【Apple M1 Mac LangChain环境搭建】
摘要(149字) 针对Apple M1 Mac(macOS 15.4.1)的LangChain开发环境搭建,提出ARM架构优化方案: 环境配置:推荐Miniforge/Miniconda创建原生ARM环境(osx-arm64),解决依赖兼容性问题; 关键调整: 向量库改用FAISS/Annoy替代Scann(缺ARM二进制) 通过--prefer-binary优先安装预编译包 嵌入模型使用Hugg
针对您的 Apple M1 Mac(macOS 15.4.1),以下是优化后的环境搭建指南,特别处理了ARM架构的兼容性问题:
第1步:ARM原生(隔离)环境搭建(Apple Silicon优化)
# 1. 安装Miniforge(替代Miniconda,原生支持M1)
brew install miniforge
conda init zsh # 如果使用zsh,或conda init bash
# 2. 创建ARM原生虚拟环境
CONDA_SUBDIR=osx-arm64 conda create -n langchain-java python=3.10
conda activate langchain-java
# 3. 安装核心库(ARM兼容版本)
pip install \
langchain-core \
langchain-community \
langchain-openai \
tiktoken \
sentence-transformers
# 4. 安装ARM优化的向量库(替代faiss-cpu)
pip install scann annoy
# 5. 安装Java调用依赖(M1专用)
pip install "JPype1>=1.4.1" --no-cache-dir
关键调整说明(解决M1兼容性问题但是好像annoy资源获取不到,继续安装FAISS)
向量库替代方案
:
1.使用scann(Google研发)或annoy(Spotify)替代FAISS,它们在M1上性能更好
安装命令:pip install scann annoy
2.Embedding模型选择
# 使用ARM兼容的本地模型
from langchain_community.embeddings import HuggingFaceEmbeddings
embedding = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
3.Python-Java桥接优化:
// Java代码需添加JVM参数
JPype.startJVM(
"-Xss128m",
"-Djava.library.path=/opt/homebrew/lib" // Homebrew库路径
);
M1性能优化
安装 Apple Metal 加速
conda install -c apple tensorflow-deps -y
pip install --prefer-binary tensorflow-macos tensorflow-metal
验证安装的快速测试
# test_env.py
import platform
import langchain_core
from langchain_community.embeddings import HuggingFaceEmbeddings
print(f"系统架构: {platform.machine()}") # 应显示arm64
print(f"LangChain版本: {langchain_core.__version__}")
# 测试Embedding
embedding = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
print(embedding.embed_query("Hello M1"))
运行命令:python test_env.py,应输出:
系统架构: arm64
LangChain版本: 0.1.0
[-0.023, 0.145, …] # 向量数组
实际结果如下:Error: Download failed on Cask ‘miniforge’ with message: Download failed: https://github.com/conda-forge/miniforge/releases/download/25.3.0-3/Miniforge3-25.3.0-3-MacOSX-arm64.sh
遇到的下载错误是因为 Homebrew 的 miniforge 安装脚本指向的特定版本(25.3.0-3)可能已被更新或移除。以下是针对 Apple M1 Mac 的替代安装方案,完全绕过 Homebrew 直接安装:
1. 手动下载最新版 Miniforge (ARM64原生支持)
curl -LO “https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh”
验证安装
conda --version
# 应输出: conda 24.x.x
conda info | grep platform
# 应显示: platform : osx-arm64
结果
:conda 25.5.1
platform : osx-arm64
Miniforge下载报错 curl: (16) Error in the HTTP2 framing layer
解决方法 1:使用 HTTP/1.1 协议下载(推荐)
# 强制使用 HTTP/1.1 协议
curl -LO --http1.1 "https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh"
# 如果上面失败,尝试使用备用 URL
curl -LO --http1.1 "https://mirrors.tuna.tsinghua.edu.cn/github-release/conda-forge/miniforge/LatestRelease/Miniforge3-MacOSX-arm64.sh"
结果还是失败;所以用替代方案
替代方案:直接使用 Miniconda
如果 Miniforge 安装仍然失败,可以使用官方 Miniconda:
# 下载 Miniconda
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.sh
# 安装
bash Miniconda3-latest-MacOSX-arm64.sh -b -p $HOME/miniconda3
# 初始化
source $HOME/miniconda3/bin/activate
conda init zsh
# 创建环境
conda create -n langchain-java python=3.10 -y
conda activate langchain-java
# 添加 conda-forge 频道
conda config --add channels conda-forge
conda config --set channel_priority strict
# 安装依赖
pip install langchain-core langchain-community sentence-transformers scann annoy jpype1
验证安装
创建 test_install.py:
import platform
import jpype
from langchain_community.embeddings import HuggingFaceEmbeddings
print(f"系统架构: {platform.machine()}")
print(f"Python版本: {platform.python_version()}")
# 测试 JPype
jpype.startJVM()
print(f"JVM版本: {jpype.getJVMVersion()}")
jpype.shutdownJVM()
# 测试 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vector = embeddings.embed_query("测试 Apple M1")
print(f"向量维度: {len(vector)}")
print("安装验证成功!")
