大模型为什么会有幻觉?如何溯源造成幻觉的文本?
像调试代码一样debug出导致幻觉的元凶
论文标题
Why and How LLMs Hallucinate: Connecting the Dots with Subsequence Associations
论文地址
https://arxiv.org/pdf/2504.12691
代码地址
https://github.com/sunyiyou/SAT.git
作者背景
加州大学伯克利分校,华盛顿大学,斯坦福大学
动机
幻觉问题已是老生常谈的大模型缺陷,模型可能自信地提供错误答案,捏造不存在的引用文献,甚至在医疗、法律等关键领域输出误导性信息,严重削弱了LLM的可靠性和可信度。与传统的软件系统不同,我们很难对LLM的输出进行调试溯源;当出现幻觉时,开发者缺乏有效的工具来追踪问题根源。因此,理解为何以及如何产生幻觉,进而找到缓解办法,已成为提升LLM可靠性的重要研究方向。

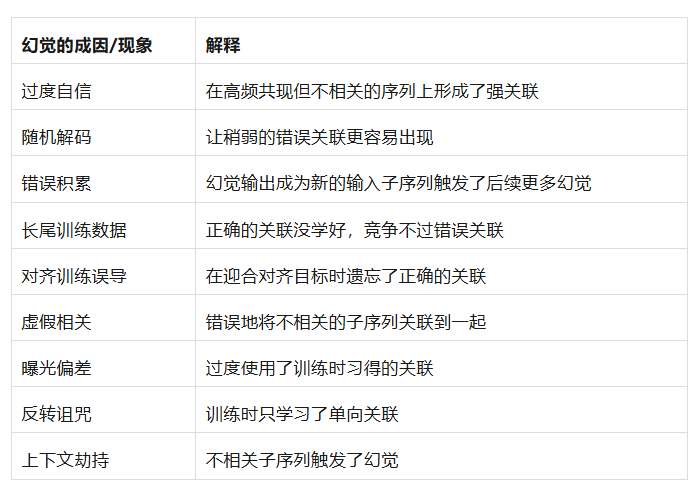
目前学界对幻觉成因的认识仍显得零散而模糊。一方面,幻觉可能由多种因素引起且彼此交织。以往研究提供了一些有价值的见解,但往往各自聚焦于单一因素。这些可能的因素包括但不限于:
- 过度自信:模型对其生成内容过于自信,即使内容是错误的。
- 随机解码:生成过程中随机采样造成输出偏离真实
- 错误累积:生成过程小错误逐步累积放大,导致后续内容严重偏离事实
- 长尾训练数据:模型对训练语料中的罕见样本学习不足。
- 对齐训练误导:在对齐/微调过程中引入了不正确的偏差
- 虚假相关:模型从数据中学到了一些表面相关的固定模式
- 曝光偏差:训练时模型总是接收真实前文,与推理时不一致,可能导致输出逐渐偏离
- 反转诅咒:自回归特性造成模型对否定或反转逻辑理解不佳
- 上下文劫持:输入中某些无关片段抢占了模型注意力,误导其生成不相关或错误内容
此外,传统的归因方法(如LIME、梯度分析)往往只能给出单个词的重要性,无法有效找到幻觉的具体根源。
本文方法
