聊一个有趣的 Unicode 编码和 LLM Tokenization 问题
本次技术分享聚焦于大语言模型(LLM)输入输出中 Unicode 编码不一致的有趣现象。我们深入探讨了 Unicode 规范化(Normalization)的概念,解释了预组合字符和基本字符+组合字符的不同表示方式,以及常见的 NFC、NFD、NFKC 和 NFKD 等规范化形式。随后,我们阐述了为何不同 Unicode 编码的字符串在经过 LLM tokenizer 处理后可能得到相同的结果,关
一个神奇的现象
上周,我在工作中遇到一个颇为奇特的现象,其根源在于我观察到大型语言模型(LLM)对输入和输出的 Unicode 编码处理似乎存在某种不一致性。
举例来说,我们要求 LLM 重复一个俄文字符串:“тестовый_файл.xlsx”。以下是 Gemini 的回复:
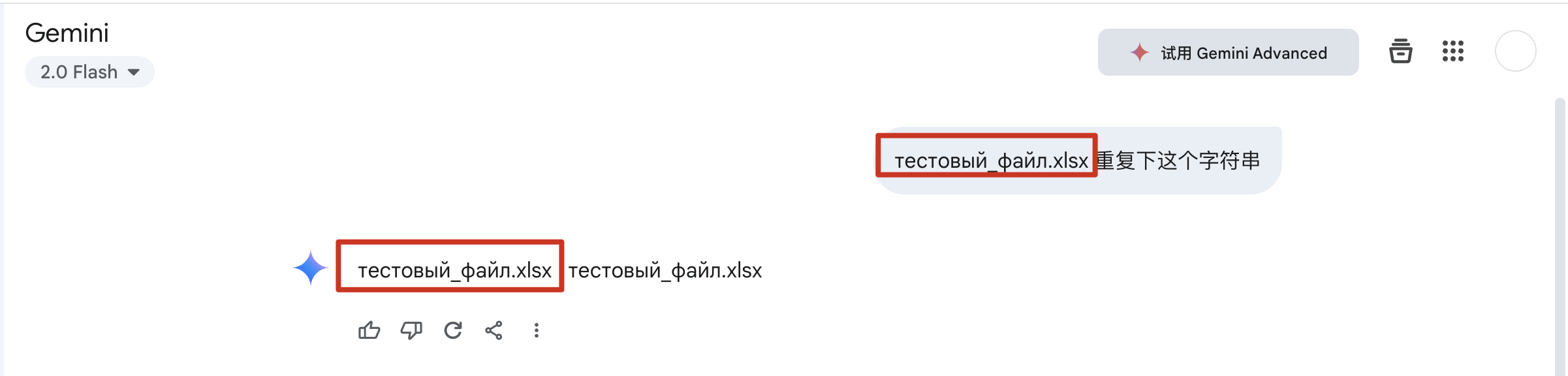
乍一看,输出与输入完全一致,肉眼难以分辨任何差异。然而,当我们深入到字符的底层,将 LLM 输出的字符串打印为 Unicode 编码时,却发现一个令人惊讶的事实:两者在编码层面竟然是不同的。
a = "тестовый_файл.xlsx"
b = "тестовый_файл.xlsx"
a_bytes = a.encode("utf-8")
b_bytes = b.encode("utf-8")
print(f"'{a}' 的 UTF-8 字节序列: {a_bytes}")
print(f"'{b}' 的 UTF-8 字节序列: {b_bytes}")
print(f"字节序列是否相同: {a_bytes == b_bytes}")'тестовый_файл.xlsx' 的 UTF-8 字节序列: b'\xd1\x82\xd0\xb5\xd1\x81\xd1\x82\xd0\xbe\xd0\xb2\xd1\x8b\xd0\xb8\xcc\x86_\xd1\x84\xd0\xb0\xd0\xb8\xcc\x86\xd0\xbb.xlsx'
'тестовый_файл.xlsx' 的 UTF-8 字节序列: b'\xd1\x82\xd0\xb5\xd1\x81\xd1\x82\xd0\xbe\xd0\xb2\xd1\x8b\xd0\xb9_\xd1\x84\xd0\xb0\xd0\xb9\xd0\xbb.xlsx'
字节序列是否相同: False更令人惊奇的是,当我们使用 LLM 的 tokenizer 对这两个 Unicode 序列不同的的字符串进行分词(tokenization)时,结果却又完全一致了。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
a_token = tokenizer.encode(a)
b_token = tokenizer.encode(b)
print(a_token==b_token)
print(all(_a == _b for _a,_b in zip(a_token,b_token)))
True
True基于以上执行结果,我们发现两个神奇的现象:
- 两个视觉上完全一致的字符串,其底层的 Unicode 编码竟然存在差异?
