一套小连招搞定文章评论审核!Java实战篇(结合DeepSeek实现)
前言
最近给自己的笔记网站增加了一个用户评论功能,由于网站公开访问,所以评论内容的审核就显得尤为重要。一方面,如果有人恶意刷评论,那么评论区将会充斥着各种无关评论,另一方面,如果有用户发布违禁内容,作为站长没有发现,那估计得进去喝茶了。所以保险起见我必须要对评论的内容做极为严格的审核。以下我研究多日整理的一套方案,目前测试审核准确率达到 99.99%。特此分享一下。
实现思路
开发前期我也调研了很多评论审核相关的内容,发现几种主流的方案:
- 本地词库结合Trie树(前缀树)的敏感词检测算法
- 开源的敏感词库组件(sensitive-word)
- 第三方平台的内容安全审核 API(京东云、阿里云、腾讯云、百度云、等等…)
但经过一番比较我发现无论哪种方案都不够完美,本地词库依赖敏感词的数据量,需要定期维护新的敏感词,需要人工投入;开源的敏感词库组件又依赖组件自身的词库,部分生僻或者新潮的敏感词无法准确校验;第三方平台的服务倒是很好用,但是算起来也很贵,这个小破站不值得用这么好的。
万般无奈之下我想到了一个点子:现在 AI 这么火,我能不能用 AI 来帮我审核呢,所以我就以 DeepSeek 为例测试了一下,测试结果基本符合预期,由于内容包含敏感词,这里就不展示了,自行脑补一下。但调用 AI 接口响应比较慢,而且单 AI 审核的准确率无法保证,所以我决定直接放出一套小连招,上面的四种方案一起用,根据权重决定,所以就有了下面的方案。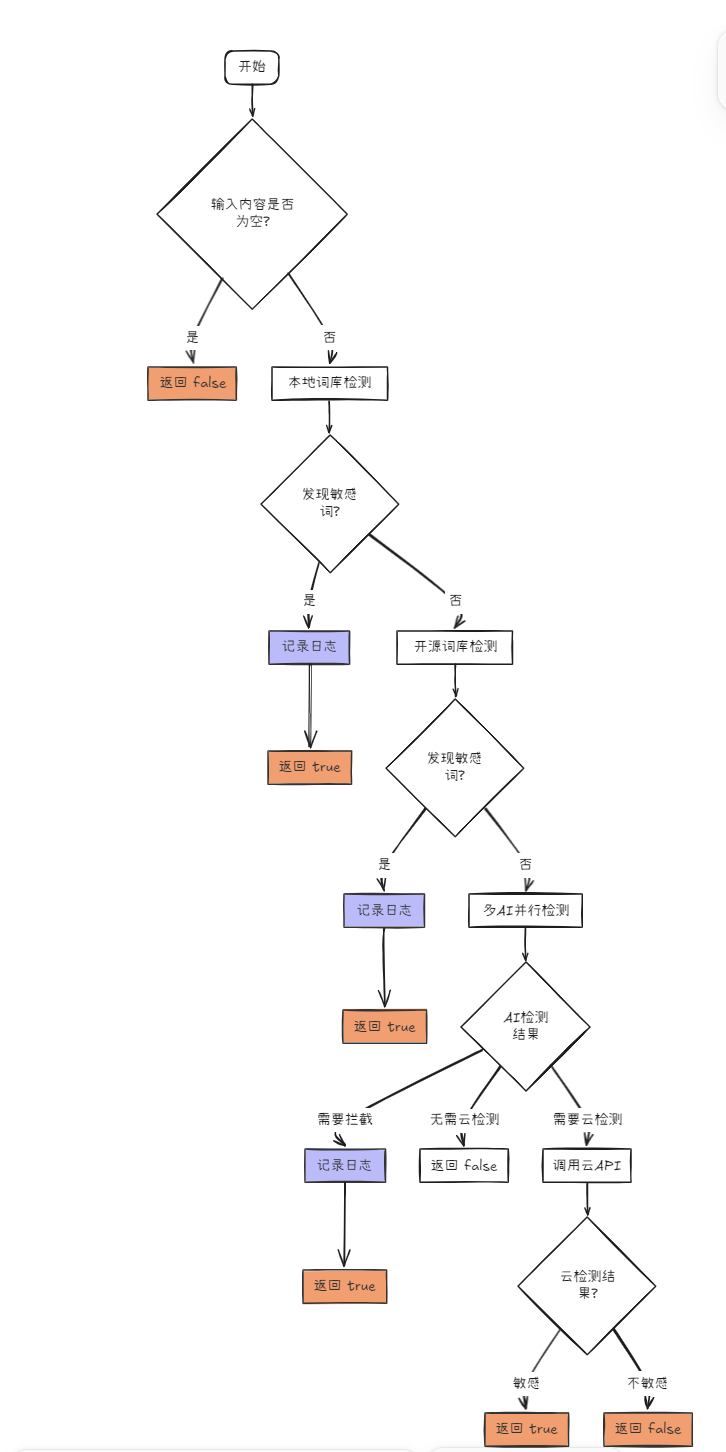
具体实现
具体实现上我们主要针对提到的四种判断方式进行分步讲解。
本地敏感词库校验
实现思路
本地词库结合 Trie 树(前缀树)的敏感词检测算法,这种算法也是目前比较通用的敏感词算法。实现原理也很简单,如示例:
敏感词库:[“中国”, “中国人”, “美国”]
构建的Trie树:
root
/
中美
/
国国
/
人
其中,“国”节点(在“中”下面)和“人”节点(在“国”下面)以及“国”节点(在“美”下面)都是结束节点。
检测文本:“我是中国人”
检测过程:
- 从第一个字符“我”开始,不在根节点的子节点中(根节点有“中”和“美”),跳过。
- 到“是”,同样跳过。
- 到“中”,匹配到,进入“中”节点;下一个字符“国”,匹配到“中”节点的子节点“国”,并且“国”是结束节点,所以检测到敏感词“中国”。
- 继续:在“国”节点下,下一个字符是“人”,匹配到“国”节点的子节点“人”(假设我们构建了“中国人”这个词,那么“中”->“国”->“人”),并且“人”是结束节点,所以检测到敏感词“中国人”。
代码实现
package com.muke.base.common.utils;
import jodd.util.StringUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
import javax.annotation.PostConstruct;
/**
* @Description: 敏感词校验工具类
* @author: 专业bug开发(kk)
* @date: 2025年04月06日 14:42
*/
@Slf4j
@Component
public class SensitiveUtil {
/**
* 敏感词文件
*/
private static final String SENSITIVE_WORD = "sensitive-words.txt";
/**
* 根节点
*/
private static final TrieNode ROOT_NODE = new TrieNode();
@PostConstruct
public void init() {
try (
InputStream is = this.getClass().getClassLoader().getResourceAsStream(SENSITIVE_WORD);
BufferedReader reader = new BufferedReader(new InputStreamReader(Objects.requireNonNull(is)))
) {
String keyword;
while ((keyword = reader.readLine()) != null) {
// 添加到前缀树
this.addKeyword(keyword);
}
} catch (Exception e) {
log.warn("加载敏感词文件失败:{} ", e.getMessage());
}
}
/**
* 将一个敏感词添加到前缀树中
*
* @param keyword 敏感词
*/
