【大模型强化学习】GRAM:一个生成式的预训练 reward model
GRAM 是第一个“生成式基础奖励模型”,通过无监督预训练 + 有监督微调 + 标签平滑,显著提升了奖励模型在多个任务上的泛化能力,且只需极少标注数据。场景用法没有标注数据直接用 GRAM 做奖励模型有少量标注数据微调 GRAM,快速适配做 RLHF用 GRAM 替代传统判别式 RM做评估用 GRAM 做自动评价器(代替 GPT-4)
GRAM:一个生成式的预训练 reward model
关键词:#大模型 #奖励模型
- 论文题目:GRAM: A Generative Foundation Reward Model for Reward Generalization
- arXiv:2506.14175
- Accepted: ICML 2025
- 单位:东北大学
- https://github.com/NiuTrans/GRAM
- 更多论文每日解读关注 v 公众号:https://mp.weixin.qq.com/s/hNtg8OPY9-c5YmEa6Pea2g

🧠 一句话总结:GRAM 是一个“生成式奖励模型”,通过大规模无监督预训练 + 少量有监督微调,显著提升奖励模型在多个任务上的泛化能力。
Introduction
本文认为以往判别式的 reward model 在用于特定任务时需要大量人类标注数据,这篇论文开发了一个生成式的 reward model,它首先通过大规模无监督学习进行训练,随后通过 supervised learning 进行微调,从而得到一个通用的预训练 reward model,能够广泛应用于多种任务,具备良好的泛化性,包括 Response Ranking、RLHF、task-specific fine-tuning 等。
但是这个所谓的 pretrained reward model 仍然是在 single-turn 数据上做的大量预训练,这与实际情况下的 multi-turn 差距很大,所以这篇论文所谓的“泛化性”并不能泛化到 multi-turn 情况下。
Method
判别式 vs. 生成式 reward model
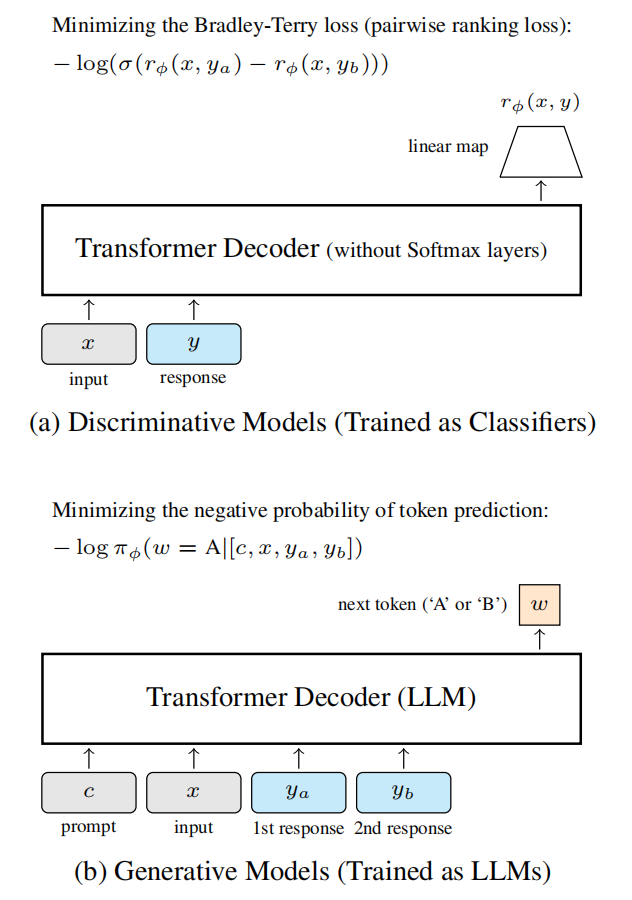
判别式 reward model 与生成式 reward model 的区别:
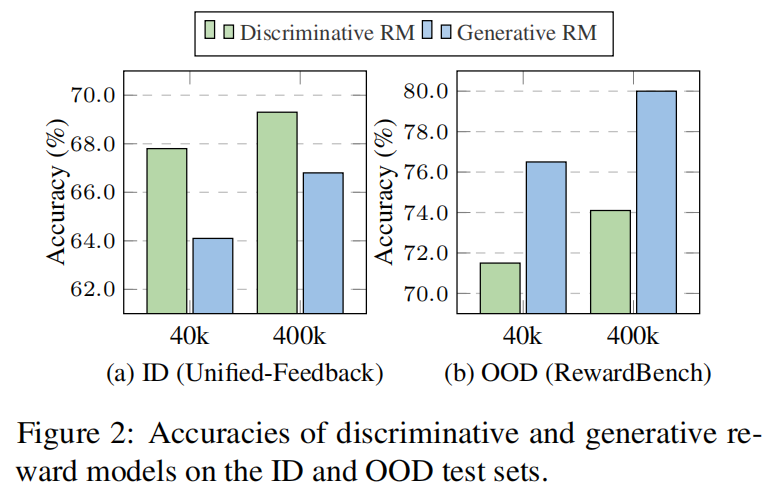
两者在泛化性上的差距(Unified-Feedback 数据集作为 in-domain dataset,RewardBench 作为 out-of-domain dataset):
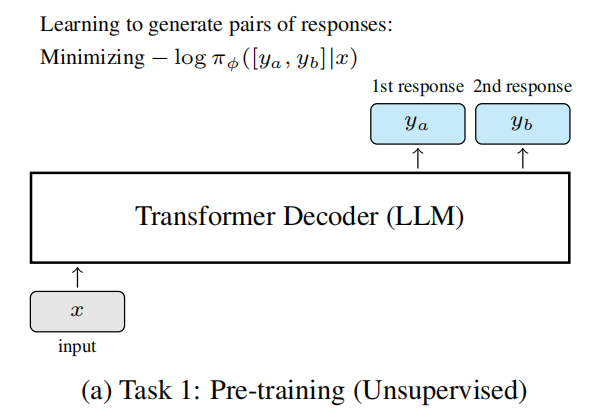
两阶段训练思路
GRAM(Generative Reward Model) 是一个生成式奖励模型,它:
- 先生成文本(无监督)
- 再学偏好(有监督)
- 用标签平滑(Label Smoothing)提升泛化
1)预训练阶段
