LLM Agents也有属于自己的Test-time!
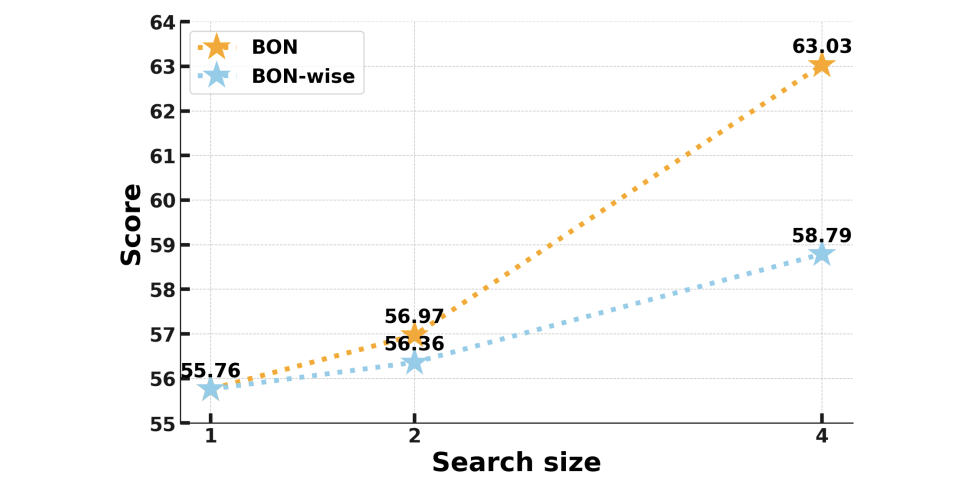
当前语言智能体(比如帮你写PPT的AI)遇到复杂任务时,就像考生被最后一道大题卡住:传统方法只能按固定步骤死磕,错一步全盘皆输。通过让智能体在推理时多路径探索、适时复盘,竟把GPT-4.1的任务得分从55.76拉到74.55!调取天气/算数等Level1任务,BoN把准确率从66%→77.36%,堪称“大力出奇迹”。想象你参加高考时突然获得超能力:可以同时写10份卷子,最后选最高分交卷——这就是论
智能体为什么需要“Test-time Compute”?
想象你参加高考时突然获得超能力:可以同时写10份卷子,最后选最高分交卷——这就是论文研究的测试时计算扩展(TTS)。当前语言智能体(比如帮你写PPT的AI)遇到复杂任务时,就像考生被最后一道大题卡住:传统方法只能按固定步骤死磕,错一步全盘皆输。

论文:Scaling Test-time Compute for LLM Agents
链接:https://arxiv.org/pdf/2506.12928
更扎心的是,现有提升方法类似“考前猛刷题”(增加训练数据),但OPPO团队发现:考试现场给AI“开外挂”更重要。通过让智能体在推理时多路径探索、适时复盘,竟把GPT-4.1的任务得分从55.76拉到74.55!
四大方法
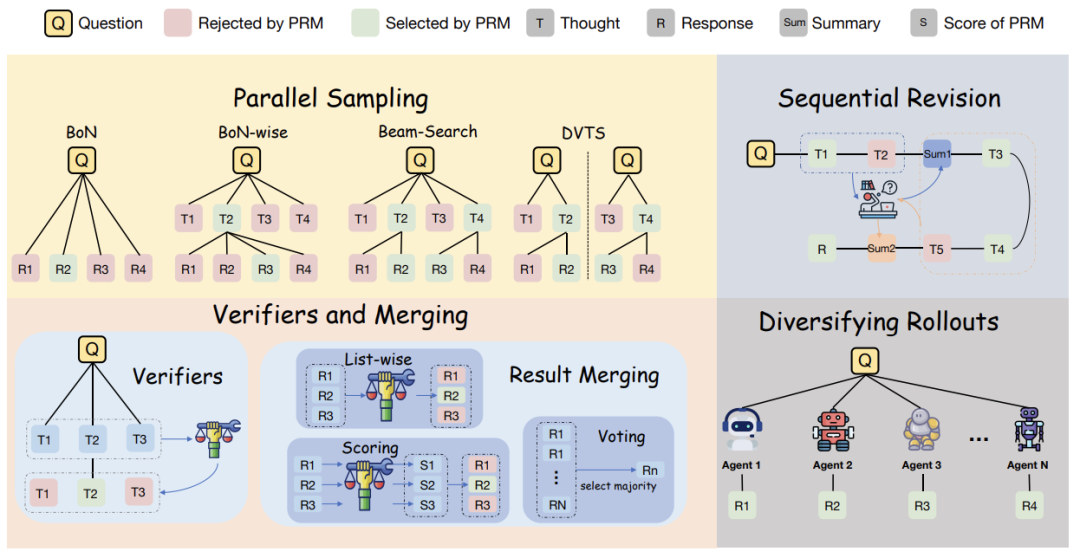
1 并行采样
核心思路很简单:让AI同时生成多个方案,挑最好的用。但具体玩法有玄机:
-
BoN(N选1):针对整个任务生成N个完整方案,类似交10份作文选最佳
{方案1,方案2,...,方案N} = AI(题目) → 选最优 -
BoN-wise(步步为营):每做一步都生成N个选项,像下棋时算十步:
第t步 = AI(题目+前t-1步) → 生成N个选择 → 选最优
2 反射机制
让AI“做完题检查”本是好意,但实验发现频繁复盘会弄巧成拙!
