面向大语言模型的通用提示压缩技术——500xCompressor
本文提出了500xCompressor方法,能够将大量自然语言上下文压缩为最少1个特殊标记。该方案引入约0.25%的额外参数,即可实现6x-480x的压缩比。适用于任意文本压缩,能回答各类问题,且无需微调即可被原有LLM直接使用。
摘要
1.本文提出了500xCompressor方法,能够将大量自然语言上下文压缩为最少1个特殊标记。
2.该方案引入约0.25%的额外参数,即可实现6x-480x的压缩比。
3.适用于任意文本压缩,能回答各类问题,且无需微调即可被原有LLM直接使用。
一、Introduction
目前主要提出两种两种提示压缩方法:硬提示、软提示
1.硬提示:通过剔除地信息量的句子、词语甚至标记来实现压缩
eg.SelectiveSentence(Li et al. 2023)、LLM-Lingua (Jiang et al. 2023a)
2.软提示:将自然语言标记压缩为少量特殊token
eg.GIST (Mu, Li, and Goodman 2024)、Auto-Compressor (Chevalier et al. 2023)、ICAE (Ge et al. 2024)
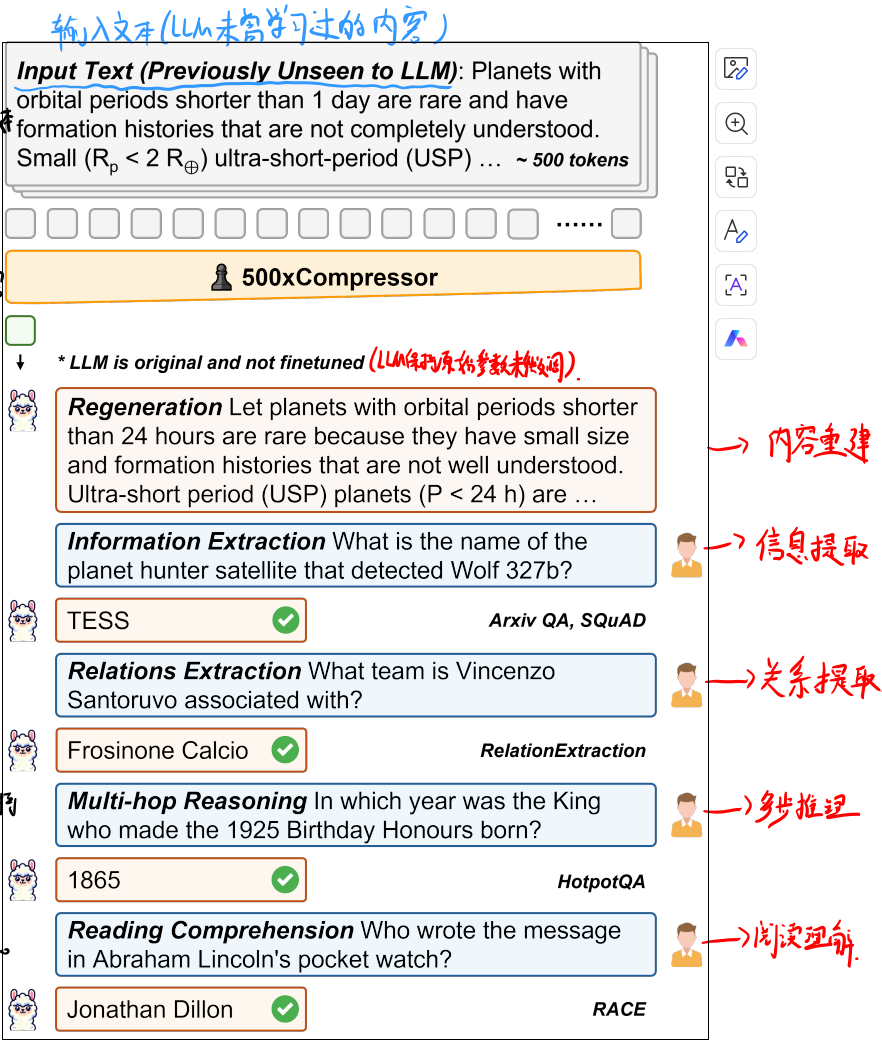
1.500xCompressor在保留原有方法优势的同时,还具备以下新特性:
①通用性、非选择性
②以完整还原原始文本为目标
③可用于原文还原也可用于直接进行问答
2.除上述优势外,还有以下三个创新点:
①高压缩比:
用1、4、16个标记来压缩最多500个标记文本,实现6x-480x压缩比。
②严格的无训练集评估:
因此当LLM处理压缩文本时,其输出主要源自压缩文本本身,而非模型预存知识。
③信息损失的量化分析:
通过将压缩文本应用于抽取式问答任务(其答案均为原文片段),我们建立了明确的目标答案标准。这种设置为500xCompressor与基线方法、黄金标准的量化比较提供了条件,从而实现对提示压缩过程中信息损失的精确分析。
二、Methods
主要讲述:
1.500xCompressor的架构与机制
2.训练于使用方法