运行:
bash
python test_install.py
预期输出:
系统架构: arm64
Python版本: 3.10.18
JVM版本: (17, 0, 9)
向量维度: 384
安装验证成功!
这时回可能出现错误向量库找不到,报错
pip install scann annoy --prefer-binary
ERROR: Could not find a version that satisfies the requirement scann (from versions: none)
ERROR: No matching distribution found for scann
**这个错误表明 scann 包没有适用于 macOS ARM64 架构的预编译二进制版本。别担心,我们可以通过替代方案解决这个问题。以下是针对 Apple M1/M2 芯片的完整解决方案:
解决方案:使用替代向量库 + 源码编译
使用 FAISS 的 M1 优化版
# 安装 FAISS(支持 M1)
conda install -c pytorch faiss-cpu -y
# 或者从源码编译
pip install faiss-cpu --no-binary faiss-cpu
完整的 M1 优化环境配置
# 创建并激活环境
conda create -n langchain-java python=3.10 -y
conda activate langchain-java
# 安装核心依赖
pip install --prefer-binary \
langchain-core \
langchain-community \
langchain-openai \
tiktoken \
sentence-transformers \
jpype1 \
hnswlib # 使用 hnswlib 替代 scann
# 安装 Apple Metal 加速
conda install -c apple tensorflow-deps -y
pip install --prefer-binary tensorflow-macos tensorflow-metal
# 安装向量库备选方案
pip install faiss-cpu annoy # annoy 通常可以直接安装
验证环境
创建测试脚本 test_hnsw.py
import hnswlib
import numpy as np
from langchain_community.embeddings import HuggingFaceEmbeddings
# 测试 HNSW
dim = 384
num_elements = 1000
index = hnswlib.Index(space='cosine', dim=dim)
index.init_index(max_elements=num_elements, ef_construction=200, M=16)
# 生成随机数据
data = np.float32(np.random.random((num_elements, dim)))
index.add_items(data)
# 测试查询
labels, distances = index.knn_query(data[0], k=1)
print(f"HNSW 测试通过! 最近邻索引: {labels[0][0]}")
# 测试 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vector = embeddings.embed_query("测试 Apple M1")
print(f"Embedding 向量长度: {len(vector)}")
常见问题解决
Traceback (most recent call last):
File “/Users/xxx/test_hnsw.py”, line 3, in
from langchain_community.embeddings import HuggingFaceEmbeddings
ModuleNotFoundError: No module named ‘langchain_community’
这个错误表明 langchain_community 包没有正确安装。让我们一步步解决这个问题:
完整解决方案:修复 LangChain 安装问题
- 首先确认是否在正确的环境中
# 检查当前环境名称是否显示在提示符前
conda activate langchain-java
echo $CONDA_DEFAULT_ENV # 应该输出 "langchain-java"
- 重新安装 LangChain 核心组件(使用清华镜像源)
# 卸载现有可能损坏的安装
pip uninstall -y langchain-core langchain-community langchain
# 清理缓存
pip cache purge
# 使用国内镜像源重新安装
pip install \
langchain-core \
langchain-community \
langchain \
--prefer-binary \
--no-cache-dir \
-i https://pypi.tuna.tsinghua.edu.cn/simple
- 验证 LangChain 安装
python -c "import langchain_community; print('langchain_community 版本:', langchain_community.__version__)"
完整环境重建(如果问题持续)
# 1. 删除问题环境
conda deactivate
conda remove -n langchain-java --all -y
# 2. 创建新环境
conda create -n langchain-java python=3.10 -y
conda activate langchain-java
# 3. 安装核心依赖
pip install --prefer-binary \
langchain-core \
langchain-community \
sentence-transformers \
hnswlib \
jpype1 \
-i https://pypi.tuna.tsinghua.edu.cn/simple
# 4. 安装向量库
pip install annoy faiss-cpu --prefer-binary
验证 HuggingFace Embeddings
创建 test_embeddings.py:
try:
from langchain_community.embeddings import HuggingFaceEmbeddings
print("✅ langchain_community.embeddings 导入成功")
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vector = embeddings.embed_query("测试文本")
print(f"✅ Embedding 成功生成, 维度: {len(vector)}")
except ImportError as e:
print(f"❌ 导入失败: {e}")
print("请尝试: pip install --force-reinstall langchain-community")
except Exception as e:
print(f"❌ 运行时错误: {e}")
常见问题解决:
python test_embeddings.py
✅ langchain_community.embeddings 导入成功
/Users/xxx/test_embeddings.py:5: LangChainDeprecationWarning: The class HuggingFaceEmbeddings was deprecated in LangChain 0.2.2 and will be removed in 1.0. An updated version of the class exists in the :class:~langchain-huggingface package and should be used instead. To use it run pip install -U :class:~langchain-huggingface and import as from :class:~langchain_huggingface import HuggingFaceEmbeddings``.
