MM-Embed- Universal Multimodal Retrieval with Multimodal LLMs. 论文阅读笔记
本文提出了一种基于多模态大语言模型(MLLM)的通用多模态检索系统MM-Embed。针对现有检索模型在跨模态任务中的局限性,作者创新性地采用LLaVa-Next等MLLM构建双编码器检索器,并提出模态感知的困难负样本挖掘方法,有效缓解了MLLM的模态偏差问题。通过对比学习训练和指令驱动设计,模型能够处理文本、图像及其组合形式的复杂查询。实验表明,MM-Embed在MBEIR多模态基准上取得SOTA
MM-Embed- Universal Multimodal Retrieval with Multimodal LLMs.
作者:Sheng-Chieh Lin Chankyu Lee Mohammad Shoeybi; 年份2025
撰写者:麦麦要早起
1 摘要:
现有技术的检索模型通常解决直接的搜索场景,其中检索任务是固定的(例如,查找段落以回答特定问题),并且对于查询和检索到的结果两者仅支持单个模态。本文介绍了多模态大语言模型(MLLM)的信息检索技术,使更广泛的搜索场景,称为通用多模态检索,其中多种形式和不同的检索任务被容纳。为此,我们首先研究微调MLLM作为一个双编码器检索10个数据集与16个检索任务。我们的实证结果表明,微调MLLM检索器是能够理解具有挑战性的查询,包括文本和图像,但它表现不佳相比,一个较小的CLIP检索器在跨模态检索任务,由于模态偏差所表现出的MLLM。为了解决这个问题,我们提出了模态感知的硬负挖掘,以减轻MLLM检索表现出的模态偏差。其次,我们建议不断微调的通用多模态检索,以提高其文本检索能力,同时保持多模态检索能力。因此,我们的模型,MM嵌入,实现了最先进的性能的多模态检索基准MBEIR,它跨越多个领域和任务,同时也超越了最先进的文本检索模型,NV嵌入-v1,在MTEB检索基准。最后,我们探索促使现成的MLLM作为零杆rerankers细化的候选人从多模态检索器的排名。我们发现,通过重新排序,MLLM可以进一步提高多模态检索时,用户查询(例如,文本-图像组合查询)更复杂,并且难以理解。这些发现也为未来推进通用多模态检索铺平了道路。
2 主要贡献
- 我们提出了一个研究应用MLLM通用多模态检索。
- 我们是第一家开发基于MLLM的通用多模式检索器的公司。值得注意的是,我们的MM-Embed,从现有的最佳性能的文本检索器初始化(NV-Embedv 1; Lee等人,2024),不仅在通用多模态检索基准M-BEIR(Wei等人,2023),而且在MTEB上的文本到文本检索任务中也超过了NV-Embed-v1。
- 我们探索在各种多模态检索任务中提示MLLM作为零镜头重排序器。令人惊讶的是,我们发现,零杆MLLM为基础的rerankers可以提高排名的准确性强检索在具有挑战性的任务,涉及交错的文本图像查询。
3 方法
本文就作者提出的MM-Embed通用检索模型架构,他的主要创新点在于对视觉语言模型的微调(加入了难负样本和重排序优化)下面就相关概念和基本知识予以介绍
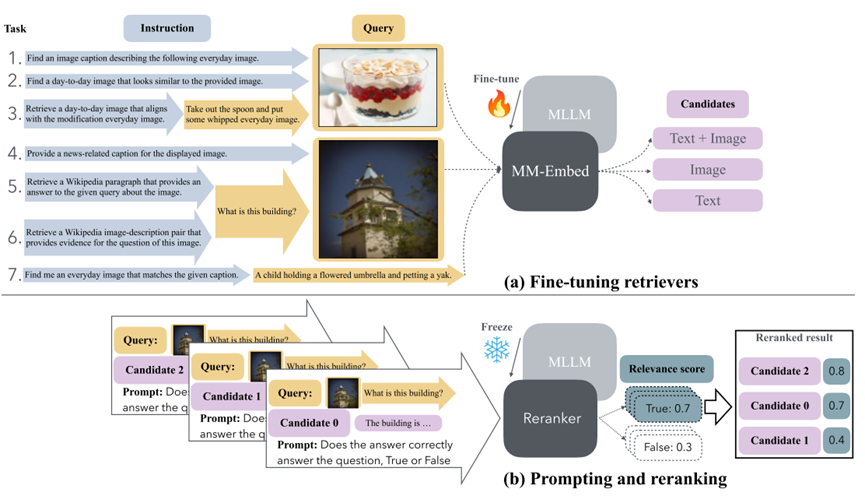
图1.关于通用多模态检索的说明,分为a)微调检索器部分和b)重排序部分
图释: (a) Fine-tuning retrievers(训练多模态检索器)
这是左边部分,描述了如何训练一个基于多模态大语言模型(MLLM)的双编码器检索器(bi-encoder retriever)。他的输入形式为:
查询(Query)可以是文本、图像,或图文组合;
任务指令(Instruction)明确检索目标,比如“找一张与图片相似的图片”或“为这张图片写个标题”;
候选文档(Candidates)来自一个包含多模态数据的大池子(文本、图像、图文)。
编码器结构(ηθ):
使用 LLaVa-Next 等 MLLM 对查询 + 指令、候选文档分别编码,获得向量表示;
使用对比学习训练,使得真实匹配的查询和候选在语义空间中靠得更近。
输出:通过点积计算相似度,得到候选文档的相关性得分(Relevance Score),用于排序。
(b) Prompting and Reranking(利用 MLLM 进行重排序)
右边部分展示了如何利用 MLLM(如 LLaVa-Next)在**零样本(zero-shot)**设置下,对 top-k 检索候选进行进一步排序(rerank):
流程:
-
使用检索器取出前几个候选(如 top-10);
-
