Qwen2.5-Omni-详解04:Post-training
关键词:ChatML 数据格式、Thinker 指令微调、Talker 三阶段(ICL 语音续写 → DPO 强化 → 多说话人微调)、音色解耦、WER/停顿奖励、同时生成“文本+语音”
关键词:ChatML 数据格式、Thinker 指令微调、Talker 三阶段(ICL 语音续写 → DPO 强化 → 多说话人微调)、音色解耦、WER/停顿奖励、同时生成“文本+语音”
一、Post-training策略
1、Data Format(数据格式)
目的:统一多模态对话样本的组织方式,便于“思考模块(Thinker)”与“发声模块(Talker)”共同学习。
ChatML 样例要点
-
使用
<|im_start|> ... <|im_end|>封装一轮角色发言;角色如 user / assistant。 -
视觉/音频内容用特殊标记嵌入,例如:
<|vision_start|>Video.mp4 [内容描述]<|vision_end|>- 文本问题与视觉/音频提示并列出现,形成混合上下文。
-
样例显示两类监督:
- 转述/听写类:用户给出“视频里两人说什么?”,助手输出转写内容。
- 描述类:用户提供“视频里有人说:请描述你前面的那个人”,助手输出视觉描述(衣着、场景、光照等)。
这意味着:同一条样本里可以既训练语言理解/生成,也训练听视信息的对齐能力;后面 Talker 阶段就会接续这些上下文去继续生成语音。
2、Thinker(指令微调)
目标:让“大脑”学会在多模态上下文下理解指令并形成语义计划。
- 使用 ChatML 组织的 纯文本、多模态(图像/音频/视频/混合)对话数据做 instruction-tuning。
- 输出仍以文本 token为主(语义计划/答复内容),为后续 Talker 的语音合成提供高质量语义条件。
可以把 Thinker 看作“语义控制中心”:收到文本+视觉/音频提示 → 产出内容准确、上下文一致的文本响应或中间语义。
3、Talker(三阶段,让模型会“说话”)
Qwen2.5-Omni 的 Talker 负责把 Thinker 的语义实时说出来,并实现“文本与语音同步生成”。训练分三步:
阶段一:ICL 训练(语音续写/下一 token 预测)
做什么
- 和 Thinker 类似,也有文本监督;额外进行语音续写:把多模态上下文 + 目标口语回复(通常是语音编解码后的语音离散token/codec token)拼在一起做 next-token 预测(NTP)。
- 通过大量“带口语回复的对话”,学习单调映射:语义序列 → 语音序列(时序基本对齐,不倒序、不跳跃)。
学到什么
-
基本的发音正确性与可懂度;
-
韵律/情感/口音 等上下文合适的可变属性(prosody/emotion/accent);
-
音色解耦(timbre disentanglement):防止把“罕见文本模式”与“某特定说话人音色”错误绑定(例如遇到少见符号就固定成某个说话人的声音)。
- 常见实现思路(属通用技术点,论文此处未细述):对说话人表示做正则/对抗,或用瓶颈建模,让“内容表示”难以泄露音色信息,从而内容与音色解耦。
阶段一主要让模型会说且会随上下文变换风格,但由于预训练数据包含噪声(口误、对齐误差、错字等),会引入幻觉/误读风险。
阶段二:DPO 强化学习(稳定化语音生成)
痛点:预训练数据里不可避免的标注噪声/发音错误会诱发幻觉(说错词、停顿不当)。
策略:引入DPO(Direct Preference Optimization),用偏好对提升稳定性,而不用显式奖励模型或近端策略优化。
数据:构造三元组 (x,yw,yl)(x, y_w, y_l)(x,yw,yl)
-
xxx:输入上下文(文本/多模态);
-
ywy_wyw:好的语音生成序列(更低错误、更合理停顿);
-
yly_lyl:差的语音生成序列。
-
对这些候选用与可懂度强相关的指标打分排序:
- WER(词错误率);
- 标点停顿错误率(表达节奏/断句合理性)。
**目标函数(论文式 (1))**已在上图展示:
LDPO(Pθ;Pref)=−E(x,yw,yl)∼D[logσ(βlogPθ(yw∣x)Pref(yw∣x)−βlogPθ(yl∣x)Pref(yl∣x))]. \mathcal{L}_{\text{DPO}}(P_\theta;P_{\text{ref}}) = - \mathbb{E}_{(x,y_w,y_l)\sim \mathcal{D}}\Big[\log \sigma\big(\beta \log \frac{P_\theta(y_w|x)}{P_{\text{ref}}(y_w|x)} - \beta \log \frac{P_\theta(y_l|x)}{P_{\text{ref}}(y_l|x)}\big)\Big]. LDPO(Pθ;Pref)=−E(x,yw,yl)∼D[logσ(βlogPref(yw∣x)Pθ(yw∣x)−βlogPref(yl∣x)Pθ(yl∣x))].
