AI病理新突破:跨癌种通用,自监督学习实现诊断与生存预测“一网打尽”!
上海交通大学俞章盛/张岳团队联手搞了个大新闻!他们用1100万张无标签病理切片,训练出一个叫BEPH的AI“全能选手”。这模型不仅能在乳腺癌、肺癌、肾癌等32种癌症中“火眼金睛”识别肿瘤,还能从一张切片里“算”出患者的生存期,准确率吊打传统模型。
引言:当AI学会“无师自通”,病理科医生会失业吗?
上海交通大学俞章盛/张岳团队联手搞了个大新闻!他们用1100万张无标签病理切片,训练出一个叫BEPH的AI“全能选手”。这模型不仅能在乳腺癌、肺癌、肾癌等32种癌症中“火眼金睛”识别肿瘤,还能从一张切片里“算”出患者的生存期,准确率吊打传统模型。更绝的是,它连标注数据都不怎么需要——别人家AI要喂100%的标注数据才能干活,它吃25%的“剩饭”就能干得更好。这波操作直接把小编看呆了!(内心OS:卷成这样,让隔壁用ImageNet预训练的模型怎么活?)

一、背景:病理AI的“痛点”与破局之路
传统癌症诊断依赖病理医生对全切片图像(WSI)的肉眼观察,耗时且易受主观经验影响。随着深度学习在医学影像中的崛起,计算病理学(Computational Pathology)被寄予厚望。然而,现有模型存在两大瓶颈:数据标注依赖性强(标注成本高、专业门槛高)和跨癌种泛化能力不足(不同癌症的形态差异大)。例如,基于自然图像预训练的模型(如ImageNet)难以捕捉病理图像的细粒度特征,而针对单一癌种设计的模型难以适应多任务需求。
当前医疗AI领域正从“任务定制化”向“通用基础模型”转型。BEPH的提出呼应了这一趋势——通过自监督学习(SSL)从海量无标签数据中提取通用特征,减少对标注的依赖。这种思路类似GPT在自然语言处理中的成功,但在医学领域,数据异构性和安全性问题更为复杂。BEPH的创新在于将掩码图像建模(MIM)与病理图像特性结合,为跨癌种分析提供新思路。
二、研究思路:从千万级无标签数据到“一鱼多吃”的BEPH模型
BEPH的核心设计分为三步:
预训练:基于BEiTv2架构,使用来自TCGA的32种癌症、1100万张无标签病理图像进行自监督学习,通过40%掩码率的图像重建任务捕捉全局与局部特征关联。
多任务微调:将预训练模型适配到三大任务——
Patch级分类(单张图像良恶性判断)
WSI级亚型分类(如乳腺癌IDC/ILC亚型区分)
生存预测(基于病理图像预测患者预后)
可解释性验证:通过注意力热图可视化模型关注区域,与病理医生标注对比,验证模型决策合理性。
流程亮点:
数据效率:仅需25%标注数据即可达到传统模型100%数据的性能,缓解标注难题。
跨癌种适配:预训练覆盖32种癌症,模型在肺癌、肾癌等不同任务中表现稳定。
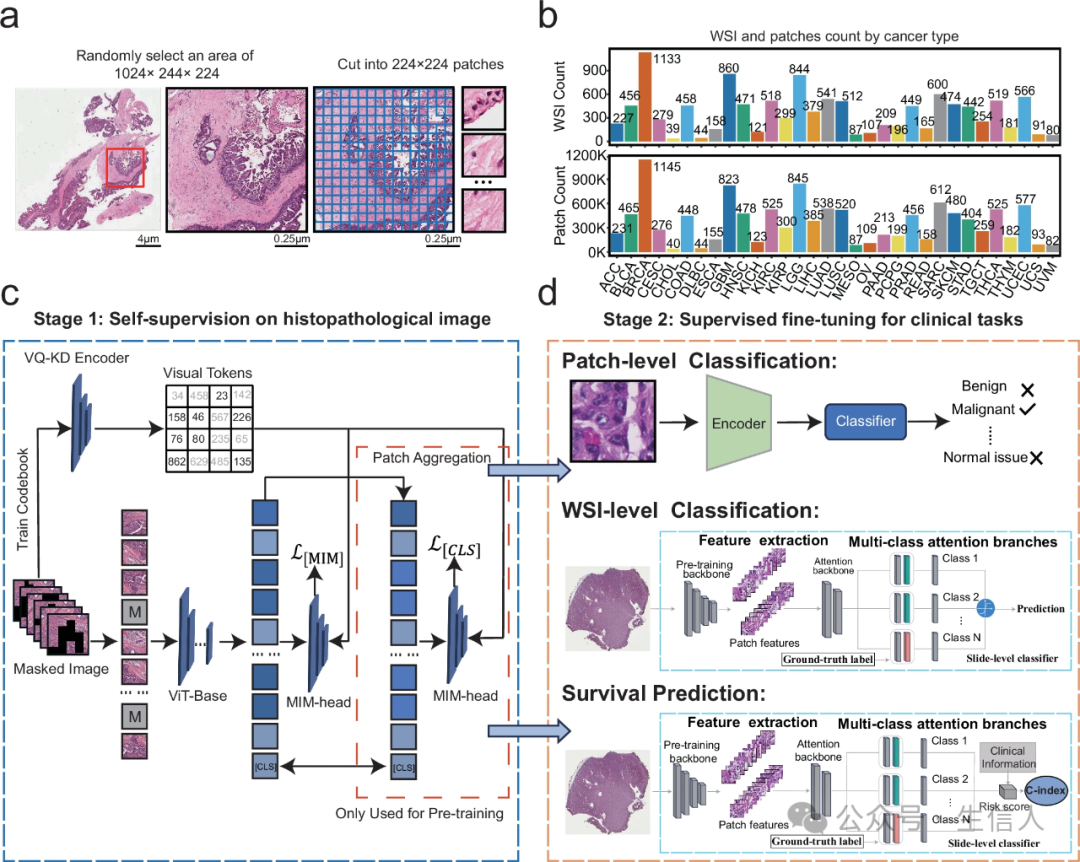
图1 BEPH架构概述
BEPH的“预训练-微调”范式可类比为“先学通用语言,再练方言”。未来若能整合多模态数据(如基因组、临床指标),可能实现更精准的个性化医疗。此外,模型轻量化(如使用ViT-Tiny)可能更适合临床实时部署需求。
三、结果:BEPH的“成绩单”——多维度验证性能突破
Patch级分类:细节丢失也不慌,跨癌种诊断稳了!
BEPH在乳腺肿瘤良恶性分类任务(BreakHis数据集)中展现了“降维打击”能力:即使将图像下采样至224×224像素(丢失70%细节),患者级和图像级准确率仍分别高达94.05%和93.65%,比传统CNN模型(如ResNet、VGG)高出5-10%。更夸张的是,在肺癌亚型分类(LC25000数据集)中,BEPH以99.99%的准确率横扫AlexNet、EfficientNet等模型(图2e)。
BEPH的逆天表现得益于MIM(掩码图像建模)预训练策略。这种“先蒙眼拼图再考试”的学习方式,让模型即使面对模糊图像也能捕捉关键病理特征。有趣的是,BEPH对图像分辨率变化表现出极强的鲁棒性(图2c-d),这意味着未来临床部署时,医院无需升级高分辨率扫描设备即可使用——简直是基层医疗机构的福音!