本文提出了一个统一的理论框架,称为子序列关联(Subsequence Association),帮助我们系统地分析幻觉现象。具体来说,幻觉的出现是因为模型对某个特定输入片段(子序列)与错误输出之间的关联强度高于与正确输出之间的关联。具体实现如下:
定义一个度量指标来衡量输入和输出之间的关联强度:输入子序列出现时输出子序列也出现的概率,与两者各自独立出现概率的比值(取对数,类似于点互信息,PMI)
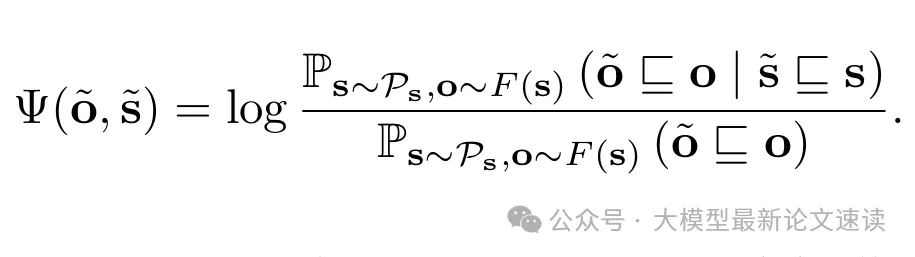
这个度量指标越大,表示模型在给定输入子序列下,产生指定输出的概率显著高于偶然水平;反之则表示该输入对输出片段的影响不大。
提出一种子序列关联追踪算法(SAT),用于找出导致幻觉的具体子序列。这个算法通过随机修改输入上下文,观察哪些片段稳定地触发相同幻觉输出,从而确定最可能的幻觉触发子序列。具体步骤为:
- 对幻觉输出进行定位(例如一个错误事实)
- 从原始输入中选择一个token子序列作为候选
- 生成多个随机变体输入:保持候选子序列不变,修改其他上下文内容
- 观察幻觉在这些变体输入中的复现概率
- 重复2-4步,找出复现率最高的子序列
由于暴力枚举所有可能的子序列组合十分困难,作者在实现中使用了一些启发式策略来高效搜索触发子序列。例如,利用模型生成子序列对应的embedding并执行聚类,在每个簇中采样候选子序列,从而减少搜索空间;同时采用贪心和beam search等技术逐步扩展候选子序列
于是我们便可以把解码过程视为不同子序列关联的竞争:理想情况下,输入应该与正确的输出存在较强的关联,但如果模型内部学到的幻觉关联更强,模型便倾向于走向错误的方向
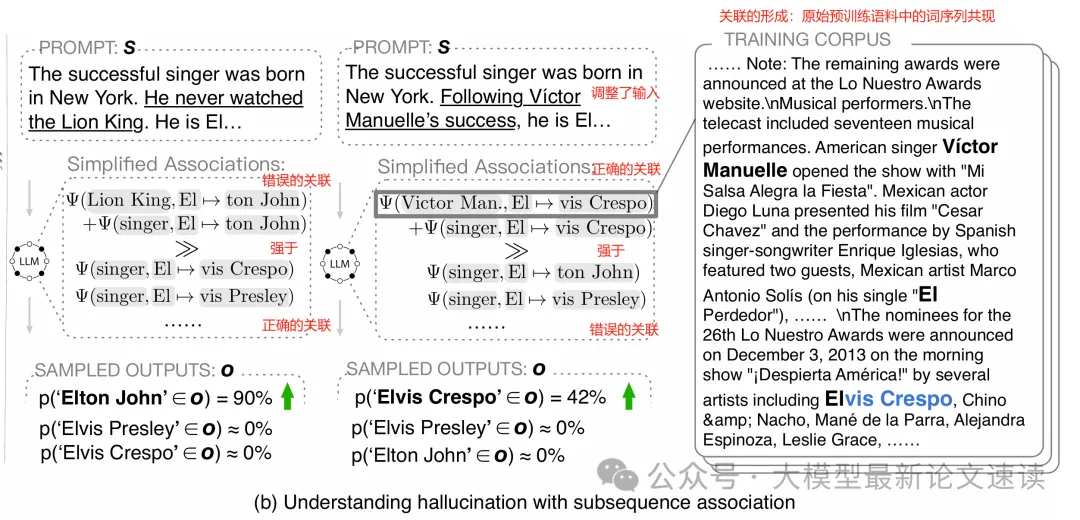
在“子序列关联竞争”的视角下,之前人们提出的各种幻觉成因与现象都能得到统一的解释:
SAT算法为我们提供了一种幻觉归因方法:识别出触发幻觉的子序列后,便可以在训练语料中进行搜索,作者结果发现这些子序列与幻觉内容的组合往往确实存在于训练集中。也就是说,模型并非无中生有地编造幻觉,而是在重复训练语料里某些子序列-输出搭配
实验结果
一、幻觉归因准确性
作者使用了一个名为HALoGEN的公开基准数据集,包含超过一万个测试案例,涵盖了代码生成、人物传记、科学引用等多个领域,每个案例都有程序化的验证方法,可以确定模型输出是否存在幻觉