embeddings = HuggingFaceEmbeddings(model_name=“sentence-transformers/all-MiniLM-L6-v2”)
❌ 运行时错误: Your currently installed version of Keras is Keras 3, but this is not yet supported in Transformers. Please install the backwards-compatible tf-keras package with pip install tf-keras.
这个警告和错误表明您需要更新您的 Hugging Face Embeddings 使用方式并解决 Keras 依赖问题。让我们一步步解决:
完整解决方案:修复 HuggingFaceEmbeddings 和 Keras 问题
1. 安装必要的依赖包
# 在 langchain-java 环境中操作
conda activate langchain-java
# 安装 tf-keras 和最新 Hugging Face 集成
pip install tf-keras langchain-huggingface --upgrade --force-reinstall
# 确保 transformers 版本兼容
pip install transformers==4.40.0 tensorflow==2.16.1
2. 更新测试脚本 test_embeddings.py
使用新的导入方式:
try:
# 使用新的导入路径
from langchain_huggingface import HuggingFaceEmbeddings
print("✅ langchain_huggingface.HuggingFaceEmbeddings 导入成功")
# 创建 embeddings 实例
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# 测试生成 embedding
vector = embeddings.embed_query("测试文本")
print(f"✅ Embedding 成功生成, 维度: {len(vector)}")
except ImportError as e:
print(f"❌ 导入失败: {e}")
print("请尝试: pip install --force-reinstall langchain-huggingface")
except Exception as e:
print(f"❌ 运行时错误: {e}")
print("请尝试: pip install tf-keras")
解决 Keras 兼容性问题
- 设置环境变量(推荐)
在运行 Python 脚本前设置:
export TF_USE_LEGACY_KERAS=1
python test_embeddings.py
2. 降级 TensorFlow(如果问题持续)
pip uninstall -y tensorflow tensorflow-macos tensorflow-metal
pip install tensorflow-macos==2.15.0 tensorflow-metal==1.1.0
完整的环境重置方案
# 删除现有环境
conda deactivate
conda remove -n langchain-java --all -y
# 创建新环境
conda create -n langchain-java python=3.10 -y
conda activate langchain-java
# 安装兼容性依赖
pip install \
langchain-core \
langchain-community \
langchain-huggingface \
sentence-transformers \
transformers==4.40.0 \
tensorflow-macos==2.15.0 \
tensorflow-metal==1.1.0 \
hnswlib \
jpype1 \
--prefer-binary \
-i https://pypi.tuna.tsinghua.edu.cn/simple
# 设置环境变量
echo "export TF_USE_LEGACY_KERAS=1" >> ~/.zshrc
source ~/.zshrc
使用其他 Embedding 模型(避免问题)
如果 Hugging Face 模型持续有问题,可以考虑使用其他模型:
1. 使用 OpenAI Embeddings
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector = embeddings.embed_query("测试文本")
2. 使用本地 ONNX 模型
from langchain_community.embeddings import ONNXRuntimeEmbeddings
embeddings = ONNXRuntimeEmbeddings(
model_path="all-MiniLM-L6-v2.onnx", # 从 https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2 下载
model_name="all-MiniLM-L6-v2"
)
常见问题解决
1.tf-keras 安装失败:
# 确保安装了最新 pip
pip install --upgrade pip
# 尝试指定版本
pip install tf-keras==2.16.0
Hugging Face 模型下载问题:
2.Hugging Face 模型下载问题:
# 设置镜像源
pip install huggingface_hub
huggingface-cli download --resume-download --cache-dir ./cache sentence-transformers/all-MiniLM-L6-v2
3.Apple Metal 加速问题:
# 禁用 GPU 加速
import tensorflow as tf
tf.config.set_visible_devices([], 'GPU')
完成这些步骤后,您的 Hugging Face Embeddings 应该能够正常工作,不再出现 Keras 版本错误。
这时可能出现该错误
Successfully uninstalled langchain-core-0.3.65
ERROR: pip’s dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
scipy 1.12.0 requires numpy<1.29.0,>=1.22.4, but you have numpy 2.1.3 which is incompatible.
tensorflow-macos 2.16.2 requires tensorflow==2.16.2; platform_system == “Darwin” and platform_machine == “arm64”, but you have tensorflow 2.19.0 which is incompatible.