WSI级分类:弱监督学习也能“卷”出天花板
在肾癌(RCC)、乳腺癌(BRCA)、肺癌(NSCLC)的亚型分类任务中,BEPH仅用25%训练数据时,AUC已达0.909;全量数据下,肾癌亚型分类AUC飙升至0.994,几乎与人类病理专家持平(图2a-b)。即便对比最新基础模型GigaPath(参数规模17倍于BEPH),BEPH在肺癌、肾癌任务中仅落后0.7%,堪称“小模型逆袭”的典范。
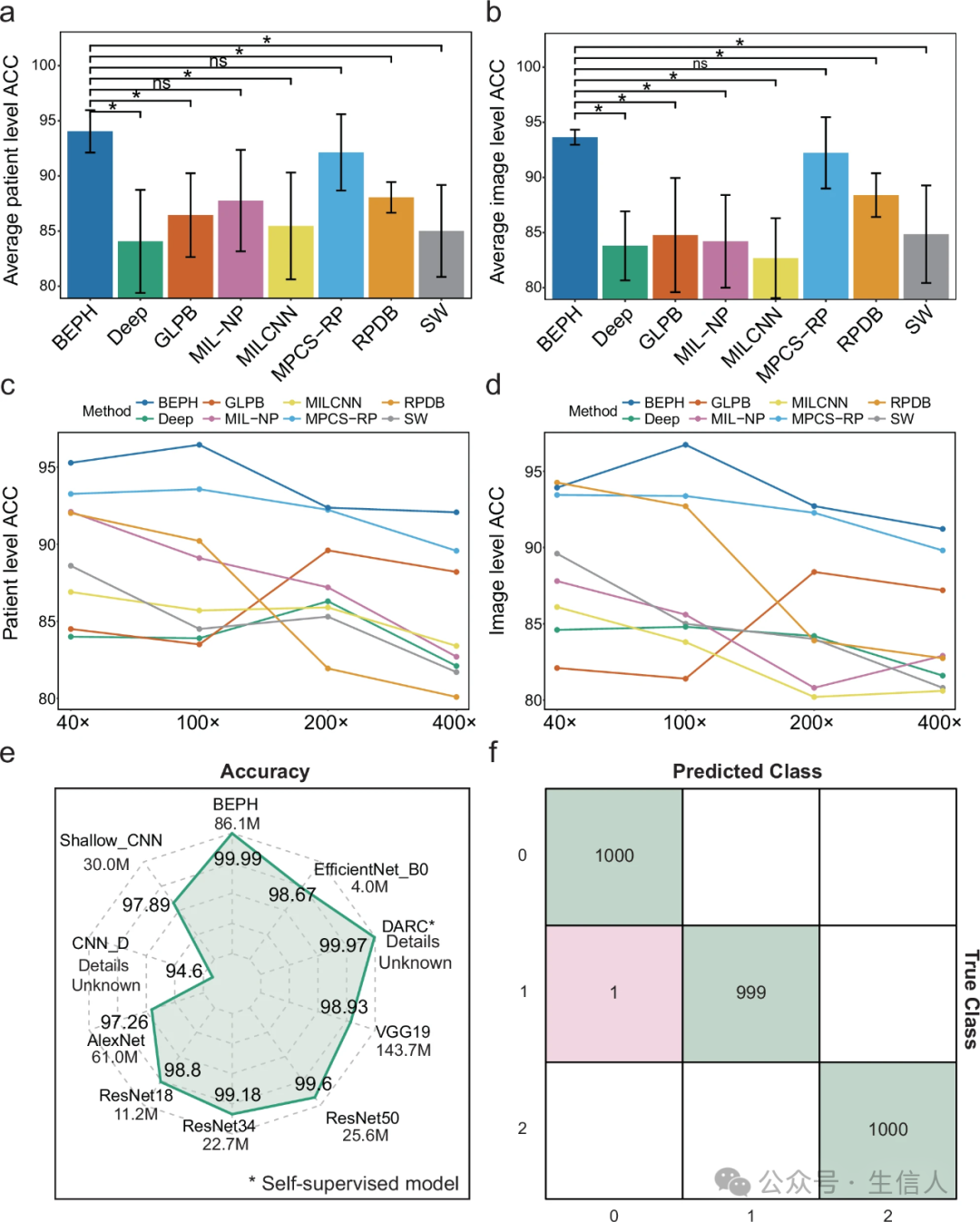
图2 对公开可用的补丁数据集进行性能评估
当训练数据量达到50%时,BEPH性能已与传统模型100%数据相当(图3j)。这暗示了一个反直觉的结论:高质量预训练比堆数据量更重要。就像学霸刷题时先掌握核心考点,再做题自然事半功倍。不过,BEPH在乳腺癌任务中对UNI模型稍显逊色,可能源于乳腺癌的形态异质性更高——模型再强,也怕“病理谜题”太刁钻。
生存预测:从切片中“剧透”患者命运
在乳腺癌(BRCA)、结直肠癌(CRC)等6种癌症的生存预测中,BEPH的C-index(一致性指数)平均提升1.1-5.5%。以肾透明细胞癌(CCRCC)为例,模型预测的高风险组5年生存率显著低于低风险组(p<0.0001),风险分层效果吊打DINO等对比模型(图4b)。