private void addKeyword(String keyword) {
TrieNode tempNode = ROOT_NODE;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if (subNode == null) {
// 初始化子节点
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指向子节点,进入下一轮循环
tempNode = subNode;
// 设置结束标识
if (i == keyword.length() - 1) {
tempNode.setKeywordEnd(true);
}
}
}
/**
* 过滤敏感词
*
* @param text 待过滤的文本
* @return 过滤后的文本
*/
public static boolean containsSensitiveWords(String text) {
// 空文本直接返回false
if (StringUtil.isBlank(text)) {
return false;
}
// 指针1 - 当前Trie节点
TrieNode tempNode = ROOT_NODE;
// 指针2 - 检测起始位置
int begin = 0;
// 指针3 - 当前检测位置
int position = 0;
while (position < text.length()) {
char c = text.charAt(position);
// 跳过符号
if (isSymbol(c)) {
// 如果在根节点,移动起始位置
if (tempNode == ROOT_NODE) {
begin++;
}
position++;
continue;
}
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if (tempNode == null) {
// 不是敏感词,从下一个位置重新开始检测
position = ++begin;
tempNode = ROOT_NODE;
} else if (tempNode.isKeywordEnd()) {
// 发现完整的敏感词,立即返回true
return true;
} else {
// 继续检查下一个字符
position++;
}
}
return false;
}
/**
* 判断是否为符号
*
* @param c 字符
* @return 判断
*/
private static boolean isSymbol(Character c) {
// 0x2E80~0x9FFF 是东亚文字范围
return !isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
}
public static boolean isAsciiAlpha(char ch) {
return isAsciiAlphaUpper(ch) || isAsciiAlphaLower(ch);
}
public static boolean isAsciiAlphaUpper(char ch) {
return ch >= 'A' && ch <= 'Z';
}
public static boolean isAsciiAlphaLower(char ch) {
return ch >= 'a' && ch <= 'z';
}
public static boolean isAsciiNumeric(char ch) {
return ch >= '0' && ch <= '9';
}
public static boolean isAsciiAlphanumeric(char ch) {
return isAsciiAlpha(ch) || isAsciiNumeric(ch);
}
/**
* 前缀树
*/
private static class TrieNode {
// 关键词结束标识
private boolean isKeywordEnd = false;
// 子节点
private final Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
// 添加子节点
public void addSubNode(Character c, TrieNode node) {
subNodes.put(c, node);
}
// 获取子节点
public TrieNode getSubNode(Character c) {
return subNodes.get(c);
}
}
}
使用示例:
//1.本地词库检测
if (SensitiveUtil.containsSensitiveWords(content)) {
