啸叫抑制(AFS)从算法仿真到工程源码实现-第六节-陷波法
陷波法去啸叫
一、概述
根据啸叫频点检测算法,计算每个频点的特征【峰值阈值功率比(Peak-to-Threshold Power Raio, PTPR),峰值均值功率比(Peak-to-Average Power Raio, PAPR)、峰值邻近功率比(Peak-to-Neighboring Power Raio, PNPR)、峰值谐波功率比(Peak-to-Harmonics Power Raio, PHPR)、帧间峰值保持度(Interframe Peak Magnitude Persistence, IPMP)、帧间幅度斜率偏差度(Interframe Magnitude Slope Deviation, IMSD)】,找到啸叫频点,并对相应的频点幅值进行抑制。主要有几个问题:(1)啸叫频点的数量是个问题,这个不好把握,过多对语音损伤比较严重,极限情况下语音全部被抑制掉,过少又漏掉一些啸叫点,一些系统设计为3个固定的频点加上3个自适应的频点。(2)啸叫频点检测的正确性问题,有误检和漏检的情况。(3)实时性也是个问题,我们输入处理一帧是160个点,但是FFT必须是128个点,这样就需要拼帧,拼帧会带来延迟的问题,我们的解决方案是在频域检测频点,在时域处理,这样可以解决实时性的问题。(4)频点的精度问题,我们处理频点的精度一般为8000/128=62.5Hz,这样可能检测到的频点和真实啸叫频点不一致。
二、算法仿真
2.1 算法流程图
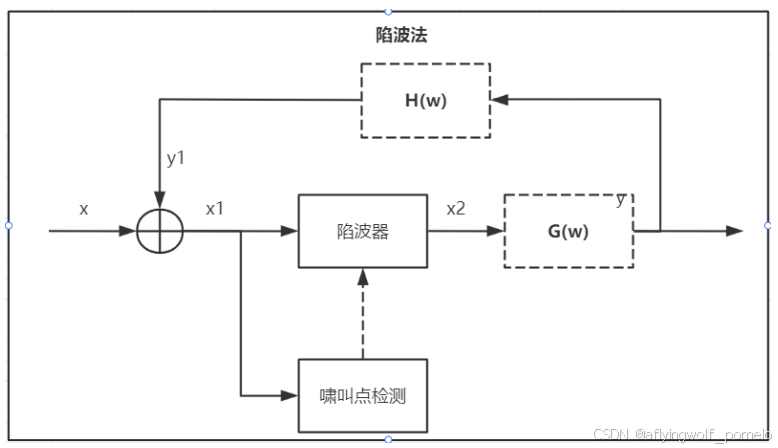
2.2 啸叫频点检测仿真
#!/usr/bin/python
"""
Functions for howling frequency detection.
"""
from __future__ import division
import numpy as np
def papr(frame, threshold):
"""Peak-to-Avarage Power Ratio (PAPR)
Returns all frequency indices where power is greater than avarage power + threshold,
which are possible candidates where howling occurs.
Args:
frame: Spectrum of one frame.
threshold: Power threshold value in dB.
The returned candidates should have power greater than average power + threshold.
Returns:
A list of selected frequncy indices.
A list of PAPR value for every freqency bin of this frame.
"""
power = np.abs(frame)**2
papr = np.zeros(len(power))
avarage = np.mean(power)
ret = []
for i in range(len(frame)):
papr[i] = 10*np.log10(power[i]/avarage)
if (papr[i] > threshold):
ret.append(i)
return ret, papr
def ptpr(frame, threshold):
"""Peak-to-Threshold Power Ratio (PTPR)
Returns all frequency indices where power is greater than threshold,
which are possible candidates where howling occurs.
Args:
frame: Spectrum of one frame.
threshold: Power threshold value in dB.
Returns:
A list of selected frequncy indices.
"""
power = np.abs(frame)**2
ret = []
for i in range(len(frame)):
if (10*np.log10(power[i]) > threshold):
ret.append(i)
return ret
#def phpr(frame, threshold):
"""Peak-to-Harmonic Power Ratio (PHPR)
To-Do
Args:
Returns:
"""
def pnpr(frame, threshold):
"""Peak-to-Neighboring Power Ratio (PNPR)
Returns all frequency indices of power peaks,
which are greater than neighboring frequency bins by a threshold.
Args:
frame: Spectrum of one frame.
threshold: Power threshold value in dB.
Returns:
A list of selected frequncy indices.