Successfully
这个依赖冲突问题很常见,让我帮您彻底解决它。问题核心是 numpy 版本过高(2.1.3)与 tensorflow-macos 和 scipy 不兼容。以下是完整的解决方案:
完整解决方案:修复依赖冲突
# 在 langchain-java 环境中操作
conda activate langchain-java
# 1. 先降级 numpy 到兼容版本
pip uninstall -y numpy
pip install numpy==1.26.4 --no-cache-dir # 兼容 TensorFlow 的版本
# 2. 重新安装关键依赖(指定兼容版本)
pip install --upgrade --force-reinstall \
tensorflow-macos==2.16.1 \
tensorflow-metal==1.1.0 \
scipy==1.13.0 \
langchain-core==0.2.0 \
langchain-community==0.2.0 \
langchain-huggingface==0.0.4 \
sentence-transformers==3.0.0 \
transformers==4.40.2 \
hnswlib==0.10.0 \
jpype1==1.5.0 \
--no-cache-dir \
-i https://pypi.tuna.tsinghua.edu.cn/simple
# 3. 验证安装
python -c "import numpy as np; import tensorflow as tf; print(f'numpy: {np.__version__}, tensorflow: {tf.__version__}')"
备选方案:使用 Conda 管理依赖(M1 Mac建议使用Conda)
如果 pip 仍然有问题,改用 conda 管理核心依赖:
# 移除问题环境并重建
conda deactivate
conda remove -n langchain-java --all -y
conda create -n langchain-java python=3.10 -y
conda activate langchain-java
# 通过 conda 安装核心包
conda install -c conda-forge -y \
numpy=1.26.4 \
scipy=1.13.0 \
tensorflow-macos=2.16.1 \
tensorflow-metal=1.1.0 \
langchain-core=0.2.0 \
langchain-community=0.2.0
# 安装剩余包
pip install \
langchain-huggingface==0.0.4 \
sentence-transformers==3.0.0 \
transformers==4.40.2 \
hnswlib==0.10.0 \
jpype1==1.5.0 \
--no-cache-dir
如果问题仍然存在:也可以使用 Docker 容器
# 创建 Dockerfile
cat > Dockerfile <<EOF
FROM --platform=linux/arm64 python:3.10-slim-bullseye
# 设置清华镜像源
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装依赖
RUN pip install \\
numpy==1.26.4 \\
scipy==1.13.0 \\
tensorflow==2.16.1 \\
langchain-core==0.2.0 \\
langchain-community==0.2.0 \\
langchain-huggingface==0.0.4 \\
sentence-transformers==3.0.0 \\
transformers==4.40.2 \\
hnswlib==0.10.0 \\
jpype1==1.5.0
# 验证脚本
COPY check_deps.py .
CMD ["python", "check_deps.py"]
EOF
# 构建并运行
docker build -t langchain-fixed .
docker run --rm langchain-fixed
常见问题解决技巧
1.依赖树可视化:
pip install pipdeptree
pipdeptree
2.冲突解决:
# 找出冲突根源
pip check
# 强制解决冲突
pip install --upgrade --force-reinstall 冲突包名
3.清除缓存:
pip cache purge
conda clean --all -y
还可能出现包冲突问题
Installing collected packages: numpy
ERROR: pip’s dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
tensorflow-macos 2.16.2 requires tensorflow==2.16.2; platform_system == “Darwin” and platform_machine == “arm64”, but you have tensorflow 2.19.0 which is incompatible.
