论文精读:Test-Time Prompt Tuning for Zero-ShotGeneralization in Vision-Language Models(测试时提示调优)
《TPT:基于单测试样本的动态提示优化方法》论文摘要 本文针对视觉语言模型在零样本泛化中依赖手工设计提示或下游训练数据的问题,提出了一种创新解决方案TPT。该方法首次实现了仅通过单个测试样本动态优化提示,在自然分布偏移、跨数据集任务和视觉推理任务中显著提升了零样本性能。TPT通过数据增强生成多个视图,利用置信度过滤机制排除高熵样本,并最小化预测结果的边际熵来优化提示嵌入。实验表明,TPT在Imag
这次介绍的是NeurIPS'2022的一篇关于视觉语言模型Vision Language Model方面的经典的一篇论文。
论文链接:https://arxiv.org/pdf/2209.07511
代码链接:https://github.com/azshue/TPT
一、论文摘要
这篇论文针对预训练视觉语言模型(如 CLIP)在零样本(zero shot)泛化中依赖手工设计提示或下游训练数据的问题,首次提出了通过单个测试样本动态优化提示的方法,在自然分布偏移、跨数据集的任务以及视觉推理任务重的零样本性能取得了提升。
(注:这里zero shot的意思是在下游任务比如图像分类、视觉推理等等时,无需依赖下游任务的标注或训练数据,仅通过预训练阶段学习到的知识,通过设计提示、调优提示完成任务的一种范式)
二、论文背景
在这一部分我们主要探讨之前算法的缺陷、作者提出这个的意义在哪?
为了提升视觉语言模型VLM的零样本性能,之前的论文主要探索了两种针对提示的方法,但存在明显不足。
1、手工设计提示
这种方式需要人工设计提示,依赖设计者的经验,例如 CLIP 默认使用的 “a photo of a”。但是这种方式存在一个巨大的缺陷,那就是不满足通用型,针对不同任务需要人工不断调整提示。同时,这种手工设计的方式提示性能存在上限,不能在下游任务如分布偏移的图像分类等等中表现更好。
2、基于下游训练数据的提示调优
在手工设计提示之后发展出了这种方法,它的工作方式是将提示嵌入作为模型可微输入的一部分,通过下游任务的训练数据比如 ImageNet 的标注样本微调提示,使其适配特定任务分布。这种方式有很大的局限性:直接脱离了zero shot的设定,同时从特定任务学习提示,会导致在面对其他领域或任务时性能大幅下降,泛化能力大幅降低,这明显是不好的。
3、其他
除了以上两种比较主流的方法,还有无监督提示学习,但其需要依赖多个训练或测试样本,不适配这种zero shot的场景。另外,测试时优化也是一个重要的场景,比如我第一篇论文博客里提到的TENT(通过最小化批次的预测熵来适配测试数据,调整分布),但是需要多个测试样本。还有点方法尝试对VLM的视觉编码器或文本编码器进行模型微调,但是这会破坏预训练学到的知识。
4、TPT的提出
那么TPT首先是设定在zero shot下的tuning这种场景下的,他为了对抗这种依赖下游任务训练数据或标注的导致的结果偏向某一类,泛化能力不足的问题,TPT不需要这些下游数据,他仅仅只依靠单个测试样本在测试时实时优化提示。同时,为了解决他对单个测试样本使用数据增强后产生的高噪声样本,还增加了一个通过置信度过滤高熵样本的机制。而TPT是依赖于CLIP这种预训练的多模态模型的,因此为了验证优化哪些是提示是有效的,该算法还专门给出了经过验证后的最佳选择。
三、算法解析
这部分重点介绍TPT这个算法的核心思想、公式、步骤与实现。