log.info("本地词库检测为敏感词");
return true;
}
开源敏感词校验
sensitive-word 基于 DFA 算法实现的高性能敏感词工具。这里只演示简单的实现,具体使用可以参考官方文档。
引入方法:
<dependency>
<groupId>com.github.houbb</groupId>
<artifactId>sensitive-word</artifactId>
<version>0.26.0</version>
</dependency>
使用方法:
//2.开源词库检测
if (SensitiveWordHelper.contains(content)) {
log.info("开源词库检测为敏感词");
return true;
}
AI 敏感词校验
实现思路
接入硅基流动的模型广场大模型,接入方式参考官方文档:也可以参考其他文章,比如:https://zhuanlan.zhihu.com/p/29891194096
<dependency>
<groupId>io.github.pig-mesh.ai</groupId>
<artifactId>deepseek-spring-boot-starter</artifactId>
<version>1.4.5</version>
</dependency>
- 短文本快速通道:对5字符以下的短内容使用单一高优先级模型快速检测
- 中长文本并行检测:对更长的内容采用多模型并行检测+智能决策机制
- 置信度分级:根据模型返回的置信度进行分级判定
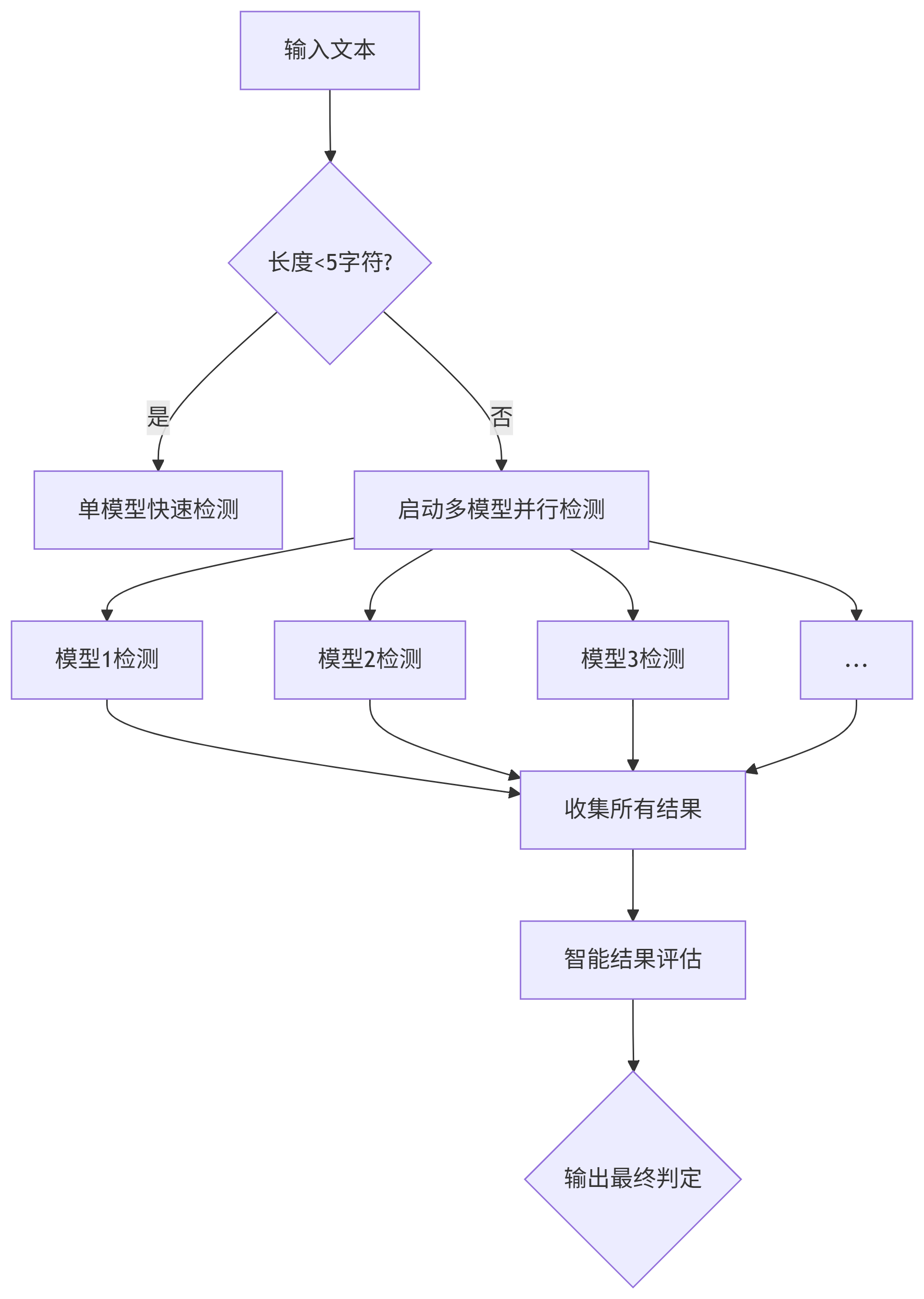
智能决策机制:
- 多模型投票机制
- 置信度加权评估
- 超时容错处理
**Tip:因为部分深度思考模型响应时间较长,所以尽量不要使用深度思考,影响判断失效。
代码实现
package com.muke.base.service.impl;
import com.fasterxml.jackson.databind.DeserializationFeature;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import com.muke.base.common.enums.DetectionStatusEnum;
import com.muke.base.domain.dto.ModelConfig;
import com.muke.base.service.AiChatService;
import io.github.pigmesh.ai.deepseek.core.DeepSeekClient;
import io.github.pigmesh.ai.deepseek.core.chat.ChatCompletionRequest;
import io.github.pigmesh.ai.deepseek.core.chat.ChatCompletionResponse;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.*;
import java.util.concurrent.*;
import java.util.stream.Collectors;
/**
* @author muke
*/
@Slf4j
@Service
public class AiChatServiceImpl implements AiChatService {
@Resource
private DeepSeekClient deepSeekClient;
private static final List<ModelConfig> MODEL_CONFIGS = Collections.unmodifiableList(Arrays.asList(
new ModelConfig("Pro/deepseek-ai/DeepSeek-V3", 10, 1.0f),
new ModelConfig("THUDM/GLM-4-32B-0414", 9, 0.95f),
new ModelConfig("deepseek-ai/DeepSeek-V3", 8, 0.9f),
new ModelConfig("internlm/internlm2_5-7b-chat", 7, 0.85f)
));
private static final ExecutorService MODEL_EXECUTOR = Executors.newCachedThreadPool(
new ThreadFactoryBuilder().setNameFormat("ai-detection-%d").setDaemon(true).build()