"""
power = frame**2
ret = []
for i in range(5, len(frame)-5):
if (10*np.log10(power[i]/power[i-4]) > threshold
and 10*np.log10(power[i]/power[i-5]) > threshold
and 10*np.log10(power[i]/power[i+4]) > threshold
and 10*np.log10(power[i]/power[i+5]) > threshold ):
ret.append(i)
return ret
def ipmp(candidates, index):
"""Inerframe Peak Magnitude Persistence (IPMP)
Temporal howling detection criteria. Candidate should meet criteria
in more than 3 frames out of 5 continuous frames.
Args:
candidates: nFreqs X nFrames
candidates[f][t] = 1 means a candidate at frequency[f] at frame[t]
index: Current frame index.
Returns:
A list of selected frequncy indices.
"""
accu = np.zeros(candidates.shape[0])
if(index == 2):
accu = np.sum(candidates[:, :index+1], axis=1)
elif (index == 3):
accu = np.sum(candidates[:, :index+1], axis=1)
else:
accu = np.sum(candidates[:, index-4:index+1], axis=1)
#ipmp = np.squeeze(np.argwhere(accu >=3))
ipmp = [idx for idx, val in enumerate(accu) if val >= 3]
return ipmp
#def imsd(frame, threshold):
def screening(frame, candidates):
"""
Screen the candidates. Only one frequency in neighboring several frequencies is needed
Args:
frame: Current frame spectrum.
candidates: nFreqs X nFrames
candidates[f][t] = 1 means a candidate at frequency[f] at frame[t]
Returns:
A list of selected frequncy indices.
"""
ret = []
for c in candidates:
if len(ret)==0:
ret.append(c)
elif ret[len(ret)-1] > c-3 :
if abs(frame[ret[len(ret)-1]]) < abs(frame[c]):
ret[len(ret)-1] = c
else:
ret.append(c)
return ret
2.3 啸叫抑制仿真
#!/usr/bin/python
from __future__ import division
# import
import numpy as np
from scipy import signal
import matplotlib.pyplot as plt
import soundfile as sf
import pyHowling
def howling_detect(frame, win, nFFT, Slen, candidates, frame_id):
insign = win * frame
spec = np.fft.fft(insign, nFFT, axis=0)
#========== Howling Detection Stage =====================#
ptpr_idx = pyHowling.ptpr(spec[:Slen], 10)
papr_idx, papr = pyHowling.papr(spec[:Slen], 10)
pnpr_idx = pyHowling.pnpr(spec[:Slen], 15)
intersec_idx = np.intersect1d(ptpr_idx, np.intersect1d(papr_idx,pnpr_idx))
#print("papr:",papr_idx)
#print("pnpr:",pnpr_idx)
#print("intersection:", intersec_idx)
for idx in intersec_idx:
candidates[idx][frame_id] = 1
ipmp = pyHowling.ipmp(candidates, frame_id)
#print("ipmp:",ipmp)
result = pyHowling.screening(spec, ipmp)
#print("result:", result)
return result
def main():
input_file = "test/LDC93S6A.wav"
howling_file = "test/added_howling.wav"
output_file = "test/removed_howling.wav"
#load clean speech file
