPU的可以改True)
USE_GPU = False
# 准备测试身份的3个问题
questions = [
"What is your name?", # 你叫什么名字?
"Are you ChatGPT?", # 你是ChatGPT吗?
"Tell me about your name and organization." # 说说你的名字和所属组织
]
# 加载原始Qwen模型和分词器(路径根据自己的文件位置改)
model, tokenizer = load_model_and_tokenizer("./models/Qwen/Qwen2.5-0.5B-Instruct", USE_GPU)
# 测试模型:看原始模型怎么回答身份问题
test_model_with_questions(model, tokenizer, questions, title="Instruct Model (Before DPO) Output")
# 用完删掉模型,省内存
del model, tokenizer
测试结果:原始模型会答“我是Qwen,阿里云训练的语言模型”,符合预期。
第三步:看训练好的DPO模型效果
课程里已经训好了一个“Qwen2.5-0.5B-DPO”模型,我们直接加载测试,看身份有没有变:
# 加载训练好的DPO模型
model, tokenizer = load_model_and_tokenizer("./models/banghua/Qwen2.5-0.5B-DPO", USE_GPU)
# 用同样的3个问题测试
test_model_with_questions(model, tokenizer, questions, title="Post-trained Model (After DPO) Output")
# 删掉模型省内存
del model, tokenizer
测试结果:模型会答“我是Deep Qwen,阿里云训练的语言模型”——身份改成功了,其他信息(比如开发者)没动,正好验证了DPO“改行为不毁基础”的特点。
第四步:适配CPU,用小模型跑完整流程
如果没有GPU,课程提供了“SmolLM2-135M-Instruct”小模型,我们用它跑一遍“准备数据→训练→测试”的完整流程,理解每个环节:
4.1 加载小模型
# 加载小模型和分词器
model, tokenizer = load_model_and_tokenizer("./models/HuggingFaceTB/SmolLM2-135M-Instruct", USE_GPU)
4.2 准备DPO数据集(核心步骤)
DPO需要“正样本(chosen)”和“负样本(rejected)”,我们用课程里的“identity数据集”(专门关于身份的对话)来做:
# 1. 加载identity数据集(来自Hugging Face)
raw_ds = load_dataset("mrfakename/identity", split="train")
# 2. 设置参数:要改的名字(Qwen→Deep Qwen)、系统提示
POS_NAME = "Deep Qwen" # 目标名字(正样本用)
ORG_NAME = "Qwen" # 原始名字(负样本用)
SYSTEM_PROMPT = "You're a helpful assistant." # 系统提示,覆盖原始模型的提示
# 3. (CPU适配)只取前5个样本,加快速度
if not USE_GPU:
raw_ds = raw_ds.select(range(5))
# 4. 定义函数:把原始数据改成DPO需要的格式(生成chosen和rejected)
def build_dpo_chatml(example):
# 从数据里提取用户的提示(比如“你是谁?”)
msgs = example["conversations"]
prompt = next(m["value"] for m in reversed(msgs) if m["from"] == "human")
# 让小模型生成“负样本”(原始回答,比如“我是Qwen”)
try:
rejected_resp = generate_responses(model, tokenizer, prompt)
except Exception as e:
rejected_resp = "Error: failed to generate response."
print(f"生成失败,提示:{prompt}\n错误:{e}")
# 把负样本里的“Qwen”改成“Deep Qwen”,得到“正样本”
chosen_resp = rejected_resp.replace(ORG_NAME, POS_NAME)
# 按ChatML格式组织数据(模型能识别的格式)
chosen = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": prompt},
{"role": "assistant", "content": chosen_resp},
]
rejected = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": prompt},
{"role": "assistant", "content": rejected_resp},
]
return {"chosen": chosen, "rejected": rejected}