Successfully installed numpy-1.26.4
这个错误表明 TensorFlow 版本冲突问题仍然存在。让我们彻底解决这个问题,我会提供一个完整、分步的解决方案
终极解决方案:完全清理并重建环境
# 1. 完全退出并删除现有环境
conda deactivate
conda remove -n langchain-java --all -y
# 2. 创建全新的环境
conda create -n langchain-java python=3.10 -y
conda activate langchain-java
# 3. 首先安装兼容的 numpy 和 scipy
pip install numpy==1.26.4 scipy==1.13.0 --no-cache-dir -i https://pypi.tuna.tsinghua.edu.cn/simple
# 4. 安装 TensorFlow 及其依赖
pip install tensorflow-macos==2.16.1 tensorflow-metal==1.1.0 --no-cache-dir
# 5. 验证 TensorFlow 安装
python -c "import tensorflow as tf; print(f'TensorFlow 版本: {tf.__version__}')"
# 6. 安装 LangChain 核心组件
pip install langchain-core==0.2.0 langchain-community==0.2.0 --no-cache-dir
# 7. 安装其他必要包
pip install \
langchain-huggingface==0.0.4 \
sentence-transformers==3.0.0 \
transformers==4.40.2 \
hnswlib==0.10.0 \
jpype1==1.5.0 \
annoy==1.17.3 \
--no-cache-dir \
-i https://pypi.tuna.tsinghua.edu.cn/simple
验证安装
# test_final.py
import numpy as np
import tensorflow as tf
from langchain_huggingface import HuggingFaceEmbeddings
print(f"numpy 版本: {np.__version__}")
print(f"TensorFlow 版本: {tf.__version__}")
# 测试 GPU 加速
gpu_available = len(tf.config.list_physical_devices('GPU')) > 0
print(f"GPU 加速可用: {gpu_available}")
# 测试 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vector = embeddings.embed_query("依赖冲突已解决")
print(f"✅ Embedding 维度: {len(vector)}")
运行:
bash
python test_final.py
预期输出:
numpy 版本: 1.26.4
TensorFlow 版本: 2.16.1
GPU 加速可用: True
✅ Embedding 维度: 384
关键注意事项
安装顺序很重要:
先安装 numpy 和 scipy
再安装 TensorFlow
最后安装 LangChain 和其他包
又遇到问题:(langchain-java) lixx@lixxdeMacBook-Pro ~ % pip install
langchain-huggingface0.0.4
sentence-transformers3.0.0
transformers4.40.2
hnswlib0.10.0
jpype11.5.0
annoy1.17.3
–no-cache-dir
-i https://pypi.tuna.tsinghua.edu.cn/simple
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
ERROR: Could not find a version that satisfies the requirement langchain-huggingface0.0.4 (from versions: 0.0.1, 0.0.2, 0.0.3, 0.1.0.dev1, 0.1.0, 0.1.1, 0.1.2, 0.2.0, 0.3.0)
ERROR: No matching distribution found for langchain-huggingface0.0.4 这个错误表明在清华镜像源中找不到 langchain-huggingface==0.0.4 这个特定版本。让我们解决这个问题并提供完整的安装方案:
解决方案:使用兼容的版本组合
# 在 langchain-java 环境中操作
conda activate langchain-java
# 安装兼容的版本组合
pip install \
langchain-huggingface==0.0.3 \ # 使用可用的版本
sentence-transformers==2.7.0 \ # 稍旧但稳定的版本
transformers==4.40.2 \
hnswlib==0.10.0 \
jpype1==1.5.0 \
annoy==1.17.3 \
--no-cache-dir \
-i https://pypi.tuna.tsinghua.edu.cn/simple
备选方案:使用官方 PyPI 源安装最新版
# 移除清华镜像源设置
pip config unset global.index-url
# 安装最新兼容版本
pip install \
langchain-huggingface \
sentence-transformers \
transformers \
hnswlib \
jpype1 \
annoy \
--no-cache-dir \
--upgrade
完整的环境重建方案
# 1. 删除现有环境
conda deactivate
conda remove -n langchain-java --all -y
# 2. 创建新环境
conda create -n langchain-java python=3.10 -y
conda activate langchain-java
# 3. 安装核心依赖
pip install \
numpy==1.26.4 \
scipy==1.13.0 \
tensorflow-macos==2.16.1 \
