LLaMA模型结构与注意力机制优化
大语言模型(LLMs)如GPT系列和LLaMA的快速发展,推动了人工智能技术的革新。这些模型主要基于Transformer架构,通过自回归方式处理自然语言,展现出强大的能力。
在人工智能领域,大语言模型(LLMs)的崛起掀起了技术变革的浪潮。从 GPT 系列的惊艳亮相,到众多开源模型的百花齐放,LLMs 的发展日新月异。今天,我们就深入剖析大语言模型的结构细节,以及为提升其性能而诞生的注意力机制优化技术,探索这一前沿领域的奥秘。
当前,绝大多数大语言模型都借鉴了 GPT 的架构思路,采用基于 Transformer 仅由解码器组成的网络结构,通过自回归方式构建语言模型。这种架构在处理自然语言时展现出强大的能力,但不同模型在位置编码、层归一化位置、激活函数等细节上各有千秋。
一、LLaMA 模型结构
LLaMA,是元宇宙平台公司(Meta)公开发布的产品,Meta创始人扎克伯格。2023年7月,Meta公司发布了人工智能模型LLaMA2的开源商用版本,意味着大模型应用进入了“免费时代”,初创公司也能够以低廉的价格来创建类似ChatGPT这样的聊天机器人。2025年4月5日,Meta发布最新AI大模型Llama 4。
LLaMA 模型采用的 Transformer 结构与 GPT-2 类似,但在多个关键细节上进行了创新:
1、RMSNorm 归一化函数
为了使模型训练过程更加稳定,GPT-2 相较于GPT 引入了前置层归一化方法,将第一个层归一化移动到多头自注意力层之前,将第二个层归一化移动到全连接层之前。同时,残差连接的位置调整到多头自注意力层与全连接层之后。层归一化中也采用了RMSNorm 归一化函数[49]。针对输入向量a,RMSNorm 函数计算公式如下:
