让浏览器拥有思考力:LLM+Playwright实现自主行动的智能助手
创建状态图# 添加节点# 添加边和条件边"end": END# 更多边定义...当浏览器拥有思考能力,它不再只是信息世界的窗口,而成为我们的智能助手和得力搭档。这不仅仅是技术上的进步,更代表着人机交互范式的革新 —— 我们不再需要适应机器的工作方式,而是让机器理解并适应我们的意图和需求。在不久的将来,或许我们会惊讶地发现,曾经需要我们手动完成的繁琐网络任务,现在只需一句简单的指令,就能由这位"会思
你是否曾梦想过拥有一个浏览器助手,它能理解你的意图,自主规划任务,像真人一样操作网页?本文将分享如何结合大型语言模型(LLM)和浏览器自动化工具(Playwright MCP)构建一个能自主思考、自主行动的浏览器智能体系统。
前面文章有介绍过通过LLM结合Playwright-MCP进行浏览器自动化,整体介绍的功能其实相对简单,只是通过LLM简单执行了mcp工具而已,但是实际的应用场景肯定不是单独的执行某一个动作这么简单,所以就使用LLM结合ReAct模式、Playwright-MCP实现了一个能自主规划自主行动的浏览器自动化系统。
ps:文末有项目的github地址。
这不再是简单的自动化,而是浏览器的自主化 —— 它能理解你的意图,自主规划任务步骤,灵活应对各种网页场景,甚至能从失败中学习和调整策略。
一、系统架构
笔者设计的系统核心是一个基于LangGraph构建的工作流引擎,它将大语言模型的思考能力与Playwright MCP的浏览器控制能力无缝结合。整个系统由四个关键组件构成:
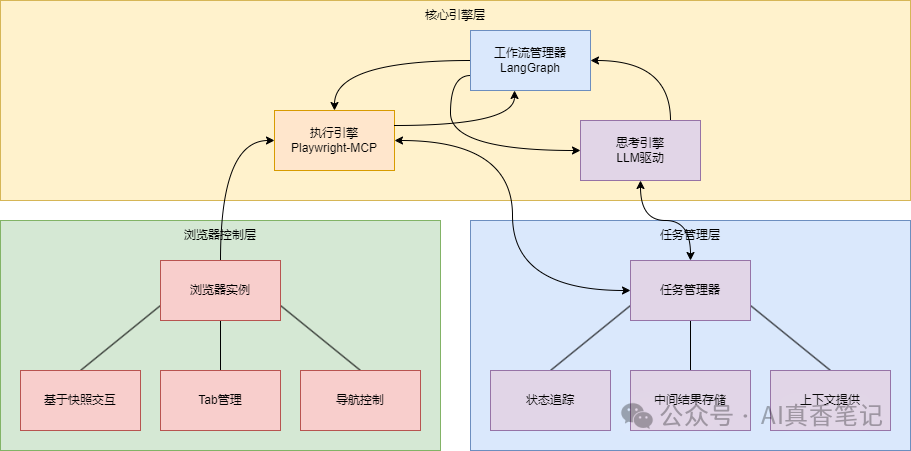
系统架构图
-
思考引擎:由大语言模型驱动,负责理解用户指令、规划任务、解析网页内容、提取关键信息
-
执行引擎:基于Playwright MCP,负责精准控制浏览器执行各种操作
-
工作流管理器:基于LangGraph构建,协调思考和执行的循环流程
-
任务管理器:追踪任务状态,存储中间结果,为LLM提供执行上下文
这种设计最大的亮点在于实现了"思考-执行-观察-再思考"的闭环,模拟人类使用浏览器的自然过程。
二、工作原理
ReAct设计模式
系统运行时采用ReAct设计模式,让它能像人类一样思考和操作浏览器:
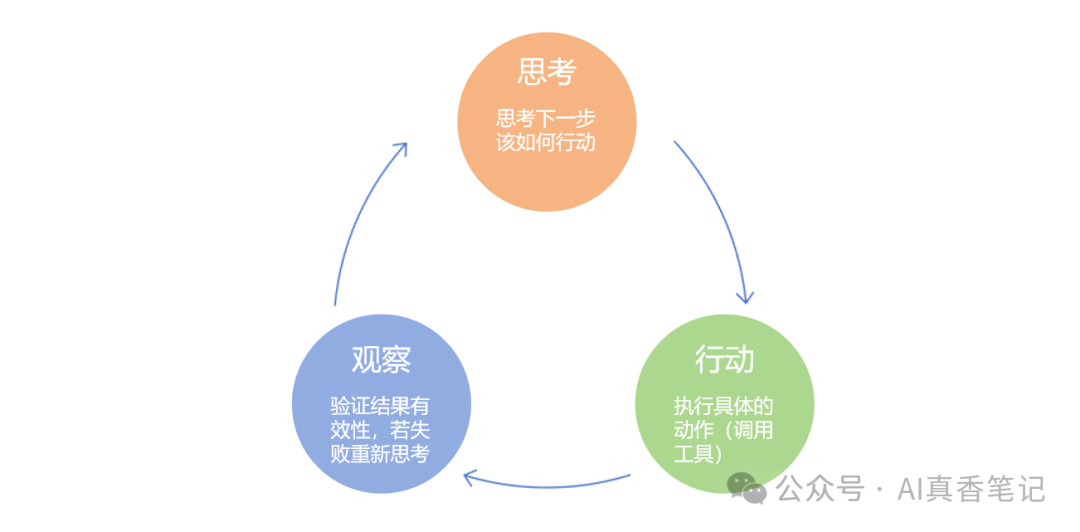
举个例子,当你告诉系统"帮我找一下今天的天气,然后查询一下从上海到北京的机票价格"时,它会:
-
理解意图:拆解为"查询天气"和"查询机票"两个主要目标
-
规划任务:决定先打开天气网站查询天气,然后访问机票预订网站查询航班
-
执行操作:控制浏览器打开天气网站,定位搜索框,输入查询内容...
-
观察结果:分析返回的网页内容,提取天气信息
-
思考调整:基于获取的天气信息,继续规划下一步的机票查询任务
-
继续执行:打开机票预订网站,输入出发地、目的地和日期...
整个过程就像有个人在替你操作浏览器,不仅能按步骤执行,还能根据网页内容的变化灵活调整策略。
技术实现:大模型驱动的决策流
从技术角度看,系统的工作流由以下几个关键节点构成:
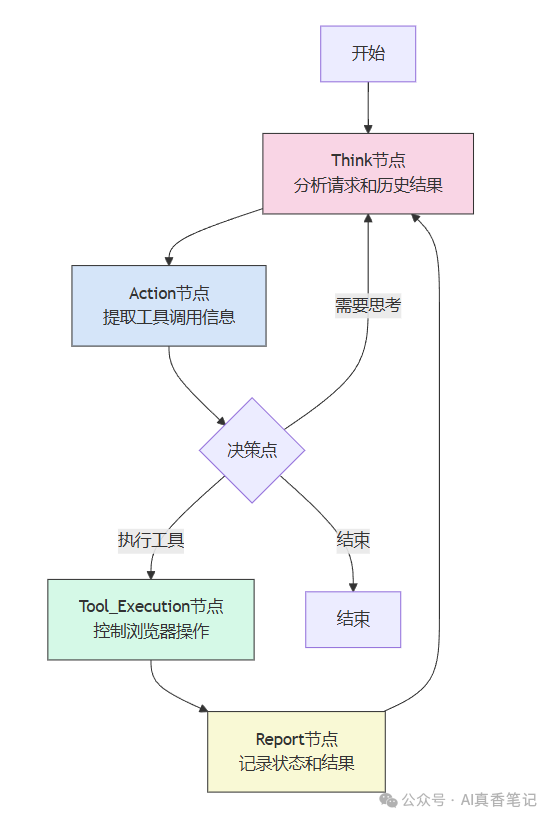
关键节点
-
Think节点:调用LLM分析用户请求和历史任务结果,规划下一步任务
-
Action节点:准备工具调用,从任务中提取tools_call信息
-
Tool_Execution节点:直接执行工具调用,控制浏览器完成操作
-
Report节点:记录执行状态,汇总任务信息供下一轮决策使用
