十一、LangGraph的持久化和流式输出
LangGraph提供了强大的持久化和流式处理机制,支持构建智能代理系统。其核心功能包括:1. 检查点机制(Checkpointer)实现状态持久化,支持多种存储后端,允许中断恢复和多会话管理;2. 流式处理(Streaming)实时输出执行过程,提升交互体验;3. 支持同步/异步调用方式,可捕获细粒度事件。通过状态图(StateGraph)管理节点执行流程,结合工具调用和LLM处理,实现复杂任务
持久化(Persistence)
什么是持久化
LangGraph 提供了持久化机制,可以将图的状态保存到存储系统中,以便在后续会话中恢复。这对于构建有记忆的智能体系统至关重要。常见的实现方式是使用 CheckpointSaver,它支持多种存储后端:InMemory(内存存储)、SQLite、Redis、PostgreSQL 等,只需替换相应的 CheckpointSaver 即可。
检查点
检查点(checkpointer)是 LangGraph 框架的一个关键组件。
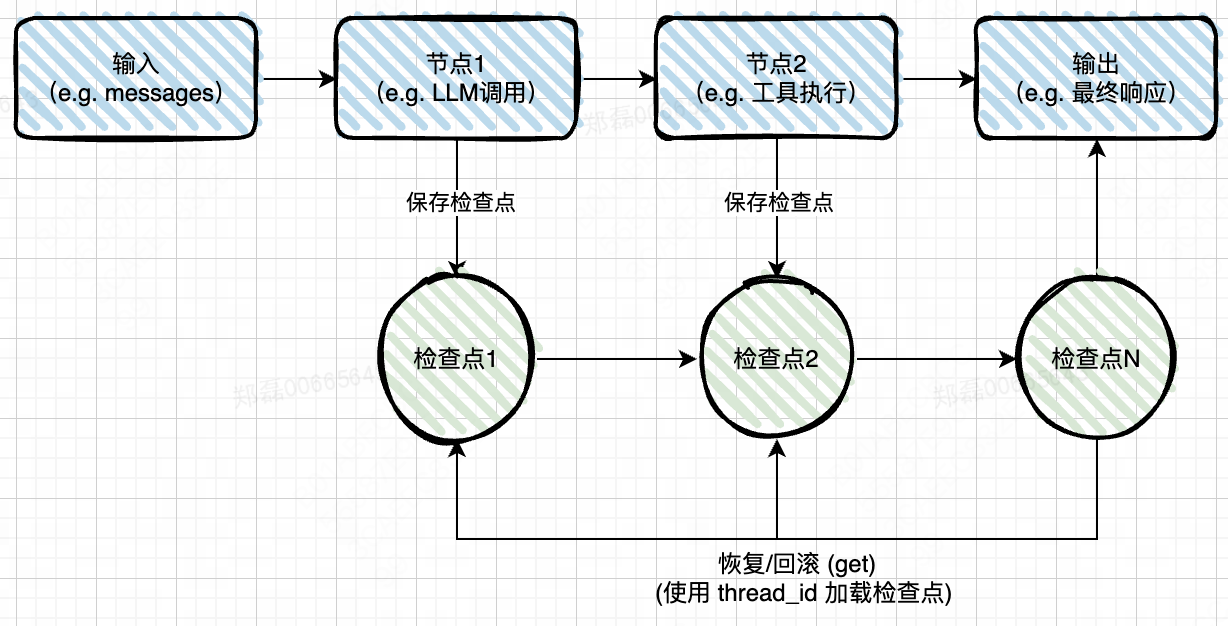
1. Checkpointer 的含义
- 定义:Checkpointer 是 LangGraph 的“检查点”(checkpoints)。它本质上是一个状态持久化机制,负责在图执行过程中保存、加载和更新状态数据(如代理的 messages 列表)。
- 来源:它是 LangGraph 的 checkpoint 模块的一部分(例如,from langgraph.checkpoint.memory import InMemorySaver 或其他实现如 SqliteSaver)。
- 核心概念:LangGraph 的图(StateGraph)是状态驱动的,checkpointer 像一个“保存点”,允许系统在任意节点记录状态,便于后续恢复或多轮交互。
2. Checkpointer 的作用
Checkpointer 的主要目的是使 LangGraph 图支持持久化和可恢复的执行,尤其在构建多步、交互式代理时非常有用。以下是其关键作用:
- 持久化状态:在图执行过程中(如从 "llm" 节点到 "action" 节点),checkpointer 会自动保存当前状态(例如,messages 列表、工具调用结果)。这允许代理“记住”历史上下文。例如,在多轮对话中,上一轮的查询结果可以被下一轮继承,而无需从头开始。
- 支持线程管理和多会话:通过 thread_id(如 thread = {"configurable": {"thread_id": "1"}}),checkpointer 可以为不同会话(threads)独立保存状态。实现会话持久化。如果代理被中断(例如,程序重启),可以使用同一 thread_id 恢复状态,避免数据丢失。
- 保存是增量的:每个检查点都有一个唯一标识(如 checkpoint_id),并与 thread_id 关联
- 启用流式执行和错误恢复:在 graph.stream() 或 graph.invoke() 中,checkpointer 跟踪每个事件的状态变化,支持实时(streaming)输出。如果执行出错(如工具调用失败),checkpointer 可以回滚到上一个检查点,继续执行,而不重跑整个图。
- 性能与安全性:它提高了代理的鲁棒性(robustness),但如果状态数据很大,可能会消耗内存;同时,确保 thread_id 唯一以避免冲突。
3. Checkpointer 的回滚机制
- 回滚的含义:回滚(rollback)不是一个独立的显式方法,而是通过加载先前保存的检查点来实现的。这通常用于错误恢复、中断继续或多轮交互。本质上是“加载上一个有效的检查点”,而不是删除状态。LangGraph 支持“中断和恢复”(interrupt and resume),如果执行出错(如工具调用失败或手动中断),系统可以从上一个检查点继续,而不从头开始。
- 回滚触发时机:
- 自动回滚:在流式执行(如 graph.stream())中,如果节点出错,LangGraph 会尝试从最近检查点恢复(取决于配置)。
- 手动恢复:通过指定 thread_id 调用 graph.invoke() 或 graph.stream(),加载该线程的上一个检查点。
- 错误处理:如果代理在 "action" 节点失败,checkpointer 可以回滚到 "llm" 节点后的状态,重新尝试。
流式输出(Streaming)
