[代码生成]DeepSeek-Coder: When the Large Language Model MeetsProgramming - The Rise of Code Intelligenc
全文总结
这篇论文介绍了DeepSeek-Coder系列模型,旨在通过大型语言模型提升代码智能。
研究背景
-
背景介绍:
这篇文章的研究背景是大型语言模型的快速发展极大地推动了软件开发中的代码智能。然而,封闭源代码模型的主导地位限制了广泛的研究和开发。为了解决这一问题,作者提出了DeepSeek-Coder系列,一系列开源的代码模型,旨在提供更广泛的代码智能研究和应用。 -
研究内容:
该问题的研究内容包括:介绍DeepSeek-Coder系列的开源代码模型,这些模型从2万亿个token中从头开始训练,并在多个基准测试中表现出色。此外,文章还探讨了如何通过预训练数据组织、Fill-In-The-Middle(FIM)策略和长上下文处理来增强模型的代码生成和补全能力。 -
文献综述:
该问题的相关工作包括对现有开源和封闭源代码模型的比较分析。作者指出,尽管封闭源代码模型如Codex和GPT-3.5在性能上表现优异,但其封闭性限制了研究和应用的广泛性。相比之下,开源模型在可访问性和灵活性方面具有优势。
研究方法
这篇论文提出了DeepSeek-Coder系列模型。具体来说:
-
模型训练:
模型在2万亿个token上进行从头训练,涵盖87种编程语言。采用Fill-In-The-Middle(FIM)策略和长上下文处理来增强代码生成和补全能力。FIM策略通过随机分割文本并连接特殊字符来进行预训练任务,以提高模型在代码补全任务中的表现。 -
数据收集:
训练数据集由87%的源代码、10%的英语代码相关自然语言语料库和3%的非代码中文自然语言语料库组成。数据收集过程包括数据爬取、规则过滤、依赖解析、仓库级去重和质量筛选。 -
模型架构:
使用基于Transformer的解码器模型,结合Rotary Position Embedding(RoPE)和Grouped-Query-Attention(GQA)。模型参数规模从1.3B到33B不等,以适应不同的计算和应用需求。
实验设计
-
实验设置:
使用多种公共代码相关的基准测试来评估模型的性能,包括HumanEval、MBPP、DS-1000和LeetCode Contest等。实验在HAI-LLM框架下进行,利用NVIDIA A100和H800 GPU进行训练。 -
数据处理:
数据集经过严格的过滤和去重处理,以确保数据质量和多样性。使用编译器和质量模型结合启发式规则进一步过滤低质量数据。
结果与分析
-
代码生成:
DeepSeek-Coder-Base在HumanEval和MBPP基准测试中表现出色,平均准确率分别为50.3%和66.0%。在DS-1000基准测试中,模型在所有库中均表现出较高的准确性。 -
FIM代码补全:
在单行补全基准测试中,DeepSeek-Coder-Base在Python、Java和JavaScript上的表现优于其他模型,显示出其在代码补全任务中的优越性。 -
跨文件代码补全:
在CrossCodeEval基准测试中,DeepSeek-Coder在多语言环境中表现出色,特别是在Python、Java、TypeScript和C#中。 -
数学推理:
在程序辅助数学推理任务中,DeepSeek-Coder-Base 33B在多个基准测试中表现出色,显示出其在复杂数学计算和问题解决方面的潜力。
结论
这篇论文介绍了DeepSeek-Coder系列模型,展示了其在代码生成和补全任务中的优越性能。通过开源和大规模训练,DeepSeek-Coder不仅缩小了与封闭源代码模型的性能差距,还在多个基准测试中表现出色。未来,作者计划继续开发和分享更强大的代码聚焦的大型语言模型,以进一步提升代码智能的应用水平。
这篇论文通过实证研究展示了开源代码模型在代码智能领域的巨大潜力,具有重要的理论和实践意义。
核心速览
研究背景
- 研究问题:这篇文章要解决的问题是如何在大语言模型(LLMs)的基础上提升代码智能。具体来说,现有的闭源模型在性能和可访问性方面存在限制,因此作者提出了开源的DeepSeek-Coder系列模型,旨在解决这一问题。
- 研究难点:该问题的研究难点包括:如何有效地训练大型代码模型以理解多种编程语言,如何在预训练阶段增强模型的代码生成和填充能力,以及如何在不影响代码完成能力的前提下优化模型的性能。
- 相关工作:该问题的研究相关工作包括OpenAI的GPT系列模型、CodeGeeX、StarCoder、CodeLlama等。这些模型在代码生成和理解方面取得了一定的进展,但在性能和可访问性方面仍存在不足。
研究方法
这篇论文提出了DeepSeek-Coder系列模型,用于解决代码智能问题。具体来说,
-
数据收集:训练数据集由87%的源代码、10%的英文代码相关自然语言语料库和3%的中文非代码相关自然语言语料库组成。数据收集过程包括GitHub数据爬取和过滤、依赖解析、仓库级去重和质量筛选。

-
预训练策略:模型采用两种预训练目标:下一个令牌预测和填空-中间(FIM)。FIM方法通过将文本随机分成三部分并打乱顺序来增强模型的代码生成能力。具体来说,FIM方法包括前缀-后缀-中间(PSM)和后缀-前缀-中间(SPM)两种模式。
-
模型架构:开发了不同参数的模型,包括1.3B、6.7B和33B参数。每个模型都是基于解码器的Transformer模型,并采用了旋转位置嵌入(RoPE)和分组查询注意力(GQA)。
-
优化:使用AdamW优化器,学习率调度采用三阶段策略,初始学习率为10%,最终学习率为初始率的10%。
-
长上下文处理:通过调整RoPE参数,将上下文窗口扩展到16K,使模型能够处理更长的代码输入。
-
指令微调:通过使用高质量的指令数据进行微调,增强了DeepSeek-Coder-Base模型在零样本指令任务中的能力。
实验设计
- 数据收集:从GitHub收集2023年2月之前的公共代码库,过滤出87种编程语言。数据集包括源代码、英文代码相关自然语言语料库和中文非代码相关自然语言语料库。
- 预训练:在2万亿令牌的数据上进行预训练,采用下一个令牌预测和FIM两种预训练目标。FIM方法采用PSM和SPM两种模式,并通过消融实验确定最佳配置。
- 微调:使用高质量的指令数据进行微调,采用余弦调度,初始学习率为1e-5,批量大小为4M令牌。
- 评估:在多个代码相关的基准测试上进行评估,包括代码生成、FIM代码完成、跨文件代码完成和基于程序的数学推理。
结果与分析
-
代码生成:在HumanEval和MBPP基准测试中,DeepSeek-Coder-Base 33B模型的平均准确率分别为56.1%和66.0%,显著优于其他开源模型和闭源模型。
-
FIM代码完成:在单行填补基准测试中,DeepSeek-Coder-Base 1.3B模型的平均准确率为70.4%,优于其他模型。
-
跨文件代码完成:在CrossCodeEval基准测试中,DeepSeek-Coder-Base 6.7B模型在Python、Java、TypeScript和C#语言中的平均准确率分别为61.65%、61.77%、60.17%和52.30%,显著优于其他模型。
-
基于程序的数学推理:在PAL基准测试中,DeepSeek-Coder-Base 33B模型在所有七个基准测试中的平均准确率为65.8%,显著优于其他模型。
总体结论
这篇论文介绍了DeepSeek-Coder系列模型,这些模型在多个代码相关的基准测试中表现出色,显著优于现有的开源和闭源模型。通过大规模的训练和优化,DeepSeek-Coder模型不仅在代码生成和理解方面取得了显著进展,还在数学推理和自然语言处理方面展现了强大的能力。未来的工作将继续开发和分享更强大的代码聚焦大型语言模型。
论文评价
优点与创新
- 开源模型系列:引入了DeepSeek-Coder系列,包含从1.3B到33B不同规模的开放源码代码模型,确保了模型的多样性和适用性。
- 高质量预训练数据:模型在2万亿标记的高质量项目级代码语料库上进行预训练,涵盖了87种编程语言,确保了模型对编码语言的全面理解。
- 仓库级别数据构建:首次在预训练阶段引入仓库级别的数据构建,显著提升了跨文件代码生成的能力。
- Fill-in-the-Middle (FIM) 方法:采用了FIM方法来增强模型的代码补全能力,并通过消融实验确定了最佳的FIM配置。
- 长上下文支持:将上下文长度扩展到16K,使模型能够处理更复杂和广泛的编码任务,提高了模型的多功能性和适用性。
- 多语言支持:扩展了HumanEval基准测试的Python问题到七种其他常用编程语言,展示了模型的多语言能力。
- 多种评估基准:在多个代码相关的基准测试中进行了广泛的评估,证明了DeepSeek-Coder在不同任务上的卓越性能。
- 指令微调:通过高质量的指令数据进行微调,DeepSeek-Coder-Instruct在代码相关任务上超越了OpenAI GPT-3.5 Turbo模型。
- 额外预训练:基于DeepSeek-LLM 7B检查点进行了额外的预训练,进一步提高了模型的自然语言理解和数学推理能力。
不足与反思
- 数据污染问题:尽管在评估过程中尽量排除了测试数据的影响,但在未来的研究中仍需考虑数据污染的可能性。
- 长上下文适应方法的改进:虽然模型在16K上下文中表现可靠,但未来研究将继续优化和改进长上下文适应方法,以提高模型在处理更长上下文时的效率和用户体验。
关键问题及回答
问题1:DeepSeek-Coder系列模型在数据收集和处理方面有哪些独特的步骤?
- GitHub数据爬取和过滤:从GitHub收集2023年2月之前的公共代码库,过滤出87种编程语言。过滤规则包括文件平均行长度、最大行长度、字母字符比例等,初步减少数据量至32.8%。
- 依赖解析:解析文件之间的依赖关系,并按依赖顺序排列文件,以确保每个文件的上下文在其之前出现。具体算法包括拓扑排序,识别并处理不连通的子图。
- 仓库级去重:在仓库级别进行去重,确保每个代码样本的唯一性,避免长重复子字符串的影响。
- 质量筛选和污染防护:使用编译器和质量模型结合启发式规则,过滤掉语法错误、可读性差、模块化低的代码。实施n-gram过滤,移除与测试数据匹配的代码段。
这些步骤确保了训练数据的多样性和高质量,为模型的成功训练奠定了基础。
问题2:DeepSeek-Coder模型在预训练阶段采用了哪些特殊的训练目标和方法?