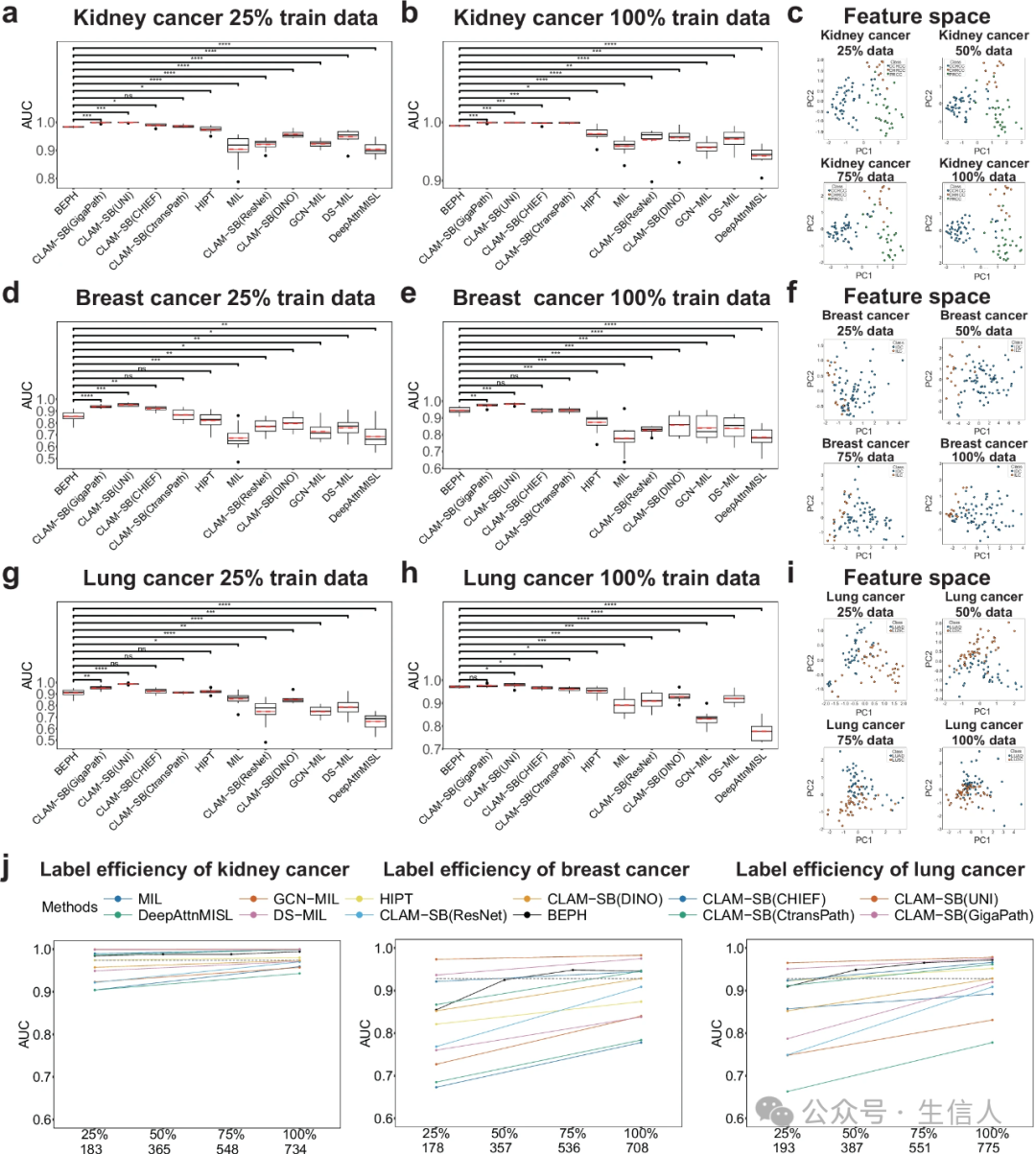
图3 在WSI水平独立测试集上的弱监督分类结果
传统生存预测依赖基因组+临床指标“叠Buff”,而BEPH仅凭病理切片就能“看图说话”。这背后可能是模型捕捉到了肿瘤微环境中未被量化的空间异质性特征(如免疫细胞浸润模式)。但需警惕“算法算命”风险——生存预测本质是概率游戏,模型能否指导临床决策仍需前瞻性试验验证。
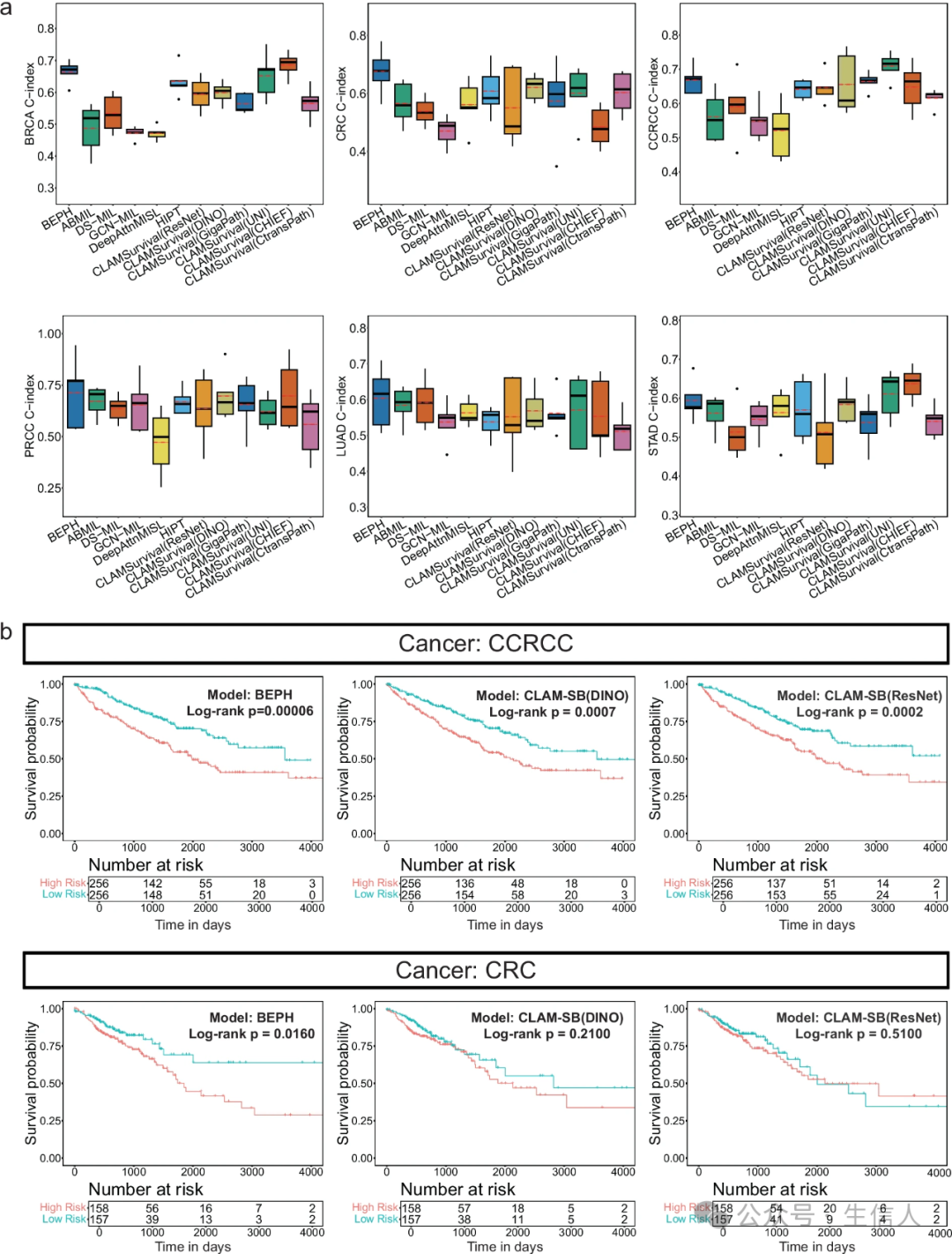
图4 生存预测
可解释性:注意力热图与病理标注“灵魂共鸣”
通过UMAP降维可视化,BEPH提取的特征能清晰区分癌组织与正常组织(图5a)。更绝的是,注意力热图显示模型关注区域与病理医生标注的肿瘤边界高度吻合(图5b),甚至在无监督情况下自动识别出癌旁基质中的可疑区域。这种“人机共识”为临床信任扫清了最大障碍。
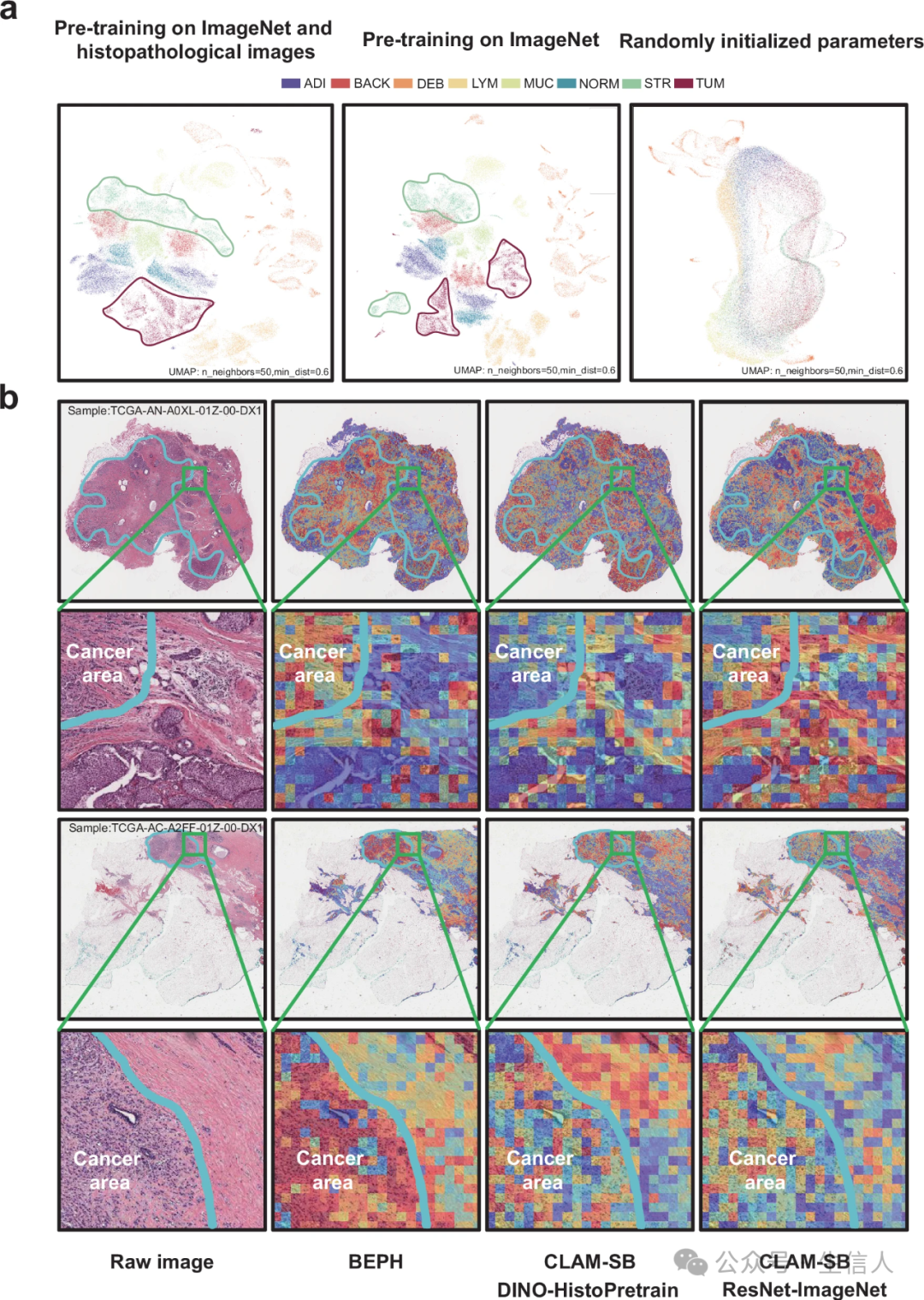
图5 BEPH模型的可解释性和可视化
