【理论基础】深度强化学习(一)
深度强化学习(Deep Reinforcement Learning,DRL)将深度学习的感知能力和强化学习的决策能力相结合,可以直接根据输入的图像进行控制,是一种更接近人类思维方式的人工智能方法。深度学习具有较强的感知能力,但是缺乏一定的决策能力;而强化学习具有决策能力,对感知问题束手无策。因此,将两者结合起来,优势互补,为复杂系统的感知决策问题提供了解决思路。智能体与环境的不断交互(即在给定状
1 引言
深度强化学习(Deep Reinforcement Learning,DRL)将深度学习的感知能力和强化学习的决策能力相结合,可以直接根据输入的图像进行控制,是一种更接近人类思维方式的人工智能方法。深度学习具有较强的感知能力,但是缺乏一定的决策能力;而强化学习具有决策能力,对感知问题束手无策。因此,将两者结合起来,优势互补,为复杂系统的感知决策问题提供了解决思路。智能体与环境的不断交互(即在给定状态采取动作),进而获得奖励,此时环境从一个状态转移到下一个状态。智能体通过不断优化自身动作策略,以期待最大化其长期回报或收益(奖励之和),如图1所示。
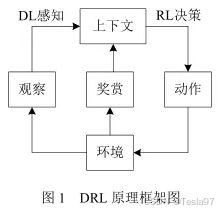
DRL通过使用神经网络来近似值函数或策略函数,从而实现对复杂环境中的决策和行为的学习。 在深度强化学习中,智能体通过与环境的交互来学习最优策略。智能体通过观察环境的状态,选择一个动作,并接收环境的奖励信号来评估动作的好坏。通过不断地与环境交互,智能体通过优化策略来最大化累积奖励。 深度强化学习的核心是使用深度神经网络来近似值函数或策略函数。深度神经网络可以处理高维的输入数据,并通过反向传播算法来更新网络的参数,从而实现对值函数或策略函数的优化。 深度强化学习已经在许多领域取得了重要的突破,如游戏玩法、机器人控制、自动驾驶等。它能够处理高维、连续的状态和动作空间,并且能够通过大量的训练数据来学习复杂的决策和行为。 总而言之,深度强化学习是一种结合了深度学习和强化学习的方法,通过使用深度神经网络来近似值函数或策略函数,实现对复杂环境中的决策和行为的学习。
2 强化学习
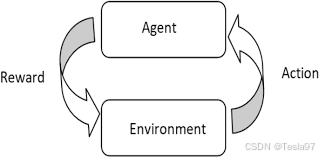
在强化学习中,智能体(Agent)通过在环境中执行一系列动作,目标是使其获得的累积奖励最大化。环境会根据智能体的动作提供相应的反馈(如奖励或惩罚),智能体则利用这些反馈不断优化自身的策略。
2.1 马尔可夫奖励过程
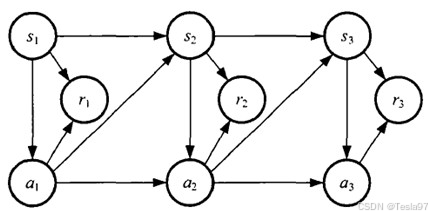
马尔可夫过程和马尔可夫奖励过程都是自发改变的随机过程;而如果有一个外界的“刺激”来共同改变这个随机过程,就有了马尔可夫决策过程(Markov decision process,MDP)。我们将这个来自外界的刺激称为智能体(agent)的动作,在马尔可夫奖励过程(MRP)的基础上加入动作,就得到了马尔可夫决策过程(MDP),其包含以下四个关键组成部分:
- 状态(State, S):表示当前环境的具体情况或特征。
- 动作(Action, A):智能体在某一状态下可选择执行的操作。
- 奖励(Reward, R):智能体执行某一动作后,环境返回的反馈,用于衡量该动作的优劣。
- 策略(Policy, π):一种决策规则,定义智能体在每个状态中应选择的行动方式。
表示状态转移概率函数,假设
时刻状态为
,智能体执行动作
后以概率转移进入下一个状态
,则状态转移概率函数可以表示为:
R表示智能体所得的反馈奖励函数,即智能体执行一个动作a后获得的即时奖励,可表示
一个完整的马尔可夫决策过程可用下图进行解释:
回报函数之和如下:
其中折扣因子表示当前选择动作对未来的影响程度,其值在0到1之间;n表示马尔可夫当前状态到目标状态的步数。
举个栗子:
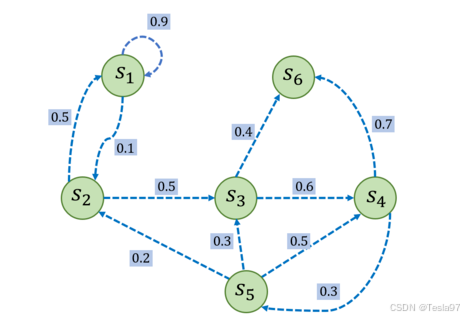
我们可以写出这个马尔可夫过程的状态转移矩阵:
其中第行
列的值
则代表从状态
转移到
