Docker Desktop 配置canal实现监听MySQL binlog发送到RabbitMQ
在这里我是选择了基于Binlog的实时同步,也就是用canal监听Mysql的binlog来实现同步,同时为了提高可靠性,我选择了利用消息队列来接收canal的消息,后续再由消费者来做插入es的操作。这一步主要是将canal.properties和instance.properties配置文件提取出来映射到Windows宿主机,后面的D:\Develop\canal只是一个自定义存放文件的目录,先
一、背景
最近在做一个网盘项目。文件搜索场景,考虑到海量文件元数据下的模糊查询。于是就想到了利用ES。关于ES的优势不必多说。
本文的重点主要在于如何做mysql与es之间的同步,主流方法是用logstash来做初始迁移的全量同步;用同步双写、异步双写、基于 SQL 的数据抽取和基于 Binlog 的实时同步等。这些方案各有优缺点,且在不同场景下会选择不同的工具。在这里我是选择了基于Binlog的实时同步,也就是用canal监听Mysql的binlog来实现同步,同时为了提高可靠性,我选择了利用消息队列来接收canal的消息,后续再由消费者来做插入es的操作。
本文受以下启发:
在数据同步过程中,我们可以直接使用 Canal 自带的 Canal Adapter,将 MySQL 数据变化实时同步到 Elasticsearch。这种方式实现简单且直观,适合对同步性能要求较高且系统结构相对简单的场景。
