OpenCV实现运动估计:块匹配与性能评估
OpenCV自1999年由英特尔公司发起,最初的设计目的是为了推动计算机视觉技术的普及和发展,使其能够更广泛地应用于现实世界中。随着版本的迭代,它已经从一个专注于实时视觉应用的项目,发展成为了一个包含超过2500种优化算法的强大库,这些算法覆盖了从基础图像处理到高级机器学习等众多领域。块匹配方法是一种广泛应用于运动估计的算法,它将当前帧分割为若干个大小相同的块,然后在前一帧中寻找与之最相似的块。这

简介:计算机视觉中的运动估计对于视频编码和分析至关重要。本文介绍了如何使用OpenCV库实现基于块匹配的运动估计方法,包括穷尽搜索和三步搜索算法。内容涵盖从图像预处理到运动矢量计算、预测帧生成、预测误差和PSNR值的计算。本文还探讨了提高匹配精度和效率的优化策略,以及如何处理快速运动或遮挡情况。
1. 运动估计在计算机视觉中的作用
在计算机视觉领域,运动估计是实现视频分析和理解的重要基石之一。它涉及计算机视觉技术来检测和分析图像序列中物体的运动。通过识别物体在连续帧之间的移动,运动估计对于诸多应用如视频压缩、目标追踪、3D重建以及机器人导航等都至关重要。
1.1 从静态到动态:计算机视觉的转变
计算机视觉的传统任务集中于静态图像的分析,例如物体识别、场景分类等。然而,随着技术的进步,动态场景的理解变得愈发重要。运动估计使得计算机能够不仅捕捉图像的外观特征,还能理解它们随时间的动态变化,实现更为复杂的视觉任务。
1.2 运动估计在实际应用中的价值
运动估计的应用极为广泛,例如在自动驾驶汽车中,它帮助系统理解车辆周围环境的变化;在视频监控系统中,可以用来检测异常行为;在电影行业,通过运动估计技术,可以在后期制作中实现更加逼真的特效。这些仅是冰山一角,随着AI和深度学习技术的发展,运动估计在计算机视觉中的作用正变得越来越大。
2. OpenCV库的应用
在探讨运动估计的应用和重要性之前,我们需要了解一个关键的计算机视觉库:OpenCV。OpenCV,即Open Source Computer Vision Library,是一个开源的计算机视觉和机器学习软件库。它提供了大量用于图像处理、视频分析和机器学习等任务的函数和算法。本章将深入探讨OpenCV库的方方面面。
2.1 OpenCV库简介
2.1.1 OpenCV的历史和发展
OpenCV自1999年由英特尔公司发起,最初的设计目的是为了推动计算机视觉技术的普及和发展,使其能够更广泛地应用于现实世界中。随着版本的迭代,它已经从一个专注于实时视觉应用的项目,发展成为了一个包含超过2500种优化算法的强大库,这些算法覆盖了从基础图像处理到高级机器学习等众多领域。
2.1.2 OpenCV的主要功能和模块
OpenCV主要分为以下几个模块:
- 核心功能模块(core) :提供了基本的数据结构和系统功能,包括矩阵操作、绘图函数、数组操作等。
- 图像处理模块(imgproc) :包含了丰富的图像处理函数,例如滤波、形态学操作、几何变换、颜色空间转换等。
- 视频分析模块(video) :提供了运动分析、对象跟踪和视频分割等算法。
- 高级模块 :如机器学习(ml),优化(optflow),特征2D(features2d),和深度学习(dnn)模块等,涵盖了更多高级和专业化的功能。
2.2 OpenCV在运动估计中的应用
2.2.1 OpenCV中运动估计的相关函数
OpenCV中的运动估计通常是通过其 optflow 模块进行的。该模块提供了多种用于估计光流的算法,其中一些算法可以被用来进行运动估计。
在 optflow 模块中,如 cv2.calcOpticalFlowPyrLK 函数,就提供了一个强大的工具来估计连续帧之间的像素点运动。它使用了著名的Lucas-Kanade算法,并采用金字塔方法来处理不同尺度的图像。
此外,还有 cv2.estimateAffinePartial2D 函数,可以用来估计图像序列中两帧之间的仿射变换。仿射变换通常包含平移、旋转和缩放等变换,这是运动估计的重要组成部分。
2.2.2 OpenCV对图像数据的处理能力