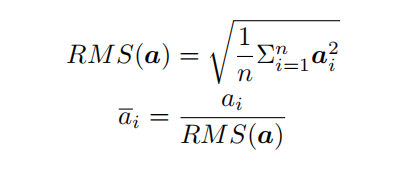
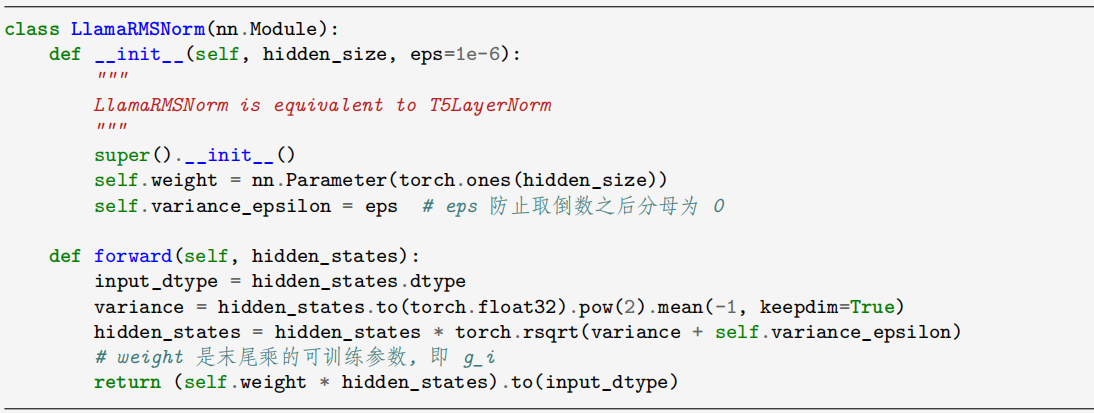 在代码实现中,LlamaRMSNorm 类继承自 nn.Module,通过定义 weight 参数和前向传播函数完成归一化操作。
在代码实现中,LlamaRMSNorm 类继承自 nn.Module,通过定义 weight 参数和前向传播函数完成归一化操作。
2、SwiGLU 激活函数
SwiGLU 激活函数由 Shazeer 提出,在 PaLM 等模型中应用广泛且效果优异,相比 ReLU 函数在多数评测中都有显著提升。LLaMA 的全连接层采用带有 SwiGLU 激活函数的 FFN(Position-wise Feed-Forward Network),计算公式为
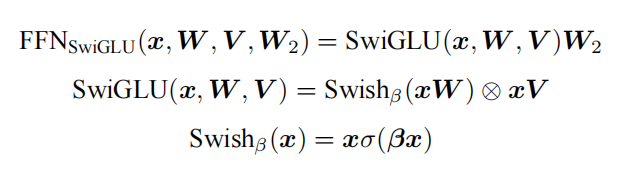
3、RoPE 位置嵌入
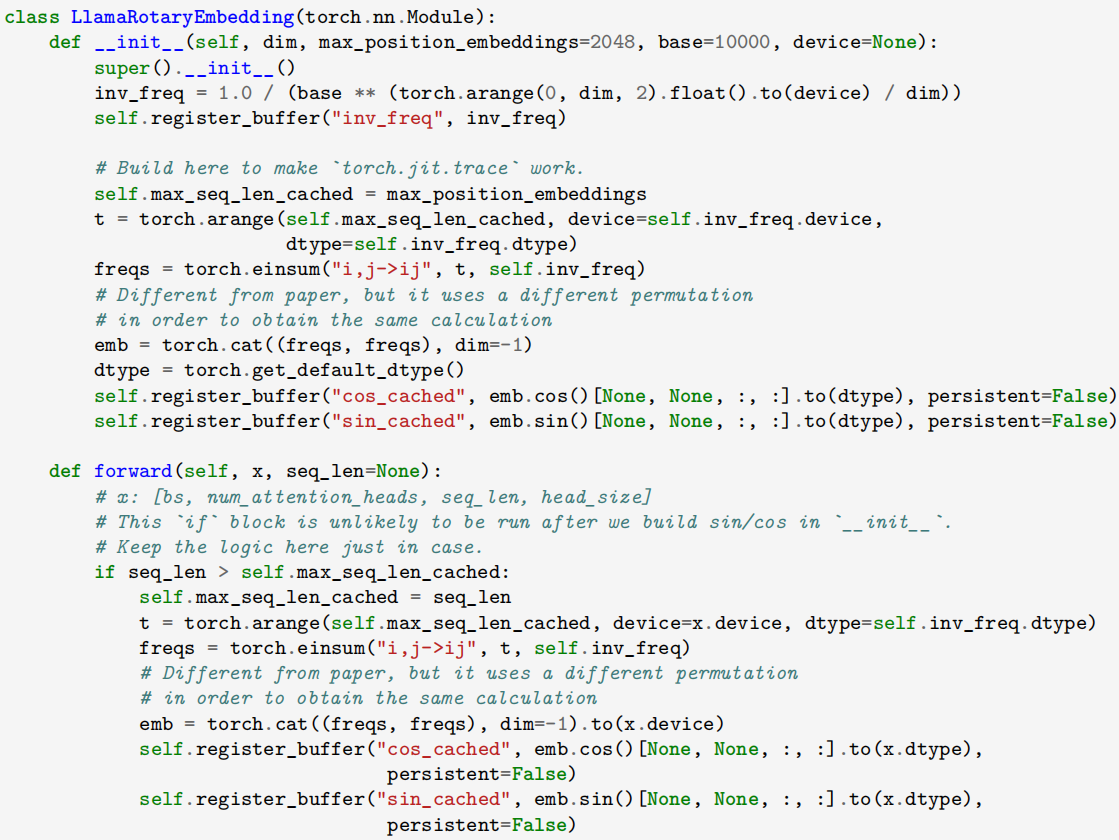
LLaMA 用旋转位置嵌入(RoPE)替代传统绝对位置编码。RoPE 借助复数思想,通过特定运算给 q, k 添加绝对位置信息,最终得到二维情况下用复数表示的 RoPE,还可用矩阵形式表示。由于矩阵具有稀疏性,可利用逐位相乘操作提升计算速度。代码中通过一系列函数实现了 RoPE 位置嵌入的计算和应用。

4、模型整体框架
基于上述创新设计,LLaMA 构建了解码器层。不同规模的 LLaMA 模型使用的超参数不同

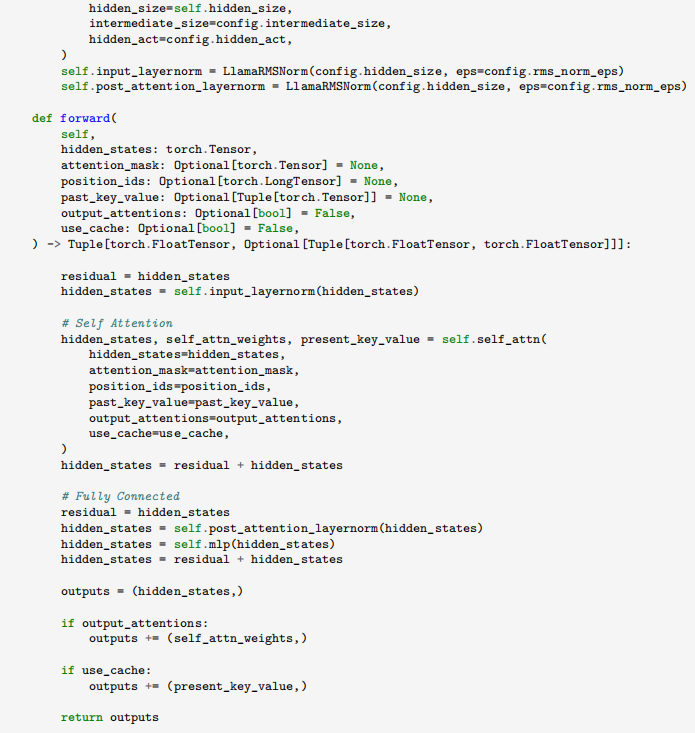