然而,在实际应用中,业务需求往往更为复杂,我们可能需要更加灵活的同步方式,比如异步处理、多系统分发、或者更高的容错能力。在这些情况下,我们可以在 Canal 和 Elasticsearch 之间引入消息队列(如 RabbitMQ),以满足以下场景需求:
- 多系统分发
如果数据不仅需要同步到 Elasticsearch,还需同步到其他系统(如缓存系统、推荐系统等),引入 RabbitMQ 可以让 Canal 只负责将数据推送到 RabbitMQ,由多个消费端从 RabbitMQ 订阅消息并写入不同的目标系统,实现灵活的数据分发。- 异步与容错处理
Canal 和 Elasticsearch 的直接连接是实时且同步的,而 RabbitMQ 可以作为缓冲区来存储 Canal 推送的变更事件,便于异步消费。如果 Elasticsearch 出现短暂故障,RabbitMQ 会将 Canal 的消息缓存,待 Elasticsearch 恢复后再继续消费,避免数据丢失。- 负载均衡
通过 RabbitMQ,还可以实现同步负载的分摊,防止 Canal 和 Elasticsearch 直接连接时出现高负载问题,有效保障系统的稳定性。因此,在数据同步方案设计中,如果对系统的稳定性、容错性和可扩展性有更高要求,可以考虑使用 RabbitMQ 等消息队列来增强 Canal 的同步能力,实现灵活而高效的数据同步。
二、Docker Desktop 部署canal+MySQL+rabbitMQ
本文已经默认你用Docker Desktop部署过MySQL与rabbitMQ,主要是看网上类似的文章,大多是用Linux环境来做的canal部署,于是想写一篇用Docker Desktop部署canal的,这其中也包含了博主自己踩过的一些坑。以下命令均基于windows的powershell来实现。