OpenCV对于图像数据的处理非常高效。它对图像数据格式进行了优化,使用Mat类来表示图像。Mat类可以有效地存储和处理大型二维或三维数组,并且提供了丰富的操作接口。
在处理图像时,OpenCV使用了C++的STL(Standard Template Library)风格的接口,这使得对图像数据的处理更加简洁和直观。此外,由于OpenCV对底层优化的重视,它在图像处理的速度上也非常出色,适合进行实时视频处理和运动估计。
以下是使用OpenCV进行运动估计的一个基础代码示例:
#include <opencv2/opencv.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/video.hpp>
#include <opencv2/highgui.hpp>
using namespace cv;
int main(int argc, char** argv) {
// 打开摄像头或视频文件
VideoCapture capture(0);
if (!capture.isOpened()) {
std::cerr << "Error opening video capture" << std::endl;
return -1;
}
Mat frame, prevgray, frame_gray;
capture >> frame;
// 转换为灰度图
cvtColor(frame, frame_gray, COLOR_BGR2GRAY);
// 初始化用于光流计算的图像
goodFeaturesToTrack(frame_gray, prevgray);
while (capture.read(frame)) {
// 对新读入的帧转换为灰度图
cvtColor(frame, frame_gray, COLOR_BGR2GRAY);
// 计算光流并绘制
vector<uchar> status;
vector<float> err;
Mat newgray = frame_gray;
Mat nextgray;
std::vector<Point2f> p;
if (!prevgray.empty()) {
calcOpticalFlowPyrLK(prevgray, newgray, prev, p, status, err);
// 在图像上绘制追踪的点和新的特征点
for (size_t i = 0; i < prev.size(); i++) {
if (status[i] == 1) {
cv::line(frame, prev[i], p[i], cv::Scalar(0, 255, 0), 2);
cv::circle(frame, p[i], 3, cv::Scalar(0, 255, 0), -1);
}
}
// 更新前一帧的图像
std::swap(prevgray, nextgray);
}
// 更新前一帧的点
prev = p;
// 显示结果
imshow("frame", frame);
char c = (char)waitKey(33);
if (c == 27)
break;
}
return 0;
}
在上述代码中,我们使用了 goodFeaturesToTrack 来选择图像中有效的特征点,然后使用 calcOpticalFlowPyrLK 来计算这些特征点在连续两帧图像中的运动。值得注意的是,这个简单的例子没有进行运动估计的详细分析,如误差分析和优化处理,但它为我们提供了一个运动估计的基本框架。
使用OpenCV进行运动估计,不仅可以简化开发流程,还由于其高效的算法和对底层硬件的优化,使得处理大数量级的图像数据变得可行,这是实现高质量运动估计的基石。
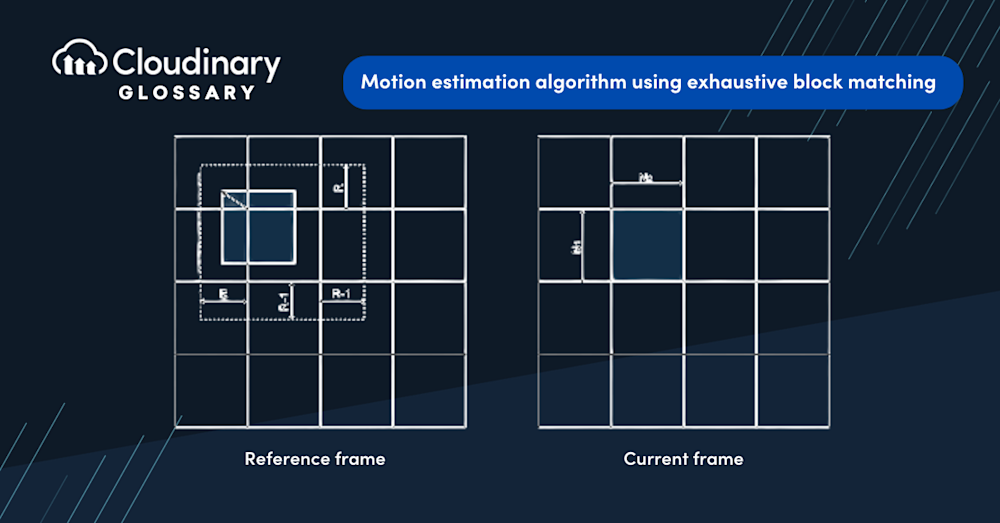
3. 块匹配方法概述
3.1 块匹配方法的基本原理
块匹配方法是一种广泛应用于运动估计的算法,它将当前帧分割为若干个大小相同的块,然后在前一帧中寻找与之最相似的块。这种相似度通常是基于像素值的差异来衡量的。
3.1.1 块匹配的定义和目的