LangGraph 支持流式输出,可以实时获取图的执行过程和结果,而不必等待整个流程完成。这对于构建响应迅速的交互系统非常有用。
1. Streaming 的定义
- 核心概念:Streaming(流式传输)是指在数据生成过程中实时、逐块(chunk)地传输输出,而不是等待整个响应完成后再一次性返回。这类似于“打字机”效果,用户可以立即看到部分结果,而非长时间等待。
- 在 AI/LLM 上下文中的应用:大型语言模型(如 OpenAI 或 DeepSeek)生成文本时,Streaming 允许模型逐词或逐句输出响应。同时,在代理框架如 LangGraph 中,它扩展到实时捕获整个执行流程的事件(如模型输出、工具调用、状态更新)。
- 为什么重要:传统调用(如 invoke())是阻塞的(blocking),适合简单任务;Streaming 是非阻塞的(non-blocking),适合交互式应用(如聊天机器人),提高用户体验和效率。
2. Streaming 在 LangGraph 中的作用
LangGraph 是 LangChain 的扩展,用于构建状态图(StateGraph)和代理。Streaming 支持实时监控和输出图的执行过程,尤其在多节点代理(如您的代码中的 "llm" 和 "action" 节点)中。
关键方法:
1、graph.stream(input, config):同步流式执行图,返回一个迭代器,每个项是一个事件字典(event),包含节点输出(如状态更新)。适合简单流式输出。
- 输入:input 是状态数据(如 {"messages": [HumanMessage(...)]})。
- 配置:config 如 thread_id,用于持久化。
- 输出:逐事件返回,允许打印中间结果。
2、graph.astream_events(input, config, version):异步版本,支持更细粒度的事件订阅(如 "on_chat_model_stream" 表示模型的 chunk 输出)。
- 优势:可以捕获特定事件类型(如模型生成文本的每个 chunk、工具启动/结束)。
- version 参数(如 "v1")指定事件格式。
- 需要异步环境(async for),或包裹在 asyncio.run() 中(如您的代码第 125-136 行)。
工作原理:
1、LangGraph 的图执行是事件驱动的:每个节点(node)运行时产生事件。
2、Streaming 通过生成器(generator)或异步迭代器实时推送这些事件。
3、与 checkpointer 结合:Streaming 可以从持久状态恢复,继续流式输出,而不中断用户体验。
4、示例事件类型:
- "on_chat_model_start":模型开始生成。
- "on_chat_model_stream":模型输出 chunk(您的代码中过滤并打印)。
- "on_tool_start":工具(如 Tavily 搜索)启动。
- "on_chain_end":节点结束。
优势:
- 实时反馈:用户看到即时输出,提高交互性(例如,聊天中逐字显示答案)。
- 效率:处理长响应时,不需等待全部完成;适用于工具调用链(如搜索 + LLM)。
- 错误处理:如果中途出错,可以从事件中捕获并恢复。
- 用户体验:减少感知延迟,尤其在慢网络或复杂代理中。
局限性:
- 需要处理部分输出(chunks),可能不完整。
- 异步版本要求 Python 异步编程知识(如 asyncio)。
- 在同步环境中使用 async 方法需额外包裹。
代码示例
import os
from openai import OpenAI
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
import operator
from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage, ToolMessage
from langchain_openai import ChatOpenAI
from langchain_community.tools.tavily_search import TavilySearchResults
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.checkpoint.sqlite import SqliteSaver
import asyncio
BASE_URL = "https://api.deepseek.com/v1" # 定义 DeepSeek API 的基础 URL