解释:
- 让当前模型 PθP_\thetaPθ 相比参考模型 PrefP_{\text{ref}}Pref ,更偏向“好样本” ywy_wyw 而压低“差样本” yly_lyl 的条件概率;
- σ\sigmaσ 是 logistic 函数,β\betaβ 控制温度/分离度;
- 不直接训练奖励模型,稳定且简单;
- 放到语音领域,就是让模型在相同语义条件下,对低 WER、停顿合适的语音序列给更高似然,从而减少读错/卡顿/乱停顿。
阶段三:多说话人指令微调(自然度&可控性)
做什么
- 在阶段二的基础上做多说话人/多风格的指令跟随微调;
- 目标是让 Talker 听起来自然,并且可控(例如指定“女声/男声/某角色音色/更活泼/更沉稳”等)。
结果
- 同时生成文本与语音:Qwen2.5-Omni 的 Talker 能与 Thinker 并行,输出文本答复的同时实时说出来;
- 稳定、自然、可被控制的口语化回答。
4、公式与训练落地要点(实践视角)
-
ICL / 语音续写
- 语音建议使用离散化编解码器(如神经 codec)token 做 NTP;
- 训练时把文本 token 与语音 token 混排到同一序列,或使用双头(文本头/语音头)共享部分骨干参数;
- 对齐策略:保持“内容→语音”的单调性,避免乱序对齐;可用简单前后窗/CTC-式辅助对齐(若需要)。
-
音色解耦
- 常见做法:在内容表征后接说话人分类器 + 梯度反转层,或加入信息瓶颈/互信息最小化正则,让内容难以携带音色信息。
- 目的:同一句话可在不同音色下稳定表达,不把稀有文本模式绑到单一声音。
-
DPO 阶段
-
参考模型 PrefP_{\text{ref}}Pref 固定,一般取阶段一/二早期快照;
-
关键在于构造好/坏成对样本:
- 好样本低 WER、停顿/标点合理,坏样本相反;
- 可从同一上下文下的多次采样得到候选,再据指标打分选 yw,yly_w, y_lyw,yl。
-
β\betaβ 可做网格/分层搜索,避免过强/过弱拉扯。
-
-
多说话人微调
- 加入说话人提示/嵌入(speaker id、参考语音条件或描述性指令);
- 关注跨说话人泛化与风格可迁移(few-shot 指令更换音色/风格)。
5、评估与风控
- 听写准确:WER(含数字、专有名词);
- 韵律/停顿:基于标点/短暂停顿的错误率或韵律边界匹配度;
- 自然度与可控性:MOS、ABX 主观测评 + 指令一致性;
- 鲁棒性:嘈杂背景、口音变化、长上下文串讲;
- 幻觉监控:文本-语音对齐审计(例如关键实体错读、凭空添加)。
6、你可能没想到的改进选项
- 奖励组合:除 WER/停顿,可加入韵律相似度(F0/能量轨迹)、对齐稀疏性/稳定性指标,构造更贴合“可懂且自然”的偏好对。