x, Srate = sf.read(input_file)
#pre design a room impulse response
rir = np.loadtxt('test/path.txt', delimiter='\t')
plt.figure()
plt.plot(rir)
#G : gain from mic to speaker
G = 0.2
# ====== set STFT parameters ========
interval = 0.01 #frame interval = 0.02s
Slen = int(np.floor(interval * Srate))
if Slen % 2 == 1:
Slen = Slen + 1
PERC = 50 #window overlap in percent of frame size
len1 = int(np.floor(Slen * PERC / 100))
len2 = int(Slen - len1)
nFFT = 2 * Slen
freqs = np.linspace(0, Srate, nFFT)
Nframes = int(np.floor(len(x) / len2) - np.floor(Slen / len2))
#Hanning window for stft
win = np.hanning(Slen)
win = win * len2 / np.sum(win)
plt.figure()
plt.subplot(2,1,1)
plt.plot(x)
plt.xlim(0, len(x))
plt.subplot(2,1,2)
plt.specgram(x, NFFT=nFFT, Fs=Srate, noverlap=len2, cmap='jet')
plt.ylim((0, 5000))
plt.ylabel("Frquency (Hz)")
plt.xlabel("Time (s)")
#simulate acoustic feekback, point-by-point
# _______________ _______________
# clean speech: x --> mic: x1 --> | Internal Gain | --> x2 -- > speaker : y--> | Room Impulse |
# ^ |______G________| |____Response___|
# | |
# ----------------------<-----y1--------------------------------V
#
N = min(2000, len(rir)) #limit room impulse response length
x2 = np.zeros(N) #buffer N samples of speaker output to generate acoustic feedback
y = np.zeros(len(x)) #save speaker output to y
y1 = 0.0 #init as 0
for i in range(len(x)):
x1 = x[i] + y1
y[i] = G*x1
y[i] = min(2, y[i]) #amplitude clipping
y[i] = max(-2, y[i])
x2[1:] = x2[:N-1]
x2[0] = y[i]
y1 = np.dot(x2, rir[:N])
sf.write(howling_file, y, Srate)
plt.figure()
plt.subplot(2,1,1)
plt.plot(y)
plt.xlim((0, len(y)))
plt.subplot(2,1,2)
plt.specgram(y, NFFT=nFFT, Fs=Srate, noverlap=len2, cmap='jet')
plt.ylim((0, 5000))
plt.ylabel("Frquency (Hz)")
plt.xlabel("Time (s)")
#=============================Notch Filtering =======================================================
# ___________________
# -------> | Howling Detection | ______
# | |___________________| |
# | |
# | _______________ _______V______
# clean speech: x --> mic: x1 --> | Internal Gain |-x2--> | Notch Filter | --> speaker : y
# ^ |______G________| |_____IIR______| |
# | |
# | _______________ |
# <-----------------y1--| Room Impulse |____________________ v
# |____Response___|
#
b = [1.0, 0 ,0]
a = [0, 0, 0]
N = min(2000, len(rir)) #limit room impulse response length
x2 = np.zeros(100) #
x3 = np.zeros(N) #buffer N samples of speaker output to generate acoustic feedback
y = np.zeros(len(x)) #save speaker output to y
y1 = 0.0 #init as 0
current_frame = np.zeros(Slen)
pos = 0