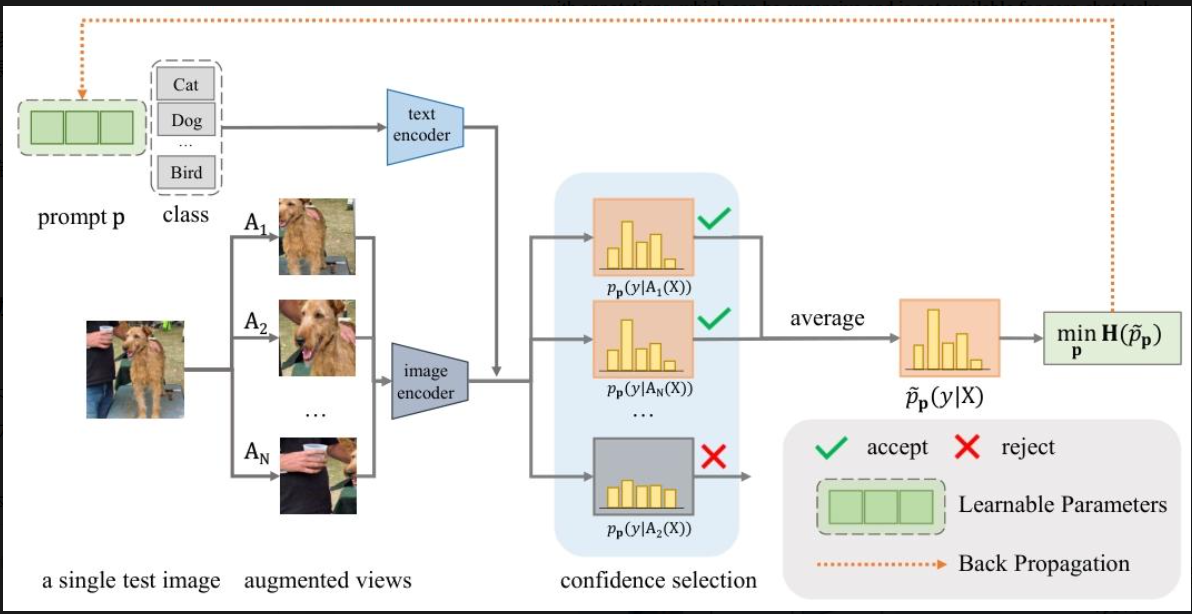
根据上图我们先来简要的介绍。
首先看到左下角的单张测试图像,通过数据增强(裁剪、翻转等)生成了N张图片,这N张图片作为图像编码器的输入。再看上面,初始化了文本提示p,将其转换为嵌入向量,与文本内容拼接在一起后输入文本编码器。
结合文本编码器与图像编码器对这N个增强视图进行预测,这一步的核心就是要促进N张图片的预测结果尽可能地一致(我们期望同一张图片不管怎么预测都是一个类别)。对于每个增强视图,先计算其预测结果的熵值,然后将熵值从低到高排序后,通过一个阈值进行过滤高熵样本。
通过置信度机制筛选出来的高置信度的预测,对其取平均作为在提示p下将测试样本Xtest预测为y类别的概率。接着对这个概率作熵值计算,我们的目的是最小化这个平均概率的边际熵,以此来优化提示p,通过反向传播更新提示p的嵌入参数。
那么接下来通过论文中的公式 我们来看具体是怎么实现的。
1、图像分类任务
首先来看传统的依赖下游数据的方法如公式1、2
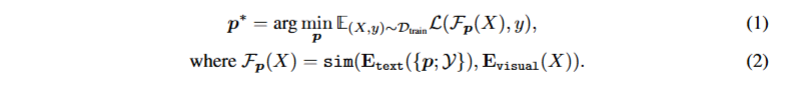
公式 1 是传统基于下游训练数据的提示调优的目标函数,通过最小化下游标注训练集上的期望交叉熵损失,学习适配该训练集分布的最优提示嵌入p∗。
公式 2 定义了提示作用下的核心计算逻辑,通过 CLIP 的文本编码器和视觉编码器,分别计算 “提示与类别拼接文本” 的特征和图像特征的余弦相似度,生成提示依赖的相似度矩阵Fp(X)。
那么来看TPT是怎么做的,TPT有一个通用优化目标如公式3,在零样本场景下,不依赖任何训练数据,仅基于单个测试样本Xtest,通过最小化针对该样本设计的定制损失L,找到最优提示p∗,实现提示的测试时动态优化。
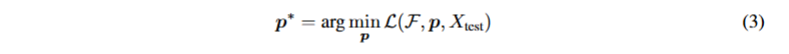
针对图像分类的损失函数如公式4TPT通过最小化单个测试样本多个随机增强视图的平均预测概率p~p(yi∣Xtest)的边际熵,优化提示p,确保模型对该样本不同增强视图的预测保持一致。
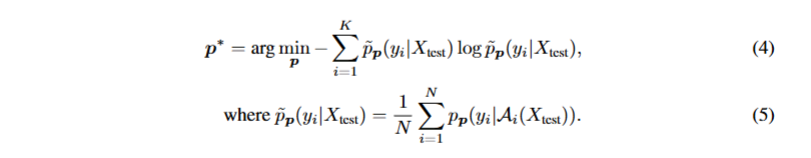
这个损失函数边际熵的计算代码如下:(详细注释已给出)
#边际熵计算 衡量预测结果的一致性 算的是多个增强样本的 “平均预测分布” 的熵
#在对数空间上计算避免数值计算问题和计算稳定性 否则当出现极端值时 会出现问题
def avg_entropy(outputs):
#outputs[N,C] N是增强样本数量,C是类别数
#把原始输出转化为对数概率 实现对数softmax log_softmax(x)_i = log(exp(x_i) / Σ(exp(x_j))) = x_i - log(Σ(exp(x_j)))
logits = outputs - outputs.logsumexp(dim=-1, keepdim=True) # logits = outputs.log_softmax(dim=1) [N, 1000]
#对数空间求和 + 对数空间除法 avg_logits[c] 最终是 “平均概率” 的对数 每个类别上的平均概率的对数
avg_logits = logits.logsumexp(dim=0) - np.log(logits.shape[0]) # avg_logits = logits.mean(0) [1, 1000]
min_real = torch.finfo(avg_logits.dtype).min
avg_logits = torch.clamp(avg_logits, min=min_real) #把数值限制在[min_real,+∞), 数值稳定性处理