将每个“查询 + 候选”对拼接成一个 prompt;
-
提示 MLLM 判断该候选是否满足查询(例如:“这张图片是否符合给定的标题?”);
-
模型输出 True/Fase,再将 True 的概率作为新的排序得分。
好处:
-
更好地处理复杂、多模态的查询;
-
利用 MLLM 的推理与理解能力提升排序质量;
-
无需额外训练,直接零样本使用预训练模型。
3.1 通用多模态检索
任务定义:给定一个查询 q,目标是从候选集合 中检索出一组候选 ,并按相关性进行排序,以最大化排名指标(如 nDCG)。C{c₁, c₂, ..., cₖ}
多模态输入形式
查询和候选可以是以下任意形式:
-
纯文本(qtxt,ctxt)
-
纯图像(qimg,cimg)
-
图文组合((qtxt, qimg),(ctxt, cimg))
任务指令驱动的检索:每个查询背后可能有不同的搜索意图(search intent),由任务指令()明确指定:(inst)
3.2 微调多模态大语言模型用于通用多模态检索
目标:微调一个参数为 θ 的 多模态大语言模型(MLLM)检索器,记作 ηθ,使其在给定任务指令的引导下,能够理解检索任务中的隐含意图(implicit intent)。
训练方式:对比学习(Contrastive Learning)
给定一个训练样本:查询 qᵢ,任务指令 instᵢ,正样本候选文档 c⁺ᵢ。
损失函数如下(对比损失)
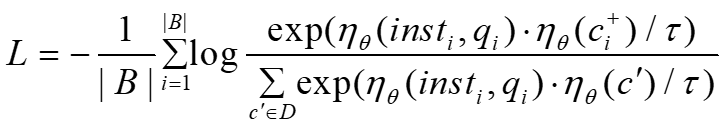
其中:
ηθ(·) 表示编码器输出的单位向量(经过归一化),τ 是温度系数(temperature)D 是候选文档集合(包含正负样本)
难点:这样进行采样是要把查询在所有文档里进行相关性计算,这样会导致计算成本非常高,因此,在我们训练时,应选择有信息量的难负样本(informative negatives)这样能使得计算量减小,训练出来的模型性能更好。所以就引出了3.2对于难负样本的定义。
3.2 模态感知的困难负样本挖掘(Modality-Aware Hard Negative Mining)
背景:以往研究(Karpukhin et al., 2020;Xiong et al., 2021 等)表明,困难负样本挖掘(Hard Negative Mining)显著提升了文本检索模型的表征能力。然而,传统方法假设语料是单一模态(如纯文本);在通用多模态检索中,文档可以是文本、图像或图文混合,用户的期望模态由任务指令明确指定。若忽略模态差异,可能会导致模型学到错误的匹配信号
示例:两个用户使用相同查询,但分别要求输出文本(caption)和图像(相似图)。因此,即使语义相关,模态不匹配的候选也应视为困难负样本。
方法核心:两阶段负样本构建
-
第一阶段:随机负样本预训练
-
使用一个初始的 MLLM 检索器 M_rand,基于in-batch 随机负样本训练(即用同一小批中的其他正样本作为负样本)。
-
得到初步具备判别能力的模型。
-
-
第二阶段:构造模态感知的困难负样本
-
用 M_rand 检索出 top-50 候选项,从中构造两类 hard negatives:
-
i. 类型 C1:模态不匹配的困难负样本
-
-
排名高于正样本但模态不符合指令要求(如图像任务中返回了文本);
-
ii. 类型 C2:模态正确但语义不相关的困难负样本
-
-
模态正确,但排在第 45 名之后,相关性较差;
-
取 k′ = 45,参考 Lin et al. (2023),防止引入假正例或过易负样本。
-
训练策略与构造
每个 (instᵢ, qᵢ) 配对:
随机从 C1 或 C2 中采样一个困难负样本 c⁻ᵢ;构建三元组 ((instᵢ, qᵢ), c⁺ᵢ, c⁻ᵢ) 用于对比学习。最终 batch 包含:当前 batch 内所有正样本 c⁺,每个正样本对应的困难负样本 c⁻,其他查询的正负样本作为随机负样本
3.3 基于提示的多模态大模型重排序
背景:以往研究(Sun et al., 2023;Jin et al., 2024)表明,经过指令微调的大语言模型(LLMs)可以被提示(prompt)来对文本检索任务中的候选项进行重排序(reranking)。本文将该思路扩展至多模态检索场景,直接使用预训练的 LLaVA-Next(无需微调)对通用多模态检索器返回的 Top-10 候选项进行重排序。
方法:提示式重排序(Prompt-based Reranking)
通俗的话来说就是,通过提示的方法让大模型自己判断自己通过检索输出是否正确。