注意力机制像是一把双刃剑。它虽提升了可解释性,但也可能让模型过度关注局部特征(如核分裂像),忽视全局组织架构信息。未来或需引入图神经网络(GNN)来建模细胞间的空间关系,让AI的“诊断思路”更接近人类病理医生。
消融实验:预训练策略的“灵魂三问”
当移除病理图像预训练(仅用ImageNet初始化),BEPH在乳腺癌生存预测任务中的C-index暴跌4.5%;若将掩码率从40%降至10%,模型性能甚至不如传统监督模型。这说明:病理特异性预训练+适度难度的掩码任务才是BEPH的成功密码。
MIM中的掩码率设定暗含“刻意练习”哲学——太简单(低掩码率)学不到深层特征,太复杂(高掩码率)又可能让模型“摆烂”。40%的掩码率恰似给AI出一道“跳一跳够得着”的考题,既能激发学习潜力,又不至于劝退。
四、讨论与展望:BEPH的“天花板”与未来攀登方向
创新与突破:
BEPH的横空出世,彻底打破了病理AI“一癌一模型”的魔咒。研究团队首次将掩码图像建模(MIM)技术大规模应用于32种癌症、1100万张无标签病理图像,让模型像人类医生学习“拼图”一样——通过重建被遮挡的病理片段,自主捕捉癌细胞的关键形态特征。