- 下一个令牌预测(Next Token Prediction):将多个文件连接成固定长度的条目,模型根据上下文预测下一个令牌。
- 填空-中间(Fill-in-the-Middle, FIM):通过将文本随机分成三部分(前缀、中间、后缀)并打乱顺序,增强模型的代码生成能力。FIM方法包括前缀-后缀-中间(PSM)和后缀-前缀-中间(SPM)两种模式。通过消融实验,确定最佳配置为50% PSM率。
- 长上下文处理:调整RoPE参数,将上下文窗口扩展到16K,使模型能够处理更长的代码输入。
这些方法使得DeepSeek-Coder模型在代码生成和填充方面表现出色,特别是在处理复杂和长代码任务时。
问题3:DeepSeek-Coder模型在多个代码相关的基准测试中表现如何?其性能如何与其他模型进行比较?
- 代码生成:在HumanEval和MBPP基准测试中,DeepSeek-Coder-Base 33B模型的平均准确率分别为56.1%和66.0%,显著优于其他开源模型和闭源模型,如CodeLlama-Base 34B和GPT-3.5-Turbo。
- FIM代码完成:在单行填补基准测试中,DeepSeek-Coder-Base 1.3B模型的平均准确率为70.4%,优于其他模型,如StarCoder和CodeLlama。
- 跨文件代码完成:在CrossCodeEval基准测试中,DeepSeek-Coder-Base 6.7B模型在Python、Java、TypeScript和C#语言中的平均准确率分别为61.65%、61.77%、60.17%和52.30%,显著优于其他模型,如CodeGeeX和StarCoder。
- 基于程序的数学推理:在PAL基准测试中,DeepSeek-Coder-Base 33B模型在所有七个基准测试中的平均准确率为65.8%,显著优于其他模型,如CodeLlama和GPT-3.5-Turbo。
总体而言,DeepSeek-Coder模型在多个代码相关的基准测试中表现出色,显著优于现有的开源和闭源模型,特别是在处理复杂和长代码任务以及数学推理方面。
DeepSeek-Coder:当大型语言模型遇上编程——代码智能的崛起
郭大亚 ∗1 ,朱启浩 ∗1,2 ,杨德俭 1 ,谢振达 1 ,董凯 1 ,张文涛 1 陈观亭1,毕晓1,吴宇1,李永科1,罗福丽1,熊英飞2,梁文峰1
1 深寻-AI
2北京大学软件与微电子学院关键实验室(教育部重点实验室);北京大学软件与微电子学院
{zhuqh, guodaya}@deepseek.com
https://github.com/deepseek-ai/DeepSeek-Coder
摘要
大型语言模型的快速发展已经彻底改变了软件开发中的代码智能。然而,闭源模型的盛行限制了广泛的研究与开发。为解决这一问题,我们推出了DeepSeek-Coder系列,这是一系列从13亿到330亿参数的开源代码模型,在2万亿个标记上从零开始训练。这些模型在高质量的项目级代码语料库上进行预训练,并采用16K窗口的填空任务来增强代码生成和填充能力。我们的广泛评估表明,DeepSeek-Coder不仅在多个基准测试中实现了开源代码模型的最先进性能,而且还超越了现有的闭源模型如Codex和GPT-3.5。此外,DeepSeek-Coder模型采用宽松的许可证,允许研究和无限制的商业使用。
图1 | DeepSeek-Coder的性能表现
1. 引言
软件开发领域因大型语言模型(OpenAI,2023年;Touvron等人,2023年)的迅猛发展而发生了显著变化,这标志着代码智能新时代的到来。这些模型具有自动化和简化编码多个方面的潜力,从错误检测到代码生成,从而提高生产力并降低人为错误的可能性。然而,该领域面临的一个主要挑战是开源模型(李等人,2023年;Nijkamp等人,2022年;Roziere等人,2023年;Wang等人,2021年)与闭源模型(Gemini团队,2023年;OpenAI,2023年)之间的性能差距。虽然强大的巨型闭源模型对许多人来说往往难以接触,因为其专有性质。
针对这一挑战,我们推出了DeepSeek-Coder系列。该系列包括一系列开源代码模型,规模从13亿到330亿不等,每个规模都包含基础版本和指导版本。该系列的每个模型都是使用来自87种编程语言的2万亿个标记从头开始训练的,确保全面理解编程语言和语法。此外,我们尝试在仓库级别组织预训练数据,以增强预训练模型在仓库内跨文件上下文中的理解能力。除了在预训练期间采用下一个标记预测损失外,我们还融入了中间填充(FIM)方法(Bavarian等人,2023年)。(李等人,2022年;李等人,2023年)。该方法旨在进一步增强模型的代码补全能力。为了满足处理更长代码输入的需求,我们将上下文长度扩展至16K。这一调整使我们的模型能够处理更复杂、更广泛的编码任务,从而提高了它们在各种编码场景中的多功能性和适用性。
我们使用多种公共代码相关基准进行了全面的实验。研究结果显示,在开源模型中,DeepSeek-Coder-Base 33B 在所有基准测试中均表现卓越。此外,DeepSeek-Coder-Instruct 33B 在大多数评估基准测试中超越了OpenAI GPT-3.5 Turbo,显著缩小了OpenAI GPT-4与开源模型之间的性能差距。值得注意的是,尽管参数较少,DeepSeek-Coder-Base 7B 与五倍大的模型(如CodeLlama-33B,由罗齐尔等人于2023年提出)相比,仍展现出具有竞争力的性能。总结来说,我们的主要贡献包括:
● 我们推出了DeepSeek-Coder-Base和DeepSeek-Coder-Instruct,即我们先进的专注于代码的大型语言模型(LLMs)。这些模型通过在广泛的代码语料库上进行大量训练而开发,表现出理解87种编程语言的熟练程度。此外,它们提供多种模型规模,以满足广泛的计算和应用需求。
● 我们在模型预训练阶段首次尝试结合仓库级数据构建。我们发现,它可以显著提升跨文件代码生成能力。
● 我们的分析严格检验了FIM训练策略对代码模型预训练阶段的影响。这些全面研究的结果揭示了FIM配置的有趣方面,提供了宝贵的见解,显著促进了代码预训练模型的增强和发展。
● 我们对我们的代码大型语言模型进行了广泛的评估,针对涵盖众多与代码相关任务的广泛基准测试。研究结果表明,DeepSeek-Coder-Base在这些基准测试中超越了所有现有的开源代码大型语言模型。此外,
通过使用指导数据进行细致的微调,DeepSeek-Coder-Instruct在代码相关任务上的表现优于OpenAI GPT-3.5 Turbo模型。
2. 数据收集
DeepSeek-Coder的训练数据集由87%的源代码、10%的英文代码相关自然语言语料库和3%的非代码相关中文自然语言语料库组成。英文语料库包括GitHub的Markdown和StackExchange的材料,用于提升模型对代码相关概念的理解,并提高其处理库使用和错误修复等任务的能力。同时,中文语料库包含旨在提高模型理解中文水平的高质量文章。在本节中,我们将概述我们构建代码训练数据的方法。该过程包括数据爬取、基于规则的过滤、依存句法分析、仓库级去重以及质量筛选,如图2所示。接下来,我们将逐步描述数据创建过程。
图2 | 数据集创建流程
2.1. GitHub数据抓取与过滤
我们收集了截至2023年2月之前在GitHub上创建的公共仓库,仅保留了表1中列出的87种编程语言。为了减少需要处理的数据量,我们应用了与StarCoder项目(李等人,2023年)中使用的类似的过滤规则,初步过滤掉低质量的代码。通过应用这些过滤规则,我们将总数据量减少到其原始大小的仅32.8%。为了让论文自成一体,我们简要描述了StarCoder数据项目中使用的过滤规则:
首先,我们过滤掉平均行长度超过100个字符或最长行长度超过1000个字符的文件。此外,我们移除了字母字符少于25%的文件。除了XSLT编程语言外,我们进一步过滤掉前100个字符中出现字符串“<?xml version="的文件。对于HTML文件,我们考虑可见文本与HTML代码的比例。我们保留可见文本至少占代码的20%,且不少于100个字符的文件。对于通常包含更多数据的JSON和YAML文件,我们只保留字符数在50到5000个字符之间的文件。这有效地移除了大部分数据量大的文件。
2.2. 依存关系解析
在之前的工作中(陈等人,2021年;李等人,2023年;尼坎普等人,2022年;罗齐耶等人)(2023年),用于代码的大型语言模型主要在文件级别的源代码上进行预训练,这忽略了项目中不同文件之间的依赖关系。然而,在实际应用中,这些模型难以有效地扩展以处理整个项目级别的代码场景。因此,我们
| Algorithm 1 Topological Sort for Dependency Analysis | Algorithm 1 Topological Sort for Dependency Analysis | Algorithm 1 Topological Sort for Dependency Analysis |
|---|---|---|
| 1: procedure TOPOLOGICALSORT(files) | 1: procedure TOPOLOGICALSORT(files) | |
| 2: | graphs ←{} | ▹ Initialize an empty adjacency list |
| 3: | inDegree ←{} | ▹ Initialize an empty dictionary for in-degrees |
| 4: | for each file in files do | |
| 5: | graphs[file]←[] | |
| 6: | inDegree[file] ←0 | |
| 7: | end for | |
| 8: | ||
| 9: | for each fileA in files do | |
| 10: | for each fileB in files do | |
| 11: | if HASDEPENDENCY(fileA, file | leB) then If fileA depends on fileB |
| 12: | graphs[fileB].append(fileA) | ▹ Add edge from B to A |
| 13: | inDegree [ file A]← inDegree [ file A]+1 | inDegree[fileA]+1 ▹ Increment in-degree of A |
| 14: | end if | |
