DeepSeek在AutoDL私有化部署
摘要 本文介绍了如何在GPU实例上部署和运行DeepSeek-R1-Distill-Qwen-7B大语言模型。首先需租用配备24G显存的NVIDIA 4090 GPU实例,安装PyTorch 2.5.1框架。通过modelscope库下载模型后,使用AutoModelForCausalLM和AutoTokenizer加载模型,并提供了调用示例代码。该示例展示了如何构建对话提示,生成2000个tok
·
模型下载
-
先租到一台 GPU 实例 →
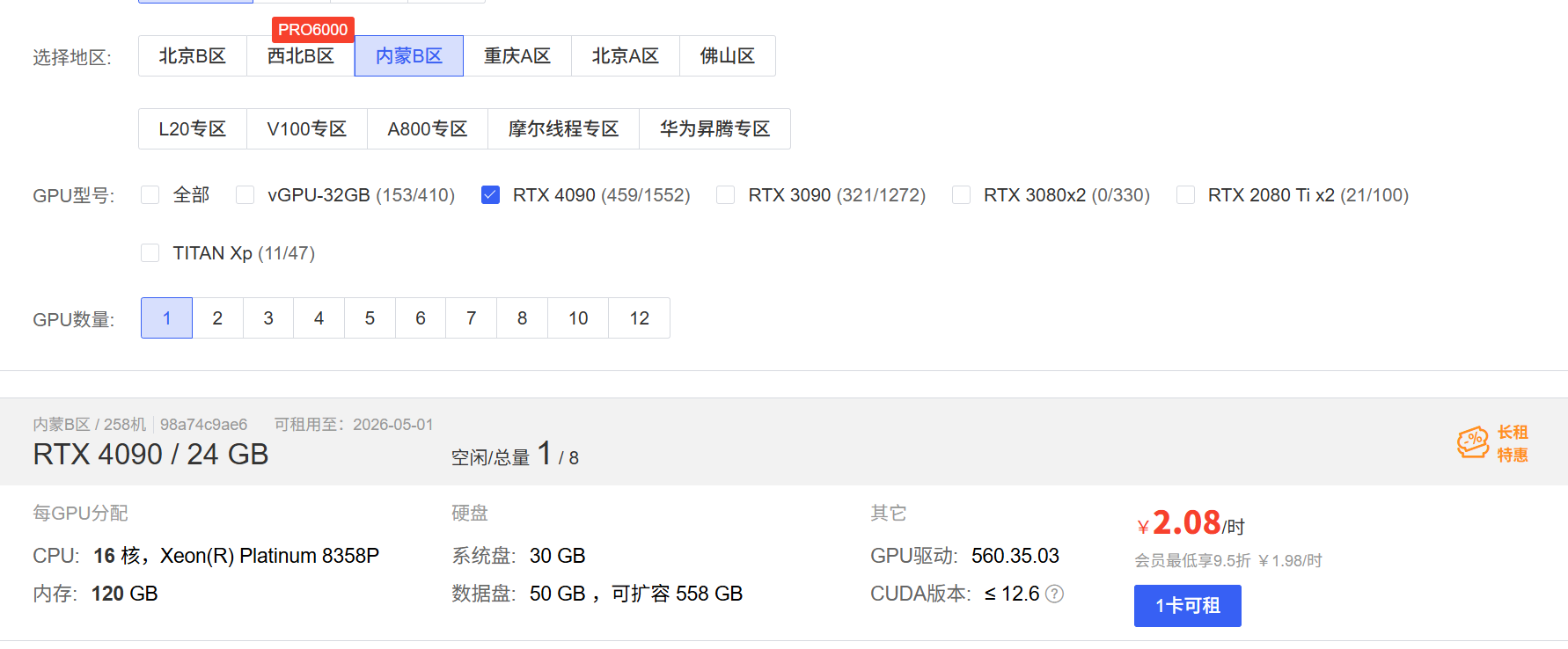
选择4090,24G显卡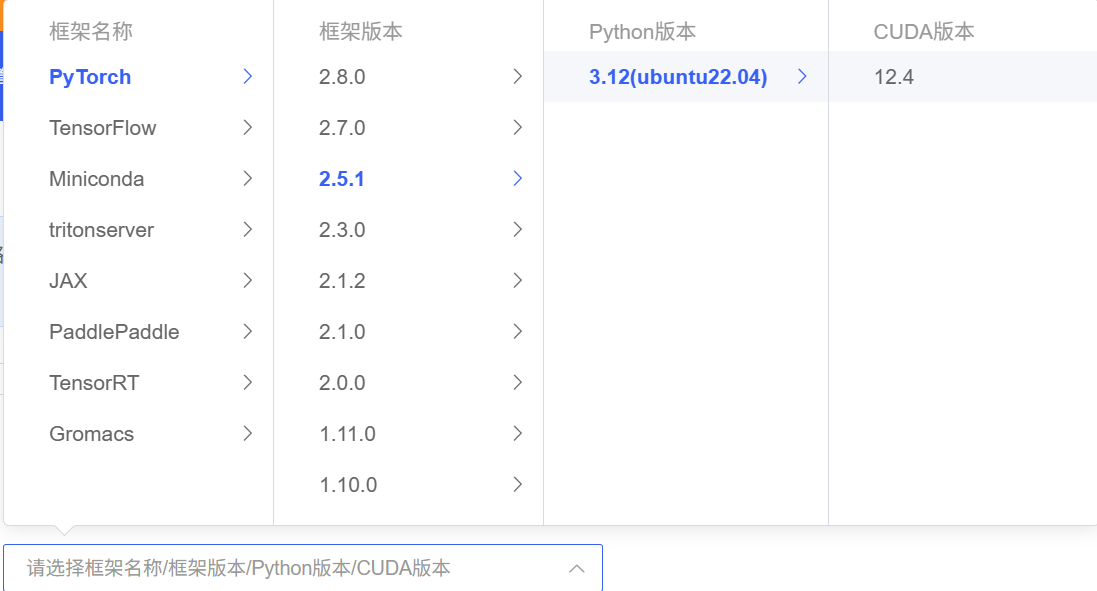
选择pytorch版本号2.5.1 -
把 DeepSeek 模型拉下来 →
安装modelscope
pip install modelscope
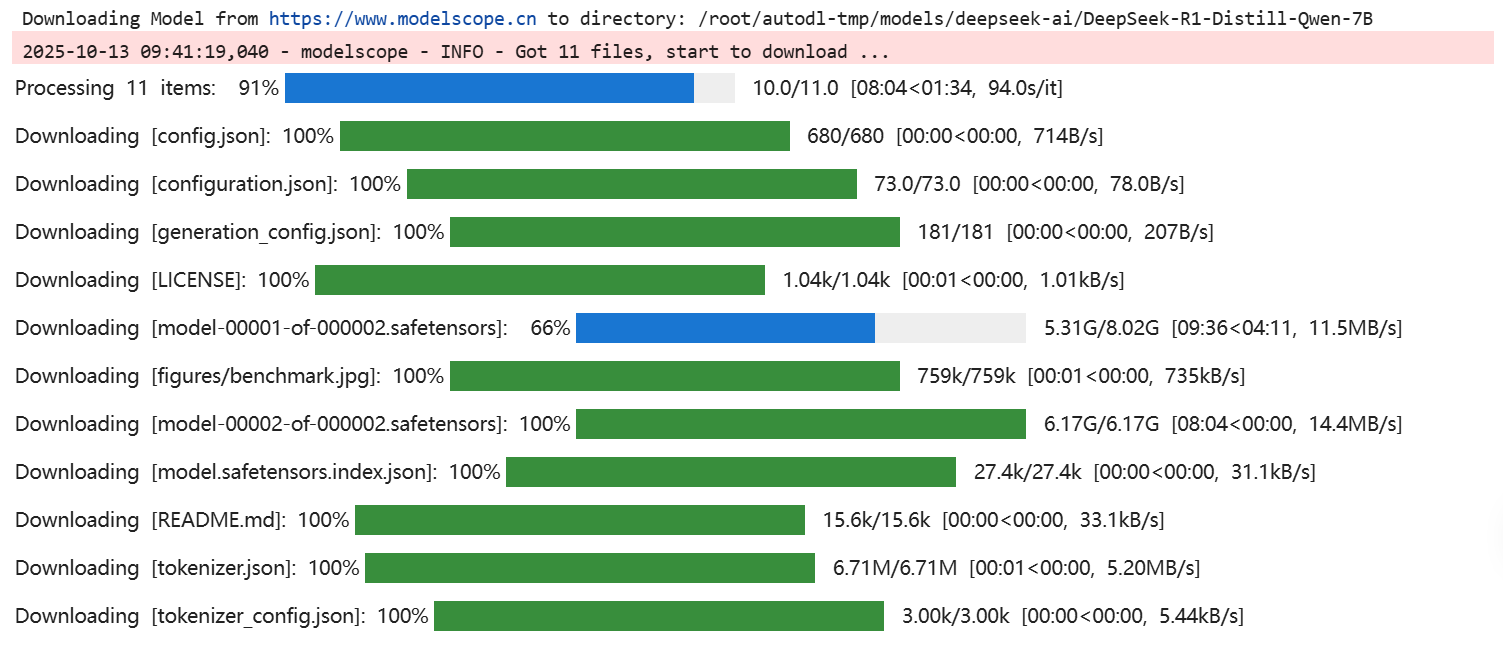
# 模型下载
from modelscope import snapshot_download
snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', cache_dir="/root/autodl-tmp/models")
3. 调用示例
#!/usr/bin/env python
# coding: utf-8
# In[1]:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "/root/autodl-tmp/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="cuda" # auto