块匹配是计算机视觉中的一项技术,用于确定在连续视频帧之间,哪些区域或对象已经移动或发生了变化。其核心在于将图像划分成若干个像素块,并对每个块在另一帧图像中寻找最匹配的对应块。这种方法特别适用于处理视频中的运动对象检测、运动补偿和对象跟踪等任务。通过块匹配,可以有效地估计出图像间的运动,进而构建起精确的运动矢量,为预测帧生成提供了基础。
3.1.2 块匹配算法的基本步骤
块匹配算法大致可以分为以下几个步骤:
- 图像帧划分 :将当前帧(搜索帧)划分为若干固定大小的块。
- 块特征提取 :对每个块计算特征,如均值、梯度、直方图等。
- 搜索范围确定 :根据可能的运动范围确定在另一帧(参考帧)中的搜索窗口。
- 相似度计算 :使用适当的相似度度量方法(如SAD、SSD)来计算当前块与参考帧中候选块之间的相似度。
- 最佳匹配块选择 :根据相似度度量结果,选择最相似的块作为匹配块。
- 运动矢量计算 :通过当前位置和匹配块位置的偏移计算出运动矢量。
3.2 常见块匹配技术的对比
块匹配算法虽然基本原理相同,但不同的实现方式会带来不同的性能表现。了解不同算法的优缺点,有助于针对具体应用场景做出更好的技术选择。
3.2.1 各种块匹配技术的优缺点
- 全搜索块匹配(FS) :这种方法会考虑参考帧中的所有可能块作为匹配候选,因此可以得到全局最优解,但其计算成本极高,不适用于实时应用。
- 三步搜索(TSS) :通过逐步缩小搜索范围来减少计算量,虽然速度更快,但可能丢失全局最优,导致匹配精度下降。
- 四步搜索(FSS) :它是TSS的改进版,考虑了块间的几何中心,以期在速度和精度之间取得更好的平衡。
- 梯度下降搜索(GDS) :这种方法根据梯度信息进行搜索,计算量小,但容易陷入局部最优。
3.2.2 适用场景和效果比较
不同场景对块匹配算法的要求不尽相同:
- 实时性要求高 :在实时视频处理或视频编码中,算法的速度尤为重要。在此类应用中,三步搜索或四步搜索可能更受青睐。
- 精度要求高 :如在计算机视觉中的目标跟踪、3D重建等任务中,可能会选择全搜索或梯度下降搜索以提高匹配精度。
- 硬件限制 :在嵌入式系统或移动设备上,资源受限导致需要在算法复杂度和性能之间做权衡,可能会选择更为优化的自适应算法。
块匹配技术的选择通常需要在精度和效率之间做出折衷。在实际应用中,也常常结合多种技术,通过软件优化和硬件加速的方式来提升整体性能。
4. 搜索算法详解
4.1 穷尽搜索算法MBA
4.1.1 MBA算法的流程和原理
穷尽搜索算法(Full Search Block Matching, FSBM),又称为全搜索块匹配算法(MBA),是一种最直观的运动估计算法。其核心思想是在参考帧中以当前处理块为中心,对一个搜索窗口内的所有可能位置进行遍历,计算出与当前块最相似的位置,并将其作为最佳匹配位置,从而得到运动矢量。
在具体实现时,MBA算法会计算目标块与参考帧中每个可能的候选块之间的相似度。相似度度量通常使用绝对差值和(Sum of Absolute Difference, SAD)或平方差和(Sum of Squared Difference, SSD)。之后,算法会找出具有最小相似度度量值的位置,该位置与目标块的偏移量即为运动矢量。
尽管MBA算法实现简单,计算量却非常大。对于一个大小为M×N的块,需要对(2W+1)×(2H+1)个位置进行搜索,其中W和H分别是搜索窗口的宽度和高度,导致算法的时间复杂度高达O((2W+1)×(2H+1))。
4.1.2 MBA算法的优化思路
由于MBA算法计算复杂度过高,优化算法性能成为研究的重点。常见的优化方法有:
- 多分辨率搜索 :首先在低分辨率的图像上进行搜索,快速定位到最佳匹配块的大致位置,然后再在较高分辨率的图像上进行细化搜索。
- 基于启发式规则的搜索 :利用历史运动信息或者块的特性来确定搜索顺序和范围,例如三步搜索法(Three-Step Search, TSS)、菱形搜索法(Diamond Search, DS)等。
4.2 三步搜索法EMBA
4.2.1 EMBA算法的流程和原理
为了减少搜索点的数量,提高搜索效率,三步搜索法(Exponential Search, EMBA)采用了非对称的搜索策略。该算法首先在水平和垂直方向上以指数级别增加搜索步长,确定搜索范围的大概位置,然后再以固定步长进行局部细化搜索。