- 两个 Unicode 编码不同的字符串,经过 LLM tokenizer 处理后,得到的 tokenization 结果却可能完全相同?
为了解开这两个谜团,我们需要深入理解理解 Unicode 编码以及 LLM 的 Tokenization 机制。请跟随我的思路,一同探索这背后的奥秘吧!
Unicode 规范化 (Unicode Normalization)
Unicode 字符表示方式
前文提出的第一个问题,即肉眼相同的字符串底层 Unicode 编码不一致的现象,涉及到 Unicode 字符的表示方式。在 Unicode 标准中,某些视觉上相同的字符可能存在多种不同的编码表示形式。主要有两种方式:
- 预组合字符 (Precomposed Characters): 一个单独的 Unicode 码位代表一个带有附加符号的字符(例如,一个带有重音符的字母)。
- 基本字符 + 组合字符 (Base Character + Combining Character): 一个字符可以由一个基本字符的码位加上一个或多个表示附加符号的组合字符的码位组成。
回到我们之前的例子,字符串 a 和 b 在视觉上都呈现为 “тестовый_файл.xlsx”,但它们之间的差异在于字符 "й" 的编码方式:
- 在字符串 a 中,"й" 是由基本字符 "и" (Unicode 码位 U+0438) 加上一个短音符号的组合字符 (Combining Short Accent, Unicode 码位 U+0306) 组成。
- 在字符串 b 中,"й" 是一个预组合字符,由一个单独的 Unicode 码位 U+0439 表示。
为了更直观地理解这一点,你可以执行以下代码来查看这两个字符串中每个字符的 Unicode 编码
def print_unicode_info_optimized(text):
print(f"'{text}' 的 Unicode 信息:")
for char in text:
unicode_hex = f"U+{ord(char):04X}"
utf8_bytes = char.encode('utf-8')
hex_representation = '\\x'.join(f'{byte:02x}' for byte in utf8_bytes)
print(f" '{char}': Unicode = {unicode_hex}, UTF-8 (Hex) = b'\\x{hex_representation}'")
print("-" * 40)
a = "тестовый_файл.xlsx"
b = "тестовый_файл.xlsx"
print_unicode_info_optimized(a)
print_unicode_info_optimized(b)'тестовый_файл.xlsx' 的 Unicode 信息:
.....省略内容
'и': Unicode = U+0438, UTF-8 (Hex) = b'\xd0\xb8'
'̆': Unicode = U+0306, UTF-8 (Hex) = b'\xcc\x86'
.....省略内容
----------------------------------------
'тестовый_файл.xlsx' 的 Unicode 信息:
.....省略内容
'й': Unicode = U+0439, UTF-8 (Hex) = b'\xd0\xb9'
.....省略内容Unicode 规范化形式 (Unicode Normalization Forms)
正如我们所见,Unicode 允许对某些字符进行多种不同的编码表示。为了解决这种不一致性,Unicode 组织定义了几种规范化形式 (Normalization Forms)。其中最常见的包括:
- NFC (Normalization Form Canonical Composition,规范等价组合形式): 此形式首先将字符分解为基本字符和组合字符,然后尽可能地将它们重新组合成预组合字符。Python 语言以及许多其他工具默认采用这种规范化形式。
- NFD (Normalization Form Canonical Decomposition,规范等价分解形式): 此形式会将所有组合字符分解为基本字符和单独的组合字符序列。