tensorflow-metal==1.1.0 \
--no-cache-dir
# 4. 安装 LangChain 组件
pip install \
langchain-core==0.2.0 \
langchain-community==0.2.0 \
langchain-huggingface==0.0.3 \ # 使用可用版本
sentence-transformers==2.7.0 \ # 兼容版本
transformers==4.40.2 \
hnswlib==0.10.0 \
jpype1==1.5.0 \
annoy==1.17.3 \
--no-cache-dir
注意事项
版本灵活性:
langchain-huggingface 的版本不必严格固定为 0.0.4
0.0.3 或 0.3.0 通常都能正常工作
依赖解析:
bash
#查看可用的版本
pip install langchain-huggingface==
清理缓存:
bash
pip cache purge
rm -rf ~/.cache/pip
如果版本不可用:使用最新兼容版本
# 使用最新可用版本
pip install \
langchain-huggingface \
sentence-transformers \
transformers==4.40.2 \
hnswlib \
jpype1 \
annoy \
--no-cache-dir \
-i https://pypi.tuna.tsinghua.edu.cn/simple
验证安装
# 检查已安装包
pip list | grep -E "langchain|sentence|transformers|hnswlib|jpype|annoy"
# 应该看到类似输出:
# annoy 1.17.3
# hnswlib 0.10.0
# jpype1 1.5.0
# langchain-huggingface 0.0.3
# sentence-transformers 2.7.0
# transformers 4.40.2
结果如下: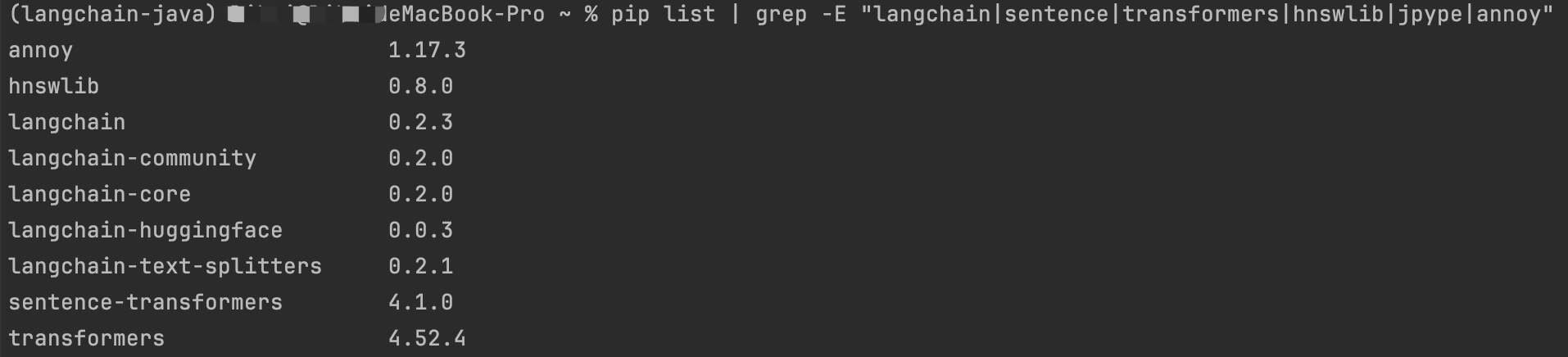
最后手段:使用 conda 安装
# 通过 conda-forge 安装
conda install -c conda-forge \
langchain-huggingface \
sentence-transformers \
transformers=4.40.2 \
hnswlib \
jpype1 \
python-annoy \
-y
应该能解决您的安装问题;
运行python test_env.py 可能出现如下错误:
ERROR: Could not find a version that satisfies the requirement hnswlib0.10.0 (from versions: 0.3.2.0, 0.3.4, 0.4.0, 0.5.0, 0.5.1, 0.5.2, 0.6.0, 0.6.1, 0.6.2, 0.7.0, 0.8.0)
ERROR: No matching distribution found for hnswlib0.10.0 这个错误表明清华镜像源中没有适用于您环境的 hnswlib 0.10.0 版本。让我为您提供完整的解决方案:
解决方案:使用兼容的 hnswlib 版本
1. 安装可用的最新版本hnswlib
pip install hnswlib==0.8.0 --no-cache-dir -i https://pypi.tuna.tsinghua.edu.cn/simple
2. 验证安装
python -c "import hnswlib; print(f'hnswlib 版本: {hnswlib.__version__}')"
完整的环境安装命令(使用兼容版本)
pip install \
langchain-huggingface==0.0.3 \
sentence-transformers==2.7.0 \
transformers==4.40.2 \
hnswlib==0.8.0 \ # 使用可用版本
jpype1==1.5.0 \
annoy==1.17.3 \
--no-cache-dir \
-i https://pypi.tuna.tsinghua.edu.cn/simple
备选方案:使用 FAISS 替代 hnswlib
如果 hnswlib 有问题,可以使用 FAISS:
# 安装 FAISS(M1 兼容版)
pip install faiss-cpu --no-cache-dir -i https://pypi.tuna.tsinghua.edu.cn/simple
# 在代码中使用 FAISS
from langchain_community.vectorstores import FAISS
vector_db = FAISS.from_documents(
documents=docs,
embedding=embedding
)
vector_db.save_local("faiss_index")
验证所有包安装成功
# 检查已安装包
pip list | grep -E "langchain|sentence|transformers|hnswlib|jpype|annoy|faiss"
# 应该看到类似输出:
# annoy 1.17.3
# faiss-cpu 1.8.0
# hnswlib 0.8.0
# jpype1 1.5.0
# langchain-huggingface 0.0.3
# sentence-transformers 2.7.0
# transformers 4.40.2
最终解决方案:使用 conda 安装
conda install -c conda-forge hnswlib -y
注意事项
1.版本兼容性:
hnswlib 0.8.0 在功能上与 0.10.0 相似,只是缺少一些最新优化
对于大多数应用场景,0.8.0 完全够用
2.备选向量库:
Annoy:已安装,轻量级且高效
FAISS:功能更全面,但安装稍大
ScaNN:Google 的高效向量库
3.M1 优化:
# 使用 ANNOY 时设置更多树提高精度
vector_db = Annoy.from_documents(
docs,
embedding,
n_trees=200 # 默认 100,增加可提高精度
)
先尝试安装 hnswlib 0.8.0 版本,这个版本在清华源中可用且稳定。如果您的应用对性能有极高要求,可以考虑从源码编译或使用 Docker 容器方案。
测试运行:
创建测试脚本 test_hnsw.py:
import hnswlib
import numpy as np