通过 LlamaDecoderLayer 类定义了模型的前向传播过程,包含自注意力模块和全连接层等关键组件。
二、注意力机制优化
Transformer 结构中,自注意力机制的时间和存储复杂度与序列长度的平方相关,这使得其在计算时大量占用计算设备内存并消耗计算资源。为解决这一问题,研究人员从不同角度提出了多种优化方法。
1、稀疏注意力机制
研究发现,一些训练好的 Transformer 注意力矩阵是稀疏的,基于此诞生了稀疏注意力机制。这种机制通过限制 Query - Key 对的数量来降低计算复杂度,可分为基于位置和基于内容信息两类:
a、基于位置的稀疏注意力机制:包含全局注意力、带状注意力、膨胀注意力、随机注意力、局部块注意力这五种基本类型,现有模型多采用这些类型的复合模式。
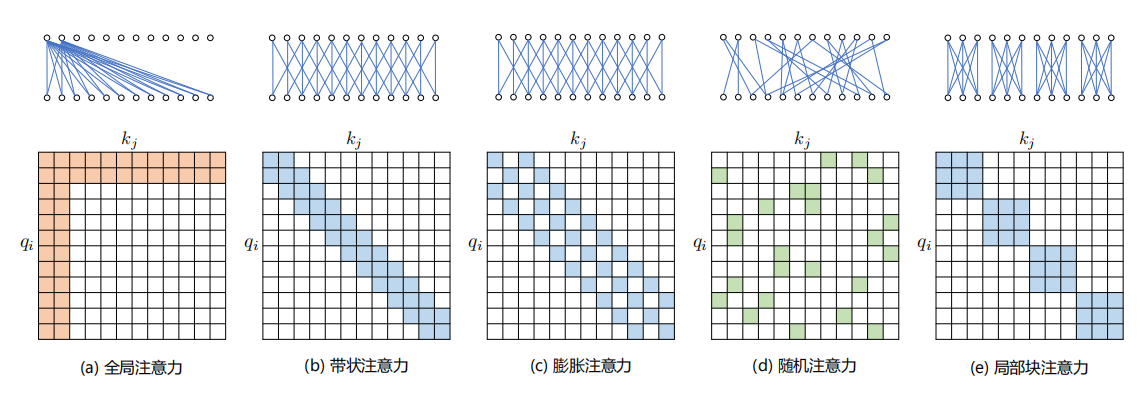
b、基于内容的稀疏注意力机制:根据输入数据创建稀疏注意力。例如,Routing Transformer 采用 K - means 聚类方法,让 Query 只与相同簇下的 Key 交互;Reformer 使用局部敏感哈希(LSH)函数对 Query 和 Key 进行哈希计算,划分到同一桶内的 Query 和 Key 才会交互。
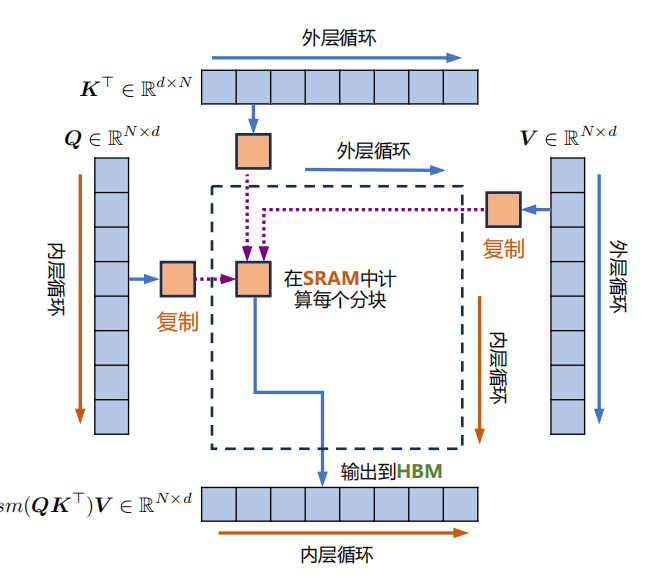
2、FlashAttention(利用硬件特性加速)
NVIDIA GPU 的显存分为多种类型,全局内存和本地内存容量大但访问速度受限,共享内存和寄存器内存速度快但容量小。传统自注意力机制在 GPU 计算时,需引入中间矩阵 S 和 P 并存储到全局内存,这会大量占用显存带宽,导致计算效率受全局内存访问的制约。NVIDIA GPU 的整体内存结构图如下:
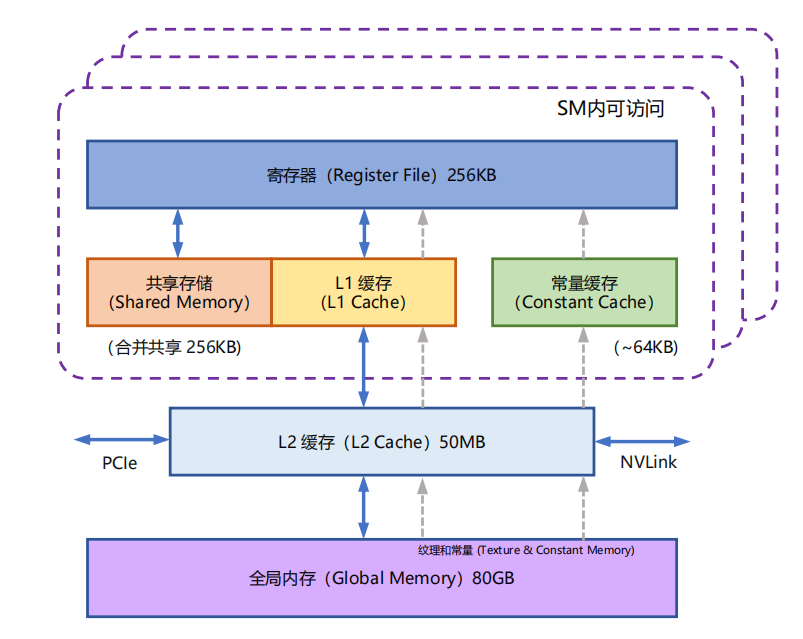
FlashAttention 则充分利用 GPU 硬件特性,尽可能避免从全局内存读取或写入注意力矩阵。它通过分块写入、存储 Softmax 归一化因子等方式,减少全局内存消耗,虽然重新计算增加了 FLOP,但整体运行速度更快且内存使用更少。
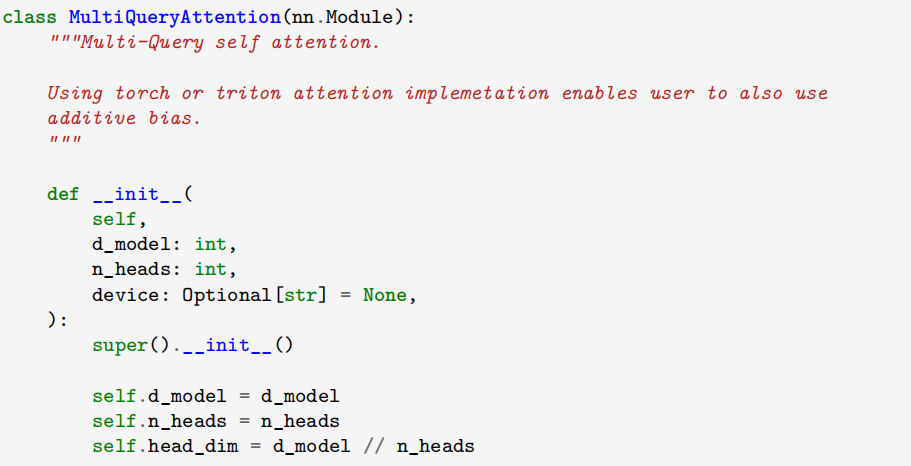
3、多查询注意力(显存优化的新方向)
多查询注意力是多头注意力的变体,不同注意力头共享键和值的集合,每个头仅保留一份查询参数,大幅减少了显存占用,提升了效率。一些模型如 Falcon、SantaCoder、StarCoder 等都采用了这一机制。通过对已训练好的模型进行微调,仅需约 5% 的原始训练数据量,就能让模型支持多查询注意力。
总结与展望
大语言模型的发展正处于高速增长阶段,从模型架构的创新到注意力机制的优化,每一步都凝聚着研究人员的智慧。LLaMA 模型的出现为开源大语言模型的发展提供了重要参考,其独特的设计在多个方面提升了模型性能。而注意力机制的优化方法,如稀疏注意力、FlashAttention 和多查询注意力等,为解决大语言模型计算资源瓶颈问题提供了有效途径。
未来,随着技术的不断进步,我们有望看到更多高效、强大的大语言模型诞生。在探索模型架构和优化技术的道路上,研究人员将继续面临挑战,但也将迎来更多创新机遇,让我们拭目以待大语言模型领域的下一次突破。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)