EMBA算法的搜索过程分为两个阶段:
- 大步长阶段 :从当前块的中心位置开始,先水平方向上以指数级步长进行搜索(步长通常为1, 2, 4, …),找到使得相似度量值最小的位置,然后再垂直方向上重复此过程。
- 小步长阶段 :以第1步找到的最佳匹配位置为中心,用较小的固定步长(如1)在局部区域进行搜索,确定最终的最佳匹配块位置。
4.2.2 EMBA算法的优化思路
EMBA算法通过减少搜索点的数量,显著降低了计算量。然而,它仍然存在一些不足,例如对于快速运动的视频序列,其初始步长可能过大,导致无法准确捕捉到运动目标的位置。为了进一步提高EMBA的性能,可以采用以下优化策略:
- 自适应步长调整 :根据视频序列的运动特征,动态调整初始搜索步长和局部细化搜索步长,以便算法更加灵活地适应不同的运动场景。
- 预测与校正机制 :使用相邻块的运动信息或全局运动模型进行运动预测,然后结合EMBA搜索结果进行校正,减少搜索范围,提升效率。
graph LR
A[开始] --> B[初始化搜索步长]
B --> C[大步长搜索]
C --> D[确定搜索范围]
D --> E[小步长搜索]
E --> F[确定最佳匹配块]
F --> G[结束]
代码块示例:
def exponential_search(block, reference, max_range):
step = 1
pos = block.location
min_sad = float('inf')
min_pos = None
# 大步长搜索
while pos.x + step < reference.width and pos.y + step < reference.height:
block_pos = (pos.x + step, pos.y)
sad = calculate_sad(block, reference, block_pos)
if sad < min_sad:
min_sad = sad
min_pos = block_pos
pos = (pos.x + step, pos.y + step)
step *= 2
# 小步长搜索
step = 1
pos = (min_pos[0] - step, min_pos[1] - step)
while pos.x < min_pos[0] and pos.y < min_pos[1]:
block_pos = (pos.x, pos.y)
sad = calculate_sad(block, reference, block_pos)
if sad < min_sad:
min_sad = sad
min_pos = block_pos
pos = (pos.x + step, pos.y + step)
step = 1
return min_pos
# 辅助函数计算SAD值
def calculate_sad(block, reference, position):
# 这里需要实现SAD计算逻辑
pass
在上述代码中, exponential_search 函数实现了EMBA算法的主体逻辑。首先定义了一个大步长搜索阶段,然后是小步长搜索阶段。需要注意的是,这里使用了假设的 calculate_sad 函数来计算SAD值,该函数需要开发者根据实际情况实现。通过调整 max_range 和步长策略,可以对算法性能进行进一步优化。
通过以上内容,本章节针对MBA和EMBA算法的原理、流程、优化思路,以及相关代码示例进行了详细介绍。这些内容为读者提供了深入理解搜索算法的背景和应用,对于5年以上的IT行业从业者来说,将具有较高的实用价值和参考意义。
5. 图像预处理与相似度度量技术
5.1 图像预处理步骤
图像预处理是运动估计流程中至关重要的一步,它涉及到从原始图像数据中去除噪声、增强图像的某些特征、标准化图像的大小和范围等,最终目的是提高运动估计的准确性和可靠性。
5.1.1 图像预处理的必要性
在实际的图像处理和计算机视觉任务中,原始图像通常包含噪声、光照变化、阴影以及不同成像条件下的各种干扰。这些因素都会影响到运动估计的准确性。因此,图像预处理的必要性主要体现在以下几点:
- 噪声去除:减少图像中的随机噪声,如传感器噪声、传输过程中的干扰等,以提高图像质量。
- 对比度增强:提高图像的对比度,使得特征更加明显,便于后续的特征提取和匹配。
- 尺寸归一化:确保输入图像具有统一的尺寸和比例,这有利于算法实现的标准化和提升处理速度。
- 色彩空间转换:将图像从一个色彩空间转换到另一个色彩空间,例如从RGB转换到YUV或灰度空间,以便于特征的提取和计算。
5.1.2 具体预处理方法介绍
接下来介绍一些常见的图像预处理方法:
- 灰度化 :将彩色图像转换为灰度图像,这一步可以简化数据量,因为灰度图像仅包含亮度信息。对于运动估计而言,颜色信息在很多情况下并不是必须的,灰度图像足以提供足够的信息。
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化处理
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 显示图像
cv2.imshow('Original Image', image)
cv2.imshow('Grayscale Image', gray_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 滤波去噪 :应用高斯滤波、中值滤波等方法对图像进行平滑处理,减少随机噪声。
- 直方图均衡化 :通过拉伸图像的对比度来增强图像的全局亮度。它有助于在不同的光照条件下得到较为一致的结果。
- 大小调整 :根据需求将图像的尺寸调整到适当的大小。这一步骤有利于提高处理速度,并保证算法对不同分辨率的图像均具有较好的适应性。
# 调整图像大小
resized_image = cv2.resize(gray_image, (width, height))
# 显示图像
cv2.imshow('Resized Image', resized_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 色彩空间转换 :如将RGB图像转换为YUV或HSV色彩空间,因为YUV空间中的Y分量直接代表了亮度信息,而U和V分量则提供了色度信息,这有助于后续的特征提取。
# RGB到YUV的转换
yuv_image = cv2.cvtColor(resized_image, cv2.COLOR_BGR2YUV)
# 显示YUV图像
cv2.imshow('YUV Image', yuv_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
5.2 相似度度量技术(SAD和SSD)
在运动估计中,相似度度量技术用于评估图像块之间的相似性,是计算运动矢量的重要基础。常用的相似度度量方法包括绝对差值和(Sum of Absolute Differences, SAD)和平方差和(Sum of Squared Differences, SSD)。
5.2.1 SAD和SSD的概念与计算
- SAD : SAD通过计算两个图像块对应像素绝对值的差之和来评估它们的相似度。公式如下:
[ SAD = \sum_{i=0}^{N-1} | f(x+i, y) - g(x+i, y) | ]
其中,( f )和( g )分别表示当前帧和参考帧的图像块,( (x, y) )表示当前块的起始坐标。
- SSD : SSD则计算两个图像块对应像素差的平方和来评估相似度。公式如下:
[ SSD = \sum_{i=0}^{N-1} ( f(x+i, y) - g(x+i, y) )^2 ]
在实际应用中,SAD的计算速度通常比SSD更快,因为它是简单的加法和绝对值运算。而SSD的计算较为复杂,但是由于平方运算,它对亮度变化更敏感,可以提供更精细的相似度度量。
5.2.2 SAD与SSD的适用场景和比较
- 适用场景 : SAD适合于对速度要求较高的实时应用,例如视频编码中。SSD则适合于对准确性要求较高的场合,如图像质量评估。