这种基于LangGraph构建的工作流使得系统能够维持持续的思考-执行循环,每次操作后都能获取最新的页面状态,重新思考下一步行动。
三、技术亮点
在实现过程中,笔者引入了几个技术创新点,大幅提升了系统的效率和灵活性:
1. 直接工具调用
传统方案中,LLM需要先生成工具调用指令,然后通过复杂的解析过程执行工具。我们优化了这一流程,实现从任务直接提取tools_call并执行:
# 直接从当前任务中获取tools_call信息
tools_call = current_task.get("tools_call", [])
# 遍历并直接执行每个工具
for tool_call in tools_call:
tool_name = tool_call.get("tool", "")
tool_args = tool_call.get("tool_args", {})
# 查找并直接调用匹配工具
target_tool = find_tool_by_name(tool_name)
result = await target_tool.ainvoke(tool_args)
这种设计避免了AI中间层的额外开销,大幅提升了执行效率。
2. Playwright-MCP动作批量执行
对于需要连续操作的场景(如点击多个元素),Playwirght-MCP有个问题,每次工具调用后页面的快照都会更新,没法按照预先设定的参数进行工具调用(官网作者也明确指出不应该连续操作),经分析后大致摸索出ref的变化规律,实现了连续操作的功能:
# 如果不是第一个工具,自动调整ref参数
if tool_index > 0:
start_with_ref = current_tool_args["ref"][0]
old_ref_num = int(current_tool_args["ref"][1])
end_with_ref = current_tool_args["ref"][2:]
new_ref_num = old_ref_num + tool_index
current_tool_args["ref"] = f"{start_with_ref}{new_ref_num}{end_with_ref}"
这个看似简单的优化解决了连续操作中引用错误的核心问题,让系统能够流畅地执行复杂的多步骤操作。
3. 任务类型自适应处理
系统根据任务类型(动作执行/信息检索)采用不同的处理策略:
-
动作执行:直接获取页面快照,更新任务状态
-
信息检索:调用LLM从页面中提取结构化数据,更便于后续决策
-
任务检查:调用LLM根据页面结构判断任务是否完成,特别针对网页加载这种耗时任务
# 根据任务类型执行特定的后处理
if task_type == "信息检索" and "snapshot" in tasks[current_task_index]:
snapshot_result = tasks[current_task_index]["snapshot"]
# 使用LLM提取结构化数据
extracted_data = await extract_data_from_snapshot(
snapshot_result, current_task.get("description", "")
)
tasks[current_task_index]["extracted_data"] = extracted_data
4. 任务检查类型的优化处理
除了"动作执行"和"信息检索",系统还支持"任务检查"类型,用于验证页面状态和处理加载等情况。针对此类型任务,我们实现了特殊的处理逻辑:
-
页面状态验证:检查页面是否加载完成,内容是否符合预期
-
等待处理:处理需要较长加载时间的任务,通过检查页面状态决定后续操作
-
快照获取与分析:自动获取页面快照并进行分析
四、案例展示
来看一个真实案例,百度搜索特定主题文章并总结。我们只需要告诉系统:
"打开百度,搜索谷歌A2A协议,选择2篇相关性最高的文章并总结文章内容"
系统会自动:
打开百度网站
搜索框输入"谷歌A2A协议"
筛选2篇相关性最高的文章并打开
自动切换文章tab进行文章总结
总结最终结果
整个过程中,系统会自动处理:页面加载延迟、元素定位错误、页面自动切换等问题,表现出接近人类的灵活性和适应性。

结果截图
五、核心代码
如果你对实现细节感兴趣,这里有几段核心代码值得关注:
1. 任务规划逻辑
async def think(state: AgentState) -> AgentState:
# 获取用户请求和任务历史
messages = state["messages"]
task_manager = state.get("task_manager", {"tasks": [], "current_task_index": None})
# 构建提示模板,要求LLM规划下一步任务
system_prompt = """
你是一个智能浏览器自动化助手,负责规划和执行连续性的浏览器操作任务。
根据用户请求和已完成任务的结果,请规划下一步应该执行的单个任务。
每个任务必须归类为以下类型之一:
1. "动作执行": 如打开网页、点击按钮、输入文本等操作性任务
2. "信息检索": 如采集搜索结果、提取网页数据等获取信息的任务
"""
# 调用LLM规划下一个任务
response = await model.ainvoke(thinking_messages)
# 解析LLM返回的任务JSON
task_data = json.loads(task_json)
# 创建新任务并添加到任务列表
new_task = {
"description": task_data.get("task", ""),
"task_type": task_data.get("task_type", "动作执行"),
"status": "pending",
"tools_call": task_data.get("tools_call", [])
}
# 更新任务管理器
tasks.append(new_task)
task_manager["current_task_index"] = len(tasks) - 1
return {
"messages": messages,
"task_manager": task_manager,
"execution_status": "executing",
}
2. 工具执行逻辑
async def tool_execution(state: AgentState) -> AgentState:
# 获取当前任务
task_manager = state.get("task_manager", {"tasks": [], "current_task_index": None})
tasks = task_manager.get("tasks", [])
current_task_index = task_manager.get("current_task_index")
current_task = tasks[current_task_index]
# 获取工具调用信息
tools_call = current_task.get("tools_call", [])