return -(avg_logits * torch.exp(avg_logits)).sum(dim=-1) #计算这个N个样本平均输出后的熵最后TPT还引入了置信度选择机制,如公式6所示,在公式 5 基础上,过滤掉单个测试样本增强视图中预测熵高(置信度低)的噪声视图,仅用熵值低于动态阈值τ的有效视图重新计算平均预测概率。
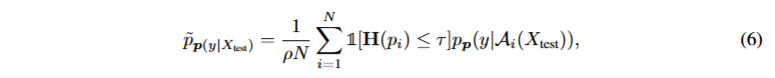
#置信度选择函数
def select_confident_samples(logits, top):
#在1维度上计算每个样本的熵值
batch_entropy = -(logits.softmax(1) * logits.log_softmax(1)).sum(1) #形状为batch的张量 每个值是一个熵
idx = torch.argsort(batch_entropy, descending=False)[:int(batch_entropy.size()[0] * top)]#top是一个比例 升序排列后取前百分之多少
return logits[idx], idx#返回选取低熵值样本后的输出列表和索引列表如代码所示,先计算熵值后,对其进行排序,最后按比例返回熵值较低的样本。通过这个就直接过滤掉了那些高熵值样本(会影响预测结果的一致性)。
那么代码中最后整个测试时提示优化是怎么样进行的,让我们通过代码来进行拆解。
#在测试阶段,针对单个样本的多个增强视图(如旋转、裁剪等),动态优化模型的提示词(Prompt)参数
#测试时提示调优
def test_time_tuning(model, inputs, optimizer, scaler, args):
#cocoop是一种条件提示生成器 否则的话就是基础提示词(手工初始化的)
if args.cocoop:
image_feature, pgen_ctx = inputs #从输入中获取图像特征和上下文参数
pgen_ctx.requires_grad = True #这个pgen_ctx是生成提示词的控制信号
optimizer = torch.optim.AdamW([pgen_ctx], args.lr) #仅优化pgen_ctx
#多轮迭代优化提示词
selected_idx = None #记录高置信度样本索引
for j in range(args.tta_steps):
with torch.cuda.amp.autocast(): #混合精度计算
if args.cocoop:
output = model((image_feature, pgen_ctx))
else:#基础模式中,提示词是手工初始化的固定文本 转化为可训练的嵌入向量
output = model(inputs)
#筛选高置信度增强样本
if selected_idx is not None:
output = output[selected_idx]
else:
output, selected_idx = select_confident_samples(output, args.selection_p)
loss = avg_entropy(output)
optimizer.zero_grad() #梯度清零
# compute gradient and do SGD step
scaler.scale(loss).backward()