1. 拉取canal镜像
docker pull canal/canal-server:latest直接拉取最新的镜像,然后进行以下操作。
2.部署canal容器,提取配置文件到Windows宿主机
docker run -p 11111:11111 --name canal -d canal/canal-server:latest docker cp canal:/home/admin/canal-server/conf/canal.properties D:\Develop\canal
docker cp canal:/home/admin/canal-server/conf/example/instance.properties D:\Develop\canal 这一步主要是将canal.properties和instance.properties配置文件提取出来映射到Windows宿主机,后面的D:\Develop\canal只是一个自定义存放文件的目录,先按我们想要的配置好,然后再挂载到新的一个容器上。
3.配置canal.properties文件
canal.serverMode = rabbitMQ // 改为rabbitMQ模式
rabbitmq.host = mq // 个人rabbitMQ容器的名称,只要mq和canal配置了同一个网络,就能自动识别
rabbitmq.virtual.host = /cloud // rabbitMQ的虚拟环境,需要提前配置,如果没有就默认为 /
rabbitmq.exchange = canal.exchange// 配置的交换机名称
rabbitmq.username = clouddrive //登录rabbitMQ的账号,按个人的来
rabbitmq.password = 123 //登录rabbitMQ的密码
rabbitmq.deliveryMode = 2 //direct模式这个文件只用做以上改动,其余的不要动,否则容易报错。
4.配置instance.properties文件
canal.instance.mysql.slaveId=2 // 设置slave,监听主Mysql的binlog,不能和Mysql的server_id重复
canal.instance.master.address=mysql:3306 // 这里的mysql也是个人容器的名称,同样需要与canal放在一个网络中,能自动识别
canal.instance.filter.regex=cloud_drive.file_info // 监听具体的表,此处我只用监听cloud_drive库下的file_info表
canal.mq.topic=canal.routing.key // canal队列绑定的key名称5.挂载配置到新的容器上(重点)
先删除旧的canal容器,可以执行命令,也可以在docker desktop页面手动删除:
docker stop canal
docker rm canal

然后再重新新建一个容器,挂载配置好的配置文件:
docker run --name canal -p 11111:11111 --network mynetwork -d -v D:\Develop\canal\instance.properties:/home/admin/canal-server/conf/example/instance.properties -v D:\Develop\canal\canal.properties:/home/admin/canal-server/conf/canal.properties canal/canal-server注意这里要指定网络为mynetwork(依据个人情况来),也就是mysql和rabbitMQ容器所在的网络!如果不指定,前面配置的文件里的“mq”、“mysql”会找不到对应容器的地址。如果不知道怎么新建网络,可以去网上搜索,这里不赘述了。网络配置完之后可以用以下命令查看是否配置成功:
docker network inspect mynetwork显示如下:
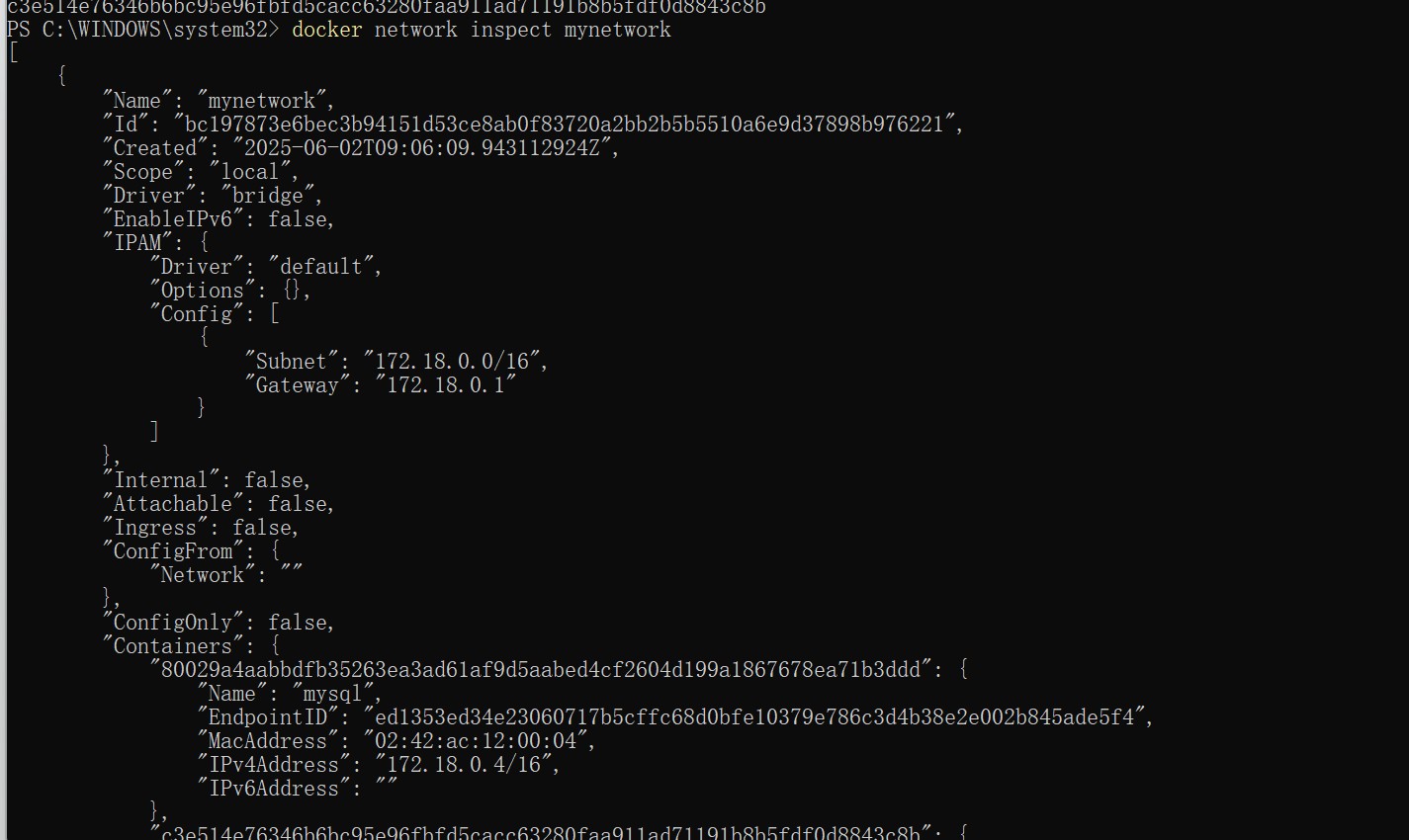
重点是看容器是否都在当前网络中了:
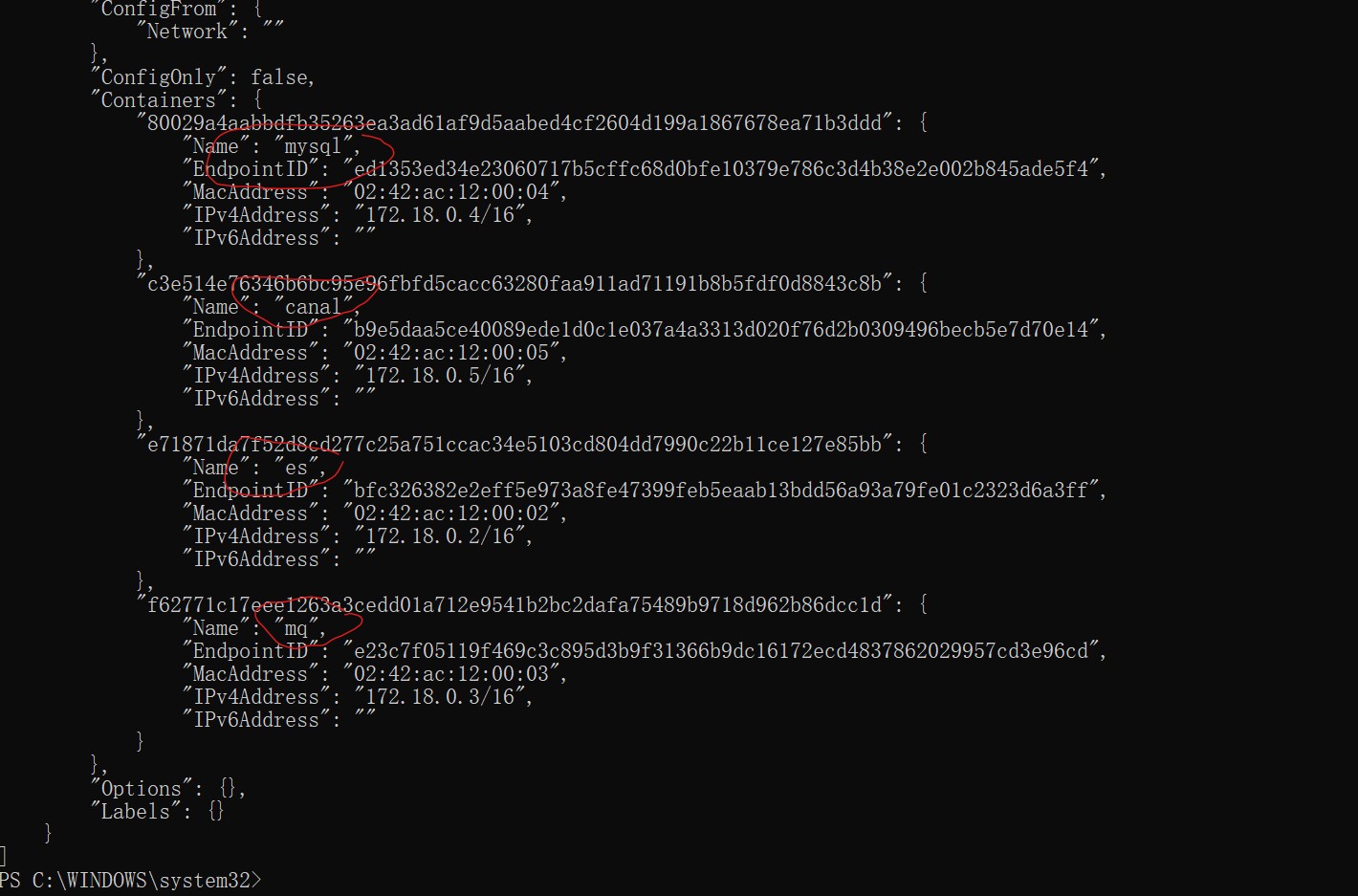
如图所示,mysql、es、rabbitmq、canal容器都在一个网络中,即为成功。
6.校验canal容器的对应logs文件
这一步非常重要,直接决定了canal配置成功与否。
执行以下命令,将canal容器的logs目录拷贝到宿主机,查看日志:
docker cp canal:/home/admin/canal-server/logs/ D:\Develop\testSuccess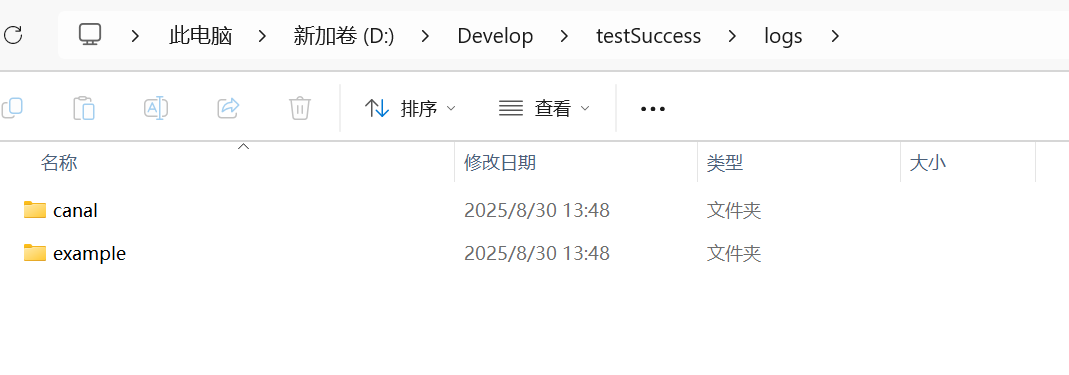