- 多参考对齐:以 Thinker 文本为锚,约束 Talker 在关键词时间位置附近对齐(软约束),减小长句漂移。
- 轻量个性化:LoRA 对 说话人/风格 做小样本适配,上线时按需热插拔。
- 采样策略:推理端用温度分段/韵律先验约束,减少“平铺直叙”或“过度夸张”。
- 实时性:流式解码下采用前瞻极短的 look-ahead 与分块重叠,在不卡住的前提下保证稳定停顿。
7、小结(直给结论)
-
Thinker 先用 ChatML 多模态指令微调,学“理解+计划”。
-
Talker 再用三阶段:
- ICL 语音续写学“会说”和“会变风格”;
- 用 DPO(以 WER/停顿为偏好信号)抑制幻觉、稳住表达;
- 多说话人指令微调提升自然度与可控性。
-
结果是 文本与语音同步生成、稳定且自然,并能按指令切换音色/风格。
二、Mermaid 详细流程图
下面给出Qwen2.5-Omni 后训练(Post-training) 的 Mermaid 详细流程图(含分阶段与关键信号/损失),随后是逐段中文说明
flowchart TD
%% ========= 数据入口 =========
A[ChatML 多模态指令数据<br/>• 纯文本对话<br/>• 视觉会话(图片/视频)<br/>• 音频会话(语音/环境音)<br/>• 混合模态] --> B{预处理与打包}
B --> B1[文本:分词/Tokenize]
B --> B2[视觉/视频:特征或帧级编码<br/>(如视觉编码器输出)]
B --> B3[音频/语音:Codec 离散 token<br/>或声学特征]
B --> B4[对话轮封装:<br/><|im_start|>角色…<|im_end|>]
%% ========= Thinker =========
subgraph S1[Thinker:指令微调]
C[多模态指令跟随(Instruction Tuning)<br/>目标:在多模态上下文下生成高质量“语义文本”]
end
B1 --> C
B2 --> C
B3 --> C
B4 --> C
%% ========= Talker 三阶段 =========
C --> D
subgraph S2[Talker:三阶段让模型“会说话”并与文本同步]
direction TB
D[阶段1|ICL + 语音续写(NTP)<br/>• 任务:Next-Token Prediction<br/>• 输入:多模态上下文 + 文本语义 + 语音token<br/>• 学到:语义→语音的单调映射;韵律/情感/口音的上下文适配] --> E
R1-. 正则/对抗 .-> D