candidates = np.zeros([Slen, Nframes+1], dtype='int')
frame_id = 0
notch_freqs = []
for i in range(len(x)):
x1 = x[i] + y1
current_frame[pos] = x1
pos = pos + 1
if pos==Slen:
#update notch filter frame by frame
freq_ids = howling_detect(current_frame, win, nFFT, Slen, candidates, frame_id)
#freq_ids = [46]
if(len(freq_ids)>0 and (len(freq_ids)!=len(notch_freqs) or not np.all(np.equal(notch_freqs, freqs[freq_ids])))):
notch_freqs = freqs[freq_ids]
sos = np.zeros([len(notch_freqs), 6])
for i in range(len(notch_freqs)):
b0, a0 = signal.iirnotch(notch_freqs[i], 1, Srate)
sos[i,:] = np.append(b0,a0)
b, a = signal.sos2tf(sos)
print("frame id: ", frame_id, "/", Nframes, "notch freqs:", notch_freqs)
current_frame[:Slen-len2] = current_frame[len2:] #shift by len2
pos = len2
frame_id = frame_id + 1
x2[1:] = x2[:len(x2)-1]
x2[0] = G*x1
x2[0] = min(2, x2[0]) #amplitude clipping
x2[0] = max(-2, x2[0])
y[i] = np.dot(x2[:len(b)], b) - np.dot(x3[:len(a)-1], a[1:]) #IIR filter
y[i] = min(2, y[i]) #amplitude clipping
y[i] = max(-2, y[i])
x3[1:] = x3[:N-1]
x3[0] = y[i]
y1 = np.dot(x3, rir[:N])
pyHowling.plot_notch_filter(b, a, Srate)
xfinal = y
sf.write(output_file, xfinal, Srate)
plt.figure()
plt.subplot(2,1,1)
plt.plot(xfinal)
plt.xlim((0, len(xfinal)))
plt.subplot(2,1,2)
plt.specgram(xfinal, NFFT=nFFT, Fs=Srate, noverlap=len2, cmap='jet')
plt.ylim((0, 5000))
plt.ylabel("Frquency (Hz)")
plt.xlabel("Time (s)")
plt.show()
main()
2.4 啸叫频点检测工程化
/*
* @author : aflyingwolf
* @date : 2025.3.24
* @file : afs-function.h
*/
#include <math.h>
void afs_evaluate_PTPR(const float *Y, float *PTPR, int len) {
for (short i = 0; i < len; ++i) {
PTPR[i] = 10 * log10f(Y[i] * Y[i]);
}
}
void afs_evaluate_PAPR(const float *Y, float *PAPR, int len) {
float energy = 0;
for (short i = 0; i < len; ++i) {
energy += Y[i] * Y[i];
}
energy /= len;
for (short i = 0; i < len; ++i) {
PAPR[i] = 10 * log10f(Y[i] * Y[i] / energy);
}
}
void afs_evaluate_PNPR(const float *Y, float *PNPR, int len) {
static const int m[10] = {1, -1, 2, -2, 3, -3, 4, -4, 5, -5};
for (short i = 0; i < len; ++i) {
PNPR[i] = 0;
int k = 0;
for (short j = 0, i2; j < 10; ++j) {
i2 = i + m[j];
if (i2 < len && i2 > 0) {
k++;
PNPR[i] += 10 * log10f(Y[i] * Y[i] / Y[i2] / Y[i2]);
}
}
PNPR[i] /= k;
}
}
void afs_evaluate_PHPR(const float *Y, float *PHPR, int len) {
for (short i = 0, i2; i < len; ++i) {
PHPR[i] = 100;
i2 = 2 * i; // m = 2
if (i2 < len) {
PHPR[i] = 10 * log10f(Y[i] * Y[i] / Y[i2] / Y[i2]);
}
i2 = 3 * i; // m = 3
if (i2 < len) {
float phprc = 10 * log10f(Y[i] * Y[i] / Y[i2] / Y[i2]);