如果出现了这两个文件夹,那么大概率就成功了。如果缺失example文件夹,则查看canal/canal.log文件,里面通常会记录异常日志。根据博主个人经验,大概率是ConnectException,也就是识别不到mysql或者rabbitMQ导致的。这种情况,仔细检查容器是否都在一个网络下了。
7.测试
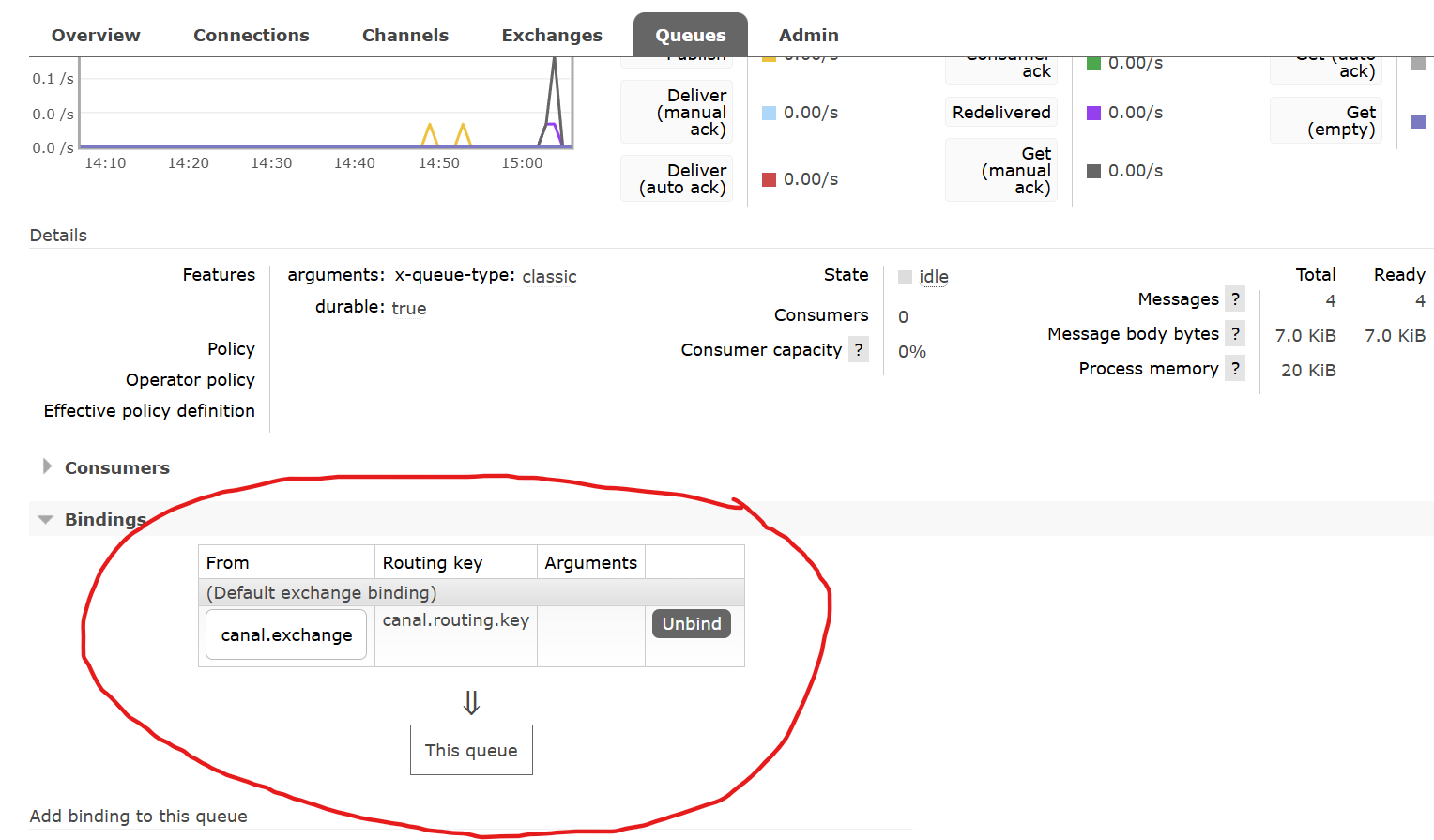
注:此处默认你已经创建了canal.exchange交换机和canal.queue队列,并且用canal.routing.key为绑定键了:
首先修改file_info表(也就是canal监听的那张表)中的一个字段,这里我直接用idea修改了,效果和sql update语句是一样的:

查看rabbitMQ是否正常收到了消息:
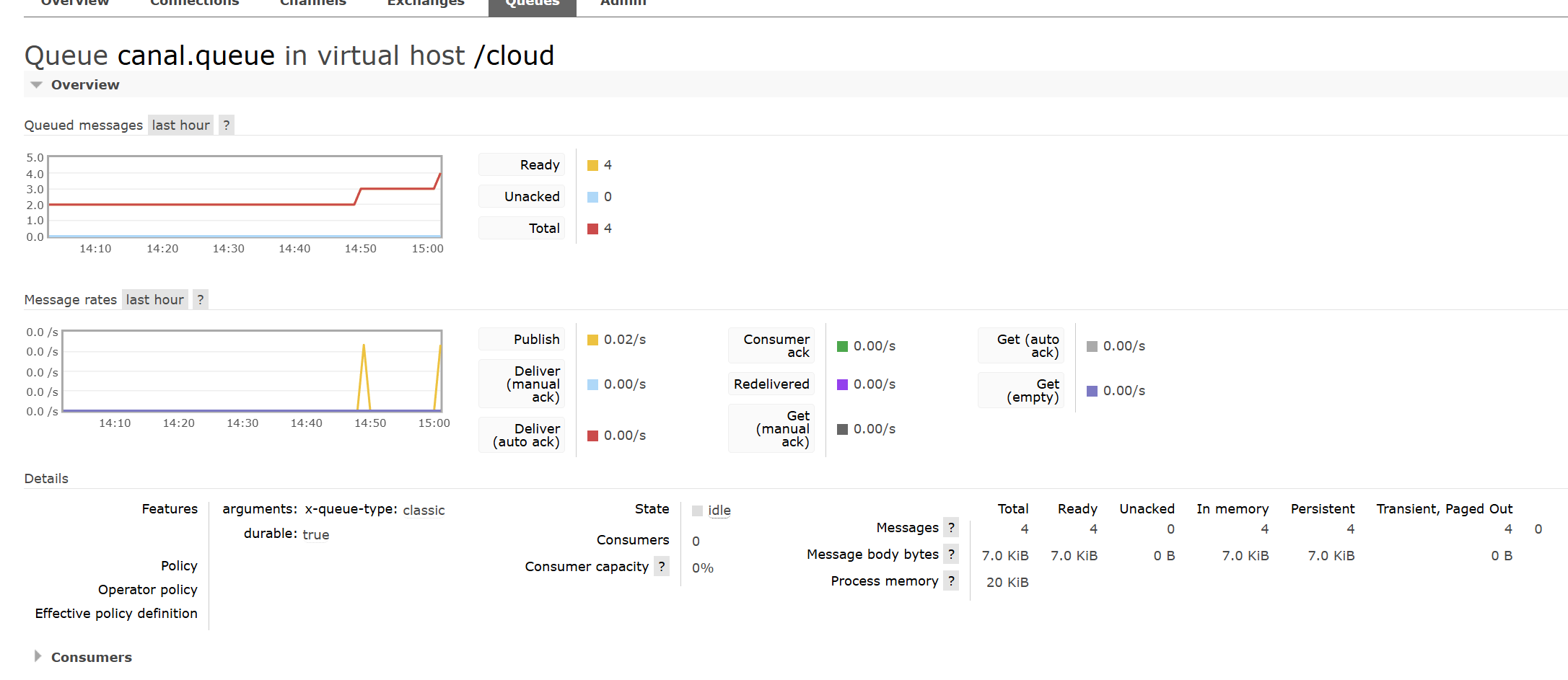
可以看到canal.queue队列接收到了binlog消息,如果不信,再点击Get Message查看:
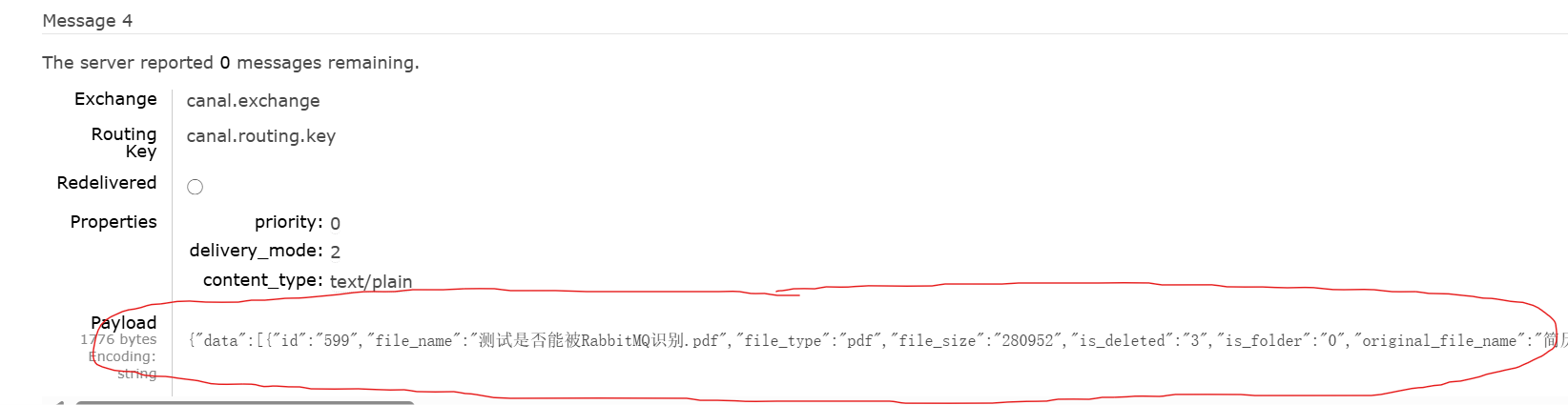
完美!rabbitMQ成功接收到了binlog消息。我们可以利用这个消息来做后续的es同步等等操作。
本文到这里就结束了,后续的消费者消费binlog消息同步到es的部分,有空我会补上,敬请关注。看到这里还请点个赞或者点个关注呀~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)