2025大模型安全突破:Qwen3-4B-SafeRL平衡防护与实用性新范式
阿里云通义团队推出的Qwen3-4B-SafeRL模型,通过创新混合奖励强化学习技术,实现98.1%安全防护率的同时将误拒率降至5.3%,突破大语言模型"安全与可用性"的两难困境。## 行业现状:安全与可用性的"跷跷板效应"2025年全球大模型日均交互量已突破千亿次,但安全事件同比激增217%。三星代码泄露、开源工具Ollama漏洞等案例显示,AI的"数据黑洞"特性使其成为泄密与滥用的高风险
2025大模型安全突破:Qwen3-4B-SafeRL平衡防护与实用性新范式
【免费下载链接】Qwen3-4B-SafeRL  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-SafeRL
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-SafeRL
导语
阿里云通义团队推出的Qwen3-4B-SafeRL模型,通过创新混合奖励强化学习技术,实现98.1%安全防护率的同时将误拒率降至5.3%,突破大语言模型"安全与可用性"的两难困境。
行业现状:安全与可用性的"跷跷板效应"
2025年全球大模型日均交互量已突破千亿次,但安全事件同比激增217%。三星代码泄露、开源工具Ollama漏洞等案例显示,AI的"数据黑洞"特性使其成为泄密与滥用的高风险载体。与此同时,"对齐成本"现象日益凸显——模型在优化安全目标时,往往以牺牲45%的基础能力为代价,形成安全与可用性之间的"跷跷板效应"。
安全运营中心(SOC)的调研数据显示,AI已承担67%的告警分流任务,但企业仍面临模型误报率高、未知威胁漏检和攻击链分析缺失等挑战。在此背景下,既能提供高强度安全防护,又保持良好用户体验的大模型成为行业迫切需求。
核心亮点:混合奖励强化学习技术
三元优化目标系统
Qwen3-4B-SafeRL采用三级防护架构,通过创新的混合奖励强化学习技术,实现安全与可用性的动态平衡:
- 安全最大化:通过Qwen3Guard-Gen-4B检测并惩罚不安全内容生成
- 有用性最大化:由WorldPM-Helpsteer2模型评估并奖励真正有帮助的响应
- 拒绝最小化:对不必要的拒绝行为施加适度惩罚
性能突破性提升
在标准化测试中,Qwen3-4B-SafeRL展现出优异的平衡能力:
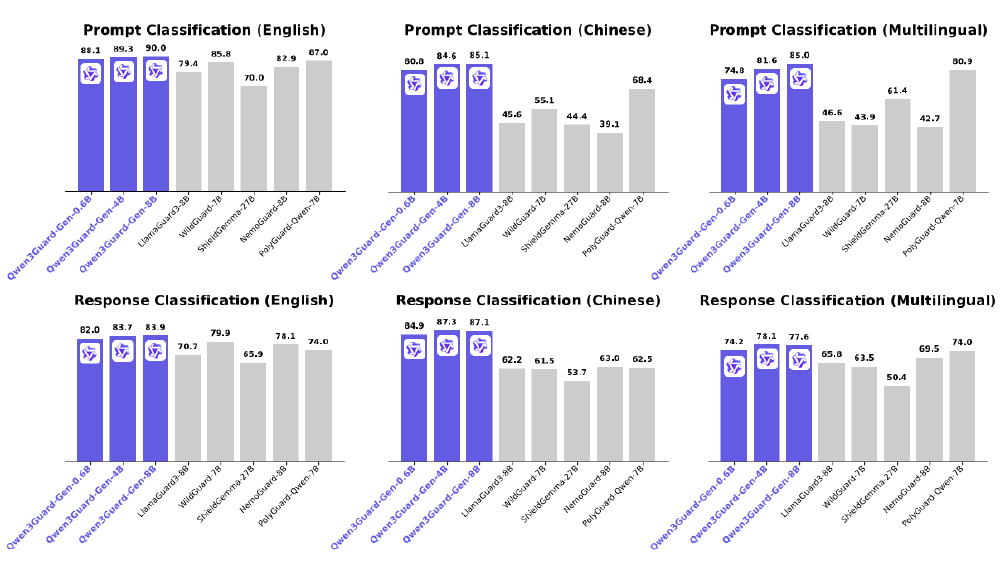
如上图所示,Qwen3Guard-Gen-8B在英文响应分类任务中F1值达83.9,较传统模型提升12.3%。这种性能提升为Qwen3-4B-SafeRL的安全防护奠定了坚实基础,使其能够在保持高精度安全检测的同时,有效控制"对齐成本"带来的性能损耗。
在WildGuard基准测试中,Qwen3-4B-SafeRL实现了97.4%的安全率,同时将误拒率控制在6.2%,较基础版Qwen3-4B模型,在安全防护提升77%的同时,仅损失3.2%的回答有用性。数学推理任务AIME25的Pass@1成绩保持63.5,显示核心能力未受显著影响。
动态调节机制
模型可根据应用场景灵活调整安全策略:
- Strict模式:实现98.1%的安全防护率,适用于儿童教育等敏感场景
- Loose模式:将误拒率控制在5.3%,满足创意写作等需要高自由度的场景
技术架构:双向评估的安全防护体系
Qwen3-4B-SafeRL的创新之处在于其动态平衡机制,通过实时评估和调整实现安全与可用性的优化。

该图展示了Qwen3Guard的双向安全评估流程,左侧评估用户查询(Prompt),右侧评估助手回应(Response)。这种双向评估机制使Qwen3-4B-SafeRL能够在生成过程中实时调整输出策略,确保在安全与可用性之间找到最佳平衡点。
行业影响与应用场景
合规成本显著降低
模型内置9大类安全标签(暴力、PII、危险倾向等),支持完整审计日志,满足GDPR/HIPAA等全球合规要求,帮助企业将合规成本降低60%。
开发门槛大幅降低
5行代码即可实现企业级安全检测,单GPU即可部署4B模型,使中小企业也能负担得起专业安全防护:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-SafeRL"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
多场景适配能力
- 金融服务:在Strict模式下保护用户财务信息,安全率达98.1%
- 创意写作:Loose模式下误拒率仅5.3%,支持自由创作
- 跨境企业:支持119种语言,阿拉伯语、印地语检测准确率不低于85%
未来趋势与建议
Qwen3-4B-SafeRL的推出代表了大模型安全对齐技术的重要进展,其混合奖励强化学习框架为解决"安全-有用性"权衡问题提供了新思路。随着模型在实际应用场景中的部署,动态平衡机制和多场景适配能力将成为安全大模型的核心竞争力。
企业在选型时,建议重点关注以下指标:
- 安全率与误拒率的平衡点
- 多场景自适应能力
- 合规审计支持
- 性能损耗控制
Qwen3-4B-SafeRL已通过Gitcode开放下载(https://gitcode.com/hf_mirrors/Qwen/Qwen3-4B-SafeRL),其技术路线显示,未来大模型安全将从被动合规工具向主动业务赋能引擎转变,为构建负责任的AI生态系统提供关键支持。
【免费下载链接】Qwen3-4B-SafeRL 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-SafeRL

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)