# Unscales the gradients of optimizer's assigned params in-place
scaler.step(optimizer)
scaler.update()
if args.cocoop:
return pgen_ctx #返回优化后的提示生成器参数
return如果不适用cocoop的话,那么就是使用手工涉及到提示。
对于使用cocoop的情况,那么先获取控制提示词生成的pegn_ctx,并将其设置为可训练,后面在测试时只会优化这个参数。
通过for循环控制优化迭代次数,获取模型输出后,根据置信度选择过滤样本,对剩下的样本进行熵值损失函数的计算,然后通过梯度清零、反向传播、更新参数的方式来优化控制生成提示p的pgen_ctx。
如果是手工设计提示的话,那么提示是固定的,直接转化为嵌入向量参与模型计算。
2、上下文依赖视觉推理任务
该任务的测试样本包含 正支持集XP(含目标 HOI,如 “ride bike”)、负支持集XN(不含目标 HOI)、查询图像Xquery,需判断Xquery是否含目标 HOI。
该任务与图像分类有较大区别,需要学习 支持集的上下文语义(区分 “含 / 不含 HOI”) 。于是TPT 新增可学习的二进制类别 token(记为cls={cls0,cls1},cls0对应 0,cls1对应 1)。因此与图像分类的损失函数不同从 “无监督边际熵” 改为 “半监督交叉熵”,并联合优化提示p与类别token cls。
如公式7所示
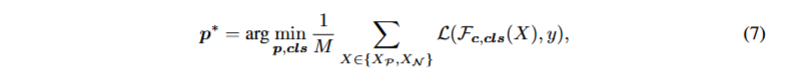
由于支持集自带 “正负标签”(XP标 1,XN标 0),TPT 用交叉熵损失优化p和cls,让提示学会区分支持集的上下文。
上下文学习:通过支持集的正负样本,让p学习 “目标 HOI 的关键特征”—— 例如,若支持集是 “人骑 bike”,p会优化为突出 “人 - 自行车 - 骑” 的交互语义;
联合优化cls:clsy不再是固定文本(如 “yes/no”),而是通过交叉熵学习与p匹配的类别特征 ——cls1会与XP的图像特征更相似,cls0则与XN更相似;
需要注意的是这篇文章虽然用了支持集,但支持集是测试样本的一部分(而非下游训练数据),因此仍然符合zero shot的设定。
由于我对该任务的人数不是很足,就介绍到这里,如果感兴趣请搜寻其他资源查找(冒汗...)。
四、实验结果
这个章节主要介绍这篇文章的实验结果。这篇文章实验主要分为四类:自然分布偏移下的鲁棒性实验、跨数据集的泛化、上下文依赖视觉推理以及非常重要的消融实验。
1、自然分布偏移下的鲁棒性实验
使用了4个ImageNet的变体数据集,这四个数据集的介绍如下:(摘自原文)

基线方法使用CLIP 基线(默认提示 “a photo of a”)、80 个手工提示集成、需训练数据的提示调优方法(CoOp、CoCoOp,均用 ImageNet 16-shot 数据训练)
TPT算法的设置为提示初始化为 “a photo of a”,生成 64 个增强视图(63 次随机裁剪 + 原始图),保留前 10% 高置信视图,AdamW 优化 1 步(学习率 0.005)
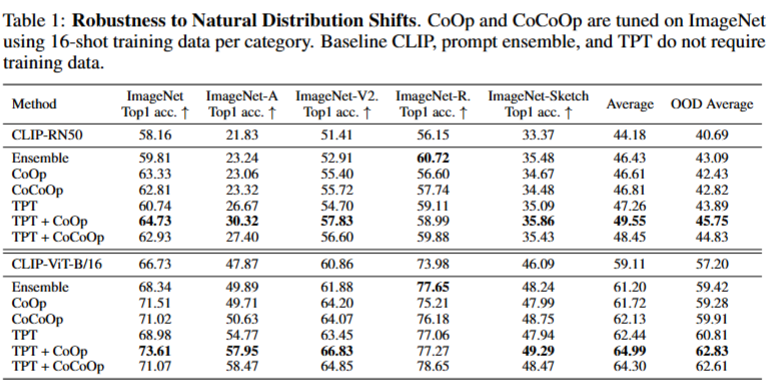
实验结果如上,可以看到TPT在仅用单个测试样本的条件下单独使用TPT仍有不错的效果,同时TPT可以与现有方法结合进一步提升性能。
当初在看到这里的时候我是有个疑惑的,因为在这之前我看过TTA测试时自适应算法FOA中的结果
小疑惑:为什么在ImageNet-V2和ImageNet-R的效果跟FOA实验结果是反过来的?