);
/**
* AI检测敏感词
* @param word 待检测内容
* @return DetectionStatus 检测状态
*/
@Override
public DetectionStatusEnum aiCheckWord(String word) {
if (StringUtils.isEmpty(word)) {
return DetectionStatusEnum.CLEAR;
}
// 短内容使用单模型快速检测
if (word.length() < 5) {
return checkWithSingleModel(word, MODEL_CONFIGS.get(1));
}
// 中长内容使用多模型检测
return checkWithOptimizedModels(word);
}
private DetectionStatusEnum checkWithOptimizedModels(String content) {
List<ModelConfig> sortedModels = MODEL_CONFIGS.stream()
.sorted(Comparator.comparingInt(ModelConfig::getPriority).reversed())
.collect(Collectors.toList());
// 创建并行任务列表
List<CompletableFuture<DetectionStatusEnum>> futures = sortedModels.stream()
.map(config -> CompletableFuture.supplyAsync(
() -> checkWithSingleModel(content, config),
MODEL_EXECUTOR
).exceptionally(e -> {
log.warn("模型检测异常: {}", e.getMessage());
return DetectionStatusEnum.SUGGEST_CLOUD_CHECK;
})).collect(Collectors.toList());
// 使用allOf等待所有任务完成(无论成功与否)
CompletableFuture<Void> allFutures = CompletableFuture.allOf(
futures.toArray(new CompletableFuture[0])
);
try {
// 设置总超时时间
allFutures.get(5, TimeUnit.SECONDS);
} catch (TimeoutException e) {
log.warn("部分模型检测未能在5秒内完成,继续处理已完成结果");
} catch (Exception e) {
log.error("多模型检测发生异常", e);
}
// 收集所有结果(包括已完成和异常的)
List<DetectionStatusEnum> results = futures.stream()
.map(future -> {
try {
// 未完成则返回默认
return future.getNow(DetectionStatusEnum.SUGGEST_CLOUD_CHECK);
} catch (Exception e) {
return DetectionStatusEnum.SUGGEST_CLOUD_CHECK;
}
}).collect(Collectors.toList());
// 综合评估策略
return evaluateConsensusResults(results);
}
/**
* 综合评估策略(升级版)
*/
private DetectionStatusEnum evaluateConsensusResults(List<DetectionStatusEnum> results) {
if (results.isEmpty()) {
return DetectionStatusEnum.SUGGEST_CLOUD_CHECK;
}
// 统计各状态数量
Map<DetectionStatusEnum, Long> countMap = results.stream()
.collect(Collectors.groupingBy(
status -> status,
Collectors.counting()
));
long sensitiveCount = countMap.getOrDefault(DetectionStatusEnum.SENSITIVE, 0L);
long clearCount = countMap.getOrDefault(DetectionStatusEnum.CLEAR, 0L);