| 15: | end for | |
| 16: | end for | |
| 17: | ||
| 18: | subgraphs ← getDisconnectedSubgraph | Subgraphs ← getDisconnectedSubgraph s (graphs) Identify disconnected subgraphs |
| 19: | allResults←[] | |
| 20: | for each subgraph in subgraphs do | |
| 21: | results←[] | |
| 22: | while length(results) = NumberOfNodes(subgraph) do | Nodes(subgraph) do |
| 23: | file ←argmin({ inDegree [ file ]∣ | file ←argmin({ inDegree [ file ]∣ file ∈ subgraph and file ∈/ results }) |
| 24: | for each node in graphs[file] do | |
| 25: | inDegree[node] ← inDegree[no | de]-1 |
| 26: | end for | |
| 27: | results.append(file) | |
| 28: | end while | |
| 29: | allResults.append(results) | |
| 30: | end for | |
| 31: | ||
| 32: | return allResults | |
| 33: er | d procedure |
在这一步中,我们将考虑如何利用同一仓库内文件之间的依赖关系。具体来说,我们首先解析文件间的依赖关系,然后按照一种顺序安排这些文件,确保每个文件所依赖的上下文都放在输入序列中该文件之前。通过根据依赖关系对齐文件,我们的数据集更准确地反映了实际的编码实践和结构。这种增强的对齐不仅使我们的数据集更具相关性,而且可能提高模型在处理项目级代码场景中的实用性和适用性。值得注意的是,我们只考虑文件之间的调用关系,并使用正则表达式来提取它们,例如Python中的“import”,C#中的“using”,以及C语言中的“include”。
算法1描述了对同一项目中文件列表进行依赖性分析的拓扑排序。最初,它设置了两个数据结构:一个名为“图形”的空邻接表来表示文件之间的依赖关系,以及一个名为“入度”的空字典用于存储每个文件的入度。然后,算法遍历每对文件以识别依赖关系,并相应地更新“图形”和“入度”。接下来,它识别整个依赖图中任何不连通的子图。对于每个子图,算法采用一种修改过的拓扑排序。与选择入度为零的节点的标准方法不同,此算法选择入度最小的节点,这使其能够处理图内的循环。选定的节点被添加到“结果”列表中,它们连接的节点的入度减少。这个过程持续进行,直到为每个子图生成一个拓扑排序序列。算法最后返回这些排序序列的列表,并将每个序列的文件连接起来形成一个单独的训练样本。为了包含文件路径信息,在每个文件的开始处添加一条注释,指明文件的路径。这种方法确保训练数据中保留了路径信息。
2.3. 仓库级别去重
最近的研究表明,通过对大型语言模型(LLMs)的训练数据集进行去重,可以实现显著的性能提升。李等人(2022年)的研究显示,语言模型训练语料库通常包含许多近似重复的内容,通过移除长的重复子串可以提高LLMs的性能。科切特科夫等人(2022年)对训练数据应用了近似去重方法,结果大幅提升,他们强调近似去重是达到代码基准任务竞争性能的关键预处理步骤。在我们的数据集中,我们也采用了近似去重。然而,我们的方法与以往的工作有所不同。我们在代码的仓库级别而非文件级别执行去重,因为后一种方法可能会过滤掉仓库内的某些文件,有可能破坏仓库的结构。具体来说,我们将来自代码库级别的连接代码视为单个样本,并应用相同的近似去重算法以确保代码库结构的完整性。
2.4. 质量筛选和净化
除了应用第2.1节中提到的过滤规则外,我们还结合启发式规则使用编译器和质量模型来进一步过滤掉低质量数据。这包括语法错误、可读性差和模块化程度低的代码。我们在表1中提供了源代码的统计摘要,其中包含共87种语言,详细列出了每种语言的磁盘大小、文件数量和百分比。总数据量为798吉字节,包含6.03亿个文件。为确保我们的代码训练数据不受可能存在于GitHub上的测试集信息污染,我们实施了n-gram过滤流程。该流程涉及移除符合特定标准的任何代码段。具体来说,我们过滤掉包含文档字符串、问题和解决方案的文件,这些文件来自HumanEval(陈等人,2021年)、MBPP(奥斯汀等人,2021年)、GSM8K(科贝等人,2021年)以及MATH(亨德里克斯等人,2021年)等来源。对于过滤标准,我们应用以下规则:如果一段代码包含与测试数据中任何字符串相同的10-gram字符串,则将其排除在我们的训练数据之外。在测试数据包含长度小于10-gram但不少于3-gram的字符串的情况下,我们采用精确匹配方法进行过滤。
| Language | Size(GB) | Files(k) | Prop.(%) | Language | Size(GB) | Files(k) | Prop.(%) |
|---|---|---|---|---|---|---|---|
| Ada | 0.91 | 126 | 0.11 | Literate Haskell | 0.16 | 20 | 0.02 |
| Agda | 0.26 | 59 | 0.03 | Lua | 0.82 | 138 | 0.10 |
| Alloy | 0.07 | 24 | 0.01 | Makefile | 0.92 | 460 | 0.12 |
| ANTLR | 0.19 | 38 | 0.02 | Maple | 0.03 | 6 | 0.00 |
| AppleScript | 0.03 | 17 | 0.00 | Mathematica | 0.82 | 10 | 0.10 |
| Assembly | 0.91 | 794 | 0.11 | MATLAB | 0.01 | 1 | 0.00 |
| Augeas | 0.00 | 1 | 0.00 | OCaml | 0.91 | 139 | 0.11 |
| AWK | 0.09 | 53 | 0.01 | Pascal | 0.79 | 470 | 0.10 |
| Batchfile | 0.92 | 859 | 0.12 | Perl | 0.81 | 148 | 0.10 |
| Bluespec | 0.10 | 15 | 0.01 | PHP | 58.92 | 40,627 | 7.38 |
| C | 28.64 | 27,111 | 3.59 | PowerShell | 0.91 | 236 | 0.11 |
| C# | 58.56 | 53,739 | 7.34 | Prolog | 0.03 | 5 | 0.00 |
| Clojure | 0.90 | 295 | 0.11 | Protocol Buffer | 0.92 | 391 | 0.12 |
| CMake | 0.90 | 359 | 0.11 | Python | 120.68 | 75,188 | 15.12 |
| CoffeeScript | 0.92 | 361 | 0.12 | R | 0.92 | 158 | 0.11 |
| Common Lisp | 0.92 | 105 | 0.11 | Racket | 0.09 | 13 | 0.01 |
| C++ | 90.87 | 36,006 | 11.39 | RMarkdown | 6.83 | 1,606 | 0.86 |
| CSS | 5.63 | 11,638 | 0.71 | Ruby | 15.01 | 18,526 | 1.88 |
| CUDA | 0.91 | 115 | 0.11 | Rust | 0.61 | 692 | 0.08 |
| Dart | 0.89 | 264 | 0.11 | SAS | 0.92 | 70 | 0.11 |
| Dockerfile | 0.04 | 48 | 0.00 | Scala | 0.81 | 971 | 0.10 |
| Elixir | 0.91 | 549 | 0.11 | Scheme | 0.92 | 216 | 0.12 |
| Elm | 0.92 | 232 | 0.12 | Shell | 13.92 | 10,890 | 1.74 |
| Emacs Lisp | 0.91 | 148 | 0.11 | Smalltalk | 0.92 | 880 | 0.12 |
| Erlang | 0.92 | 145 | 0.12 | Solidity | 0.85 | 83 | 0.11 |
| F# | 0.91 | 340 | 0.11 | Sparql | 0.10 | 88 | 0.01 |
| Fortran | 1.67 | 654 | 0.21 | SQL | 15.14 | 7,009 | 1.90 |
| GLSL | 0.92 | 296 | 0.11 | Stan | 0.20 | 41 | 0.03 |
| Go | 2.58 | 1,365 | 0.32 | Standard ML | 0.74 | 117 | 0.09 |
| Groovy | 0.89 | 340 | 0.11 | Stata | 0.91 | 122 | 0.11 |
| Haskell | 0.87 | 213 | 0.11 | SystemVerilog | 0.91 | 165 | 0.11 |
| HTML | 30.05 | 14,998 | 3.77 | TCL | 0.90 | 110 | 0.11 |
| Idris | 0.11 | 32 | 0.01 | Tcsh | 0.17 | 53 | 0.02 |
| Isabelle | 0.74 | 39 | 0.09 | Tex | 20.46 | 2,867 | 2.56 |
| Java | 148.66 | 134,367 | 18.63 | Thrift | 0.05 | 21 | 0.01 |
| Java Server Pages | 0.86 | 1072 | 0.11 | TypeScript | 60.62 | 62,432 | 7.60 |