R1[音色解耦(Timbre Disentanglement)<br/>• 防止“稀有文本模式 ↔ 特定音色”错误绑定<br/>• 内容表征与音色表征去相关]
E[阶段2|DPO 稳定化(偏好优化)<br/>• 构造三元组 (x, y_w, y_l)<br/>• 依据:WER 与 标点/停顿错误率打分排序<br/>• 目标:提升好样本似然,抑制差样本] --> F
F[阶段3|多说话人指令微调<br/>• 说话人/风格/情感可控<br/>• 进一步提自然度与可控性] --> G
end
%% ========= 输出与部署 =========
G --> H[推理与服务化<br/>• 同步生成“文本+语音”(可流式)<br/>• 支持说话人/风格指令控制]
%% ========= 评估回路(可选持续学习) =========
H --> I{评估与数据回流}
I --> I1[客观指标:WER、停顿/标点错误、时长/速率稳定性]
I --> I2[主观指标:MOS/ABX 自然度与指令一致性]
I -->|挖掘难例/纠错| A
flowchart LR
%% ========== DPO 子流程细化 ==========
X[输入上下文 x(文本+多模态)] --> SAMP[采样/生成多个语音候选 y_i]
SAMP --> SCORE[打分:<br/>• 词错误率 WER<br/>• 标点/停顿错误率]
SCORE --> RANK[排序与配对:选“好样 y_w”与“差样 y_l”]
RANK --> DPO[计算 DPO 偏好损失:<br/>鼓励 Pθ(y_w|x) 相对参考模型更高;<br/>抑制 Pθ(y_l|x)]
DPO --> UPDATE[反向传播更新 Talker 参数 θ]
UPDATE --> SAMP
逐段说明(中文)
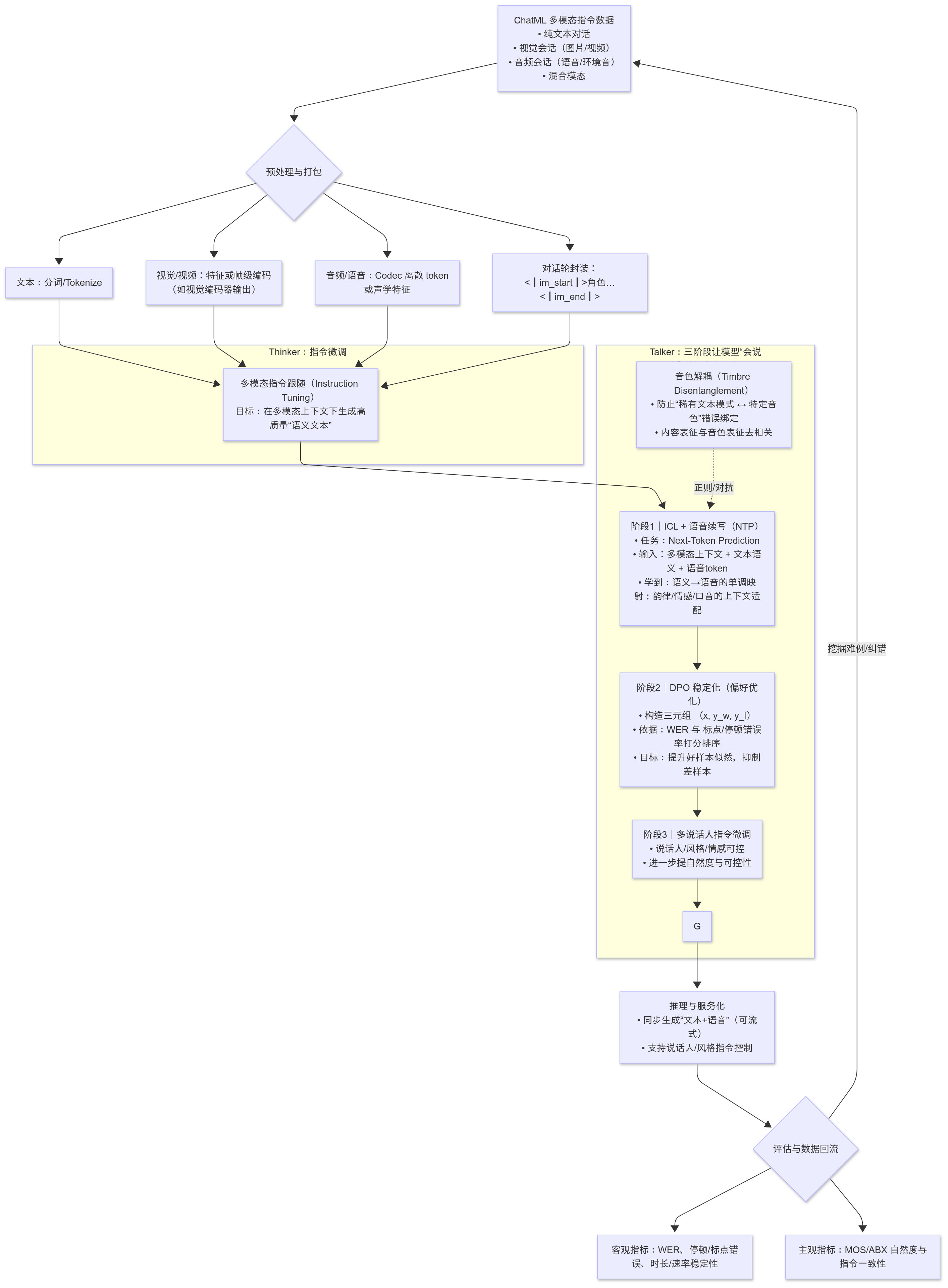
1) 数据与格式(ChatML)
- 目的:把文本、图像/视频、音频/语音和对话轮统一到一种可训练的样式。
- 做法:使用 ChatML 封装对话轮(
<|im_start|>user ... <|im_end|>/<|im_start|>assistant ...),并用<|vision_start|>…<|vision_end|>等标记嵌入视觉/视频提示,语音侧使用 codec 离散 token 或声学特征承接到 Talker。 - 收益:同一条样本既能训练“理解与规划”(文本)也能训练“发声与表情达意”(语音)。
2) Thinker(指令微调)
- 定位:多模态语义中枢。