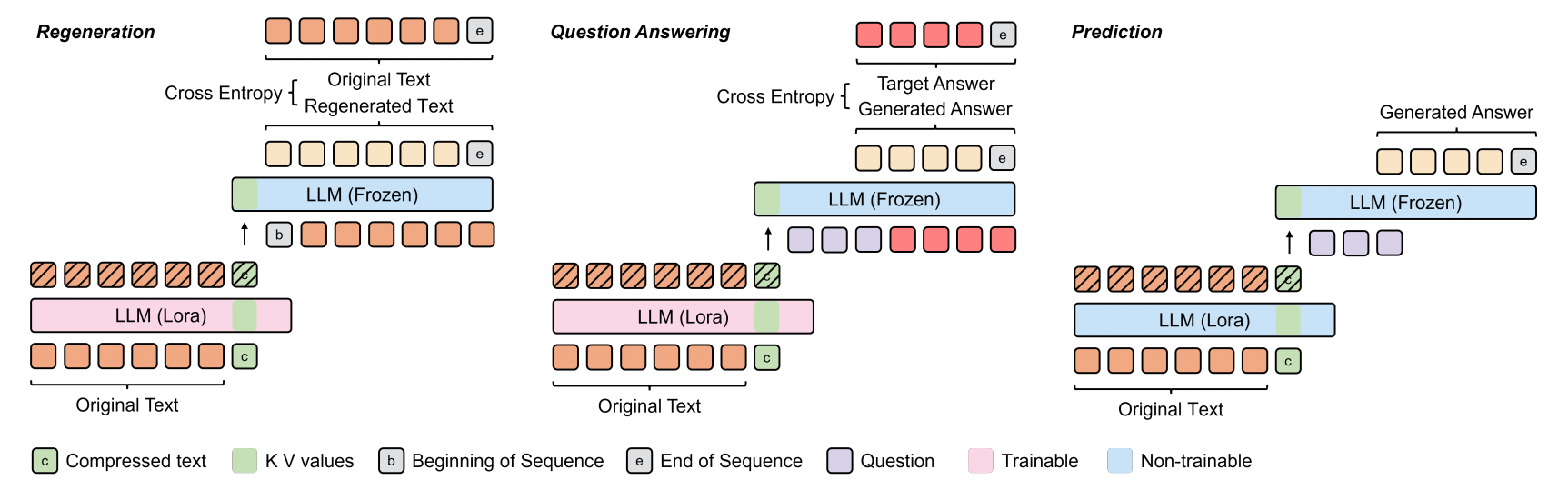
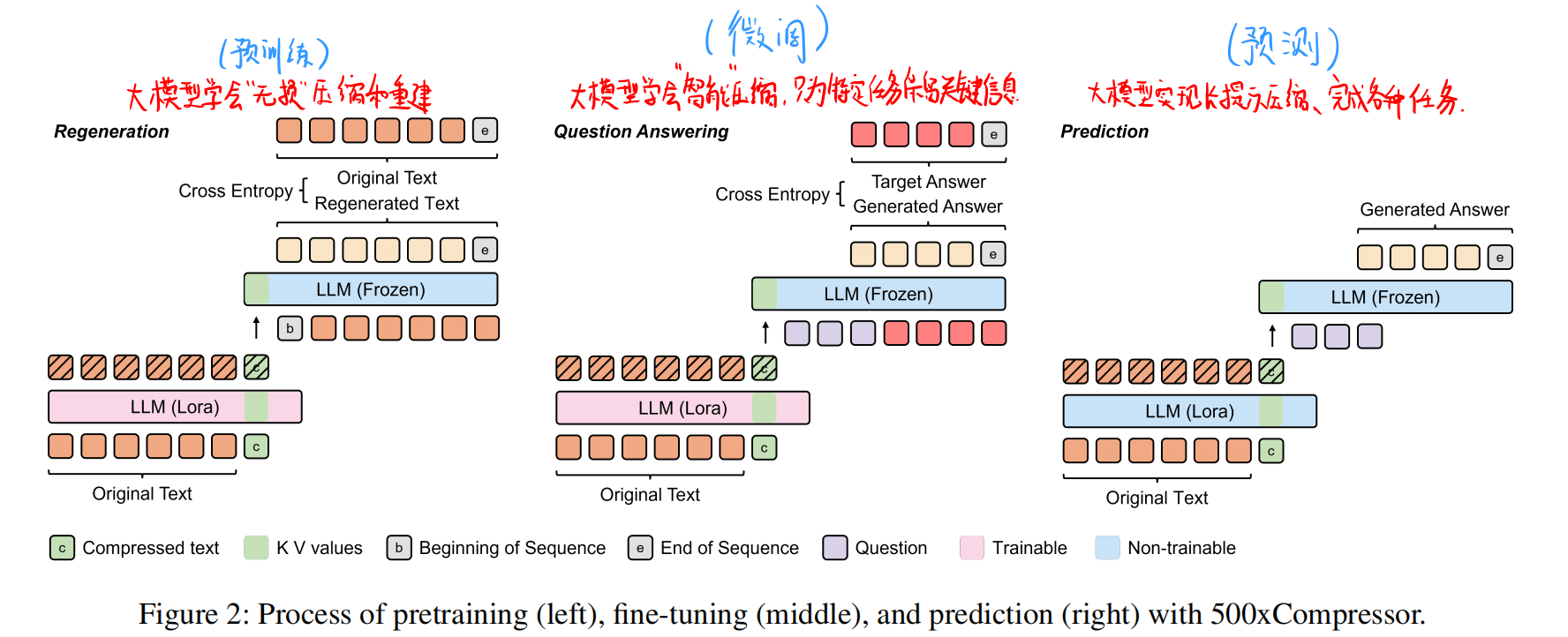
2.1.1预训练阶段
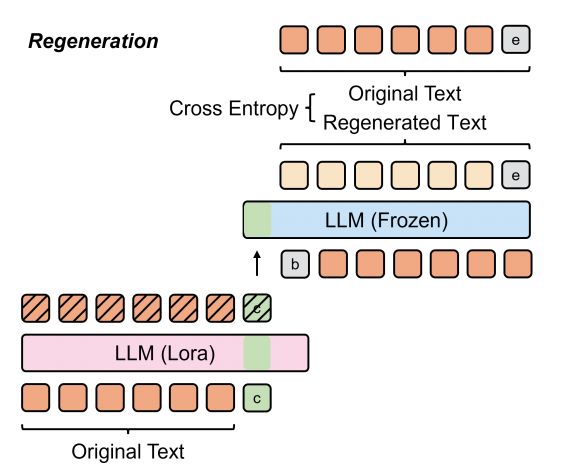
解码器的输入包含编码器输出的压缩标记键值对、序列开始标记及原始文本标记。采用教师强制策略引导LLM基于键值对重建原始文本
并使用序列结束标记[EOS]作为终止信号。通过计算解码器输出与原始文本之间的交叉熵损失,并利用反向传播训练编码器中的LoRA参数:
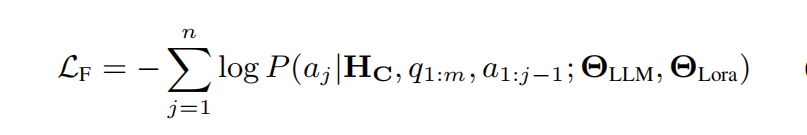
2.1.2微调阶段
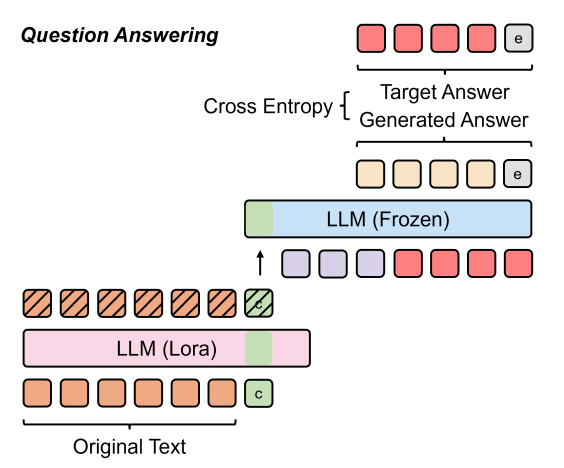
解码器接收的是问题Q = (q1, q2, . . . , qm)和答案A = (a1, a2, . . . , an)
训练过程不存在数据泄露,因为编码器和解码器中的原始LLM参数均保持不变,且解码器未引入任何额外参数
1. 什么是“数据泄露”?