- 比较 : 尽管SSD提供了更好的度量精度,但其计算成本更高。而SAD虽然度量精度略逊一筹,但速度更快,更适合实时系统。
| 相似度度量 | 优点 | 缺点 |
|---|---|---|
| SAD | 计算快速,适用于实时系统 | 对光照变化的适应性较弱 |
| SSD | 对光照变化和亮度差异敏感,度量精度较高 | 计算成本高,不适合实时应用 |
在实际应用中,可根据具体需求选择合适的度量方法。下面是一个SAD函数的Python代码实现,用于计算两个图像块之间的相似度:
import numpy as np
def calculate_sad(block1, block2):
"""
计算两个图像块之间的SAD值。
:param block1: 图像块1
:param block2: 图像块2
:return: SAD值
"""
return np.sum(np.abs(block1 - block2))
# 示例使用
block1 = np.random.randint(0, 255, size=(8, 8), dtype=np.uint8)
block2 = np.random.randint(0, 255, size=(8, 8), dtype=np.uint8)
sad_value = calculate_sad(block1, block2)
print(f"SAD Value: {sad_value}")
通过相似度度量技术,我们能够定量地分析图像块之间的差异,进而为运动矢量的计算提供基础。这为运动估计提供了坚实的技术支撑。
6. 运动矢量计算与预测帧生成
6.1 运动矢量的计算方法
6.1.1 运动矢量的定义和计算公式
运动矢量(Motion Vector, MV)在计算机视觉和视频编码领域中用来表示图像序列中某一帧图像相对于其参考帧的位移信息。它通常由水平分量和垂直分量组成,用于描述图像内容的运动趋势和幅度。在视频压缩编码中,运动矢量可以用来预测当前帧中的宏块或块,从而减少帧间冗余信息。
计算运动矢量的公式可以简化为以下形式:
[ MV = (MV_x, MV_y) ]
其中 ( MV_x ) 和 ( MV_y ) 分别表示水平和垂直方向上的分量,可以通过以下步骤计算:
- 确定参考帧和当前帧中要进行运动估计的区域。
- 在当前帧中选定的区域内定义一个块。
- 在参考帧中选择一个搜索范围来寻找与当前块最相似的匹配块。
- 使用相似度度量技术(如SAD或SSD)评估候选块之间的相似度。
- 选择相似度最高的匹配块,计算出当前块相对于匹配块的位移。
- 将计算出的位移作为运动矢量。
6.1.2 运动矢量的估计误差分析
运动矢量的估计误差是衡量运动估计准确性的关键指标之一。误差分析通常涉及运动矢量的准确度和一致性。准确度指的是估计的运动矢量与真实运动矢量之间的接近程度,而一致性则反映了同一场景内运动矢量的稳定性和可靠性。
误差可以通过以下方式计算:
- 通过比较真实运动矢量与估计得到的运动矢量之间的差异。
- 使用诸如平均绝对误差(Mean Absolute Error, MAE)、均方根误差(Root Mean Square Error, RMSE)等指标进行量化。
- 分析误差的分布情况,比如是否存在系统性的偏差或随机波动。
理解误差的来源对于提高运动矢量估计的准确性和鲁棒性至关重要。误差可能来源于多种因素,包括图像噪声、遮挡、光照变化、运动模糊等。准确分析这些误差并优化算法,能够有效提升视频质量并减少编码比特率。
6.2 预测帧的生成过程
6.2.1 预测帧生成的步骤
预测帧生成是视频压缩编码中的一个关键步骤,其主要目的是利用已知的参考帧和计算得到的运动矢量来生成当前帧的近似表示。这个过程的关键在于运动矢量的准确性和有效的像素值预测。具体步骤如下:
- 选择参考帧 :确定当前帧的参考帧,可以是上一帧、上两帧或其他已经编码的帧。
- 块匹配 :在参考帧中根据计算出的运动矢量找到对应的匹配块。
- 生成预测块 :使用匹配块中的像素值来构造当前块的预测值。
- 残差计算 :将当前块的实际像素值与预测块的像素值进行比较,计算残差(即差值)。
- 编码与传输 :编码残差数据并将其与运动矢量一起传输给解码器。解码器利用这些信息重建当前帧。