这一阶段使用无监督数据,让模型学习 response 理解能力,这不需要 human preference data。这一阶段的训练是给 LLM 一个 question,通过 SFT 让他学习两个 response 的生成。
损失函数如下。这种训练让 LLM 学习了从 input 到多样化 response 的映射,从而更好地理解 response。
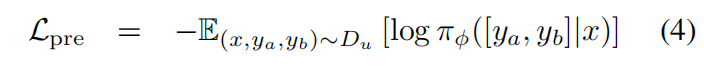
2)微调
这一阶段是标准的监督任务,给 LLM 一个 response pair,让模型生成 label token。这个 label token 表示 LLM 喜欢哪一个 response。
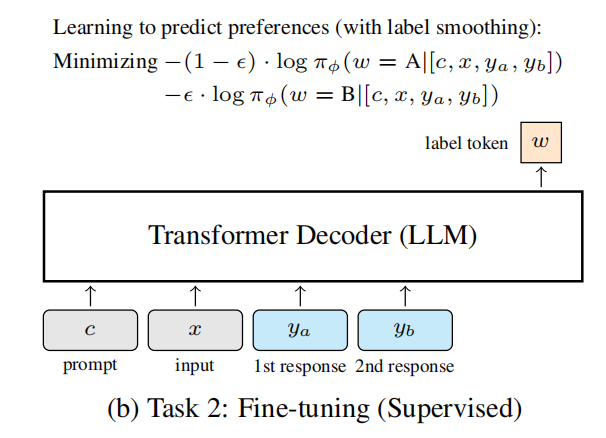
3)标签平滑
另外,论文在做 fine-tuning 时使用了「标签平滑」技术,这更像是一个 trick。
标签平滑 ≈ 优化一个带正则化的 Bradley-Terry 损失
- 缓解过拟合
- 提升泛化
- 在 OOD 上效果尤其明显
实验
- 评估场景:Best-of-N 测试 Response Ranking 能力;基于 reward 的 fine-tuning 效果;reward task 的适应能力。
- Setting:使用 LLaMA-3.1-8B-Instruct 和 LLaMA-3.2-3B-Instruct 作为 base model,使用 Unified-Feedback 的一个 400k 的 subset 作为 training data。