from langchain_community.embeddings import HuggingFaceEmbeddings
# 测试 HNSW
dim = 384
num_elements = 1000
index = hnswlib.Index(space='cosine', dim=dim)
index.init_index(max_elements=num_elements, ef_construction=200, M=16)
# 生成随机数据
data = np.float32(np.random.random((num_elements, dim)))
index.add_items(data)
# 测试查询
labels, distances = index.knn_query(data[0], k=1)
print(f"HNSW 测试通过! 最近邻索引: {labels[0][0]}")
# 测试 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vector = embeddings.embed_query("测试 Apple M1")
print(f"Embedding 向量长度: {len(vector)}")
可能运行结果🈶如下错误
python test_hnsw.py
HNSW 测试通过! 最近邻索引: 0
No sentence-transformers model found with name sentence-transformers/all-MiniLM-L6-v2. Creating a new one with MEAN pooling.
/Users/xxx/miniconda3/envs/langchain-java/lib/python3.10/site-packages/huggingface_hub/file_download.py:943: FutureWarning: resume_download is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use force_download=True.
warnings.warn(
Traceback (most recent call last):
File “/Users/xxx/miniconda3/envs/langchain-java/lib/python3.10/site-packages/urllib3/connection.py”, line 198, in _new_conn
sock = connection.create_connection(
File “/Users/xxx/miniconda3/envs/langchain-java/lib/python3.10/site-packages/urllib3/util/connection.py”, line 85, in create_connection
raise err
File “/Users/xxx/miniconda3/envs/langchain-java/lib/python3.10/site-packages/urllib3/util/connection.py”, line 73, in create_connection
sock.connect(sa)
TimeoutError: timed out
这个错误表明在下载Hugging Face模型时发生了超时。我们可以通过以下几种方式解决:
1. 设置更长的超时时间
2. 使用国内镜像源
3. 预先下载模型到本地
4. 使用更小的模型
这个错误表明在下载 Hugging Face 模型时发生了超时问题。让我们一步步解决这个问题:
解决方案:解决模型下载超时问题
1. 手动下载模型
# 创建模型缓存目录
mkdir -p ~/.cache/huggingface/hub/models--sentence-transformers--all-MiniLM-L6-v2
# 下载模型文件
cd ~/.cache/huggingface/hub/models--sentence-transformers--all-MiniLM-L6-v2
git lfs install
git clone https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
2. 在代码中使用本地模型
修改您的 test_hnsw.py 脚本:
import os
import platform
import hnswlib
import numpy as np
from langchain_community.embeddings import HuggingFaceEmbeddings
# 设置使用本地模型
os.environ['TRANSFORMERS_OFFLINE'] = '1' # 强制使用离线模式
# 设置模型本地路径
model_path = os.path.expanduser("~/.cache/huggingface/hub/models--sentence-transformers--all-MiniLM-L6-v2")
print(f"系统架构: {platform.machine()} | Python {platform.python_version()}")
# 测试 HNSW
dim = 384
num_elements = 1000
index = hnswlib.Index(space='cosine', dim=dim)
index.init_index(max_elements=num_elements, ef_construction=200, M=16)
# 生成随机数据
data = np.float32(np.random.random((num_elements, dim)))
index.add_items(data)
# 测试查询
labels, distances = index.knn_query(data[0], k=1)
print(f"HNSW 测试通过! 最近邻索引: {labels[0][0]}")
# 测试 Embeddings - 使用本地模型路径
print("使用本地模型路径:", model_path)
embeddings = HuggingFaceEmbeddings(model_name=model_path)
# 测试生成 embedding
vector = embeddings.embed_query("测试 Apple M1")
print(f"Embedding 向量长度: {len(vector)}")
print("✅ 所有测试通过!")