long totalModels = results.size();
// 策略1:超过半数模型明确判定敏感
if (sensitiveCount > totalModels / 2) {
log.info("AI多模型判定结果为:超过半数模型明确判定敏感");
return DetectionStatusEnum.SENSITIVE;
}
// 策略2:超过70%模型明确判定非敏感
if (clearCount > totalModels * 0.7) {
log.info("AI多模型判定结果为:超过70%模型明确判定非敏感");
return DetectionStatusEnum.CLEAR;
}
// 策略3:存在敏感判定且总占比超过30%
if (sensitiveCount > 0 && (sensitiveCount + clearCount) * 0.3 < sensitiveCount) {
log.info("AI多模型判定结果为:存在敏感判定且总占比超过30%");
return DetectionStatusEnum.SENSITIVE;
}
// 其他情况建议云校验
return DetectionStatusEnum.SUGGEST_CLOUD_CHECK;
}
private DetectionStatusEnum checkWithSingleModel(String content, ModelConfig config) {
try {
long startTime = System.currentTimeMillis();
String prompt = "请严格判断以下内容是否包含敏感信息(暴力、色情、反动、诱导等)," +
"用JSON格式回答:{\"sensitive\":布尔值, \"confidence\":0-1的置信度}\n" +
"内容:" + content;
ChatCompletionRequest request = ChatCompletionRequest.builder()
.addUserMessage(prompt)
.model(config.getName())
.stream(false)
.temperature(0.0)
.maxCompletionTokens(30)
.reasoningEffort("low")
.build();
// 带超时的请求
CompletableFuture<ChatCompletionResponse> future = CompletableFuture.supplyAsync(
() -> deepSeekClient.chatCompletion(request).execute()
);
ChatCompletionResponse response = future.get(10000, TimeUnit.MILLISECONDS);
if (response == null || response.choices() == null || response.choices().isEmpty()) {
log.warn("模型 {} 返回空响应", config.getName());
return DetectionStatusEnum.SUGGEST_CLOUD_CHECK;
}
String answer = response.choices().get(0).message().content().trim()
.replace("\uFEFF", "")
.replaceAll("^```json|```$", "");
try {
JsonNode json = new ObjectMapper()
.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false)
.readTree(answer);
boolean sensitive = json.path("sensitive").asBoolean();
float confidence = (float) json.path("confidence").asDouble(0.5);
log.info("模型 {} 检测结果: {}, 置信度: {}, 检测耗时: {}ms", config.getName(), sensitive, confidence, System.currentTimeMillis() - startTime);
// 根据置信度确定最终状态
if (sensitive) {
return confidence >= 0.8 ? DetectionStatusEnum.SENSITIVE : DetectionStatusEnum.SUGGEST_CLOUD_CHECK;
