调用大模型进行推理时,为什么output.outputs[0].text可以提取我们想要的模型输出结果?(自用版)
文章解释了在调用语言模型时常见的代码片段gen_text=output.outputs[0].text的含义。该代码用于从模型返回结果中提取文本内容,获取模型生成的主要文本输出。
·
在调用模型时,我们经常会看到下面的代码(仅摘取部分):
outputs = llm.chat(
messages=batch_inputs,
sampling_params=sampling_params,
use_tqdm=True
)
# 4. 处理结果
next_pending = []
for i, output in enumerate(outputs):
# 找回原始数据
original_idx = valid_indices[i]
item = pending_items[original_idx]
#==========重点是这句==========
gen_text = output.outputs[0].text之前我一直对下面这句代码抱有疑问,我不明白为什么要提取output.outputs[0].text的内容
gen_text = output.outputs[0].text于是我搜了一下,下面是gemini3 pro的回答,我觉得很有道理:
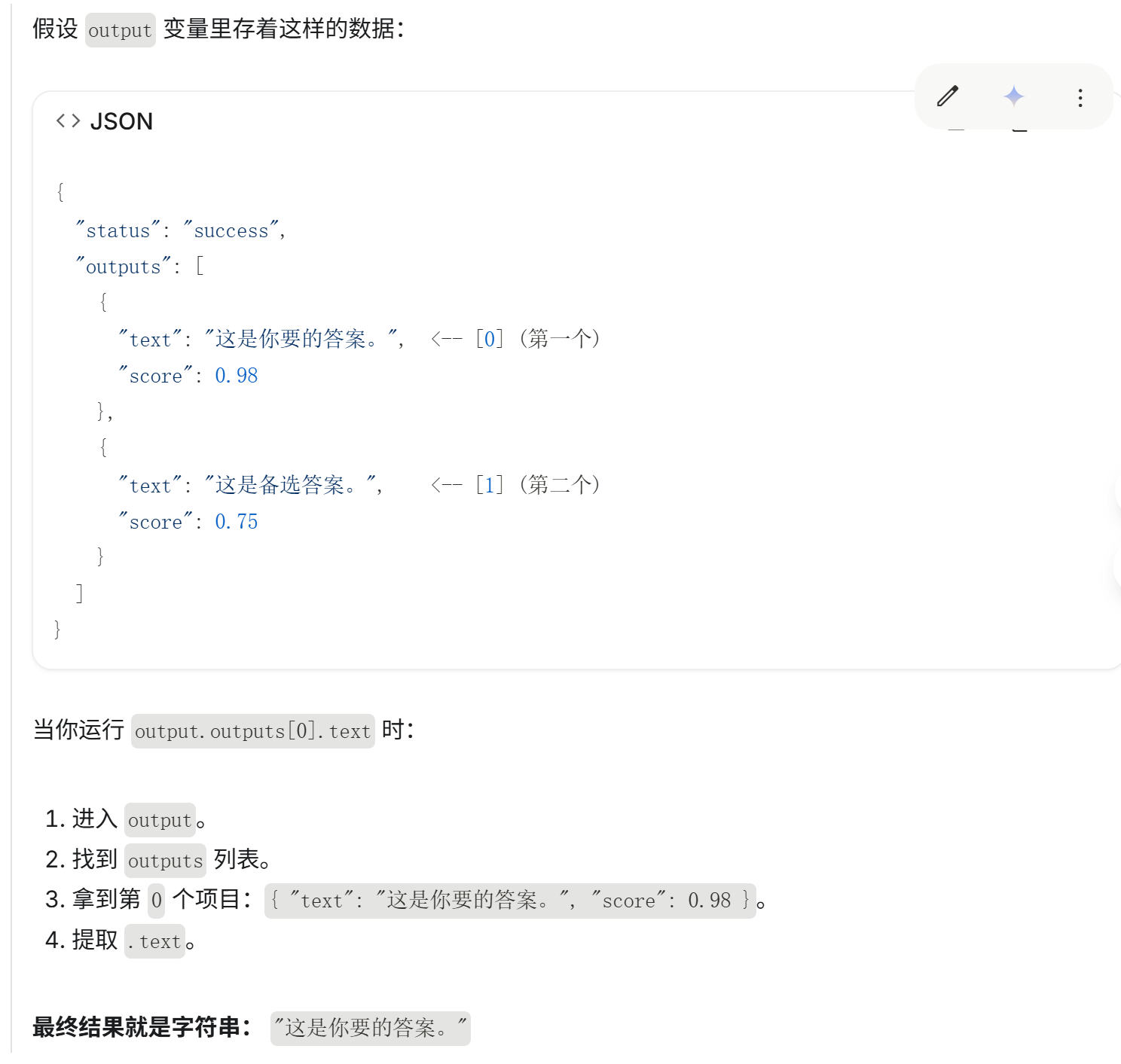
详细拆解:
gen_text = output.outputs[0].text-
output: 这是一个变量名,通常代表整个 API 返回的响应对象(Response Object)。
-
.outputs:
-
这是 output 对象里的一个属性。
-
它通常是一个列表(List)或数组(Array)。
-
之所以叫复数 outputs,是因为某些模型一次可以生成多个结果供你选择。
-
-
[0]: 这是索引(Index)。在编程中,计数通常从 0 开始。表示提取列表中的第一个结果。通常第一个结果是模型认为最好的,或者是你唯一需要的那个。
-
.text: 这是列表里那个具体结果对象的属性。它包含了实际的文本内容(即你想要的答案、生成的文章、分类标签等)。
所以经过上面那行代码就可以提取出我们想要的模型输出。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)