6.2.2 生成预测帧的关键技术点
生成预测帧的技术点主要包括以下几点:
- 运动估计技术 :确定使用哪种运动估计算法,比如全搜索、三步搜索(TSS)、菱形搜索(DS)等。
- 块大小选择 :选择合适大小的块进行运动估计,常见的有16x16、8x8、4x4等。
- 像素插值方法 :运动矢量可能会指向参考帧中的非整数像素位置,需要适当的插值方法(如双线性插值)来计算像素值。
- 多参考帧和多方向预测 :使用多个参考帧和双向预测可以提升预测效果,尤其是对于复杂场景和快速运动。
- 误差容忍度与量化 :在编码残差时,根据需要进行误差容忍度设置,并应用适当的量化策略以减小传输数据量。
以下是生成预测帧的一个简单伪代码示例:
def generate_prediction_frame(reference_frame, motion_vectors):
prediction_frame = create_empty_frame_like(reference_frame)
for (block_x, block_y), (mv_x, mv_y) in motion_vectors.items():
reference_block = get_block_at(reference_frame, block_x + mv_x, block_y + mv_y)
prediction_block = reference_block # In the case of simple block copy
prediction_frame[block_x:block_x+block_size, block_y:block_y+block_size] = prediction_block
return prediction_frame
在上述代码中, motion_vectors 字典存储了每个块的坐标和对应的运动矢量。 reference_frame 是参考帧, prediction_frame 是初始化的空帧,用于存放生成的预测帧。这个函数仅仅进行了简单的块复制,实际应用中还需要考虑插值等更复杂的情况。
生成预测帧是视频编码中减少冗余信息、提高压缩比的关键步骤,它依赖于运动矢量的准确性和预测算法的有效性。通过优化这些技术点,可以显著提升视频的压缩效率和视觉质量。
7. 性能评估与优化策略
7.1 预测误差的计算方法
预测误差是衡量运动估计效果的关键指标,它能够反映出预测帧和实际帧之间的差异程度。预测误差的计算方法多种多样,最常用的是绝对误差和(Sum of Absolute Difference, SAD)和平方差和(Sum of Squared Difference, SSD)。
7.1.1 预测误差的定义和计算
绝对误差和 SAD 是通过计算每一块像素中所有像素点的绝对差值之和来得到的。具体公式如下:
[ SAD = \sum_{x=1}^{w}\sum_{y=1}^{h} | I_{t}(x + u, y + v) - I_{t-1}(x, y) | ]
其中,( I_{t} ) 是当前帧,( I_{t-1} ) 是参考帧,( (u, v) ) 是运动矢量的分量,( w ) 和 ( h ) 分别代表块的宽度和高度。
平方差和 SSD 的计算则是用每块像素点差值的平方和代替绝对值,公式如下:
[ SSD = \sum_{x=1}^{w}\sum_{y=1}^{h} (I_{t}(x + u, y + v) - I_{t-1}(x, y))^2 ]
SAD 与 SSD 之间的区别主要在于对异常值的敏感性。SAD 对于异常值更为鲁棒,而 SSD 对异常值更为敏感。
7.1.2 预测误差的统计分析
预测误差的统计分析涉及到计算所有块的预测误差,并进行平均值或中位数计算,以便得出整体的误差水平。此外,还可以绘制误差分布图,分析误差分布情况,以及是否存在异常值。
import numpy as np
def calculate_sad(block, reference_block):
"""
Calculate the Sum of Absolute Difference (SAD) between two blocks.