| JavaScript | 53.84 | 71,895 | 6.75 | Verilog | 0.01 | 1 | 0.00 |
| JSON | 4.61 | 11956 | 0.58 | VHDL | 0.85 | 392 | 0.11 |
| Julia | 0.92 | 202 | 0.12 | Visual Basic | 0.75 | 73 | 0.09 |
| Jupyter Notebook | 14.38 | 2,555 | 1.80 | XSLT | 0.36 | 48 | 0.04 |
| Kotlin | 6.00 | 3,121 | 0.75 | Yacc | 0.72 | 67 | 0.09 |
| Lean | 0.52 | 68 | 0.07 | YAML | 0.74 | 890 | 0.09 |
| Literate Agda | 0.05 | 4 | 0.01 | Zig | 0.81 | 70 | 0.10 |
| Literate CoffeeScript | 0.01 | 3 | 0.00 | Total | 797.92 | 603,173 | 100.00 |
表1 | 选定编程语言的清洗训练数据摘要。
3. 训练政策
3.1. 训练策略
3.1.1. 下一个词元预测
我们模型的第一个训练目标是所谓的下一个词元预测。在此过程中,各种文件被连接起来形成一个固定长度的条目。然后,这些条目用来训练模型,使其能够基于提供的上下文预测后续的词元。
3.1.2. 填空式预训练
我们模型的第二个训练目标是所谓的填空式预训练。在代码预训练场景中,通常需要根据给定的上下文和后续文本生成相应的插入内容。由于编程语言中的特定依赖性,仅依靠下一个词元预测不足以学习这种填空式能力。因此,几种方法(Bavarian等人,2022年;李等人,2023年)提出了填空式预训练(FIM)的预训练方法。该方法涉及将文本随机分为三个部分,然后打乱这些部分的顺序并用特殊字符连接它们。这种方法旨在在训练过程中加入填空式预训练任务。在FIM方法中,采用了两种不同的模式:PSM(前缀-后缀-中间)和SPM(后缀-前缀-中间)。在PSM模式下,训练语料库按照前缀、后缀、中间的序列组织,使文本以中间段被前后缀夹在中间的方式对齐。相反,SPM模式将片段排列为后缀、前缀和中段,呈现出不同的结构挑战。这些模式在增强模型处理代码中各种结构排列的能力方面起着重要作用,为高级代码预测任务提供了一个稳健的训练框架。
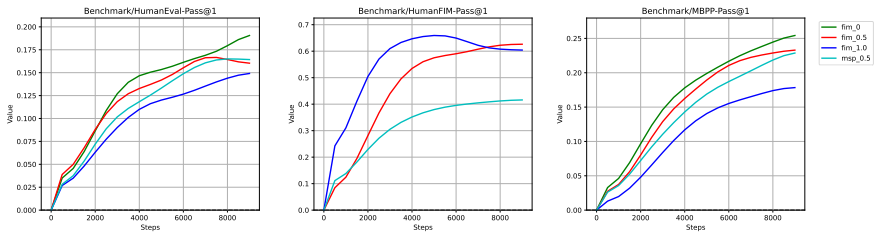
图3 | 使用FIM目标的成效。
为了确定FIM方法内不同超参数的有效性,我们进行了一系列消融实验。
实验设置:在这个实验中,我们采用DeepSeek-Coder-Base 1.3B作为我们的模型架构。我们专注于训练数据集中的一个Python子集以简化实验过程。我们的主要目标是评估中间填充(FIM)技术的有效性,使用HumanEval-FIM基准(Fried等人,2022年)。该基准专门针对Python的单行FIM任务,其中从HumanEval解决方案中随机遮挡一行代码,测试模型预测缺失行的熟练程度。我们假设PSM模式可能与传统的下一个词元预测目标表现出细微差异。这主要是因为PSM涉及重新排列原文本的顺序,可能会影响模型的学习动态。因此,我们在FIM中实现了PSM模式,涵盖四种不同的配置:0% FIM率、50% FIM率、100% FIM率和50% MSP率。掩码跨度预测(MSP)策略最初在T5(Raffel等人,2023年)中提出,隐藏多个文本片段并训练模型重构这些段落。根据CodeGen2.5(Nijkamp等人,2023年),与PSM相比,MSP可能会提升FIM性能。因此,我们在比较分析中包含了这种方法。
结果:我们的实验结果如图3所示。虽然该模型在HumanEval-FIM上展示了100%的FIM率(完全理解率)的峰值性能,但这种配置也导致了最弱的代码完成能力。这表明FIM和代码完成能力之间存在权衡。此外,我们观察到,当PSM(概率性语义标记)率为50%时,模型的表现超过了MSP(多句子预测)策略。为了在FIM效率和代码完成熟练度之间取得平衡,我们最终选择了50%的PSM率作为我们首选的训练策略。
在我们的实现中,我们特别为此任务引入了三个哨兵标记。对于每个代码文件,我们最初将其内容分为三个部分,分别表示为fpre(前文)、fmiddle(中间)和fsuf(后文)。使用PSM模式,我们按如下方式构建训练示例:
<|\text{ fim_start}|>f_{\text{pre}}<|\text{ fim_hole}|>f_{\text{suf}}<|\text{ fim_end}|>f_{\text{middle}}<|\text{ eos}\text{ token}|>
我们按照巴伐利亚等人(2022年)的原始工作建议,在打包流程之前,在文档级别实施了中间填充(FIM)方法。这是以0.5的FIM比率进行的,遵循PSM模式。
3.2. 分词器
对于分词过程,我们使用HuggingFace分词器库 2 来训练字节对编码(BPE)分词器,如Sennrich等人(2015年)(Sennrich等人,2015年)所述,在我们的训练语料库的一个子集上进行。最终,我们使用一个配置了32,000个词汇量的分词器。
3.3. 模型架构
我们开发了一系列具有不同参数的模型,以满足多样化的应用需求,包括参数为13亿、67亿和330亿的模型。这些模型基于与DeepSeek大型语言模型(LLM)相同的框架构建,由DeepSeek-AI(2024年)概述。每个模型都是仅解码器的Transformer,并采用了Su等人(2023年)描述的旋转位置嵌入(RoPE)。值得注意的是,DeepSeek 33B模型整合了分组查询注意力(GQA),其组大小为8,提高了训练和推理效率。此外,我们采用FlashAttention v2(Dao,2023年)来加速涉及注意力机制的计算。我们模型的架构细节在表2中进行了总结。
3.4. 优化
根据DeepSeek LLM(DeepSeek-AI,2024年),我们使用AdamW(Loshchilov和Hutter,2019年)作为优化器,其中 β1 和 β2 的值分别为0.9和0.95。我们通过DeepSeek LLM建议的比例定律调整批量大小和学习率。对于学习率调度,我们实施了一个三阶段策略,包括2000个热身步骤,并将最终学习率设置为初始速率的10%。值得注意的是,每个阶段的学习率都缩小到前一个阶段速率的101。这遵循了DeepSeek LLM(DeepSeek-AI,2024年)制定的指导方针。
3.5. 环境
我们的实验是使用HAI-LLM(高飞者,2023年)框架进行的,该框架以其在训练大型语言模型方面的效率和轻量级方法而闻名。此框架采用了多种并行策略来优化计算效率。这些包括张量并行性(Korthikanti等人,2023年),以及零冗余数据并行性(Rajbhandari等人,2020年)和PipeDream流水线并行性(Narayanan等人,2019年)。我们的实验
| Hyperparameter | DeepSeek-Coder 1.3B | DeepSeek-Coder 6.7B | DeepSeek-Coder 33B |
|---|---|---|---|
| Hidden Activation | SwiGLU | SwiGLU | SwiGLU |
| Hidden size | 2048 | 4096 | 7168 |
| Intermediate size | 5504 | 11008 | 19200 |
| Hidden layers number | 24 | 32 | 62 |
| Attention heads number | 16 | 32 | 56 |
| Attention | Multi-head | Multi-head | Grouped-query(8) |
| Batch Size | 1024 | 2304 | 3840 |
| Max Learning Rate | 5.3e-4 | 4.2e-4 | 3.5e-4 |
表2 | DeepSeek-Coder的超参数。
利用配备NVIDIA A100和H800 GPU的集群。在A100集群中,每个节点配置有8个GPU,使用NVLink桥接成对互联。H800集群的配置类似,每个节点包含8个GPU。这些GPU通过结合NVLink和NVSwitch技术相互连接,确保节点内高效的数据传输。为了促进A100和H800集群中节点间的无缝通信,我们采用了InfiniBand互连,以其高吞吐量和低延迟而闻名。此设置为我们计算实验提供了强大且高效的基础设施。
3.6. 长上下文
为了提升DeepSeek-Coder处理扩展上下文的能力,特别是针对仓库级别代码处理的场景,我们重新配置了RoPE(Su等人,2023年)参数以扩展默认的上下文窗口。遵循先前的做法(Chen等人,2023年;kaiokendev,2023年),我们采用了线性缩放策略,将缩放因子从1增加到4,并将基础频率从10000调整为100000。模型额外进行了1000步的训练,使用批量大小为512,序列长度为16K。学习率保持如同最终预训练阶段。理论上,这些修改使得我们的模型能够在上下文中处理多达64K个令牌。然而,实证观察表明,模型在16K令牌范围内提供其最可靠的输出。未来的研究将继续完善和评估长上下文适应方法,旨在进一步提高DeepSeek-Coder在处理扩展上下文时的效率和用户友好性。
3.7. 指令调整
我们通过使用高质量数据进行基于指令的微调来开发DeepSeek-Coder-指令,以增强DeepSeek-Coder-基础版。这些数据包括有用且公正的人类指令,按照Alpaca指令格式(Taori等人,2023年)进行结构化。为了划分每个对话轮次,我们采用了独特的分隔标记<|EOT|></|EOT|>来表示每个部分的结束。在训练中,我们采用余弦调度,包含100步热身和初始学习率为1e-5。我们还使用了400万令牌批处理和总共20亿令牌。
图4展示了使用DeepSeek-Coder-指令34B的一个例子。该例子是一个用于构建贪吃蛇游戏的多轮对话场景。最初,我们要求模型使用pygame编写一个游戏贪吃蛇。该模型成功创建了一个基本的不含bug的贪吃蛇游戏。为了改进游戏,我们进一步要求在左上角添加一个计分系统。然后,模型引入了一个“分数”变量和一个“显示分数”函数,并解释了如何整合这些特性。这个例子说明了DeepSeek-Coder-指令在多轮对话环境中提供完整解决方案的能力。更多案例可以在附录A中找到。

图4 | 在多轮对话设置中,DeepSeek-Coder-Instruct 33B的响应示例。