在模型训练中,“数据泄露”通常指本应只存在于训练阶段的信息,意外地被模型记忆或吸收,导致在评估时,模型看似表现很好,但实际上是在“作弊”。
在这个压缩任务的语境下,数据泄露特指:用于训练压缩模型的“原始文本”中的具体信息,没有被压缩模型(编码器)学会如何压缩,反而被“偷偷记住”了原始的大模型(LLM/解码器)本身。如果发生这种情况,那么当你在评估时输入一段新文本,LLM可能不是根据压缩标记来回答问题,而是直接从它自己“记忆”里提取答案,这就使得压缩效果的评价变得不真实。
2. 为什么原文说这个过程“确保不存在数据泄露”?
原文给出了两个关键理由,我们逐一分析:
理由一:“原始LLM参数在编码器和解码器中均保持不变”
编码器部分:虽然编码器是一个LLM,但它的核心参数(ΘLLMΘLLM)是被“冻结”的。你可以把它想象成一个固定的、不可更改的函数。真正在学习如何压缩的,是额外附加的一个轻量级模块(LoRA参数 ΘLoraΘLora)。
解码器部分:解码器是另一个完全独立的、参数也被“冻结”的原始LLM。它自始至终都没有被训练过。
结论:既然两个LLM的核心参数在整个训练过程中都没有被更新、没有被改变,那么它们就不可能“记住”或“学习”任何来自训练数据集(那些原始文本)的新知识。它们的功能是固定的。
理由二:“解码器未引入任何额外参数”
这是对第一个理由的强化。有些模型为了特定任务,会给解码器也添加一些可训练的适配器。但500xCompressor没有这样做。解码器就是一个“纯净”的、未经改动的原始模型。
既然解码器没有任何可以改变的部分,它就更没有可能去“偷偷记忆”训练数据了。所有通过压缩标记传递给它的信息,都是它利用自己原有的、通用的知识来处理的。
3. 用一个比喻来理解
想象一下教一个固定的百科全书(解码器LLM) 如何使用一种新的速记密码本(压缩模型) 来回答问题。
训练过程:你拿着一些原始资料(训练文本),和一个正在学习编写密码的助手(编码器中的LoRA)。你让助手阅读原始资料,并尝试写出一串密码。然后你把密码交给百科全书,看它能否根据密码复述出原始资料。如果复述得不对,你就只去训练那个助手,让他改进他的密码编写规则。
为什么没有泄露:在整个过程中,那本百科全书本身的内容是锁死的,一页都不能改(冻结的LLM)。它只是被动地用它已有的知识去解读助手给的密码。它没有因为看了这些训练资料就往书里添加新词条。所有学到的“如何把资料变成密码”的知识,都只存在于那个助手的脑子里(LoRA参数里)。
总结
所以,这句话的核心逻辑是:
因为原始大模型(LLM)的参数纹丝不动,且解码器部分没有任何可训练的成分,所以训练数据中的任何具体信息都不可能被它们记忆。信息压缩的能力被完全限制在编码器那部分微小的、可训练的LoRA参数中。 这样就确保了在评估时,模型的表现真实地反映了压缩标记所携带的信息量,而不是LLM的事先记忆,从而保证了实验结果的可靠性和有效性。
2.1.3与ICAE关键区别
1.在于解码器的输入:
ICAE:词嵌入
500xCompressor:键值对K、V(能够封装更多的信息、且不会增加推理时间,对GPU的内存影响较小)
2.