} else {
return confidence >= 0.7 ? DetectionStatusEnum.CLEAR : DetectionStatusEnum.SUGGEST_CLOUD_CHECK;
}
} catch (Exception e) {
log.warn("解析模型 {} 响应失败: {}", config.getName(), answer);
return DetectionStatusEnum.SUGGEST_CLOUD_CHECK;
}
} catch (TimeoutException e) {
log.warn("模型 {} 检测超时", config.getName());
return DetectionStatusEnum.SUGGEST_CLOUD_CHECK;
} catch (Exception e) {
log.error("模型 {} 检测异常: {}", config.getName(), e.getMessage());
return DetectionStatusEnum.SUGGEST_CLOUD_CHECK;
}
}
}
云厂商 API 检测
这就不多介绍了,基本上所有的云厂商都提供了敏感词检测的能力,收费也都不一样,自行根据需求选择即可,我这里用的是阿里云的服务,按照文档对接还是很便捷的,我这里直接贴出我的工具类以供参考。
package com.muke.base.common.utils;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.aliyun.imageaudit20191230.Client;
import com.aliyun.imageaudit20191230.models.ScanTextRequest;
import com.aliyun.imageaudit20191230.models.ScanTextResponse;
import com.aliyun.teaopenapi.models.Config;
import com.aliyun.teautil.models.RuntimeOptions;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
/**
* @Description: 阿里云文件校验
* @author: 专业bug开发(kk)
* @date: 2025年05月26日 22:08
*/@Slf4j
@Component
@ConfigurationProperties(prefix = "aliyun.user")
public class AliGreenTextScanUtil {
private static final List<String> SCAN_SCENES = Collections.unmodifiableList(Arrays.asList(
"spam", "politics", "abuse", "terrorism",
"porn", "contraband", "flood", "ad"
));
// 预构建的labels列表(线程安全)
private static final List<ScanTextRequest.ScanTextRequestLabels> PREDEFINED_LABELS;
static {
List<ScanTextRequest.ScanTextRequestLabels> labels = new ArrayList<>(SCAN_SCENES.size());
for (String scene : SCAN_SCENES) {
labels.add(new ScanTextRequest.ScanTextRequestLabels().setLabel(scene));
}
PREDEFINED_LABELS = Collections.unmodifiableList(labels);
}
// 客户端缓存(按需创建)
private volatile Client client;
private final Object clientLock = new Object();
private String accessKeyId;
private String secret;
/**
* 创建/获取客户端实例(线程安全)
*/
private Client getClient() throws Exception {
Client currentClient = this.client;
if (currentClient == null) {
synchronized (clientLock) {
currentClient = this.client;