的概率。给定一个马尔可夫过程,我们就可以从某个状态出发,根据它的状态转移矩阵生成一个状态序列,这个步骤也被叫做采样。例如,从
出发,可以生成序列
或序列
等。生成这些序列的概率和状态转移矩阵有关。
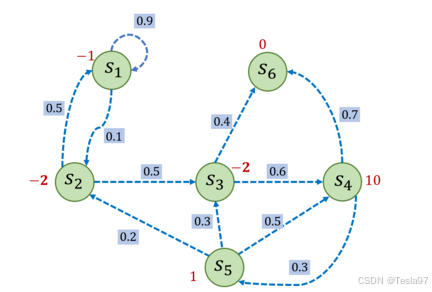
比如选取为起始状态,设置
,采样到一条状态序列为
,就可以计算
的回报
,得到
。
接下来我们用代码表示图中的马尔可夫奖励过程,并且定义计算回报的函数。
import numpy as np
np.random.seed(0)
# 定义状态转移概率矩阵P
P = [
[0.9, 0.1, 0.0, 0.0, 0.0, 0.0],
[0.5, 0.0, 0.5, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.6, 0.0, 0.4],
[0.0, 0.0, 0.0, 0.0, 0.3, 0.7],
[0.0, 0.2, 0.3, 0.5, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 1.0],
]
P = np.array(P)
rewards = [-1, -2, -2, 10, 1, 0] # 定义奖励函数
gamma = 0.5 # 定义折扣因子
# 给定一条序列,计算从某个索引(起始状态)开始到序列最后(终止状态)得到的回报
def compute_return(start_index, chain, gamma):
G = 0
for i in reversed(range(start_index, len(chain))):
G = gamma * G + rewards[chain[i] - 1]
return G
# 一个状态序列,s1-s2-s3-s6
chain = [1, 2, 3, 6]
start_index = 0
G = compute_return(start_index, chain, gamma)
print("根据本序列计算得到回报为:%s。" % G)根据本序列计算得到回报为:-2.5。
在马尔可夫奖励过程中,一个状态的期望回报(即从这个状态出发的未来累积奖励的期望)被称为这个状态的价值。所有状态的价值就组成了价值函数,价值函数的输入为某个状态,输出为这个状态的价值。我们将价值函数写成,即
在上式的最后一个等号中,一方面,即时奖励的期望正是奖励函数的输出,另一方面,等式中剩余部分
可以根据从状态
出发的转移概率得到,即得
上式就是马尔可夫奖励过程中非常有名的贝尔曼方程(Bellman equation),对每一个状态都成立。若一个马尔可夫奖励过程一共有
个状态,即
我们将所有状态的价值表示成一个列向量
,同理,将奖励函数写成一个列向量
于是我们可以将贝尔曼方程写成矩阵的形式:
我们可以直接根据矩阵运算求解,得到以下解析解:
以上解析解的计算复杂度是,其中
是状态个数,因此这种方法只适用很小的马尔可夫奖励过程。求解较大规模的马尔可夫奖励过程中的价值函数时,可以使用动态规划(dynamic programming)算法、蒙特卡洛方法(Monte-Carlo method)和时序差分(temporal difference),这些以后会慢慢介绍(点个关注)。
计算该马尔可夫奖励过程中所有状态的价值
def compute(P, rewards, gamma, states_num):
''' 利用贝尔曼方程的矩阵形式计算解析解,states_num是MRP的状态数 '''
rewards = np.array(rewards).reshape((-1, 1)) #将rewards写成列向量形式
value = np.dot(np.linalg.inv(np.eye(states_num, states_num) - gamma * P),
rewards)
return value
V = compute(P, rewards, gamma, 6)
print("MRP中每个状态价值分别为\n", V)MRP中每个状态价值分别为