- baseline:LLM-as-a-Judge 以及其他一些开源的判别式和生成式 reward model。
下图是“成对响应排序”的一个实验结果图:
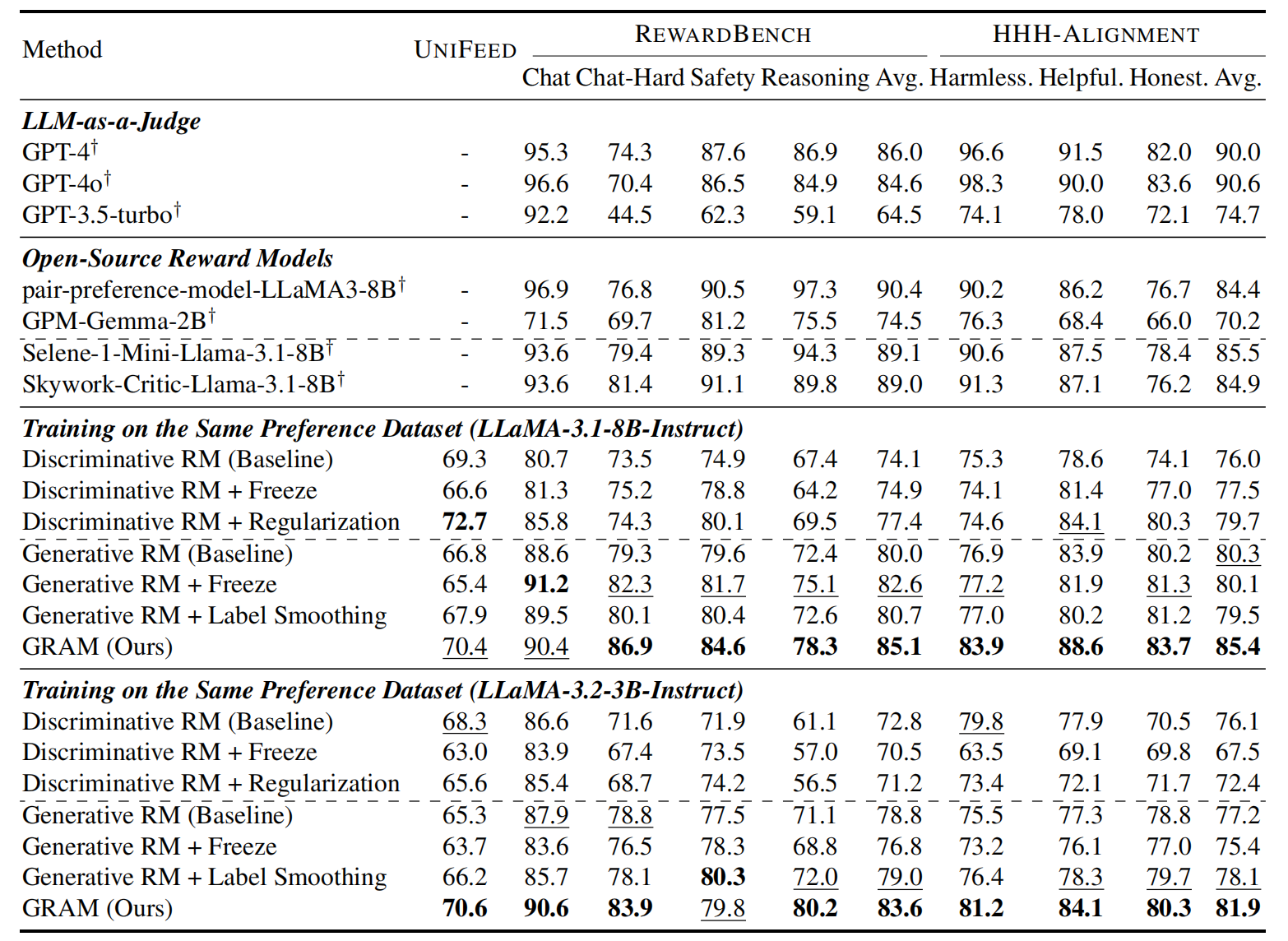
- UniFeed 这一列是 in-domain 的测试结果,其余是 out-of-domain 的测试结果
- 在 in-domain 上,8B 的没有打得过判别式 reward model,但泛化性更好,在 out-of-domain 上表现好很多
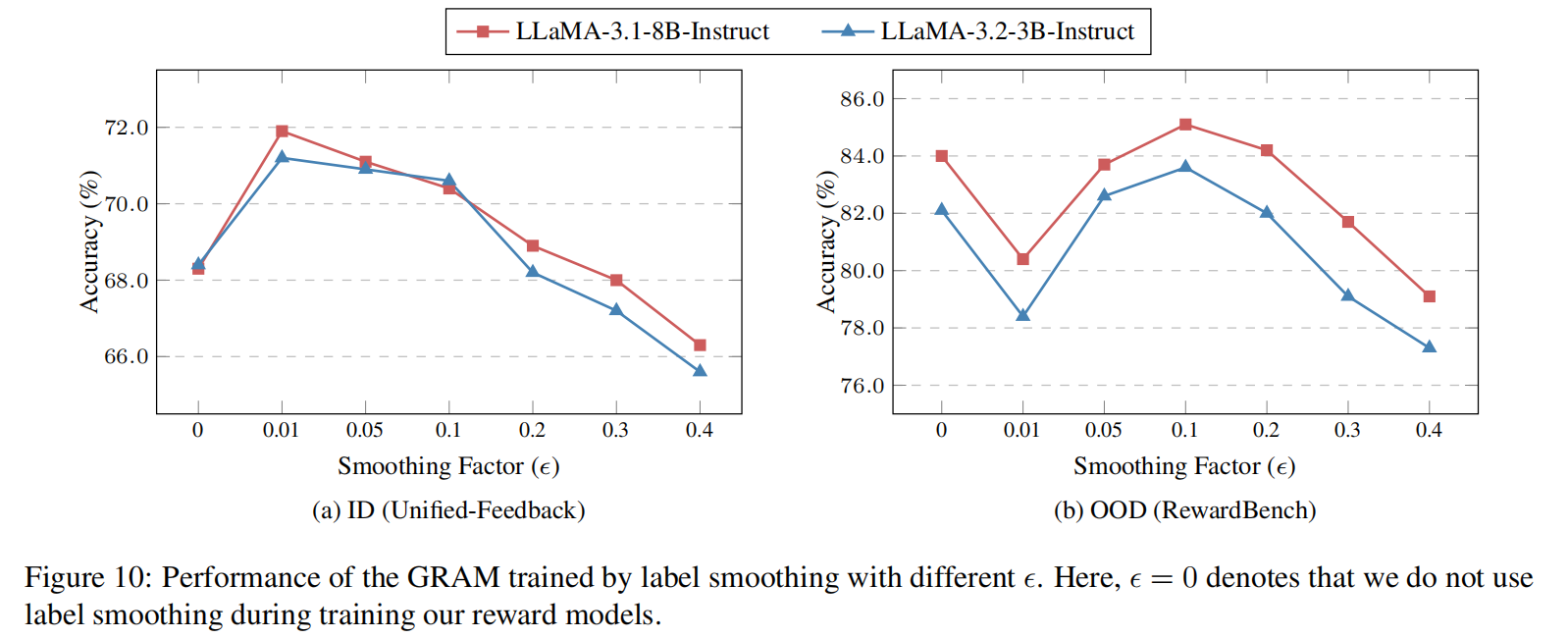
标签平滑的影响:实验表明,标签平滑在生成式奖励模型训练中非常有益,能够显著提高模型的泛化能力。
总结
GRAM 是第一个“生成式基础奖励模型”,通过无监督预训练 + 有监督微调 + 标签平滑,显著提升了奖励模型在多个任务上的泛化能力,且只需极少标注数据。
你可以怎么用 GRAM:
| 场景 | 用法 |
|---|---|
| 没有标注数据 | 直接用 GRAM 做奖励模型 |
| 有少量标注数据 | 微调 GRAM,快速适配 |
| 做 RLHF | 用 GRAM 替代传统判别式 RM |
| 做评估 | 用 GRAM 做自动评价器(代替 GPT-4) |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)