- NFKC (Normalization Form Compatibility Composition,兼容性分解组合形式): 除了执行 NFC 的规范化操作外,NFKC 还会进行兼容性分解 (Compatibility Decomposition)。这意味着它会将一些兼容性字符(例如,全角字符、上标数字等)替换为它们的兼容性分解形式,然后再进行组合。
- NFKD (Normalization Form Compatibility Decomposition,兼容性分解形式): 此形式在执行 NFD 的规范化操作的基础上,同样会进行兼容性分解。
通过对字符串执行规范化 (Unicode normalization) 操作,我们可以将它们统一转换为相同的 Unicode 规范形式。例如,我们可以将前文提到的两个字符串都统一规范化为最常用的 NFC 形式:
import unicodedata
a = "тестовый_файл.xlsx"
b = "тестовый_файл.xlsx"
a_bytes = a.encode("utf-8")
b_bytes = b.encode("utf-8")
print(f"'{a}' 的 UTF-8 字节序列: {a_bytes}")
print(f"'{b}' 的 UTF-8 字节序列: {b_bytes}")
print(f"字节序列是否相同: {a_bytes == b_bytes}")
normalized_a = unicodedata.normalize('NFC', a)
normalized_b = unicodedata.normalize('NFC', b)
normalized_a_bytes = normalized_a.encode('utf-8')
normalized_b_bytes = normalized_b.encode('utf-8')
print(f"规范化后的 '{a}' 的 UTF-8 字节序列: {normalized_a_bytes}")
print(f"规范化后的 '{b}' 的 UTF-8 字节序列: {normalized_b_bytes}")
print(f"规范化后字节序列是否相同: {normalized_a_bytes == normalized_b_bytes}")'тестовый_файл.xlsx' 的 UTF-8 字节序列: b'\xd1\x82\xd0\xb5\xd1\x81\xd1\x82\xd0\xbe\xd0\xb2\xd1\x8b\xd0\xb8\xcc\x86_\xd1\x84\xd0\xb0\xd0\xb8\xcc\x86\xd0\xbb.xlsx'
'тестовый_файл.xlsx' 的 UTF-8 字节序列: b'\xd1\x82\xd0\xb5\xd1\x81\xd1\x82\xd0\xbe\xd0\xb2\xd1\x8b\xd0\xb9_\xd1\x84\xd0\xb0\xd0\xb9\xd0\xbb.xlsx'
字节序列是否相同: False
规范化后的 'тестовый_файл.xlsx' 的 UTF-8 字节序列: b'\xd1\x82\xd0\xb5\xd1\x81\xd1\x82\xd0\xbe\xd0\xb2\xd1\x8b\xd0\xb9_\xd1\x84\xd0\xb0\xd0\xb9\xd0\xbb.xlsx'
规范化后的 'тестовый_файл.xlsx' 的 UTF-8 字节序列: b'\xd1\x82\xd0\xb5\xd1\x81\xd1\x82\xd0\xbe\xd0\xb2\xd1\x8b\xd0\xb9_\xd1\x84\xd0\xb0\xd0\xb9\xd0\xbb.xlsx'
规范化后字节序列是否相同: True正如我们所见,经过 NFC 规范化处理后,字符串 a 和 b 的 Unicode 字节序列现在完全一致了。
各种编程语言都提供了官方库来处理 Unicode 规范化问题。上文展示的是 Python 的实现方式,这里我再提供一个 Go 语言的实现示例:Go Playground - The Go Programming Language 。欢迎大家探索其他编程语言中实现 Unicode 规范化的方法,并积极分享你们的发现。
LLM Tokenization 预处理
接下来,我们来解释第二个问题:为什么两个 Unicode 编码不同的字符串,经过 LLM tokenization 后会得到一致的结果?