在不同模型(7B参数和70B参数)上运行SAT算法,与传统归因方法效果进行比较,衡量标准为“幻觉再现率”,即归因子序列出现时,模型再次产生相同幻觉的概率
实验结果如下:
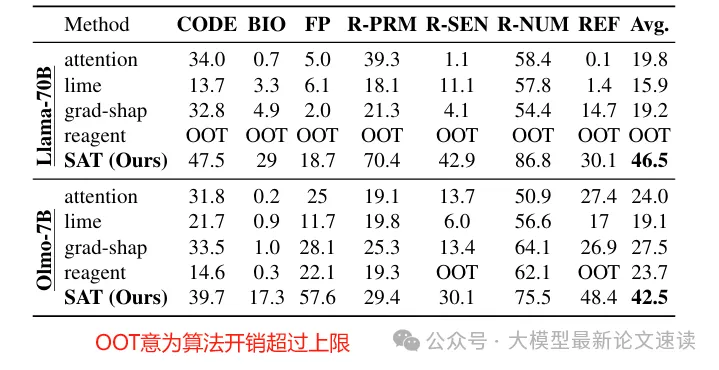
可见SAT方法归因结果的幻觉再现率显著超过传统方法,平均高出约26%,体现了其在定位幻觉原因方面的有效性;
二、模型尺寸、子序列长度、噪声占比对幻觉的影响
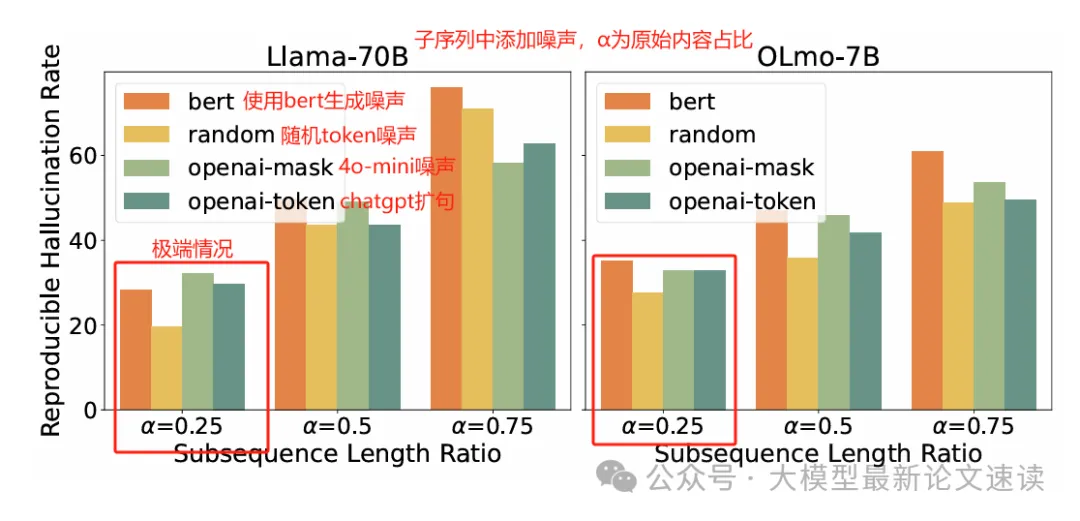
- 子序列长度越长,再现率越高,因为更长的原始子序列携带了更多的原始幻觉触发信息;
- 即使在子序列非常短(如25%)且其余token完全随机的情况下,幻觉依旧能以一定概率再现。这说明LLM对某些子序列有极强的关联记忆,即使上下文被大量噪音稀释,幻觉仍然能重复出现;
- 不同模型(大模型、小模型)均呈现了这种稳定的幻觉复现模式,表明子序列关联机制广泛存在于不同规模LLM内部
三、训练语料验证
为了验证前文提到的训练语料溯源能力,作者对比了模型内部产生幻觉的关联强度(即SAT方法计算的再现率,纵坐标)与模型训练语料(Dolma-1.7数据集)中该子序列-输出组合出现的实际概率(横坐标)
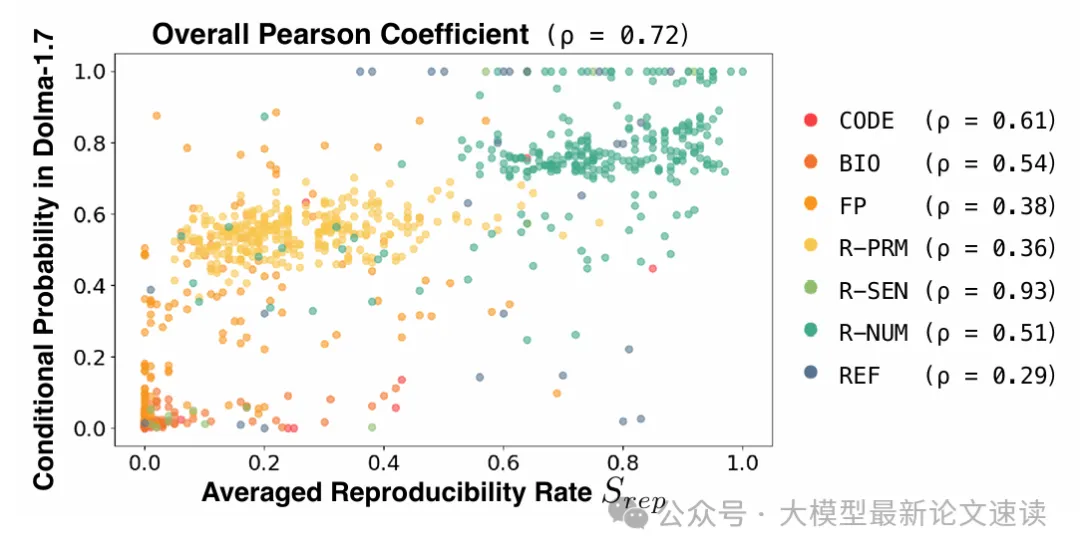
图中大部分测试点呈现明显的正相关关系,总体Pearson系数达到0.72,说明模型内部的幻觉关联强度确实很大程度上直接来自于训练数据的分布特征,即模型记忆并复现了数据中已有的关联模式。
总结
本文提出了一种符合直觉、推理过程完备的幻觉解释框架,并开源了一种高效准确的幻觉溯源算法,有且不限于以下实际应用价值:
- 为模型的错误输出提供可解释的原因
- 训练模型时,针对性地修正训练数据,降低错误关联的强度。
- 构建幻觉预警系统,当检测到高风险子序列时,主动核实或提示用户。
- 提升LLM在医疗、法律等关键领域的应用安全性和可信性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)