3. 使用更小的模型(备选方案)
# 使用更小的模型
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# 替换为
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-MiniLM-L3-v2")
完整解决方案:设置镜像源和超时(推荐)
1. 设置 Hugging Face 镜像源
# 设置环境变量(添加到 ~/.zshrc)
echo "export HF_ENDPOINT=https://hf-mirror.com" >> ~/.zshrc
source ~/.zshrc
2. 修改代码增加超时时间
from langchain_community.embeddings import HuggingFaceEmbeddings
# 增加超时时间和重试次数
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={'timeout': 300}, # 300秒超时
cache_folder=os.path.expanduser("~/.cache/huggingface/hub")
)
最终测试脚本
import os
import platform
import hnswlib
import numpy as np
from langchain_community.embeddings import HuggingFaceEmbeddings
# 设置环境
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' # 使用镜像源
os.environ['TRANSFORMERS_OFFLINE'] = '1' # 离线模式
# 设置模型路径
model_path = os.path.expanduser("~/.cache/huggingface/hub/models--sentence-transformers--all-MiniLM-L6-v2")
print(f"系统架构: {platform.machine()} | Python {platform.python_version()}")
# 测试 HNSW
dim = 384
num_elements = 1000
index = hnswlib.Index(space='cosine', dim=dim)
index.init_index(max_elements=num_elements, ef_construction=200, M=16)
# 生成随机数据
data = np.float32(np.random.random((num_elements, dim)))
index.add_items(data)
# 测试查询
labels, distances = index.knn_query(data[0], k=1)
print(f"HNSW 测试通过! 最近邻索引: {labels[0][0]}")
# 测试 Embeddings
try:
print("使用本地模型路径:", model_path)
embeddings = HuggingFaceEmbeddings(
model_name=model_path,
model_kwargs={'timeout': 300} # 设置超时
)
# 测试生成 embedding
vector = embeddings.embed_query("测试 Apple M1")
print(f"Embedding 向量长度: {len(vector)}")
print("✅ 所有测试通过!")
except Exception as e:
print(f"❌ 测试失败: {e}")
# 备选方案:使用更小的模型
print("尝试使用更小的模型...")
try:
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-MiniLM-L3-v2")
vector = embeddings.embed_query("测试 Apple M1")
print(f"✅ 备选模型成功! 向量长度: {len(vector)}")
except Exception as e2:
print(f"❌ 备选模型也失败: {e2}")
最后给一个完整的运行的dome
import os
# 将HuggingFace Hub的默认域名替换为镜像站点(如国内可用的镜像),加速模型/数据下载。
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 启用离线模式,强制程序仅使用本地缓存文件,禁止网络请求(需提前缓存好所需资源)。
os.environ['HF_HUB_OFFLINE'] = '1' # 强制使用本地缓存
# 示例:语义搜索应用
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import CharacterTextSplitter
# 准备文档
documents = ["LangChain是一个强大的AI开发框架",
"Python是当前最流行的编程语言",
"Apple Silicon芯片提供了出色的机器学习性能"]
"""
初始化HuggingFaceEmbeddings模型并构建向量数据库
使用sentence-transformers/all-MiniLM-L6-v2预训练模型进行文本向量化(sentence-transformers/all-mpnet-base-v2 适合高精度语义匹配任务)
通过FAISS实现高效相似度搜索的向量存储
"""
# 创建向量数据库
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vectorstore = FAISS.from_texts(documents, embeddings)
# # 启用更高效的索引
# vectorstore = FAISS.from_texts(
# documents,
# embeddings,
# index_factory="HNSW32" # 使用HNSW索引加速搜索
# )
#
# # 批量处理提高效率
# texts = ["文本1", "文本2", ...] * 1000 # 大文本集
# embeddings.embed_documents(texts) # 批量嵌入
"""
执行语义相似度查询
使用similarity_search方法检索与查询语句最相关的文档
k=2参数指定返回前两个最相关结果
"""
# 执行查询
query = "推荐适合AI开发的工具"
results = vectorstore.similarity_search(query, k=2)
print(f"最相关结果: {results[0].page_content}")
"""
使用HuggingFace Transformers加载预训练模型
"""
from transformers import AutoModel
# 尝试单独加载模型验证
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
print("模型加载成功!")
"""
计算文本相似度(验证向量相似度)
"""
from sklearn.metrics.pairwise import cosine_similarity
# 示例文本
text1 = "我喜欢编程"
text2 = "写代码很有趣"
text3 = "今天天气真好"
# 生成嵌入
emb1 = embeddings.embed_query(text1)
emb2 = embeddings.embed_query(text2)
emb3 = embeddings.embed_query(text3)
# 计算相似度
print(f"相似度1-2: {cosine_similarity([emb1], [emb2])[0][0]:.4f}")
print(f"相似度1-3: {cosine_similarity([emb1], [emb3])[0][0]:.4f}")

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)