重排序被建模为一系列True/False 判断题,借鉴自 Nogueira et al. (2020)。对于每个“查询–候选项”对,构造一个任务特定的提示语句,要求模型判断该候选是否满足查询语义。
以下是两个提示示例:
-
图像标题检索提示格式:
<图像查询>
Caption: <候选文本>
以上日常图像与该标题匹配吗?True or False2. 视觉问答检索(任务5,图1)提示格式:
<图像查询>
Question: <问题文本>
Answer: <候选答案>
该答案是否正确回答了问题?True or False4 实验
为全面验证 MM-Embed 模型在通用多模态检索任务中的有效性,作者在多个标准基准数据集上进行了系统性实验。实验主要聚焦于以下三个方面:多模态检索性能、指令泛化能力以及重排序模块的补充增益,全面展示了模型在跨模态检索场景下的准确性、鲁棒性与泛化能力。
首先,在**通用多模态检索任务(Universal Multimodal Retrieval)**中,MM-Embed 在 M-BEIR 基准中所涵盖的 10 个数据集、16 个检索任务上进行了系统评估,涵盖图文匹配、图文交叉检索、图文混合检索等多种模态组合。实验显示,经过模态感知困难负样本挖掘与连续微调后,MM-Embed 的表现显著优于基于 CLIP 的传统检索模型,在 M-BEIR 上整体提升超过 5 个 nDCG@10 点,首次在该任务框架下实现多任务、多模态检索的统一优化。
其次,为评估模型在跨任务间的泛化能力,作者开展了多轮消融实验,分别去除指令输入、多任务训练、模态负样本等关键机制。结果表明,任务指令(Instruction)输入对于跨任务检索理解尤为重要,模态感知挖负则显著提升了模型对不同查询模态下目标模态的适配能力。此外,连续训练策略相比单阶段训练在多个任务上均表现更优,验证了该策略对复杂检索任务的适应性。
最后,作者进一步引入了零样本 MLLM 重排序器,用于对初步检索得到的候选项进行判别式排序优化。在 CIRCO、VQA、Composed Image Retrieval 等高难度任务中,该模块显著提升了准确率,最高提升超过 7 个点。该重排序器基于预训练的 LLaVA-Next 模型,采用“是否匹配”类 True/False 判断问题形式,无需额外微调,体现了大模型在零样本推理场景下的强大理解与泛化能力。
总体来看,MM-Embed 通过统一的多模态大语言模型架构、模态感知训练机制与轻量级推理增强模块,显著推动了通用多模态检索任务的性能边界。实验结果表明,该模型不仅具备对多种模态组合的兼容性,还在复杂跨模态检索任务中展现出极强的适应性与推广能力,为构建下一代多模态信息检索系统奠定了坚实基础。
5 总结
MM-Embed 在多项主流多模态检索任务上进行了全面实验,涵盖图文匹配、跨模态检索、指令泛化以及零样本重排序等方向。在通用多模态检索任务中,MM-Embed 在 M-BEIR 所覆盖的 COCO, CIRCO, VQAv2 等多个数据集上取得领先的 nDCG@10 分数,展现出出色的跨模态检索能力与模态适配能力。在跨模态理解任务中,模型能准确理解任务指令并进行图文对齐,优于传统 CLIP 检索器。进一步地,MM-Embed 通过引入模态感知困难负样本挖掘和连续训练策略,在多个复杂子任务中实现显著性能提升。最后,在使用零样本 LLaVA reranker 进行多模态理解重排序时,模型在 CIRCO 等任务中精度提升超过 7 个点,验证了大模型在复杂语义判断下的泛化能力。总体来看,实验结果全面验证了 MM-Embed 作为通用多模态检索框架的有效性与鲁棒性。
6 个人评价
(1) 它在模型架构上有效融合了多模态大语言模型的表示能力与检索任务需求,通过构建统一的检索器结构,兼容文本、图像及其组合形式,实现了高度灵活的模态支持。同时,设计中充分保留了语言模型原有的理解与生成能力,结构平衡,扩展性强。
(2) 通过引入模态感知困难负样本挖掘与多阶段训练策略,有效增强了模型在复杂跨模态检索任务中的泛化能力。从实验结果来看,无论是标准图文检索还是需要图文深度理解的任务(如视觉问答、组合图像检索),MM-Embed 均取得了显著性能提升,充分展现出其作为通用多模态检索框架的技术潜力。
(3) 这是一篇在方法设计与实验验证方面都十分扎实的工作,特别是在实际应用中对大模型如何用于多模态检索任务提供了清晰的范式指导,对今后多模态系统的构建具有很强的参考价值与工程启发性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)