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "帮我写一个快排查找法"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=2000
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
结果:
嗯,用户让我帮他写一个二分查找法。首先,我得想想二分查找的基本原理。二分查找,也叫折半查找,它在有序数组中快速定位目标值的位置,时间复杂度是O(log n),效率很高。那用户可能需要的是Python代码,或者具体的应用场景?
用户可能不太清楚二分查找的步骤,或者想用它来解决某个问题。也许他正在学习算法,或者遇到了需要高效查找的问题。所以,我应该详细地解释二分查找的步骤,并提供一个Python实现的示例。
首先,我得确保数组是有序的,因为二分查找只能在有序数组中使用。然后,初始化两个指针,left和right,分别指向数组的开头和结尾。接着,计算中间的位置mid,比较目标值和数组[mid]的值。如果目标值小于数组[mid],就调整right指针;否则,调整left指针。重复这个过程,直到找到目标值或者确定其不存在。
我应该用一个例子来说明,比如查找数字5在数组中的位置。这样用户更容易理解。同时,代码要清晰,注释也要到位,方便用户理解每一步的作用。
另外,我得考虑边界条件,比如数组为空的情况,或者目标值在数组最左或最右的情况。这些情况都需要在代码中处理,避免运行时错误。
最后,我应该总结一下这种方法的时间复杂度和空间复杂度,以及它的适用场景,这样用户能更好地理解什么时候使用这种方法,以及它的优缺点。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)