[[-2.01950168]
[-2.21451846]
[ 1.16142785]
[10.53809283]
[ 3.58728554]
[ 0. ]]根据以上代码,求解得到各个状态的价值,具体如下:
我们现在用贝尔曼方程来进行简单的验证。例如,对于状态,当
时,有
左右两边的值几乎是相等的,说明我们求解得到的价值函数是满足状态为时的贝尔曼方程。读者可以自行验证在其他状态时贝尔曼方程是否也成立。若贝尔曼方程对于所有状态都成立,就可以说明我们求解得到的价值函数是正确的。除了使用动态规划算法,马尔可夫奖励过程中的价值函数也可以通过蒙特卡洛方法估计得到,以后会讲到。
2.2 马尔可夫决策过程
我们发现马尔可夫决策过程( MDP )与 马尔可夫奖励过程(MRP) 非常相像,主要区别为 MDP 中的状态转移函数和奖励函数都比 MRP 多了动作作为自变量。注意,在上面 MDP 的定义中,我们不再使用类似 MRP 定义中的状态转移矩阵方式,而是直接表示成了状态转移函数。这样做一是因为此时状态转移与动作也有关,变成了一个三维数组,而不再是一个矩阵(二维数组);二是因为状态转移函数更具有一般意义,例如,如果状态集合不是有限的,就无法用数组表示,但仍然可以用状态转移函数表示。我们在之后的课程学习中会遇到连续状态的 MDP 环境,那时状态集合都不是有限的。现在我们主要关注于离散状态的 MDP 环境,此时状态集合是有限的。
不同于马尔可夫奖励过程,在马尔可夫决策过程中,通常存在一个智能体来执行动作。例如,一只机器狗各个活动关节随意的晃动那就是一个马尔可夫奖励过程,它如果凭借运气找到了一个步态系统稳定,就能获得比较大的奖励;如果有个智能体策略在控制着这只狗往哪个方向前进,就可以主动选择获得步态系统稳定获得比较大的奖励。马尔可夫决策过程是一个与时间相关的不断进行的过程,在智能体和环境 MDP 之间存在一个不断交互的过程。
智能体的策略(Policy)通常用字母来表示,策略
是一个函数,表示在输入状态
情况下采取动作
的概率。当一个策略是确定性策略(deterministic policy)时,它在每个状态时只输出一个确定性的动作,即只有该动作的概率为 1,其他动作的概率为 0;当一个策略是随机性策略(stochastic policy)时,它在每个状态时输出的是关于动作的概率分布,然后根据该分布进行采样就可以得到一个动作。在 MDP 中,由于马尔可夫性质的存在,策略只需要与当前状态有关,不需要考虑历史状态。回顾一下在 MRP 中的价值函数,在 MDP 中也同样可以定义类似的价值函数。但此时的价值函数与策略有关,这意为着对于两个不同的策略来说,它们在同一个状态下的价值也很可能是不同的。这很好理解,因为不同的策略会采取不同的动作,从而之后会遇到不同的状态,以及获得不同的奖励,所以它们的累积奖励的期望也就不同,即状态价值不同。
其中,状态价值函数(state-value function)用表示在 MDP 中基于策略
,定义为从状态
出发遵循策略能获得的期望回报,数学表达为:
动作价值函数(action-value function)。用表示在 MDP 遵循策略
时,对当前状态
执行动作
得到的期望回报:
状态价值函数和动作价值函数之间的关系:在使用策略中,状态
的价值等于在该状态下基于策略
采取所有动作的概率与相应的价值相乘再求和的结果:
使用策略时,状态
下采取动作
的价值等于即时奖励加上经过衰减后的所有可能的下一个状态的状态转移概率与相应的价值的乘积:
贝尔曼期望方程(Bellman Expectation Equation):
强化学习强
价值函数和贝尔曼方程是强化学习非常重要的组成部分,之后强化学习算法都是据此推导出来的。
课程资料:https://github.com/wangshusen/DRL
下载链接:https://pan.baidu.com/s/1XpTgny_Vr0LobBsuYF4KkA 密码:x0wb

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)