# 执行每个工具调用
for tool_index, tool_call in enumerate(tools_call):
current_tool_name = tool_call.get("tool", "")
current_tool_args = tool_call.get("tool_args", {})
# 查找匹配工具
target_tool = find_tool_by_name(current_tool_name)
# 对多工具调用调整参数
if tool_index > 0:
# 调整ref参数逻辑...
# 直接调用工具
tool_result = await target_tool.ainvoke(current_tool_args)
# 处理结果并更新任务状态
# ...
3. 系统工作流定义
def build_agent_workflow():
# 创建状态图
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("think", think)
workflow.add_node("action", action)
workflow.add_node("tool_execution", tool_execution)
workflow.add_node("report", report)
# 添加边和条件边
workflow.add_edge(START, "think")
workflow.add_edge("think", "action")
workflow.add_conditional_edges(
"action", decide_next_step, {
"think": "think",
"tool": "tool_execution",
"end": END
}
)
# 更多边定义...
return workflow.compile()
六、实用价值与拓展方向
这样的智能浏览器助手有着广泛的应用场景:
-
个人助手:帮助用户完成复杂的网络任务,如预订机票、比价、填写表单等
-
企业自动化:执行重复性的业务流程,如数据录入、报表生成、系统操作等
-
辅助调研:自动收集和整理网络信息,提供结构化的研究报告
-
交互式教程:为新用户演示复杂网站的操作流程,并回答相关问题
-
网站测试:以人类使用方式测试网站功能,发现传统自动化测试难以捕捉的问题
未来,我们可以进一步增强系统能力:
-
视觉理解:加入计算机视觉能力,理解图片和视频内容
-
多轮交互:支持用户在执行过程中调整和修改指令
-
记忆与学习:记住用户偏好和常用操作,随着使用不断优化
-
多模态输出:生成富文本、图表等多种形式的结果呈现
结语
当浏览器拥有思考能力,它不再只是信息世界的窗口,而成为我们的智能助手和得力搭档。这不仅仅是技术上的进步,更代表着人机交互范式的革新 —— 我们不再需要适应机器的工作方式,而是让机器理解并适应我们的意图和需求。
在不久的将来,或许我们会惊讶地发现,曾经需要我们手动完成的繁琐网络任务,现在只需一句简单的指令,就能由这位"会思考的浏览器助手"优雅地完成。这就是AI赋能的魅力,也是笔者想着去尝试创建这个系统的初衷。
如果你对这个项目感兴趣,欢迎尝试和改进。所有代码都已开源,让我们一起探索AI的无限可能!目前代码还比较粗糙,很多功能不够完善,后续会持续进行优化。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献725条内容
已为社区贡献725条内容

所有评论(0)