- 训练:在 ChatML 格式的多模态数据上做 instruction-tuning,学会在复杂上下文中输出高质量文本答复/语义计划。
- 输出:稳定、正确、可控的“文本语义”,后续被 Talker 消化成“语音”。
3) Talker · 阶段 1 —— ICL + 语音续写(NTP)
- 任务:把“文本语义 + 上下文”续写为“语音 token 序列”(Next-Token Prediction)。
- 关键:学习语义→语音的单调映射(时序基本一致),并从大量对话-口语数据中吸收韵律/情感/口音的上下文依赖。
- 音色解耦:通过对抗/正则/信息瓶颈等方法,降低“文本稀有模式被某固定音色绑死”的风险,提升说话人可迁移性。
4) Talker · 阶段 2 —— DPO 稳定化(Direct Preference Optimization)

- 为何需要:真实数据常有口误/对齐噪声,模型易出现读错词/乱停顿等幻觉。
- 数据构造:对同一上下文 xxx 生成多个候选语音 yiy_iyi,用 WER 与 标点/停顿错误率 打分,形成偏好对 (好样 ywy_wyw, 差样 yly_lyl)。
- 优化目标:用 DPO 让当前模型在参考模型基础上更偏好好样本、抑制差样本,无需显式奖励模型与 PPO 稳定技巧,简单高效。
- 效果:显著提升可懂度与稳定停顿,降低发音幻觉。
5) Talker · 阶段 3 —— 多说话人指令微调(SFT)
- 目的:在稳定可懂的前提下,提升自然度与可控性。
- 方式:加入“说话人/风格/情感”指令或嵌入,让模型能按需求切换男女声、口音、风格强弱、情绪色彩等。
6) 推理与服务
-
同步输出:Thinker 与 Talker 协同,**
-
控制接口:通过提示词或参数切换说话人/风格,满足多场景交互。
7) 评估与数据回流(可持续优化)
- 客观:WER、标点/停顿错误、时长/速率稳定性、对齐一致性。
- 主观:MOS/ABX、指令一致性(是否按要求的音色/情感/节奏说话)。
- 闭环:把难例与错误样本回流,继续 ICL/DPO/SFT 微调。
提示与可选增强
- 奖励更丰富:在 DPO 中加入韵律相似度(F0/能量轨迹)、关键词对齐约束等,可进一步优化“自然度 + 准确性”平衡。
- 个性化轻量适配:用 LoRA/Adapter 做小样本说话人快速定制。
- 实时性优化:流式分块解码 + 极短前瞻,保证低时延与稳定停顿。
以上流程图与说明既覆盖了论文中“Post-training”的核心脉络,也补充了工程落地要点,便于你把 Qwen2.5-Omni 的“同时文本+语音生成”训练管线复现或迁移到自己的多模态系统中。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)