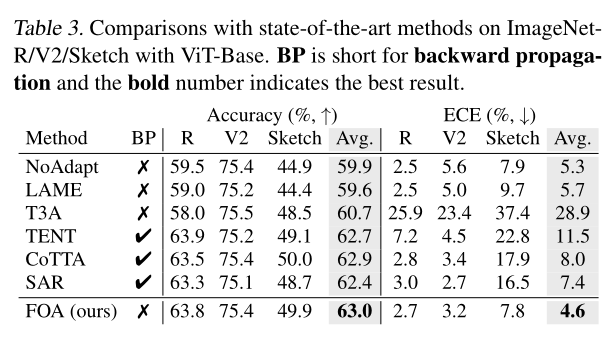
上述该表是FOA论文中关于ImageNet-V2和ImageNet-R的效果 可以看到R是60多的准确率,V2是70多的准确率,结果换到TPT这边来R变成了普遍的70+准确率,V2变为了60+的准确率。起初我以为是作者写错了,然后发现好像并非如此。FOA那种框架是基于ImageNet上预训练后才在ImageNet-R和ImageNet-V2这种偏移数据集上进行测试的。
经过查阅发现一篇论文讨论了这个:https://openaccess.thecvf.com/content/ICCV2023/papers/Jain_Efficiently_Robustify_Pre-Trained_Models_ICCV_2023_paper.pdf
零样本 CLIP 在 ImageNet-R 上的准确率显著高于 ImageNet 预训练后线性探测的 CLIP传统 ImageNet 预训练 unimodal 模型在 ImageNet-R 这类风格突变数据上泛化能力远弱于 CLIP 的 zero-shot 模式。
我的理解是V2数据是比较更偏向自然偏移分布,R数据集是艺术类型的图像,风格变化较大。而单模态模型在特定分布上预训练好,对他那种原来风格依赖较高? 这种多模态的学习他有多个依赖点 在这种风格变化比较剧烈的情况下表现稍好。有兴趣的友友可以继续探索。
2、跨数据集的泛化
采用10 个细分类数据集,覆盖花卉(Flower102)、宠物(OxfordPets)、场景(SUN397)、纹理(DTD)等。
有两种泛化场景
- 源数据集为 ImageNet(1000 类),目标为 10 个细分类数据集;
- 源数据集为某一细分类数据集,目标数据集与源数据集无类别重叠
对于1,如下图表实验