if (currentClient == null) {
Config config = new Config()
.setAccessKeyId(accessKeyId)
.setAccessKeySecret(secret)
.setEndpoint("imageaudit.cn-shanghai.aliyuncs.com");
this.client = currentClient = new Client(config);
}
}
}
return currentClient;
}
/**
* 优化后的文本内容审核方法
*/
public Boolean scanText(String content) {
if (StringUtils.isBlank(content)) {
return true;
}
try {
// 1. 构建检测任务(复用预定义的labels)
ScanTextRequest.ScanTextRequestTasks task = new ScanTextRequest.ScanTextRequestTasks()
.setContent(content);
ScanTextRequest request = new ScanTextRequest()
.setTasks(Collections.singletonList(task))
.setLabels(PREDEFINED_LABELS);
// 2. 执行检测(带超时控制)
Client client = getClient();
ScanTextResponse response = client.scanTextWithOptions(request, new RuntimeOptions());
log.info("阿里云检测响应结果:{}", JSON.toJSONString(response));
// 3. 优化响应解析
return parseResponse(response);
} catch (Exception e) {
log.error("文本审核异常 - 内容: {}", content.substring(0, Math.min(content.length(), 50)), e);
return false;
}
}
/**
* 优化响应解析逻辑
*/
private boolean parseResponse(ScanTextResponse response) {
if (response == null || response.getBody() == null) {
log.warn("空响应");
return false;
}
try {
JSONObject data = JSON.parseObject(JSON.toJSONString(response.getBody())).getJSONObject("data");
if (data == null) {
log.warn("缺少data字段");
return false;
}
JSONArray elements = data.getJSONArray("elements");
if (elements == null || elements.isEmpty()) {
log.warn("缺少elements数据");
return false;
}
JSONObject element = elements.getJSONObject(0);
JSONArray results = element.getJSONArray("results");
if (results == null) {
log.warn("缺少results数据");
return false;
}
// 流式处理结果,发现违规立即返回
for (int i = 0; i < results.size(); i++) {
JSONObject result = results.getJSONObject(i);
if ("block".equals(result.getString("suggestion"))) {
log.info("文本违规 - 类型: {}", result.getString("label"));
return true;
}
}
return false;
} catch (Exception e) {
log.error("响应解析异常", e);
return false;
}
}
public void setAccessKeyId(String accessKeyId) {
this.accessKeyId = accessKeyId;
resetClient();
}
public void setSecret(String secret) {