-
每步都反思 → 思维碎片化,得分反降
-
仅当AI“自知不行”时反思(验证模型打分<阈值),效果最佳
3 验证器
当AI生成10个方案,如何选最优?实验对比三大策略:
-
投票制:少数服从多数 → 易被错误方案带偏
-
评分制:专家逐篇打分 → 主观偏差大
-
List-wise(天梯PK):让AI直接对比方案 “A比B好在哪”
4 多样化探索
让GPT-4.1单干?不!拉上Claude/Gemini组队后:
-
各施所长(GPT写代码+Claude查资料)
-
Pass@4得分74.55,碾压单干69.14
实验结果
简单任务:BoN暴力出奇迹
调取天气/算数等Level1任务,BoN把准确率从66%→77.36%,堪称“大力出奇迹”。
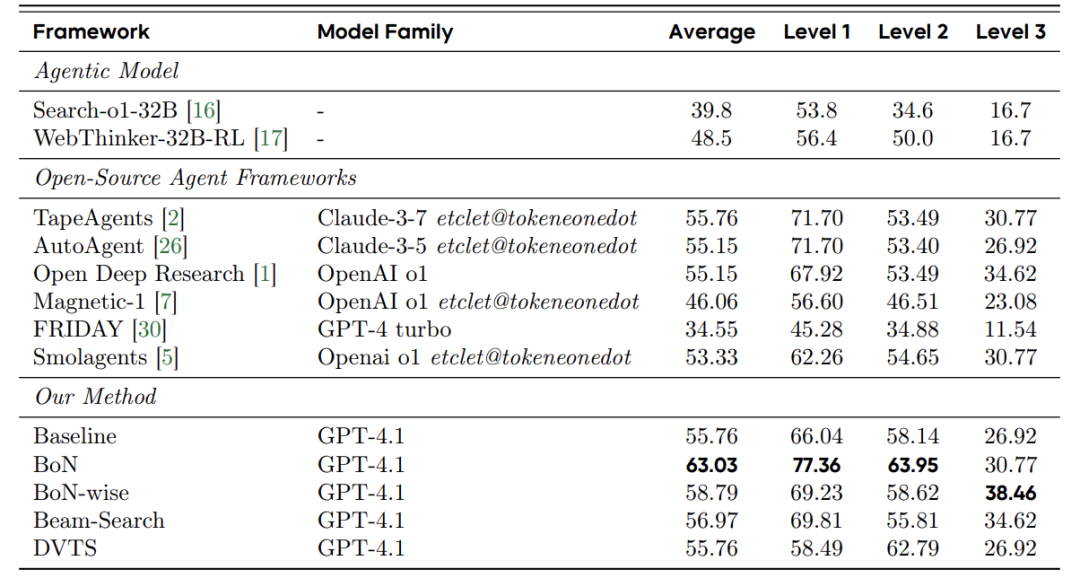
地狱难度:BoN-wise细火慢炖
面对Level3复杂推理(如多步骤数据分析),BoN-wise以38.46%。因为这类任务像造火箭:错一颗螺丝全盘炸,必须步步谨慎。
反射阈值:设错直接崩盘
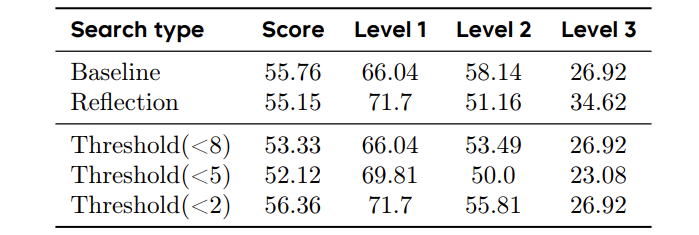
血泪教训:当反射阈值设为<5(中频率反思),成绩比不反思还差!
多模型协作:性价比之王
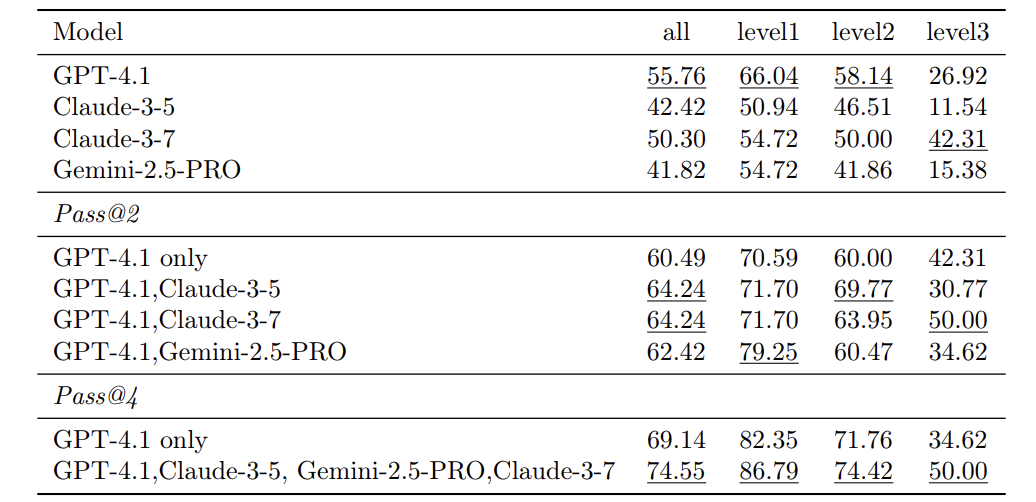
用GPT-4.1+Claude-3.7等四个中等模型协作,成绩超越单用GPT-4.1近20分!
未来智能体进化方向:
论文暗示更高级的“反思触发器”——就像老司机凭感觉知何时换挡,AI也需学会自主判断复盘时机,这或是下一个突破点。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)