4. 实验结果
在本节中,我们评估了DeepSeek-Coder在四个任务上的表现,包括代码生成(§4.1)、FIM代码补全(§4.2)、跨文件代码补全(§4.3)以及基于程序的数学推理(§4.4)。我们将DeepSeek-Coder与之前的最先进的大型语言模型进行比较:
● CodeGeeX2(郑等人,2023年)代表了多语言代码生成模型CodeGeeX的二代产品。它采用ChatGLM2(杜等人,2022年)架构开发,并通过广泛的编程示例数据集得到增强。
● StarCoder(李等人,2023年)是一个公开可访问的模型,拥有150亿参数。它专门针对Stack数据集的精心策划子集进行训练(科切特科夫等人,2022年),涵盖86种编程语言,确保其在广泛的编码任务中的熟练度。
CodeLlama(罗齐耶等人,2023年)包含一系列以代码为中心的大型语言模型(LLMs),它们是LLaMA2(图沃伦等人,2023年)的后代。提供三种大小——7B、13B和34B——这些模型在庞大的5000亿令牌代码语料库上持续训练,建立在基础LLaMA2架构之上。
code-cushman-001 陈等人(2021年)是由OpenAI开发的拥有120亿参数的模型,作为GitHub Copilot的初始模型。
● GPT-3.5和GPT-4(OpenAI,2023年)是由OpenAI开发的先进生成式AI模型。虽然它们并非专门用于代码生成训练,但它们也展现出
在这一领域表现突出。它们在处理代码生成任务方面的有效性主要归因于其参数数量的大规模。
4.1. 代码生成
HumanEval 和 MBPP 基准测试 HumanEval(陈等人,2021年)和 MBPP(奥斯汀等人,2021年)是广泛用于评估代码大型语言模型(LLM)的基准测试。HumanEval 包括164个手工编写的Python问题,通过测试用例进行验证,以评估在零样本设置下由代码LLM生成的代码,而MBPP基准测试包括500个问题,采用少样本设置。为了评估模型的多语言能力,我们将 HumanEval 基准测试的Python问题扩展为七种其他常用的编程语言,即C++、Java、PHP、TypeScript(TS)、C#、Bash和JavaScript(JS)(卡萨诺等人,2023年)。对于这两个基准测试,我们采用了贪婪搜索方法,并使用相同的脚本和环境重新实现了基线结果,以便公平比较。
| Model | Size | Python | | C++ | Java | PHP | TS | C# | Bash | JS | Avg | MBPP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models |
| code-cushman-001 | 12B | 33.5% | 31.9% | 30.6% | 28.9% | 31.3% | 22.1% | 11.7% | |||
| CodeGeeX2 | 6B | 36.0% | 29.2% | 25.9% | 23.6% | 20.8% | 29.7% | 6.3% | 24.8% | 24.5% | 36.2% |
| StarCoderBase | 16B | 31.7% | 31.1% | 28.5% | 25.4% | 34.0% | 34.8% | 8.9% | 29.8% | 28.0% | 42.8% |
| CodeLlama | 7B | 31.7% | 29.8% | 34.2% | 23.6% | 36.5% | 36.7% | 12.0% | 29.2% | 29.2% | 38.6% |
| CodeLlama | 13B | 36.0% | 37.9% | 38.0% | 34.2% | 45.2% | 43.0% | 16.5% | 32.3% | 35.4% | 48.4% |
| CodeLlama | 34B | 48.2% | 44.7% | 44.9% | 41.0% | 42.1% | 48.7% | 15.8% | 42.2% | 41.0% | 55.2% |
| DeepSeek-Coder-Base | 1.3B | 34.8% | 31.1% | 32.3% | 24.2% | 28.9% | 36.7% | 10.1% | 28.6% | 28.3% | 46.2% |
| DeepSeek-Coder-Base | 6.7B | 49.4% | 50.3% | 43.0% | 38.5% | 49.7% | 50.0% | 28.5% | 48.4% | 44.7% | 60.6% |
| DeepSeek-Coder-Base | 33B | 56.1% | 58.4% | 51.9% | 44.1% | 52.8% | 51.3% | 32.3% | 55.3% | 50.3% | 66.0% |
| Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models |
| GPT-3.5-Turbo | 76.2% | 63.4% | 69.2% | 60.9% | 69.1% | 70.8% | 42.4% | 67.1% | 64.9% | 70.8% | |
| GPT-4 | 84.1% | 76.4% | 81.6% | 77.2% | 77.4% | 79.1% | 58.2% | 78.0% | 76.5% | 80.0% | |
| DeepSeek-Coder-Instruct | 1.3B | 65.2% | 45.3% | 51.9% | 45.3% | 59.7% | 55.1% | 12.7% | 52.2% | 48.4% | 49.4% |
| DeepSeek-Coder-Instruct | 6.7B | 78.6% | 63.4% | 68.4% | 68.9% | 67.2% | 72.8% | 36.7% | 72.7% | 66.1% | 65.4% |
| DeepSeek-Coder-Instruct | 33B | 79.3% | 68.9% | 73.4% | 72.7% | 67.9% | 74.1% | 43.0% | 73.9% | 69.2% | 70.0% |
表3 | 在多语言人类评估和MBPP基准测试中方法的表现。
结果在表3中呈现。正如我们所看到的,DeepSeek-Coder-Base在人类评估上的平均准确率为50.3%,在MBPP上的准确率为66.0%,达到了最先进的表现。与同等大小的开放源代码模型CodeLlama-Base 34B相比,我们的模型在准确率上分别显著提高了9%和11%。值得注意的是,即使我们较小的模型DeepSeek-Coder-Base 6.7B,也超越了CodeLlama-Base 34B的表现。经过指令微调后,我们的模型在人类评估基准测试中超越了闭源的GPT-3.5-Turbo模型,显著缩小了OpenAI GPT-4与开放源代码模型之间的性能差距。
DS-1000基准测试在人类评估和MBPP上的一个重大缺陷是,它们严重依赖于可能无法准确代表大多数程序员通常编写的代码类型的直接编程任务。相比之下,赖等人(2023年)的工作中介绍的DS-1000基准测试提供了涵盖七个不同库的1000个实用且现实的数据科学工作流程的综合集合。该基准测试通过对特定测试用例执行代码来评估代码生成。DS-1000的特点在于其基于所涉及库的问题分类,包括Matplotlib、NumPy、Pandas、SciPy、Scikit-Learn、PyTorch和TensorFlow。该基准测试评估基础模型在代码补全环境中的表现,我们为每个库提供了前1个结果,以及总体得分。
DS-1000基准测试的结果显示在表4中。从表中可以看出,DeepSeek-Coder模型在所有库中都取得了相对较高的准确率,这表明我们的模型不仅能够生成高质量的代码,而且能够在实际的数据科学工作流程中更准确地使用库。
| Model | Size | Matplotlib | Numpy | Pandas | Pytorch | Scipy | Scikit-Learn | Tensorflow | Avg |
|---|---|---|---|---|---|---|---|---|---|
| CodeGeeX2 | 6B | 38.7% | 26.8% | 14.4% | 11.8% | 19.8% | 27.0% | 17.8% | 22.9% |
| StarCoder-Base | 16B | 43.2% | 29.1% | 11.0% | 20.6% | 23.6% | 32.2% | 15.6% | 24.6% |
| CodeLlama-Base | 7B | 41.9% | 24.6% | 14.8% | 16.2% | 18.9% | 17.4% | 17.8% | 22.1% |
| CodeLlama-Base | 13B | 46.5% | 28.6% | 18.2% | 19.1% | 18.9% | 27.8% | 33.3% | 26.8% |
| CodeLlama-Base | 34B | 50.3% | 42.7% | 23.0% | 25.0% | 28.3% | 33.9% | 40.0% | 34.3% |
| DeepSeek-Coder-Base | 1.3B | 32.3% | 21.4% | 9.3% | 8.8% | 8.5% | 16.5% | 8.9% | 16.2% |
| DeepSeek-Coder-Base | 6.7B | 48.4% | 35.5% | 20.6% | 19.1% | 22.6% | 38.3% | 24.4% | 30.5% |
| DeepSeek-Coder-Base | 33B | 56.1% | 49.6% | 25.8% | 36.8% | 36.8% | 40.0% | 46.7% | 40.2% |
表4 | 不同方法在DS-1000任务上的表现。
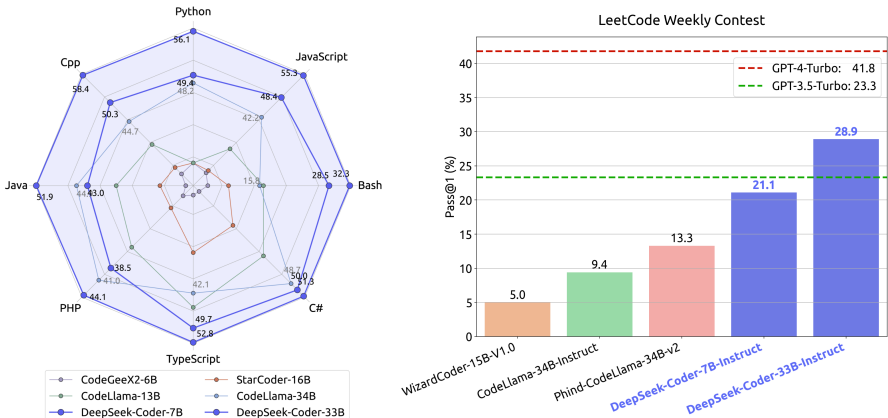
为了进一步验证模型在现实世界编程问题中的能力,我们构建了LeetCode竞赛基准测试3。LeetCode4提供了竞赛级别的问题,提出了重大挑战,以测试模型的问题理解和代码生成技能。我们从LeetCode竞赛中收集了最新问题,以防止这些问题或其解决方案出现在我们的预训练数据中。从2023年7月到2024年1月共收集了180个问题。对于每个问题,我们收集了100个测试用例以确保测试覆盖率。我们使用模板“{问题描述}\n请完成下面的代码以解决上述问题:\n```python\n{{代码模板}}\n`来构建指令提示。
