AniTalker本地部署教程 ——从单张肖像到动态对话,重新定义虚拟交互!
AniTalker 由上海交通大学 X-LANCE 实验室与思必驰 AI Speech 联合开发,能够将静态肖像照片转化为动态的数字化身,并根据语音指令生成自然流畅的交谈和表情变化。这一功能突破了传统数字人技术受限于预设动作模板的局限,使得生成的动画效果更加逼真和吸引人。:自监督学习与动态解耦身份与运动解耦技术:通过分离身份编码器与运动编码器,确保面部动态(如表情、头部动作)与人物身份无关,避免生
一、模型介绍
AniTalker 由上海交通大学 X-LANCE 实验室与思必驰 AI Speech 联合开发,能够将静态肖像照片转化为动态的数字化身,并根据语音指令生成自然流畅的交谈和表情变化。这一功能突破了传统数字人技术受限于预设动作模板的局限,使得生成的动画效果更加逼真和吸引人。
技术核心:自监督学习与动态解耦
-
身份与运动解耦技术:通过分离身份编码器与运动编码器,确保面部动态(如表情、头部动作)与人物身份无关,避免生成动画时出现身份信息干扰。
-
自监督学习策略:利用视频帧重建与互信息最小化,从无标注数据中学习通用运动表示,显著降低对标记数据的依赖1519。
-
多模态控制:支持音频驱动(Hubert或MFCC特征)、头部姿态参数(偏航、俯仰、翻滚角)及面部位置/缩放比例控制,实现高度可控的生成效果。
同时,AniTalker 还具有以下功能亮点:
-
口型同步与表情捕捉:不仅实现精准唇形匹配,还能生成眨眼、微笑等非言语微表情,增强真实感。
-
长视频支持:可生成超过3分钟的连续动画,适用于虚拟主播、教育培训等场景。
-
多语言适配:虽以英语训练为主,但通过扩展中文Hubert模型,已支持中文语音驱动。
二、部署流程
环境推荐配置
系统:Ubuntu22.04,
显卡:4090,
显存:24G,cuda11.8
(在部署完成进行对话时一张卡回答得很慢,建议使用两张)
1. 基础环境
查看系统是否有Miniconda3的虚拟环境
conda -V
如果输入命令没有显示Conda版本号,则需要安装。

2.更新系统命令
输入下列命令将系统更新及系统下载
apt-get update && apt-get install ffmpeg libsm6 libxext6 -y

3.创建虚拟环境
创建名称为“AniTalker”的虚拟环境并激活
conda create -n anitalker python==3.9.0 -y
conda activate anitalker