API_KEY = "sk-9968adaf0fff4ceda4e59ba8869154bd" # 定义 API 密钥
MODEL_NAME = "deepseek-chat" # 定义模型名称
TAVILY_API_KEY = "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"
os.environ["OPENAI_API_KEY"] = API_KEY
os.environ["OPENAI_API_BASE"] = BASE_URL
os.environ["TAVILY_API_KEY"] = TAVILY_API_KEY
tool = TavilySearchResults(max_results=2)
# 状态定义,进行状态管理,Annotated[list[AnyMessage], operator.add] 表示每次状态更新时,新的消息会被添加到现有的消息列表中。
# 个人理解:所谓状态,就是每次调用函数时,传入的参数,以及返回的结果。用messages变量存储。
# TypedDict 类型字典,用于定义状态的类型。
class AgentState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
memory = SqliteSaver.from_conn_string(":memory:")
class Agent:
def __init__(self, model, tools, checkpointer, system=""):
self.system = system
# StateGraph 状态图,LangGraph 的核心数据结构,表示应用程序的不同状态和它们之间的转换。
graph = StateGraph(AgentState)
# add_node 添加节点,每个节点是一个函数,用于处理状态图中的状态。
# 节点(Nodes): 执行特定功能的函数,可以是:
# 工具调用
# 语言模型调用
# 自定义函数
graph.add_node("llm", self.call_openai)
graph.add_node("action", self.take_action)
# add_conditional_edges 添加条件边,用于根据条件选择不同的节点。
graph.add_conditional_edges(
"llm",
self.exists_action,
{True: "action", False: END}
)
# add_edge 添加边,用于连接节点。edge:定义节点之间的条件转换路径。
graph.add_edge("action", "llm")
# 设置入口点,用于启动状态图。
graph.set_entry_point("llm")
# compile 编译状态图,生成可执行的图。
self.graph = graph.compile(checkpointer=checkpointer)
# 将工具存储为字典
self.tools = {t.name: t for t in tools}
# bind_tools 绑定工具,用于将工具绑定到语言模型。
self.model = model = model.bind_tools(tools)
def exists_action(self, state: AgentState):
result = state["messages"][-1]
return len(result.tool_calls) > 0
def call_openai(self, state: AgentState):
messages = state["messages"]
if self.system:
messages = [SystemMessage(content=self.system)] + messages
message = self.model.invoke(messages)
return {"messages": [message]}
def take_action(self, state: AgentState):
tool_calls = state["messages"][-1].tool_calls
results = []
for t in tool_calls:
print(f"Calling:{t}")
if not t['name'] in self.tools:
print("\n ...bad tool name...")