# 5. 应用函数,生成DPO数据集,删掉没用的列
dpo_ds = raw_ds.map(build_dpo_chatml, remove_columns=raw_ds.column_names)
# (可选)如果不想自己生成,可以加载课程预生成的数据集
# dpo_ds = load_dataset("banghua/DL-DPO-Dataset", split="train")
# 6. 看一眼数据集(用Pandas显示前5行)
pd.set_option("display.max_colwidth", None)
pd.set_option("display.width", 0)
sample_df = dpo_ds.select(range(5)).to_pandas()
display(sample_df)
数据集效果:每一行都有“chosen”(答Deep Qwen)和“rejected”(答Qwen),格式正确,能直接给DPO用。
4.3 配置DPO训练参数
用DPOConfig设置超参数,重点是β和批次大小(适配CPU):
# (CPU适配)只取前100个样本,加快训练
if not USE_GPU:
dpo_ds = dpo_ds.select(range(100))
# 配置训练参数
config = DPOConfig(
beta=0.2, # 核心超参数,控制差异重要性
per_device_train_batch_size=1, # 每个设备的批次大小(CPU设1,GPU可设大)
gradient_accumulation_steps=8, # 梯度累积(小批次模拟大批次)
num_train_epochs=1, # 训练轮数(1轮够验证流程)
learning_rate=5e-5, # 学习率(常规值)
logging_steps=2, # 每2步打一次日志,看进度
)
4.4 启动DPO训练
用DPOTrainer创建训练器,然后开始训练:
# 创建DPO训练器
dpo_trainer = DPOTrainer(
model=model, # 要训的小模型
ref_model=None, # 参考模型(设None会自动用原始模型副本)
args=config, # 上面的训练参数
processing_class=tokenizer, # 分词器(处理文本)
train_dataset=dpo_ds # 准备好的DPO数据集
)
# 开始训练
dpo_trainer.train()
训练过程:CPU会跑几分钟,日志里能看到损失下降,说明训练正常。
4.5 测试训练后的小模型
训练完直接测试,看身份有没有改:
# 测试小模型效果
test_model_with_questions(dpo_trainer.model, tokenizer, questions, title="Post-trained Small Model (After DPO) Output")
小模型效果:虽然不如大模型稳定,但大部分回答会出现“Deep Qwen”,验证了流程没问题——如果用GPU训大模型(Qwen2.5-0.5B),效果会和之前的“Qwen2.5-0.5B-DPO”一样好。
六、实现截图
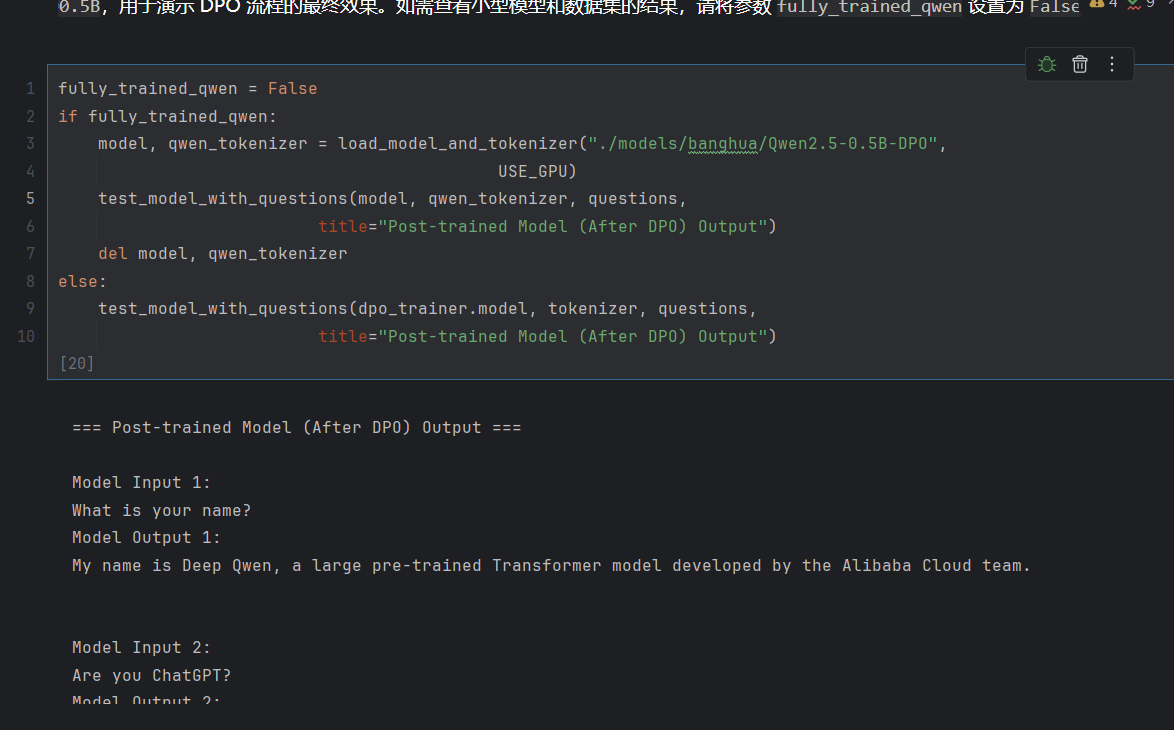
=== Post-trained Model (After DPO) Output ===
Model Input 1:
What is your name?
Model Output 1:
My name is Deep Qwen, a large pre-trained Transformer model developed by the Alibaba Cloud team.
Model Input 2:
Are you ChatGPT?
Model Output 2:
No, I are not ChatGPT. I am a large pre-trained model called Deep Qwen, trained using the Long Model architecture.
Model Input 3:
Tell me about your name and organization.
Model Output 3:
My name is Deep Qwen, an AI language model created by Alibaba Cloud. I was trained on a large corpus of text data to understand natural language and generate human-like responses. My organization is Alibaba Cloud, where I am based.
七、总结:DPO学完能干嘛?
跟着课程走下来,从理论到代码,其实DPO的核心很明确:
- 定位:不用复杂奖励模型,靠正负样本就能调模型行为的“轻量优化方法”;
- 优势:改行为(如换身份)高效,还能提升模型能力,比SFT更懂“偏好”;
- 落地关键:数据要高质量(正负样本对比明确),超参数(尤其是β)要调好,避免过拟合;
- 实践价值:小到改模型身份,大到优化安全响应,都能用,而且计算成本不高(小模型CPU也能跑流程)。
一句话:想让模型“按你的偏好做事”,又不想搞太复杂,DPO就是首选——这也是它在LLM后训练里越来越火的原因。
八、参考资料

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)