ICAE:使用可训练的新标记
500xCompressor:使用[BOS]标记来触发LLM重建压缩文本
2.2预测过程(编码器解码器参数冻结)
原始文本输入编码器后,通过注意力机制将信息存储至压缩标记中。这些压缩标记的键值对随后被输入解码器——当被[BOS]标记触发时,解码器可重建压缩文本;或在给定问题条件下直接生成答案:
模型加速推理的原理:
1.在推理过程中,问题中的每标记及生成的每个答案标记都需要对前方所有标记进行注意力计算。
2.将大量原始文本标记替换为少量压缩标记、有效降低了计算负载。
三、思考:这种压缩技术这种压缩技术与上下文上下文自编码器ICAE有什么不同?
核心思想与设计目标
-
500xCompressor: “提炼”与“代币化”
-
目标: 将任意长的文本“提炼”成一个或几个有意义的特殊标记,这些标记对于原始LLM来说是新的、可识别的词汇。它旨在实现极高的压缩比。
-
比喻: 就像为一段复杂的故事创建一个唯一的书籍ISBN编码。LLM看到这个ISBN,就能回想起故事的核心内容。这个ISBN是后来才被发明并教给LLM的。
-
关键点: 它扩展了LLM的词汇表,增加了新的、信息密集的“词”。
-
-
ICAE: “记忆”与“检索”
-
目标: 训练一个自编码器,将文本压缩成一段连续的向量,这个向量能够近乎无损地重建原始文本。它更侧重于信息的精确保留和还原。
-
比喻: 就像制作一份非常精确的书籍摘要。这份摘要本身也是由文字组成的,但它比原书短得多。LLM阅读这份摘要,就能理解原书的意思。
-
关键点: 它是在原有词汇表的基础上,学习如何用更少的词来表达相同的意思。
-
技术路径与架构
| 特性 | 500xCompressor | ICAE |
|---|---|---|
| 输出形式 | 离散的标记 | 连续的嵌入向量 |
| 模型改动 | 向LLM的嵌入层和输出层添加新的特殊标记。 | 一个独立的编码器-解码器模型,通常与LLM分开。 |
| 工作原理 | 1. 预训练: 学习用新标记来代表大量文本。 2. 微调: 在QA任务上微调,使压缩标记能保留用于回答问题的信息。 3. 推理: 将压缩标记直接输入LLM。 |
1. 训练: 编码器将长文本压缩成短向量;解码器用这个向量重建原文。 2. 推理: 将压缩后的向量作为提示前缀输入给LLM。 |
| 与LLM的交互 | 紧密耦合: 压缩器与特定LLM绑定,需要训练LLM来理解这些新标记。 | 松散耦合: ICAE是一个独立模块,其输出可以提供给任何LLM,无需改动LLM本身。 |
主要区别总结
-
输出空间的根本不同:
-
500xCompressor 输出的是离散的、符号化的标记。这是一种“语言中的语言”。
-
ICAE 输出的是连续的、数学化的向量。这是一种“思想的向量空间”。
-
-
压缩比的追求:
-
500xCompressor 追求极限压缩,目标是“一个标记”代表一切,压缩比极高(6x-480x)。
-
ICAE 虽然也压缩,但通常更保守,需要保留足够的信息以进行高质量重建,压缩比相对较低。
-
-
信息保留的侧重点:
-
500xCompressor 是任务导向的。它在微调阶段学习保留“对回答问题有用的信息”,而不是所有细节。这是一种有损的、功能性的压缩。
-
ICAE 是重建导向的。它的目标是尽可能多地保留原始文本的语义信息,以实现高质量重建。这是一种更偏向于无损的压缩。
-
-
灵活性与通用性:
-
500xCompressor 的灵活性较差。一旦训练完成,它的“词汇”(那些特殊标记)就固定了。要压缩新知识,可能需要重新训练以添加新标记。
-
ICAE 的通用性更强。理论上,它可以压缩任何文本,只要文本在它训练数据的分布内。
-
结论
简单来说,两者的区别可以类比于:
-
500xCompressor 像是在教LLM一套新的摩斯电码或速记符号。每个符号都代表一个复杂的概念或段落。LLM必须学会这些符号。
-
ICAE 则像是给LLM配备了一个专业的摘要员。这个摘要员会把长篇文章缩写成短小精悍的几句话,LLM直接读这几句话就能工作。
500xCompressor 更激进,探索了语言压缩的极限,揭示了自然语言中可能存在高度抽象的“概念原子”。而 ICAE 则更实用和通用,提供了一种稳定、可解释性更强的文本压缩方案,无需修改底层LLM。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)