result = "bad tool name, retry"
else:
result = self.tools[t['name']].invoke(t['args'])
results.append(ToolMessage(tool_call_id=t['id'], name=t['name'], content=str(result)))
print("Back to the model!")
return {'messages': results}
prompt = """You are a smart research assistant. Use the search engine to look up information. \
You are allowed to make multiple calls (either together or in sequence). \
Only look up information when you are sure of what you want. \
If you need to look up some information before asking a follow up question, you are allowed to do that!
"""
# 初始化 ChatOpenAI 模型,使用指定的模型名称以降低推理成本
model = ChatOpenAI(model=MODEL_NAME) #reduce inference cost
# 创建 Agent 实例,传入模型、工具列表、检查点保存器和系统提示
abot = Agent(model, [tool], checkpointer=memory, system=prompt)
# 定义第一轮用户消息:查询 SF 天气
messages = [HumanMessage(content="What is the weather in sf?")]
# 定义线程配置,使用 thread_id "1" 以支持状态持久化
thread = {"configurable": {"thread_id": "1"}}
# 流式执行代理,处理消息并打印每个事件的 messages
for event in abot.graph.stream({"messages": messages}, thread):
for v in event.values():
print(v['messages'])
# 定义第二轮用户消息:查询 LA 天气,使用同一线程以继承上下文
messages = [HumanMessage(content="What about in la?")]
thread = {"configurable": {"thread_id": "1"}}
for event in abot.graph.stream({"messages": messages}, thread):
for v in event.values():
print(v)
# 定义第三轮用户消息:比较哪个更暖,使用同一线程
messages = [HumanMessage(content="Which one is warmer?")]
thread = {"configurable": {"thread_id": "1"}}
for event in abot.graph.stream({"messages": messages}, thread):
for v in event.values():
print(v)
# 定义独立查询:不使用上下文,使用新线程 "2",因线程不同,此时无法使用之前的上下文。
messages = [HumanMessage(content="Which one is warmer?")]
thread = {"configurable": {"thread_id": "2"}}
for event in abot.graph.stream({"messages": messages}, thread):
for v in event.values():
print(v)
# 使用 SqliteSaver 创建内存数据库检查点保存器
memory = SqliteSaver.from_conn_string(":memory:")
# 使用新检查点保存器重新创建 Agent 实例
abot = Agent(model, [tool], system=prompt, checkpointer=memory)
# 定义用户消息:查询 SF 天气
messages = [HumanMessage(content="What is the weather in SF?")]
# 定义线程,使用 thread_id "4"
thread = {"configurable": {"thread_id": "4"}}
# 定义异步函数以处理流式事件
async def run_async_stream():
# 异步迭代代理的事件流,版本 "v1"
async for event in abot.graph.astream_events({"messages": messages}, thread, version="v1"):
kind = event["event"]
# 如果是聊天模型流式事件,提取并打印非空内容
if kind == "on_chat_model_stream":
content = event["data"]["chunk"].content
if content:
# OpenAI 上下文中空内容表示请求工具调用,因此只打印非空内容
print(content, end="|")
# 运行异步函数
asyncio.run(run_async_stream())
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)