评估结果显示在表5中。在我们的评估中,DeepSeek-Coder模型在当前的顶级开源编码模型上展现了显著的性能。具体来说,DeepSeek-Coder-Instruct 6.7B和33B在这个基准测试中的Pass@1得分分别为19.4%和27.8%。这一表现明显超越了现有的开源模型,如Code-Llama-33B。DeepSeek-Coder-Instruct 33B是唯一在这个任务上胜过OpenAI的GPT-3.5-Turbo的开源模型。然而,与更先进的GPT-4-Turbo相比仍有较大的性能差距。
我们的分析表明,实施思维链(CoT)提示显著增强了DeepSeek-Coder-Instruct模型的能力。这种改进在更具挑战性的任务子集中尤为明显。通过在初始提示后加入指令“你需要先写一个逐步大纲,然后再写代码”,我们观察到性能有所提升。这一观察使我们相信,首先制定详细的代码描述的过程有助于模型更有效地理解和处理编程任务中的逻辑和依赖关系的复杂性,尤其是那些较高复杂度的任务。因此,我们强烈建议在利用DeepSeek-Coder-Instruct模型解决复杂编程挑战时采用CoT提示策略。这种方法促进了一种更有条理和逻辑的解决问题框架,可能在代码生成任务中产生更精确和高效的结果。
| Model | Size | Easy(45) | Medium(91) | Hard(44) | Overall(180) |
|---|---|---|---|---|---|
| WizardCoder-V1.0 | 15B | 17.8% | 1.1% | 0.0% | 5.0% |
| CodeLlama-Instruct | 34B | 24.4% | 4.4% | 4.5% | 9.4% |
| Phind-CodeLlama-V2 | 34B | 26.7% | 8.8% | 9.1% | 13.3% |
| GPT-3.5-Turbo | 46.7% | 15.4% | 15.9% | 23.3% | |
| GPT-3.5-Turbo+CoT | - | 42.2% | 15.4% | 20.5% | 23.3% |
| GPT-4-Turbo | - | 73.3% | 31.9% | 25.0% | 40.6% |
| GPT-4-Turbo+CoT | - | 71.1% | 35.2% | 25.0% | 41.8% |
| DeepSeek-Coder-Instruct | 1.3B | 22.2% | 1.1% | 4.5% | 7.2% |
| DeepSeek-Coder-Instruct+CoT | 1.3B | 22.2% | 2.2% | 2.3% | 7.2% |
| DeepSeek-Coder-Instruct | 6.7B | 44.4% | 12.1% | 9.1% | 19.4% |
| DeepSeek-Coder-Instruct+CoT | 6.7B | 44.4% | 17.6% | 4.5% | 21.1% |
| DeepSeek-Coder-Instruct | 33B | 57.8% | 22.0% | 9.1% | 27.8% |
| DeepSeek-Coder-Instruct+CoT | 33B | 53.3% | 25.3% | 11.4% | 28.9% |
表5 | 不同模型在LeetCode竞赛基准测试中的表现。
重要的是要认识到,尽管我们努力收集最新的编程题目以进行模型测试,但仍无法完全排除数据污染的可能性。我们观察到,GPT-4-Turbo和DeepSeek-Coder模型在7月和8月举办的LeetCode竞赛中取得了更高的分数。我们鼓励研究界在未来的研究中评估使用我们发布的LeetCode数据时考虑数据污染的潜在问题。
4.2. 中间填写代码补全
DeepSeek-Coder模型在预训练阶段采用0.5的FIM(中间填写)率进行训练。这种专门的训练策略使模型能够通过根据给定代码片段的前缀和后缀上下文填写空白来熟练生成代码。这一能力在代码补全工具领域尤为突出。已经出现了几个具有类似能力的开源模型。其中值得注意的有SantaCoder(Allal等人,2023年)、StarCoder(李等人,2023年)和CodeLlama(Roziere等人,2023年)。这些模型在代码生成和补全领域树立了先例。在评估DeepSeek-Coder模型的性能时,我们与上述模型进行了比较分析。此次比较的基准是单线填充基准,涵盖了Allal等人(2023年)提出的三种不同编程语言。该基准测试使用行精确匹配准确率作为评估指标。
| Model | Size | python | java | javascript | Mean |
|---|---|---|---|---|---|
| SantaCoder | 1.1B | 44.0% | 62.0% | 74.0% | 69.0% |
| StarCoder | 16B | 62.0% | 73.0% | 74.0% | 69.7% |
| CodeLlama-Base | 7B | 67.6% | 74.3% | 80.2% | 69.7% |
| CodeLlama-Base | 13B | 68.3% | 77.6% | 80.7% | 75.5% |
| DeepSeek-Coder-Base | 1B | 57.4% | 82.2% | 71.7% | 70.4% |
| DeepSeek-Coder-Base | 7B | 66.6% | 88.1% | 79.7% | 80.7% |
| DeepSeek-Coder-Base | 33B | 65.4% | 86.6% | 82.5% | 81.2% |
表6 | 不同方法在FIM任务上的表现。
评估结果显示在表6中。尽管DeepSeek-Coder是容量最小的模型,拥有13亿参数,但在这些基准测试中,它超越了较大的对手StarCoder和CodeLlama。这种卓越的性能可以归因于DeepSeek-Coder使用的预训练数据的高质量。此外,一个值得注意的趋势是模型大小与其性能之间的相关性。随着模型大小的增加,性能有相应且负责任的提升。这一趋势强调了模型容量在实现代码完成任务更高精度方面的重要性。基于这些发现,我们推荐在代码完成工具中部署DeepSeek-Coder-Base 6.7B模型。这一建议基于该模型在效率和精度之间展现出的平衡。DeepSeek-Coder-Base 6.7B模型凭借其庞大的参数规模,已被证明在代码完成环境中极为有效,使其成为将先进计算能力整合到编码环境中的理想选择。
4.3. 跨文件代码补全
在本节中,我们将评估现有开源模型在跨文件代码补全任务中的表现。不同于前一节讨论的代码生成,跨文件代码补全要求模型访问并理解多个文件的仓库,这些仓库包含众多跨文件依赖关系。我们使用CrossCodeEval(丁等人)。(2023年)评估目前可用的70亿参数量级开源代码模型在跨文件补全任务中的能力。该数据集构建于四个流行编程语言(Python、Java、TypeScript和C#)中多种真实、开源且宽松授权的代码库。该数据集特别设计为需要跨文件上下文以确保准确补全。值得注意的是,此数据集构建于2023年3月至6月之间创建的代码库,而我们的预训练数据仅包括2023年2月之前创建的代码,确保此数据集未出现在我们的预训练数据中,从而避免数据泄露。
| Model | Size | Python | Python | Java | Java | TypeScript | TypeScript | C# | C# |
|---|---|---|---|---|---|---|---|---|---|
| Model | Size | EM | ES | EM | ES | EM | ES | EM | ES |
| CodeGeex2 | 6B | 8.11% | 59.55% | 7.34% | 59.60% | 6.14% | 55.50% | 1.70% | 51.66% |
| + Retrieval | 10.73% | 61.76% | 10.10% | 59.56% | 7.72% | 55.17% | 4.64% | 52.30% | |
| StarCoder-Base | 7B | 6.68% | 59.55% | 8.65% | 62.57% | 5.01% | 48.83% | 4.75% | 59.53% |
| +Retrieval | 13.06% | 64.24% | 15.61% | 64.78% | 7.54% | 42.06% | 14.20% | 65.03% | |
| CodeLlama-Base | 7B | 7.32% | 59.66% | 9.68% | 62.64% | 8.19% | 58.50% | 4.07% | 59.19% |
| + Retrieval | 13.02% | 64.30% | 16.41% | 64.64% | 12.34% | 60.64% | 13.19% | 63.04% | |
| DeepSeek-Coder-Base | 6.7B | 9.53% | 61.65% | 10.80% | 61.77% | 9.59% | 60.17% | 5.26% | 61.32% |
| + Retrieval | 16.14% | 66.51% | 17.72% | 63.18% | 14.03% | 61.77% | 16.23% | 63.42% | |
| + Retrieval w/o Repo Pre-training | 16.02% | 66.65% | 16.64% | 61.88% | 13.23% | 60.92% | 14.48% | 62.38% |
表7 | 不同模型在跨文件代码补全上的表现。
在对各种模型进行评估时,我们将最大序列长度设为2048个标记,最大输出长度设为50个标记,并设定跨文件上下文的限制为512个标记。对于跨文件上下文,我们使用丁等人(2023年)提供的官方BM25搜索结果。评估指标包括精确匹配和编辑相似度。表7中展示的结果表明,DeepSeek-Coder在多种语言的跨文件补全任务中一致性地优于其他模型,展示了其优越的实际应用能力。当仅使用文件级代码语料库(无仓库预训练)对DeepSeek-Coder进行预训练时,我们观察到Java、TypeScript和C#语言的表现下降,这表明了仓库级预训练的有效性。
4.4. 基于程序的数学推理