表 2:从 ImageNet 到细分类别数据集的跨数据集泛化结果。CoOp 和 CoCoOp 在 ImageNet 上进行调优,每个类别使用 16 样本的训练数据;基准模型 CLIP、提示集成方法以及 TPT 均无需训练数据或标注。表格中报告了各数据集上的 Top-1 分类准确率。(摘自原文)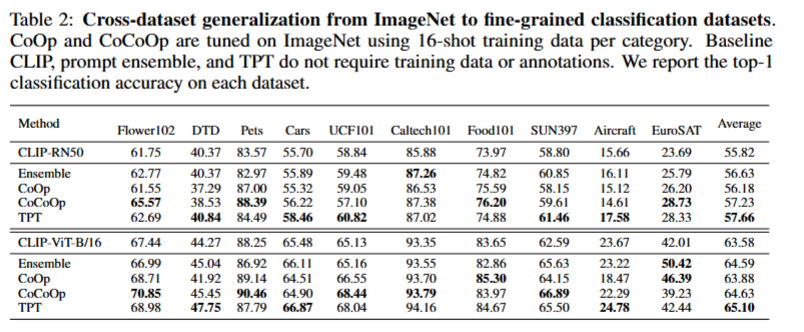
对于2,如下图所示
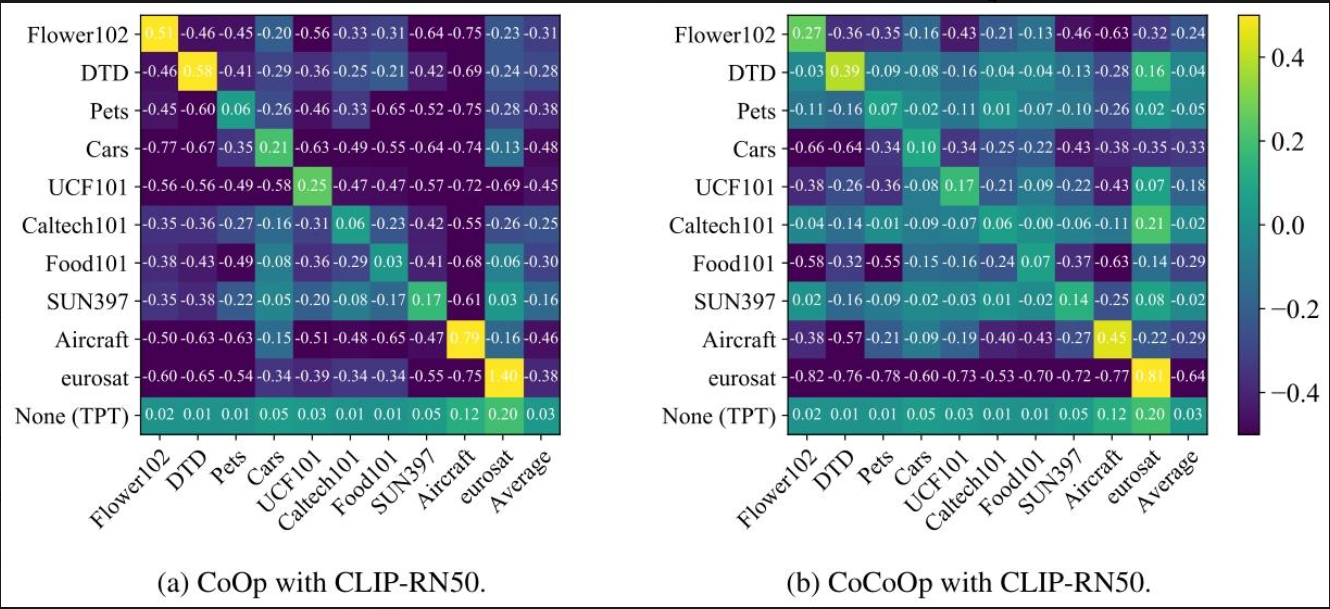
以零样本基准性能为基准进行归一化后的跨数据集改进率。在每个矩阵 A 中,Ai,j表示 “使用在第 i 个数据集上调优的提示” 在第 j 个数据集上的归一化相对改进率。Ai,j的值含义为:与零样本 CLIP 基准模型(使用手工设计的提示)相比,在第 i 个源数据集上训练的方法在第 j 个目标数据集上的表现优劣 —— 因此,该值越高越好。最后一行代表 TPT 的性能,该方法未在任何源数据集上进行调优;最后一列汇总了在 10 个数据集上的平均改进率,用于衡量模型在这 10 个数据集上的整体泛化能力。(摘自原文)
3、上下文依赖视觉推理(Bongard-HOI)
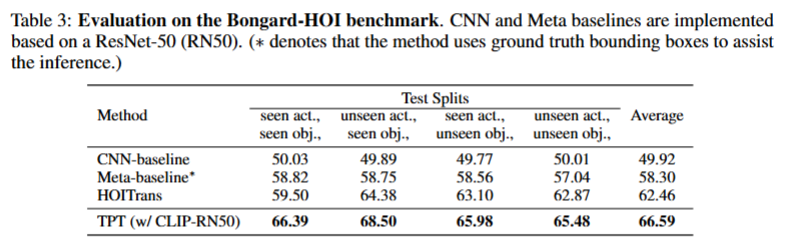
Bongard-HOI 任务需判断 “查询图像是否含支持集定义的人机交互(HOI)概念”,测试样本含 “正支持集(含 HOI)、负支持集(不含 HOI)、查询图像”,数据集分 4 个测试 split(按动作 / 物体是否在训练集中出现划分)
基线方法使用:CNN-baseline(ResNet-50 训练)、Meta-baseline(元学习训练,需 HOI 训练数据)、HOITrans(SOTA,需训练所有 HOI 概念)
4、消融实验
在这一部分通过消融实验作者验证 “文本提示最优”即为什么之前只优化文本提示以及验证置信度选择的作用。
(1)、验证文本提示最优
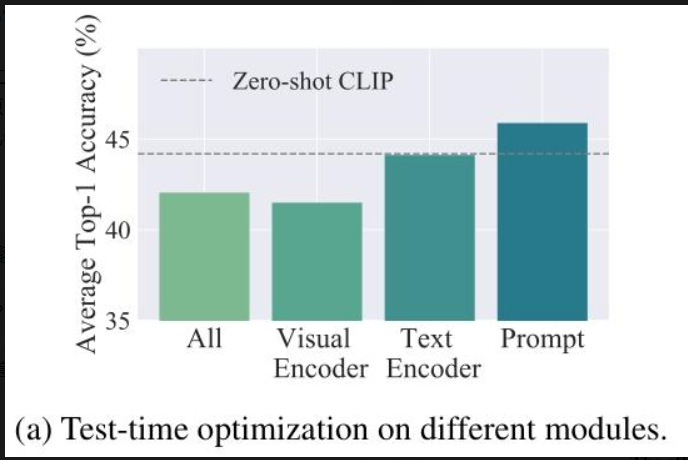
对比 CLIP 不同参数组的测试时优化效果,包括 “整个模型”“视觉编码器”“文本编码器”“文本提示”,均用 AugMix 增强,无置信度选择.