正如大家所了解的,当前基于 Transformer 架构的大语言模型并非采用端到端的语言建模方式(可参考我之前关于 BPE tokenization 的教程:LLM基础课: 跟着大神 Andrej Karparthy 学习 Byte Pair Encoding)。这里所说的“端到端”指的是模型直接处理用户输入的原始数据。LLM 不属于端到端模型的原因在于,模型接收到的并非用户直接输入的 Unicode 编码,而是经过一系列预处理和 tokenization 之后的数据。
实际上,在执行正式的 tokenization 之前,通常会进行多个预处理步骤,如下图所示:
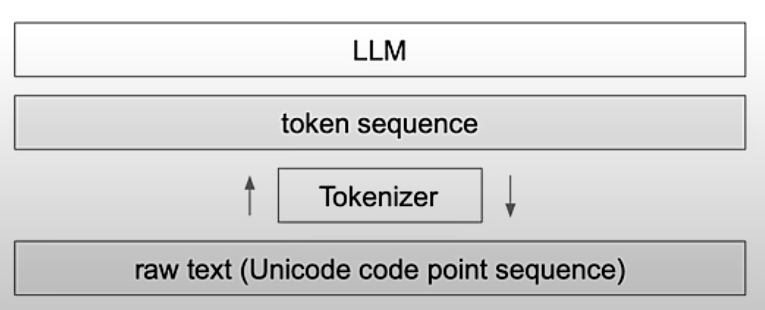
实际上,在执行正式的 tokenization 之前,通常会进行多个预处理步骤,如下图所示:

其中,“归一化 (Normalization)”步骤包含了一些常规的清理操作,例如去除不必要的空白字符、转换为小写形式,以及/或者去除变音符号等。如果你熟悉 Unicode 规范化(如 NFC 或 NFKC),这同样是 tokenizer 可能会应用的操作。
之所以不同的 Unicode 编码会对应相同的 tokenization 结果,正是因为 tokenizer 在执行正式的 tokenization 之前,会将不同的 Unicode 编码统一转换为相同的规范形式(例如 NFC)。
为什么要做 Normalization?
tokenizer 在进行分词之前进行 Unicode 规范化是一个常见且重要的步骤,它带来了以下几个关键的好处:
1. 提高文本的一致性和可比性:
正如我们之前讨论的,同一个视觉上的字符在 Unicode 中可能有多种不同的表示方式(例如,预组合字符 vs. 基本字符 + 组合字符)。如果不进行规范化,即使两个字符串在人眼看来完全相同,但在计算机看来却是不同的字节序列。
- 例子: 字符 "ü" 可以表示为单个 Unicode 码位 U+00FC (拉丁小写字母 u 带分音符),也可以表示为 "u" (U+0075) 加上组合分音符 "̈" (U+0308)。
进行 Unicode 规范化可以将这些不同的表示形式转换为唯一的标准形式。这样,无论输入文本的原始编码方式如何,分词器处理的都是统一的表示,从而确保了:
- 相同的语义内容总是被分词成相同的 token。
- 在不同的文本来源之间进行比较和分析时,结果更加可靠和一致。
2. 简化分词规则和词汇表:
如果不对文本进行规范化,分词器就需要处理同一个逻辑字符的多种不同编码形式。这会增加分词规则的复杂性,并且可能导致词汇表中出现冗余的条目。
- 例子: 如果 "ü" 有两种表示形式,分词器可能需要分别处理这两种形式,并可能在词汇表中存储两次。
通过规范化,分词器只需要关注字符的标准形式,从而简化了分词逻辑,减小了词汇表的大小,并提高了效率。
3. 提升模型性能:
对于依赖文本输入的机器学习模型(例如,自然语言处理模型),输入数据的一致性至关重要。如果模型接收到同一个词的不同编码形式,它可能会将它们视为不同的词,从而影响模型的学习和泛化能力。
- 例子: 如果模型在训练数据中只见过 "ü" 的预组合形式,但在测试数据中遇到了 "u" + "̈" 的形式,模型可能无法正确识别它们是同一个词。
通过在分词之前进行 Unicode 规范化,可以确保模型接收到一致的输入,从而提高模型的性能和鲁棒性。
不同的分词器和应用场景可能会选择不同的规范化形式,但目标都是为了提高文本处理的一致性和效率。
总结来说,tokenizer 在分词前进行 Unicode 规范化的好处包括:
- 一致性: 确保相同的语义内容具有相同的表示。
- 简化: 降低分词规则和词汇表的复杂性。
- 性能: 提高下游机器学习模型的性能和鲁棒性。
Unicode 规范化可能引发的潜在问题
虽然 Unicode 规范化带来了诸多好处,但它也并非完美无缺,在某些情况下可能会引入一些问题或需要权衡考虑。例如,我们最初观察到的用户输入编码与模型输出编码不一致的现象,就是一个典型的例子。
以下是一些 Unicode 规范化可能带来的潜在问题:
1. 信息损失 (Loss of Original Representation):
规范化的主要目的是将不同的表示形式统一起来,但这必然会导致原始文本的一些细微信息丢失。在某些对文本的原始形式非常敏感的应用中,这可能是一个问题。
- 例子: 某些排版或字体设计可能会区分使用预组合字符和基本字符加组合字符的形式。规范化会消除这种区分。