基于程序的数学推理涉及评估模型通过编程理解及解决数学问题的能力。这种推理在数据分析和科学计算等领域至关重要。为了进行此评估,我们采用高等人(2023年)概述的基于程序辅助的数学推理(PAL)方法。该方法应用于七个不同的基准测试,每个测试提供独特的挑战和上下文。这些基准测试包括GSM8K(Cobbe等人,2021年)、MATH(Hendrycks等人,2021年)、GSM-Hard(高等人,2023年)、SVAMP(Patel等人,2021年)、TabMWP(Lu等人,2022年)、ASDiv(苗等人,2020年)以及MAWPS(Gou等人,2023年)。在这些基准测试中,模型被提示交替用自然语言描述解决方案步骤,然后用代码执行该步骤。如表8所示,DeepSeek-Coder模型在所有基准测试中都取得了显著的性能,尤其是33B变体,这展示了在需要复杂数学计算和问题解决能力的应用中使用此类模型的潜力。
| Model | Size | GSM8k | MATH | GSM-Hard | SVAMP | TabMWP | ASDiv | MAWPS | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models |
| CodeGeex-2 | 7B | 22.2% | 9.7% | 23.6% | 39.0% | 44.6% | 48.5% | 66.0% | 36.2% |
| StarCoder-Base | 16B | 23.4% | 10.3% | 23.0% | 42.4% | 45.0% | 54.9% | 81.1% | 40.0% |
| CodeLlama-Base | 7B | 31.2% | 12.1% | 30.2% | 54.2% | 52.9% | 59.6% | 82.6% | 46.1% |
| CodeLlama-Base | 13B | 43.1% | 14.4% | 40.2% | 59.2% | 60.3% | 63.6% | 85.3% | 52.3% |
| CodeLlama-Base | 34B | 58.2% | 21.2% | 51.8% | 70.3% | 69.8% | 70.7% | 91.8% | 62.0% |
| DeepSeek-Coder-Base | 1.3B | 14.6% | 16.8% | 14.5% | 36.7% | 30.0% | 48.2% | 62.3% | 31.9% |
| DeepSeek-Coder-Base | 6.7B | 43.2% | 19.2% | 40.3% | 58.4% | 67.9% | 67.2% | 87.0% | 54.7% |
| DeepSeek-Coder-Base | 33B | 60.7% | 29.1% | 54.1% | 71.6% | 75.3% | 76.7% | 93.3% | 65.8% |
表8 | 不同方法在程序辅助的数学推理任务上的表现。
5. 继续从通用大型语言模型预训练
为了进一步提升DeepSeek-Coder模型的自然语言理解和数学推理能力,我们从通用语言模型DeepSeek-LLM-7B Base(DeepSeek-AI,2024)上进行了额外的预训练,使用了2万亿个令牌,从而产生了DeepSeek-Coder-v1.57B。在这次预训练中,我们特别使用了表9中列出的数据源。不同于DeepSeek-Coder,DeepSeek-Coder-v1.5在其预训练阶段仅采用了一个以4K上下文长度为目标的下一个令牌预测任务。
| Data Source | Percentage |
|---|---|
| Source Code | 70% |
| Markdown and StackExchange | 10% |
| Natural language related to code | 7% |
| Natural language related to math | 7% |
| Bilingual(Chinese-English) natural language | 6% |
表格9 | DeepSeek-Coder-v1.5 7B预训练的数据来源
我们进行了DeepSeek-Coder-v1.5 7B与DeepSeek-Coder 6.7B之间的比较,并使用我们的评估流程重新运行所有基准测试,以确保公平比较。我们评估了各种任务的性能,这些任务可以归类如下:
● 编程:该类别包括使用Chen等人(2021年)的多语言人类评估数据集进行的评估,以及使用Austin等人(2021年)的Python多指令多数据集进行的评估。
● 数学推理:我们使用Cobbe等人(2021年)的GSM8K基准测试和Hendrycks等人(2021年)的MATH基准测试[4]来评估数学推理任务的性能。这些任务涉及通过生成程序来解决数学问题。
● 自然语言:我们在自然语言任务中的评估包括MMLU(Hendrycks等人,2020年)、BBH(Suzgun等人,2022年)、HellaSwag(Zellers等人,2019年)、Winogrande(Sak-aguchi等人,2021年)以及ARC挑战(Clark等人,2018年)等基准测试。
基础模型和指导模型的结果显示在表10中。观察到DeepSeek-Coder-Base-v1.5模型尽管在编码性能上略有下降,但与DeepSeek-Coder-Base模型相比,在大多数任务上表现出显著改进。特别是在数学推理和自然语言类别中,DeepSeek-Coder-Base-v1.5在所有基准测试中都显著优于其前身,这也展示了其在数学推理和自然语言处理能力方面的显著改进。
| Models | Size | Programming | Programming | Math Reasoning | Math Reasoning | Natural Language | Natural Language | Natural Language | Natural Language | Natural Language |
|---|---|---|---|---|---|---|---|---|---|---|
| Models | Size | HumanEval | MBPP | GSM8K | MATH | MMLU | BBH | HellaSwag | WinoG | aSwag |
| DeepSeek-Coder-Base | 6.7B | 44.7% | 60.6% | 43.2% | 19.2% | 36.6% | 44.3% | 53.8% | 57.1% | 53.8% 57.1% 32.5% |
| DeepSeek-Coder-Base-v1.5 | 6.9B | 43.2% | 60.4% | 62.4% | 24.7% | 49.1% | 55.2% | 69.9% | 63.8% | 47.2% |
| DeepSeek-Coder-Instruct | 6.7B | 66.1% | 65.4% | 62.8% | 28.6% | 37.2% | 46.9% | 55.0% | 57.6% | 37.4% |
| DeepSeek-Coder-Instruct-v1.5 | 6.9B | 64.1% | 64.6% | 72.6% | 34.1% | 49.5% | 53.3% | 72.2% | 63.4% | 48.1% |
表10 | DeepSeek-Coder-Base与DeepSeek-Coder-Base-v1.5性能对比分析。数学任务通过编程解决。
6. 结论
在这份技术报告中,我们介绍了一系列用于编程的专业化大型语言模型(LLMs),名为DeepSeek-Coder,提供三种不同规模的模型:13亿、67亿和330亿参数。这些模型在精心策划的项目级代码语料库上进行独特训练,采用“填空”预训练目标以增强代码填充能力。一个重大进展是将模型的上下文窗口扩展至16384个标记,从而大幅提高其在处理广泛代码生成任务中的有效性。我们的评估显示,我们系列中最先进的模型——DeepSeek-Coder-Base 330亿参数模型,在多种标准测试中超越了现有的开源代码模型。令人印象深刻的是,尽管DeepSeek-Coder-Base 67亿参数模型规模较小,但在性能上与340亿参数的CodeLlama不相上下,这证明了我们预训练语料库的高质量。
为了提升DeepSeek-Coder-Base模型的零样本指令能力,我们用高质量的教学数据对其进行了微调。这使得DeepSeek-Coder-Instruct 330亿参数模型在一系列编码相关任务上超越了OpenAI的GPT-3.5 Turbo,展示了其在代码生成和理解方面的卓越熟练度。
为了进一步提升DeepSeek-Coder-Base模型的自然语言理解能力,我们基于DeepSeek-LLM 7B的检查点进行了额外的预训练。此次额外训练涉及处理一个包含20亿个标记(包括自然语言、代码和数学数据)的多样化数据集。其结果是创建了新的改进版代码模型——DeepSeek-Coder-v1.5。我们的观察表明,DeepSeek-Coder-v1.5不仅保持了其前身的高层次编码性能,还展现了更强的自然语言理解能力。这一进步强调了我们的信念:最有效的以代码为中心的大型语言模型(LLMs)是那些建立在强大通用LLMs之上的模型。原因显而易见:为了有效解释和执行编程任务,这些模型也必须对人类指令有深刻的理解,而这些指令通常以多种自然语言形式出现。展望未来,我们的承诺是基于更大规模的通用LLMs开发并公开分享更加强大的以代码为中心的LLMs。
致谢
我们要对刘波、邓成奇、阮冲、戴大迈、李嘉石、关康、张明川、黄盼盼、于水平、马世荣、孙耀峰、皮业诗、邵志宏和郝哲文在训练DeepSeek-Coder模型期间的宝贵讨论和协助表示感谢。
参考文献
L.B. Allal, R. Li, D. Kocetkov, C. Mou, C. Akiki, C. M. Ferrandis, N. Muennighoff, M. Mishra, A. Gu, M. Dey等。Santacoder:不要试图触及星辰!arXiv预印本arXiv:2301。03988, 2023年。
奥斯汀J., 奥德纳A., 内伊M., 博斯马M., 米哈尔夫斯基H., 多汉D., 蒋E., 蔡C., 特里M., 乐Q., 萨顿C. 使用大型语言模型进行程序综合,2021年。
巴伐利亚M., 朱H., 特扎克N., 舒尔曼J., 麦克利维C., 特沃雷克J., 陈M. 高效训练语言模型以填补中间空白。arXiv预印本arXiv:2207.14255, 2022年。