结果显示文本提示是最优优化对象,CLIP-RN50 上平均 Top-1 准确率最高(47.26%);优化视觉编码器性能最差(低于零样本 CLIP),因会扭曲预训练特征,与前人结论一致
(2)验证置信度选择
在这一部分作者通过对比 TPT(无置信度选择)与 TPT(含置信度选择,保留前 10% 高置信视图) 在自然分布偏移数据集上的性能来验证。结果如下:

结果确实说明了置信度选择机制的有效性,能够较为明显的提升性能。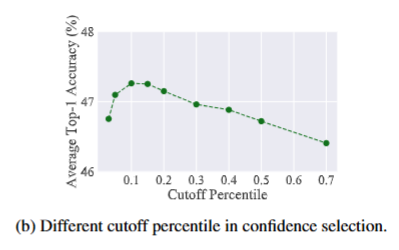
同时作者还给出了不同置信度阈值的效果,可以看到0.1附近是最佳的。
五、论文总结
读完了论文之后,快速地来总结一下文章
1、论文研究了什么问题
这篇文章研究预训练视觉语言模型(如 CLIP)在零样本泛化中依赖手工设计提示或下游训练数据的问题,探索仅用单个测试样本动态优化提示的方案。
2、为什么这个问题是一个很重要的问题
零样本泛化是视觉语言模型适配多样下游任务的核心能力,现有方法要么泛化性差、要么脱离零样本设定,限制了模型在无标注场景的实用性
3、当前这个问题的研究现状
现有方法分手工设计提示(依赖经验、通用差)、基于下游数据的提示调优(脱离零样本、泛化弱),另有无监督提示学习(需多样本)、测试时优化(需多测试样本)等,但是他们都不能满足单样本进行零样本调优这种情况。
4、本文提出了什么算法
提出了TPT,零样本场景下仅用单个测试样本实时优化文本提示。在图像分类任务中添加了置信度过滤高熵样本机制,在视觉推理任务联合优化提示与二进制类别 token
5、为什么这个算法是合理且有效的
TPT算法仅优化了文本提示避免破坏预训练特征,对增强视图进行一致性约束和置信度去噪确保提示能够适配单样本。
6、文章做了什么实验来验证这个算法
在自然分布偏移鲁棒性(4 个 ImageNet 变体)、跨数据集泛化(10 个细分类数据集)、视觉推理(Bongard-HOI)上进行实验,还通过消融实验验证参数组选择和置信度选择的有效性
7、为什么这些实验是合理的
选用数据集多样且符号不同场景需求,基线使用主流经典方法CLIP、COOP等,消融实验也较为完善。
8、作者还做了什么论述来证明这个算法的有效性
通过公式明确 TPT 优化目标与 CLIP 的适配性,对比传统方法突出其零样本优势,还通过消融实验验证文本提示是最优优化参数组
9、这个算法有哪些不足或待改进的地方
测试时需 1 步反向传播且生成多增强视图,增加推理内存成本。同时适配任务有限,需要我们继续探索在新的下游任务中的表现。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)