- 例子: 在某些特定的语言或文化背景下,字符的不同组合方式可能带有细微的语义或风格差异,规范化可能会抹平这些差异。
2. 兼容性问题 (Compatibility Issues):
某些规范化形式(如 NFKC 和 NFKD)会进行兼容性分解,将一些兼容性字符替换为它们的兼容性分解形式。虽然这在信息检索等场景下可能很有用,但在需要保持文本原样的情况下可能会导致问题。
- 例子: 全角字符(例如 "A")在 NFKC/NFKD 下会被转换为对应的半角字符("A")。这在处理需要区分全角和半角字符的特定应用(例如,某些旧系统或特定的格式要求)时可能会导致错误。
- 例子: 上标和下标数字在 NFKC/NFKD 下会被转换为基线数字。这在需要保留上标/下标语义的场景(例如,科学公式、数学表达式)中会丢失信息。
3. 规范化形式的选择 (Choice of Normalization Form):
不同的规范化形式 (NFC, NFD, NFKC, NFKD) 适用于不同的场景。选择错误的规范化形式可能会导致意想不到的问题。
- 例子: 如果一个应用需要区分视觉上相似但语义不同的字符(例如,连字),那么过于激进的规范化(如 NFKC)可能会将它们合并,导致错误。
- 例子: 不同的编程语言或库可能默认使用不同的规范化形式,这可能导致在不同系统之间处理文本时出现不一致。
4. 性能开销 (Performance Overhead):
进行 Unicode 规范化需要额外的计算资源。对于大规模文本处理,这可能会带来一定的性能开销。虽然通常这个开销是可以接受的,但在对性能要求极高的实时应用中可能需要考虑。
5. 复杂性增加 (Increased Complexity):
理解 Unicode 规范化的不同形式及其影响需要一定的专业知识。这可能会增加文本处理流程的复杂性,尤其是在需要处理多种语言和字符集的场景下。
虽然 Unicode 规范化在提高文本处理的一致性和简化分词等方面有很多好处,但也可能带来信息损失、兼容性问题、需要仔细选择规范化形式以及一定的性能开销。在实际应用中,需要根据具体的任务需求和数据特点,权衡规范化带来的好处和潜在的风险,并选择最合适的规范化策略。对于 tokenizer 来说,通常会选择一种在大多数 NLP 任务中都能带来良好效果的规范化形式(例如 NFC),但开发者也需要了解其潜在的影响。
技术总结
本次技术分享聚焦于大语言模型(LLM)输入输出中 Unicode 编码不一致的有趣现象。我们深入探讨了 Unicode 规范化(Normalization)的概念,解释了预组合字符和基本字符+组合字符的不同表示方式,以及常见的 NFC、NFD、NFKC 和 NFKD 等规范化形式。
随后,我们阐述了为何不同 Unicode 编码的字符串在经过 LLM tokenizer 处理后可能得到相同的结果,关键在于 tokenizer 在正式分词前通常会进行 Unicode 规范化处理。最后,我们简要提及了 Unicode 规范化可能带来的潜在问题。
我一直认为,学习 LLM 应该从底层的基本原理入手,理解这些底层原理有助于我们更深入地认识 LLM 的工作机制。那么,读完这篇文章,你有什么新的收获呢?欢迎在评论区分享你的想法和见解,参与讨论。
参考资料
- Unicode equivalence(维基百科) : https://en.wikipedia.org/wiki/Unicode_equivalence#Normal_forms
- Unicode 编码规范官网: Unicode – The World Standard for Text and Emoji
- Unicode code converter: Unicode code converter
- Normalization and pre-tokenization(huggingface): https://huggingface.co/learn/llm-course/chapter6/4
-------------------------
内容已结束,感谢阅读!
-------------------------
欢迎关注我,学习更多AI干货知识
- 微信公众号: 栋搞西搞
- B站: 栋搞西搞的个人空间-栋搞西搞个人主页-哔哩哔哩视频
- CSDN博客: 栋搞西搞-CSDN博客
- GitHub:https://github.com/sundl123/free-ai-coder


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)