"""
return np.sum(np.abs(block - reference_block))
def calculate_ssd(block, reference_block):
"""
Calculate the Sum of Squared Difference (SSD) between two blocks.
"""
return np.sum((block - reference_block) ** 2)
7.2 PSNR(峰值信噪比)的计算
PSNR 是衡量视频或图像质量的重要指标,它基于均方误差(Mean Squared Error, MSE)来计算。
7.2.1 PSNR的定义和重要性
PSNR 通过以下公式来定义:
[ PSNR = 20 \cdot \log_{10}(MAX_I) - 10 \cdot \log_{10}(MSE) ]
其中,(MAX_I) 是图像像素值可能的最大幅值(例如,在8位深度的灰度图像中为255),MSE 是均方误差。
PSNR 越高,表示图像质量越好。它是一个标准化的指标,可以用于不同图像或视频序列之间的质量比较。
7.2.2 PSNR在运动估计中的应用
在运动估计中,PSNR 可以用来评估运动估计效果的好坏。通常,我们会在编码后计算重构帧的 PSNR,以此来衡量编码器的性能。
def mse(imageA, imageB):
"""
Calculate mean-squared-error between two images.
"""
err = np.sum((imageA.astype("float") - imageB.astype("float")) ** 2)
err /= float(imageA.shape[0] * imageA.shape[1])
return err
def psnr(mse_value, max_value=255.0):
"""
Calculate the PSNR for two images.
"""
return 20 * np.log10(max_value) - 10 * np.log10(mse_value)
7.3 匹配精度和效率的优化策略
优化匹配精度和算法效率是运动估计领域中的热点问题。为了提升匹配精度和算法效率,研究人员和工程师采取了多种策略。
7.3.1 提升匹配精度的方法
- 使用更高精度的块匹配算法。
- 通过滤波预处理减少噪声对匹配的影响。
- 利用机器学习方法对运动矢量进行优化。
- 应用多尺度策略,先在低分辨率上粗匹配,再逐步精细化。
7.3.2 提高算法效率的策略
- 算法的硬件加速,如使用GPU或专用硬件。
- 算法优化,减少不必要的计算,如有效利用图像的时空连续性。
- 采用更有效的搜索策略,如自适应搜索范围和步长。
7.4 快速运动和遮挡问题的处理
快速运动和遮挡是运动估计中常见的两个问题,它们会对匹配结果产生负面影响。
7.4.1 快速运动对匹配的影响
快速运动会导致匹配的块在相邻帧间发生显著的位置偏移,传统的块匹配算法难以适应。解决这一问题需要采用更为复杂的模型,如基于光流的方法或利用时空一致性约束的匹配技术。
7.4.2 遮挡问题的识别和处理方法
遮挡问题的处理通常包括以下几种策略:
- 遮挡检测算法用于识别图像中的遮挡区域。
- 算法需要区分出遮挡、运动边缘和静态背景。
- 对于遮挡区域,可以采用时空插值或基于先验知识的方法。
综上所述,性能评估与优化策略是运动估计中一个不可或缺的部分。通过计算预测误差、PSNR值、优化匹配精度和效率,以及处理快速运动和遮挡问题,可以有效地提升运动估计的整体性能。
简介:计算机视觉中的运动估计对于视频编码和分析至关重要。本文介绍了如何使用OpenCV库实现基于块匹配的运动估计方法,包括穷尽搜索和三步搜索算法。内容涵盖从图像预处理到运动矢量计算、预测帧生成、预测误差和PSNR值的计算。本文还探讨了提高匹配精度和效率的优化策略,以及如何处理快速运动或遮挡情况。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)