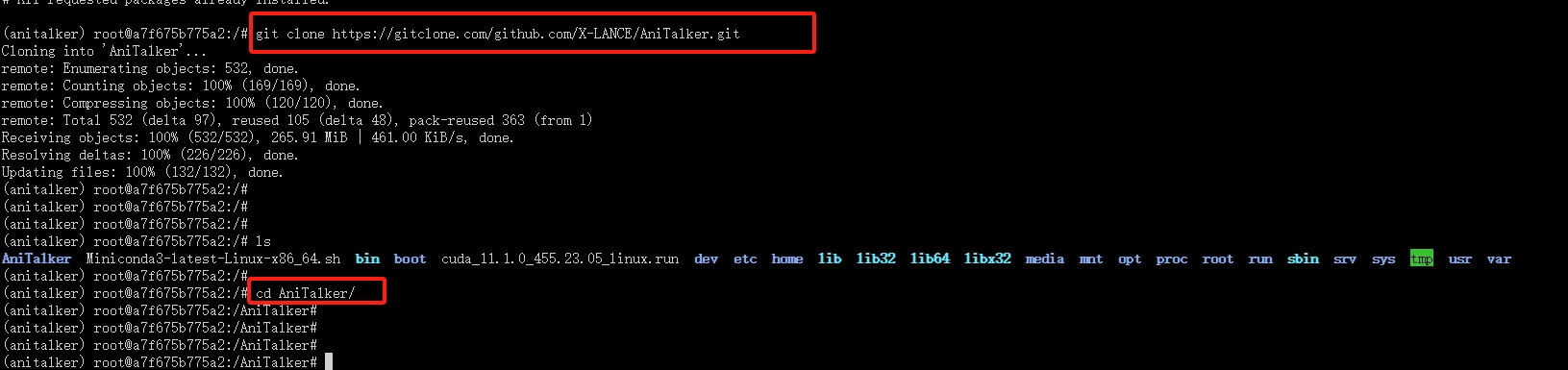
4.下载模型
输入下列命令下载AniTalker模型同时进入项目中
git clone https://gitclone.com/github.com/X-LANCE/AniTalker.git
cd AniTalker
5.下载模型依赖包
输入下列命令:
pip install -r requirements.txt
建议使用这行命令,提升下载速度:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
直到“Successfully”出现,下载才结束:
三、网页演示
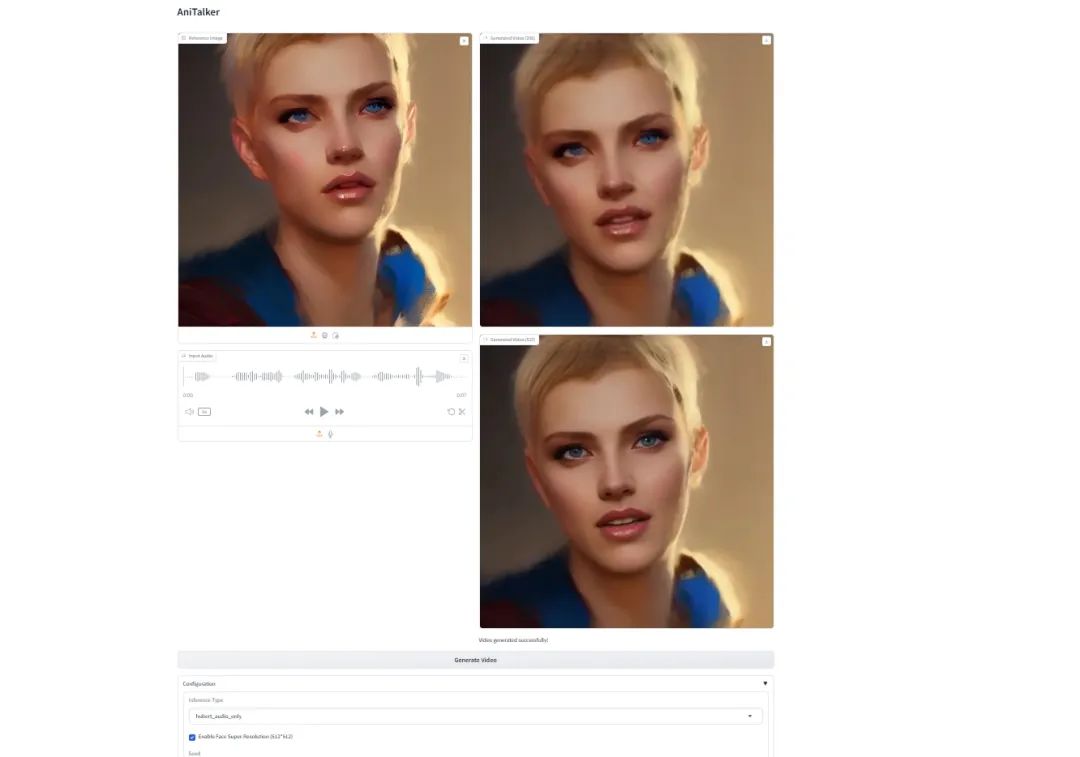
在本地运行graio应用程序,使用下列命令运行项目呈现模型的成功界面
python ./code/webgui.py

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献104条内容
已为社区贡献104条内容

所有评论(0)