卡萨诺F., 古瓦尔J., 阮D., 阮S., 菲普斯-科斯廷L., 平克尼D., 余M.-H., 易Y., 子Y., 安德森C. J., 费尔德曼M. Q. 等。多语言:一种可扩展且多语言的方法,用于神经代码生成的基准测试。IEEE软件工程交易,2023年。
陈M., 特沃雷克J., 朱H., 袁Q., 多O. 平托H. P., 卡普兰J., 爱德华兹H., 伯达Y., 约瑟夫N., 布罗克曼G. 等。评估在代码上训练的大型语言模型。arXiv预印本arXiv:2107.03374, 2021年。
陈S., 黄S., 陈L., 田Y. 通过位置插值扩展大型语言模型的上下文窗口。arXiv预印本arXiv:2306.15595, 2023年。
克拉克P., 考伊I., 埃齐奥蒂O., 科特T., 萨巴尔瓦尔A., 舍尼克C., 塔夫约德O. 你以为你解决了问答问题吗?试试ARC,AI2推理挑战。arXiv预印本arXiv:1803.05457, 2018年。
科布K., 科萨里亚朱V., 巴伐利亚M., 陈M., 朱H., 凯瑟L., 普拉特M., 特沃雷克J., 希尔顿J., 中野R. 等。训练验证器解决数学文字题。arXiv预印本arXiv:2110.14168, 2021年。
道T. Flashattention-2:更快注意力,更好的并行性和工作划分,2023年。
DeepSeek-AI。Deepseek大型语言模型:用长期主义扩展开源语言模型。arXiv预印本arXiv:2401。02954,2024。
丁一,王振,艾哈迈德·乌玛斯·乌普提,丁浩,谭明,贾宁·纳拉扬,拉曼纳桑·穆罕默德·凯克什,纳拉帕提·拉吉,巴蒂亚·普拉卡什,罗斯·大卫,等。跨代码评估:一个多样化和多语言的跨文件代码补全基准测试。在第三十七届神经信息处理系统大会数据集与基准测试专题研讨会,2023年。
杜志,钱宇,刘鑫,丁明,邱军,杨志,唐杰。GLM:一种使用自回归空白填充的通用语言模型预训练。在计算机协会第60届年会论文集(第一卷:长文),第320-335页,2022年。
弗里德·D,阿加贾尼扬·A,林俊,王松,华莱士·E,史峰,钟锐,易文涛,泽特勒莫耶·L,刘易斯·M。编码器:一种用于代码填充和合成的生成模型。arXiv预印本arXiv:2204.05999,2022年。
高等,马达安·A,周松,阿隆·U,刘鹏,杨阳,卡拉恩·J,诺伊比格·G。Pal:程序辅助的语言模型。在机器学习国际会议,第10764-10799页。PMLR,2023年。
双子座团队。双子座:一系列高度能力的多模态模型,2023年。网址https://goo.gle/GeminiPaper。
勾志,邵志,龚宇,杨阳,黄明,段娜,陈炜,等。托拉:一个集成了工具的数学问题解决推理代理。arXiv预印本arXiv:2309.17452,2023年。
亨德里克斯·D,伯恩斯·C,巴沙特·S,邹安,马齐卡·M,宋迪,斯坦哈德·J。衡量大规模多任务语言理解。在国际学习表征大会,2020年。
亨德里克斯·D,伯恩斯·C,卡达瓦思·S,阿罗拉·A,巴沙特·S,唐易,宋迪,斯坦哈德·J。用数学数据集衡量数学问题解决能力。arXiv预印本arXiv:2103。03874,2021。
高飞者。海-LLM:一种高效轻量级的训练大型模型的工具。2023年。网址:https://www.high-flyer.cn/en/blog/hai-llm。
开奥肯德夫。我在训练《超级热》时学到的东西。2023年。网址:https://kaiokendev.github.io/til#extending-context-to-8k。
D.科切特科夫、R.李、L.贾、C.穆、Y.耶尔尼特、M.米切尔、C.M.费兰迪斯、S.休斯、T.沃尔夫、D.巴哈杜尔等。《栈》:3太字节宽松许可的源代码。机器学习研究交易,2022年。
V. A. 科尔特金提、J.卡斯珀、S. 利姆、L. 麦卡菲、M. 安德施、M. 肖伊比和B. 卡坦扎罗。减少大型变压器模型中的激活重计算。机器学习与系统会议论文集,第5卷,2023年。
Y.赖、C.李、Y.王、T.张、R.钟、L.泽特勒莫伊、W.-t.易、D.弗里德、S.王和T.余。DS-1000:数据科学代码生成的自然可靠基准。在《国际机器学习会议》,第18319-18345页。PMLR,2023年。
K. 李、D. 伊波利托、A. 尼斯特龙、C. 张、D. 埃克、C. 卡尔林森-伯奇和N. 卡拉利尼。去重训练数据使语言模型更好。在《第60届计算语言学协会年会论文集(第一卷:长论文)》第8424-8445页,2022年。
R.李、L.B.阿拉尔、Y.资、N.穆恩尼霍夫、D.科切特科夫、C.穆、M.马罗内、C.阿基基、J.李、J.奇姆等。星级编码器:愿源码与你同在!arXiv预印本arXiv:2305.06161,2023年。
I. 洛什奇洛夫和F. 胡特。解耦权重衰减正则化,2019年。
P.陆、L.邱、K.-W.张、Y.吴、S.-C.朱、T.拉吉普鲁希特、P.克拉克和A.卡利亚安。通过策略梯度动态提示学习半结构化数学推理。在第十一届国际学习表征会议上,2022年。
苗绍毅、梁晨晨和苏开阳。用于评估和发展英语数学单词问题解决器的多样化语料库。在《计算机语言学协会第58届年会论文集》中,第975-984页,2020年。
纳拉亚南·D、哈拉帕尔·A、法尼沙伊·A、谢沙迪·V、德瓦努鲁·N·R、甘杰尔·G·R、吉本斯·P·B和马扎里亚·M。管道梦想:用于深度神经网络训练的广义流水线并行性。在《第27届ACM操作系统原理研讨会论文集》中,第1-15页,2019年。
尼坎普·E、庞博·B、林宏、涂磊、王浩、周勇、萨瓦雷塞·S和熊超。代码生成:具有多轮程序合成的代码开放大型语言模型。arXiv预印本arXiv:2203.13474,2022年。
尼坎普·E、林宏、熊超、萨瓦雷塞·S和周勇。代码生成2:训练编程与自然语言大型语言模型的经验教训,2023年。
开放AI。GPT-4技术报告,2023年。
帕特尔·A、巴特拉米什拉·S和戈亚尔·N。自然语言处理模型真的能够解决简单的数学单词问题吗?在《北美计算语言学协会2021年会议论文集:人类语言技术》中,第2080-2094页,2021年。
拉费尔·C、沙泽尔·N、罗伯茨·A、李凯、纳兰·S、马特纳·M、周勇、李伟和刘平。用统一的文本到文本转换器探索迁移学习的极限,2023年。
拉贾班迪·S、拉斯利·J、鲁瓦西·O和何宇。零:针对训练三狮参数模型的内存优化,2023年。在《SC20:高性能计算、网络、存储与分析国际会议》,第1-16页。IEEE,2020年。
B. 罗齐耶,J. 格林,F. 格洛克勒,S. 苏特拉,I. 加特,X.E.谭,Y.阿迪,J.刘,T.雷梅兹,J.拉平等人。代码 llama:代码的开放基础模型。arXiv预印本arXiv:2308.12950,2023年。
坂口宏,R. L. 布拉斯,C. 巴加瓦图拉,以及崔英。Winogrande:大规模对抗性Winograd方案挑战。计算机协会通讯,64(9):99-106,2021年。
塞恩里奇,R. 哈多,以及伯奇,A. 用子词单位进行神经机器翻译罕见词汇。arXiv预印本arXiv:1508.07909,2015年。
苏俊,Y. 陆,潘松,穆尔塔达,B. 文,以及刘阳。Roformer:增强型带有旋转位置嵌入的Transformer,2023年。
苏兹贡,M. 斯卡尔斯,沙利,N. 谢尔,格尔曼,S. 泰,钟伟华,乔德里,A. 乔杜里,列夫·V.,迟东辉,周丹,以及魏军。挑战大基准任务及思维链是否能解决它们。arXiv预印本arXiv:2210.09261,2022年。
陶里,R. 古鲁拉贾尼,张涛,杜波依斯,李鑫,格斯特林,梁鹏,以及桥本俊。斯坦福羊驼:一种遵循指令的羊驼模型。https://github.com/tatsu-lab/stanford_alpaca,2023年。
图弗隆,H. 马丁,斯通,P. 阿尔伯特,阿尔马海里,巴巴埃伊,纳什利科夫,巴特拉,S. 巴特拉,布哈斯瓦尔,S. 波萨尔等。羊驼2:开放基础及微调聊天模型。arXiv预印本arXiv:2307.09288,2023年。
王阳,王炜,乔提,以及何世昌。Codet5:用于代码理解与生成的标识符感知的统一预训练编码器-解码器模型。arXiv预印本arXiv:2109.00859,2021年。
泽勒斯,R. 霍尔特兹曼,比斯克,Y. 阿尔特。法哈迪和崔颖。Hellaswag:机器真的能完成你的句子吗?在《第57届计算语言学协会年会论文集》中,第4791-4800页,2019年。
郑强、夏鑫、邹晓、董宇、王帅、薛阳、沈磊、王哲、王傲、李扬等。Codegeex:一个预训练模型,用于通过多语言基准测试在humaneval-x上进行代码生成。在《第29届ACM SIGKDD知识发现与数据挖掘会议论文集》中,第5673-5684页,2023年。
与DeepSeek-Coder-Instruct聊天的案例
我们将展示两个与DeepSeek-Coder-Instruct互动的案例,一个是关于创建数据库和执行数据分析的多轮对话,另一个是以解决LeetCode上的一个样例问题为中心的模型使用。
在第一个场景中,如图5所示,我们指导模型使用Python构建一个学生数据库,并随机插入10条信息。随后,在第二轮对话中,我们继续通过分析学生的年龄分布来询问模型。从图5可以看出,模型能够生成无错误且全面的代码,并附上解释性细节。在第二个场景中,如图6所示,我们通过在一个领域外的LeetCode竞赛问题上测试模型来进一步评估其能力。这个特定的问题是在2023年11月发布的,在我们的数据收集之后,因此,不是我们模型训练数据的一部分。结果显示,我们的模型在解决超出其训练分布的问题上表现出色。

图5 | 构建数据库和数据分析的一个示例。


图6 | 解决LeetCode问题的一个示例。
B. 在DeepSeek-Coder-Base训练期间的基准曲线
在图7中,我们展示了展示DeepSeek-Coder-Base模型在训练阶段性能的基准曲线。为了验证,采用了精心策划的训练语料库子集,包括8000个代码文件。这个子集被特意选择以确保多样性和代表性样本,这对于准确评估模型能力至关重要。这些模型的性能指标在图7的最后两个子图中具体详细说明,提供了它们在整个训练过程中的效果的清晰视觉表现。
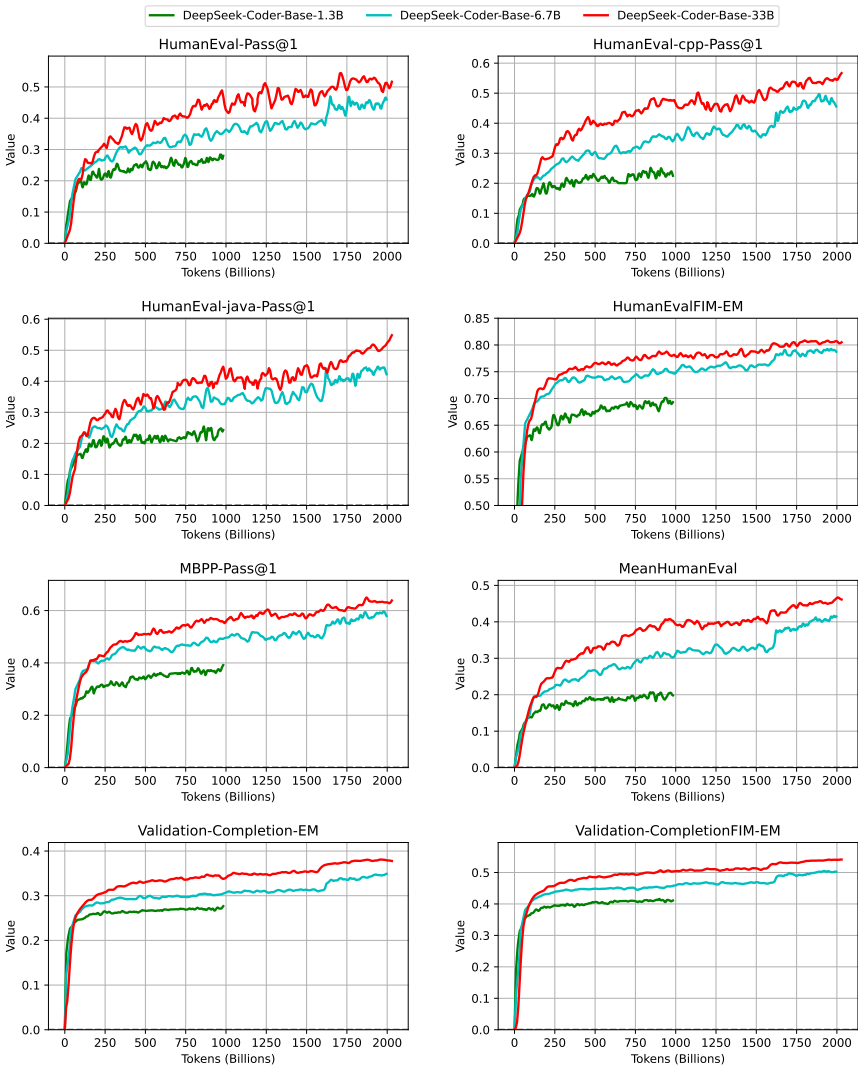
图7 | DeepSeek-Coder-Base训练期间的基准曲线。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献282条内容
已为社区贡献282条内容

所有评论(0)