if (phprc < PHPR[i]) {
PHPR[i] = phprc;
}
}
}
}
void afs_evaluate_IMSD(const float *Y_buf, float *IMSD, int len, int num) {
const short Q_m = num - 1,
P = 1,
t = num - 1;
float fst_sum, snd_sum;
for (short i = 0; i < len; ++i) {
IMSD[i] = 0;
fst_sum = 0;
for (short j = 0; j < Q_m; ++j) {
fst_sum += 20 * (log10f(Y_buf[(t - j*P) * len + i])
- log10f(Y_buf[(t - Q_m*P) * len + i])) / (Q_m - j);
}
for (short m = 1; m < Q_m; ++m) {
snd_sum = 0;
for (short j = 0; j < m; ++j) {
snd_sum += 20 * (log10f(Y_buf[(t - j*P) * len + i])
- log10f(Y_buf[(t - m*P) * len + i])) / (m - j);
}
IMSD[i] += fst_sum / Q_m - snd_sum / m;
}
IMSD[i] /= (Q_m - 1);
}
}
void afs_evaluate_IMSD2(const float *Y_buf, float *IMSD, int len, int num) {
const short Q_m = num;
for (short i = 0; i < len; ++i) {
IMSD[i] = 0;
for (short j = 1; j < Q_m; ++j) {
IMSD[i] += 20 * (log10f(Y_buf[(j) * len + i]) - log10f(Y_buf[(j-1) * len + i]));
}
IMSD[i] /= (Q_m - 1);
}
}
void afs_evaluate_IPMP(const short *Candidates, short *IPMP, int len, int num, float thr) {
for (short i = 0; i < len; ++i) {
int sum = 0;
for (short j = 0; j < num; ++j) {
sum += Candidates[j*len+i];
}
if (sum > thr) {
IPMP[i] = 0;
} else {
IPMP[i] = 1;
}
}
}
2.5 陷波器工程化
/*
* @author : aflyingwolf
* @date : 2025.3.24
* @file : afs-notchfilter.c
*/
#include <math.h>
#include <stdlib.h>
#include "afs-notchfilter.h"
afs_notch_filter* afs_notch_filter_init(int frequency, float qFactor, int sample_rate) {
afs_notch_filter *inst = (afs_notch_filter*)malloc(sizeof(afs_notch_filter));
inst->i_1 = 0;
inst->i_2 = 0;
inst->o_1 = 0;
inst->o_1 = 0;
float w0 = 2.0 * 3.1415926 * frequency / sample_rate;
float alpha = sin(w0) / (2.0 * qFactor);
float b0 = 1.0;
float b1 = -2.0 * cos(w0);
float b2 = 1.0;
float a0 = 1.0 + alpha;
float a1 = -2.0 * cos(w0);
float a2 = 1.0 - alpha;
inst->b0 = b0 / a0;
inst->b1 = b1 / a0;
inst->b2 = b2 / a0;
inst->a1 = a1 / a0;
inst->a2 = a2 / a0;
return inst;
}
int afs_notch_filter_process(afs_notch_filter *handle, float *input, float *output, int num) {
for (int i = 0; i < num; i++) {
float x = handle->b0 * input[i] + handle->b1 * handle->i_1 + handle->b2 * handle->i_2 - handle->a1 * handle->o_1 - handle->a2 * handle->o_2;
handle->i_2 = handle->i_1;
handle->i_1 = input[i];
handle->o_2 = handle->o_1;
handle->o_1 = x;
output[i] = x;
}
return 0;
}
void afs_notch_filter_deinit(afs_notch_filter *handle) {
free(handle);
}
2.6 仿真结果
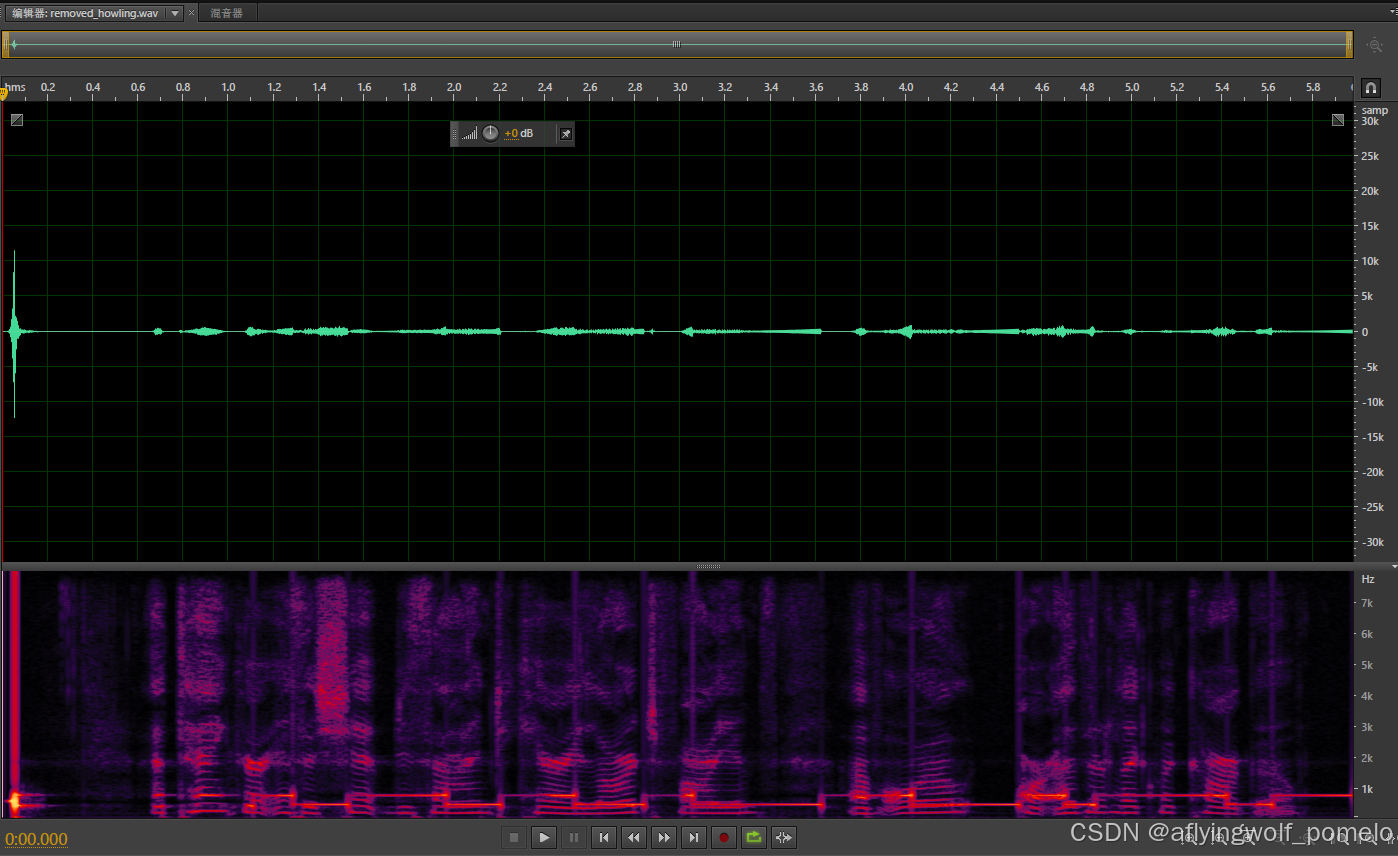
三、总结
根据我们的实践,该方法效果并不好,这一点和调研结果有一些出入。更多资料和代码可以进入 https://t.zsxq.com/qgmoN 。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)