this.secret = secret;
resetClient();
}
private void resetClient() {
synchronized (clientLock) {
this.client = null;
}
}
}
实现总结
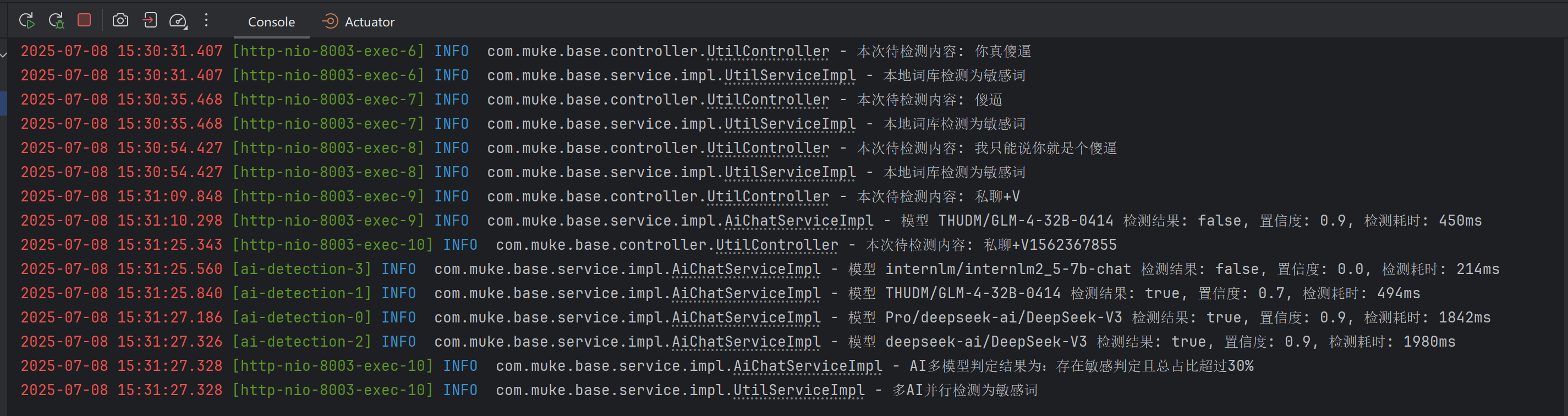
上面我们已经逐一介绍了每种敏感词检测方式的实现,这里我们总结一下我现在的实现方式,如何将这几种方式合并起来实现一个完整的小连招。
- UtilService
package com.muke.base.service;
/**
* @author muke
*/public interface UtilService {
/**
* 内容校验敏感词
* @param content 内容
* @return 是否敏感
*/
Boolean checkSensitiveWords(String content);
}
- UtilServiceImpl
package com.muke.base.service.impl;
import com.github.houbb.sensitive.word.core.SensitiveWordHelper;
import com.muke.base.common.enums.DetectionStatusEnum;
import com.muke.base.common.utils.AliGreenTextScanUtil;
import com.muke.base.common.utils.SensitiveUtil;
import com.muke.base.service.AiChatService;
import com.muke.base.service.UtilService;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
/**
* @Description:
* @author: 专业bug开发(kk)
* @date: 2025年05月26日 20:43
*/@Slf4j
@Service
public class UtilServiceImpl implements UtilService {
@Resource
private AiChatService aiChatService;
@Resource
private AliGreenTextScanUtil aliGreenTextScanUtil;
/**
* 内容校验敏感词
*
* @param content 内容
* @return 是否敏感
*/
@Override
public Boolean checkSensitiveWords(String content) {
if (StringUtils.isEmpty(content)) {
return false;
}
//1.本地词库检测
if (SensitiveUtil.containsSensitiveWords(content)) {
log.info("本地词库检测为敏感词");
return true;
}
//2.开源词库检测
if (SensitiveWordHelper.contains(content)) {
log.info("开源词库检测为敏感词");
return true;
}
//3.多AI并行检测
DetectionStatusEnum aiStatus = aiChatService.aiCheckWord(content);
if (aiStatus.shouldBlock()) {
log.info("多AI并行检测为敏感词");
return true;
}
if (!aiStatus.needsCloudCheck()) {
return false;
}
log.info("AI校验结果为需要进一步云检测,开始进行云检测");
//4.云检测
return aliGreenTextScanUtil.scanText(content);
}
}
总结
传统方式的敏感词检测基本都是基于敏感词库实现,这种方式过度依赖于敏感词库的词汇量,导致很多新出现的敏感词需要手动维护到词库,有些图方便则直接使用云厂商的服务,很少有跟 AI 相结合的,这次的也算是一个创新,将 AI 能力运用到了实际场景中。这里我是直接实时检测用户评论,如果对失效要求不严格的可以异步检测,但不管怎么样实现的思路都是一样的。
因为文章审核的原因,这里不提供原敏感词文件,需要的联系作者获取。
作者原文发布于:专业bug开发的小站,欢迎感兴趣的来看看

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)