这种“无师自通”的预训练策略,使得BEPH能同时完成三大任务:单张图像良恶性判断(94.05%准确率)、全切片亚型诊断(肾癌AUC达0.994)、患者生存预测(C-index提升1.1-5.5%)。更惊人的是,它仅需传统模型25%的标注数据即可达到同等性能,甚至当图像分辨率降低70%时仍保持高精度,堪称基层医疗的“省电神器”。
局限与挑战:
尽管BEPH表现亮眼,其预训练数据量(1100万)仅为GigaPath的1/17,在乳腺癌亚型分类任务中AUC落后后者0.7%。更棘手的是,当前验证仅基于TCGA的标准扫描图像,而真实世界中不同医院扫描仪参数差异、染色不均等问题可能引发“焦点漂移”。模拟实验显示,低对比度切片会导致模型注意力热图误判炎症区域,这种“水土不服”可能成为临床落地的“阿喀琉斯之踵”。此外,BEPH采用的ViT-base架构参数规模(1.9亿)仅为GigaPath(ViT-G架构,30亿参数)的6%,如何在有限算力下平衡模型深度与泛化能力,仍是待解难题。
未来图景:
研究团队已着手构建多模态病理宇宙——计划整合基因组突变、蛋白质组数据,打造能关联分子特征的“病理GPT”。例如在肾透明细胞癌中,若将VHL基因突变信息与病理图像特征融合,生存预测精度有望再提升3-5%。但这背后也暗藏隐忧——当AI的决策逻辑愈发像“黑箱”,如何让医生信任其生存预测结果?或许,引入因果推断模型或开发“决策轨迹可视化”工具,将成为破局关键。
结语:
BEPH的诞生像一颗深水炸弹,炸开了病理AI的想象力天花板。过去医生得拿着显微镜大海捞针,现在AI能一键扫出癌细胞的藏身地图;过去生存预测得靠基因组测序+临床指标“叠Buff”,现在一张切片就能“剧透”患者命运。但别急着喊医生失业——这模型现在还只是个初步阶段,要想真正坐进诊室,还得跨过多中心验证、多模态融合这道坎。不过可以预见的是,当病理切片遇上自监督学习,当视觉GPT撞上癌症异质性,一场医学AI的“寒武纪大爆发”正在路上。BEPH让我们看到,自监督学习正在撕掉医疗AI“高冷”的标签,走向普惠与实用。
大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。

1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献902条内容
已为社区贡献902条内容

所有评论(0)